基于多级跳跃残差组的运动人像去模糊网络
2023-10-21纪佳奇卢振坤熊福棚张甜杨豪
纪佳奇,卢振坤,熊福棚,张甜,杨豪
基于多级跳跃残差组的运动人像去模糊网络
纪佳奇,卢振坤*,熊福棚,张甜,杨豪
(广西民族大学 电子信息学院,南宁 530006)( ∗ 通信作者电子邮箱lzk06@sina.com)
为解决复原后的运动模糊人像图像的轮廓模糊、细节丢失等问题,提出了基于多级跳跃残差组生成对抗网络(GAN)的运动人像去模糊方法。首先,改进残差块以构造多级跳跃残差组模块,并改进PatchGAN的结构以使GAN能够更好地结合各层的图像特征;其次,使用多损失融合的方法优化网络,从而增强重建后图像的真实纹理;最后,采用端到端的模式将运动模糊的人像图像进行盲去模糊操作,并输出清晰的人像图像。在CelebA数据集上的实验结果表明,相较于DeblurGAN(Deblur GAN)、尺度循环网络(SRN)和MSRAN(Multi-Scale Recurrent Attention Network)等基于卷积神经网络(CNN)的方法,所提方法的峰值信噪比(PSNR)和结构相似度(SSIM)分别至少提高了0.46 dB和0.05;同时,所提方法的模型参数更少,修复速度更快,且复原后的人像图像具有更多的纹理细节。
图像去模糊;盲去模糊;生成对抗网络;多级跳跃残差组;多损失融合
0 引言
拍摄人像图像时容易产生运动模糊,主要原因是在相机的短曝光时间内,相机与拍照对象产生了相对运动。单幅运动图像去模糊问题是指在给定一幅运动模糊图像的情况下,估计未知的清晰图像。图像去模糊问题分为两种类型:盲去模糊和非盲去模糊。早期的方法主要是非盲去模糊,即假设模糊系数已知,采用Lucy-Richardson算法[1]、Wiener或Tikhonow滤波器等进行去卷积操作,但是实际情况中模糊图像的模糊核通常是未知的。自Fergus等[2]研究成功,许多方法被相继提出。Pan等[3]采用暗通道检验的模糊核估计方法,提出了L0正则化项,以最小化恢复图像的暗通道。该方法在一般的自然图像上表现良好,但不适用于特殊的场景,如文本图像、人像图像和低光照图像。Li等[4]采用数据驱动先验方式,提出了一种基于半二次方分裂法和梯度下降算法的高效数值算法,在计算过程中可以快速收敛,并且可以应用在不同的场景中。Levin等[5]采用超拉普拉斯先验建模图像的梯度估计模糊核,但该方法仅适合求解一维的模糊核。除了以上几种方法,还有使用稀疏核先验[6]、正则化稀疏先验[7]等方法进行图像去模糊操作;但是传统方法存在模糊核的估计准确度不高、图像修复质量差、去模糊位置不准确等缺点,导致成像图像质量不高。
近年来,基于卷积神经网络(Convolutional Neural Network, CNN)的方法在计算机视觉领域得到了广泛的应用。基于深度学习的运动图像去模糊方法,借助神经网络强大的特征学习能力,能够更好地抓取图像特征,提高去模糊效果,修缮图像纹理细节,展现出良好的图像复原效果。Xu等[8]引入一种新颖的、可分离结构的卷积结构进行反卷积,它使网络具有更强的表现力,可以映射到更高的维度以适应非线性特征,并取得了比图像先验更好的复原效果。Sun等[9]使用CNN估计模糊系数,再使用马尔可夫随机场,将基于patch的估计融合到运动核的密集域中。Gong等[10]使用完全卷积网络(Fully Convolutional Network, FCN)估计运动流,并据此进行图形去模糊,得到清晰图像。Nah等[11]使用一种端到端的多尺度神经网络,遵循传统的“由粗到细”的网络框架恢复模糊图像。网络的输入和输出都采用高斯金字塔形式,同时提出了多尺度损失函数,更好地优化处理模糊图像中的不同层次特征,但它的结构复杂,收敛较慢。Kupyn等[12]提出去模糊网络DeblurGAN(Deblur Generation Adversarial Network),使用端到端的基于条件性的生成对抗网络(Generative Adversarial Network, GAN)和内容损失的学习方法。对抗网络通过学习图像的图形结构特征,在运动模糊图像上取得了较好的视觉观感和感知保真度,但是在处理小尺寸的模糊图像时,容易出现振铃效果。Tao等[13]利用“由粗到细”的方法,在单幅去模糊图像中使用尺度循环网络(Scale-Recurrent Network, SRN)还原图像;但是该方法在还原模糊人像时,人像边缘细节容易模糊不清。Wu等[14]结合“由粗到细”和“堆叠”这两种结构,解决了原本“由粗到细”架构用于人脸去模糊时,模型难训练、参数计算量大等问题,但该方法在人像的纹理细节部分修复效果较差。陈贵强等[15]使用半监督的方式,在不需要训练大量成对图像的基础上,将视频监控下的模糊人像图像恢复成清晰人像图像;但是由于缺少先验知识,在人像图像过于模糊时,人像轮廓难以恢复。欧阳宁等[16]在GAN的基础上,使用形变卷积模块和通道注意力模块组成的自适应残差块,有效去除图像的运动模糊,但对于结构较为复杂的人像图像复原效果较差。魏海云等[17]针对运动模糊图像引入带有注意力机制的残差块,加入空间金字塔池化,复原非均匀模糊图像。刘万军等[18]在多尺度网络中使用跨尺度网络权值共享并融合DenseNet,减少模型参数,提高网络的稳定性。王向军等[19]提出MSRAN(Multi-Scale Recurrent Attention Network),在SRN的基础上,使用深度可分离卷积,改进注意力机制模块,并对卷积层密集连接,提高网络特征参数的利用率;虽然该网络带来了良好的模糊图像修复效果,但是网络较为庞大,训练测试速度较慢。Zhang等[20]提出一种深度堆叠的多尺度补丁网络(Deep Multi-Patch Hierarchical Network, DMPHN),打破了简单堆叠网络深度而不能提升性能的限制,在不同层输入具有相同分辨率,采用较小的滤波器尺寸提高网络的计算速度。李福海等[21]提出一种梯度信息联合GAN的去模糊方法,该方法的生成网络使用特征金字塔网络(Feature Pyramid Network, FPN)和梯度分支获取多尺度特征和更小的局部特征,再联合梯度信息和FPN重建图像的高频信息。虞志军等[22]提出一种增强多尺度特征网络,该网络使用多分支不同大小的卷积核扩大感受野,使用跳跃连接跨阶进行特种融合,解决了多尺度图像特征提取利用不充分和深层网络信息丢失的问题。王晨卿等[23]提出一种多尺度条件下的GAN,该网络使用一种多尺度残差块,在单个块内构建分级连接和增加不同感受野分支,以提高多尺度残差模块的特征提取能力。魏丙财等[24]针对拍摄过程中的运动抖动、电子干扰导致的图像模糊问题,提出了一种基于深度残差的GAN,并通过改进PatchGAN[25],将底层感受野提高了两倍,但是该方法在人像细节部位恢复上仍存在不足。
针对上述问题,本文改进GAN,提出了一种端到端基于多级跳跃残差组生成对抗网络的运动人像去模糊方法。利用GAN强大的学习图形结构能力和保留图像纹理细节的能力,本文方法的生成网络使用改进残差块(Residual Block)和多级跳转连接[26]组成的多级跳跃残差组模块学习图像的多层特征,使网络更加稳定,细节处理更加完善,输出清晰人像图像,判别网络使用改进的PatchGAN结构进行判别。相较于DeblurGAN[12],本文方法的参数更少、速度更快,模糊人像修复效果更好。
1 相关工作
1.1 人像图像的模糊
人像去模糊的目的是从所获得的模糊人像图像中恢复清晰人像。模糊人像图像的生成过程通常可以表示为以下数学模型[19]:
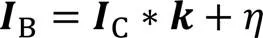
1.2 生成对抗网络
作为深度学习领域研究的重点,各式各样的GAN层出不穷,如DeblurGAN、SRGAN(Super-Resolution GAN)、ESRGAN(Enhanced SRGAN)等。根据文献[27],本文方法在生成网络和判别网络的对抗训练中生成真实的去模糊人像图像。判别网络使用PatchGAN的方式,交替与生成网络一起优化[26],以解决对抗性最小最大问题,公式如下:

其中:为数据分布;是随机噪声分布;、表示输入的真实数据和随机噪声。在GAN中,训练G的目标是尽量生成真实图像,以欺骗D;而D的目标是区分G生成图像与真实图像。本文方法的流程如图1所示。
2 本文方法
2.1 生成网络
结构复杂的网络可能难以训练,但是复杂的映射关系可能大幅提升网络的性能。为了使更深层次的网络表现得更好,本文使用批量标准化(Batch Normalization, BN)消除中间层数据分布发生改变的问题,保留BN层可以帮助网络加快学习速度、解决梯度消失的问题,保证网络的稳定性。本文方法的生成网络部分如图2所示,网络由3部分组成:浅层特征提取模块、多级跳跃残差组模块和特征重建模块。生成网络的核心部分由具有相同布局的个残差组构成。受文献[28-29]的启发,使用2个卷积层(Conv)、1个BN层和2个整流线性单元(Rectified Linear Unit, ReLU)作为激活函数改进残差块。
为了进一步提高本文方法的恢复图像质量,设计一个多级跳跃残差组模块,代替原本生成网络中的残差块。多级跳跃残差组模块由3个改进残差块、1个3×3的卷积层和多级跳跃连接组成,激活函数使用ReLU。多级跳跃连接可以有效地将图像原始特征信息传给更深层次,进行跨层有效学习,最后将原始特征和深度残差特征以对应元素相加的方式融合。
特征重建模块使用两个3×3的卷积层、一个9×9的卷积层和ReLU,激活函数使用tanh。特征重建模块能够重建残差组的深层次特征,并结合全局跳跃连接生成去模糊图像。在图2中,卷积操作时的步长大小为1。
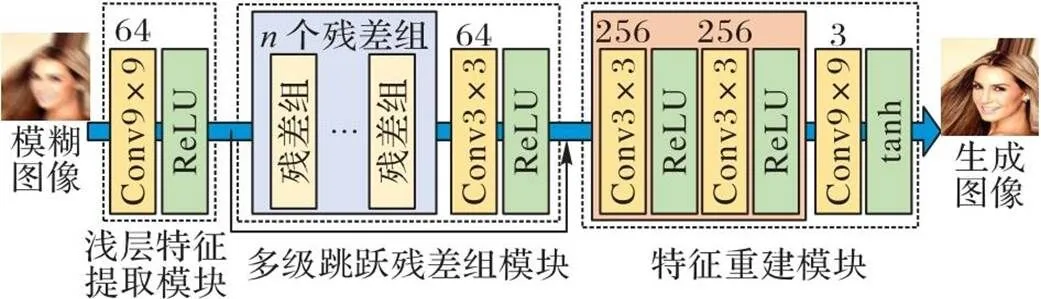
图2 生成网络结构
2.2 判别网络
本文在判别网络中使用PatchGAN方式。普通GAN的判别网络是将输入映射成一个实数,即输入样本为真样本的概率;而PatchGAN将输入映射为×的矩阵,X,j的值表示每个patch为真实样本的概率,将X,j求平均值,即为判别网络最终输出。PatchGAN的X,j对应判别网络输入图像的一小块的判别输出,它的感受域对应输入图像的一小块区域,可以充分考虑图像不同部分的影响,在模糊人像的修复上,可以更关注图像的细节。如表1所示,判别网络中含有8个卷积层,卷积核大小都设置为3×3,每一层卷积后都加入非线性激活函数LeakyReLU(负斜率=0.2),避免整个网络最大池化。判别网络的过滤器(filter)数从64增长到1 024,特征数量每增加一倍时,就使用步长为2的卷积层使图像分辨率降低为原本的1/2。输入人像图像默认设置大小为256×256×3,PatchGAN通过8层卷积层的叠加,将16×16×1作为最终的判别矩阵的大小。

表1 判别网络模型参数
2.3 改进的残差结构
残差网络(Residual Network)[30]很好地解决了网络层数过深导致的训练难度大、梯度消失和梯度爆炸等问题,引入残差网络可以训练更深的网络结构。

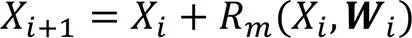
图3为多级跳跃残差组和改进残差块。通过实验可知,BN层可以有效解决梯度消失问题,但改进残差块用于模糊人像修复时,模糊人像图像尺寸较小,采用大小为2的小批量训练模型,因此改进残差块包括1个BN层,2个3×3卷积核的卷积层,2个ReLU激活函数,这样可以加快收敛,使得网络训练更加灵活。最后使用一个跳跃连接,在一定程度上解决梯度消失带来的问题。

图3 多级跳跃残差组结构
2.4 损失函数
本文使用和文献[12,28-29]中同样预训练的VGG19。图4为VGG19不同层的特征图对比,对比不同层的图像特征信息可以看出,激活前的特征图包含了更多的信息。

图4 VGG19不同层激活前后特征图对比

对抗损失的计算方式如下:

感知损失侧重修复图像的一般内容[32],能保持图像的感知保真度,使生成图像与清晰图像的内容和全局结构更加接近。感知损失计算方式如下:

3 实验与结果分析
3.1 实验数据及实验参数
实验使用CelebA数据集[34]进行训练测试。CelebA是一个大规模的人脸属性数据集,包含20多万张名人图像,每张图像有40个属性注释,该数据集中的图像涵盖了较大的姿势变化和背景变化。CelebA的图像种类多、数量多、注释丰富,包括10 177个身份、202 599张人脸图像和5个地标位置,每张图像有40个二进制属性注释。本文将180 000张人像图像用于训练,22 599张用于性能评估,图像的大小为178×218,训练时将RGB图像大小重新设置为256×256。模糊数据集采用3×3的高斯模糊进行处理,运动模糊数据集采用getRotationMatrix2D函数,生成旋转中心和旋转角度为20°以内的任意整数的旋转变化矩阵,再通过warpAffine方法进行仿射变换,模拟真实场景中不同程度的图像运动模糊。实验分两组,一组还原处理3×3的高斯模糊人像图像,另一组还原处理旋转中心和旋转角度均为20°的人像运动模糊图像。
为了验证真实场景中对模糊的人像图像的处理效果,本文采用GoPro数据集。GoPro数据集包括3 214张大小为1 280×720的模糊图像,其中2 103张是训练图像,1 111张是测试图像。该数据集由一一对应的真实模糊图像与ground truth图像组成,均由高速摄像机拍摄。

3.2 评价指标
为了验证本文方法在运动人像去模糊上的有效性,在相同条件下进行了大量实验。采用峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)和结构相似性(Structural SIMilarity, SSIM)作为评价指标。PSNR和SSIM的公式如下:


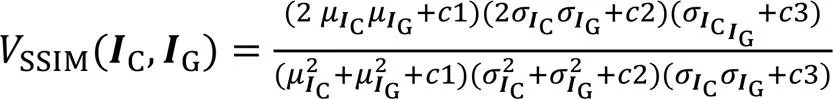

3.3 消融实验
3.3.1VGG19不同卷积层去模糊效果对比
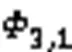

表2 VGG19不同卷积层的去模糊效果对比
3.3.2不同损失函数组合
在CelebA数据集上,对不同损失函数的去模糊效果进行了实验,结果如表3、图5所示。可以看出,只使用对抗损失和感知损失作为损失函数得到的性能指标较低,使用对抗损失和感知损失融合的损失函数得到的结果最好。

表3 不同损失函数的消融实验结果

图5 不同损失函数的去模糊结果
3.4 实验结果与分析
3.4.1不同数量残差块去模糊效果对比
为了探究不同残差块数组成的多级跳跃残差组对去模糊效果的影响,分别在不同残差块数下进行实验,结果如表4、图6所示。每组残差块的最后加入了一个卷积核为3×3、通道数为64的卷积层,激活函数使用ReLU。当残差块数为1时,本文方法能基本还原人像的轮廓信息,但是色准偏差较大;通过增加每个残差组中残差块的数量后,当残差块数为3时,得到了视觉效果最佳的人像修复效果。由表4可知,相较于每个多级跳跃残差组使用1个和2个残差块,使用3个残差块的PSNR分别提升了2.36 dB和1.98 dB,SSIM分别提升了0.19和0.12。综上可知,随着每个多级跳跃残差组中的残差块数的增多,本文方法在运动人像去模糊方面拥有更好的色准还原能力和更强的图像高频细节修复能力;但考虑模型计算量,为了高效快速地去除运动模糊人像,以下实验均使用3个残差块。
3.4.2CelebA数据集上效果验证
为了验证本文方法的有效性和鲁棒性,以在CelebA数据集上的平均PSNR和平均SSIM作为定量评价指标,分别进行人像图像高斯模糊去除和运动模糊去除对比实验,与模糊去除的典型方法Multi-scale CNN[11]、DeblurGAN[12]、SRN[13]、MSRAN[19]和DMPHN[20]进行定量比较,其中DeblurGAN同样使用GAN,实验结果如表5~6所示。

表4 不同数量的残差块性能分析

图6 不同残差块数情况下的去模糊结果
从表5可知,本文方法在CelebA数据集上取得了最佳的PSNR和SSIM值,相较于DeblurGAN和DMPHN,分别提高了4.29 dB、0.09和0.58 dB、0.03。其中,本文的生成网络模型比DeblurGAN的生成网络模型参数量减少了74.33%。

表5 不同方法去除人像高斯模糊性能的定量比较结果
图7为不同方法对模糊人像去模糊效果对比。其中:基于GAN的DeblurGAN对模糊图像的修复效果有限,在人像的边缘和细节部分,存在较大的失真现象,图像边缘存在粘连的情况,图像整体修复效果不佳;SRN、MSRAN和DMPHN均采用多尺度循环网络的方式对图像去模糊,整体成像效果较接近,并且比DeblurGAN的人像修复效果更好,修复的图像整体相对平滑;本文方法修复的人像图像较其他对比方法,在纹理方面细节更加丰富,能清楚地还原发丝的轮廓和细节,并且人物和背景之间的虚化更加自然。

图7 不同方法在CelebA数据集上对高斯模糊人像的去模糊结果对比
表6给出了针对人像图像去除运动模糊的对比实验结果。相较于同样使用GAN的DeblurGAN,本文方法在PSNR和SSIM值上分别提高了1.95 dB、0.09。与使用多尺度的SRN和MSRAN相比,分别提高了2.42 dB、0.10和0.46 dB、0.05。与DMPHN相比,分别提高了1.35 dB、0.07,但是DMPHN的修复速度更高。其中,本文方法的单张图像的修复时间相较于DeblurGAN减少了8.25%。

表6 不同方法去除人像运动模糊性能的定量比较结果
图8为不同方法对运动模糊人像去模糊的结果。在去除运动模糊后,DeblurGAN修复图像的效果有限,依旧存在失真现象。图8(c)~(d)、(f)都具有一定的去模糊效果,但是在边缘细节部分存在模糊、噪点较多的问题。本文方法修复的图像较其他对比方法具有更清晰的边缘。

图8 不同方法在CelebA数据集上对运动模糊人像的去模糊结果对比
由以上实验结果可以看出,本文方法在人像的高斯模糊去除和运动模糊去除上均取得了不错的成绩。本文方法对CelebA数据集上的图像复原质量更高、时间更短,在较少的生成网络参数基础上,实现更好的人像的纹理细节修复效果,修复后的人像图像人眼视觉观感更佳。
3.4.3GoPro数据集上效果验证
为了验证本文方法在真实场景的去模糊效果,采用GoPro数据集测试,并与典型模糊去除方法Multi-scale CNN、DeblurGAN、SRN、MSRAN和DMPHN进行定量比较,评价指标采用PSNR和SSIM,结果如表7所示。DMPHN取得了最高的PSNR值,比本文方法高0.03 dB;但在SSIM指标上,本文方法取得最佳数值,相较于DMPHN提高了0.2。相较于同样使用生成对抗网络的DeblurGAN,本文方法的PSNR和SSIM数值分别提高了2.23 dB、0.07。
图9为不同方法在GoPro数据集上对运动模糊图像的去模糊结果对比。在人像修复方面,DeblurGAN在去模糊时,偏向于较高锐化度,导致人像部分修复细节不足;SRN与MSRAN的修复效果相较于DeblurGAN有所改善,但存在噪点和色差;本文方法在修复人像时,能减少噪点的影响并准确还原颜色。但是,在标牌图的去模糊结果中,DeblurGAN的高锐化度带来了更好的识别效果,MSRAN能够还原字母的边缘轮廓,表明MSRAN在文字修复上效果最好,文字轮廓更清晰。本文方法在人像方面修复效果优于其他对比方法,颜色还原更为准确,轮廓较为清晰;但由于本文方法是在人像数据集上训练,所以在标识牌的修复效果上稍弱于MSRAN。综上,实验结果验证了本文方法在人像去模糊上的有效性和鲁棒性。

表7 不同方法在GoPro数据集上的去模糊效果实验结果对比

图9 不同方法在GoPro数据集上对运动模糊图像的去模糊结果对比
4 结语
本文针对运动人像图像去模糊问题,提出了一种基于多级跳跃残差组生成对抗网络的运动人像去模糊方法。本文方法采用端到端的模式,在生成网络中构造由改进的残差块组成的多级跳跃残差组模块,充分利用神经网络中各层的数据,得到更多图像特征,实现了精度更高的人像运动模糊复原。与DeblurGAN相比,本文方法提高了模糊人像图像的还原质量,同时减少了修复图像的修复时间和生成网络的参数量。实验结果表明,在不同模糊程度的人像图像上,本文方法均取得了良好的图像还原效果,修复的人像图像轮廓层次更加鲜明,纹理细节更加丰富。然而,由于对抗网络训练的不稳定性,本文方法对一些结构较为丰富的人像图像的恢复效果不是很理想,在人像图像的边缘与背景交界部分依旧存在噪点。未来的工作将集中于上述问题,并通过寻找新的方法改善缺点。
[1] WHITE R L. Image restoration using the damped Richardson-Lucy method[C]// Proceedings of the SPIE 2198, Instrumentation in Astronomy Ⅷ. Bellingham, WA: SPIE, 1994: 1342-1348.
[2] FERGUS R, SINGH B, HERTZMANN A, et al. Removing camera shake from a single photograph[M]// ACM SIGGRAPH 2006 Papers. New York: ACM, 2006: 787-794.
[3] PAN J, SUN D, PFISTER H, et al. Blind image deblurring using dark channel prior[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1628-1636.
[4] LI L, PAN J, LAI W S, et al. Learning a discriminative prior for blind image deblurring[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 6616-6625.
[5] LEVIN A. Blind motion deblurring using image statistics[C]// Proceedings of the 19th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2006: 841-848.
[6] YUAN X, ZHU J, LI X. Blur kernel estimation by structure sparse prior[J]. Applied Sciences, 2020, 10(2): No.657.
[7] LIU S, FENG Y, ZHANG S, et al.0sparse regularization-based image blind deblurring approach for solid waste image restoration[J]. IEEE Transactions on Industrial Electronics, 2019, 66(12): 9837-9845.
[8] XU L, REN J S J, LIU C, et al. Deep convolutional neural network for image deconvolution[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems — Volume 1. Cambridge: MIT Press, 2014: 1790-1798.
[9] SUN J, CAO W, XU Z, et al. Learning a convolutional neural network for non-uniform motion blur removal[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 769-777.
[10] GONG D, YANG J, LIU L, et al. From motion blur to motion flow: a deep learning solution for removing heterogeneous motion blur[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 3806-3815.
[11] NAH S, KIM T H, LEE K M. Deep multi-scale convolutional neural network for dynamic scene deblurring[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 257-265.
[12] KUPYN O, BUDZAN V, MYKHAILYCH M, et al. DeblurGAN: blind motion deblurring using conditional adversarial networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8183-8192.
[13] TAO X, GAO H, SHEN X, et al. Scale-recurrent network for deep image deblurring[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8174-8182.
[14] WU Y, HONG C, ZHANG X, et al. Stack-based scale-recurrent network for face image deblurring[J]. Neural Processing Letters, 2021, 53(6): 4419-4436.
[15] 陈贵强,何军,罗顺茺. 基于改进CycleGAN的视频监控人脸超分辨率恢复算法[J]. 计算机应用研究, 2021, 38(10):3172-3176.(CHEN G Q, HE J, LUO S C. Improved video surveillance face super-resolution recovery algorithm based on CycleGAN[J]. Application Research of Computers, 2021, 38(10):3172-3176.)
[16] 欧阳宁,邓超阳,林乐平. 基于自适应残差的运动图像去模糊[J]. 计算机工程与设计, 2021, 42(6):1684-1690.(OUYANG N, DENG C Y, LIN L P. Motion image deblurring based on adaptive residuals[J]. Computer Engineering and Design, 2021, 42(6): 1684-1690.)
[17] 魏海云,郑茜颖,俞金玲. 基于多尺度网络的运动模糊图像复原算法[J]. 计算机应用, 2022, 42(9): 2838-2844.(WEI H Y, ZHENG Q Y, YU J L. Motion blurred image restoration algorithm based on multi-scale network[J]. Journal of Computer Applications, 2022, 42(9): 2838-2844.)
[18] 刘万军,张正寰,曲海成. 融合DenseNet的多尺度图像去模糊模型[J]. 计算机工程与应用, 2021, 57(24): 219-226.(LIU W J, ZHANG Z H, QU H C. Multi-scale image deblurring model with DenseNet[J]. Computer Engineering and Applications, 2021, 57(24):219-226.)
[19] 王向军,欧阳文森. 多尺度循环注意力网络运动模糊图像复原方法[J]. 红外与激光工程, 2022, 51(6): No.20210605.(WANG X J, OUYANG W S. Multi-scale recurrent attention network for image motion deblurring[J]. Infrared and Laser Engineering, 2022, 51(6): No.20210605.)
[20] ZHANG H, DAI Y, LI H, et al. Deep stacked hierarchical multi-patch network for image deblurring[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 5971-5979.
[21] 李福海,蒋慕蓉,杨磊,等. 基于生成对抗网络的梯度引导太阳斑点图像去模糊方法[J]. 计算机应用, 2021, 41(11):3345-3352.(LI F H, JIANG M R, YANG L, et al. Solar speckle image deblurring method with gradient guidance based on generative adversarial network[J]. Journal of Computer Applications, 2021, 41(11): 3345-3352.)
[22] 虞志军,王国栋,张镡月. 基于增强多尺度特征网络的图像去模糊[J]. 激光与光电子学进展, 2022, 59(22): No.2215007.(YU Z J, WANG G D, ZHANG X Y. Image deblurring based on enhanced multi-scale feature network[J]. Laser and Optoelectronics Progress, 2022, 59(22): No.2215007.)
[23] 王晨卿,荆涛,刘云鹏,等. 基于多尺度条件生成对抗网络的图像去模糊[J]. 计算机工程与设计, 2022, 43(4):1074-1082.(WANG C Q, JIN T, LIU Y P, et al. Image deblurring based on multi-scale conditional generative adversarial network[J]. Computer Engineering and Design, 2022, 43(4):1074-1082.)
[24] 魏丙财,张立晔,孟晓亮,等. 基于深度残差生成对抗网络的运动图像去模糊[J]. 液晶与显示, 2021, 36(12): 1693-1701.(WEI B C, ZHANG L Y, MENG X L, et al. Motion image deblurring based on depth residual generative adversarial network[J]. Chinese Journal of Liquid Crystals and Displays, 2021, 36(12): 1693-1701.)
[25] LI C, WAND M. Precomputed real-time texture synthesis with Markovian generative adversarial networks[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9907. Cham: Springer, 2016: 702-716.
[26] SCHULER C J, HIRSCH M, HARMELING S, et al. Learning to deblur[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(7): 1439-1451.
[27] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems — Volume 2. Cambridge: MIT Press, 2014: 2672-2680.
[28] LEDIG C, THEIS L, HUSZÁR F, et al. Photo-realistic single image super-resolution using a generative adversarial network[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 105-114.
[29] WANG X, YU K, WU S, et al. ESRGAN: enhanced super-resolution generative adversarial networks[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11133. Cham: Springer, 2019: 63-79.
[30] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
[31] JOHNSON J, ALAHI A, LI F F. Perceptual losses for real-time style transfer and super-resolution[C]// Proceedings of the 2016 European Conference on Computer Vision. Berlin: Springer, 2016: 694-711.
[32] ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5967-5976.
[33] DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2009: 248-255.
[34] LIU Z, LUO P, WANG X, et al. Large-scale CelebFaces attributes (CelebA) dataset[DS/OL]. [2022-06-14].http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html.
[35] KINGMA D P, BA J L. Adam: a method for stochastic optimization[EB/OL]. (2017-01-30) [2022-06-14].https://arxiv.org/pdf/1412.6980.pdf.
Moving portrait debluring network based on multi-level jump residual group
JI Jiaqi, LU Zhenkun*, XIONG Fupeng, ZHANG Tian, YANG Hao
(,,530006,)
To address the issues of blurred contours and lost details of portrait image with motion blur after restoration, a moving portrait deblurring method based on multi-level jump residual group Generation Adversarial Network (GAN) was proposed. Firstly, the residual block was improved to construct the multi-level jump residual group module, and the structure of PatchGAN was also improved to make GAN better combine with the image features of each layer. Secondly, the multi-loss fusion method was adopted to optimize the network to enhance the real texture of the reconstructed image. Finally, the end-to-end mode was used to perform blind deblurring on the motion blurred portrait image and output clear portrait image. Experimental results on CelebA dataset show that the Peak Signal-to-Noise Ratio (PSNR) and Structural SIMilarity (SSIM) of the proposed method are at least 0.46 dB and 0.05 higher than those of the Convolutional Neural Network (CNN)-based methods such as DeblurGAN (Deblur GAN), Scale-Recurrent Network (SRN) and MSRAN (Multi-Scale Recurrent Attention Network). At the same time, the proposed method has fewer model parameters, faster restoration, and more texture details in the restored portrait images.
image debluring; blind deblurring; Generative Adversarial Network (GAN); multi-level jump residual group; multi-loss fusion
This work is partially supported by National Natural Science Foundation of China (61561008), Natural Science Foundation of Guangxi (2018GXNSFAA294019).
JI Jiaqi, born in 1997, M. S. candidate. His research interests include deep learning, image processing.
LU Zhenkun, born in 1979, Ph. D., professor. His research interests include image processing, ultrasound testing and imaging, computer vision, deep learning.
XIONG Fupeng, born in 1998, M. S. candidate. His research interests include deep learning.
ZHANG Tian, born in 1999, M. S. candidate. Her research interests include deep learning, image processing.
YANG Hao, born in 1995, M. S. candidate. His research interests include deep learning, image processing.
1001-9081(2023)10-3244-07
10.11772/j.issn.1001-9081.2022091457
2022⁃10⁃08;
2023⁃01⁃03;
国家自然科学基金资助项目(61561008);广西自然科学基金资助项目(2018GXNSFAA294019)。
纪佳奇(1997—),男,江苏徐州人,硕士研究生,主要研究方向:深度学习、图像处理; 卢振坤(1979—),男,广西百色人,教授,博士,CCF会员,主要研究方向:图像处理、超声检测与成像、计算机视觉、深度学习; 熊福棚(1998—),男,河南光山人,硕士研究生,主要研究方向:深度学习; 张甜(1999—),女,陕西黄陵人,硕士研究生,主要研究方向:深度学习、图像处理; 杨豪(1995—),男,广西钦州人,硕士研究生,主要研究方向:深度学习、图像处理。
TP391.41
A
2023⁃02⁃01。
