基于游览行为和逆向强化学习的游客偏好学习
2023-10-22宣闻,常亮
宣 闻,常 亮
(桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004)
利用旅游推荐技术为用户提供个性化服务并提高推荐性能和游客满意度,是当前智慧旅游领域研究的热点之一。在旅游推荐中,理解游客的行为模式,学习游客偏好是非常重要的。当前的旅游推荐技术主要根据游客游览展品的评分、签到数据、访问的频次等数据作为游客对游览展品喜好程度的评判依据。但是,具体景区内部,如博物馆、主题公园等,通常无法获得游客针对游览点或展品的具体评分数据,因此不能对游客进行细粒度偏好学习,从而也不能获得针对特定景区内部的游览推荐。并且许多推荐算法需要大量的游客数据来训练,从而学习出游客偏好再进行推荐,然而展馆内部的游客数据较为稀缺、不完整,因此,无法根据有限的游客数据学习出精准的偏好。鉴于此,为了在游客数据较少的情况下获得游客更加真实、细粒度的偏好,提出一种基于游览行为和逆向强化学习的偏好学习方法。首先,通过物联网和移动传感器技术采集游客在特定景点内的各个游览点的拍照次数、游玩时间等游览行为数据;然后,针对采集到的行为数据设计逆向强化学习算法,基于获取到的真实数据进行细粒度偏好学习。
1 研究现状
1.1 位置感知技术
目前最常见的定位技术是GPS(global positioning system)全球定位系统,它通过卫星发射的基准信号来工作,但是在有建筑物遮挡的情况下,就无法运用GPS精准定位,因此GPS也被称为室外定位系统[1];在室内定位技术中,WiFi(wireless fidelity)部署成本低,但是,目前的WiFi定位技术需要通过预先测量来提供相对应的接入点(APs)、传播参数(PPs)以及地图上的具体位置,这个预先测量的过程既耗时又费力[2];Wang等[3]使用射频识别(radio frequency identification,简称RFID)技术来实现细粒度室内定位,该系统利用RFID的多路径效应进行精确定位,通过合成孔径雷达(synthetic aperture radar,简称SAR)提取多路径的配置文件,采用动态时间规划技术确定RFID 标签的位置,从而实现定位,但是RFID需要标签和读写器,部署成本较大,不适合在大型场合使用。iBeacon是苹果公司于2013年9月发布的新一代室内定位技术,具有低功耗蓝牙(bluetooth low energy,简称BLE)的通讯功能,它可以向周围发送自己特有的ID,同时根据iBeacon设备所发出的广播信号强度的变化,对智能手机和iBeacon之间的距离进行计算,得出距离最近的iBeacon设备,从而实现定位。iBeacon具有成本低、功耗低、跨平台、易安装部署等优点,在室内定位中具有较大的优势[4-5]。
1.2 用户偏好评估和应用
众多的社交媒体提供了丰富的数据信息,可用于获取游客的历史位置并分析他们的偏好,从而为游客提供个性化的推荐服务,因此,基于位置的社交网络在游客偏好学习在旅游推荐中得到了广泛的应用。Yuan等[6]提出基于位置-时间-序列的方法,利用基于位置的社交网络数据集从空间和时间两个方面对用户的偏好进行建模,然后用时间和空间特征结合的方式对用户的个人偏好进行预测。Zhu等[7]提出了一种基于语义模式和偏好感知的挖掘方法,首先将位置分为不同的类型,从而进行位置识别,然后从游客的位置轨迹、语义轨迹、位置的流行程度和用户熟悉度4个方面为每位用户进行建模,从而获取用户偏好并推荐兴趣点。Wang等[8]提出基于上下文感知的用户偏好预测算法,构建了云模型,将分类信息引入用户和位置的相似性估计中,当用户在一个新景点时,通过新景点的类别和访问过该景点的用户类别,预测用户的偏好。Zhu等[9]在基于位置的社交网络数据集上构建了旅游推荐的系统架构,并对每位用户的移动模式进行建模,最后根据产生的兴趣点进行推荐。
尽管上述的方法都可以学习游客的偏好,但是仍存在以下问题:首先,现有的游客偏好学习方法大多使用基于位置的社交网络数据集,而基于位置的社交网络数据集中,位置仅到景区级别,因此只能学习出游客对景区级别的粗粒度偏好,从而进行粗粒度的旅游景点推荐;其次,现有方法仅考虑了游客的位置、签到等数据信息,却未考虑到游客访问展品的先后顺序对游客偏好的影响。此外,在游客实际旅游的过程中,不会一直共享自己的位置信息,因此最后收集到的游客签到的数据集仅包含了游客一部分的位置信息,从而导致数据稀疏,对游客偏好的学习不全面,无法对景区内部景点进行细粒度的推荐。
1.3 逆向强化学习
逆向强化学习(inverse reinforcement learning,简称IRL)是一种通过专家数据学习出回报函数的技术,它首先通过马尔科夫决策过程(Markov decision process,简称MDP)对应用场景进行建模,然后利用相关算法进行学习。吴恩达等[10]通过观察该领域的专家示例来学习用户偏好,从而学习到背后的回报函数,这个逆向强化学习的方法被称为学徒学习。Ratliff等[11]将评估回报函数转化为特征到回报的线性映射问题,在这种线性映射下,最优的策略与专家策略十分接近,此方法称为最大边际规划方法。但是基于最大边际规划方法的主要问题是会产生歧义,比如有很多不同的回报函数会导致相同的专家策略。为了解决这个问题,Ziebart等[12]提出基于最大熵的逆向强化学习方法,即在已知专家轨迹的情况下,求解产生轨迹分布的概率模型。上述方法虽然能够学习出回报函数,但是所需的数据量较大,需要较多的数据进行不断地迭代才能训练出较为准确的回报函数。Babes等[13]提出的极大似然逆向强化学习方法,与前面的算法相比,优势在于可以在数据较少的情况下训练出回报函数。Massimo等[14]提出基于用户与项目的交互来学习用户偏好方法,该方法将极大似然逆向强化学习运用于学习用户对项目的偏好上,最后学习出用户偏好;2018年,Massimo等[15]在之前方法的基础上,提出一个基于上下文用户行为模型的方法,该方法对用户的轨迹进行分类对于每个分类都产生一个基于上下文用户行为模型,最后将用户的轨迹与得出的行为模型相结合,从而学习出用户的偏好。上述2个方法均考虑到在用户与项目交互的过程中现场所产生的行为对偏好的影响。
2 预备技术
对游客在室内展馆的游览行为进行马尔科夫决策过程建模。首先,简单介绍了运用iBeacon进行数据采集的整体流程,然后详细介绍了马尔科夫决策过程建模过程,并对相关评估函数进行简要说明。
2.1 数据收集
场景布置在室内展馆。首先,给游客的智能手机上安装导览App,同时在展馆入口处、展馆内部的每一个展品都布置iBeacon,用于获取游客的位置信息,游客数据采集过程如图1所示。游客智能手机上的导览App通过手机照相机、加速度传感器来接收iBeacon所发送的信号,从而收集游客多种游览行为数据(比如拍照、停留时间等)。iBeacon设备就是利用低功耗蓝牙(BLE)通信协议向周围发送自己特有的设备ID;在iBeacon协议数据中,包含了Minor和Major两种标识符。在应用场景中,将iBeacon设备进行分组,其中Major用来识别iBeacon设备属于哪一组,Minor用来标识同一组内的不同iBeacon设备,即Minor设置为展馆内部展品的ID,Major设置为展品所属的分区,因此可以通过Minor和Major两种标识的结合来对游客当前游览展品的位置信息进行定位。
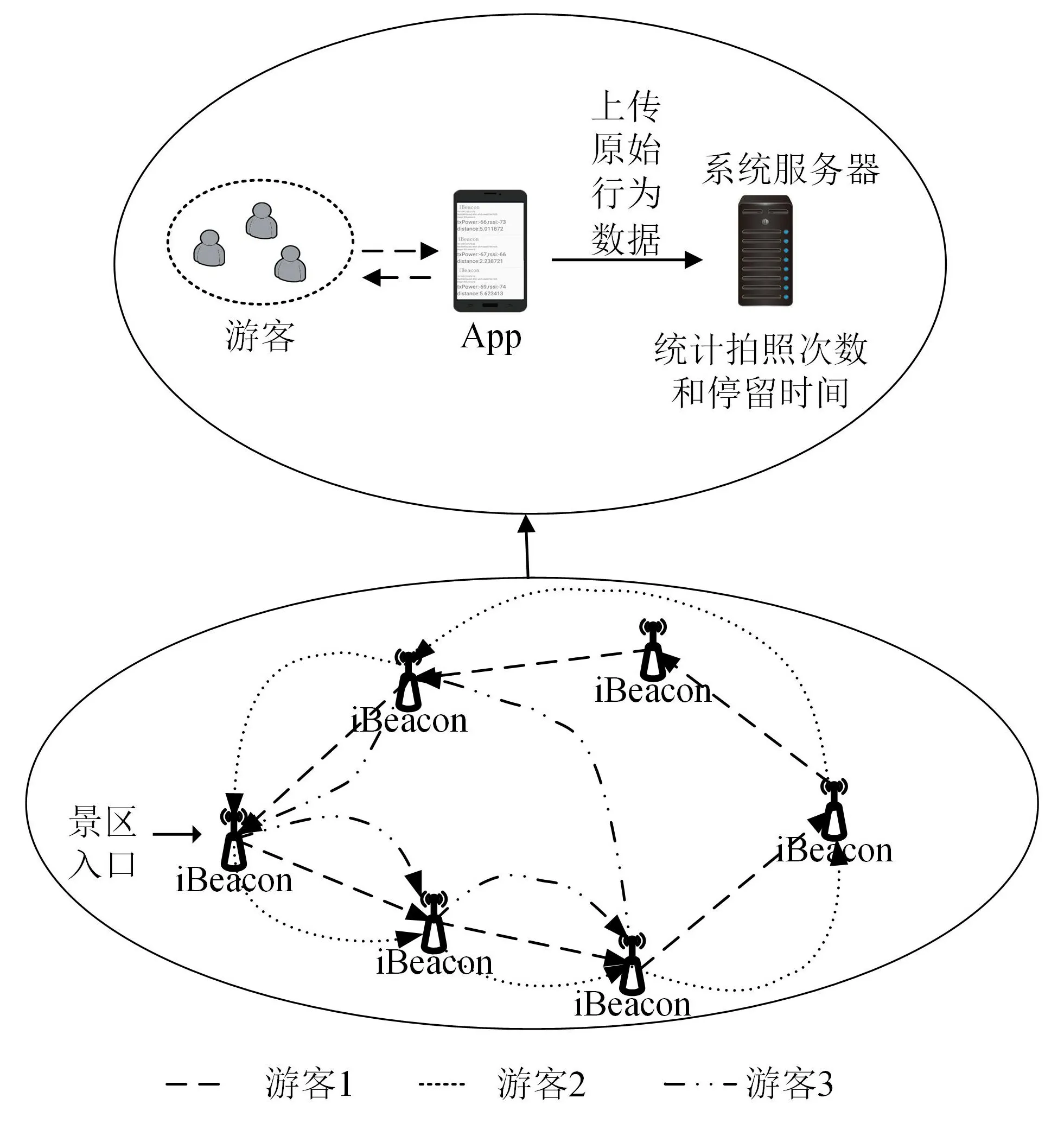
图1 游客行为数据的采集
智能手机中的应用程序接收到iBeacon设备广播信号,然后智能手机读取传感器数据并监听拍照广播,最后通过无线网络将采集的数据上传至系统服务器。当有游客进行拍照时,智能手机中的应用程序会立即检测到拍照行为的发生,随后向系统服务器发送广播;系统服务器根据接收拍照广播的次数和iBeacon的位置标识统计出游客在某展品的拍照次数,并存储游客行为数据。如图2所示,收集数据的日志中包含了游客与iBeacon交互的时间戳序列,用户的行为加速度数据和浏览展品的标识。
2.2 马尔科夫决策模型构建
通过马尔科夫决策过程MDP模型对游客在室内展馆的游览行为进行建模,马尔科夫决策过程可以用一个五元组(S,A,p,r,γ)来表示,其五要素的定义如下:
定义1状态s表示游客当前浏览展品的记录,其状态空间为S。
例如:游客刚进入展馆,状态默认为s0,其中s0=∅;当游客浏览了展品a1时,则游客的状态变为s1,其中s1={a1};游客下一个浏览了展品a2,则游客的状态变为s2,其中s2={a1,a2},以此列推S={s0,s1,s2,…}。
定义2动作a表示在状态s下,游客下一个将要浏览的展品,其动作空间为A。
定义3状态转移概率p(st+1|st,at)表示从状态st通过动作at转移到状态st+1的概率,其中,st∈S,at∈A。
例如,游客浏览展品记录s1的情况下,接下来想要浏览展品a2或者展品a3,那么状态转移概率可定义为p(s2|s1,a2)=0.5,p(s3|s1,a3)=0.5。
定义4r(st,at)表示回报函数,是在游客当前浏览展品记录st下,浏览展品at后所能获得的回报,其中,st∈S,at∈A。这个回报值与游客偏好值成正比,也就是说游客对展品at的偏好越高,那么回报值也就越高。为了方便计算,定义r(st,at)≤1。
定义5γ∈[0,1]代表折扣因子,用来计算累积的回报。
游客与展馆内展品的交互过程可看作一个马尔科夫决策过程,如图3所示。
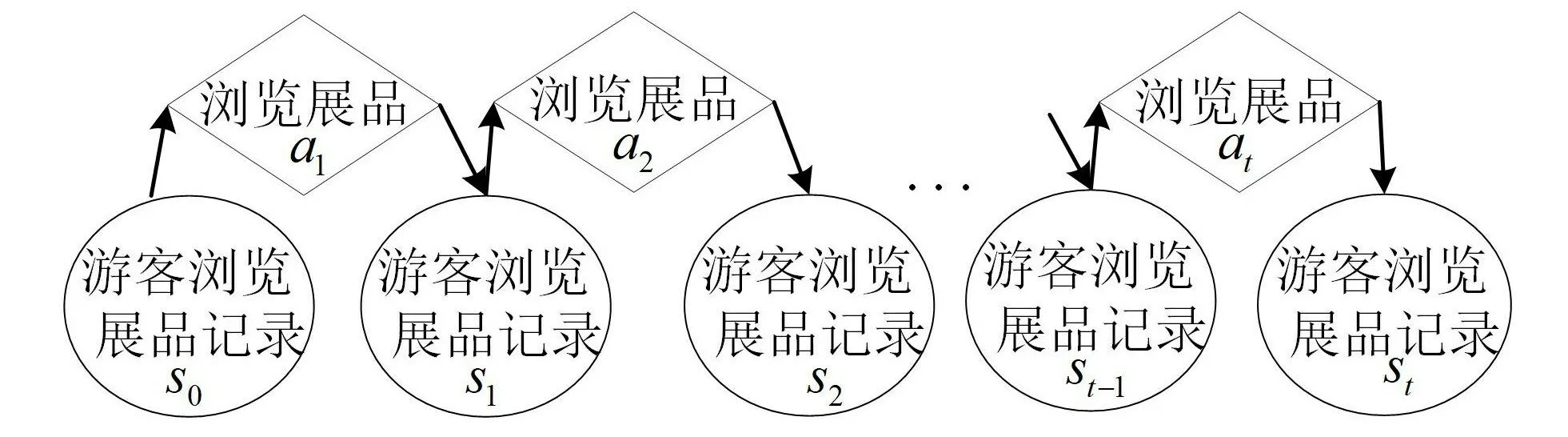
图3 马尔科夫决策过程模型
游客从进入展馆内开始,浏览记录默认为s0。当浏览展品a1时,会有相应的拍照次数和停留时间;将拍照次数和停留时长作为特征值加入回报函数中,计算出回报值r1,并更新游客浏览记录s1;然后游客浏览下一个展品a2,以相同的方式计算出回报值r2,游客浏览记录相应地变为s2,一直交互下去,因此游客浏览时的交互序列如式(1)所示,其中s0,s1,…,st-1,st∈S。
马尔科夫性是指下一个时刻游客浏览的展品记录st+1,只取决于当前时刻游客浏览过的展品记录st和正在浏览的展品at,其他所有的历史浏览过的展品记录都可以被丢弃。如式(2)所示,其中p(st+1|st,at)为游客浏览展品的转移概率:
而在各状态下如何选择动作at的这一规则是由策略π决定的,见定义6。
定义6策略(policy)定义为π:S→A,代表游客浏览展品记录的状态空间到游客下一个浏览展品的行为映射。通过式(3)可知,策略π是指在给定状态s时,动作集上的条件概率分布,即策略π可以在每个状态s上指定一个动作的概率,也就是策略π可以根据游客浏览展品的记录s来决定下一步推荐给游客的展品a:
例如,一个游客浏览展品的策略为π(a2|s1)=0.3,π(a3|s1)=0.7,这表示游客在浏览记录s1的情况下,浏览下一个展品a2的概率为0.3,浏览展品a3的概率为0.7,显然游客浏览展品a3的可能性更大。
在给定策略π和马尔科夫决策过程模型的基础上,就可以确定一条游客游览展品的交互序列τ:
游客浏览展品的交互序列所能获得的累积回报为G(τ),总回报G(τ)如式(5)所示,其中rt表示游客浏览的第t个展品所获得的回报。
因此,目标就是学习出一个最优策略π*,使得累积回报值G(τ)达到最大。但是,在当前求得的策略π下,假设从状态s1出发,游客的浏览展品状态序列可能如图4所示。
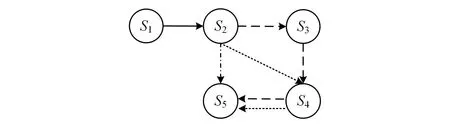
图4 游客浏览展品状态序列示意图
此时,在策略π下,利用式(5)可以计算出累积回报G(τ);通过图4可知,游客浏览展品的交互状态序列存在多种可能性,所以此时计算出来的G(τ)也存在多种可能值,因此无法通过累积回报G(τ)评估当前策略π是否最优,但是累积回报的期望是一个确定值,可以用来评估。因此在一个状态s下,基于特定策略π,做出行为a得到累积回报的期望值可由式(6)得到:
因此,当Q值达到了最大即Qmax时,所求的策略π为最优。
但是现实中很多情况下回报函数是未知的,用户浏览某个展品时,未必会给出反馈,因此,很多时候回报函数难以定义。针对此问题,可采用逆向强化学习算法来解决,根据已有的游客浏览展品相关轨迹示范数据学习出对应的回报函数。
3 基于逆向强化学习的游客行为偏好学习
3.1 逆向强化学习
逆向强化学习是一个未知回报函数的马尔科夫决策过程(MDP ),可以用一个四元组(S,A,p,γ)来表示。当专家在完成某项任务时,其动作往往是最优或者接近最优,那么可以假设,当所有的策略π所计算出的累积回报期望无限接近于专家策略所计算出的累积回报期望时,可以认为专家示例所学到的回报函数即为所需要的回报函数。因此,逆向强化学习可以从专家示例中学习到回报函数,也就是在已知状态S、行为A、状态转移概率为p的条件下,从已有的游客浏览展品相关轨迹数据中反推出相对应的回报函数。也就是使算法产生的游客浏览展品轨迹与已有的游客浏览展品轨迹相近,这等价于在某个回报函数下求解最优策略π*,在该策略下产生的轨迹与已有的游客轨迹相近,当策略达到最优时,游客轨迹的累积回报达到最大,所学到的回报函数也达到最优。
因为回报函数r(st,at)未知,所以可利用函数逼近的方法对其进行参数逼近,其逼近形式为
式(7)中,Ø=(∅1,∅2,…,∅d)T,Ø:S×A→Rd为数量有限并且固定有界的特征基函数,d为特征基的个数,Øi为每个状态的特征向量。θ=(θ1,θ2,…,θd)表示各个特征基之间的权重向量。通过这样的线性表示,可以对权重进行调整,从而改变回报函数值。逆向强化学习的目标是学习出权重向量θ,从而计算出回报函数Rθ(s,a)。
在应用的场景中,一共有15个展品,首先统计在当前状态s下,某展品的拍照次数ms和停留时间ys(以s为单位)2种游客行为特征。然后,将回报函数定义为浏览展品时所产生的瞬时回报与在该状态下游客浏览展品时的拍照次数和停留时间所产生的回报之和。为了便于计算,将拍照次数和停留时间所产生的回报通过式(8)将数据归一化,其中:x*代表当前状态下的拍照次数或者停留时间的值,min和max代表在所有状态下拍照次数或者停留时间的最小值和最大值;
则在当前状态下的回报函数可表示为
将已有的游客浏览轨迹处理成“状态-动作-行为特征”序列。假设有N个游客轨迹数据D={ζ1,ζ2,…,ζN},每条轨迹数据长度为H,则一组轨迹数据序列可表示为ζi=((s1,a1,m1,y1),(s2,a2,m2,y2),…,(sH,aH,mH,yH)),其中sH∈S,aH∈A。将每条轨迹数据长度H定义为15。例如,一个游客u的浏览轨迹为ζu=((s1,a2,m1,y1),(s2,a4,m2,y2),…,(s15,a1,m15,y15)),则代表游客u在状态s1下浏览了展品a2,其中在展品a2的拍照次数为m1,停留时间为y1;然后浏览了展品a4,其中在展品a4的拍照次数为m2,停留时间为y2,以此类推。逆向强化学习整体过程如图5所示。首先,游客在状态s下,选择动作a所能获得的回报R(s,a)往往是未知的,因此需要通过专家示例(已有的相关游客浏览展品的轨迹数据)来学习到背后的回报函数。而在学习过程中,加入了拍照次数、停留时间2种游客行为特征来进行训练;最后通过逆向强化学习算法,学习出回报函数Rθ(s,a)。
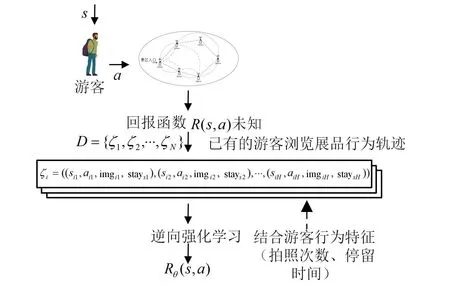
图5 逆向强化学习过程示例图
3.2 最大似然逆向强化学习
根据Babes等[13]提出的最大似然逆向强化学习(maximum likelihood inverse reinforcement learning,简称MLIRL)算法并结合游客行为特征(拍照次数、停留时间)来学习θ。最大似然逆向强化学习算法与贝叶斯逆向强化学习[16]类似,采用了一种概率模型,通过θ创建一个值函数,然后假设专家在单个操作选择级别随机化;与最大熵逆向强化学习类似[12],在已知专家轨迹的情况下,求出产生该轨迹分布的最大似然模型;与策略匹配类似,它使用梯度方法求得用户行为策略,并在训练的过程中,用户行为策略不断向专家策略靠近。因此,最大似然逆向强化学习融合了其他逆向强化学习模型的特点,且可在专家轨迹较少情况下对回报函数进行估计,通过专家轨迹寻找出最大似然模型,并不断对初始的回报函数进行调整,通过梯度不断优化策略π。因此,在一个状态s下,做出行为a得到累积回报期望可表示为
在MDP中,动作定义为下一个浏览的展品,所以动作空间并不大,因此采用玻尔兹曼分布作为策略,可表示为
在此策略下,基于已有的游客浏览展品相关轨迹示范数据的对数似然估计函数可表示为
因此,最大似然逆向强化学习算法是通过梯度上升的方法求出函数中θ的最大值,即θ=argmaxθL(D|θ)。
在给定的马尔科夫决策模型中,通过已有的游客浏览展品相关轨迹示范数据得到的最优回报函数可能存在多个;而MLIRL算法可以对观测到的行为分配较高的权重,对于未观测到的值分配较低的权重,从而解决回报函数不唯一的问题。MLIRL算法即极大似然逆向强化学习(maximum likelihood inverse reinforcement learning,简称MLIRL)如下所示。
4 实验
4.1 实验条件
客户端应用程序使用的是Android studio开发,JDK1.7版本,运行在Android智能手机系统版本6.0.1。相关应用程序运行在JetBrains PyCharm上。15个基于CC2541的iBeacon。
4.2 实验环境
应用场景布置在一个具有15个展品的室内展馆,每个展品都提前安装了iBeacon。本研究邀请了35名年龄段在20~22周岁的女大学生作为志愿者参观展馆,并且进入展馆前在他们的智能手机中装上采集数据App。同时,给每个志愿者发一份调查问卷,便于后期处理的时候获取他们对展品的真实偏好。
4.3 参数设置
在实验中,将折扣因子γ设置为0.6。在MLIRL算法中,将参数β设置为0.75,步长λt=1/。
4.4 实验结果分析
4.4.1 游客偏好学习
利用调查问卷的形式获取游客对展品的实际偏好排名。表1为选取的35位女大学生对15个展品的平均偏好排名。

表1 游客对15个展品偏好平均排名
若MDP模型得出的志愿者对某个展品偏好排名与调查问卷中的排名一致,则定义平均偏好准确率为n/m;其中,n为MDP模型中学习出志愿者展品偏好排名与调查问卷中排名一致的总个数,m为总的展品数。
将35位志愿者的轨迹数据进行训练,从而得出志愿者的平均偏好准确率分布,结果如图6所示,其中,将仅包含了游客浏览点的数据记为原始数据。将原始数据训练出来的结果与每个浏览点加入游客行为特征(拍照次数和停留时间)的数据训练出来的结果做对比。
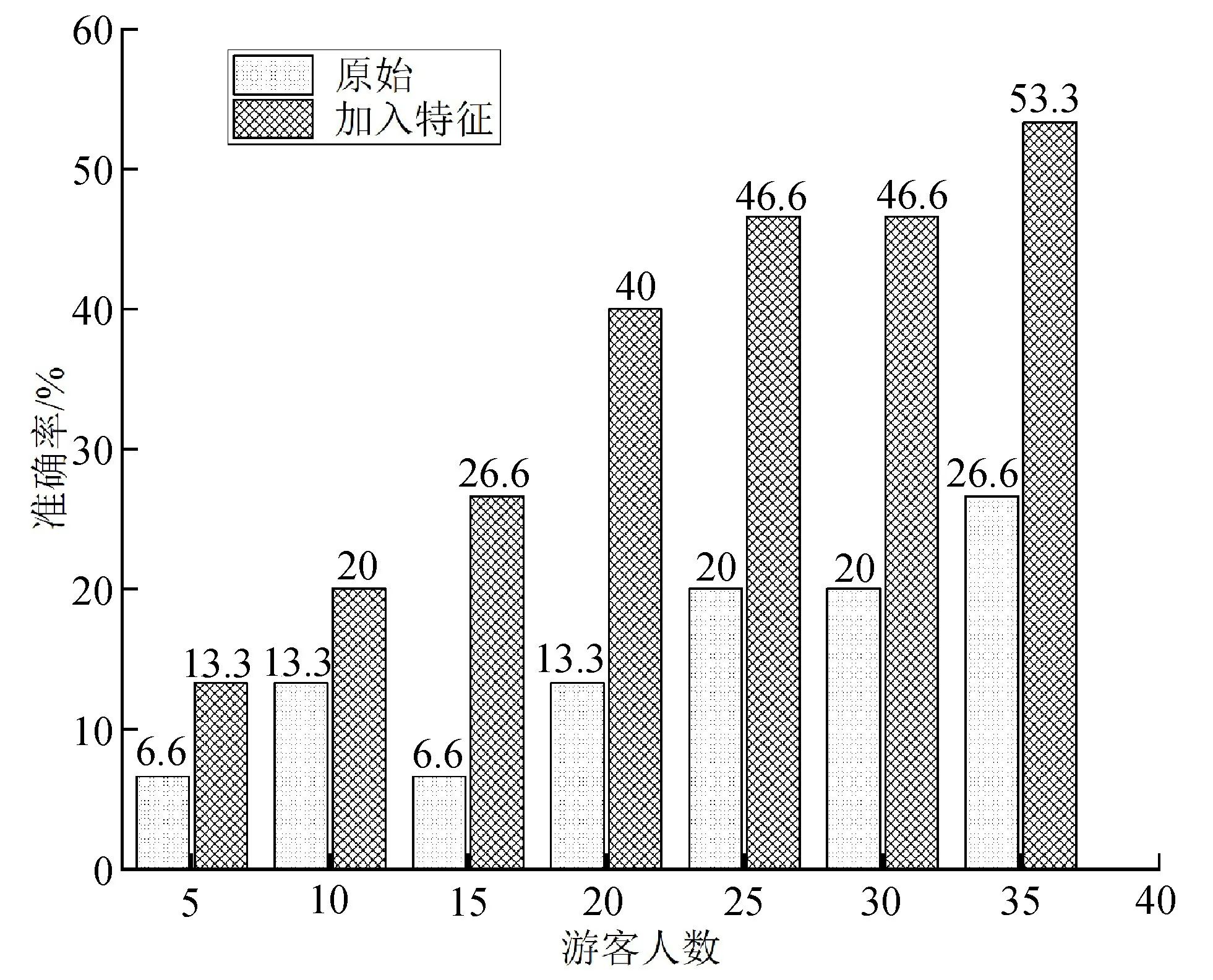
图6 平均偏好学习准确率
从图6可看出,随着人数的增加,轨迹数的增长,游客的平均偏好准确率呈现出不断上升的趋势。加入游客行为特征(拍照次数和停留时间)的数据与原始数据相比,在每个浏览点中加入游客的行为特征所学习出的游客偏好性能比之前更好,准确率提高更快,且在人数达到35个时,游客平均偏好准确率达到53.3%,这也表明在真实轨迹较少情况下,该算法在结合了游客行为特征,能够较好地从游客的轨迹中学习出年龄段在20~22周岁的女学生对展品的平均偏好。在实际应用中,随着游客人数的增加、展馆展品的增多,本方法对游客偏好的学习比传统的调查问卷方式更有优势,轨迹数越多,偏好学习的结果也会更加全面、客观。
4.4.2 游客行为特征对偏好学习的影响
在实验中,主要加入了2种游客行为特征:拍照次数和展品游玩时间。为了验证哪种特征对实验的效果影响更大,分别加入一种特征来测试,最后通过展品偏好准确率来验证。图7为分别在加入拍照次数和停留时间特征的情况下的偏好学习准确率。从图7可看出,随着游客人数的增加,轨迹数的增多,游客在展品的游玩时间对偏好学习的影响更大,而拍照次数相对就小一些。
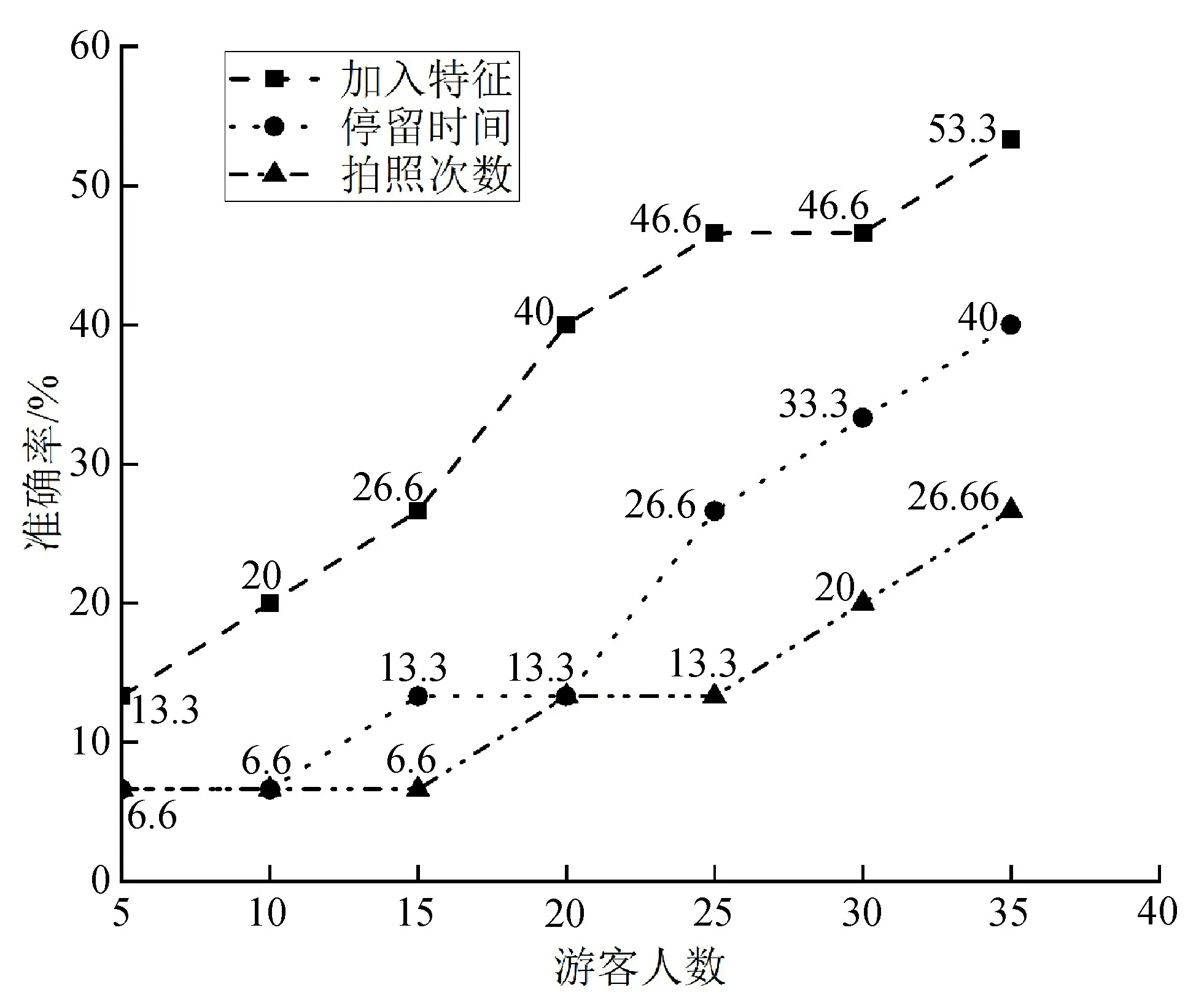
图7 游客行为特征对实验效果的影响
4.4.3 基于逆向强化学习的游客偏好学习模型参数化
在实验中,参数的取值会对模型的准确率产生一定影响。因此,为了提高模型的准确率,对折扣因子γ取不同值来对比模型的准确率,如表2所示。
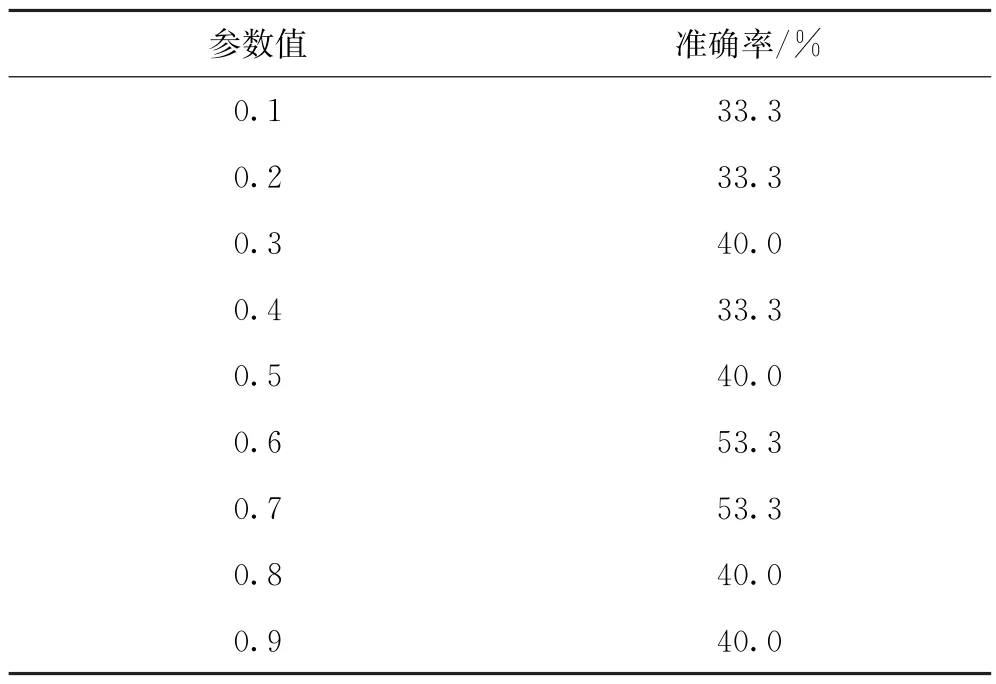
表2 准确率对比
折扣因子γ代表了未来的回报相对于当前的回报的重要程度,当γ=0时,代表只考虑当前的回报,不考虑长期回报;当γ=1时,长期回报和当前回报同等重要;通过表1可知,并不是γ越大越好,当γ=0.6和γ=0.7时,偏好学习的准确率最高,为53.3%。
5 结束语
针对在景区内中难以获取游客细粒度偏好的问题,提出一种基于现场游览行为感知和逆向强化学习的游客偏好学习方法。利用物联网与移动传感器技术相结合采集了游客在特定景区内的游览行为数据,即拍照次数和停留时间。将游客在每个展品的拍照次数和停留时间作为行为特征,将游客行为特征与逆向强化学习相结合,从而实现从较少的游客数据中学习出游客细粒度的偏好。实验结果表明,在真实的场景下,该方法能够在少量游客游览行为数据的情况下有效学习出游客的细粒度偏好。但是在实际游览过程中,天气的状况、气温的变化、人群的密集度等多种特征都会影响游客的偏好,因此将来可以综合性的考虑这些因素,更有效地学习出游客细粒度的偏好。
