基于改进的YOLOv5s安全帽佩戴检测算法
2023-10-23夏明磊翟俊杰
宫 妍, 夏明磊, 王 凯,翟俊杰
(哈尔滨商业大学 轻工学院, 哈尔滨 150028)
作为个人防护用具,安全帽是生活中最常见也是最实用的,对于外来的危险对头部的伤害可以做到有效地防止和减轻.在出入一些基础工地时,安检人员会逐一检查工人是否佩戴安全帽,仅仅是这样的检查无法保证工作人员在施工期间一直佩戴安全帽,而且原始的检查督促方法耗时又耗力.因此,对工人是否正确佩戴安全帽进行实时目标识别与检测具有重大的研究意义.本文将采用目标检测算法对安全帽佩戴状态进行实时监测.
目标检测被广泛应用于人脸识别[1],监控安全,自动驾驶[2]等众多领域.然而,由于人工神经网络建立在最少的经验风险基础上且分类结果很不稳定,容易出现“过拟合”,且其可靠性不高,其不足之处非常显著.近年来,随着深度学习领域的出现,一些学者试图把它运用到昆虫自动识别的研究中,并获得了一些结果.代表性的方法有R-CNN[3],Fast R-CNN[4],Faster R-CNN[5]等.直接进行目标的类别和位置的回归的一阶段方法, 其中代表方法有SDD[8],YOLO[9-12]系列等.
在实时监测过程中,我们要确保安全帽佩戴检测精度,同时尽可能地提升安全帽佩戴实时检测的速度,才能具备实际应用意义.因此,本文以YOLOv5s模型为基础来进行安全帽佩戴检测的相关研究.通过对 YOLOv5s 模型添加CA注意力机制模块旨在增强网络学习特征的表达能力,用 BoT3[7]作为主干网络,用来减少参数并提高网络的推理速度,将CIOU损失函数改为SIOU[13],以此增加YOLOv5s模型对于小目标的注意力.经实验结果证实,改进后的模型在安全帽佩戴实时检测中取得了良好的检测效果.
YOLOv5目标检测算法于2020[14]年发布,是一种轻量级的深度学习模型.YOLOv5s主要有四种结构,分别是[15]YOLOv5s、YOLOv5m、 YOLOv5l、YOLOv5x.YOLOv5s.其网络结构包含输入端、基准网络、主干网络和输出层,如图1、2所示.

图1 YOLOv5网络结构图
1)基准网络:可以有效地整合多种检测网络,主要包括:focus 模块和 CSP 模块;
2)主干网络:通过将BackBone与最终的 head输出层相连,形成一个骨干网络,而 YOLOv5 则采用了 FPN+PAN 的结构,以提升整体能;
3)Head 输出层:但在训练过程中,增加了损失函数GIOU_Loss以及预测框筛选DIOU_nms,以提升模型的准确性.
2 YOLOv5s算法的改进
2.1 引入CA(Coordinate Attention)坐标注意力机制
文献[21]提出目前应用比较广泛的注意力机制通道为注意力机制SE,能够实现有效建模.但是该注意力机制的缺点是容易忽视位置信息的重要性,而视觉目标中的空间结构极为重要.因此,本文引入CA坐标空间注意力机制,用以解决上述问题.CA注意力机制在特征编码的同时,还保留了位置信息,有效解决了原有注意力机制存在的问题.图3为CA注意力机制结构图.

图3 Coordinate Attention注意力机制结构图
在CA坐标注意力机制中,我们首先给定输入X,并使用尺寸为(1,W)或者(H,1)的pooling kernel[23],分别沿着垂直坐标和水平坐标对每个通道进行编码.高度为h的第c通道的输出可以表示为:
(1)
同样,宽度为w的第c通道的输出可以写成:
(2)
两种变换分别沿两个空间方向聚合特征,并由此得到相应的方向感知的特征图.
通过两种变换,可以获得全局特征信息以及编码精确的位置信息,有效地提取全局感受野中的位置信息,并将其转换为宽度和高度两个方向的特征图,从而生成两个注意力图,从而实现对位置的准确编码.此外,这种变换还能够有效地提取出更多的空间信息,从而更好地实现定位目标.使用卷积变换函数对其进行变换操作:
f=δ(F1([Zh,Zw]))
(3)
gw=δ(Fw(fw))
(4)
gh=δ(Fh(fh))
(5)
此后,再将生成的注意力图与特征图相乘,从而增强目标识别能力.其公式表示为:
(6)
其中:δ为对所提取的特征信息进行下采样操作,f为通过下采样操作得到的中间特征图,f1为1*1卷积.特征图沿空间维度进行切分后可得到两个单独张量fh和fw,再利用1*1卷积Fh和Fw进行σ变换,并利用Sigmoid激活函数分别得到特征图在高度上的注意力权重gh和在宽度上的注意力权重gw,最后将注意力权重加到输入上,得到最终输出yc.
加入了CA注意力机制后,可以对目标进行更加精确的定位,寻找到位置信息,同时并未消耗更多的计算资源,解决了原有注意力机制没有位置信息的缺点.
2.2 BoT3 (Bottleneck Transformer)模块
本文将由Transformer改进后的BoT3模块作为改进后的YOLOv5s的主干网络.BoT3由谷歌出品,BoT3即将ResNet中的第4[22]个block中的bottleneck替换为MHSA模块,形成新的模块,称为Bottleneck Transformer(BoT3) .
Transformer中的MHSA和BoT3中的MHSA的区别:
1)归一化 Transformer使用 Layer Normalization,而BoT3使用Batch Normalization;
2)非线性激活 Transformer仅仅使用一个非线性激活在FPN block模块中,BoT3使用了3个非线性激活;
3)输出投影 Transformer中的MHSA包含一个输出投影,BoT3则没有;
4)优化器 Transformer使用Adam优化器训练,BoT3使用sgd+ momentum.图4为结构对比图.

图4 ResNet Bottleneck结构图
该方法仅通过在原有ResNet变换中的第4个block中的bottleneck替换为MHSA模块,在实例分割和目标检测方面显著改善了基线,同时还减少了参数,从而使延迟最小化.增加CA注意力机制和BoT3模块后的YOLOv5s主干网络结构图如图5、6所示.
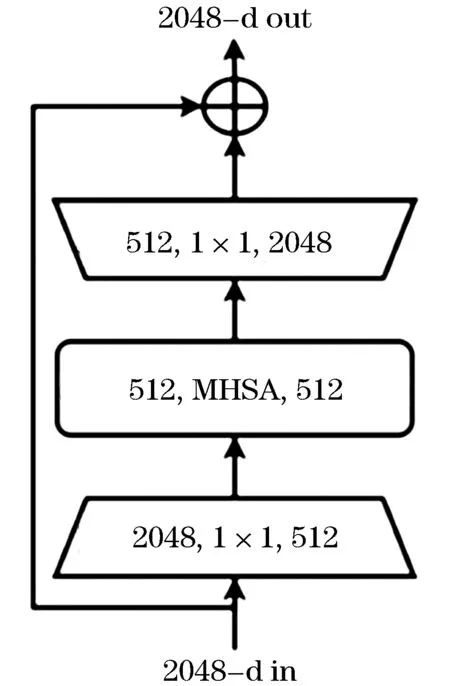
图5 Bottleneck Transformer结构图
2.3 IOU损失函数的改进
原始的YOLOv5s模型使用IOU损失函数为[23]CIOU.式(7)为CIOU计算公式和它的惩罚项.
(7)
其中:b和bgt表示预测框和目标框的中心点,ρ是欧几里得距离,c是覆盖两个盒子的最小封闭盒子的对角线长度.其中α是一个正的权衡参数,而v衡量长宽比的一致性.
(8)
(9)
最终得到:
(10)
可以看出CIOU损失函数长宽比描述的是相对值,存在一定的模糊,未考虑难易样本的平衡问题.所以本文选用SIOU,它考虑到所需回归之间的向量角度,重新定义了惩罚指标.SIOU损失函数由Angle cost,Distance cost,Shape cost和IOU cost四个函数组成.
2.3.1 Angle cost
Angle cost定义如下,图7为Angle cost示意图.
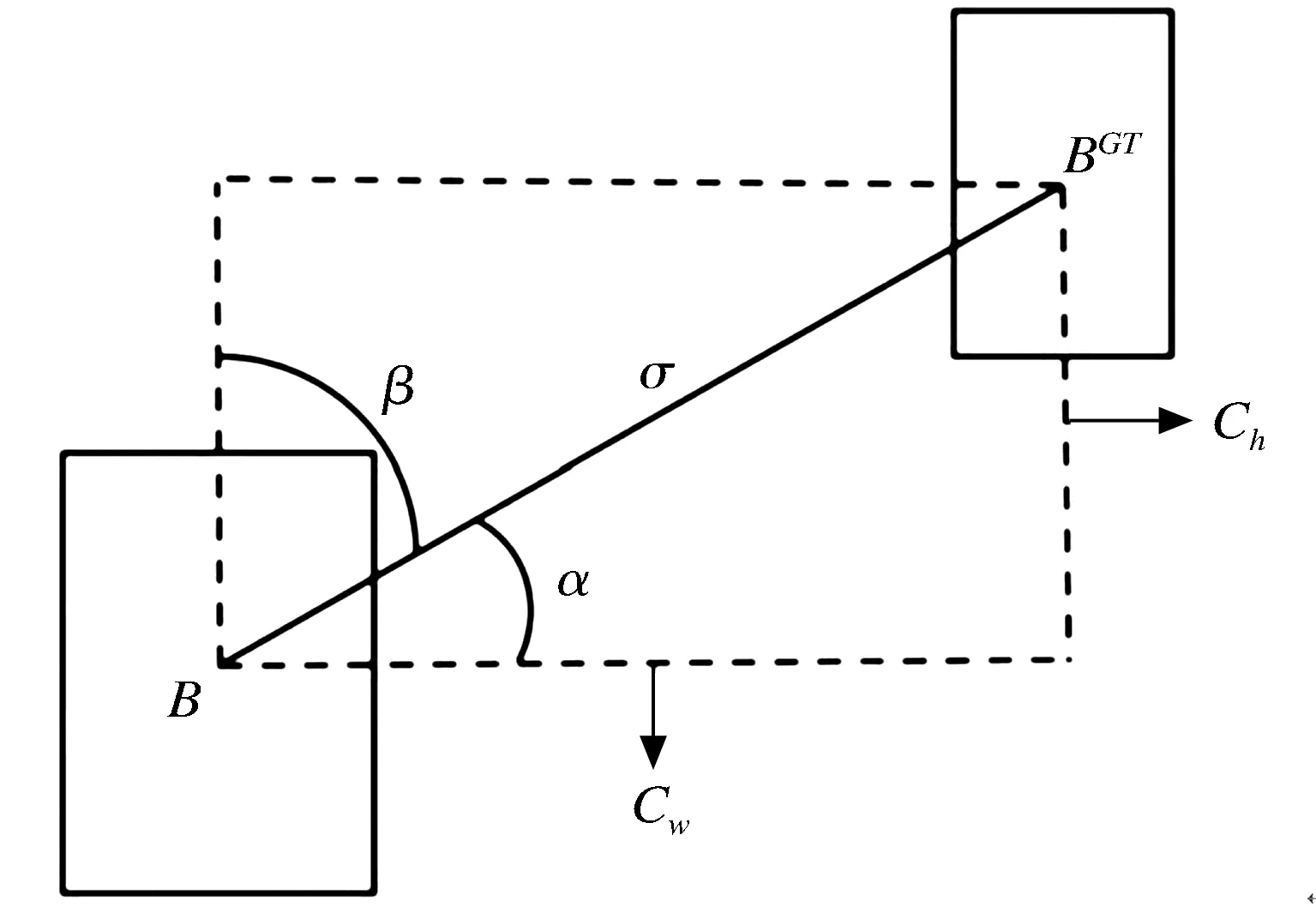
图7 Angle cost示意图
为了首先实现这一点,通过以下方式引入和定义了LF组件:
(11)
x=ch/σ=sin(α)
(12)
(13)
(14)

2.3.2 Distance cost
考虑到上面定义的Angle cost,重新定义了Distance cost:
(15)
(16)
其中:(cw,ch)为真实框和预测框最小外接矩形的宽和高,图8为Distance cost示意图.

图8 Distance cost示意图
2.3.3 Shape cost
Shape cost定义如下

(17)
(18)
其中:(w,h)和(wgt,hgt)分别为预测框和真实框的宽和高,θ控制对形状损失的关注程度.
2.3.4 IOU cost
其定义为:
(19)
图9为IOUcost示意图,最终总的损失函数为:
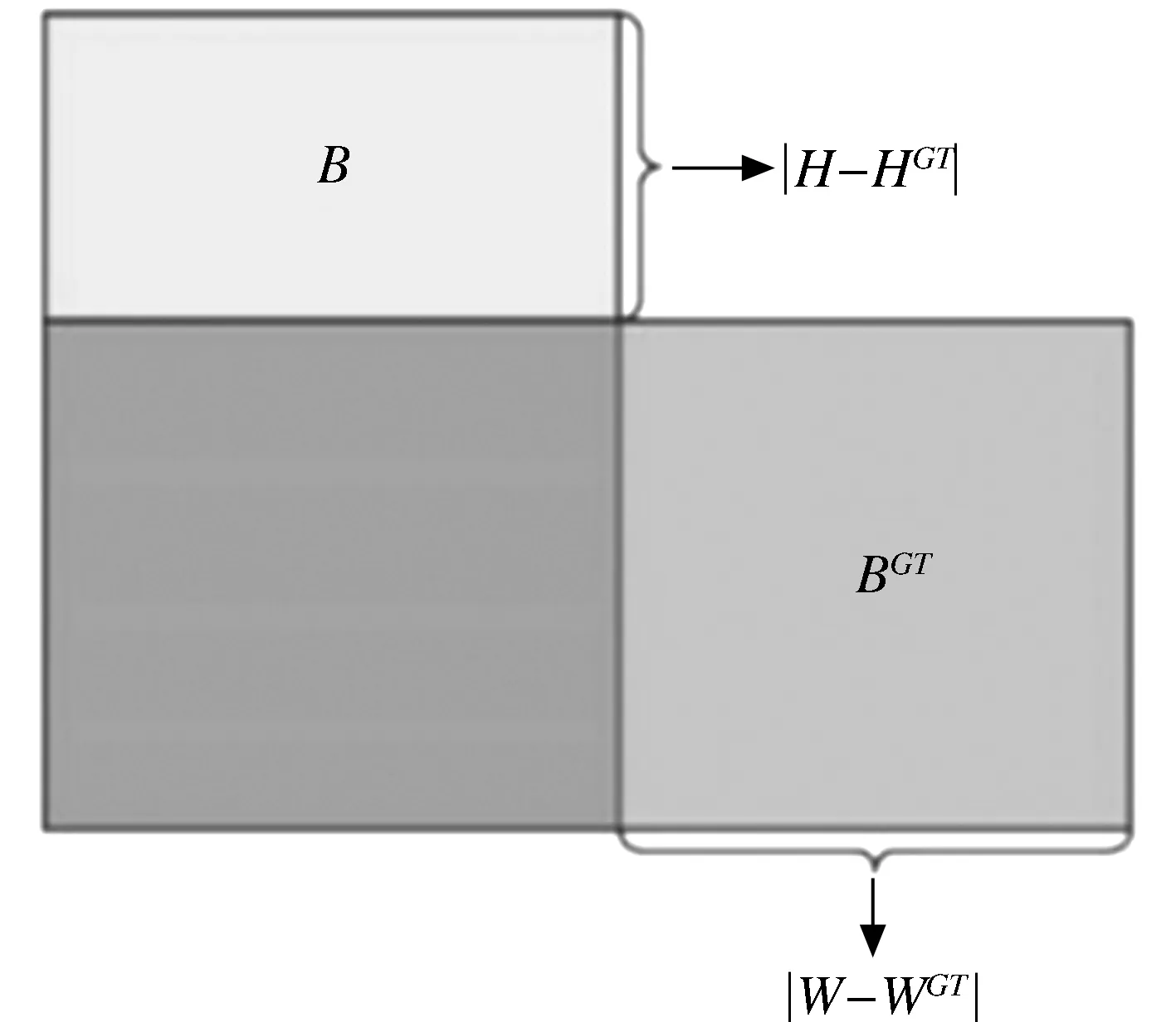
图9 IOU cost示意图
L=WboxLbox+WclsLcls
(20)
其中:LCLS为focal loss,Wbox和Wcls分别为框和分类损失权重.
3 实验结果与分析
本文自制数据集,由符合工地场景的图片和工地的实际场景拍摄制成的图片组成,这些图片不仅提供使用价值,更能反映出真实情况.同时进行图片标注,数据集共有5 225张图片,训练集有图片4 725张,测试集有图片500张,训练集和测试集严格独立.
本文软件环境为:Windows10+python3.9+pytorch 1.7.0+CUDA11.6+cudnn7.6.进行网络训练的图片大小均设置为640×640,batch_size设置为16,权重衰减系数0.000 5,训练30个epoch.
本文实验平台的硬件环境为GPU:NVIDIA GeForce RTX 3050, CPU: Intel(R) Core(TM) i5-11260H,内存:8.00GB,显存: 16GB.
3.1 评价指标
本文的模型检测性能评价指标为:平均精度(average precision,AP)和均值平均精度(mean average mAP).其中:平均精度综合考虑目标检测的精确率(precision ,P)和召回率(recall,R),并使用每秒处理的图片数量(FPS)作为模型检测速度的评价指标,相关计算如下:
(21)
(22)
(23)

(24)
3.2 实验结果
为了验证三种不同改进方法的有效性,分别将YOLOv5s算法,以及改进方法,分别验证检测性能.实验1对比更改了SIOU损失函数网络模型和原始的网络模型的性能,结果如表1所示.
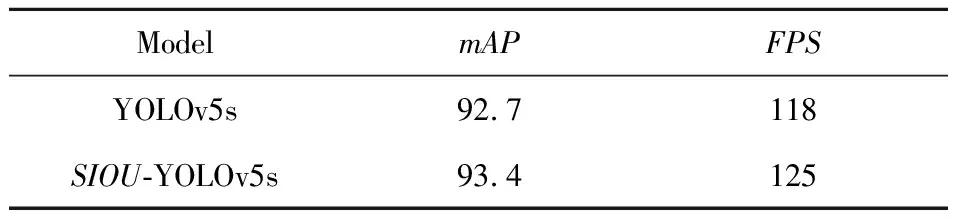
表1 更改损失函数模型前后性能对比
从实验结果来看,使用SIOU损失函数使网络的mAP从92.7%提升到了93.4%,mAP提升了0.7%,说明替换为SIOU损失函数对使得模型更加关注小目标,实验结果也表明检测精度是有提升的.
实验2为将主干网络替换为BoT3和原始模型的性能,结果如表2所示.
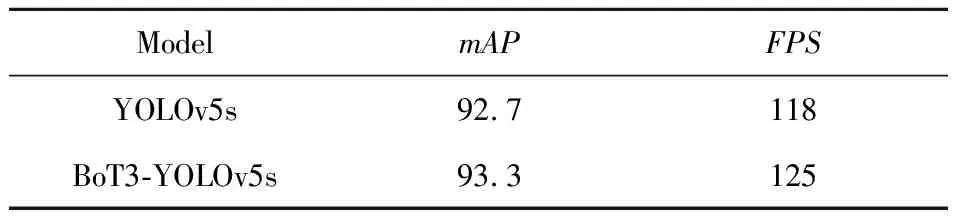
表2 更改主干网络模型前后性能对比
从实验结果来看,使用BoT3作为主干网络使网络模型mAP从92.7%提升到了93.3%,mAP提升了0.6%,说明替换为BoT3主干网络够有效减少梯度信息的重复,并且能够更好地融合特征,实验结果也表明这样的改进确实提升了检测率.
加入CA注意力机制与加入其他注意力机制模型性能的对比结果如表3所示.

表3 加入CA注意力机制与其他注意力机制模型性能对比
从实验结果看加入CA注意力机制比加入SE,CABM注意力机制效果都好,mAP和FPS提升最大,提升了0.7%.故最后确定在YOLOv5s的主干网中加入CA坐标注意力机制.
最后将改进后的模型与深度学习主流网络模型进行对比结果如表4所示.
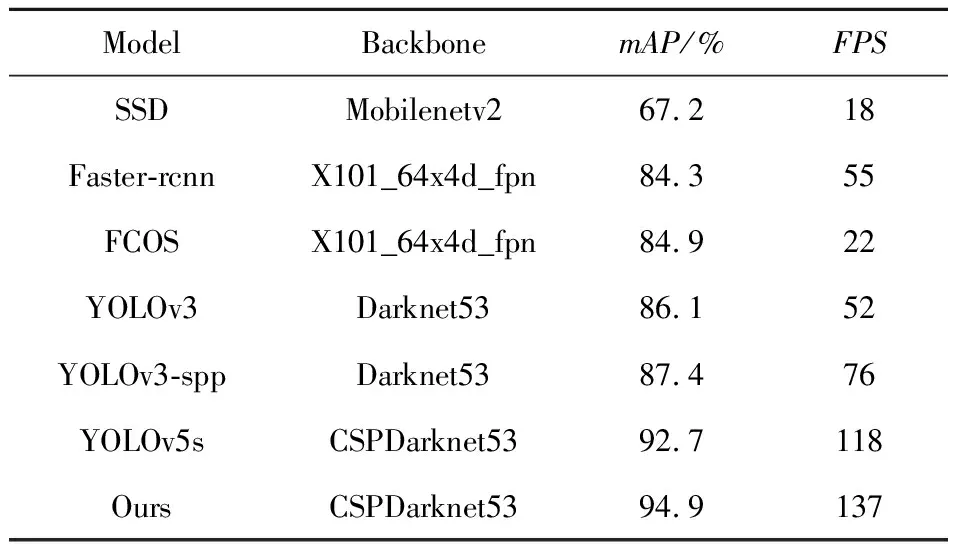
表4 与当前主流方法的实验对比
如表4所示,本文提出的算法相比于其他算法,有最快的检测速度和最高的检测精度.比原始YOLOv5s模型提高了2.2%的检测精度和19 ms的FPS,对比其他的主流模型都有较大的提升.综上所述,本文提出的改进后的YOLOv5s算法,有着最高的检测精度,保持了较好实时性.
3.3 检测结果对比
图10、11为模型改进前后的检测结果对比.通过图10可以看出改进后的模型检测准确率比原始模型的要高,通过图11、12可以看出改进后的模型减少了误检漏检的现象.证明了改进后模型的性能比原始模型有所提高.

图10 YOLOv5s模型改进前后检测结果对比

图11 YOLOv5s模型改进前后检测结果对比
4 结 语
针对现有安全帽佩戴检测算法中出现的对小目标的漏检等问题,本文提出了一种新的改进算法,它将 CA 坐标注意力机制应用于移动网络,将位置信息融入其中,从而拓展了检测范围,有效提高了检测率.为了解决原有主干网络中梯度信息重复和特征融合不足的问题,本文提出了使用 BoT3来当做主干网络,这样可以有效减少梯度信息的重复,并且能够更好地解决特征融合的问题.同时将IOU的损失函数改为SIOU,提升对小目标的注意力.经实验证明,本文提出的改进的YOLOv5s算法检测精度和速度均有提升,实时识别和检测能力增强,因此能够较好地应用于安全帽佩戴检测中.
