面向语音增强的双复数卷积注意聚合递归网络
2023-10-21余本年詹永照毛启容董文龙刘洪麟
余本年,詹永照*,毛启容,2,董文龙,刘洪麟
面向语音增强的双复数卷积注意聚合递归网络
余本年1,詹永照1*,毛启容1,2,董文龙1,刘洪麟1
(1.江苏大学 计算机科学与通信工程学院,江苏 镇江 212013; 2.江苏省大数据泛在感知与智能农业应用工程研究中心,江苏 镇江 212013)( ∗ 通信作者电子邮箱yzzhan@ujs.edu.cn)
针对现有的语音增强方法对语谱图特征关联信息表达有限和去噪效果不理想的问题,提出一种双复数卷积注意聚合递归网络(DCCARN)的语音增强方法。首先,建立双复数卷积网络,对短时傅里叶变换后的语谱图特征进行两分支信息编码;其次,将两分支中编码分别使用特征块间和特征块内注意力机制对不同的语音特征信息进行重标注;再次,使用长短期记忆(LSTM)网络处理长时间序列信息,并用两解码器还原语谱图特征并聚合这些特征;最后,经短时逆傅里叶变换生成目标语音波形,以达到抑制噪声的目的。在公开数据集VBD(Voice Bank+DMAND)和加噪的TIMIT数据集上进行的实验的结果表明,与相位感知的深度复数卷积递归网络(DCCRN)相比,DCCARN在客观语音感知质量指标(PESQ)上分别提升了0.150和0.077~0.087。这验证了所提方法能更准确地捕获语谱图特征的关联信息,更有效地抑制噪声,并提高语音的清晰度。
语音增强;注意力机制;复数卷积网络;编码;长短期记忆网络
0 引言
语音增强是一种从有噪声的语音信号中提取尽可能纯净的语音信号的技术,该技术可以提高语音的客观感知质量和可懂度。语音增强在移动通信、语音助听和语音识别预处理等方面都有广泛的应用前景。根据收录语音时使用的麦克风数量的不同,语音增强可以分为单通道语音增强和多通道语音增强。多通道语音增强可以更有效利用声音的空间信息,增强目标方向的声音信息,抑制非目标方向的干扰源,但多通道语音对硬件设备要求高,应用范围受限。与多通道语音相比,单通道语音具有硬件成本低、能耗小的优势,应用范围广,但由于声源信息和噪声的空间信息少,因此研究单通道语音增强更具有现实意义和富有挑战性。
目前常见的语音增强算法主要有两种:一种是传统的语音增强算法,另一种是基于深度学习的语音增强算法。
传统的单通道语音增强算法主要包括谱减法、维纳滤波法、基于统计模型和信号子空间语音增强算法。传统的方法在处理平稳噪声时具有较好的语音增强效果,但是这些方法都是基于噪声是平稳的这一假设,而现实中的语音信号还存在非平稳噪声,限制了语音增强性能的进一步提升。
随着深度学习方法的兴起,研究者提出了众多基于深度学习的单通道语音增强方法[1],这些方法不需要对数据进行额外的条件假设,而是通过挖掘语音数据的内在联系,更准确地实现目标语音和噪声的估计。多种单通道语音增强的神经网络结构模型被提出,如深度神经网络[2]、卷积神经网络(Convolutional Neural Network, CNN)[3]、生成对抗网络(Generative Adversarial Network, GAN)[4]、长短期记忆(Long Short-Term Memory, LSTM)网络[5]和基于注意力机制的网络[6]等,这些模型能够较好地挖掘语音特征之间的关联,提升了语音增强效果,但是这些模型对语音相位信息学习表达还不充分。
目前基于深度学习的单通道语音增强方法在提取高维特征时通常忽略或破坏了语谱图的相位信息,导致出现目标语音细节部分丢失的问题。针对语谱图中相位信息的表达不充分影响目标语音估计的问题,Hu等[7]提出了模拟复数运算的深度复数卷积递归网络(Deep Complex Convolution Recurrent Network, DCCRN),并用于单通道语音增强,通过复数运算结构保留更多的目标语音相位信息,实现了相位信息的有效捕获,提升了语音增强任务的性能。然而该方法未考虑注意力机制的运用,以及更合理地表达学习幅度与相位信息并加以利用,从而限制了语音增强效果的进一步提升。
本文针对单通道语音增强问题,在DCCRN模型的基础上提出了一种双复数卷积注意聚合递归网络(Double Complex Convolution and Attention aggregating Recurrent Network,DCCARN)的语音增强方法。受视觉特征学习的通道注意力和空间注意力机制[8]的启发,可以将语谱图的卷积编码信息分为多种特征层面的时频范围的特征块信息,并进行双注意力驱动的特征学习:1)块间注意力机制,不同特征块之间整体时频信息的注意力学习;2)块内注意力机制,相关特征块内局部时频信息的注意力学习。所提方法不同于现有的注意力机制方法,引入了两个注意力机制结构,通过双分支网络注意力机制从特征块间和特征块内两个维度注意力提高语音特征的表达质量。首先,利用短时傅里叶变换对输入波形进行频谱分析,考虑在频谱图上分别进行两个维度信息的特征学习,利用两个复数编码器提取信息的高维特征,并利用跳连方式连接编码器中各层卷积块的输出与解码器中相应的反卷积块,以避免梯度消失;其次,将两个分支编码器最后一层卷积块的输出分别作为特征块间和特征块内注意力模块的输入,实现对特征块间和块内相关性信息的重标记,使目标特征学习更加丰富;最后,经复数LSTM、解码器、特征融合、短时逆傅里叶变换和掩码得到增强后的语音。
本文的主要工作如下:
1)提出了双复数卷积递归网络语音信息编码,分别进行不同信息编码,以增加目标语音的底层信息,通过时序关联信息分析后进行语音特征解码和特征信息融合,有利于更真实还原目标语谱图特征。
2)提出了特征块间和特征块内注意力机制网络,对不同的语音特征信息重标注,聚合两个注意力重标注、时序关联和解码预测的特征,有效增强目标语音信号并抑制噪声信号,提高目标语音的清晰度。
3)将双复数卷积递归网络注意聚合方法用于语音增强,在两个公共数据集上进行了实验,实验结果显示在典型的评价指标上所提方法均优于目前先进的方法。
1 相关工作
1.1 基于注意力机制的语音增强
注意力机制也称为神经网络注意力,能够将注意力集中在输入或特征的子集上。通过引入注意力可以减少处理的信息量,减少所需的计算资源,研究结果显示,在语音增强领域,注意力机制可以有效地提高语音增强性能。Yu等[6]提出了一种新的自适应注意循环生成对抗网络(Attention-In-Attention CycleGAN, AIA-CycleGAN)用于语音增强。Koizumi等[9]采用语音增强和说话人识别的多任务学习,利用多头自注意力捕获语音和噪声中的长期依赖性。Zhang等[10]提出了一个简单且有效的时频注意(Time-Frequency Attention, TFA)模块,该模块生成一个二维注意图,为时频表示的谱分量提供不同的权重,该算法在不可见的噪声条件下具有更好的泛化能力。目前已有的基于注意力机制的语音增强算法均提升了语音增强的效果,但是都是从单个维度分析注意力机制,没有充分考虑各个维度之间的关联性信息。
1.2 基于网络模型的语音增强
基于深度学习的语音增强模型可以有效提升语音可懂度和质量,已成为研究热点,本文在此基础上进行了深入的研究和探讨。最早提出的基于全连接网络的语音增强主要是利用卷积、全卷积或者递归神经网络预测时频掩码或语音频谱,很多研究者在此基础上优化网络的结构和损失函数[11]。Pascual等[12]将波形直接输入训练模型,并将GAN应用于语音增强,提出SEGAN(Speech Enhancement GAN);卷积递归神经网络(Convolutional Recurrent neural Network, CRN)[3]是一种典型的算法,它采用了类似时域方法的编码结构,利用二维卷积从语谱图中提取高维特征,以达到更好的分离语音效果;DCCRN[7]对CRN进行了实质性的修改,在编码器中加入复数运算结构的二维卷积,解码器中加入复数的二维转置卷积,并且还考虑了复数的LSTM替代传统的LSTM。实际上语音和噪声对语音增强任务的重要程度是不同的,但这些模型都没有充分考虑底层信息的丢失问题,对噪声和纯净语音做无差别处理。因此,本文采用双复数卷积注意聚合递归网络进一步充分挖掘目标信息,以进一步提升语音增强的性能。
2 基于DCCARN的语音增强
由于语音频谱图上的信息比较丰富,充分捕获利用语谱图特征是语音增强的有效方法。针对语谱图中不同维度特征存在关联性,本文在DCCRN的基础上,构建了一种双复数卷积注意聚合递归网络(DCCARN)的语音增强方法,整体网络框架如图1所示。首先,利用短时傅里叶变换将输入的带噪时域波形转为频域的语谱图,复制语谱图,分别建立具有特征块间注意力和特征块内注意力的两个编解码器;其次,随机初始化参数,经两个编码器学习不同的高维特征,将两个编码器的最后一层输出分别送入特征块间注意力和特征块内注意力模块,对不同的语音特征信息重标注;再次,分别经LSTM时序建模和解码,形成特征块间注意力和特征块内注意力的预测语音特征;最后,融合这两种语音特征,由短时逆傅里叶变换生成增强的目标语音波形。
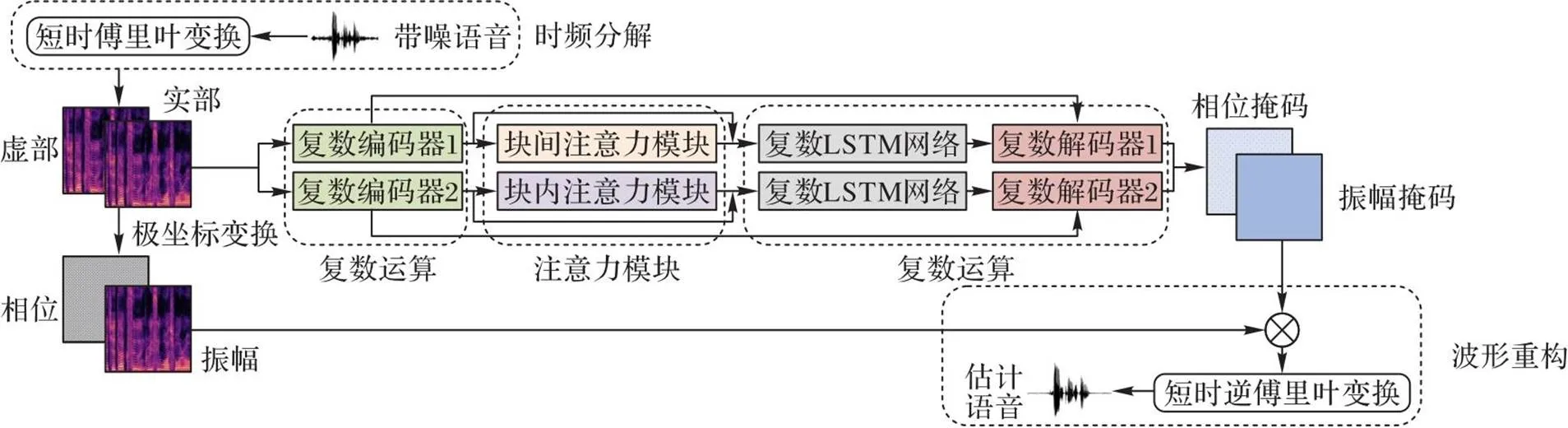
图1 DCCARN方法架构
编码层主要由5层卷积块组成,每个卷积块中包括二维卷积层、批标准化(Batch Normalization, BN)层和激活函数,其中BN的作用是保证卷积层的输出数据在网络训练过程中满足独立分布假设。编码器和解码器中第0层到第3层卷积块的输出都进行跳跃连接处理,可以有效解决梯度流动问题。
中间层是编码层和解码层之间的过渡层,每条分支的中间层由一个注意力模块和两层LSTM组成。通过在网络中加入双分支注意力机制模块,能够充分利用特征块间和特征块内的相关信息,给不同重要程度的语音特征赋予不同的权重,实现对有用特征信息的学习。具体地,LSTM进行复数运算,复数模块通过复数乘法模拟幅度和相位之间的关系。
解码层主要由5层反卷积块组成,反卷积块包括转置卷积层、BN和激活函数。解码层的反卷积模块跟编码层每一层的卷积模块相对应,有相同的卷积核数和卷积核大小,使对应编解码层的维度大小保持一致。
2.1 语音的时频分解
人类的听觉系统在频谱分析中的作用是紧密联系在一起的。因此,对语音信号频谱分析是识别和处理语音信号的一种重要方法。语音的时频分解如图1所示,它的具体流程如图2所示。从总体看,语音信号整体上是一个非平稳过程,因此需要对输入的带噪语音数据先进行采样和量化处理,将连续的语音信号幅值离散化。由于不稳定信号的波形特征无规律性,不存在瞬时频率,也就无法直接采用傅里叶变换处理。短时傅里叶变换是一种常见的时频分解方法,它主要分析不稳定信号。基于语音的短时平稳特性,可以将语音切分成若干小片处理。在分帧时,将信号设置为每30 ms一帧的信号,每一帧近似是平稳信号,从而确保了帧内语音的基本特性相对稳定,但分帧时很难保证截断后的信号为周期信号。为了减小这种误差,对分帧后的信号使用特殊的加权函数,即窗函数。窗函数可以使时域信号更好地满足周期性要求,减少频谱泄漏的情况。本文所使用的窗函数是汉明窗(Hamming Window)(语音帧长为),公式表示为:
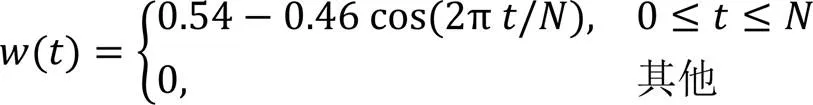
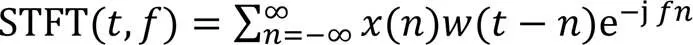
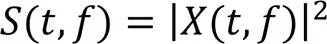
其中为语音信号的时频表示。
2.2 双分支注意力机制
在语音增强任务中,语谱图重构依赖的上下文信息越丰富,增强的效果越好。现有的语音增强网络主要通过局部卷积实现,只能获得有限的局部信息,不能有效利用频谱图的整体信息。本文引入特征块间注意力机制和特征块内注意力机制,使网络更好地捕获频谱图的上下文信息,建模各个特征块间和块内的重要程度,自适应调整不同块间和块内的权重,从而更好地优化特征,最终得到更优良的增强效果。注意力机制模块如图1中“注意力模块”所示。
2.2.1特征块间注意力机制

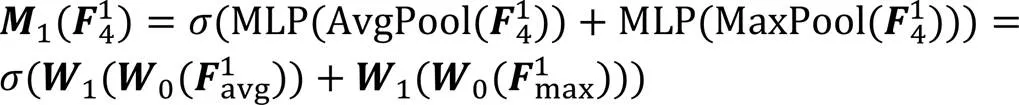

2.2.2特征块内注意力机制
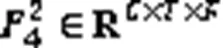
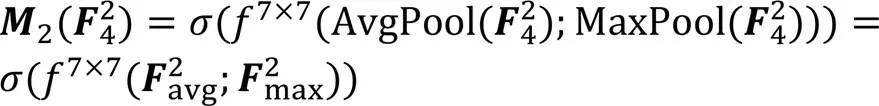
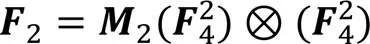
2.3 语音复数编解码
2.3.1复数编解码器

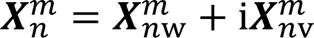

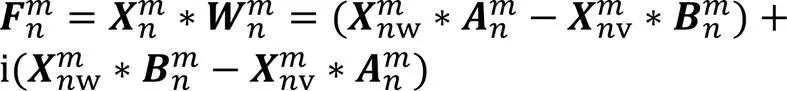
双分支复数卷积解码是双分支复数卷积编码的逆过程,融合最后一层的编码与经LSTM网络建模后的语音复数编码信息作为解码层的第一层输入,其他各层均是将上一层的解码输出与对应层的编码融合进行解码。
2.3.2复数长短期记忆


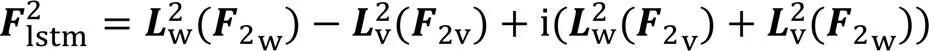
经LSTM网络建模后的特征块间和特征块内双分支的语音复数编码信息作为各分支解码器第一层的输入之一。
2.3.3双分支解码输出融合

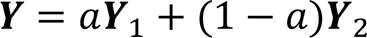
2.4 训练目标
沿用文献[7]方法,选用复数理想比率掩码(complex Ideal Ratio Mask, cIRM)作为训练目标,掩码层从复数谱的实部和虚部分量得出,最后返回复数谱,公式如下:
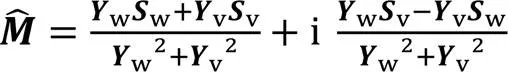
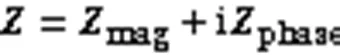

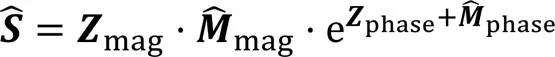


2.5 损失函数

对于第1条块间分支采用SI-SNR损失函数约束第1分支预测,公式如下:

对于第1条块内分支采用SI-SNR损失函数表示如下:
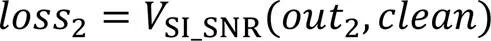
对于两个解码器融合后的整体输出损失函数约束为:
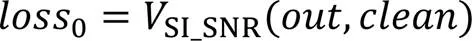
结合块间、块内分支的重构损失和两个解码器融合后的输出损失,可得到整个语音增强模型损失函数,表示如下:
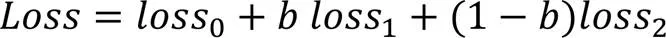
3 实验与结果分析
3.1 数据集
为了验证所提方法的有效性,选取语音增强中应用最为广泛的Voice Bank[13]+DMAND(VBD)[14]和TIMIT[15]作为实验数据集进行相关实验。
VBD数据集主要由训练集和测试集两部分组成。该训练集中有11 572组音频文件,测试集中有824组文件,每组音频文件包括一段带噪语音和一段纯净语音。
TIMIT数据集包含宽带录音有630人说美国的8种主要方言,每个人读10条语音丰富的句子。噪声数据集选择noise-92[16]。将TIMIT数据集随机分成两部分,400名发言者作为训练集的发言者,其余62名作为验证集。测试集是462名发言者以外的168名说话者。由于在低信噪比条件下语音难以估计,在高信噪比条件下噪声难以估计,故对TIMIT数据集的语音噪声混合过程是从演讲中随机地选择话语生成。
3.2 实验配置
实验服务器配置为Inter Core TM i9-9720K CPU@2.90 GHz,GPU采用 GeForce RTX2080Ti显存11 GB,内存64 GB。在此基础上,服务器采用Ubuntu 18.04系统,Python 3.7.11,CUDA10.2,PyTorch1.7.1的开发环境。
实验参照文献[7],对所有的输入音频信号降采样到16 kHz,短时傅里叶变换的窗口长度为256 ms,帧移动为64 ms,短时傅里叶变换的特征长度为512。编码器中每层的输出特征类型块数设置为{32,64,128,256,256},解码器中每层的输出特征类型块数设置为{256,256,128,64,32},卷积核大小为(5,2),步长为(2,1)。通过采用变化步长测试,选定合适的其他相关参数,具体为:初始学习率设为0.000 2,网络的批处理大小设置为8,网络训练周期设置为100。
3.3 评价指标
语音增强的性能评价指标主要有两大类:一类是客观质量指标,一类是主观测试指标。这些常用的评价指标在语音恢复质量、噪声去除程度和语音可懂度等方面各有侧重。在本文结果评估中,使用了多种测试指标评估模型的估计语音,包括:语音感知质量指标(Perceptual Evaluation of Speech Quality, PESQ);预测语音信号失真的复合度量(Composite measure for predicting SIGnal rating, CSIG),即语音信号失真的平均意见分;预测背景噪声影响的复合度量(Composite measure for predicting BAcKground noise, CBAK),即背景噪声影响的平均意见分;预测整体语音质量的复合度量(Composite measure for predicting Overall processed speech quality, COVL),即整体语音质量的平均意见分。
3.4 超参取值分析
3.4.1双分支融合权重分析
3.4.2损失权重分析

图4 在VBD数据集上的a、b取值分析
3.5 相关工作比较分析
3.5.1在VBD上比较分析
针对提升语音增强性能任务,选用以下具有代表性的方法作为对比方法:Wavenet[17]、SEGAN[12]、基于CNN的GAN(Convolutional Neural Network-based Generative Adversarial Network, CNN-GAN)[18]、Wave-U-Net[19]、基于最小均方误差GAN(Minimum Mean Square Error based GAN,MMSE-GAN)[20]、CRN[3]、多域混合去噪(Multi-Domain Processing via Hybrid Denoising, MDPHD)网络[21]、DCCRN[7]、时频和时域网络(Time-Frequency and Time Domain Network, TFT-Net)[22]、感知引导GAN(Perception-Guided GAN, PGGAN)[4]和融合Conformer和GAN的全时间尺度语音增强模型(Full-Time Scale speech enhancement model that incorporates Conformer and GAN, FTSC-GAN)[23]。表1给出了相关对比方法在VBD数据集上的4种评价指标的测评结果。

表1 不同方法在VBD数据集上的语音评价得分
注:NOISY表示未经增强处理的带噪语音评估。
从表1可以看出,SEGAN和Wave-U-Net的结果不理想,主要原因是,采用时域上的波形处理,相较于时频域方法在一定程度上捕获的目标信息不够丰富。在采用时频域处理的方法上,Wavenet的PESQ相较于CRN、CNN-GAN和MMSE-GAN更优。DCCARN是在DCCRN基础上引入双分支语谱图块间和块内注意力编码机制,在PESQ、CSIG、CBAK和COVL上均超越了DCCRN,分别提升了0.150、0.180、1.140和0.240。同时,DCCARN的PESQ、CBAK和COVL比TFT-Net分别提升了0.080、0.160和0.090,比PGGAN分别提升了0.020、0.010和0.070,比FTSC-GAN分别提升了0.080、0.250和0.040。实验结果表明,通过双分支编码器注意聚合递归网络考虑特征块内和块间注意力信息,能提高目标信息的关注度,更符合语音增强任务,可有效提高语音增强性能。
3.5.2TIMIT数据集上模型性能评估
表2给出了在信噪比为5 dB、0 dB和-5 dB条件下DCCARN和基线方法DCCRN在TIMIT数据集上的4种评价指标结果。可以看出,在信噪比为5 dB、0 dB和-5 dB时,DCCARN相较于DCCRN在PESQ、CSIG、CBAK和COVL上都得到了提升:当信噪比为5 dB时,分别提升了0.077、0.106、0.235和0.092;当信噪比为0 dB时,分别提升了0.087、0.139、0.216和0.115;当信噪比为-5 dB时,分别提升了0.079、0.165、0.186和0.125。说明DCCARN在低信噪比条件下也可以表现出很好的性能,对语音增强任务有所提升。同时,信噪比为5 dB时的评估结果要明显优于信噪比为-5 dB、0 dB的结果,也进一步说明了在高信噪比下的去噪性能都明显优于低信噪比情况下的去噪性能。实验结果表明,通过不同的加噪处理,DCCARN在语音的低频和高频部分去噪均有优化作用;针对不同的信噪比混合比率,DCCARN均能有对应的优化提升,体现了DCCARN方法相较于DCCRN在抗噪性上的优越性能。

表2 不同方法在TIMIT数据集上的语音评价得分
3.6 消融实验
为了验证DCCARN对语音增强性能的改善效果。用深度复数卷积递归网络(DCCRN)作为主干网络,在VBD数据集上进行了相关消融实验,实验结果如表3所示。可以看出,所提模块均是有效的。除DCCARN的损失函数为(式(23))外,其他实验均采用SI-SNR直接作为模型的损失函数。
1)特征块间注意力模块的有效性。在基准模型DCCRN中仅加入特征块间注意力模块,PESQ和CBAK有所提升,表明特征块间注意力模块可以提高语音感知质量和噪声影响的指标值。
2)特征块内注意力模块的有效性。在DCCRN中仅加入特征块内注意力模块,PESQ、CBAK和COVL上都有所提升,表明特征块内注意力模块可以提高语音感知质量和噪声影响的指标和整体评价指标,同时特征块内注意力机制比特征块间注意力机制的作用更加显著。
3)双分支结构的有效性。在DCCRN中仅加入双分支结构,PESQ、CBAK和COVL上都有明显提升,表明双分支结构可以提高语音感知质量和噪声影响的指标和整体评价指标,验证了双分支注意力机制的有效性。通过在DCCRN中加入特征块间、块内和双分支结构,在4个评价指标上都比单独添加模块得到了显著的提升,表明双分支注意力机制对提升4个评价指标都有着显著的作用。

表3 在VBD数据集上的消融实验结构
3.7 可视化分析
为了更加直观地验证所提方法对语音增强的效果,使用本文方法在VBD数据集中处理2个带噪语音波形信息。对p232_021.wav进行波形可视化,对比图5(a)~(c)可以看出,经DCCARN方法增强的语音能有效去除噪声信息,较为接近纯净语音的波形图。对p232_160.wav进行语谱图可视化,对比图5(d)~(f)可以看出,经DCCARN增强的语音的语谱图很接近纯净语音的语谱图,也表明了DCCARN能有效去除噪声信息,达到了语音增强目的。这也进一步验证了所提出的双复数卷积递归网络语音信息编码,通过信息聚合和时序关联信息分析进行语音特征解码,有利于目标语谱图的特征更真实还原;所提出的特征块间和特征块内注意力机制,能对不同的语音特征信息进行有效的重标注,可有效增强目标语音信息而抑制语音噪声,提高目标语音的清晰度。
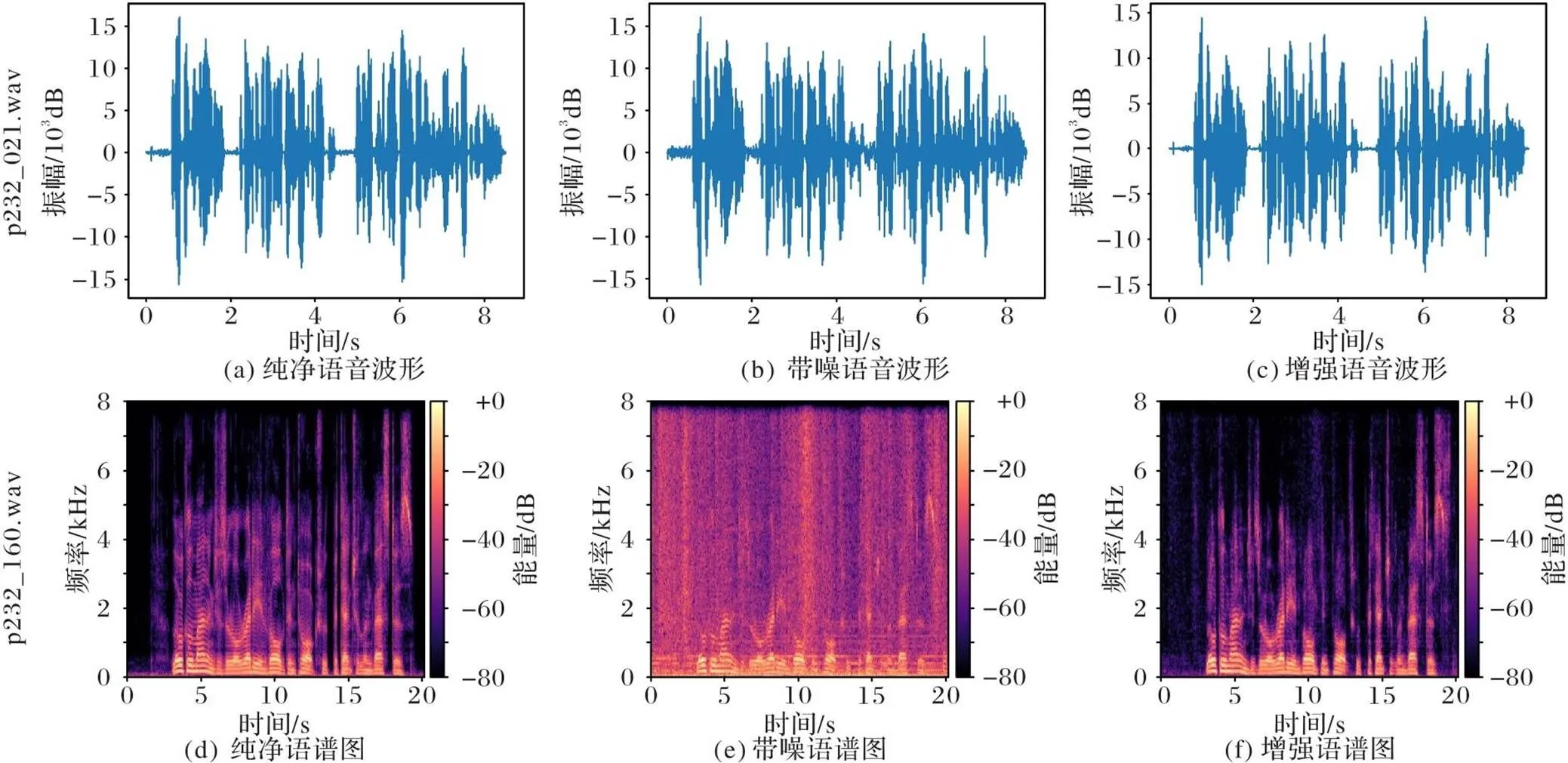
图5 语音质量对比
4 结语
本文针对带噪语音中特征块间和特征块内的内在关联性问题,对特征的块间和块内分别构建了两条分支关注块间和块内信息,并将双分支解码输出的高维特征进行加权融合,形成一种用于学习目标语音特征的注意聚合网络,提出了一种基于双分支复数卷积注意聚合递归网络单通道语音增强方法,在VBD和TIMIT这两个典型的数据集上进行了充分的实验。实验结果表明,所提出的方法能有效提高语音增强的客观语音质量和相关语音评价指标,可有效去除语音噪声信息,提高了语音增强效果。考虑到Transformer模型对信号特征表达更有优势,在后续工作中,本文可进一步研究结合复数卷积和轻量级Transformer的语音增强技术,获得较快速和更好的语音增强效果。
[1] CHOI H S, KIM J H, HUH J, et al. Phase-aware speech enhancement with deep complex U-Net[EB/OL]. (2023-08-06) [2023-08-08].https://openreview.net/pdf?id=SkeRTsAcYm.
[2] HASANNEZHAD M, YU H, ZHU W P, et al. PACDNN: a phase-aware composite deep neural network for speech enhancement[J]. Speech Communication, 2022, 136: 1-13.
[3] TAN K, WANG D. A convolutional recurrent neural network for real-time speech enhancement[C]// Proceedings of the INTERSPEECH 2018. [S.l.]: International Speech Communication Association, 2018: 3229-3233.
[4] LI Y, SUN M, ZHANG X. Perception-guided generative adversarial network for end-to-end speech enhancement[J]. Applied Soft Computing, 2022, 128: No.109446.
[5] WANG Z, ZHANG T, SHAO Y, et al. LSTM-convolutional-BLSTM encoder-decoder network for minimum mean-square error approach to speech enhancement[J]. Applied Acoustics, 2021, 172: No.107647.
[6] YU G, WANG Y, ZHENG C, et al. CycleGAN-based non-parallel speech enhancement with an adaptive attention-in-attention mechanism[C]// Proceedings of the 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Piscataway: IEEE, 2021: 523-529.
[7] HU Y, LIU Y, LV S, et al. DCCRN: deep complex convolution recurrent network for phase-aware speech enhancement[C]// Proceedings of the INTERSPEECH 2020. [S.l.]: International Speech Communication Association, 2020: 2472-2476.
[8] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 3-19.
[9] KOIZUMI Y, YATABE K, DELCROIX M, et al. Speech enhancement using self-adaptation and multi-head self-attention[C]// Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2020: 181-185.
[10] ZHANG Q, SONG Q, NI Z, et al. Time-frequency attention for monaural speech enhancement[C]// Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2022: 7852-7856.
[11] 高戈,王霄,曾邦,等. 基于时频联合损失函数的语音增强算法[J]. 计算机应用, 2022, 42(S1):316-320.(GAO G, WANG X, ZENG B, et al. Speech enhancement algorithm based on time-frequency joint loss function[J]. Journal of Computer Applications, 2022, 42(S1):316-320.)
[12] PASCUAL S, BONAFONTE A, SERRÀ J. SEGAN: speech enhancement generative adversarial network[C]// Proceedings of the INTERSPEECH 2017. [S.l.]: International Speech Communication Association, 2017: 3642-3646.
[13] VEAUX C, YAMAGISHI J, KING S. The voice bank corpus: design, collection and data analysis of a large regional accent speech database[C]// Proceedings of the 2013 International Conference Oriental COCOSDA Held Jointly with Conference on Asian Spoken Language Research and Evaluation. Piscataway: IEEE, 2013: 1-4.
[14] THIEMANN J, ITO N, VINCENT E. The Diverse Environments Multi-channel Acoustic Noise Database (DEMAND): a database of multichannel environmental noise recordings[J]. Proceedings of Meetings on Acoustics, 2013, 19(1): No.035081.
[15] GAROFOLO J S, LAMEL L F, FISHER W M. TIMIT acoustic phonetic continuous speech corpus[DS/OL]. [2022-12-15].https://catalog.ldc.upenn.edu/LDC93S1.
[16] VARGA A, STEENEKEN H J M. Assessment for automatic speech recognition: Ⅱ. NOISEX-92: a database and an experiment to study the effect of additive noise on speech recognition systems[J]. Speech Communication, 1993, 12(3): 247-251.
[17] RETHAGE D, PONS J, SERRA X. A Wavenet for speech denoising[C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 5069-5073.
[18] SHAH N, PATIL H A, SONI M H. Time-frequency mask-based speech enhancement using convolutional generative adversarial network[C]// Proceedings of the 2018 AP sia-Pacific Signal and Information Processing Association Annual Summit and Conference. Piscataway: IEEE, 2018:1246-1251.
[19] MACARTNEY C, WEYDE T. Improved speech enhancement with the Wave-U-Net[EB/OL]. (2018-11-27) [2022-12-15].https://arxiv.org/pdf/1811.11307.pdf.
[20] SONI M H, SHAH N, PATIL H A. Time-frequency masking-based speech enhancement using generative adversarial network[C]// Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2018: 5039-5043.
[21] KIM J H, YOO J, CHUN S, et al. Multi-domain processing via hybrid denoising networks for speech enhancement[EB/OL]. (2018-12-21) [2022-12-15].https://arxiv.org/pdf/1812.08914.pdf.
[22] TANG C, LUO C, ZHAO Z, et al. Joint time-frequency and time domain learning for speech enhancement[C]// Proceedings of the 29th International Joint Conferences on Artificial Intelligence. California: ijcai.org, 2020: 3816-3822.
[23] 沈梦强,于文年,易黎,等. 基于GAN的全时间尺度语音增强方法[J].计算机工程, 2023, 49(6):115-122, 130.(SHEN M Q, YU W N, YI L, et al. Full-time scale speech enhancement method based on GAN[J]. Computer Engineering, 2023, 49(6):115-122, 130.)
Double complex convolution and attention aggregating recurrent network for speech enhancement
YU Bennian1, ZHAN Yongzhao1*, MAO Qirong1,2, DONG Wenlong1, LIU Honglin1
(1,,212013,;2,212013,)
Aiming at the problems of limited representation of spectrogram feature correlation information and unsatisfactory denoising effect in the existing speech enhancement methods, a speech enhancement method of Double Complex Convolution and Attention Aggregating Recurrent Network (DCCARN) was proposed. Firstly, a double complex convolutional network was established to encode the two-branch information of the spectrogram features after the short-time Fourier transform. Secondly, the codes in the two branches were used in the inter- and and intra-feature-block attention mechanisms respectively, and different speech feature information was re-labeled. Secondly, the long-term sequence information was processed by Long Short-Term Memory (LSTM) network, and the spectrogram features were restored and aggregated by two decoders. Finally, the target speech waveform was generated by short-time inverse Fourier transform to achieve the purpose of suppressing noise. Experiments were carried out on the public dataset VBD (Voice Bank+DMAND) and the noise added dataset TIMIT. The results show that compared with the phase-aware Deep Complex Convolution Recurrent Network (DCCRN), DCCARN has the Perceptual Evaluation of Speech Quality (PESQ) increased by 0.150 and 0.077 to 0.087 respectively. It is verified that the proposed method can capture the correlation information of spectrogram features more accurately, suppress noise more effectively, and improve speech intelligibility.
speech enhancement; attention mechanism; complex convolutional network; coding; Long Short-Term Memory (LSTM) network
This work is partially supported by Key Research and Development Program of Jiangsu Province (BE2020036).
YU Bennian, born in 1996, M. S. candidate. Her research interests include speech enhancement.
ZHAN Yongzhao, born in 1962, Ph. D., professor. His research interests include pattern recognition, multimedia analysis.
MAO Qirong, born in 1975, Ph. D., professor. Her research interests include pattern recognition, multimedia analysis.
DONG Wenlong, born in 1997, Ph. D. candidate. His research interests include multimedia computing.
LIU Honglin, born in 1992, Ph. D. candidate. His research interests include image classification of pests and diseases.
1001-9081(2023)10-3217-08
10.11772/j.issn.1001-9081.2022101533
2022⁃10⁃12;
2022⁃12⁃24;
江苏省重点研发计划项目(BE2020036)。
余本年(1996—),女,安徽池州人,硕士研究生,主要研究方向:语音增强; 詹永照(1962—),男,福建尤溪人,教授,博士,CCF会员,主要研究方向:模式识别、多媒体分析; 毛启容(1975—),女,四川泸州人,教授,博士,CCF会员,主要研究方向:模式识别、多媒体分析; 董文龙(1997—),男,江苏徐州人,博士研究生,主要研究方向:多媒体计算; 刘洪麟(1992—),男,江苏宿迁人,博士研究生,主要研究方向:病虫害图像分类。
TN912.34
A
2022⁃12⁃28。
