基于BERT模型的文本对抗样本生成方法
2023-10-21李宇航杨玉丽马垚于丹陈永乐
李宇航,杨玉丽,马垚,于丹,陈永乐
基于BERT模型的文本对抗样本生成方法
李宇航,杨玉丽,马垚,于丹,陈永乐*
(太原理工大学 计算机科学与技术学院(大数据学院),太原 030600)( ∗ 通信作者电子邮箱chenyongle@tyut.edu.cn)
针对现有对抗样本生成方法需要大量访问目标模型,导致攻击效果较差的问题,提出了基于BERT (Bidirectional Encoder Representations from Transformers)模型的文本对抗样本生成方法(TAEGM)。首先采用注意力机制,在不访问目标模型的情况下,定位显著影响分类结果的关键单词;其次通过BERT模型对关键单词进行单词级扰动,从而生成候选样本;最后对候选样本进行聚类,并从对分类结果影响更大的簇中选择对抗样本。在Yelp Reviews、AG News和IMDB Review数据集上的实验结果表明,相较于攻击成功率(SR)次优的对抗样本生成方法CLARE(ContextuaLized AdversaRial Example generation model),TAEGM在保证对抗攻击SR的前提下,对目标模型的访问次数(QC)平均减少了62.3%,时间平均减少了68.6%。在此基础之上,进一步的实验结果验证了TAEGM生成的对抗样本不仅具有很好的迁移性,还可以通过对抗训练提升模型的鲁棒性。
对抗样本;注意力机制;BERT;对抗攻击;聚类算法
0 引言
针对机器学习模型容易受到对抗样本威胁的问题[1],国内外学者开展了关于对抗样本生成技术的深入研究,并取得一系列的研究成果。目前的研究主要集中在图像领域[2],涉及文本领域的研究较少[3-4]。原因主要为以下两方面:1)文本领域中单词的离散属性。与具备连续性的图像空间不同,句子中的单词是离散的,在图像领域,像素级别的改变并不会影响图片表达的意思;而在文本领域,任意单词的替换却会改变语句整体的含义。2)语法要求。单词的改变可能会使修改后的语句出现语法错误,使对抗样本很容易被发现[5-6]。
目前,在文本领域中,典型的对抗技术为基于同义词替换的单词级对抗样本生成技术。该技术是基于本地的打分函数,挑选出句子中对分类结果影响最大的关键单词,通过处理这些关键单词,产生单词级别的扰动生成对抗样本。但是这种技术依然存在以下问题:1)在打分函数的处理过程中,需要将相关单词替换为无意义的占位符标签,导致输入文本的语义被改变,在此情况下,打分函数的输出无法代表相关单词的重要性[7]。2)打分函数的处理过程需要大量访问目标模型,但实际应用中的模型,对访问次数(Query Counts, QC)都有一定的限制,在此情况下,采用传统方法攻击这些模型会受到很大的限制,生成对抗样本的效率会大幅降低。因此在保证攻击成功率(Success Rate, SR)的前提下,减少对目标模型的访问次数是亟须解决的问题。
针对上述问题,本文提出一种基于BERT(Bidirectional Encoder Representations from Transformers)模型[8]的对抗样本生成方法(Text Adversarial Examples Generation Method based on BERT model, TAEGM)。TAEGM采用了基于注意力机制的关键单词定位技术,基于BERT模型的单词级扰动生成技术和基于聚类算法的候选样本筛选技术,在保证对抗攻击成功率的前提下,可以有效地减少对目标模型的访问次数。
1 相关工作
Kuleshov等[9]和Alzantot等[10]分别提出了基于贪婪搜索的同义词替换攻击算法,这种算法通过尽可能多地替换句子中单词为它的同义词,以生成对抗样本;但是通过这种方法生成的对抗样本的语义会发生较大的改变,也会产生语法错误。在此基础上,Ren等[11]提出了一种新型算法PWWS(Probability Weighted Word Saliency),该算法在选择关键单词时采用的打分函数[12]不仅考虑了单词在句子中的重要程度,还考虑了原始输入和对抗样本对模型分类结果的影响,但算法生成的对抗样本进行攻击的成功率较低。仝鑫等[13]提出了一种词级黑盒对抗样本生成方法CWordAttacker,该方法采用定向词删除评分机制,可完成定向和非定向两种攻击模式。Maheshwary等[14]提出了一种基于决策的攻击策略,引入基于种群的优化算法,进一步提高了对抗样本的质量。虽然上述方法较好地提升生成效果,但在面对基于BERT的模型时依然存在有很大的改进空间。因此,Li等[15]将BERT引入了基于同义词替换的对抗样本生成算法中,该算法在寻找单词的同义词时,通过BERT模型根据关键单词的上下文生成最符合语法和语义的替代词。然而上述方法都没有很好地协调访问模型次数和攻击成功率之间的关系。
2 对抗样本生成方法
2.1 TAEGM的框架
本文提出一种基于BERT模型的对抗样本生成方法TAEGM,在保证攻击成功率的前提下,显著减少针对目标模型的访问次数。如图1所示,TAEGM框架主要分为3部分:
1)关键单词定位。使用BERT自带的注意力矩阵,采用基于注意力机制的关键单词定位技术,定位输入文本中对分类影响最大的关键单词。
2)生成单词级扰动。使用BERT模型生成上下文相关的单词级扰动,产生候选的对抗样本。
3)对抗样本生成。通过基于聚类算法的候选样本筛选技术,缩小候选样本的范围,选择对分类影响最大的簇,在该簇中挑选最终的对抗样本。

图1 对抗样本生成示意图
2.2 TAEGM具体流程
2.2.1关键单词定位
为了得到高质量的对抗样本,必须对语句中的关键单词或关键词组扰动。因此,本节聚焦于在不访问目标模型的情况下,通过注意力机制定位语句中的关键单词。



最后,在得到文本中所有单词的重要性分数后,将分数最大的前个单词选为关键单词。特别地,不是每次单独给一个单词打分,而是在一次遍历中给所有的单词打分。这样就实现了在不需要访问目标模型的情况下,准确定位关键单词的位置,从而显著减少对目标模型的访问。
另一方面,随着的增大,对抗攻击的成功率、对目标模型的访问次数也随之增加,对抗样本的语义相似度会下降,句子中改变的单词数也会增加,这就导致攻击效率下降和生成的对抗样本质量变差,所以的选择需要在对抗攻击的成功率与对抗样本的质量之间权衡。
2.2.2生成单词级扰动
因为关键单词对模型分类的贡献大于其他单词,所以本文通过对它们进一步处理,即对原始文本添加扰动从而欺骗目标模型。同时,为了生成高质量的对抗样本,保证对抗样本在语义和视觉效果上和原始文本相似,本文采用单词级的扰动。单词级的扰动是指在不改变文本语义的情况下,将单词替换为它在嵌入空间中距离最近的单词,并且这种操作可以使得模型产生错误的输出。
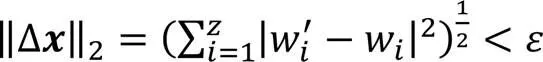
在生成候选样本后,使用语义过滤机制过滤与原始文本语义差异过大的候选样本,减小候选样本的范围,如式(5)所示:

2.2.3对抗样本生成
使用BERT对定位的关键单词完成单词级扰动之后,会生成大量的候选样本。检验所有的候选样本需要大量地访问目标模型,因此本节通过有效缩小候选样本的范围,进一步提高算法的性能。
因为属于同一类的句子在高维的编码空间中的距离很近,使得它们对模型分类结果造成的影响也很相似,所以可以使用聚类算法分类,将针对所有候选样本的操作转换为针对一个子集合的操作,从而显著减少候选样本的数量,减少针对目标模型的访问次数。
此外,每次需要处理的候选样本数量只有几千个,属于样本数较少的情况,传统的-means++算法收敛快、可解释性强,聚类效果较好,所以本文采用该算法聚类。
聚类候选样本后,如果在每个簇中选择具有代表性的样本,需要处理不同簇中的所有候选样本,这种方法虽然可以缩小候选样本的范围,但需要大量访问目标模型,导致算法性能下降。考虑到簇中所有样本都可以对模型造成相似的影响,可以随机选择簇中的一个样本代表整个簇,再通过打分函数选择最优的簇作为候选样本集,该方法只需要很少地访问目标模型,就可以有效缩小候选样本的范围。通过实验可以发现,前一种方法所需要的访问次数远多于后一种,并且两种方法得到的候选样本集合在实验中的效果很相似,因此本文选择后一种方法。

最后,进一步处理候选样本,如果其中的样本可以改变模型的输出,则将它选为对抗样本;如果不能改变,则重复上述步骤。通过上述步骤生成的对抗样本可以大幅减少访问模型的次数,并且每个关键单词也只会进行一种单词级的扰动,且不影响其他位置的操作。
与传统的算法相比,TAEGM的优势主要体现在以下3方面:1)采用注意力机制,可以在不访问目标模型的情况下,准确定位关键单词的位置;2)通过BERT模型,在只改变关键单词的情况下生成候选样本;3)在处理候选样本时,采用聚类技术聚类候选样本,将针对所有候选样本的操作转换为针对一个样本子集合的操作,再从中选择最合适的样本进行后续的操作,显著减少候选样本的数量,从而减少了对目标模型的访问次数。TAEGM的具体实现过程如算法1所示。
算法1 TAEGM。
4) end for
11) end if
12) end for
18) end if
3 实验与结果分析
3.1 实验设置
3.1.1实验平台及测试数据集
实验框架中采用的BERT版本是RoBERTa-distill[16],RoBERTa-distill是RoBERTa[17]的蒸馏版本;语义过滤机制采用USE(Universal Sentence Encoder)[18]。
本文实验的服务器配置为内存64 GB,机械硬盘1 TB,1块32 GB显存的HPE NVIDIA Tesla V100PCIe GPU和4块Intel Xeon Gold 6226R CPU。
实验采用以下3个数据集,数据集的详细信息如表1所示。
1)Yelp Reviews[19]。该数据集是一个二元情感分类的数据集,包含了正面和负面两个标签。
2)AG News。该数据集包括超过2 000篇新闻源的新闻文章,数据集仅仅援用了标题和描述字段。
3)IMDB Review[20]。该数据集包括50 000条情感二元分布的评论。

表1 三个数据集的详细信息
3.1.2对比方法
本文的对比方法如下:
1)Textfooler[21]。该方法的评分函数会处理原始文本,通过删掉单词前后得到的分数置信度的变化程度计算该单词的重要程度,找出关键单词,再将该关键词替换为同义词生成对抗样本。
2)TextHoaxer[22]。在生成对抗样本的过程中使用扰动矩阵优化框架,提高了生成对抗样本的效率。
3)CLARE(ContextuaLized AdversaRial Example generation model)[23]。对文本中的单词采用BERT模型生成扰动,再通过访问目标模型确定对抗样本是否合格。
3.1.3评价指标
1)攻击成功率(SR)。对抗样本可以成功攻击目标模型的概率,如式(7)所示:

2)目标模型的访问次数(QC):




5)生成1 000个对抗样本消耗的时间。
6)精确率(ACCuraacy, ACC):预测正确的样本数占总样本数的比例。计算公式如下:

以上各指标中,SR、Sim、SCR和ACC的值越大性能越好;QC和时间越小,性能越好。
3.2 对比实验分析
实验采用将本文方法和3种对比方法,在Yelp Reviews、AG News和IMDB Review数据集上生成1 000个对抗样本,攻击BERT base-uncased的分类器,实验结果如表2所示。
从表2中可以看出,相较于其他对比方法,TAEGM具有最好的综合性能。在Yelp Reviews数据集上,使用TAEGM进行攻击的SR达到了89.9%,相较于Textfooler、TextHoaxer和CLARE分别提高了15.6%、15.3%和14.2%;同时TAEGM的Sim和SCR也是所有算法中最优的;而在QC和时间这两项指标上,TAEGM仅次于Textfooler。可以看出,TAEGM可以通过注意力机制,能够准确定位语句中的关键单词并进行处理,使得生成的对抗样本具有很高的质量。在AG New数据集上,TAEGM的SR、SCR和Sim全都优于其他对比算法,并且QC和时间也是所有算法中的次优结果。在IMDB Review数据集上,相较于CLARE,TAEGM的SR降低了1.0%,但是QC和时间降低了55.6%和62.9%,并且Sim和SCR达到了最优结果。由此可以看出TAEGM通过聚类算法,可以在只使用较少QC和时间的情况下高效地确定候选样本,从而提高生成对抗样本的效率。
从表2中还可以看出,在3个数据集上,Textfooler的QC和时间都少于TAEGM,这是因为Textfooler相当于只使用了本文的BERT_Replace扰动,最后得到候选样本数较少,质量较差,因此所需要的QC和Time也较少;但相应地,Textfooler的攻击效果弱于TAEGM。

表2 四种方法在3个数据集上进行对抗攻击的性能比较
注:加粗数据为最优值,下划线数据为次优值。
综上所述,TAEGM具有所有算法中最好的综合性能,相较于SR次优的CLARE,TAEGM的QC平均减少了62.3%,时间平均减少了68.6%。
3.3 对抗样本示例
表3展示了在Yelp Reviews数据集上TAEGM生成的对抗样本。所有的原始文本都只需要非常小的扰动就可以生成对抗样本,从而误导目标模型BERT,使它输出错误的分类结果,并且对抗样本和原始文本的语义非常相似。

表3 在BERT上利用TAEGM生成的对抗样本展示
注:斜体表示TAEGM生成的3种扰动;“()”内是原始文本;“【】”内则标注了进行的扰动。
4 综合性能分析
4.1 超参数k对攻击结果的影响
关键单词范围是算法中的主要参数,的选取对攻击的结果具有很大的影响,因此,在3个数据集上分别生成150个对抗样本进行实验,实验结果如图2所示。

图2 关键单词的范围k对不同指标的影响
由图2(a)可知,SR先随着的增大而迅速增大,当>20后,SR的增长变慢,表明关键单词的主要分布范围为≤20。通常认为随着的增大,对抗样本中发生改变的单词数会增加,而文本的Sim也会大幅下降,但如图2(b)~(c)所示,当>20后,这两个指标都只发生了很小的改变。在Yelp Reviews数据集上,Sim保持在[0.781,0.787],SCR也保持在[9.3,9.9],说明此时选择的关键单词都很合理,所以Sim和SCR呈现趋于平缓的趋势。从图2(d)可知,QC与的取值正相关。综上,通过图2可知,当=20时,在保证攻击效率和对抗样本质量的情况下,TAEGM可以达到较高的攻击成功率。
4.2 对抗样本迁移性
本节采用了3个在Yelp Reviews数据集上训练的自然语言处理模型:TEXTCNN1、TEXTCNN2和BERT。其中:TEXTCNN1含有1个输入层/3个并行的卷积层(卷积核大小分别为3、4、5)、3个并行的最大池化层和1个全连接层;TEXTCNN2相较于TEXTCNN1增加了1个全连接层。为了验证TAEGM生成的对抗样本的迁移性,在Yelp Reviews数据集上,使用TAEGM和上述模型生成对抗样本,再使用这些对抗样本分别攻击这3个模型,结果见表4。
从表4可以看出,由TEXTCNN1生成的对抗样本,在攻击TEXTCNN2和BERT模型的SR仍达到了68.7%和65.3%。而由BERT模型生成的对抗样本,攻击TEXTCNN1和TEXTCNN2模型时的SR仍然达到了74.6%和72.9%。这表明由TAEGM生成的对抗样本可以在多个模型之间进行迁移攻击,具有一定的迁移性。
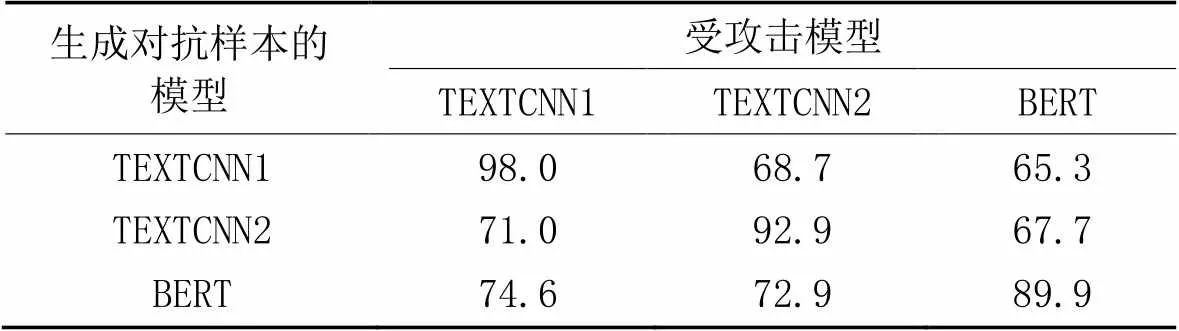
表4 在Yelp Reviews数据集上的迁移攻击成功率 单位:%
4.3 对抗训练
为了验证本文方法是否可以通过对抗训练提升模型的鲁棒性。在3个数据集上通过将生成的对抗样本加入训练集中,训练得到新的基于BERT base-uncased的分类器,其中由于Yelp Reviews数据集和AG News数据集较大,本文只选择了其中一部分数据进行实验,表5为实验结果。
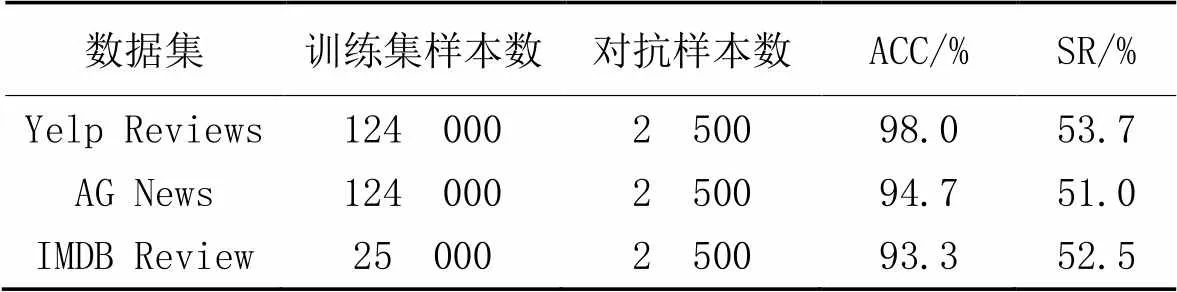
表5 TAEGM在3个数据集上对抗训练的结果
如表5所示,在Yelp Reviews数据集上训练模型时,在原始大小为124 000的训练集中加入2 500个对抗样本,经过对抗训练后得到模型的ACC为98.0%;接着使用TAEGM攻击该模型,只实现53.7%的SR,远低于表2中的数据。而在AG News数据集和IMDB Review数据集上进行对抗训练时,SR只有51.0%和52.5%。可以看出模型使用TAEGM生成的对抗样本进行对抗训练后,与表2相比可以有效降低攻击的SR,这表明了对抗训练可以提高模型防御对抗样本的能力,即有效提升了模型的鲁棒性。
5 结语
本文提出了一种基于BERT模型的对抗样本生成方法TAEGM。该方法首先通过注意力机制定位句子中的关键单词,通过BERT在这些关键单词的位置生成单词级的扰动,生成候选样本;其次,通过聚类选择对分类结果影响大的候选样本,得到高质量的对抗样本。通过大量的实验结果表明了本文方法可以将降低访问目标模型的次数,同时具有较高的攻击效率和攻击成功率。此外,还验证了生成的对抗样本不但具有很好的迁移性,还可以通过对抗训练的方式提升模型的鲁棒性。在未来的工作中,需要进一步改进算法,使得针对目标模型的访问次数进一步下降,同时可以对文本分类模型进行定向攻击,进一步提升算法的性能和灵活性。
[1] PAPERNOT N, McDANIEL P, SWAMI A, et al. Crafting adversarial input sequences for recurrent neural networks[C]// Proceedings of the 2016 IEEE Military Communications Conference. Piscataway: IEEE, 2016: 49-54.
[2] SAMANGOUEI P, KABKAB M, CHELLAPPA R, et al. Defense-GAN: protecting classifiers against adversarial attacks using generative models[EB/OL]. (2018-05-18) [2022-07-13].https://arxiv.org/pdf/1805.06605.pdf.
[3] 潘文雯,王新宇,宋明黎,等. 对抗样本生成技术综述[J]. 软件学报, 2020, 31(1):67-81.(PAN W W, WANG X Y, SONG M L, et al. Survey on generating adversarial examples[J]. Journal of Software, 2020, 31(1): 67-81.)
[4] 王文琦,汪润,王丽娜,等. 面向中文文本倾向性分类的对抗样本生成方法[J]. 软件学报, 2019, 30(8):2415-2427.(WANG W Q, WANG R, WANG L N, et al. Adversarial examples generation approach for tendency classification on Chinese texts[J]. Journal of Software, 2019, 30(8): 2415-2427.)
[5] LI J, JI S, DU T, et al. TextBugger: generating adversarial text against real-world applications[C]// Proceedings of the 26th Annual Network and Distributed System Security Symposium. Reston, VA: Internet Society, 2019: No.23138.
[6] SONG L, YU X, PENG H T, et al. Universal adversarial attacks with natural triggers for text classification[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2021: 3724-3733.
[7] MAHESHWARY R, MAHESHWARY S, PUDI V. A strong baseline for query efficient attacks in a black box setting[C]// Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2021: 8396-8409.
[8] DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]// Proceedings of the2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Stroudsburg, PA: ACL, 2019: 4171-4186.
[9] KULESHOV V, THAKOOR S, LAU T, et al. Adversarial examples for natural language classification problems[EB/OL]. [2022-07-13].https://openreview.net/pdf?id=r1QZ3zbAZ.
[10] ALZANTOT M, SHARMA Y, ELGOHARY A, et al. Generating natural language adversarial examples[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2018: 2890-2896.
[11] REN S, DENG Y, HE K, et al. Generating natural language adversarial examples through probability weighted word saliency[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2019: 1085-1097.
[12] GARG S, RAMAKRISHNAN G. BAE: BERT-based adversarial examples for text classification[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural. Stroudsburg, PA: ACL, 2020: 6174-6181.
[13] 仝鑫,王罗娜,王润正,等. 面向中文文本分类的词级对抗样本生成方法[J]. 信息网络安全, 2020, 20(9):12-16.(TONG X, WANG L N, WANG R Z, et al. A generation method of word-level adversarial samples for Chinese text classification[J]. Netinfo Security, 2020, 20(9):12-16.)
[14] MAHESHWARY R, MAHESHWARY S, PUDI V. Generating natural language attacks in a hard label black box setting[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 13525-13533.
[15] LI L, MA R, GUO Q, et al. BERT-ATTACK: adversarial attack against BERT using BERT[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: ACL, 2020: 6193-6202.
[16] MA X, ZHOU C, LI X, et al. FlowSeq: non-autoregressive conditional sequence generation with generative flow[C]// Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: ACL, 2019: 4282-4292.
[17] LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. (2019-07-26) [2022-07-13].https://arxiv.org/pdf/1907.11692.pdf.
[18] CER D, YANG Y, KONG S Y, et al. Universal sentence encoder for English[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Stroudsburg, PA: ACL, 2018: 169-174.
[19] ZHANG X, ZHAO J, LeCUN Y. Character-level convolutional networks for text classification[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems — Volume 1. Cambridge: MIT Press, 2015:649-657.
[20] MAAS A L, DALY R E, PHAM P T, et al. Learning word vectors for sentiment analysis[C]// Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2011:142-150.
[21] JIN D, JIN Z, ZHOU J T, et al. Is BERT really robust? natural language attack on text classification and entailment[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 8018-8025.
[22] YE M, MIAO C, WANG T, et al. TextHoaxer: budgeted hard-label adversarial attacks on text[C]// Proceedings of the 36th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2022: 3877-3884.
[23] LI D, ZHANG Y, PENG H, et al. Contextualized perturbation for textual adversarial attack[C]// Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2020: 5053-5069.
Text adversarial example generation method based on BERT model
LI Yuhang, YANG Yuli, MA Yao, YU Dan, CHEN Yongle*
((),,030600,)
Aiming at the problem that the existing adversarial example generation methods require a lot of queries to the target model, which leads to poor attack effects, a Text Adversarial Examples Generation Method based on BERT (Bidirectional Encoder Representations from Transformers) model (TAEGM) was proposed. Firstly, the attention mechanism was adopted to locate the keywords that significantly influence the classification results without query of the target model. Secondly, word-level perturbation of keywords was performed by BERT model to generate candidate adversarial examples. Finally, the candidate examples were clustered, and the adversarial examples were selected from the clusters that have more influence on the classification results. Experimental results on Yelp Reviews, AG News, and IMDB Review datasets show that compared to the suboptimal adversarial example generation method CLARE (ContextuaLized AdversaRial Example generation model) on Success Rate (SR), TAEGM can reduce the Query Counts (QC) to the target model by 62.3% and time consumption by 68.6% averagely while ensuring the SR of adversarial attacks. Based on the above, further experimental results verify that the adversarial examples generated by TAEGM not only have good transferability, but also improve the robustness of the model through adversarial training.
adversarial example; attention mechanism; BERT (Bidirectional Encoder Representations from Transformers); adversarial attack; clustering algorithm
This work is partially supported by Basic Research Program of Shanxi Province (20210302123131, 20210302124395).
LI Yuhang, born in 1998, M. S. candidate. His research interests include artificial intelligence.
YANG Yuli, born in 1979, Ph. D., lecturer. Her research interests include trusted cloud service computing, blockchain.
MA Yao, born in 1982, Ph. D., lecturer. His research interests include Web security.
YU Dan, born in 1988, Ph. D. Her research interests include wireless sensor network, internet of things.
CHEN Yongle, born in 1983, Ph. D., professor. His research interests include internet of things security.
1001-9081(2023)10-3093-06
10.11772/j.issn.1001-9081.2022091468
2022⁃10⁃08;
2023⁃02⁃19;
山西省基础研究计划项目(20210302123131,20210302124395)。
李宇航(1998—),男,山西临汾人,硕士研究生,CCF会员,主要研究方向:人工智能; 杨玉丽(1979—),女,山西临汾人,讲师,博士,CCF会员,主要研究方向:可信云服务计算、区块链; 马垚(1982—),男,山西太原人,讲师,博士,CCF会员,主要研究方向:Web安全; 于丹(1988—),女,北京人,博士,CCF会员,主要研究方向:无线传感网络、物联网; 陈永乐(1983—),男,山西太原人,教授,博士,CCF会员,主要研究方向:物联网安全。
TP309
A
2023⁃02⁃23。
