带Q网络过滤的两阶段TD3深度强化学习方法
2023-10-21周娴玮包明豪余松森
周娴玮,包明豪,叶 鑫,余松森
(华南师范大学 软件学院,广东 佛山 528000)
0 引 言
深度强化学习是一种解决决策性问题的算法,在自动驾驶[1]、机器人控制[2]、无人机[3]等领域应用广泛。深度强化学习以“试错”的方式与环境进行交互,智能体通过学习这些交互过程产生的经验,以最大化环境中获得的累积奖励为目标,不断优化自身策略[4]。
常规的深度强化学习模型训练方式由“零”开始训练,即智能体的起始策略为随机初始化[5]。这种方式会导致智能体在与环境进行交互的前期阶段过程中,出现盲目性探索环境,样本学习率低,并没有良好、稳定的表现,这种现象也被有关学者定义为冷启动(Cold Start)[6]问题。
为解决冷启动问题,近些年来,有学者提出两阶段深度强化学习训练方式[7]。具体而言,使用A-C(Actor-Critic)演员-评论家模式的深度强化学习模型,通过采集专家演示数据[8],利用模仿学习对智能体进行预训练,而后采用深度强化学习进行下一步的训练。通过策略预训练,减少智能体前期盲目探索次数,提高学习效率,加快网络收敛速度,从而缓解训练前期的冷启动问题。
两阶段深度强化学习训练方式虽然能够缓和智能体冷启动问题,但是在智能体从模仿学习过渡至深度强化学习阶段后,可能出现专家演示动作被遗忘的问题,具体表现为性能和回报出现突然性回落的现象[2-3,9]。
造成该现象的主要原因有以下两个:
(1)若智能体在模仿学习阶段仅对Actor网络进行预训练,而Critic网络选择随机初始化[2,9]。在深度强化学习前期训练阶段,由于Critic网络未经过预训练,因此无法提供准确的动作估值,导致Actor网络进行策略梯度更新时做出错误的选择,将所学的演示动作遗忘。
(2)即使Critic网络经过预训练,但是由于专家演示数据集中没有提供所有动作经验,预训练时演示数据集之外的动作的估值可能被过高估计,因此演示动作不一定为最高估值动作[10]。在深度强化学习阶段进行策略梯度更新时,预训练后的Actor网络追求估值最高的动作,可能选择演示数据集之外的动作,进而遗忘所学的演示动作,严重时导致训练速度大大减缓。
综上所述,该文针对上述两个主要原因做出如下改进工作:
(1)提出两阶段TD3(Twin Delayed Deep Deterministic Policy Gradient)[11]深度强化学习方法。首先,通过采集专家演示数据集采用模仿学习-行为克隆[12]方式对Actor网络进行预训练;其次,使用TD3模型Q网络更新公式对Critic网络进行预训练,避免其随机初始化。
(2)提出Q网络过滤算法,通过所提出的过滤函数调整预训练Critic网络参数权重,过滤掉网络中过高估值的演示数据集之外的动作估值,使演示动作成为估值最高的动作。目的是使预训练后的Actor网络在深度强化学习阶段进行策略梯度更新时,减少选择演示数据集之外的动作,尽量避免遗忘演示动作。
1 相关工作
模仿学习[13]是一种监督学习,可以在离线情况下根据数据集进行快速有效地学习,形成一个端到端的网络模型。虽然模仿学习存在分布不匹配、鲁棒性差等问题[14],但是可以被运用于智能体的预训练,而后采用深度强化学习进行改进训练,因此能够加快深度强化学习网络的收敛速度。例如,Peng等人[7]提出一个两阶段框架,称为IPP-RL,通过模仿学习预训练模型共享权值来初始化DDPG(Deep Deterministic Policy Gradient)[15]模型的(Actor)行动者网络,以加快深度强化学习的训练速度。Pfeiffer等人[2]提出增强模仿学习(R-IL)方法,结合基于专家演示的有监督的IL,对后续的RL策略(Actor)网络进行预训练,比纯RL更容易和更快的训练。虽然上述两阶段深度强化学习方法能够缓解冷启动问题,但Pfeiffer与Jing等人[2,9]的工作表明,由于随机初始化的Critic网络需要在深度强化学习的前期阶段进行训练工作,在此期间无法提供准确的动作估值,可能使预训练后的Actor网络做出错误的更新决定,导致智能体出现性能和回报突然性回落的情况,极大地影响了网络训练速度。
为改善此情况,许多学者提出相应的Critic网络预训练方法。例如,Chen等人[16]提出将DDPG模型中的Actor网络与Critic网络采用相同的图像提取特征CNN架构。首先对Actor网络进行预训练,随后将其卷积网络权重赋值给Critic网络,使两者均拥有初始能力。Ma等人[17]提出利用先前收集的专家演示数据集通过最小化一步TD误差公式对Critic网络进行预训练;同时Actor网络通过复合策略梯度更新公式及行为克隆损失函数进行预训练工作。将预训练完毕后的网络权重用以初始化DDPG模型进行下一步的训练。Wang等人[3]使用ORCA(Optimal Reciprocal Collision Avoidance)作为引导策略生成演示数据,设计出一个基于ORCA速度障碍的损失函数来预训练Actor网络;同时使用DDPG的Q网络更新函数对Critic网络进行预训练。当智能体达到ORCA能力值时,采用深度强化学习进行下一步的训练。
这些工作虽然提出了相应的Critic网络预训练方法来改善智能体性能和回报突然性回落的情况,但是并未关注到造成该情况出现的第二个原因,即忽略了预训练后Critic网络中虚高的演示数据集之外的动作估值对Actor网络的更新影响。为此,借鉴前人经验,该文同时弥补其不足,提出相应的改进工作。
2 带Q网络过滤的两阶段TD3深度强化学习方法
该文提出的方法分为以下两大阶段:(1)预训练阶段(Actor、Critic网络预训练)以及Q网络过滤阶段,这两个小阶段使用采集得到的专家演示数据进行网络训练;(2)深度强化学习训练阶段,将上一阶段预训练得到的Actor网络以及Q网络过滤后的Critic网络参数权重用以初始化TD3深度强化学习模型,使用深度强化学习进一步训练网络。
2.1 TD3深度强化学习模型
该文采用的TD3深度强化学习算法,是一种基于A-C模式面向连续动作空间的确定性策略深度强化学习模型。其包含主策略网络(Main Actor Network)πφ、目标策略网络(Target Actor Network)πφ';与DDPG模型相比:
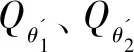
(2)增加延迟更新机制,使Actor网络更新频率相对于Critic网络更新频率要小,从而使Actor网络更加平稳地进行训练;
(3)添加了Smoothing Regularization机制,在计算目标预估值时引入随机噪声ε,目的是使预测估值更加准确(ε从正态分布中随机抽取数值,为标准差;同时ε的取值上下限为[-c,c],c为智能体动作空间数值上限)。
TD3模型的Critic网络更新公式为:

(1)
(2)
(3)
TD3模型使用均值平方差公式作为Critic网络的Loss损失函数,由目标值y与当前值Qθi(s,a)之间的差值组成。其中N表示从经验池中随机抽取得到的经验数量,这些经验(s,a,r,s')包含了当前状态、动作、奖励值、下一状态。
在进行Critic网络更新时,不断地从经验池中随机采样N条经验代入公式(3)的损失函数L,使用随机梯度下降法更新Critic网络参数θi,以最小化目标值与当前值之间的差距。
在Critic网络经过d次更新后,同样地,需要从经验池中随机采样N条经验数据(s)代入策略梯度更新公式(4)。根据Critic网络中第一个Q网络Qθ1的情况对Actor网络πφ进行训练,使用随机梯度下降法进行网络参数φ的更新:

(4)

(5)
φ'←τφ+(1-τ)φ'
(6)
2.2 预训练阶段
2.2.1 Actor网络预训练
首先,从演示数据集D中随机采样N条数据(st,at)代入公式(7)中,该文使用均值平方差作为行为克隆的损失函数LBC,利用梯度下降法进行Main Actor网络参数φ的更新。不断地随机采样N条演示数据对网络进行训练,直至网络收敛后将主网络参数权重φ复制给目标网络φ',完成该阶段预训练工作。
(7)
φ'←φ
(8)
2.2.2 Critic网络预训练
(9)
(10)
(11)
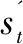

(12)
算法1 预训练阶段算法
输入:演示数据集D,样本采样数量N,奖励折扣因子γ,训练总步骤数T
2.For←0 toTdo
3.从演示数据集D中随机采样N条(st,at)数据
4.将(st,at)代入行为克隆损失函数式(7)中,更新Main Actor网络参数φ
5.End For
6.将Main Actor网络参数权重复制给目标网络φ'←φ
7.For←0 toTdo

11.End For
2.3 Q网络过滤阶段
2.3.1 Q网络过滤算法原理
由于预训练后的Critic网络中存在过高估值的演示数据集之外的动作估值,而这些估值会影响深度强化学习阶段Actor网络的更新,导致智能体出现性能和回报突然性回落的情况,大大影响网络训练速度。为此,借鉴滤波算法原理,该文提出Q网络过滤算法,对演示数据集之外的动作过高估值进行过滤操作。
Q网络过滤算法在智能体进入深度强化学习阶段之前,使用过滤函数调整预训练后Critic网络参数权重,降低网络中演示数据集之外的动作估值,使演示动作at成为估值最高的动作。
该算法原理如图1所示,横坐标表示在某个演示数据集状态st下的动作空间(Action space),在图中,将多维的动作空间进行一维化处理;纵坐标表示该动作的估值(Q-value)。
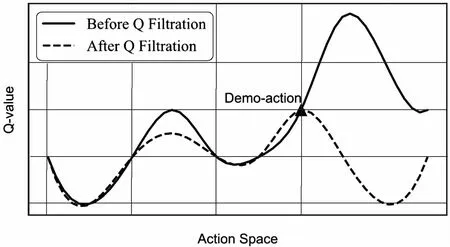
图1 Q网络过滤算法原理
图1中的实线假设为预训练后Critic网络中动作估值情况,此时演示动作at(Demo-action正三角标记)并非为最高估值动作。而在经历Q网络过滤算法后,如图1虚线所示,演示动作at成为最高估值动作。
这样做的目的是使Actor网络在过渡至深度强化学习阶段后,若是在演示数据集状态st情况下进行策略梯度更新时,所追求的最高估值动作与演示动作at重合,尽量避免误选择演示数据集之外的动作,遗忘演示动作。
2.3.2 Q网络过滤算法步骤
步骤一 寻找估值最高动作:由于演示数据集中并未提供所有动作的经验,该文利用策略梯度更新公式寻找预训练Critic网络中st状态下估值最高的动作。首先从演示数据D中随机采样N条数据(st,at),将st以及预训练后的Actor、Critic网络参数权重φ、θi代入至策略梯度更新公式(4)中,对∇φJ(φ)进行随机梯度下降,更新Main Actor网络参数φ。将更新后的网络参数φ代入式(13),得到在状态st下估值最高的动作am。
am=πφ(st)
(13)
步骤二 降低演示数据集之外动作估值:将估值最高的动作am,即演示数据集之外动作,与先前随机采样得到演示动作at及状态st代入该文提出的第一条Q网络滤波函数F1中。
(14)
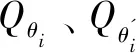
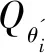
(15)
步骤四 网络更新:将两条过滤函数F1(θi)、F2(θi)进行相加后,根据式(16)进行随机梯度下降,更新Main Critic网络的参数θi。
∇θiF(θi)=∇θiF1(θi)+∇θiF2(θi)
(16)
演示数据集D中存在多条数据,因此需要多次循环过滤。经过Q网络过滤后,网络中演示数据集之外动作估值比专家动作估值大、或者相等的情况会明显减少,从而达到“过滤”目的。
步骤五 网络复制:在Q网络过滤阶段,为了寻找最高估值动作,预训练Main Actor网络参数权重φ被策略梯度公式更新,为保持预训练阶段所学习的专家知识,将过滤阶段未参与网络更新操作的Target Actor网络参数权重φ'复制给Main Actor网络。
φ←φ'
(17)
与此同时,由于Main Critic网络参数θi在过滤阶段经过了网络调整,其参数权重已经发生变化,即完成了过滤操作,因此将过滤后的主网络参数权重复制给目标网络。
(18)
算法2 Q网络过滤算法
1.For←0 toTdo
2.从演示数据集D中随机采样N条(st,at)数据
3.将N个st数据及φ、θi代入式(4),更新Main Actor网络参数φ
4.将更新后的参数φ代入式(13)得到估值最高动作am

6.End For
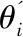
8.将网络参数权重φ'复制给φ
2.4 深度强化学习阶段
该文将预训练后的Actor网络以及经过Q网络过滤后的Critic网络参数权重用于初始化TD3深度强化学习模型,而后智能体将采用TD3更新公式进行自主探索环境学习[16]。
将上述智能体训练阶段绘制成总体算法流程,见图2。图中包括预训练阶段(Actor网络预训练,Critic网络预训练)、Q网络过滤阶段以及TD3深度强化学习阶段。
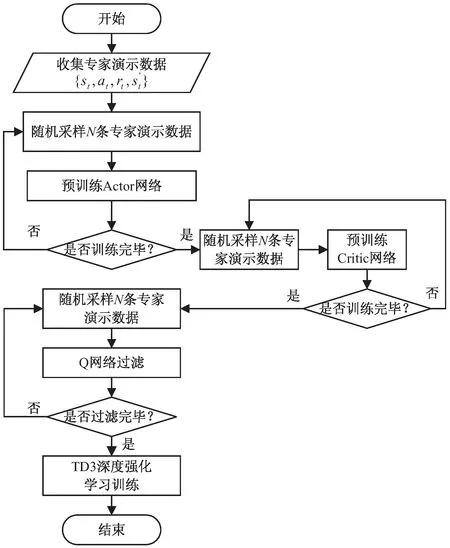
图2 总体算法流程
3 仿真实验
该文采用Deep Mind提供的Mujoco[18]多关节仿生机器人环境进行实验,如图3所示,使用3种不同关节类型的机器人Ant-v3(左下)、HalfCheetah-v3(左上)、Walker2d-v3(右)来验证所提出的Q网络过滤算法。

图3 三种不同关节结构Mujoco机器人
仿真机器人奖励函数由三部分组成:前向速度、健康度、动作消耗,不同的机器人中这三部分组成比例不相同;机器人所观察的状态s、动作a均为多维向量,每种机器人维度不相同。
3.1 实验设置
3.1.1 环境参数设置

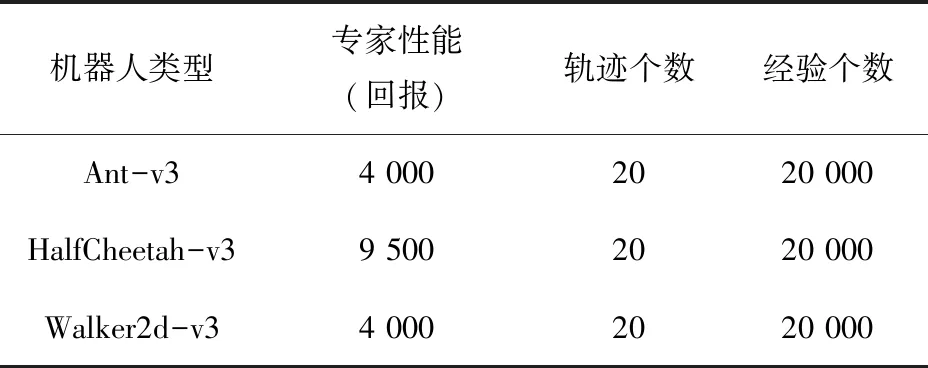
表1 专家演示数据
在深度强化学习阶段,每个机器人在一个随机种子数环境训练106次,总共训练5个随机种子数,其中机器人单次训练回合最长步数为1 000步;在回合中,若其健康度低至0,则会重置机器人,重新开始下一回合训练。实验中,机器人在与环境交互25 000步后,开始进行网络更新工作,此后每步都进行网络更新。每隔2 500步进行一次测试,其中包括回报、差异度测试。将当前环境所训练的TD3模型转移至新的随机种子数环境中测试10次,取得分结果平均值作为当前阶段的回报情况;与此同时进行智能体Actor网络输出动作与专家演示动作之间的差异度测试,将差异值记录。
3.1.2 超参数设置
该文所使用的TD3模型的Actor、Critic网络采用三层全连接网络,其中隐藏层网络宽度为256,输入输出维度根据机器人种类决定。折扣因子γ=0.99,Actor、Critic网络学习率为3e-3,软更新系数τ=0.01,网络延迟更新系数d为2,探索噪声系数ε=0.1,经验池大小为106,每次采样N=256条经验。
3.2 实验结果分析
本次实验采用以下算法进行对比:
(1)TD3模型Baseline基准;
(2)经历Actor、Critic网络预训练但未经过Q网络过滤TD3模型,即常规的两阶段TD3深度强化学习方法;
(3)经历Actor、Critic网络预训练同时经过Q网络过滤TD3模型,即带Q网络过滤的两阶段TD3深度强化学习方法。
将这三种算法分别在Ant-v3、HalfCheetah-v3、Walker2d-v3仿真环境中进行实验,同时收集智能体产生的两种数据,分别为:
(1)深度强化学习训练阶段智能体在演示集状态st下Actor网络输出动作与专家动作at差异均值,用式(7)LBC作评价,其结果如图4所示。

(a)Ant-v3
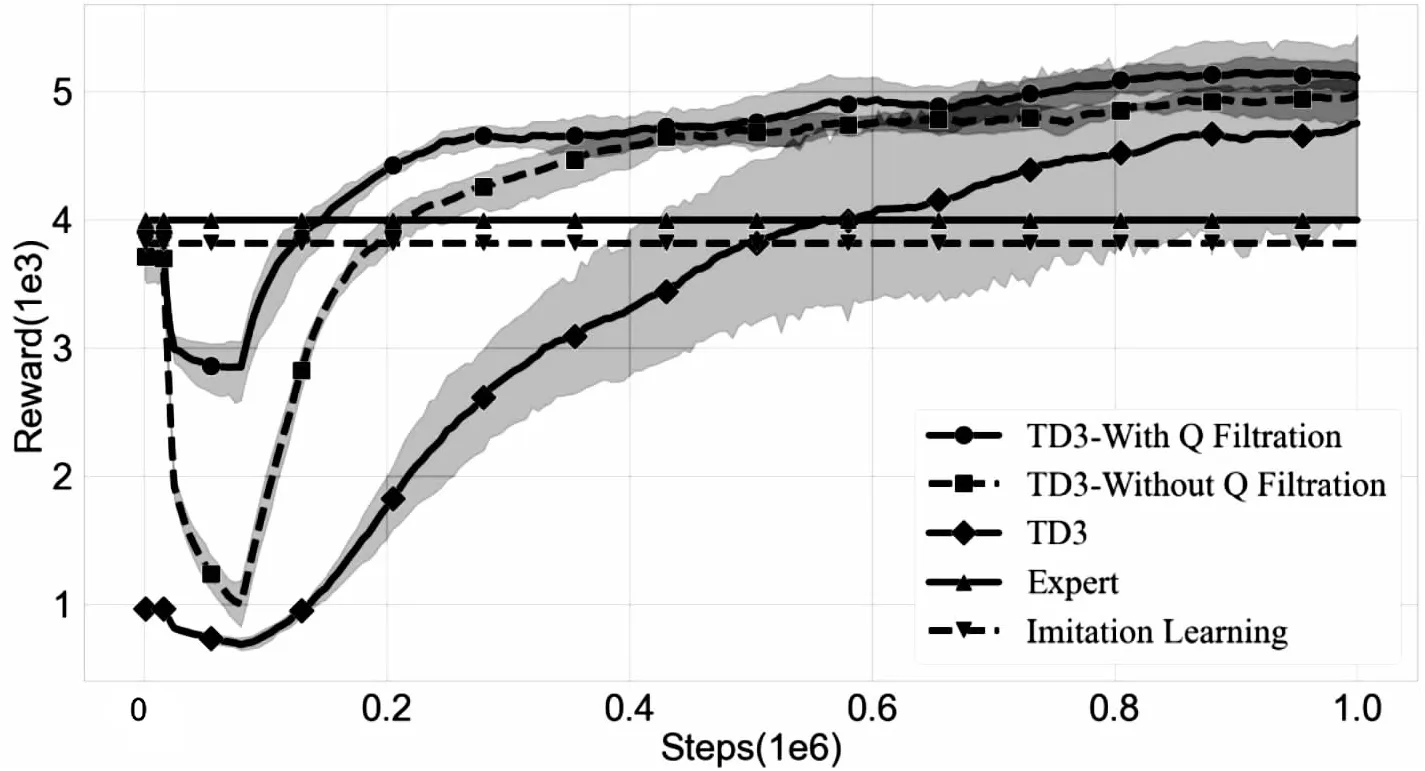
(2)在训练过程中的测试回报情况如图5所示,最终测试得分回报如表2所示。

表2 智能体最终回报
(a)Ant-v3
3.2.1 动作差异分析
如图4所示,图中用圆实线(Our)表示经过Q网络过滤后的智能体数据,正方形虚线(Without Q Filtration)表示未经过Q网络过滤的智能体。图中阴影部分表示数据的95%置信区间。
从图4的动作差异图中可以看出,在Actor网络开始进行策略梯度更新时(智能体与环境交互25 000步后),网络输出动作与数据集中演示动作的差异值急速上升。而经历了Q网络过滤的智能体,其上升幅度小于未过滤的智能体。这表明经过Q网络过滤后的智能体遗忘专家演示动作程度较小,保留了更多的专家演示动作,其中Ant-v3、HalfCheetah-v3较为明显。而在训练的后期,由于智能体探索环境,寻找到更优或者替代的动作,因此动作差异程度比较大。
3.2.2 回报情况分析
在图5的众多曲线中,用圆实线(Our)表示经过Q网络过滤后的智能体回报均值;正方形虚线(Without Q Filtration)则表示未经历过滤的智能体回报均值;使用菱形实线表示TD3基准回报均值。图中阴影部分表示数据的95%置信区间。而在直线中,使用正三角形实线(Expert)表示专家演示回报(性能),倒三角虚线(Imitation Learning)表示模仿学习回报情况。
从图5的回报结果中可以得知,由于智能体经历了预训练,其初始性能与模仿学习阶段相同。在与环境交互25 000步后,网络开始进行更新时性能和回报迅速下降,低于模仿学习阶段。但随着训练的深入,智能体能够从中恢复至模仿学习时期能力水平。而经历Q网络过滤的智能体能够更快恢复,同时其得分回报下降程度相对于未经历过滤的智能体更小。从实验中可得知Q网络过滤算法能够改善性能和回报突然性回落情况。
与TD3基准对比,该文提出的算法能够从一个较为良好的策略开始进行训练,缓解冷启动问题,从而加快了网络收敛速度,最终收敛结果如表2所示。
表2记录了3个机器人在不同算法最终收敛时的回报均值情况。从表2中可以看出,经过Q网络过滤后的智能体最终回报要高于TD3及未经过过滤的智能体回报。同时结合表2及表1的实验数据中得知,3个机器人的模仿学习平均回报均没有超过专家演示,这是因为演示与测试并不在同一个随机种子数环境中,其次是专家演示数据D中只包含环境的一部分状态-动作分布区间,并没有包括所有未知状况,因此智能体并不能很好地处理未曾遇到过的状态。
4 结束语
针对两阶段深度强化学习训练方式中存在的遗忘演示动作问题,即智能体性能和回报突然性回落问题,提出一种带Q网络过滤的两阶段TD3深度强化学习方法。通过采集专家演示数据集对Actor及Critic网络进行预训练,同时使用Q网络过滤算法过滤掉预训练后Critic网络中过高估值的演示数据集之外的动作估值,有效缓解演示动作遗忘现象,改善了智能体性能和回报突然性回落情况。最终,通过Mujoco机器人仿真实验表明,该算法能够改善智能体得分回报突然性回落情况。
