基于多特征融合的点云场景语义分割
2023-10-21郝雯汪洋魏海南
郝雯,汪洋,魏海南
基于多特征融合的点云场景语义分割
郝雯*,汪洋,魏海南
(西安理工大学 计算机科学与工程学院,西安 710048)( ∗ 通信作者电子邮箱haowensxsf@163.com)
为挖掘特征间的语义关系以及空间分布信息,并通过多特征增强进一步改善点云语义分割的效果,提出一种基于多特征融合的点云场景语义分割网络(MFF-Net)。所提网络以点的三维坐标和改进后的边特征作为输入,首先,利用-近邻(NN)算法搜寻点的近邻点,并在三维坐标和近邻点间坐标差值的基础上计算几何偏移量,从而增强点的局部几何特征表示;其次,将中心点与近邻点间的距离作为权重信息更新边特征,并引入空间注意力机制,获取特征间的语义信息;再次,通过计算近邻特征间的差值,利用均值池化操作进一步提取特征间的空间分布信息;最后,利用注意力池化操作融合三边特征。实验结果表明,所提网络在S3DIS(Stanford 3D large-scale Indoor Spaces)数据集上的平均交并比(mIoU)达到了67.5%,总体准确率(OA)达到了87.2%,相较于PointNet++分别提高10.2和3.4个百分点,可见MFF-Net在大型室内/室外场景均能获得良好的分割效果。
点云;语义分割;空间注意力;注意力池化;特征融合
0 引言
点云作为描述三维物体表面几何信息的大量点的集合,在表达三维物体的空间位置以及物体间的拓扑关系上具有独特的优势,目前点云数据已广泛运用在自动驾驶、地图勘探、数字化城市等多个领域。针对点云的语义分割作为三维场景理解与重建的重要基础,是三维环境感知和机器视觉的重要组成部分。传统的点云分割方法过分依赖人工设计特征,计算量大,难以满足复杂点云场景的处理需求。随着深度学习在图像处理领域的广泛应用,基于深度学习的点云语义分割方法也获得了长足的发展[1];然而,面对点云数据的无序性、海量性以及稠密不均性,利用深度学习技术从三维点云中提取稳定的一致性特征,准确完成点云数据的分割仍然是研究中的难点。
已有的基于深度学习的点云语义分割方法大致可以分为3类:基于多层感知机(MultiLayer Perceptron, MLP)的方法、基于图卷积的方法以及基于注意力机制的方法。
基于MLP的方法是利用共享的MLP和池化操作提取点的特征。PointNet[2]是首个直接以原始点云数据作为输入的深度学习网络,采用MLP提取每个点的特征,利用最大池化操作聚合点的信息,进而获取全局特征,但忽略了点间局部特征的提取。Qi等[3]在PointNet基础上提出了PointNet++,该方法首先对输入的点云数据进行采样和区域划分,其次在各个小区域内递归地利用PointNet进行特征提取,最后融合点云的全局和局部特征;但与PointNet相似,PointNet++未考虑点与点之间的关系,如方向性等,对于局部特征的学习仍然不够充分。RandLA-Net (Random sampling and an effective Local feature Aggregator Network)[4]利用随机点采样法对点云数据进行采样,并通过局部特征聚合模块提取几何特征;利用随机点采样法可以提升算法效率,但会造成关键点信息丢失。位置自适应卷积(Position Adaptive Convolution, PAConv)[5]利用权重矩阵优化卷积运算,提高了网络对点特征的感知能力,但存储过多的权重矩阵可能会造成网络冗余,带来较大的内存占用和计算负担。
基于MLP的方法通常比较关注点的几何特征的提取,缺乏捕捉点间语义特征的能力。
基于图卷积的方法将卷积运算与图结构进行结合,构成图卷积神经网络。图结构将每个点作为图的顶点,同时构造与邻域点之间的有向边,并在邻域点上运用卷积操作,结合池化操作聚合邻域点信息,通过边的权重传递更新顶点特征。动态图卷积神经网络(Dynamic Graph Convolution Neural Network, DGCNN)[6]通过构造局部特征邻域图,利用多层堆叠的方式动态更新特征。边卷积(EdgeConv)在网络的每一层通过动态构建图结构计算边特征,使用卷积操作提取局部几何信息。DGCNN中的边特征只关注中心点与近邻点之间的关系,忽略了各个近邻点之间的向量方向,导致损失一部分的局部结构信息。因此,Zhang等[7]在DGCNN框架的基础上,提出了LDGCNN(Linked DGCNN),它的核心在于提取来自不同动态图的特征并进行拼接,同时使用MLP代替转换网络,有效解决了梯度消失的问题,但对于高维的全局语义特征提取不足。Chen等[8]提出一种融合点云方向与距离的图卷积神经网络,首先通过计算两点间的余弦相似度,得到相似度矩阵;其次,选取相似度最高的个点构建动态邻域图,提取两点间的边缘特征。该模型关注点间几何特征的提取,忽略了点间的语义特征。Du等[9]提出了局部‒全局图卷积方法(Local-Global Graph Convolutional Method, LGGCM)。该方法通过构造近邻点的局部图计算加权邻接矩阵,更新和聚合点特征以获得点云的局部空间几何特征,并将空间几何特征输入带有门控单元的全局空间注意力模块,以提取点间的依赖关系;但对于点比较稀疏的物体类别分割效果较差。
基于图卷积的方法能有效提取点的几何特征,但由于缺少对全局语义特征的提取,使得网络对特征的感知能力不足。
基于注意力机制的方法将有限的算力集中于重点信息,快速提取最有效的特征信息。基于图注意力的点神经网络(Graph Attention based Point neural Network, GAPNet)[10]通过在MLP层中嵌入图注意力机制,有效获取局部几何特征;但该网络对全局特征提取不足,对边界区域的分割效果较差。Chen等[11]提出双重自注意力卷积网络,该网络包括点注意力模块和分组注意力模块,分别用于提取点的几何特征以及不同组之间的相关性。GA-NET(Guided Aggregation NET)[12]由点相关和点无关全局注意力模块组成,其中:点相关全局注意力模块利用两个随机抽样子集自适应聚合点的上下文信息;点无关注意力模块用于共享所有点的全局注意图,该网络更关注全局特征的获取,对局部特征的表征能力不足。Chen等[13]提出一种基于自注意的全局特征增强网络,该网络包括下采样模块、全局特征自注意编码模块、加权语义映射模块和上采样模块。通过全局自注意编码模块提取点的全局语义特征,并利用加权语义映射模块增强特征;但该网络上采样与下采样模块采用线性连接结构,会导致特征提取过程中部分特征信息的丢失。
基于注意力机制的方法能有效提取点间的语义信息,但在局部细节特征的表达能力不足。
上述网络模型主要关注点的全局或局部特征以及点间语义特征的提取,缺乏对特征间上下文关系的挖掘,导致特征提取不全面。因此,本文提出一种基于多特征融合的点云场景语义分割网络(Multi-Feature Fusion based point cloud scene semantic segmentation Network, MFF-Net),该网络以点的三维坐标和改进后的边特征作为输入,充分考虑点的几何特征和特征间的语义关系,以获得具有独特性和鲁棒性的特征。该网络具有以下特点:
1)利用点的坐标信息改进边特征,充分考虑点本身的坐标值以及该点与近邻点间的关系,提高网络的几何特征表征能力。
2)基于中心点与近邻点间的欧氏距离构造权重模块,将特征按权重融合,去除冗余信息,并引入空间注意力机制,以提取有效的局部语义特征。
3)计算特征与近邻特征间的差值,利用均值池化操作,提取空间语义分布特征,提高网络特征分布的捕捉能力。
1 基于多特征融合的点云场景语义分割网络
1.1 MFF-Net的框架

经过5层编码,点的数量从逐步采样到/512,每层输出的特征维度分别为16、64、128、256和512。之后通过5层解码层,利用最近邻插值法对高维特征进行上采样(Up-Sample, US),并对融合后的特征进行反卷积操作。最后,经过3个全连接层(Fully Connected layer, FC),为点云场景中每个点分配类别标签,从而完成点云数据的语义分割任务。

图1 MFF-Net的框架
1.2 网络输入



融合每点的三维坐标和改进后的边特征输入MFF-Net。
1.3 多特征融合模块
图2为多特征融合模块的示意图,该模块分别提取点的几何特征、特征间的语义信息和空间语义分布特征,并利用注意力池化操作聚合3个特征,以充分融合所获取的特征信息,提高网络的语义分割准确率。

图2 多特征融合模块
1.3.1几何特征提取


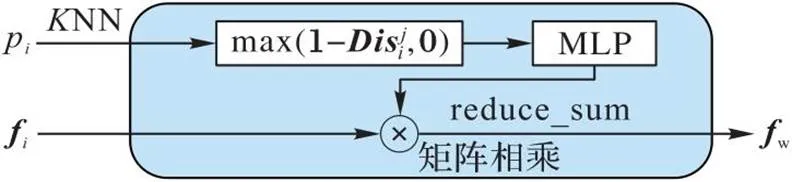
图3 权重计算模块
1.3.2局部语义特征提取


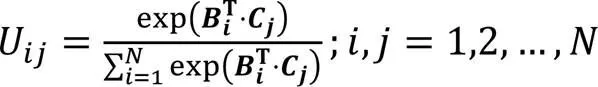
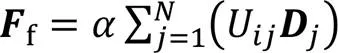

图4 空间注意力模块示意图
1.3.3空间语义分布特征提取
为了进一步提取特征在高维空间的分布情况,本文对边特征及其近邻边特征间的差值应用MLP,以提取语义特征的空间分布信息,提高网络对语义特征的感知能力。

1.3.4特征融合



2 实验与结果分析
2.1 实验数据与评价指标
本文利用两个公共的大规模三维场景数据集S3DIS(Stanford 3D large-scale Indoor Spaces)[14]和Sematic3D[15]测试MFF-Net的性能。S3DIS数据集由6个子区域共272个室内场景数据组成,每个场景的点云数量从50万到250万不等,包括三维坐标、颜色信息和归一化的三维坐标,其中每个点都被标记为13个类别中的某一类别。Semantic3D数据集由定点激光扫描仪获得,共40多亿个点,包含广场、市政厅和农场等多个场景数据,由15个训练集和15个测试集组成,该数据被标记为8个类别,原始点云数据包含三维坐标、颜色信息和强度信息。
本文实验运行环境为64位Linux操作系统,Intel i7 8700处理器、48 GB内存、RTX2080显卡。训练时batchsize设置为2,训练轮次(epoch)设置为100,损失函数选用为交叉熵函数,采用Adam作为优化器,初始学习率设置为0.01,每个epoch的衰减率为5%,全连接层中的dropout参数设置为0.5。
为了评估MFF-Net的有效性,本文采用平均交并比 (mean Intersection over Union, mIoU)、平均准确率(mean Accuracy, mAcc)和总体准确率(Overall Accuracy, OA)作为评估标准。计算公式分别为:



2.2 实验结果及分析
1)S3DIS数据集。
本文分别采用6折交叉验证和单独将Area5作为测试数据对MFF-Net进行评估,6折交叉验证是将数据分为6个部分,将每个部分的场景数据分别作为测试集进行训练和测试,以体现网络的泛化能力,由于Area5数据中包含的物体与其他5个区域存在差异,可评估网络的可推广性。
表1为不同网络模型利用6折交叉验证在S3DIS数据集上的语义分割结果。

表1 在S3DIS数据集上的6折交叉验证语义分割结果 单位:%
从表1结果可以看出,对于mAcc,本文网络模型比PointNet[2]高出13.8个百分点,比RSNet(Recurrent Slice Network)[16]高出13.5个百分点,比SPG(SuperPoint Graph)[17]高出7.0个百分点,比PointWeb[18]、GFSOP-Net(Geometric Feature Sensing Of Point Network)[21]和BAAFNet(Bilateral Augmentation and Adaptive Fusion Network)[23]分别高3.8、9.0和0.6个百分点;对于OA,本文网络模型相较于PointNet提高了8.6个百分点,比SPG高0.8个百分点,比DGCNN[6]高2.9个百分点,相较于MPNet(Memory-augmented Network)[19]和BAAFNet[23]提高了0.4和0.1个百分点;对于mIoU,本文网络模型比PointNet高19.9个百分点,比Octant-CNN(Octant Convolutional Neural Network)[20]高9.2个百分点,比AMFF-DGCNN(Attention based Multi-Feature Fusion DGCNN)[22]高7.6个百分点,相较于其他模型提高0.8~11.0个百分点。表1中第5~17列分别代表不同类别物体(例如:桌子、椅子、沙发等)的分割准确率,可以看出,MFF-Net在地板、柱、桌子、书柜、黑板和杂物这6类物体取得了最高的分割准确率。
表2为MFF-Net将Area5作为测试集的语义分割结果。MFF-Net在mIoU上比PointNet高了21.91个百分点,比SegCloud(Semantic segmentation of 3D point Clouds)高14.1个百分点,比DGCNN、PointWeb和BAAFNet[23]分别高15.4、2.7和0.7个百分点。在OA方面,MFF-Net比DGCNN高3.8个百分点,相较于其他网络模型高出0.1~2.5个百分点。在mAcc指标上,MFF-Net比PointWeb和BAAFNet分别高5.8和1.2个百分点(其中BAAFNet的实验结果是在相同硬件环境和参数下运行得到的)。

表2 S3DIS数据集上的Area5语义分割结果 单位:%
图5为MFF-Net与BAAFNet在S3DIS数据集上的可视化结果。在场景1中,MFF-Net分割得到的墙面黑板相较于BAAFNet更准确,且桌腿也分割得更准确;在场景2中,MFF-Net能够较好地分割场景中的椅子,相较于BAAFNet,墙面和黑板的分割效果更完整;在场景3中,BAAFNet错误地将大区域墙面分类为其他物体,而MFF-Net则较完整地分割出了整块的门板;在场景4中,BAAFNet错误地将大片的柜子和木板分为一类,MFF-Net则清晰地将两者分开。相较于BAAFNet,MFF-Net在S3DIS数据集上能得到更好的分割效果,这主要得益于所提出的多特征提取模块能较好地降低近邻点的歧义信息影响。
2)Semantic3D数据集。
为了进一步验证MFF-Net的有效性,将该网络在Semantic3D数据集上进行训练和测试。由于实验设备的局限性,本文将输入点数调整为28 672,batchsize设置为2。由表3可知,在同等参数的情况下,相较于BAAFNet,MFF-Net的OA和mIoU上分别提升了9.3和13.2个百分点;对于除汽车外的其他7个类别的分割准确率也都有所提升。实验结果表明,与BAAFNet相比,本文所提MFF-Net能更好地聚合特征信息,提升了网络对大型点云场景的分割准确率。

表3 Semantic3D(semantic-8)数据集上的语义分割结果 单位:%
图6为利用BAAFNet与MFF-Net在Semantic3D数据集上分割结果对比。在场景5中,BAAFNet错误地将建筑物分割成人造景观的黄色,且将树木分割成了道路,而本文模型则很好地分割建筑物和树木;在场景6中,BAAFNet将部分建筑的屋顶错分为扫描伪影,而MFF-Net完整地识别出了建筑物;在场景7中,BAAFNet将汽车分割成了人造景观,而MFF-Net将汽车正确分割成了代表汽车的红色。可以看出,相较于BAAFNet,MFF-Net能较好地分割室外点云场景。
2.3 消融实验
为了验证不同模块对网络的重要性,本文在S3DIS数据集中的Area5数据上进行消融实验,针对改进后的边特征模块、权重计算模块、空间注意力模块和空间语义分布特征模块进行实验验证,探究每个模块对实验结果的影响(如表4所示)。

表4 消融实验结果
根据表4可知,加入改进后边特征模块后,增加了几何特征信息,解决了网络的初始输入特征的几何信息不足的问题,mAcc达到了71.3%;加入邻域权重计算模块后,有效去除冗余信息,增加了显著特征的比重,网络模型的分割准确率提升了0.3个百分点;引入空间注意力机制后,有效提取了特征之间相关性,增强了网络的全局特征表示,网络模型的分割准确率提升至72.2%。为了进一步提高网络对于语义特征的感知能力,融合空间语义分布特征模块,网络模型的分割准确率达到72.4%。

图5 S3DIS数据集上BAAFNet和MFF-Net的语义分割结果

图6 Semantic3D数据集上BAAFNet和MFF-Net的语义分割效果
3 结语
本文提出了一种基于多特征融合的点云场景语义分割网络MFF-Net。在三维坐标的基础上,计算几何偏移量强化局部几何特征,提高网络对几何特征的表征能力;在计算边特征的基础上,构造权重计算模块,按权重信息融合边特征,并引入空间注意力机制,提取特征间的全局依赖关系;在高维空间计算边特征与邻域边特征间的差值,利用均值池化操作提取空间语义分布特征。实验结果表明,MFF-Net在室内场景S3DIS和室外场景Sematic3D两个数据集上均取得较好的语义分割效果。该网络适用于处理大规模室内/室外点云场景数据,可以用于构建环境语义地图,为移动机器人提供用于理解周围环境的高层语义信息,实现位置定位,提高移动机器人的场景理解能力。
然而,MFF-Net是在固定邻域中计算点的几何特征和空间语义分布特征,易受点云数据的密度影响,因此,根据点云数据的密度自动设定邻域值,以提高点云分割的准确率是下一步工作的重点。
[1] GUO Y, WANG H, HU Q, et al. Deep learning for 3D point clouds: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(12): 4338-4364.
[2] QI C R, SU H, MO K, et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 77-85.
[3] QI C R, YI L, SU H, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 5105-5114.
[4] HU Q, YANG B, XIE L, et al. RandLA-Net: efficient semantic segmentation of large-scale point clouds[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 11105-11114.
[5] XU M, DING R, ZHAO H, et al. PAConv: position adaptive convolution with dynamic kernel assembling on point clouds[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 3172-3181.
[6] WANG Y, SUN Y, LIU Z, et al. Dynamic graph CNN for learning on point clouds[J]. ACM Transactions on Graphics, 2019, 38(5): No.146.
[7] ZHANG K, HAO M, WANG J, et al. Linked dynamic graph CNN: learning on point cloud via linking hierarchical features[EB/OL]. (2019-08-06)[2022-11-12].https://arxiv.org/pdf/1904.10014.pdf.
[8] CHEN L, ZHANG Q. DDGCN: graph convolution network based on direction and distance for point cloud learning[J]. The Visual Computer, 2023, 39(3): 863-873.
[9] DU Z, YE H, CAO F. A novel local-global graph convolutional method for point cloud semantic segmentation[J]. IEEE Transactions on Neural Networks and Learning Systems, 2022(Early Access): 1-15.
[10] CHEN C, FRAGONARA L Z, TSOURDOS A. GAPNet: graph attention based point neural network for exploiting local feature of point cloud[EB/OL]. (2019-05-21) [2022-11-12].https://arxiv.org/pdf/1905.08705.pdf.
[11] CHEN L, CHEN W, XU Z, et al. DAPnet: a double self-attention convolutional network for point cloud semantic labeling[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2021, 14: 9680-9691.
[12] DENG S, DONG Q. GA-NET: global attention network for point cloud semantic segmentation[J]. IEEE Signal Processing Letters, 2021, 28: 1300-1304.
[13] CHEN Q, ZHANG Z, CHEN S, et al. A self-attention based global feature enhancing network for semantic segmentation of large-scale urban street-level point clouds[J]. International Journal of Applied Earth Observation and Geoinformation, 2022, 113: No.102974.
[14] ARMENI I, SENER O, ZAMIR A R, et al. 3D semantic parsing of large-scale indoor spaces[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1534-1543.
[15] HACKEL T, SAVINOV N, LADICKY L, et al. Semantic3D.net: a new large-scale point cloud classification benchmark[J]. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2017, IV-1/W1: 91-98.
[16] HUANG Q, WANG W, NEUMANN U. Recurrent slice networks for 3D segmentation of point clouds[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 2626-2635.
[17] LANDRIEU L, SIMONOVSKY M. Large-scale point cloud semantic segmentation with superpoint graphs[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4558-4567.
[18] ZHAO H, JIANG L, FU C W, et al. PointWeb: enhancing local neighborhood features for point cloud processing[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 5560-5568.
[19] HE T, GONG D, TIAN Z, et al. Learning and memorizing representative prototypes for 3D point cloud semantic and instance segmentation[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12363. Cham: Springer, 2020: 564-580.
[20] 许翔,帅惠,刘青山. 基于卦限卷积神经网络的3D点云分析[J]. 自动化学报, 2021, 47(12):2791-2800.(XU X, SHUAI H, LIU Q S. Octant convolutional neural network for 3D point cloud analysis[J]. Acta Automatica Sinica, 2021, 47(12):2791-2800.)
[21] 鲁斌,柳杰林. 基于特征增强的三维点云语义分割[J]. 计算机应用, 2023, 43(6):1818-1825.(LU B, LIU J L. Semantic segmentation for 3D point clouds based on feature enhancement[J]. Journal of Computer Applications, 2023, 43(6):1818-1825.)
[22] 郝雯,王红霄,汪洋. 结合空间注意力与形状特征的三维点云语义分割[J]. 激光与光电子学进展, 2022, 59(8): No.0828004.(HAO W, WANG H X, WANG Y. Semantic segmentation of three-dimensional point cloud based on spatial attention and shape feature[J]. Laser and Optoelectronics Progress, 2022, 59(8): No.0828004)
[23] QIU S, ANWAR S, BARNES N. Semantic segmentation for real point cloud scenes via bilateral augmentation and adaptive fusion[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 1757-1767.
[24] TCHAPMI L, CHOY C, ARMENI I, et al. SEGCloud: semantic segmentation of 3D point clouds[C]// Proceedings of the 2017 International Conference on 3D Vision. Piscataway: IEEE, 2017: 537-547.
Semantic segmentation of point cloud scenes based on multi-feature fusion
HAO Wen*, WANG Yang, WEI Hainan
(,’,’710048,)
In order to mine the semantic relationships and spatial distribution among features, and further improve the semantic segmentation results of point cloud through multi-feature enhancement, a Multi-Feature Fusion based point cloud scene semantic segmentation Network (MFF-Net) was proposed. In the proposed network, the 3D coordinates and improved edge features were used as input, firstly, the neighbor points of the point were searched by using-Nearest Neighbor (NN) algorithm, and the geometric offsets were calculated based on 3D coordinates and coordinate differences among neighbor points, which enhanced the local geometric feature representation of points. Secondly, the distance between the central point and its neighbor points were used to as weighting information to update the edge features, and the spatial attention mechanism was introduced to obtain the semantic information among features. Thirdly, the spatial distribution information among features was further extracted by calculating the differences among neighbor features and using mean pooling operation. Finally, the trilateral features were fused based on attention pooling. Experimental results demonstrate that on S3DIS (Stanford 3D large-scale Indoor Spaces) dataset, the mean Intersection over Union (mIoU) of the proposed network is 67.5%, and the Overall Accuracy (OA) of the proposed network is 87.2%. These two values are 10.2 and 3.4 percentage points higher than those of PointNet++ respectively. It can be seen that MFF-Net can achieve good segmentation results in both large indoor and outdoor scenes.
point cloud; semantic segmentation; spatial attention; attention pooling; feature fusion
This work is partially supported by National Natural Science Foundation of China (61602373), Natural Science Foundation of Shaanxi Province (2021JM-342), Xi’an BeiLin Science Research Plan (GX2242).
HAO Wen, born in 1986, Ph. D., associate professor. Her research interests include point cloud scene segmentation and recognition.
WANG Yang,born in 1998, M. S. candidate. His research interests include point cloud scene segmentation.
WEI Hainan, born in 1998, M. S. candidate. Her research interests include point cloud scene segmentation.
1001-9081(2023)10-3202-07
10.11772/j.issn.1001-9081.2023020119
2023⁃02⁃15;
2023⁃04⁃03;
国家自然科学基金资助项目(61602373);陕西省自然科学基金资助项目(2021JM-342);西安市碑林区研发项目(GX2242)。
郝雯(1986—),女,河南平顶山人,副教授,博士,CCF会员,主要研究方向:点云场景分割和识别; 汪洋(1998—),男,安徽合肥人,硕士研究生,主要研究方向:点云场景分割; 魏海南(1998—),女,河北承德人,硕士研究生,主要研究方向:点云场景分割。
P391.41
A
2023⁃04⁃07。
