基于域自适应的塔式起重机结构损伤诊断方法研究*
2023-10-20宋世军朱昆贤安增辉宋连玉
宋世军 朱昆贤 安增辉 宋连玉 杨 蕊
1 山东建筑大学机电工程学院 济南 250101 2 山东富友科技有限公司 济南 250101
0 引言
塔式起重机(以下简称塔机)是目前建筑工程中非常重要的起重机械,属于建筑工地中高危设备。塔机结构一旦出现损伤,有可能会发生整机变形或倒塌事故,给人民群众的生命财产安全造成巨大损失[1]。目前,采集到的塔机结构数据量庞大,数据集不完备,标签数据少且获取成本高,且人工诊断塔机结构是否损伤面临误判率高、诊断效率低等问题。因此,研究塔机结构损伤智能诊断方法,利用少量的有标签数据,训练网络模型快速高效的识别塔机结构是否损伤,对降低塔机的事故率,保障塔机安全具有重大意义。
在机械的损伤智能诊断中,深度学习具有较强学习能力,极大地提高了诊断水平和效率。Che C C 等[2]提出一种基于领域自适应深度信念网络的滚动轴承智能诊断模型,应用迁移学习中的领域自适应方法计算不同工况数据之 间的多核最大均值差(Multi Kernel-Maximum mean Discrepancies,MK-MMD),并利用反向传播算法对模型参数进行微调,解决了标记样本少的问题;Li Y B 等[3]提出一种基于改进的领域自适应方法的机械智能故障诊断方法,与特征提取器有关的特征空间距离和域失配分别使用最大均值差异(Maximum Mean Discrepancies,MMD)和域对抗训练,以提高特征表示。
面对塔机上收集到的数据具有数据量大、有标签数据少且获取成本大、不同塔机收集的数据有差异等问题,给传统的损伤诊断方法带来了困难。迁移学习为解决有标签数据样本不足的问题提供了新的思路,可使用与需要诊断的目标塔机数据不同分布的已有数据集或已有含足量训练样本的塔机数据集训练网络,将过往的有标签数据与现有无标签数据联系起来,从而有效解决样本不足的问题。本文采用迁移学习中的域自适应方法,将不同域之间的联系建立起来,以增强模型的泛用性。
本文以MMD 距离作为度量标准,将源域样本与目标域样本的特征映射到无穷维特征空间,使样本特征在再生核希尔伯特空间(Reproducing Kernel Hilbert Space,RKHS)建立联系,应用卷积神经网络,设计实验对本文方法进行验证。
1 理论基础
1.1 域自适应
在现实中,训练数据和测试数据来自不同的域,即训练数据与测试数据分布不同,但两者的任务相同,而迁移学习中的域自适应方法[4]能有效解决上述问题。域自适应方法是指通过学习源域与目标域之间的差异,将源域的知识迁移到目标域中,从而解决在目标域上数据不足或分布不同导致模型性能下降的问题。域自适应可以找出数据分布不同的域之间的联系,提取跨域不变的分类特征,提高模型的泛化能力,从而使模型目标域的性能可与在源域的性能相当甚至更好。
在塔机损伤智能诊断中,普遍面临不同域的识别问题(如不同塔机间数据有差异,同一塔机不同时间段和不同工况所收集到的数据也有区别),同时还要面对标签数据少且无标签数据庞杂的问题,这种情况下可以利用域自适应方法使模型继续应用。域自适应方法的应用背景与目的如下:
1)训练用数据包括源域数据(Ds,即已有知识域数据)和目标域数据(Dt,即要进行学习的域的数据),本文所述域指代不同塔机的数据集、同一塔机不同时间段的数据集。
2)塔机的健康状态种类相同,故源域和目标域具有相同的标签空间。
3)源域和目标域数据空间不同,边缘分布也不同,通过域自适应方法,利用源域的有标签数据和目标域的无标签数据训练模型,使数据在模型作用下进入相同的特征空间,且边缘分布相同。
1.2 最大均值差异(MMD)
最大均值差异(MMD)[5]是评价源域与目标域间域差异分布的测量方法,是衡量2 个分布差异的重要指标。设所有函数为ƒ,若这2 个分布通过ƒ映射后得到的均值均相等,则可认为2 个分布具备一致性。MMD的基本定义式为
式中:p为源域分布,q为目标域分布,x为特征,f为映射函数,E为期望,sup为函数映射的最大值,F为函数的集合。
本文使用的是Gretton A 等[6]提出的MMD 多核变形体,选取高斯径向基核函数(Gaussian Radial Basis Function,GRBF)作为多核核函数,高斯核函数作为径向基函数可将特征映射到无穷维RKHS 中,能够更好地表示出数据在高维空间的分布差异,是应用度很高的一种核函数[7]。高斯核函数形式为
在式中,σ控制高斯核函数的作用范围,其值越大高斯核函数的局部影响范围就越大。σ在内核的性能中起主要作用,σ过小易使分类任务出现过拟合现象;σ过大则指数将几乎成线性,高维投影将开始失去其非线性功能。本文采取5 个不同σ的高斯核函数来解决单一核函数的参数选择风险。
1.3 卷积神经网络
卷积神经网络(Convolutional Neural Networks,CNN)属于前馈神经网络的一种,主要包含卷积层、池化层、全连接层等结构[8]。卷积层是卷积神经网络的核心部分,当数据经过卷积层时,卷积层中所包含的卷积核会对输入数据做卷积运算。卷积的作用是将输入的样本数据进行卷积,抑制输入数据中噪声的干扰,增强原始样本信息。卷积运算可表示为
式中:xi为卷积后的特征图,Wi为卷积核权值,xi-1为当前输入特征,bi为偏置,fi(•)为激活函数。
如果直接使用卷积层的输出进行后续任务的处理会增加计算量,在卷积层间设置池化层,可有效缩小参数矩阵的尺寸和全连接层中参数的数量,既能减少计算量又不会失去数据的主要特征,能起到加快网络计算速度和防止过拟合的作用[9]。池化操作也称下采样,其主要操作是对数据进行降维,压缩卷积层提取的特征,全连接层起到对提取的特征进行压缩的作用,全连接层自身不具备特征提取能力,而是使用前置层中已提取的高阶特征完成网络学习任务。
1.4 随机梯度下降算法
随机梯度下降算法(Stochastic Gradient Descent,SGD)[10]对解决机器学习优化问题有显著效果,其核心思想是:为了获得最优解并计算函数损失值的最小值,需要先计算损失函数的梯度,然后按照梯度方向逐步减小函数损失值;需要通过反复调整权重更新函数损失值,直至达到最小值。这种算法在每次迭代过程中从样本中随机选择一组样本的梯度更新迭代总体梯度,不但加快迭代速度,而且大大降低了计算复杂度。
2 基于迁移学习的塔机结构损伤智能诊断
以CNN 为基本诊断模型,在训练时引入域自适应,利用多核MMD 方法将样本特征映射到RKHS 中进行处理,实现不同塔机间数据的特征迁移结构损伤智能诊断。
2.1 模型框架
采用一维卷积神经网络将样本数据样本输入模型,将数据的健康状态分为完好和损伤2 种,利用Softmax激活函数给出数据样本属于某一健康状态的后验概率,再根据此概率判断设备的健康状态。
输入样本xi为塔机上收集来的数据,y为C 类健康状态,数据样本经过模型处理的向前传播公式为
采用Softmax 激活函数进行激活输出o,给出样本的健康状态的后验概率,即有
式中:P=(y=c|x)为输出x时的健康状态y为c的概率。
2.2 损失函数
1)分类损失函数Lc模型通过带标签的源域数据的训练获取分类知识。在保证模型最基本的分类能力下,尽可能地减少分类误差。分类损失函数Lc最小化意味着模型通过带标签的源域数据学习到了分类特征。采用标准的Softmax 分类损失可表示为
式中:θ为参数的集合;xiS为源域样本xS通过模型输出的预测结果,根据标签可计算其与真实标签的误差;1{•}为指示函数。
2)域自适应损失函数Ld
域自适应的目的是为了减少源域和目标域的分布距离,使其进入相同的特征空间对目标域数据进行特征分类,保证目标域样本能够被准确地诊断。卷积神经网络的每层都含有分类信息的特征,取卷积神经网络最后2层提取分类信息的深层特征,用MMD 多个核函数计算这2 层的分布距离Ld1、Ld2,即在多个高维空间中计算源域和目标域之间的分布距离,其表达式为
式中:H1S、H1t、H2S、H2t是源域和目标域在该层的特征向量,K为所用核函数的个数。
采用域自适应损失函数最小化意味着模型能够学习跨域不变的分类特征。最终的域自适应损失函数为
联立分类损失函数Lc和域自适应损失函数Ld这2个优化目标,最终损失函数为
搭建整个域自适应特征提取网络模型,对塔机采集到的有标签数据样本的源域进行特征提取,利用多核MMD 找出数据分布不同的域之间的联系,提取跨域不变的分类特征。一方面,通过计算源域和目标域学习到的特征之间的MMD 距离优化计算模型的特征学习;另一方面,模型使用源域训练数据进行分类,计算分类损失函数。将源域数据的分类损失函数和源域与目标域之间的差异距离MMD 结合作为模型的总损失函数,利用随机梯度下降算法反向传播更新模型中的权重参数。如此不断地优化模型,提高其泛化性能。诊断方法如图1所示,诊断模型如图2 所示。

图1 基于域适应的结构损伤诊断方法

图2 应用MMD 的CNN 诊断模型
3 实验数据的获取
在塔机上安装刚度仪,将采集的原始顶端位移数据样本进行训练,刚度仪的安装位置为与塔身轴线是平行的结构处或塔机回转塔身的任意主肢,如图3 所示。测得相关数据可储存在计算机设备上[11]。本文以多台塔机收集的数据作为实验数据,并将这些数据分为完好和损伤2 种健康状态,样本长度为48 维。

图3 刚度仪样式及安装位置
4 实验研究
4.1 模型测试
采用一维卷积神经网络,设计CNN 结构主要包括1 层输入层、2 层卷积层、2 层池化层和4 层全连接层。卷积层的卷积核均为1×6,池化层的卷积核大小均为2×1,4 个全连接层的节点数依次为256、128、35、2。CNN 模型参数如表1 所示,激活函数采用ReLU 形式。

表1 CNN 模型的各参数设置
其中,输入层输入塔机位移原始数据,从塔机收集400 个有标签数据和500 个无标签数据作为实验样本,取300 个有标签数据作为源域训练样本,500 个无标签数据作为目标域训练样本,剩余的100 个有标签数据作为目标域测试样本。采用批训练的方法,每次迭代随机选取64 个源域有标签的数据样本和64 个目标域无标签数据样本,共训练500 步,训练好的模型对目标域有标签样本数据进行测试,以此判断网络训练的效果。在从源域到目标域迁移的训练过程中,域自适应损失函数随优化迭代过程的变化曲线如图4 所示。

图4 分类损失函数与域自适应损失函数变化曲线
由图4 可知,随着优化的不断进行,域自适应损失函数值和分类损失函数值在不断减小直至趋于平稳,表明目标域和源域的分布距离MMD 都在下降,模型可以保证源域和目标域能够进入相同的特征空间,并使2 个域深层特征的边缘分布相接近。分类损失函数Lc的降低,表明分类误差在减小,保证了模型基本的分类能力。Ld1、Ld2层损失函数曲线之所以会出现明显差异,是因为分布差异的误差会随层数的增加而累积,层数越深差异就越明显。
为了验证本文方法对于训练塔机数据样本的可行性,设定对具有相同网络结构的人工神经网络(Artificial Neural Network,ANN)模型和使用本文方法的ANN模型、具有相同网络结构的CNN 模型和使用本文方法的CNN 模型进行对比分析。诊断结果如图5 所示。

图5 不同模型的测试准确率
在未采用迁移学习方法的模型中,CNN 的诊断平均准确率为86.70%,与诊断平均准确率为79.85%的ANN 相比,CNN 诊断结果均比ANN 高。若诊断结果均难以满足诊断需求,说明数据发生变化后基于原始数据所学习到的分类能力对诊断新的样本略有乏力。在使用迁移学习方法情况下,CNN 的诊断平均准确率为91.15%,ANN 的诊断平均准确率为84.30%,CNN 对诊断准确率依旧优于ANN,但通过迁移学习方法的使用,CNN 与ANN 相比于未使用迁移方法前均有诊断效果的提升。
为验证本文方法在塔机损伤诊断方面的优越性能,设计了迁移成分分析(Transfer Componet Analysis,TCA)[12]、联合分布自适应方法(Joint Distribution Adoptation,JDA)[13]、平衡分布自适应方 法(Balanced Distribution Adaptation,BDA)[14]等3 个迁移学习方法进行对比实验。诊断准确率如表2 所示。

表2 不同迁移学习方法的损伤诊断准确率 %
本文方法的诊断准确率较TCA、JDA、BDA 迁移学习方法有明显提升,表明本文方法较其他方法对比,能够更加有效地诊断塔机结构损伤。
4.2 参数研究
批处理样本数目对模型的训练结果、诊断准确率、训练时长有重要影响,批处理样本数目太少会增加模型的训练步数,太多则会降低模型的优化效果。训练优化步数为500,批处理样本数目分别为16、32、64、128时的实验结果如表3 所示。当批处理样本数目为64 时,诊断准确率较高,训练时间在合理范围内,所以批处理样本数目设置为64。
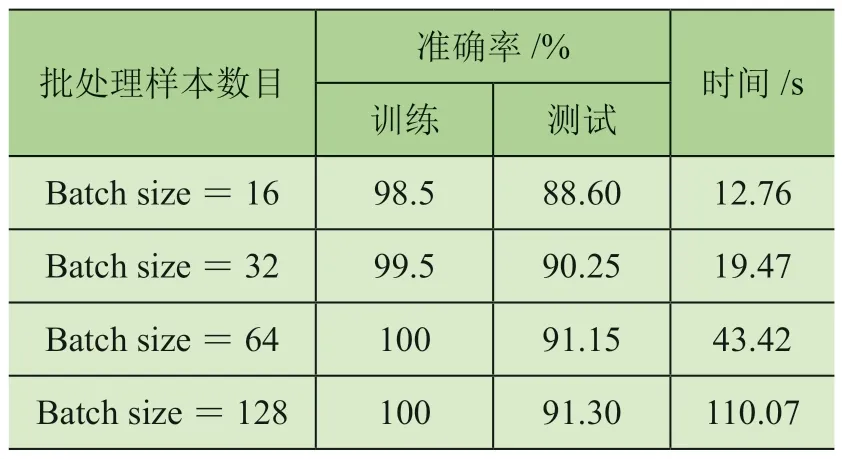
表3 不同批处理样本数目的实验统计结果
在本文方法中,域适应方法应用了多核MMD,通过改变RBF 核的个数研究多个核函数进行分布适配效果,诊断结果如图6 所示。由图6 中的诊断结果可知,随着核函数数量的增加训练时间不断增加(每百步训练时间是基于Intel I5 处理器4G 内存设备上计算得出的),诊断准确率略有上升,但标准差有所降低,表明多核MMD 能够让诊断结果更稳定。虽然增加RBF 核的个数能够让诊断结果略有提升,但训练时间地拉长将不利于模型的高效诊断。通过权衡诊断准确率核每百步训练时间,RBF 核的数量为5 的时候诊断效果较好。
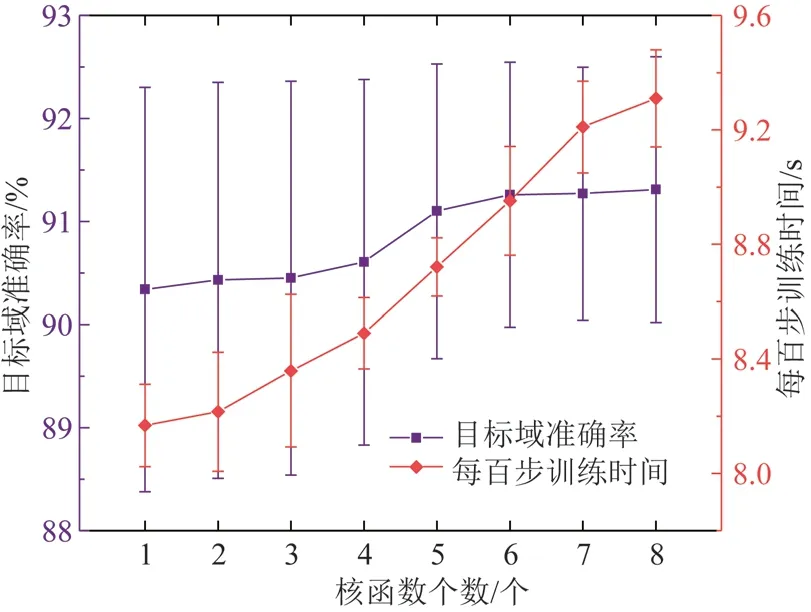
图6 不同核函数个数对准确率的影响
此外,对比域自适应损失函数在同时采用Ld1、Ld2这2 个域自适应损失函数与仅采用Ld21 个域自适应损失函数情况下的诊断效果,结果如图7 所示。在迭代500 次训练模型结果中,使用2 个域自适应损失函数的情况下源域训练准确率比仅使用1 个域自适应损失函数更快到达最高值。在目标域的训练准确率中,使用2 个域自适应损失函数要比使用单个域自适应损失函数的平均准确率略高,且更快达到最终的训练效果。所以,同时采用Ld1、Ld2这2 个域自应损失函数要比采用Ld21 个域自适应损失函数效果要好。

图7 训练过程准确率曲线
在式(9)中,λ的值确定了域自适应损失函数在总损失函数里的占比,亦表示目标域数据训练样本在训练中所占比例,改变目标域数据训练样本的占比对诊断准确率结果的影响如图8 所示。随着目标域数据训练样本在训练中所占比例的增加,目标域准确率得到提升,但在目标域训练样本比例为10%时,目标域准确率约为89%,较其他占比较高的时候的效果略差。

图8 不同目标域训练样本比例对诊断准确率的影响
5 结论
采用迁移学习中的域自适应方法对塔机进行智能损伤诊断,以深层神经网络为基本框架,研究了域自适应损失函数的作用,进行了核函数个数和提取域自适应损失函数的不同层数对诊断结果影响的研究,证明了采用多核多层方法的有效性,验证了迁移学习在使用塔机数据的情况下的可行性,解决了塔机采集的有标签数据少且无标签数据庞杂的问题。使用本文方法,可使样本数据特征进入相同的特征空间,拉近数据间的特征距离,从而进行高效损伤诊断。另外,通过实验表明了基于本文方法下的模型具有对新数据更好的适用性,稳定性以及较好的诊断效果。
