融合多粒度特征的低资源语言词性标注和依存分析联合模型
2023-10-24毛存礼余正涛高盛祥黄于欣王振晗
陆 杉,毛存礼,余正涛,高盛祥,黄于欣,王振晗
(1. 昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2. 昆明理工大学 云南省人工智能重点实验室,云南 昆明 650500)
0 引言
泰语、越南语皆属于资源稀缺型语言,其相关依存分析研究较少并且效果不佳。大多数传统的依存分析模型都靠人工定义核心的特征工程[1-2],但是这种方法受特征选取的影响较大,随着深度神经网络技术为自然语言处理研究带来崭新建模方式和性能上的巨大提升,基于神经网络的依存分析方法成为研究热点[3-5]。
目前,基于神经网络的依存分析主流的方法为基于转移的依存分析[4]和基于图的依存分析[5]。基于图的依存分析方法的目的是寻找一棵最大生成树,得到句子的整体的依存结构全局最优解,该方法对长距离依存分析准确率较高,可处理非投射现象,但模型解码时需进行全局搜索,算法复杂度较高,耗时较长。而基于转移的依存分析将句子的解码过程建模为一个有限自动机问题,使模型可以达到线性时间复杂度,但其采用的是局部搜索策略,容易出现错误传递现象,且准确率要低于基于图的依存分析方法。
无论是基于图的方法还是基于转移的方法,编码层都只使用了简单的词向量表示,如图1所示。泰语句子在进行依存分析的过程中仅仅利用了词语的语义,然而,泰语由字符、子词以及词语三种粒度组成,将三种不同粒度的表征结合能从各个层面更好地表征其语义信息。另外,基于深度学习训练方式的模型在一定程度上依赖于训练数据的规模,所以,深度学习方法针对标注数据充足的语言时往往都能取得较好的效果,但针对泰语、越南语这样的低资源语言时,模型获得的效果就不太理想,且现有方法处理泰语、越南语依存分析时,使用的词性标注信息都是和依存分析任务分开处理得到的,词性标注和依存分析作为独立的任务单独训练会导致其任务之间特征信息传递不连贯,增加词性标注错误在依存分析任务上的传递。
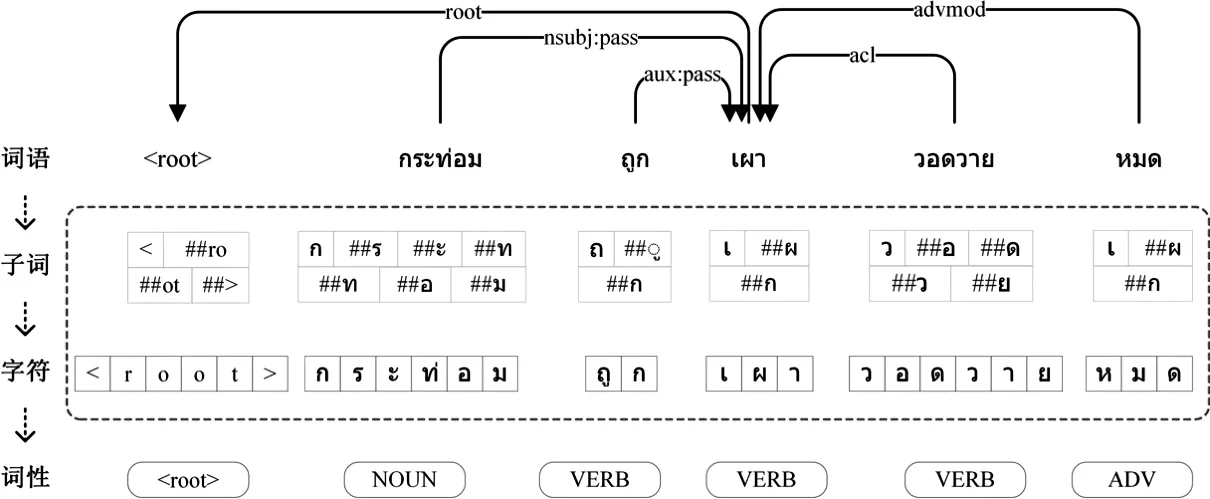
图1 泰语依存分析结果示例(汉语释义:小屋被烧毁了。)
针对上述问题,本文提出融合多粒度特征的词性标注和依存分析联合模型。与中文、英文等拥有丰富标注数据的语言不同,泰语、越南语的公开依存分析标注数据分别仅有1 000条和3 000条。为缓解泰语、越南语标注数据资源不足问题,从维基百科获取大规模单语语料,使用Word2Vec[6]将其训练成词向量来表征词级嵌入,获得词之间丰富的相似性特征信息;利用Jacob Devlin等人[7]2018年提出的一种预训练语言模型——BERT,并结合层注意力机制来表征词语的子词级嵌入,使词语的子词表征能包含此句话丰富的上下文信息,并充分吸收预训练模型中的词性、句法等信息[8];通过BiLSTM来编码表征词语的字符级嵌入,使字符级表征拥有丰富的词法信息[6];并把它们拼接作为联合嵌入,使最终嵌入拥有更加丰富的语义、上下文、句法等信息,有效缓解了由于训练数据不足导致的模型性能不佳的问题。最后,通过联合训练的方式,使词性标注和依存分析组件相互共享知识,缓解依存分析和词性标注任务之间错误传递和不连贯性问题。
本文主要贡献如下:
(1) 利用多粒度特征联合嵌入的方式,在各个粒度嵌入上使用相应方法,使词嵌入拥有丰富的上下文语义信息及词法、句法信息,有效缓解了泰语、越南语标注数据稀缺的问题;
(2) 通过联合训练的方式,使词性标注和依存分析模型之间能相互共享知识,缓解了单独训练导致的任务之间错误传递问题,提高了模型整体性能;
(3) 在宾州树库(1)https://universaldependencies.org/泰语和越南语数据集上,本文提出的方法取得了明显的效果,相较于基线模型,在POS,UAS,LAS三种评价指标上都得到了明显提升。
本文组织结构如下: 第1节介绍词性标注、依存分析的相关研究工作;第2节对本文提出的融合多粒度特征的词性标注和依存分析联合模型进行了详细说明;第3节对本文实验数据、实验参数、实验评价标准进行介绍,并对实验结果进行分析;第4节对本文的研究进行总结。
1 相关研究
词性标注和依存分析是自然语言处理任务中重要的基础工作。词性标注是将语料库内单词的词性按其含义和上下文内容进行标记的文本数据处理技术。Toutanova[9]提出使用隐马尔可夫模型来做词性标注,该词性标注模型取得了很好的效果。Tsuboi等人[10]提出一种使用神经网络的词性标注方法,在英语数据集上的词性标注结果得到明显改善。Huang等人[11]提出基于BiLSTM加上CRF的词性标注模型,该模型在增强鲁棒性的同时还提高了词性标注的准确率。Kann等人[12]在2018年提出一种使用词的字符特征作为监督信号提升低资源语言词性标注效果的模型。
依存分析的目的是确定句子的句法结构或者句子中词汇之间的依存关系。传统的依存句法分析特征向量稀疏,特征向量泛化能力差,且计算消耗大[1-2],针对此问题Chen等人[3]提出使用神经网络的方法做依存分析,大大提高了依存分析的准确率和速度。Kiperwasser等人[5]提出使用BiLSTM来改进依存分析效果,通过BiLSTM编码过后的句子会考虑词的上下文信息,因此,依存分析的效果再次提升。同年,Dozat和Manning[13]对Kiperwasser等人提出的方法加以改进,提出使用双仿射注意力机制代替传统机制,再使用双仿射依存标签分类器,使依存分析准确率达到新的高度。而后,Woraratpanya等人[14]提出融合字符信息的泰语依存分析方法,在其实验的所有基线模型中,融合了字符信息的依存分析模型效果均要好于没有融合字符的模型。
词性标注对依存分析起着重要作用,而依存分析同样也对词性标注有着巨大帮助,所以,越来越多的研究者把词性标注和依存分析通过联合训练的方法一起训练。Dat等人[15]提出一种融入字符信息的词性标注和依存分析联合模型,其效果在各项评价指标上均得到了提升。Dat等人[16]还提出一种针对于越南语的神经联合模型,根据越南语语言特点,利用越南语的音节信息对越南语进行分词、词性标注以及依存分析处理,在越南语数据集上取得了较好的效果。Yan等人[17]认为依存分析是在单词级别进行的任务,故提出一种基于图的中文分词和依存分析联合模型,其效果达到了当时中文依存分析最佳。
虽然,词性标注和依存分析联合训练已成为依存分析任务的主流方法,但是,现有的词性标注和依存分析联合模型的良好效果大都基于大规模的标注数据或针对某种语言的语言特点进行相关特征融合。模型本身并不适用于低资源语言,以至于在低资源语言上模型效果不佳。基于此,本文提出了融合多粒度特征的词性标注和依存分析联合模型。
2 多粒度特征融合的词性标注和依存分析联合模型
图2为本文提出方法的模型框架,模型从整体上可以被看作是由三个部分组合而成: 词向量表示部分、词性标注部分以及依存分析部分。

图2 融合多粒度特征的词性标注和依存分析联合模型框架图
(1)词向量表示: 将词向量表示用三部分构成,分别为词级向量、字符级词向量和子词级词向量,使其包含不同粒度的丰富上下文语义信息和部分词法、句法信息。
(2)词性标注: 对于词性标注任务,使用BiLSTM网络来学习表示词语的潜在特征向量,再将这些特征向量送入多层感知器(MLP)进行降维后通过Argmax预测得到词性标签。
(3)依存分析: 使用词的联合嵌入向量拼接词性标注组件预测得到的词性标签向量,通过另一个BiLSTM学习另一组潜在特征表示。这些潜在特征表示被送入MLP进行降维后经过双仿射注意力机制[14]预测得到最终的依存分析结果。
2.1 多粒度特征融合的词向量表示

其中,任意一个词w的词嵌入表示为ew,由k个子词组成,其表示为w=(sub1,sub2,…,subk),由n个字符组成,其表示为w=(ch1,ch2,…,chn)。对词w中第j个子词subj的向量用sj来表示,第j个字符chj的向量用cj来表示。向量cj是由随机初始化得到。而向量sj是由多语言BERT(2)https://github.com/google-research/bert预训练模型得到的12层输出再通过层注意力机制得到[21],其中,预训练语言模型可使sj拥有丰富的上下文语义信息,再结合层注意力机制使其重点获取到对后续任务更加有帮助的上下文语义信息,以达到缓解泰语、越南语标注数据稀缺的问题,如式(2)所示。
其中,BERTij表示BERT第i层的第j个子词的输出,ui是可训练的权重。

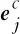
2.2 词性标注
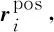

词性预测部分的损失Losspos采用交叉熵损失函数来计算。
此部分获得的词性标注的结果定义为p1,p2,…,pn,将这些结果进行向量化表示,所获得的词性标注部分特征信息继续传递给依存分析部分,如图2所示。
2.3 基于双仿射注意力机制的依存分析


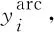
依存弧的损失Lossarc使用交叉熵损失计算。
其中,Ulabel为三维矩阵,维度为(Nlabel,Nd,Nd),Nlabel是依存关系种类数。Vlabel是维度为(Nlabel,2Nd)的二维矩阵,b为随机初始化的偏执向量。最终弧(i,j)的依存关系预测如式(12)所示。
依存关系预测的损失同样使用交叉熵损失函数来计算。
2.4 联合模型损失
最终,我们将联合模型的训练目标损失函数表示为Lossall,联合函数的损失由词性标注损失、依存分析中的依存弧损失和依存关系损失共同表示,如式(13)所示,其中,λ1, λ2, λ3为超参数。
Lossall=λ1Losspos+λ2Lossarc+λ3Lossrel
(13)
3 实验评测与结果分析
3.1 实验数据
目前,泰语、越南语公开的语料数据集极少,可用的数据资源极其稀缺,实验中使用的数据集为宾州树库公开泰文依存分析数据集Thai-PUD和越南语依存分析数据集Vietnamese-VTB,该数据集采用CoNLL-U格式,其中泰语包含1 000个句子,越南语包含3 000个句子。泰语数据集中一共包含 22 322 个词语,越南语数据由43 754个词语组成。通过分析数据集可以发现,泰语、越南语数据集中依存关系类型分别有43种、29种。
如图3、图4所示,泰语句子中词语词性类型共包含有15种,其中词语词性为名词、动词、副词的数量最多。而越南语句子中词语词性类型共有14种,其中词语词性为名词、动词、标点的数量最多,实验所用数据集中泰语、越南语句子以复杂句和长句和简单句组成[14],具体分布如表1、表2所示。其中,词语数在8个以内的句子为简单句,词语数为8~16的句子为长句,词语数大于16的句子称为复杂句。
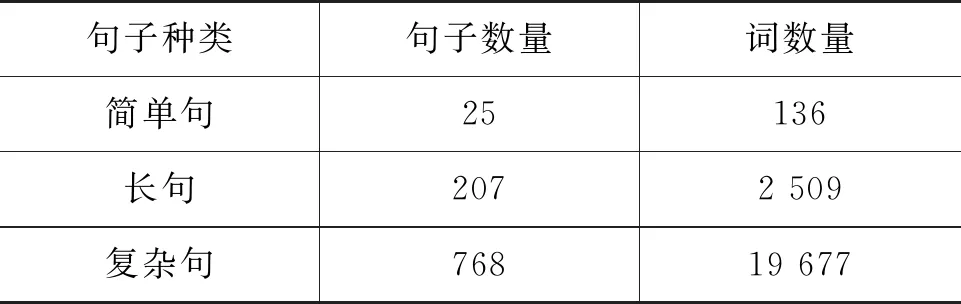
表1 泰语数据统计

表2 越南语数据统计
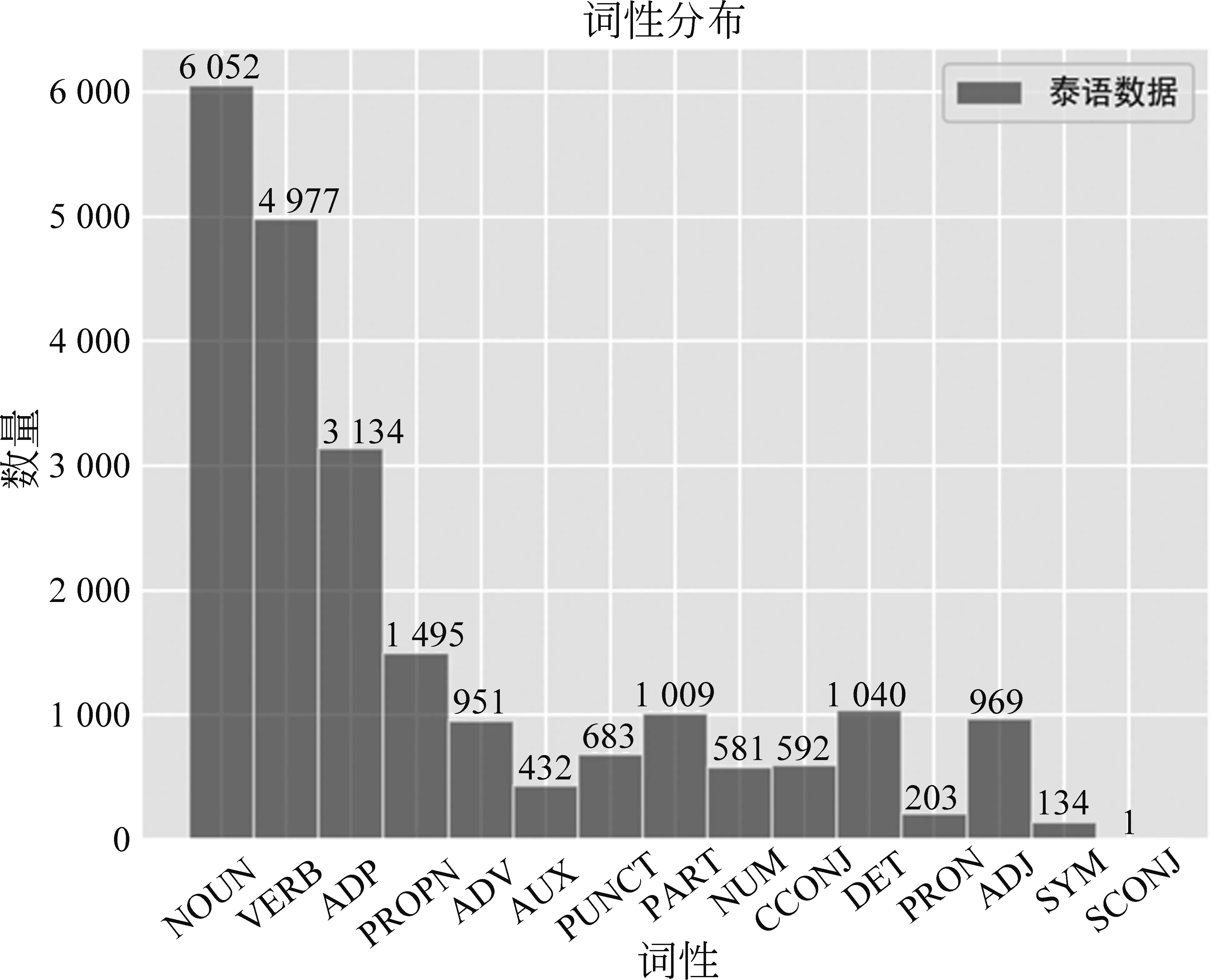
图3 泰语数据词性分布情况

图4 越南语数据词性分布情况
本文实验中泰语实验所用训练集、验证集、测试集由宾州树库的1 000句泰语依存分析数据按 8∶1∶1分割所得,800句用作训练集,100句用作验证集,100句用作测试集。越南语实验使用宾州树库划分好的数据集,其中训练集1 400句,验证集800句,测试集800句。
3.2 实验参数设置
本文使用的泰语词向量是通过维基百科(3)https://th.wikipedia.org/wiki/爬取的1 000 000句泰语单语语料经过分词(4)http://www.sansarn.com/lexto/后使用Word2Vec生成的100维静态词向量,越南语词向量是通过维基百科爬取的1 000 000句越南语单语语料经过Vncorenlp(5)https://github.com/dnanhkhoa/python-vncorenlp分词后使用Word2Vec生成的100维静态词向量。字符初始向量表示和词性标签向量表示是由随机初始化得到。
本文模型参数的具体细节如表3所示,模型优化器选用Adam,其中,β1设置为0.9,β2设置为0.99,训练轮次为30轮。模型学习率初始设置为2e-4,经过五轮预热,每轮增加e-4的学习率,直至升至1e-3,再使用余弦退火衰减进行调整,余弦退火衰减T设置为25,学习率变化如图5所示。
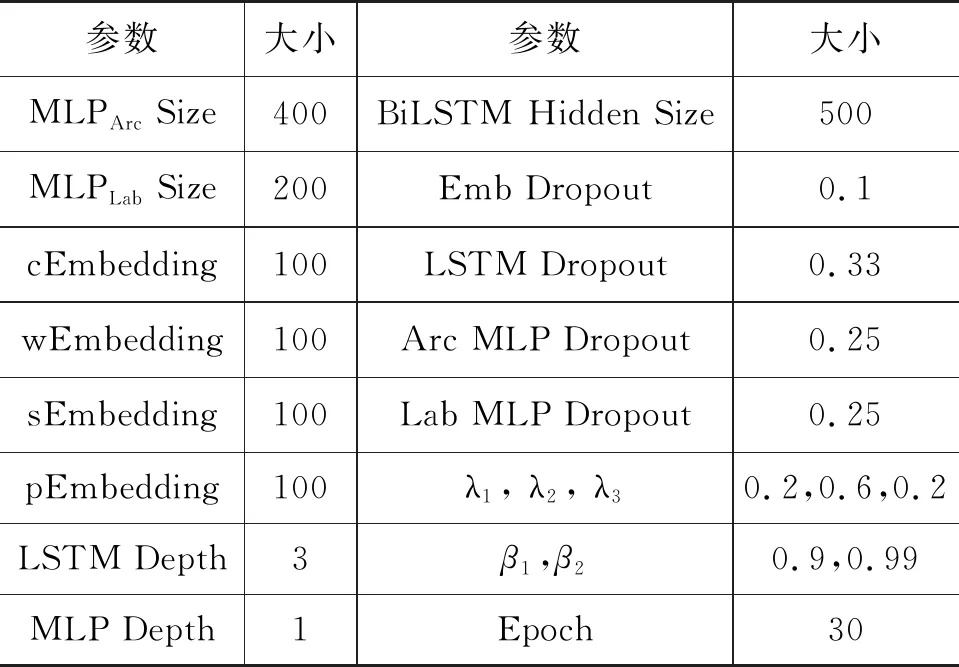
表3 实验超参数设计表

图5 学习率变化图
模型使用的LSTM层数为三层,词向量维度设置为100维,子词向量维度设置为100维,词性向量维度设置为100维,LSTM维度设置为500维,依存分析弧预测部分MLP隐藏层维度设置为500,依存分析弧关系预测部分MLP隐藏层维度设置为200,弧预测和弧关系预测部分MLP层数均为1。损失函数超参λ1、λ2、λ3分别设置为0.2,0.6,0.2。为了防止过拟合问题,我们使用了Dropout正则化[18]技术,词性预测模型的词语向量输入层、依存分析模型的词语向量输入层的Dropout概率均设置为0.1,词性预测模型的BiLSTM、 依存分析模型的BiLSTM中Dropout概率均设置为0.33,弧预测和弧关系预测部分MLP的Dropout概率均设置为0.25。文中模型中所使用的激活函数均为LeakyReLU激活函数。
3.3 实验评价指标
目前依存分析任务的评价指标主要是无标签依存关系准确率(UAS)和带标签依存关系准确率(LAS),词性标注任务的评价指标通常是词性准确率(POS)。本文是基于词性标注和依存分析的联合模型,所以评价本文实验的评价标准选取UAS、LAS、POS三种评价指标来评测模型的性能,具体如式(14)~式(16)所示。

(14)
3.4 实验结果分析
为了体现本文所提出的方法有效性,本文设计了三组对比实验。
实验一: 不同模型方法的实验结果对比
为了验证本文方法的有效性,将本文方法与其他相关模型进行对比。记录每组实验的UAS、LAS、POS,实验结果如表4所示。

表4 不同模型实验结果 (单位: %)
本文选取对比的基线模型如下:
(1)BIST-graph[5]: 由Kiperwasser等人在2016年提出的一种使用BiLSTM特征表示的基于图的依存分析模型。
(2)BIST-transition[4]: 由Dyer等人在2016年提出的一种使用Stack-LSTM的基于转移的依存分析模型。
(3)DeepBiaffineAttention[13]: 由Manning等人在2016年提出的一种双仿射注意力机制依存分析模型。
(4)UDPipe[19]: 由Milan Straka等人2018年提出的一种词性标注、依存分析的多任务模型。
(5)UDify[20]: 由Dan等人2019年提出的一种基于BERT实现的词性标注、依存分析的多任务模型。
(6)JPTDP2.0[17]: 由Dat等人2018年提出的一种联合词性的神经网络依存分析模型。
实验结果表明,本文提出的融合多粒度特征的词性标注和依存分析联合模型,在泰语数据集上,UAS、LAS和POS分别较基线模型JPTDP2.0提升了4.11%、4.26%、2.32%,在越南语数据集上,各项评价指标也较其他基线模型有明显提升。通过比较可知,针对泰语、越南语这种低资源语言,融合多粒度特征后词性标注任务和依存分析任务的词向量表示都拥有了更加丰富的语义信息,弥补了因资源稀缺导致的模型吸收语义知识不足的问题,且联合训练大大缓解了词性标注和依存分析任务之间的错误传递,共享了信息,对依存分析和词性标注效果都有明显的提升。
实验结果表明,本文提出的融合多粒度特征的词性标注和依存分析联合模型,在泰语数据集上,UAS、LAS和POS分别较基线模型JPTDP2.0提升了4.11%、4.26%、2.32%,在越南语数据集上,各项评价指标也较其他基线模型有明显提升。通过比较可知,针对泰语、越南语这种低资源语言,融合多粒度特征后词性标注任务和依存分析任务的词向量表示都拥有了更加丰富的语义信息,弥补了因资源稀缺导致的模型吸收语义知识不足的问题,且联合训练大大缓解了词性标注和依存分析任务之间的错误传递,共享了信息,使依存分析和词性标注效果都有明显的提升。
实验二: 不同BERT微调策略的实验结果对比
为了验证本文方法的有效性并研究在多语言BERT模型的12层输出上使用不同策略作为子词向量表征对实验结果的影响,本文选用泰语数据在子词向量表征分别选取BERT输出的1~4层求和、4~8层求和、8~12层求和、4~12层求和、单独使用第12层和对12层输出使用层注意力机制的结果进行对比,记录每组实验的UAS、LAS和POS,实验结果如表5所示。

表5 不同策略的BERT使用情况对实验结果的影响 (单位: %)
实验结果表明,采用不同策略使用BERT的12层输出对模型性能有着较大的影响。当使用BERT输出的1~4层,4~8层时模型在三种评价指标上均低于使用8~12层,4~12层和单独使用12层,可知BERT的12层输出中不同层数的向量对依存分析和词性标注有着不同的影响。其中,使用4~12层的求和做为子词向量表征时词性标注的结果最高,达到95.23%,可知后8层的输出对词性标注有着重要影响。而对BERT的12层输出使用层注意力机制取最后加权结果作为子词向量表征时UAS和LAS达到最高的86.84%和78.87%,可知让模型在训练过程中自主学习对BERT各层输出的权重能使模型达到较好的效果。
实验三: 消融实验
为了验证不同粒度的联合嵌入的效果,本文使用泰语数据设计了使用词本身嵌入,使用字符和词的联合嵌入,使用子词和词的联合嵌入,使用词、子词和字符的联合嵌入四种不同实验进行对比,记录每组实验的UAS、LAS和POS值,实验结果如表6所示。
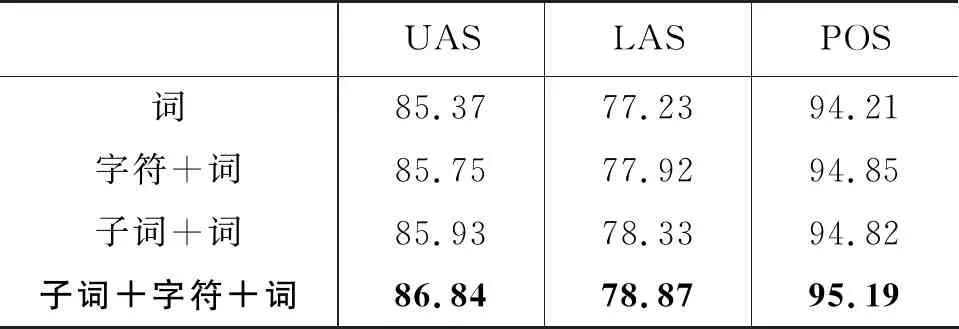
表6 不同粒度联合嵌入对实验结果的影响 (单位: %)
本组实验证明,“子词+字符+词”的联合嵌入作为实验输入相比于字符和词的联合嵌入、子词和词的联合嵌入和仅使用词嵌入本身在各项评价指标上都有更好的效果。字符为词语的最小粒度,其词表很小,不能充分利用上下文信息,且字符切分包含了大量冗余信息。子词切分的粒度介于词语与字符之间,其语义表示相比于字符更加充分,相比于词语更加细腻,所以其与词的联合嵌入效果比字符与词的联合嵌入效果更好。而把三种不同粒度的表示作为联合嵌入,更能使词表征获得各个层面上的语义信息,所以使用子词、字符加上词的联合嵌入在各项评价指标上都获得了最好的结果。
3.5 不同句子类型结果分析
本文实验中把1 000句泰语数据集按照8∶1∶1随机切分为训练集、验证集和测试集。其中测试集中包含1个简单句、10个长句和89个复杂句。观察测试集结果,如图6所示,因简单句只有1句,数据样本太少,故不做详细分析。长句有10句,包含126个词语,其中UAS、LAS和POS分别为88.09%、82.53%、92.86%。复杂句一共包含2 301个词语,其中UAS、LAS和POS分别为86.74%、78.70%、95.34%。通过上述结果可以得知,模型在对复杂句进行词性预测时,因上下文更加充分,其效果要好于其他类型句子。而对长句预测的UAS和LAS要明显高于平均值,可知模型对复杂句的句法解析效果不如对长句的解析效果。

图6 泰语不同句子类型结果分析
4 总结
针对于泰语、越南语因标注数据稀缺导致的词性标注和依存分析效果不佳问题,本文提出一种针对低资源语言的融合多粒度特征的词性标注和依存分析联合模型。通过不同方法得到字符级、子词级和词级表征,并把它们进行联合嵌入,使得编码端能拥有不同层面丰富的形态特征信息、上下文信息和相似性特征信息,有效缓解了标注数据稀缺导致的模型效果不佳问题。再结合联合模型,使词性标注和依存分析任务之间相互共享知识,有效减少单独训练各任务出现的错误线性传递问题。我们的模型有效提升词性标注以及依存分析任务的效果。今后的研究中,我们会将分词任务一同融入所提出的模型框架中来进行联合训练,探究低资源语言中分词、词性标注、依存分析组件之间能否更加有效地共享知识,达到提升依存分析效果的目的。
