基于上下文信息增强的鸡蛋沙壳区域实例分割研究
2023-10-23王鲁马志东唐辉蔡馨燕郭旭超
王鲁,马志东,唐辉,蔡馨燕,郭旭超
基于上下文信息增强的鸡蛋沙壳区域实例分割研究
王鲁1,马志东1,唐辉2*,蔡馨燕3*,郭旭超1
1. 山东农业大学信息科学与工程学院, 山东 泰安 271018 2. 山东农业大学动物科技学院, 山东 泰安 271018 3. 山东省科学技术情报研究院, 山东 济南 250101
为解决现有分割网络中小面积区域像素表达能力差、区域上下文信息类别被混淆、区域分布不规则等导致的鸡蛋沙壳区域分割性能不佳的问题,本文以此类鸡蛋图像为研究对象,提出了一种基于上下文信息的鸡蛋沙壳区域实例分割方法(Global-Local Contexts based Instance Segmentation Model for Egg Sand-shell Region, GL-ISR)。首先,对沙壳区域特征进行全局(Global Context Information Module, GCIM)和局部(Local Context Information Module, LCIM)上下文信息建模,前者利用金字塔池化对特征图进行多尺度上下文加权聚合以收集不同像素区域的上下文信息,后者则通过构建Label Map与Label Prior Layer监督上下文依赖类别以区分上下文信息来源;其次,将两部分上下文与原特征图进行聚合,以增强沙壳区域特征表达能力,从而提高模型的分割性能。为验证所提模型的有效性,本文在包含3类区域、7160幅沙壳蛋图像的自标注数据集上进行了实验。结果表明,GL-ISR在IoU阈值为0.5和0.75情况下分别取得70.02%和44.16%的最优mAP值,在IoU阈值介于0.5至0.95之间取得最优平均mAP值48.22%,显著优于其他模型。具体地,GL-ISR的在光滑区域、面状沙壳和点状沙壳上分别取得85.16%、46.39%和41.17%的像素精准度,即使在分割难度较大的点状沙壳区域上,该模型的像素精准度仍保持在40%以上。因此,上述实验结果表明了GL-ISR模型在鸡蛋沙壳区域分割方面的有效性,可为沙壳蛋品质改良提供理论基础。
沙壳性状; 图像分割; 信息识别
鸡蛋作为一种日常消费品,蛋壳质量关系着鸡蛋在运输过程中破损率,直接影响着生产者的经济效益。笼养条件下蛋壳破损率达5%-10%[1],蛋壳破损造成养禽业经济损失每年高达5亿元以上[2]。其中,沙壳蛋比正常鸡蛋有更低的蛋壳厚度和硬度,同条件下更易破损。因此,针对沙壳区域的有效分割对统计沙壳区域和评价及改良鸡蛋品质有着重要意义。沙壳区域仅凭人工统计,误差大且费时费力。传统图像分割方法如基于阈值、基于区域和基于边缘检测的方法对沙壳区域进行分割时存在难以设定阈值,区域划分困难和边缘分界不明显等问题,分割方法适用性差。
近年来,随着深度学习技术的发展,卷积神经网络(Convolutional Neural Network,CNN)在实例分割任务上不断深入应用。He K等[3]提出的Mask R-CNN基于双阶目标检测,在Faster R-CNN的基础上添加全卷积分支,连接掩膜学习和检测框学习,在COCO数据集上取得了37.1%的AP值;Liu S等[4]提出的PANet在特征金字塔网络(FPN)的基础上增加了反馈通路,引入自适应池对不同层级进行特征融合;Chen X等[5]提出的TensorMask使用密集滑动窗口检测框和像素分类来预测实例以减少对跨区域实例掩膜的损失,在COCO数据集上取得了37.3%的AP值;Bolya D等[6]提出的YOLACT将实例分割划分为候选框定位分类和实例掩膜生成两个并行的子任务以加速分割网络计算过程。Bai M等[7]提出的DWT利用一个全卷积网络学习分水岭变换后的能量级数,根据级数划分区域生成实例掩膜;Liu S等[8]提出的SGN使用3个子网络分别用来生成像素聚类、形成连通域、对连通域进行组合生成实例掩膜;Wang X等[9]提出的SOLO利用分类思想处理聚类问题,将语义类别信息的网格进行分类,使用非极大抑制(Non-Maximum Suppression,NMS)获得实例掩膜,在COCO数据集上取得了40.4%的AP值。虽然CNN在实例分割工作上取得了显著效果,但未考虑小面积像素区域上下文信息与位置信息。
Transformer结构的Self-attention机制[10]为计算机视觉问题提供了新的解决思路。其中,Vision Transformer(Vi-T)[11]将图像矩阵分解为多patch序列,对每个patch进行嵌入编码,提高了网络获取长距离语义依赖信息的能力;DETR[12]结合可学习序列与transformer结构,以端到端的方式提高了小目标分割检测性能;SETR[13]以seq2seq角度看待分割问题,提出了可替代FCN结构Encoder-Decoder模型;SOTR[14]提出了CNN+Transformer的结构,不局限检测框进行实例对象分割,提高了对无规则边界实例前景信息的获取能力。Transformer在计算机视觉问题上的表现说明了上下文信息在提高像素特征表达能力上的有效性。
鸡蛋沙壳区域颜色与背景差异较小,沙壳区域分布无规则且区域边界与光滑区域分界不明显,沙壳区域间的像素面积差异较大。上述实例分割方法的基准测试集由行人、车辆等像素表达能力强的实例组成,但对沙壳蛋数据集的分割性能较差,而且目前针对鸡蛋沙壳区域实例分割的研究较少,因此,为解决鸡蛋沙壳区域难被分割的问题,本文提出了一种基于上下文信息的实例分割方法GL-ISR,该算法基于全局和局部上下文信息,融合了沙壳区域间的像素关联信息和上下文类别信息,以实现对沙壳区域的准确分割。
1 沙壳蛋数据采集与处理
1.1 图像采集
沙壳蛋是一种由于钙化颗粒的沉积在蛋壳表面导致蛋壳强度变差的鸡蛋缺陷的鸡蛋缺陷,因钙化颗粒呈沙状附着蛋壳表面而得名。钙化颗粒,也即沙壳因常分布于蛋壳尖端、钝端,以及蛋壳赤道带,所以本文对沙壳蛋图像的采集方法如下:使用采集设备Canon RF F4L,焦距固定为75 mm,相机感光度为ISO150,拍摄距离固定为20 cm。本文从赤道面固定角度(0°、120°、240°)、钝端和尖端等多个角度分别拍摄3、1和1张图像。共得到7160幅沙壳鸡蛋原始图像,部分沙壳区域相关表征示例如表1所示。
1.2 像素类别划分
本文在领域专家指导下以沙壳区域像素面积为划分标准,将像素类别划分为光滑面(edge),点状沙壳(blog_point),面状沙壳(blog_area)。使用软件Labelme进行数据集自标注,生成对应真值标签Ground Truth;为减少图像背景信息对沙壳区域的干扰,将鸡蛋区域外的背景像素标注为_ignore_类别;为界定蛋壳边缘并确定合法掩膜,将平滑区域标注为Edge类;对标注前的图像边缘进行填充,数据集大小为7160张,图像大小为512×512,训练集,验证集及测试集的划分比例为6:2:2,各部分图像数目分别为4296张,1432张和1432张。
1.3 特征分析
如表1所示,沙壳蛋图像数据集包括赤道面、钝端和尖端的沙壳区域,与通用分割数据集相比:(1)沙壳区域与背景的差异性较弱,待分割实例区域的特征表达受到干扰,容易导致特定区域分割结果的不一致性;(2)沙壳区域分布无明显规律性,区域像素特征与位置信息的对应关系不明确,无法通过确定位置对区域特征进行差异化计算;(3)不同类型沙壳的像素面积占比差异较大,一方面,这导致像素面积占比小的点状沙壳区域特征表达能力较其他类型区域受限;另一方面,该类区域更容易受来自其他类型区域上下文的影响,致使区域特征信息无法正确表达。

表1 沙壳区域视觉及掩膜表征
2 GL-ISR网络
针对沙壳区域的视觉特征的特点,本文提出一种基于全局-局部上下文聚合的实例分割模型,其整体架构如图1所示,包括特征提取模块,上下文聚合模块和掩膜计算模块。其中,特征提取模块由预训练空洞卷积策略的残差网络组成;上下文聚合模块将上下文区分为全局及局部上下文,全局上下文代表全图中所有区域的上下文信息,局部上下文代表同一类像素的上下文信息,图2为以Edge类为例的上下文信息的聚合示意图;掩膜生成模块基于SOLOv2动态头结构。其中,上下文聚合模块是本文研究重点。
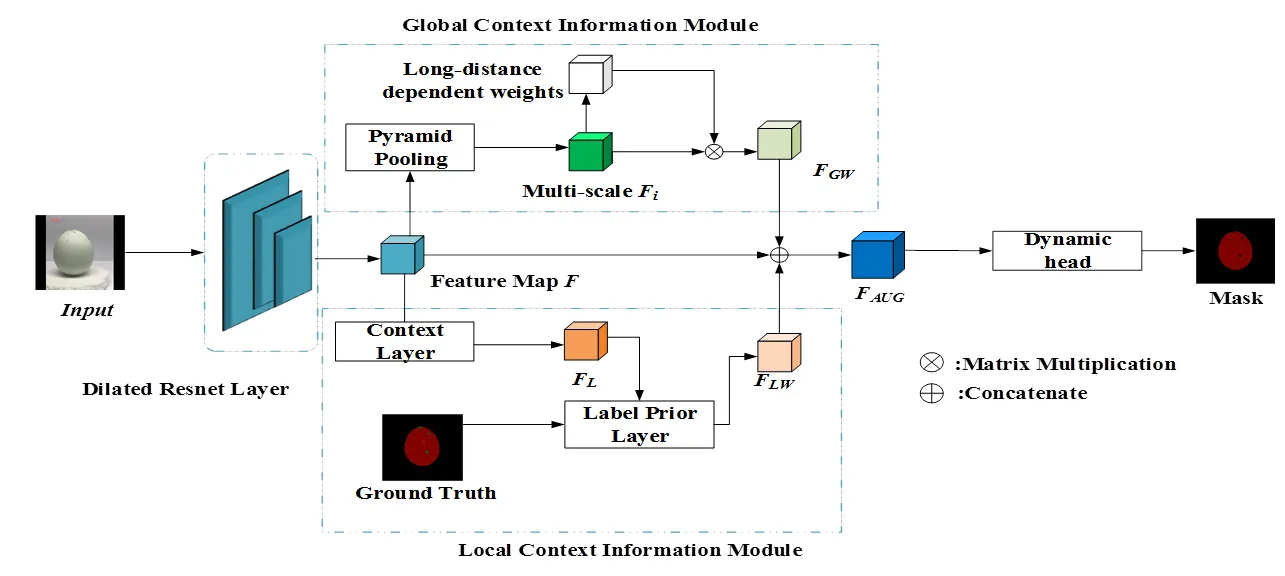
图1 GL-ISR网络结构
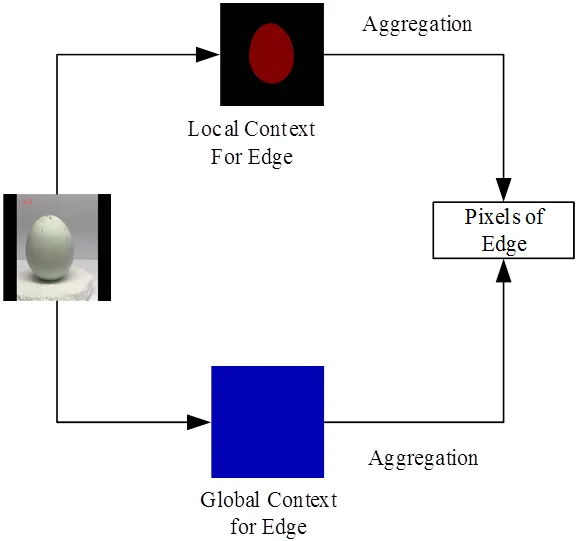
图2 上下文信息聚合
2.1 全局上下文模块
由于沙壳区域边界不明显且区域面积及区域分布无明显规律,沙壳区域特征与背景特征差异较小,不同面积沙壳区域特征表达能力差异较大,存在部分沙壳区域易被错误分割的问题。为解决上述问题,本文以金字塔池化层(Pyramid Pooling Layer)[15,16]为基础,构建全局上下文收集模块(GCIM),对不同感受野的全局信息和语义依赖信息进行收集,以增强沙壳区域特征丰富度,提高沙壳区域特征在网络中的表达能力。
沙壳蛋图像经过预训练空洞卷积策略[17]的残差网络被映射到非线性空间得特征图,其形状为0×0×0,0为像素特征维度,0与0为原图长宽的1/8[18]。如图3所示,GCIM使用金字塔结构对特征图进行分级池化,各级池化结构为自适应平均池化(AdaptiveAvgPool),使用4层结构[19]获取不同尺度下的信息。其中,1×1核对进行全局池化以在全图范围收集信息,其余层级依次用2×2,3×3,5×5池化核在3个不同尺度收集信息。为保持全局在局部位置上权重不变性,在金字塔各级池化核后使用1×1卷积层降维,当金字塔层级为时,该层表征维数降低为现有通道数的1/[19]。第级金字塔池化表征F的计算如式(1)所示。

式中,为卷积函数。
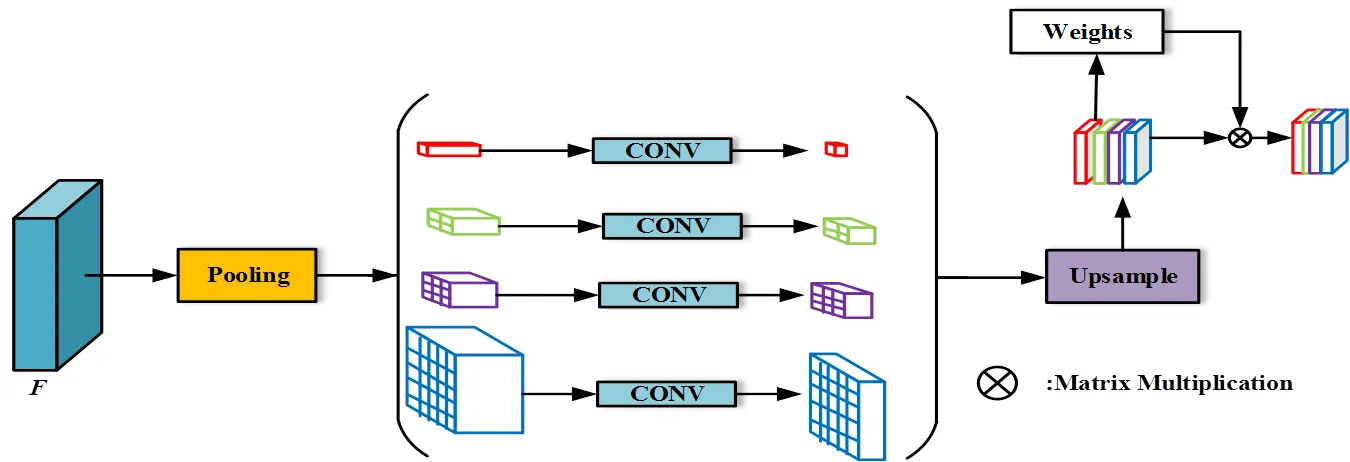
图3 全局上下文信息模块流程图
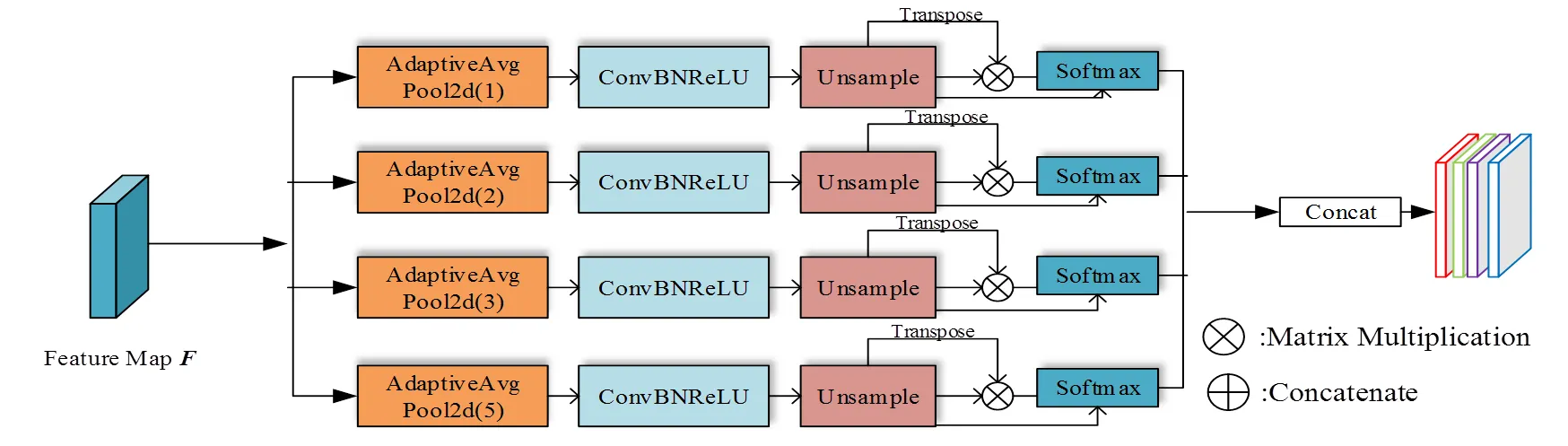
图4 GCIM网络结构图
该模块通过金字塔池化捕获全局信息,能够在一定程度上提高沙壳区域特征信息在深度网络中的表达能力[20],但并未考虑区域相邻像素的影响[21]。因此,如图4所示,本节通过构建像素关联度权重计算模块学习相邻像素依赖信息,从而进一步提高沙壳区域特征的表达能力。第层级加权特征矩阵F的计算如公式(2)所示。
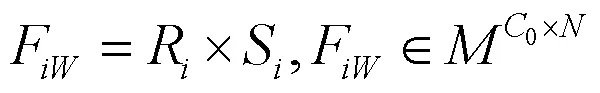
其中矩阵R为关联度权重计算的输入矩阵,其形状为0×,=0×0,矩阵S为第层级像素关联度权重矩阵,其由R计算生成,形状为×,R与S的计算公式如(3)、(4)所示。


S存储了第层表征的空间关联度信息,其每一行元素的数值和为1,逐位置权重计算如式(5)所示。
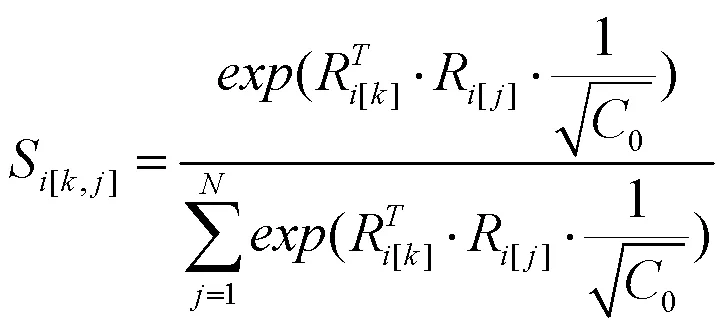
式(5)中,S表示第层级表征中位置与之间的关联度,其值越大,则对应位置的特征信息越相近。如式(6)所示,对F进行逐层聚合生成全局上下文F。

2.2 局部上下文模块
由于不同类型沙壳区域像素面差别较大,导致点状与面状沙壳存在上下文类别混淆问题,小面积的点状沙壳区域更易受到面积大的其他语义类型区域的干扰,获取到更多非本类型上下文信息,这会对小面积沙壳区域特征的表达产生类别信息干扰。为解决小面积沙壳区域受干扰而产生错误表达的问题,本文构建局部上下文模块(LCIM)区分上下文依赖来源,增强小面积沙壳区域特征在确定类别信息下的表达能力。LCIM由类别映射矩阵计算层和上下文信息类别监督层组成。
2.2.1 类别映射矩阵计算考虑到真值标签Ground Truth像素级类别信息丰富且区域间类别差异明显,因此,本节对真值标签计算编码生成类别映射矩阵以监督上下文信息类型。
类别映射矩阵Label Map(以下简称)为形状×的矩阵,其中,=0×0,被用于存储像素类别信息,被用以区分类间和类内上下文,其含义为:的第行数值代表第位置与其他位置的类别所属关系,对于任意[,],若其值为1,则表示第位置与第位置同属一类,若其值为0,则两位置非属一类。由真值标签生成类别映射矩阵的过程如图5所示。

图5 Ground Truth到 Label Map的计算
类别映射矩阵计算流程如下,首先对真值标签下采样,生成形状为0×0的矩阵,后进行One-Hot编码得到G,形状为0×0×,为像素类别数目,由于本文划分沙壳区域的类别数为3,故=3。类别映射矩阵的计算如式(7)所示。

2.2.2 上下文的收集与监督由于对上下文进行类别监督前需先在全局范围内收集上下文依赖信息,因此本节首先对依赖信息进行收集,其过程如图6所示。
图6 Context Information收集流程
Fig.6 The collection process of context information
如图6,特征图经三个并行1x1卷积降维,获得矩阵1,2与3,其形状均为1×0×0。1、2与3进行形状变换分别获得1k、2k与3k,其形状分别为×1、1×和1×,其中,=0×0。由此计算关联度权重,计算公式与逐位置关联度权重计算如(8)、(9)所示。
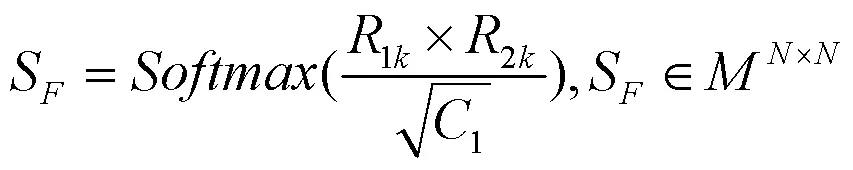
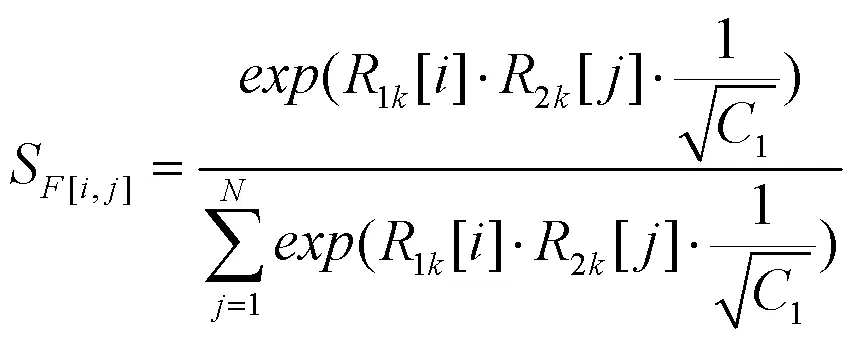
式(9)中,S[i,j]为位置对位置特征表达的影响权重,对3k进行如式(10)加权计算得全局范围的上下文依赖矩阵。
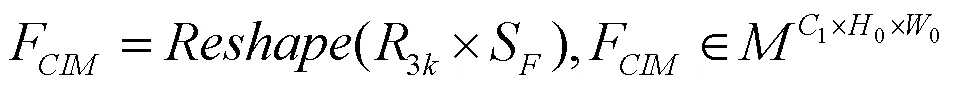
仅以像素关联度和语义距离作为聚合依据,其未对不同像素类型区域的上下文进行区分,不同沙壳区域间的类别混淆问题会导致小面积沙壳更易从大面积沙壳区域获得上下文信息,小面积沙壳区域像素类别信息也由此错误表达。因此,本节构建上下文类别监督层Label Prior Layer解决中的类别混淆问题,其计算流程如图7所示。先经1×1卷积层,Batch Norm及Sigmoid层处理得到类别映射预矩阵Label Prior Map (以下简称),其形状为(0×0)×(0×0),也即×,其计算如式(11)所示。
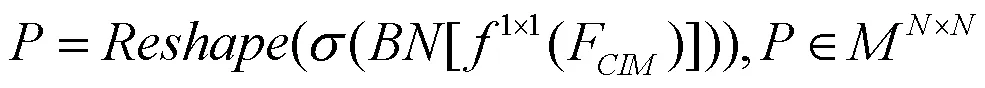
式中,为卷积函数,为Sigmoid函数。
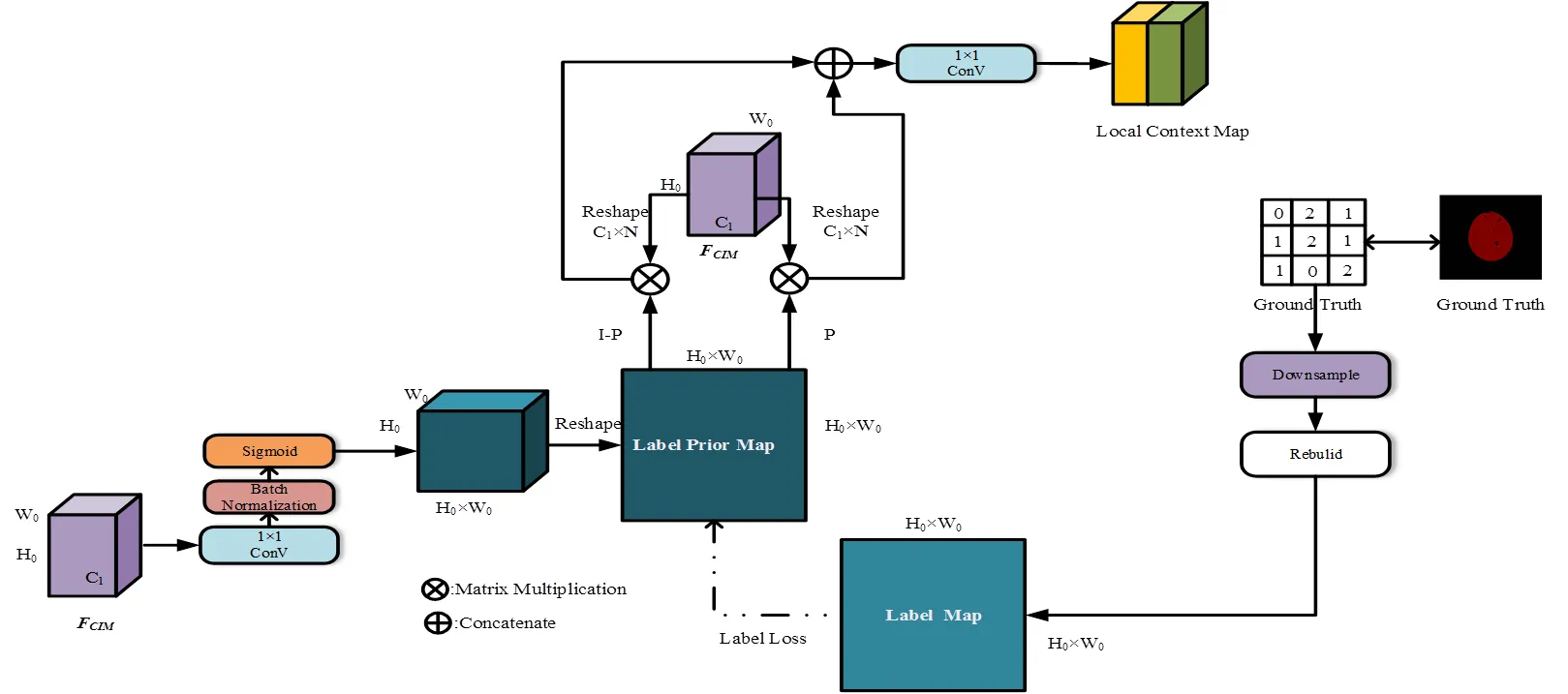
图7 Label Prior Layer计算流程
由图7可知,上下文类别监督层使用对进行监督以区分上下文类别,由的含义可知该监督过程是二分类任务,因此可得基于二分类的监督损失函数如式(12)所示。

式中,p与n分别为与中的任一单位置元素。但根据的定义,中每行元素为某一位置与全图位置的关联信息,若仅使用式(12)对监督上下文类型会导致对关联元素监督的缺失。因此,在式(12)的基础上加入对中行级元素损失的计算,计算过程如下所示。
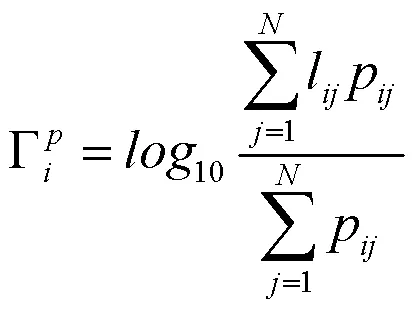
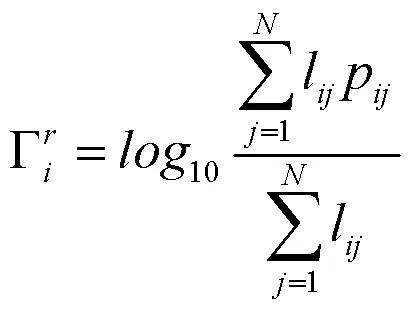
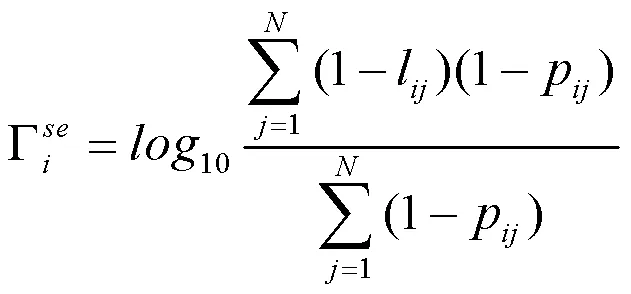

式(13)到(16)分别对中第行元素计算类内预测值、真实类内率、类间预测值及真实类间率。由此,对中行级元素和局部上下文监督损失函数分别为式(17)、(18)所示。

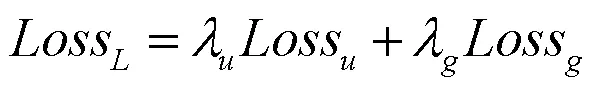
式(18)中,Loss代表单一位置下交叉熵函数,Loss代表全局行级元素监督函数,其权重λ和λ值均为1。由与CIM计算类内上下文C和类间上下文C,计算公式分别如(19)、(20)所示。
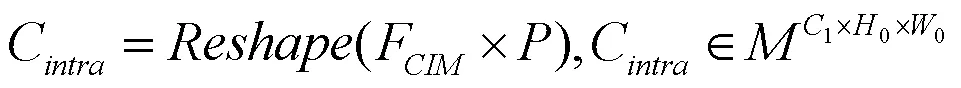
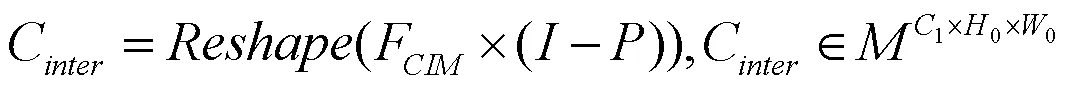
式(20)中,为与同形状的单位矩阵。将类内和类间上下文融合生成局部上下文信息矩阵。

将特征图,全局上下文及局部上下文融合得到最终增强的特征图。
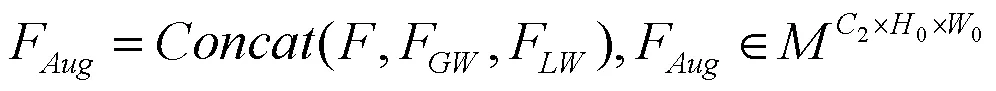
2.3 掩膜生成
掩膜生成模块的作用为由图像特征信息生成预测掩膜,其结构参考SOLOv2的动态头结构(dynamic head)[28],其结构如图8所示,该结构将掩膜预测分为掩膜核预测与掩膜特征学习两个分支任务,其中,前者对通过标准化坐标进行卷积以预测核权重;后者则用于学习区域掩膜特征。
掩膜核预测分支的输入为F,其形状2×0×0,C为聚合后特征矩阵的通道数,F经Reshape后改形状为××2,然后使用4层卷积层,最后使用3×3×卷积层生成卷积核,其尺寸为××。其中,为图像划分的网格数目,对其中任意一个网格,核分支预测维结果输出以表示区域卷积核权重[28]。的对应关系为:对1×1×2卷积核,=2;对5×5×2的卷积核,=252。
掩膜特征学习分支使用特征金字塔网络结构,在金字塔网络的P2-P5阶段重复使用3×3卷积层[28],GroupNorm,ReLU及双线性上采样层,4个阶段归一化到八分之一尺度下合并,各阶段计算公式为式(23)。该分支学习的掩膜特征F经1×1卷积层、GroupNorm及ReLU层计算生成,分支计算过程如式(24)所示。
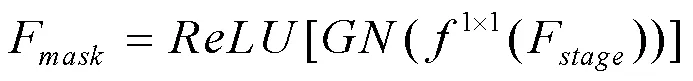
最终的实例掩膜由[i,j]与F进行卷积后经过非极大抑制(NMS)生成,如式(25)所示。
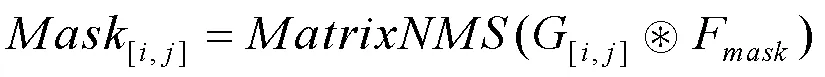
2.4 损失函数设计
损失函数如式(26),其中,Loss为LCIM中的上下文信息类别监督损失;Loss直接使用DICE Loss;Loss为辅助损失函数,网络在空洞卷积后加入Aux层计算Aux损失,Aux层及Aux损失计算如式(29)、(30)所示。
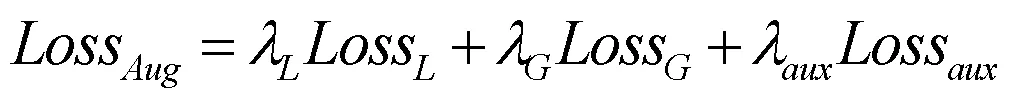
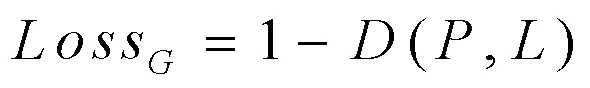


式(27)中的为DICE系数,其定义如式(30)所示,式中(i,j)与(i,j)分别为预测掩膜和真实掩膜在(i,j)位置的像素值。式(26)中的权重为:λ=1,λ=1,λ=0.4。
(29)
3 实验与模型评估
3.1 模型性能评估指标
模型使用平均精度(Average Precision, AP),平均精度均值(mean Average Precision, mAP),像素精准度(Pixel Accuracy, PA)评估指标检验模型性能。AP为具体类别样本的Percision-Recall曲线与横轴积分结果,其中正负样本的确定依赖于分割区域交并比阈值(IoU)。因此,在不同阈值下可细化为如下评价指标AP0.5与mAP0.5,AP0.75与mAP0.75及AP0.5:0.95与mAP0.5:0.95。其中,AP0.5:0.95与mAP0.5:0.95的含义为阈值递增过程中(0.5到0.95,递增步长为0.05)具体类别下AP加和均值和所有类别下mAP加和均值。本节在IoU=0.5下计算PA与mPA值。
3.2 实验环境与参数设置
本文所提模型采用Pytorch框架实现,操作系统:Ubuntu 18.04,硬件环境:CPU为i7-12700K,内存为32GB,图形处理器为RTX3090 24GB。初始训练轮数epoch设置为180,batch size设置为16,初始学习率0设为0.01,训练优化策略为Adam +learning rate decay,学习率更新策略为式(31),学习率更新率设置为0.9。为解决训练数据中的类别不平衡问题,网络对训练集数据进行全类扩充采样,读取数据时在原有训练数据基础上对图像进行随机缩放,缩放比例包括{0.5;1.0;1.5;1.75;2.0},缩放后通过填充裁剪,将图像尺寸统一为512×512。
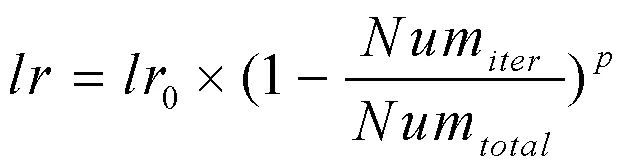
式中,Num表示当前迭代次数,Num表示总迭代次数,每迭代50次对学习率进行更新1次。
3.3 实验结果与分析
3.3.1 模型总体性能分析本文模型与其他主流模型对比,其实验结果分别如表4所示。本节将GL-ISR与PANet、FCIS、Mask R-CNN、SOLOv2、ISTR等模型进行对比分析。由表4可知,本文方法在mAP0.5:0.95较PANet、FCIS、Mask R-CNN、SOLOv2、ISTR分别提升了11.29,10.50,10.05,18.11,6.09个百分点。对比结果最优的mAP0.5,本文方法相比PANet、FCIS、Mask R-CNN、SOLOv2、ISTR分别提升了15.09,18.89,21.3,13.47,9.00个百分点。与当前主流实例分割模型的性能对比分析,可以充分说明本文方法GL-ISR能够有效对鸡蛋沙壳区域进行实例分割。
由图9、10可知,针对较易分割的光滑区域,Mask R-CNN与SOLOv2均存在边界的错误分割,而对分割难度较大的点状沙壳区域,相较于本文方法,Mask R-CNN、SOLOv2及ISTR的结果中误检、漏检的情况较多,进一步说明了本文所提模型能够对光滑区域,点状及面状沙壳进行有效分割。

表4 不同模型的分割结果对比

图9 不同模型在测试集上的分割掩膜结果

图10 不同模型在测试集上的分割可视化结果
3.3.2 在各类区域性能分析为进一步说明GL-ISR对沙壳区域分割的有效性,本节统计了各模型在不同类别沙壳区域的像素精准度(PA)以及各类别下的平均精度,其结果分别如表5、表6所示。
由表5可知,本文所提模型在光滑区域、点状沙壳、面状沙壳三类沙壳区域上均取得最优像素精准度85.16%、41.17%和46.39%,相较于最优对比模型ISTR分别高出10.67、5.12及4.25个百分点,这是因为GL-ISR对上下文类别的监督在一定程度上缓解了上下文混淆问题,增强区域上下文的类别确定性。具体地,以分割难度较大的点状沙壳为例,Mask R-CNN,SOLOv2和本文方法分别取得了17.11%,18.34%和41.17%的像素精准度,本文方法在点状沙壳上较两者分别提高了24.06和22.82个百分点,这表明GL-ISR使用全局与局部上下文增强点状沙壳区域表达能力的有效性。

表5 不同模型在测试集各类区域的像素精准度(PA)
为检验GL-ISR在不同IoU阈值下的分割性能,本节使用多阈值AP值对不同模型在各类沙壳区域分割性能进行评价。由表6可知,GL-ISR在光滑区域、点状沙壳及面状沙壳分别取得了88.12%,51.12%和70.82%的AP0.5值,相较次优对比模型ISTR在各类的AP0.5值分别提升了9.49%,8.61%和8.90%。在提高阈值后,本文方法在各类上仍然取得了60.17%,30.67%及41.55%的最优AP0.75值和63.71%,40.74和40.21的最优AP0.5:0.95值。进一步说明GL-ISR针对各类沙壳分割的有效性。
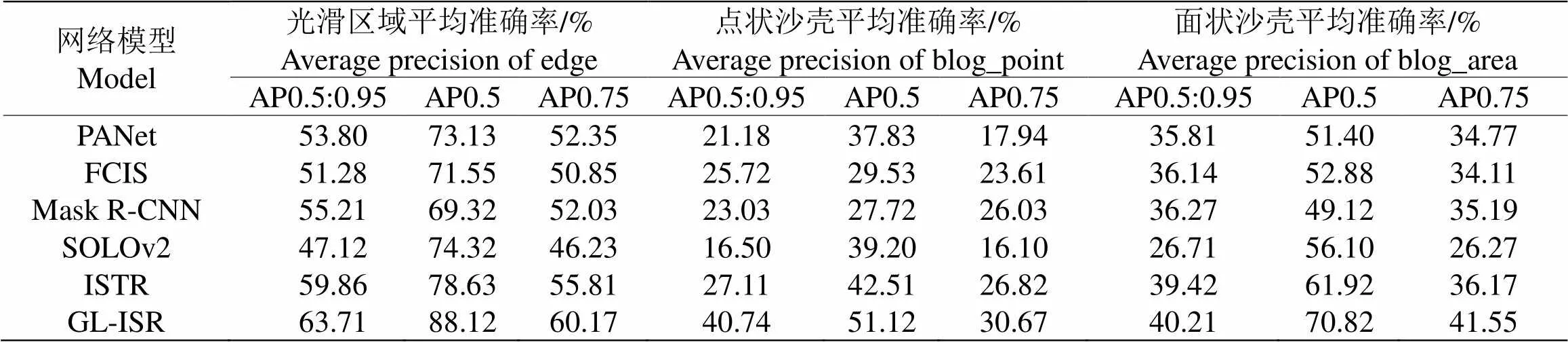
表6 不同模型在测试集各类区域上平均准确率(AP)
3.3.3 消融实验 为验证各部分模块对分割性能提升的有效性,本节对GL-ISR进行消融实验,使用不同类别的像素精准度(IoU阈值为0.5)和mAP0.5指标评价模型性能。消融实验结果如表7所示。
针对结构(2)、(3),(3)在(2)的基础上增加了像素关联度加权操作,在mAP0.5上提升2.98个百分点,在光滑区域,点状沙壳及面状沙壳的像素精准度上分别提高了11.25、4.97和3.08个百分点,这说明了像素关联度信息的加入对分割性能的提升作用。针对结构(1)、(4),(4)在(1)上增加了对上下文类别的监督,在光滑区域,点状沙壳及面状沙壳的像素精准度上分别提高了6.03、7.96和7.10个百分点,对点状沙壳区域的分割准度的提升较为明显,这验证了减少上下文混淆对分割性能的提升作用。表7结果进一步说明了GL-ISR各模块的对沙壳区域分割提升的有效性。

表7 消融实验结果
4 结论
本文针对沙壳蛋的沙壳区域像素面积小,区域像素特征在分割网络表达能力弱,从而导致沙壳区域分割精度不高的问题,构建了聚合全局和局部上下文信息的实例分割模型GL-ISR,并通过对损失函数和学习率函数的设计提高模型分割精度。本文模型遵循“增强-分割”模式聚合全局和局部上下文以增强沙壳区域的特征表达能力,网络整体结构为特征提取层,上下文聚合层及掩膜计算层。其中,特征提取层使用空洞策略下的预训练残差网络;在上下文聚合层中,全局上下文模块使用金字塔池化与像素关联度加权计算以聚合全局上下文,局部上下文模块使用真值标签二值化与类别映射监督层区分上下文类别来源以聚合局部上下文信息,将上下文信息与特征图进行聚合作为增强结果;掩膜计算层使用动态头结构(Dynamic Head)对沙壳区域进行预测。实验表明,GL-ISR相较其他模型取得了最优mAP值和像素精准度,充分说明了其在鸡蛋沙壳区域分割方面上的优越性。在未来工作,考虑将GL-ISR应用到其他领域数据,进一步验证该模型的泛化能力。此外,考虑将Transformer结构引入到上下文聚合和掩膜计算过程中以进一步提高模型性能。
[1] 胡建平.降低破蛋率和减少鲜蛋失重的有效措施[J].养禽与禽病防治,2005(7):19
[2] 宋慧芝,王俊,叶均安.鸡蛋蛋壳受载特性的有限元研究[J].浙江大学学报(农业与生命科学版),2006(3):350-354
[3] He K, Gkioxari G, Dollár P,. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017:2961-2969
[4] Liu S, Qi L, Qin H,. Path aggregation network for instance segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition, 2018:8759-8768
[5] Chen X, Girshick R, He K,. Tensormask: A foundation for dense object segmentation[C]//Proceedings of the IEEE/CVF international conference on computer vision, 2019:2061-2069
[6] Bolya D, Zhou C, Xiao F,. Yolact: Real-time instance segmentation[C]//Proceedings of the IEEE/CVF international conference on computer vision, 2019: 9157-9166
[7] Bai M, Urtasun R. Deep watershed transform for instance segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition, 2017:5221-5229
[8] Liu S, Jia J, Fidler S,. Sgn: Sequential grouping networks for instance segmentation[C]//Proceedings of the IEEE international conference on computer vision, 2017:3496-3504
[9] Wang X, Kong T, Shen C,. Solo: Segmenting objects by locations[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVIII 16. Springer International Publishing, 2020: 649-665
[10] Vaswani A, Shazeer N, Parmar N,. Attention is all you need [C]//31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA.
[11] Dosovitskiy A, Beyer L, Kolesnikov A,. An image is worth 16x16 words: Transformers for image recognition at scale [J]. arXiv preprint arXiv:2010, 2020:11929
[12] Zhu X, Su W, Lu L,. Deformable detr: Deformable transformers for end-to-end object detection [J]. arXiv preprint arXiv:2010, 2020:04159
[13] Zheng S, Lu J, Zhao H,. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021:6881-6890
[14] Guo R, Niu D, Qu L,. Sotr: Segmenting objects with transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021:7157-7166
[15] Chen LC, Papandreou G, Kokkinos I,. Semantic image segmentation with deep convolutional nets and fully connected CRFs [EB/OL]. 2016-06-02[2023-07-06]. https://arxiv.org/pdf/1412.7062.pdf
[16] Zhao H, Zhang Y, Liu S,Psanet: Point-wise spatial attention network for scene parsing[C]. Proceedings of the European conference on computer vision (ECCV), 2018:267-283
[17] Chen LC, Papandreou G, Kokkinos I,. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018,40(4):834-848
[18] Chen LC, Papandreou G, Schroff F,. Rethinking atrous convolution for semantic image segmentation [EB]. arXiv, 2017:1-5
[19] Zhao H, Shi J, Qi X,. Pyramid scene parsing network [C]. Proceedings of the IEEE conference on computer vision and pattern recognition, 2017:2881-2890
[20] Chen LC, Yang Y, Wang J,. Attention to scale: Scale-aware semantic image segmentation [C]. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
[21] Chen LC, Zhu YU, Papandreou G,. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]. European Conference on Computer Vision (ECCV), 2018:801-818
[22] Cholet F. Xception:deep learning with depthwise separable convolutions [C]. Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017:1800-1807
[23] Jin Z, Liu B, Chu Q,. ISNet: Integrate image-level and semantic-level context for semantic segmentation [C]. Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021:7189-7198
[24] Ding H, Jiang X, Shuai B,. Context contrasted feature and gated multi-scale aggregation for scene segmentation [C]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018:2393-2402
[25] Fu J, Liu J, Tian H,. Dual attention network for scene segmentation [C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019:3146-3154
[26] Zhao H, Zhang Y, Liu S,. Psanet: Point-wise spatial attention network for scene parsing [C]. Proceedings of the European Conference on Computer Vision (ECCV). 2018:267-283
[27] Yuan Y, Chen X, Chen X,. Segmentation transformer: Object-contextual representations for semantic segmentation [J]. arXiv preprint arXiv:1909.11065, 2019
[28] Wang X, Zhang R, Kong T,. Solov2: Dynamic and fast instance segmentation [J]. Advances in Neural Information Processing Systems, 2020,33:17721-17732
Research on Instance Segmentation of Egg Sand-shell Region Based on Contextual Information
WANG Lu1, MA Zhi-dong1, TANG Hui2*, CAI Xin-yan3*, GUO Xu-chao1
1.271018,2.271018,3.250100,
To address the challenges of poor pixel representation in small-area regions, confusion of region context information categories, and irregular distribution of regions in existing segmentation networks leading to suboptimal performance in eggshell region segmentation, this study focuses on such egg images and proposes a context-based instance segmentation method for egg sand-shell regions, named Global-Local Contexts based Instance Segmentation Model for Egg Sand-shell Region (GL-ISR).The approach begins by globally (Global Context Information Module, GCIM) and locally (Local Context Information Module, LCIM) modeling features of the sand-shell region. The former employs pyramid pooling to aggregate multi-scale context information from the feature map, collecting context information for different pixel regions. The latter supervises context-dependent categories by constructing a Label Map and Label Prior Layer to differentiate the sources of context information. Subsequently, the two context parts are aggregated with the original feature map to enhance the feature representation capability of the sand-shell region, thereby improving the model's segmentation performance.To validate the effectiveness of the proposed model, experiments were conducted on a self-labeled dataset containing three classes of regions and 7160 images of eggshell eggs. Results demonstrate that GL-ISR achieves optimal mAP values of 70.02% and 44.16% at IoU thresholds of 0.5 and 0.75, respectively. The optimal average mAP value of 48.22% is obtained at IoU thresholds between 0.5 and 0.95, significantly outperforming other models. Specifically, GL-ISR achieves pixel accuracy of 85.16%, 46.39%, and 41.17% on smooth regions, surface sand-shell, and point-like sand-shell, respectively. Even in the challenging area of point-like sand-shell segmentation, the model's pixel accuracy remains above 40%.Experimental results demonstrate the effectiveness of the GL-ISR in egg-shell segmentation, providing a theoretical foundation for improving the quality of sand-shell eggs.
Sand-shell Trait; image segmentation; information recognition
TP751
A
1000-2324(2023)04-0477-13
10.3969/j.issn.1000-2324.2023.04.001
2023-01-23
2023-04-05
山东省重点研发项目(2022LZGCQY016)
王鲁(1981-),男,博士,教授,主要从事计算机视觉、机器学习、智慧农业等方面的研究. E-mail:wangl@sdau.edu.cn
通讯作者:Authors for correspondence. E-mail:tanghui@sdau.edu.cn; 191523972@qq.com
