基于关键词图表示的文本语义去重算法
2023-10-21汪锦云向阳
汪锦云,向阳
基于关键词图表示的文本语义去重算法
汪锦云,向阳*
(同济大学 电子与信息工程学院,上海 201804)( ∗ 通信作者电子邮箱epiphany@tongji.edu.cn)
网络中存在大量语义相同或者相似的冗余文本,而文本去重能够解决冗余文本浪费存储空间的问题,并能为信息抽取任务减少不必要的消耗。传统的文本去重算法依赖文字重合度信息,而没有较好地利用文本语义信息,同时也无法捕捉长文本中距离较远句子之间的交互信息,去重效果不理想。针对文本语义去重问题,提出一种基于关键词图表示的长文本去重算法。首先,通过抽取文本对中的语义关键词短语,将文本对表示为以关键词短语为节点的图;其次,通过多种方式对节点进行编码,并利用图注意力网络(GAT)学习节点之间的关系,从而得到文本对图的向量表示,并判断文本对是否语义相似;最后,根据文本对的语义相似度进行去重处理。与传统算法相比,所提算法能有效利用文本的语义信息,并能通过图结构将长文本中距离较远的句子用关键词短语的共现关系连接起来,从而增加不同句子之间的语义交互。实验结果表明,所提算法在两个公开数据集CNSE (Chinese News Same Event)和CNSS(Chinese News Same Story)上都取得了比Simhash、BERT (Bidirectional Encoder Representations from Transformers)微调、概念交互图(CIG)等传统算法更好的表现。具体地,所提算法在CNSE数据集上的F1值达到84.65%,在CNSS数据集上的F1值达到90.76%,说明所提算法可以有效提升文本去重任务的效果。
文本语义去重;关键词抽取;文本匹配;图表示;图注意力网络
0 引言
随着互联网技术和互联网产业的快速发展,网络成为越来越多信息的载体,信息的获取和利用也变得容易。文本作为信息最重要的载体之一,在网络上具有传播速度快、传播范围广等特点,在人们的信息获取过程中起着重要的作用。
在互联网时代,网络文本存在被大量转载、简单修改再发布等问题,同时也存在对同一新闻事件的不同描述等,导致网络文本存在大量冗余问题,为后续信息抽取、利用增加了复杂性,因此各种文本去重技术应运而生。文本去重技术能够判断两篇文本是否属于语义相同或相似文本,选择将冗余文本去除,从而节省存储空间,同时为后续利用自然语言处理技术处理数据、抽取所需信息减少数据量,提高数据处理效率。
文本去重问题实质是通过计算两篇文本之间的语义相似度判断两篇文本是否属于语义相同或者相似文本,从而决定是否丢弃处理。文本去重算法从构建文本特征方法的角度可以分为两类。一类是以Simhash[1-2]为代表的基于哈希的去重算法,其他的类似算法还有Minhash[3]、局部敏感哈希(Locality Sensitive Hash, LSH)[4]、MurmurHash算法[5]等。基于哈希算法的文本去重方法的主要原理是将文本转化为定长的二进制编码,再通过二进制编码之间的距离判断文本是否属于相似文本,因此这类方法高度依赖文字重复度信息,难以反映文本的语义信息。如图1所示,文本1与文本2虽然都表达了相似的语义,但文字重复度较低,因此通过Simhash算法得到的海明距离相差较大;而文本3与文本4虽然语义不同,但在字面上有较多文字重复,得到的海明距离相差较小。另一类是基于深度学习模型的语义去重算法,如基于深度网络的深度结构语义模型(Deep Structured Semantic Model, DSSM)[6]、卷积潜在语义模型(Convolutional Latent Semantic Model, CLSM)[7]等。目前基于深度学习的中文文本去重算法多聚焦于中文短文本去重问题,而相较于短文本,长文本在结构层次上更为复杂,蕴含更多语义信息。这些结构信息和文本中复杂的语义信息对计算文本相似度进行文本去重至关重要,应当在算法中被充分利用。此外,多数深度学习算法独立地抽取两篇文本的特征并转化为向量表示[8]计算相似度,丢失了两篇文本之间的交互信息。

图1 Simhash相似度示例
针对以上问题,本文提出一种基于关键词图表示的文本去重算法。首先,通过构建语法分析树与词性标注确定关键词短语候选集,引入预训练语言模型获取两篇文本中的关键词短语的嵌入表示,使得抽取出的关键词短语可以很好地表示文本的语义信息。其次,将关键词作为图的节点,共现关系作为图的边,将文本对构建成图模型,从而将长文本中距离较远的句子通过关键词的共现关系联系起来,增强不同句子之间的语义交互,同时可以使得模型通过后期训练学习到两篇文本之间的交互信息。最后,拼接多种方式抽取得到的节点特征向量,通过图注意力网络(Graph Attention Network, GAT)[9-10]训练,得到图的最终向量表示,将文本对图的向量表示送入分类器中判断两篇文本是否相似,进而进行去重处理。
本文的主要工作总结如下:
1)提出一种基于关键词图表示的长文本去重算法。该算法以语义关键词短语为节点,共现关系为边,通过图表示,更好地增强文本中句子的语义交互;同时引入基于注意力机制的GAT,更好地学习各节点之间的关系,从而提升模型的表现。
2)提出一种引入语法解析树和预训练语言模型的关键词抽取算法。该算法引入预训练模型获取关键词短语的语义表示,相较于传统关键词抽取方法,更关注语义信息的利用和关键词与文本之间的语义相似度,抽取出的关键词短语能够更好地表示文本语义信息。
3)本文提出的基于关键词图表示的长文本去重算法,在CNSE(Chinese News Same Event)和CNSS(Chinese News Same Story)[11]两个公开数据集上展开实验,所提算法取得超越先前基线算法模型的结果。
1 相关工作
1.1 文本去重
以Simhash为代表的传统文本去重算法通常使用哈希函数将文本编码成二进制签名值,通过签名值之间的距离判断文本是否需要去重处理。这类方法可以有效地利用文本字面信息,相较于传统hash、LSH等算法,不会因为个别文字的差异导致签名值之间存在较大的差别,可以在一定程度上表征文本内容的相似度;并且哈希算法是一种高效的算法,因此Simhash等去重算法被广泛应用于文本去重、网页去重等领域。后续很多学者基于Simhash算法提出了很多改进措施[12-13],并取得了不错的效果。随着深度学习的快速发展,深度学习方法被用于处理文本去重任务,早期使用词嵌入编码完成文本匹配计算,但是词嵌入编码本身无法解决短语、句子的语义表示问题,也无法解决文本匹配的非对称性问题,导致去重效果不佳。随着大型预训练语言模型的出现和图表示学习的发展,文本嵌入表示能够融入更多语义信息,同时标注数据的使用大幅提高了模型的表征能力,提升了文本去重的效果。
1.2 关键词抽取方法
关键词抽取指为了方便用户能够快速地掌握文本的中心内容,从文本中抽取一定量的关键词表示文本的语义信息。关键词抽取从训练方法上可以分为无监督抽取方法[14]和有监督抽取方法[15]两类。
无监督关键词抽取方法不需要人工标注训练集合的过程,因此更加快捷且成本较低,主要分为3类:1)基于统计特征的关键词抽取,如词频(Term Frequency, TF)、词频‒逆文本频率(Term Frequency-Inverse Document Frequency, TF-IDF);2)基于词图模型的关键词抽取[16],如TextRank;3)基于主题模型的关键词抽取[17-18],如潜在狄利克雷分布(Latent Dirichlet Allocation, LDA)。
有监督关键词抽取算法可以将关键词抽取问题转化为多种自然语言处理任务,主要分为基于序列标注[19]的关键词抽取算法、基于分类模型的关键词抽取算法和基于序列生成的关键词抽取算法。有监督关键词抽取算法可以根据标注数据训练调节多种信息对关键词抽取的影响程度,取得了相较于无监督关键词抽取算法更优的效果。
1.3 图表示学习
DeepWalk是最早实现图表示学习[20]的工作之一。DeepWalk提出的背景问题是对社交网络上的每个成员分类。此后,研究者针对大规模网络计算提出了LINE(Large-scale Information Network Embedding)算法、DeepWalk和LINE算法的升级算法Node2Vec,具有很高的适应性。Kipf等[21]提出融入卷积神经网络(Convolutional Neural Network, CNN)的图卷积网络(Graph Convolutional Network, GCN)。图注意力网络(GAT)[9-10]是在图表示学习中引入注意力机制,能够有效学习节点与邻居节点的关系,实现对不同邻居节点的权值自适应匹配,提高模型的表征能力。
目前,图表示学习被广泛应用在文本相似度计算和文本匹配问题中。Liu等[11]提出一种概念交互图(Concept Interaction Graph,CIG)的图表示学习模型,通过将文本转化为图,较好地概括文本,并且通过GCN学习节点特征,大幅提升中文长文本匹配效果。
2 基于关键词图表示的长文本去重算法
为了充分利用文本的语义信息,增强文本对之间的信息交互,本文提出基于关键词图表示的长文本去重算法。该算法整体架构如图2所示。整个算法可以分为4个部分:首先引入预训练模型抽取出两篇文本的关键词;其次根据抽取出的关键词构建文本对图表示;再次对图的节点编码并通过GAT模型训练进行匹配聚合;最后将生成的文本对的向量表示送入分类器中分类,并根据分类结果进行去重处理。

图2 基于关键词图表示的中文长文本去重算法整体结构
2.1 关键词抽取

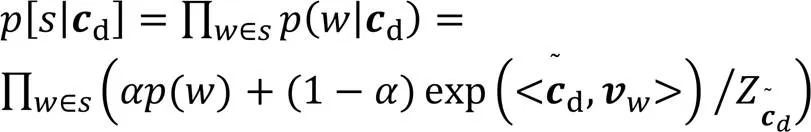



对关键词候选集合中的候选短语按照相似度得分排序,选取相似度得分较高词语作为文本的关键词。
2.2 图构建
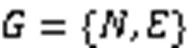

当构建出以聚合后的关键词簇为节点的图后,需要匹配两篇文本中的句子与节点。首先计算每一个句子与每一个节点之间的余弦相似度,匹配句子与相似度最高的节点。其次,为了构建图中各节点之间的边的初始权重,将每个节点匹配的句子拼接为序列表示节点的特征,按式(5)计算每两个节点之间的TF-IDF相似度,确定两节点之间的初始权重。

2.3 编码及GAT训练





训练过程中,需要计算每个节点与它的邻居节点的注意力得分(Attention score),再根据注意力得分融合邻居节点的表示得到该节点的新的表示,使用式(8)计算:
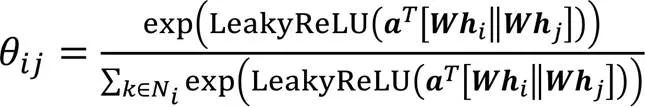


多头注意力机制能够使得特征向量映射到不同的子空间,通过聚合不同子空间的向量能够得到更好的特征向量表示,GAT训练过程如图3所示。

图3 多头注意力GAT训练过程
2.4 分类器
判断文本对是否语义相同或相似是一个二分类任务,文本对通过基于关键词的图表示,将该任务转化为图的二分类任务,经过编码和基于多头注意力机制的GAT训练后得到文本对的向量表示,再将向量送入分类器中,通过多层感知机(Multi-Layer Perceptron, MLP)对向量分类。

3 实验与结果分析
3.1 实验数据集
为了公平且全面地评估基于关键词图表示的长文本去重算法,本文选用了两个公开数据集,分别是CNSE和CNSS[11]。这两个数据集经过相关领域专家的标注,并且被广泛使用于验证去重匹配算法的有效性。其中CNSE数据集中含有29 063对长文本对,被标注是否两篇文本在描述同一新闻事件;CNSS数据集中含有33 503对长文本对,被标注是否两篇文本在描述同一故事。在这两个数据集中,60%的样本作为数据集,20%作为验证集,另外的20%作为测试集。两个数据集的信息如表1所示。
两个数据集中文本的平均词数为734,最大的文本词数为21 791,并且两个数据集中负样本的产生均不是随机产生的,而是选择包含类似关键字的文本对,并排除TF-IDF相似度低于特定阈值的样本,增加了分类的难度。

表1 数据集信息
3.2 对比算法
为了评估基于关键词图表示的长文本去重算法的性能,将本文算法与8种基线算法对比,基线算法主要可以分为以下4类:
1)基于哈希的去重算法。
Simhash算法是一种基于局部敏感哈希(locality sensitive hash)的文本去重算法,通过将高维的特征向量映射为低维的特征向量,比较两个向量的海明距离(Hamming Distance)确定文本是否重复或高度相似。
2)基于词汇语义相似度的算法。
①BM25算法[25]是一种基于概率检索模型提出的算法,用以评价文档之间的相关性。
②LDA模型[26]是一种基于生成式贝叶斯概率模型,通过主题找出文本与文本之间的关系。
3)基于深度学习模型的算法。
①短文本语义匹配SimNet(SimilarityNet)[27]是一种在深度学习框架下进行端到端建模的有监督学习模型。
②DSSM[6]主要通过将两段文本编码为固定长度的向量,再通过两个向量间计算相似度计算两段文本之间的关系。
③C-DSSM[7]是一种通过使用CNN抽取局部信息,再在上层采用最大池化的方式抽取归纳全局信息,判断文本是否相似的算法。
④CIG[11]是一种使用图结构表示文本,对图编码并判断文本是否匹配的算法。
4)基于大规模预训练语言模型的方法。
BERT(Bidirectional Encoder Representations from Transformers)微调[28]是一种基于预训练模型,对它微调生成文本向量,判断文本是否相似的算法。
3.3 评价指标
实验采用通用的二分类评价标准评估算法效果,分别为准确率(Accuracy)和F1值(F1 score),计算公式如下:
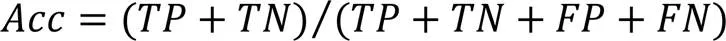
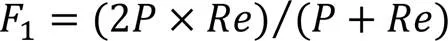
其中:真正例表示将标签为正样本预测为正类的数量;假反例表示将标签为正样本预测为正类的数量;假正例表示将标签为正样本预测为正类的数量;真反例表示将标签为正样本预测为正类的数量;为精确率,代表在所有预测为正的例子中,实际上为正的比例;为召回率,代表在所有实际为正的例子中,预测为正的比例。
3.4 对比实验
表2展示了不同算法在CNSE和CNSS数据集上的实验结果。本文算法在CNSE和CNSS两个数据集上都取得比基线算法更好的结果。相较于基于哈希的去重算法,本文算法在CNSE和CNSS数据集上F1值分别提高了44.6%和53.3%;相较于基于词汇语义相似度的去重算法,本文算法在CNSE和CNSS数据集上F1值分别提高了27.1%~35.6%和28.9%~31.3%;相较于其他基于深度学习模型的去重算法,本文算法在CNSE和CNSS数据集上F1值分别提高了2.3%~74.3%和0.8%~59.9%;相较于基于大规模预训练语言模型的去重算法,本文算法在CNSE和CNSS数据集上F1值分别提高了6.9%和4.2%。从表2中可以看出,传统的去重算法相较于深度学习算法在只利用文本字面信息的情况下去重效果不佳,而本文算法利用文本的语义信息并增强文本之间的信息交互,显著提升去重效果。

表2 CNSE和CNSS数据集上不同算法的实验结果 单位:%
3.5 消融实验
为了验证本文提出的基于关键词图表示的中文长文本去重算法各模块的有效性,本文在CNSS和CNSE两个数据集上进行了消融实验。表3展示了本文算法的消融实验结果。首先,尝试只使用孪生网络或只基于规则编码节点,以验证不同编码方式对文本去重效果的影响,可以看出,基于规则的节点编码方式在CNSE及CNSS数据集上的F1值分别为82.71%和88.52%,均优于孪生网络编码方式的结果(74.22%和80.80%),取得了更好的文本去重效果。其次,验证关键词聚合对文本去重的影响,对节点进行社区检测,即找到网络中联系紧密的部分,将它们聚合为关键词短语簇,这些簇内部联系稠密,簇之间联系稀疏,结果表明对节点聚合会使F1值降低0.4~1.7个百分点,原因是聚合节点会忽略聚合节点之间的关系。最后,验证GAT学习对结果的有效性,结果显示,通过GAT训练能够使F1值提升1.8~7.7个百分点。
注:“Siam”表示通过孪生网络对节点的句子编码,“Sim”表示通过基于特定规则对节点编码,“cd”表示对节点进行社区检测,“GAT”表示使用采用图注意力网络学习节点特征。
3.6 实验结果分析
从表2~3中可以看出,本文算法在这两个数据集上达到的结果优于所有8种基线模型,在两个数据集上F1值达到了84.65%和90.76%,充分说明本文提出的基于关键词图表示的长文本去重算法可以有效提升文本去重即文本相似匹配任务中的表现。相较于另一图表示学习算法CIG,几乎在各环节表现均有所提升。
分析实验结果,可以总结如下:
1)在关键词抽取阶段,引入预训练模型能够在抽取关键词的过程中考虑更多词语的语义信息,从而更好地表示文本整体的语义信息,同时后期采用关注词汇的编码方式能够更有效地利用关键词中的信息,从而达到更佳的实验效果。
2)相较于其他表示文本的方式,通过图表示文本对能够达到更好的效果。将两篇文本表示为一张图,避免了独立对两篇文本处理,融入了两篇文本的交互信息。同时引入GAT多头注意力网络显著提高了模型的效果,这是因为经过GAT网络学习,考虑了图的拓扑信息,使得模型捕捉每个节点与邻居节点之间的交互关系。
3)当文本长度较大时,传统的去重方法的效果较差,它们很难获得合适的上下文向量表示匹配,文本中距离较远的句子也很难进行信息交互。通过以关键词为节点并通过关键词之间的共现关系将文本对表示成图,能够有效联系长文本中距离较远的句子,从而交互语义信息,克服文本长度带来的困难,因此能够取得较好的效果。
4)本文算法在使用Sim编码特征时的效果(82.71%和88.52%)优于使用Siam编码特征的效果(74.22%和80.80%),这是因为使用孪生网络的优点是增强两段文本之间的信息交互,而本文通过将文本对表示成图已经能够对文本中的句子进行信息交互,所以收益较小。
4 结语
针对语义去重问题,提出了一种基于关键词图表示的语义去重算法,引入预训练模型抽取出关键词并构建基于关键词的图表示,将长文本去重任务转化为文本对图分类任务,引入多种方法对节点的特征编码,通过图表示学习的方式学习求解。同时,引入多头注意力图神经网络学习抽取图节点特征,注意力机制使得模型能够捕获节点之间的权重关系,增强了节点之间的信息交互。通过在CNSE和CNSS两个公开数据集上进行了实验,实验结果表明本文算法取得了出色的表现。本文提出的基于关键词图表示的中文长文本去重算法充分展现了算法的优越性与可行性。
基于关键词图表示的语义去重算法在实验中表现出了较好的性能,但是时间复杂度较高,关键词抽取阶段和图网络训练阶段消耗时间较长;此外,长文本结构信息未能被完全有效地利用。后续工作中,将考虑如何提升模型效率,降低算法的时间复杂度,同时将其他文本结构信息融合到网络表示中,以提升去重算法的效率与表现。
[1] CHARIKAR M. Similarity estimation techniques from rounding algorithms[C]// Proceedings of the 34th ACM Symposium on Theory of Computing. New York: ACM, 2002:380-388.
[2] 王诚,王宇成. 基于Simhash的大规模文档去重改进算法研究[J]. 计算机技术与发展, 2019, 29(2):115-119.(WANG C, WANG Y C. Research on improved large-scale documents deduplication algorithm based on Simhash[J]. Computer Technology and Development, 2019, 29(2):115-119.)
[3] BRODER A Z. On the Resemblance and containment of documents[C]// Proceedings of the 1997 International Conference on Compression and Complexity of Sequences. Piscataway: IEEE, 1997: 21-29.
[4] INDYK P, MOTWANI R. Approximate nearest neighbors: towards removing the curse of dimensionality[C]// Proceedings of the 30th ACM Symposium on Theory of Computing. New York: ACM, 1998:604-613.
[5] APPLEBY A. MurmurHash[EB/OL]. (2011-03-01) [2022-08-22].https://sites.google.com/site/murmurhash.
[6] HUANG P S, HE X, GAO J, et al. Learning deep structured semantic models for Web search using clickthrough data[C]// Proceedings of the 22nd ACM International Conference on Information and Knowledge Management. New York: ACM, 2013:2333-2338.
[7] SHEN Y, HE X, GAO J, et al. A latent semantic model with convolutional-pooling structure for information retrieval[C]// Proceedings of the 23rd ACM International Conference on Information and Knowledge Management. New York: ACM, 2014:101-110.
[8] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL]. (2013-09-07) [2022-08-22].https://arxiv.org/pdf/1301.3781.pdf.
[9] VELIČKOVIĆ P, CUCURULL G, CASANOVA A, et al. Graph attention networks[EB/OL]. (2018-02-04) [2022-08-22].https://arxiv.org/pdf/1710.10903.pdf.
[10] ZHANG T, LIU B, NIU D, et al. Multiresolution graph attention networks for relevance matching[C]// Proceedings of the 27th ACM International Conference on Information and Knowledge Management. New York: ACM, 2018:933-942.
[11] LIU B, NIU D, WEI H, et al. Matching article pairs with graphical decomposition and convolutions[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2019: 6284-6294.
[12] 彭双和,图尔贡·麦提萨比尔,周巧凤. 基于Simhash的中文文本去重技术研究[J]. 计算机技术与发展, 2017, 27(11):137-140, 145.(PENG S H, MAITISABIER T, ZHOU Q F. Research on deduplication technique of Chinese text with Simhash[J]. Computer Technology and Development, 2017, 27(11):137-140, 145.)
[13] 张亚男,陈卫卫,付印金,等. 基于Simhash改进的文本去重算法[J]. 计算机技术与发展, 2022, 32(8):26-32.(ZHANG Y N, CHEN W W, FU Y J, et al. Improved text deduplication algorithm based on Simhash[J]. Computer Technology and Development, 2022, 32(8): 26-32.)
[14] SUN Y, QIU H, ZHENG Y, et al. SIFRank: a new baseline for unsupervised keyphrase extraction based on pre-trained language model[J]. IEEE Access, 2020, 8:10896-10906.
[15] YE J, GUI T, LUO Y, et al. One2Set: generating diverse keyphrases as a set[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, PA: ACL, 2021:4598-4608.
[16] BARUNI J S, SATHIASEELAN J G R. Keyphrase extraction from document using RAKE and TextRank algorithms[J]. International Journal of Computer Science and Mobile Computing, 2020, 9(9):83-93.
[17] CHO T, LEE J H. Latent keyphrase extraction using LDA model[J]. Journal of Korean Institute of Intelligent Systems, 2015, 25(2):180-185.
[18] 朱泽德,李淼,张健,等. 一种基于LDA模型的关键词抽取方法[J]. 中南大学学报(自然科学版), 2015, 46(6):2142-2148.(ZHU Z D, LI M, ZHANG J, et al. A LDA-based approach to keyphrase extraction[J]. Journal of Central South University (Science and Technology), 2015, 46(6):2142-2148.)
[19] DING L, ZHANG Z, LIU H, et al. Automatic keyphrase extraction from scientific Chinese medical abstracts based on character-level sequence labeling[J]. Journal of Data and Information Science, 2021, 6(3):35-57.
[20] HAMILTON W L, YING R, LESKOVEC J. Representation learning on graphs: methods and applications[J]. Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, 2017, 40(3):52-74.
[21] KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL]. (2017-02-22) [2022-08-22].https://arxiv.org/pdf/1609.02907.pdf.
[22] PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations[C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Stroudsburg, PA: ACL, 2018:2227-2237.
[23] CHE W, LIU Y, WANG Y, et al. Towards better UD parsing: deep contextualized word embeddings, ensemble, and treebank concatenation[C]// Proceedings of the CoNLL 2018 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies. Stroudsburg, PA: ACL, 2018:55-64.
[24] ARORA S, LIANG Y, MA T. A simple but tough-to-beat baseline for sentence embeddings[EB/OL] (2022-07-22) [2022-08-22].https://openreview.net/pdf?id=SyK00v5xx.
[25] 陈乐乐,黄松,孙金磊,等. 基于BM25算法的问题报告质量检测方法[J]. 清华大学学报(自然科学版), 2020, 60(10):829-836.(CHEN L L, HUANG S, SUN J L, et al. Bug report quality detection based on the BM25 algorithm[J]. Journal of Tsinghua University (Science and Technology), 2020, 60(10): 829-836.)
[26] BLEI D M, NG A Y, JORDAN M I. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3:993-1022.
[27] ZHENG C, SUN Y, WAN S, et al. RLTM: an efficient neural IR framework for long documents[C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2020:5457-5463.
[28] DEVLIN J, CHANG W M, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: ACL, 2019:4171-4186.
Text semantic de-duplication algorithm based on keyword graph representation
WANG Jinyun, XIANG Yang*
(,,201804,)
There are a large number of redundant texts with the same or similar semantics in the network. Text de-duplication can solve the problem that redundant texts waste storage space and can reduce unnecessary consumption for information extraction tasks. Traditional text de-duplication algorithms rely on literal overlapping information, and do not make use of the semantic information of texts; at the same time, they cannot capture the interaction information between sentences that are far away from each other in long text, so that the de-duplication effect of these methods is not ideal. Aiming at the problem of text semantic de-duplication, a long text de-duplication algorithm based on keyword graph representation was proposed. Firstly, the text pair was represented as a graph with the keyword phrase as the vertex by extracting the semantic keyword phrase from the text pair. Secondly, the nodes were encoded in various ways, and Graph Attention Network (GAT) was used to learn the relationship between nodes to obtain the vector representation of text to the graph, and judge whether the text pairs were semantically similar. Finally, the de-duplication processing was performed according to the text pair’s semantical similarity. Compared with the traditional methods, this method can use the semantic information of texts effectively, and through the graph structure, the method can connect the distant sentences in the long text by the co-occurrence relationship of keyword phrases to increase the semantic interaction between different sentences. Experimental results show that the proposed algorithm performs better than the traditional algorithms, such as Simhash, BERT (Bidirectional Encoder Representations from Transformers) fine-tuning and Concept Interaction Graph (CIG), on both CNSE (Chinese News Same Event) and CNSS (Chinese News Same Story) datasets. Specifically, the F1 score of the proposed algorithm on CNSE dataset is 84.65%, and that on CNSS dataset reaches 90.76%. The above indicates that the proposed algorithm can improve the effect of text de-duplication tasks effectively.
text semantic de-duplication; keyword extraction; text matching; graph representation; Graph Attention Network (GAT)
This work is partially supported by National Natural Science Foundation of China (72071145).
WANG Jinyun, born in 1998, M. S. candidate. His research interests include natural language processing, machine learning, big data.
XIANG Yang, born in 1962, Ph.D., professor. His research interests include natural language processing, data mining, knowledge graph.
1001-9081(2023)10-3070-07
10.11772/j.issn.1001-9081.2022101495
2022⁃10⁃12;
2022⁃11⁃29;
国家自然科学基金资助项目(72071145)。
汪锦云(1998—),男,江西上饶人,硕士研究生,主要研究方向:自然语言处理、机器学习、大数据; 向阳(1962—),男,上海人,教授,博士,CCF高级会员,主要研究方向:自然语言处理、数据挖掘、知识图谱。
TP391.1
A
2022⁃12⁃02。
