基于Transformer的行人重识别网络
2023-10-22莫建文莫伦麟
莫建文,莫伦麟
(桂林电子科技大学 信息与通信学院,广西 桂林 541004)
行人重识别(person re-identification,简称ReID)是一种利用计算机视觉来判断图像或者视频序列中是否存在特定行人的技术。它根据待检索的行人图像,在目标图片库中找到不同摄像头下的同一行人。早在2017年,Transformer[1]开始在NLP自然语言处理领域出圈,且在后续GPT[2]、BERT[3]中被继续发扬光大。鉴于此,谷歌的ViT[4]也成功将Transformer引入了CV图像领域,用于建模图像块path之间的关联性,证明了Transformer在图像领域也具备强大的表征能力。TransReID[5]作为第一个应用ViTs架构到行人重识别领域的方法,其在车辆重识别和行人重识别中都取得了较好的性能。AAformer[6]则应用ViT[4]主干网络以及额外的部件tokens向量来表征和汇聚行人的部件信息。LATransformer[7]则是将PCB 的主干ResNet-50替换成Transformer,并将全局token向量融入各人体部件中。但这些方法都是直接将ViT[4]引入ReID中,将行人进行补丁式分块建模。
为了解决由于CNN 感受野重叠带来的分块数量限制问题,即当分块达到一定数量时,CNN 的感受野之间存在重叠现象(如图1所示)。当CNN 中分块数达到一定数量时,块与块之间就会重复,块数越多,重复就越多,经ReLU 激活后,很多重复区域会被置零,从而实际视野会产生很多暗幕。当无对齐算法的辅助时,分块数就会成为限制模型性能的主要因素之一。鉴于此,将CNN 与Transformer相结合,提出一种基于Transformer 的行人重识别网络(CNN with INOUT_transformer,简称CIT)。利用Transformer内部的多头注意力机制和全局建模能力,对多分块条件下CNN 感受野重叠区域自动分配低权重,并把块与块之间的关键信息分别汇聚到全局token向量中,进而更高效地利用有效信息。在Market-1501和DukeMTMC-reID 的实验结果表明,本方法能够提高切片数量,并能进一步提高模型性能。

图1 感受野重叠展示
1 相关研究
深度学习行人重识别相关方法主要分为姿态关键点[8-9]、分割[10]、网格[11]、跨域[12]、水平切片[13-16]等。除此之外,无监督行人重识别方法[17-18]也开始涌现。对于姿态关键点,它是利用人体姿态估计得到的关键点信息来对行人进行部件分块,从而得到更有针对性的特征。类似地,分割和网格方法则是利用分割和网格信息来得到更有效的特征。在水平切片方法中,PCB[14]利用水平切片分块思想,将行人水平分成6块,并对每块特征利用softmax和交叉熵损失单独进行分类,最终也取得了不错的性能。而AlignedReID++[13]也是一种切片方法,其利用动态局部对齐算法DMLI来解决分块对齐问题,从而将分块切片数量提高到了8块。直到ViT[4]出现后,Transformer才开始应用到图像领域。TransReID[5]、AAformer[6]、LA-Transformer[7]参 考ViT 基 于Transformer提出了各自的行人重识别网络,并取得了不错的性能。
2 CIT方法
CIT总的网络设计框图如图2所示。总的来说,CIT中的卷积神经网络CNN 用于抽取图像特征F。对F进行分块后,利用TransformerIN 建模分块内部像素token向量之间的关联性,并将每块中的有用信息融合到全局token向量中。Transformer-OUT则用来对TransformerIN 融合的各个分块全局token向量做进一步建模,最终将各分块全局token向量的信息融合到一个分类token向量中,然后通过对最终的分类token向量c进行softmax和交叉熵损失来对行人进行分类。
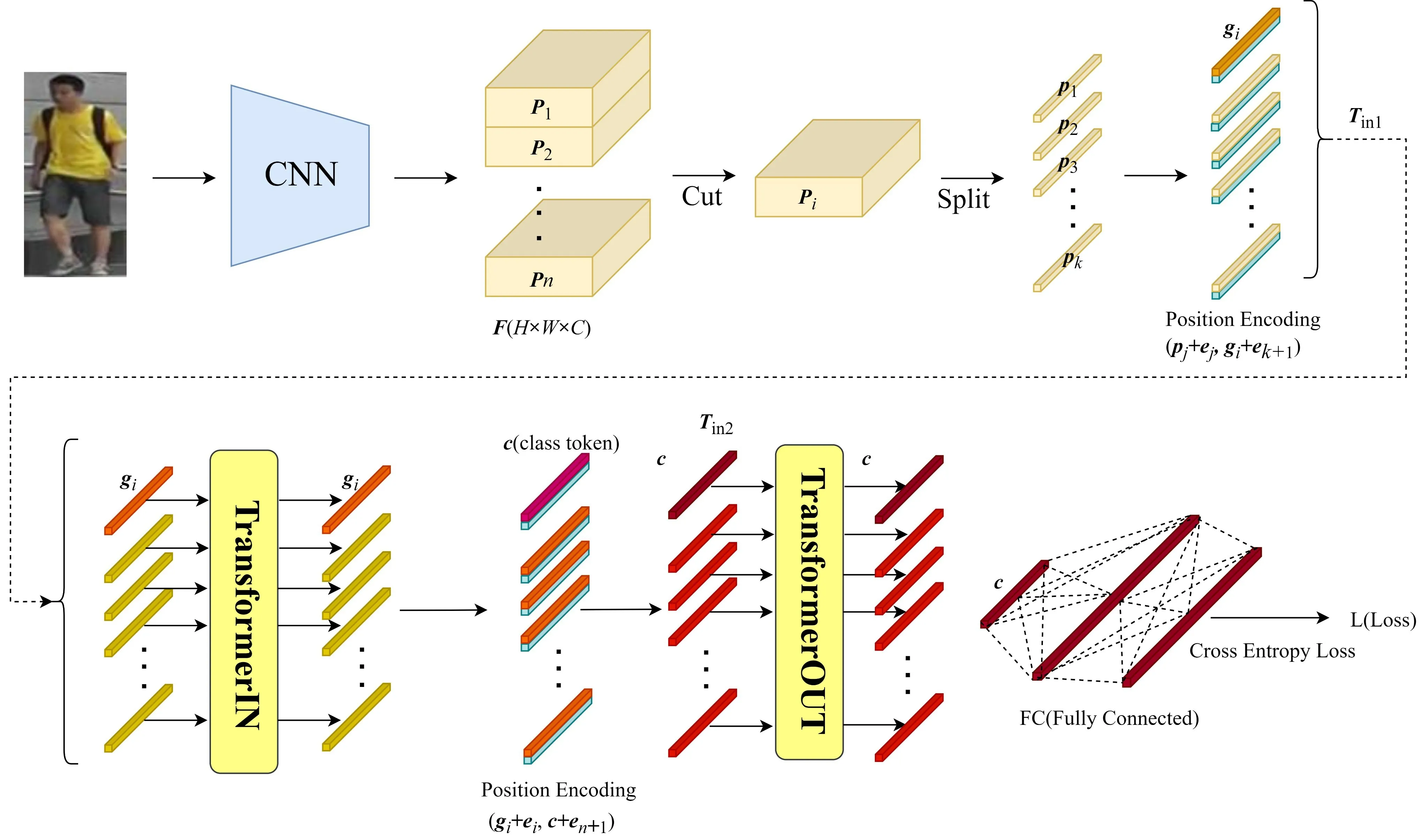
图2 CIT网络设计框架图
2.1 Transformer 简介
Transformer[1]主要由以下4个部分组成:
2)Multi-head Self-Attention:如果只利用上述的一组Wq、Wk、Wv矩阵得到的注意力输出,难免过于单一,难以适应实际复杂的应用环境。不同的环境下,不同的任务中,模型需要能注意到不同部分之间的关联性。所以,需要设置多组(多头)可学习的Wq、Wk、Wv矩阵来应对复杂情况下的表征,多头自注意力机制可表示为
其中,Zout为多头自注意力的输出矩阵,维度与输入矩阵相同,
总的来说,就是对上述m组Wq、Wk、Wv分别进行式(2)的Attention操作,得到m组输出,对m组的输出矩阵进行Concat拼接,然后通过乘上一个WZ矩阵来降维匹配输入矩阵的维度,从而得到与输入矩阵Tin同维度的编码输出矩阵Zout。
3)MLP 和Residual Connection 以及Layer-Norm:类似于为了解决CNN 中网络过深带来的梯度消失问题而引入残差连接(residual connection,简称RC)一样,在每个Transformer模块都引入残差跳跃连接。此外,还包括简单的多层感知机(multi layer perceptron,简称MLP)以及层归一化Layer-Norm,如图3所示。
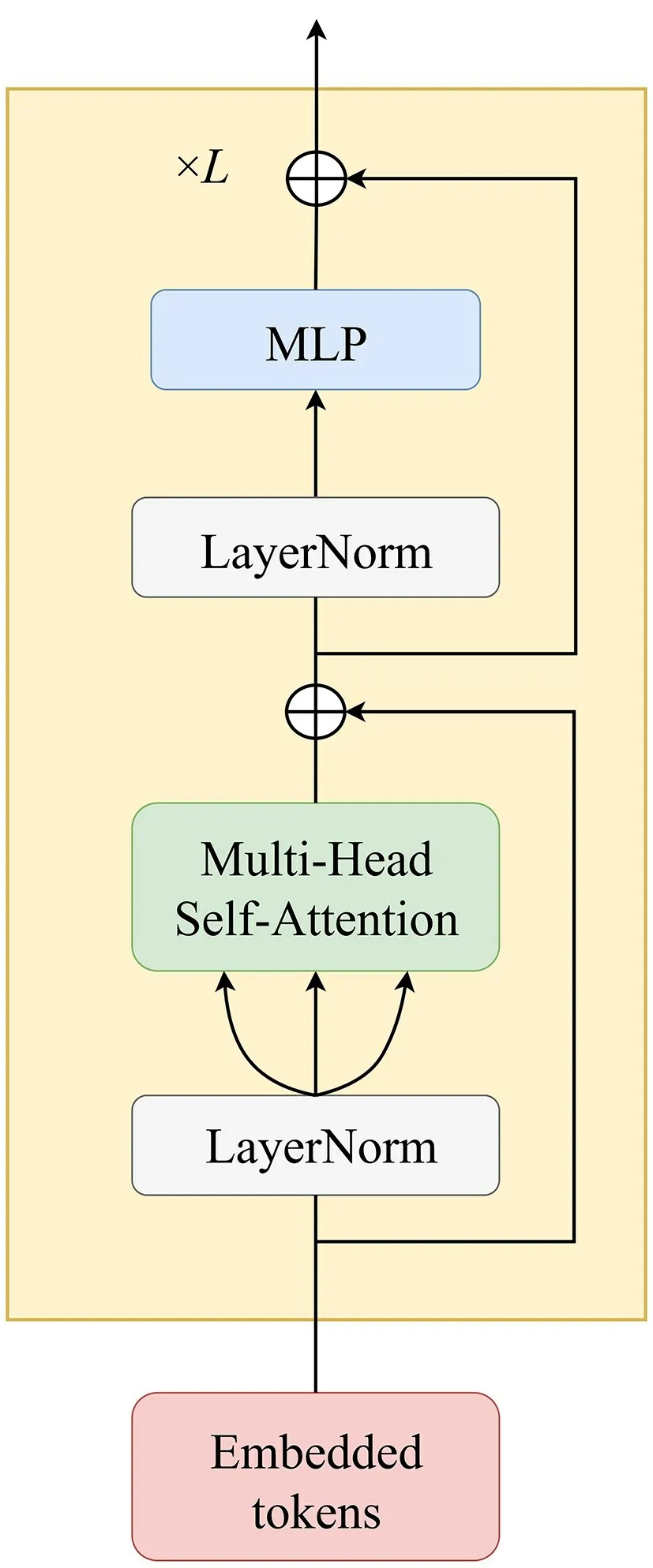
图3 Transformer结构
4)Position Encoding: 一维位置编码主要用来编码各个输入token的位置信息,可通过网络自主学习得到,或者直接通过正余弦函数的组合来指定绝对位置信息。
2.2 CNN均等分块切片
PCB[1]利用分块均值池化(global average pooling,简称GAP)来对F进行切片,当分块数达到一定数量时,这种做法会因为CNN 的感受野重叠和激活函数的双重影响在原图上产生暗幕(如图1所示),从而影响模型的性能。这也是为什么切片分块方法有分块数量限制的原因。首先,输入图像X,经过卷积神经网络CNN得到特征图F(F∈RH×W×C)。然后,对F进行平均等切片分块,但不池化。将F分成n块,即
2.3 TransformerIN与TransformerOUT
TransformerIN 和TransformerOUT 都是标准的Transformer结构,但两者各自所在的位置不同,担任的任务也不同。TransformerIN用于建模Pi内的像素级token向量信息,而TransformerOUT 则用于建模各个Pi得到的全局token向量之间的关联性,并做进一步的信息融合。在将Pi送入TransformerIN模块建模之前,需对Pi作进一步拆分,对拆分后的像素级token向量添加一个全局token向量gi和网络可自动学习的位置编码e。总的过程可表示为
其中:pk∈R1×1×C为Pi的像素级token向量;Tin1∈为TransformerIN的输入;ej∈R1×1×C为可学习的位置编码向量;gi∈R1×1×C为第i个分块Pi的全局token向量。
同理,对所有分块Pi,i=1,2,…,n,利用式(7)得到TransformerOUT的输入g,将g输入TransformerOUT前,加入全局分类token向量c,然后再进行位置编码,表达式为
2.4 损失函数
通过式(8)得到全局分类token向量c后,利用两层全连接(fully connected,简称FC)和softmax激活函数将分类token向量c映射并归一化到预测向量,维度和训练集中的行人类别数保持一致。这里参考PCB网络,采取简单的交叉熵损失函数,与其不同的是,只对融合后的分类token向量c做一路损失,而不是对每个分块部件向量都做一路损失。因此,本损失函数更加简单高效,其表达式为
其中:qi为真实标签值;softmax(FC(c))i为网络的预测值。
3 实验与结果分析
实验基于Intel® CoreTMi9-10900X CPU @3.70 GHz处理器,64 GiB 内存和英伟达的RTX-2080Ti显卡,采用基于Python的PyTorch深度学习框架来对网络进行实现。
3.1 数据集
采用行人重识别领域中较常用的2个数据集Market1501和DukeMTMC-ReID 作为主要的实验数据集。Market1501包含32 217张图片和1 501个行人标签以及6个摄像头视角,其中751个行人身份用于训练集,750个行人身份用于测试集。DukeMTMC-reID共收集了36 441张行人图片,包含由8个摄像头采集的1 812个行人身份,其中702个行人身份作为训练集,1 110个行人身份作为测试集。数据集的具体参数如表1所示。训练和测试时输入图像都裁剪为192像素×384像素。
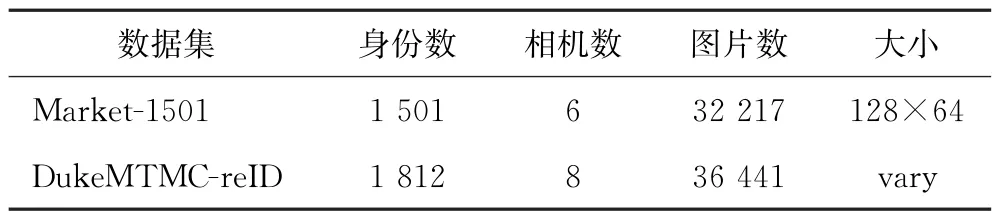
表1 数据集参数
3.2 实现细节
CIT模型实验中使用的CNN 主干网络为Res-Net-50,并将其中的conv5_x的步幅2改为1。对ResNet-50的输出进行0.5的dropout后,进行一次1×1的卷积,将通道数从2 048降为512,随后进行PReLU 激活函数[20]处理。然后通过Tensor的重编排操作将Tensor的宽高维度合并,最后通过算法1基于Transformer的核心代码进行处理。
在训练过程中,对输入图像进行水平翻转和归一化,并将batch size设置为64。模型学习率初始化为0.001,并使用不同的激活函数进行消融实验。总的训练epoch数为60。
算法1
3.3 结果及分析
实验主要采用的评价指标为rank-1和mAP[19]。对于rank-k,即算法返回的排序列表中,若前k位存在检索目标,则称rank-k命中,rank-k指的是搜索结果中最靠前的k张图片是正确结果的概率。mAP指的是前k位每个目标的AP值的平均,而AP值指的是返回的排序列表中含有目标的每个位置前包括当前位置目标的频率。mAP能够衡量模型在所有目标行人上的好坏。
3.3.1 激活函数的作用
在Market-1501数据集上,保持其他超参数不变,对PCB中的分块数设为12,将激活函数进行替换,每种激活函数训练5次并训练60个epoch取mAP平均值,得到结果如表2所示。
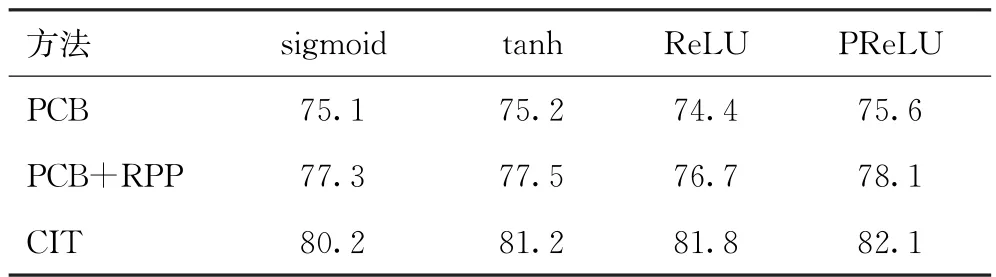
表2 激活函数的影响
由表2可看出,对于分成12块的PCB,由PCB的原文知道此时的感受野是存在重叠区的,ReLU 激活函数会将负值强制置零,相比之下更易产生暗幕,信息丢失得更多。而其他激活函数则在负值时仍有激活值保存下来,虽说可能在重叠区会保存一些重复信息,但CIT 因为内部Transformer擅长把握全局信息和信息融合的特性,仍能达到PCB 及PCB+RPP分成6块时的表现效果。
3.3.2 分块数的影响
由于图像在输入前都裁剪为192像素×384像素,图像经过CNN后得到的特征图大小为24×12×C,于是分块数n的可能取值只能为1、2、4、6、8、12、24。但对于Transformer,若分块数过小,则会导致输入CIT中第一个TransformerIN 的像素级token向量过多,从而加大相应的计算量。因此,对于CIT,分块数由4开始。对每种分块数进行实验,分别得到如图4、5所示的rank-1和mAP曲线。
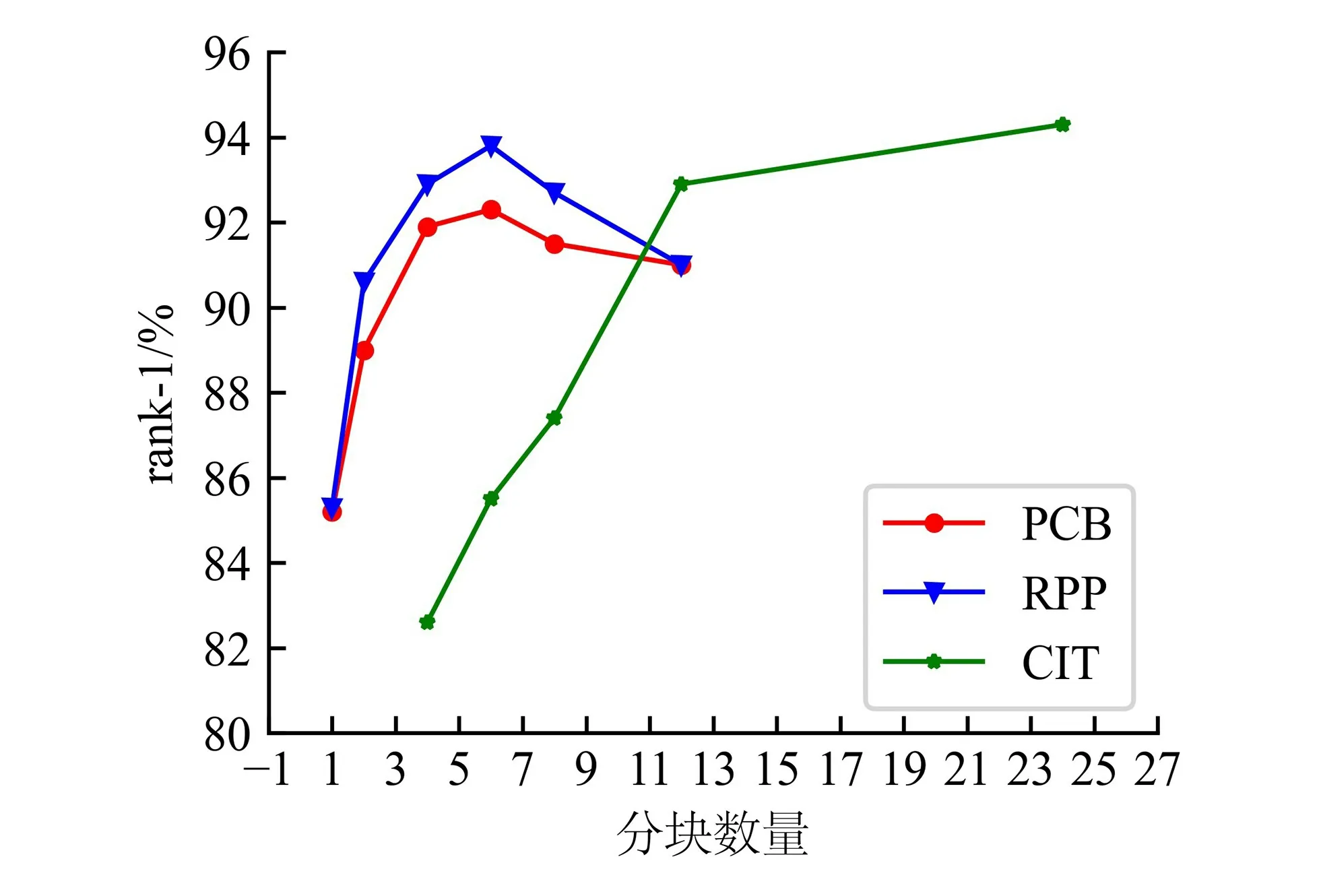
图4 分块数量对rank-1的影响

图5 分块数量对mAP的影响
从图4、5可看出,当分块数小于等于6块时,由于分块特征感受野之间并无过多的重复区域,PCB和PCB+RPP的性能都随分块数的增多而提升。当分块数大于6时,特征感受野之间的重叠现象加重,导致CNN从中提取有用信息更加困难,模型表现开始随着分块数量的增多而下降。但对于CIT而言,内部的2个Transformer结构中的一个在分块内进行全局建模,在有效去除冗余信息的同时,将块内主要信息融合到全局token向量中,而另一个则将各个块的全局token向量的信息进一步融合到分类token向量当中。因此,CIT性能够随着分块数量的增多而提升。
3.3.3 特征图大小的影响
将输入图像重塑成192像素×576像素后,再输入网络中,此时得到的特征图变为36×12×C,比之前的24×12×C大了144个像素级token向量。因此,CIT可对其进行更加细粒度的建模。在分块数方面进行对比实验,其rank-1和mAP指标的结果分别如图6、7所示。
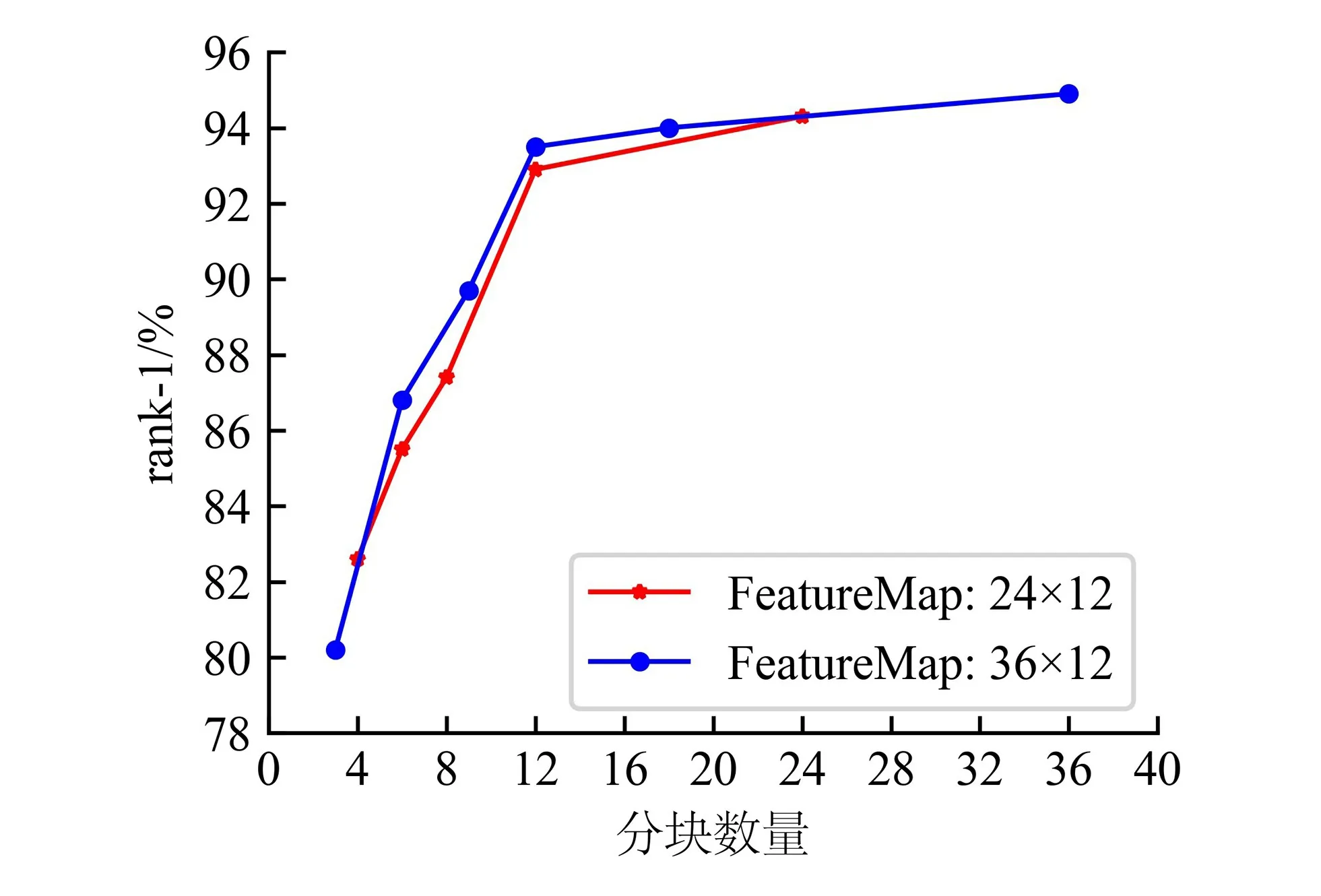
图6 不同特征图大小的分块数量对rank-1的影响
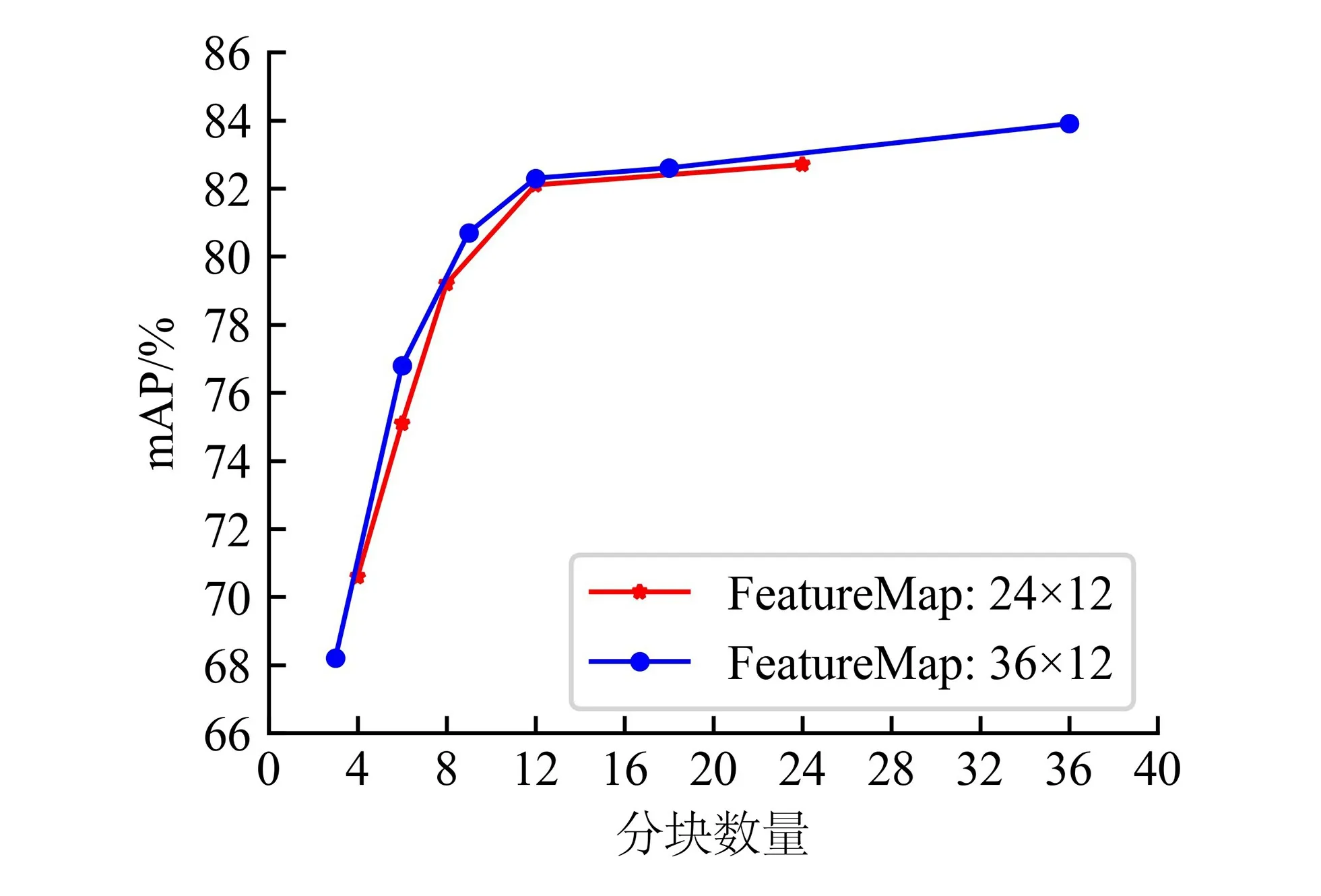
图7 不同特征图大小的分块数量对mAP的影响
从图6、7可看出,对于不同特征图大小的分块结果,模型性能总体上还是随着分块数量的增加而提升。对于相同或相近的分块数,如3、4、6、8、9、12,特征图大的无论在rank-1还是mAP上都比特征图小的高一点。也就是说,CIT确实能够对更加细粒度的特征进行建模,从中学习到了更多有用的信息。
3.3.4 与其他方法的比较
将CIT与其他切片方法在数据集Market-1501、DukeMTMC-reID上进行比较,结果如表3所示。
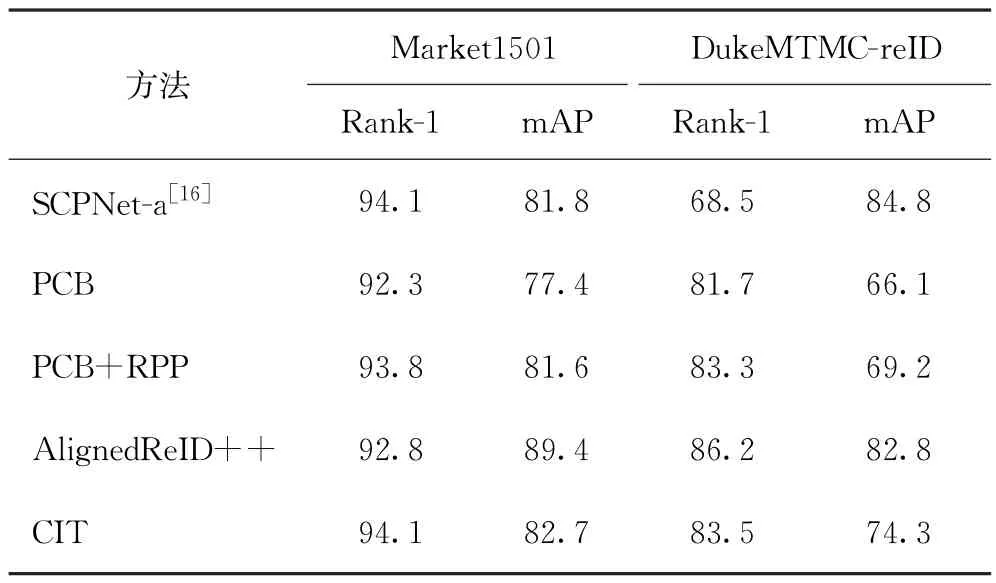
表3 CIT与其他方法在数据集Market1501和DukeMTMC-reID上的比较
从表3可看出,CIT比PCB及PCB+RPP表现要好,无论是在rank-1还是mAP都有小幅度提升。主要是因为CIT内部的2个Transformer结构能够更加高效地去除冗余信息,融合有效信息。但相比AlignedReID++,则略微逊色,主要是因为AlignedReID++中用到了动态局部对齐DMLI算法和reranking技术。但CIT和PCB+RPP在rank-1的指标上仍比AlignedReID++高一点,每个模型都有自己的擅长点与偏重点。
4 结束语
针对行人重识别中由于特征图感受野带来的切片分块限制问题,提出一种基于Transformer的行人重识别网络CIT。通过CIT中的TransformerIN 对分块特征进行更细粒度的特征建模,同时有效去除由感受野重叠带来的冗余信息。此外,CIT 中的TransformerOUT对由TransformerIN 得到的每个分块全局token向量进行建模,做进一步的信息提取,并融合到全局分类token向量中。实验结果表明,CIT确实能够很好地对更加细粒度的特征进行建模,善于把控全局,从中去除冗余的同时提取出有用信息。未来工作可以尝试直接去除CNN,利用单纯的Transformer来搭建整个特征提取网络,从而对更加细粒度的特征进行建模。
