基于舒适度的骑行路径推荐系统设计与开发
2023-10-20汪陈晨周茂林牟倍民吴慈恒金永霞
汪陈晨,周茂林,杨 芹,牟倍民,吴慈恒,金永霞*
(1. 河海大学物联网工程学院,常州 213000;2. 河海大学商学院,常州 213000)
0 引言
由于骑行方式易受环境、交通状况、道路设施等因素影响,骑行者在选择出行路径时越来越关注舒适度,为出行者提供舒适安全的骑行路径推荐方案成为城市交通建设的迫切需要[1]。本文开发一套基于舒适度评价的骑行路径推荐系统,综合道路客观情况与骑行者主观体验构建科学的舒适度评价体系,对各路段骑行舒适度进行量化,采用多级迪杰斯特拉算法实现路径推荐并可视化呈现给用户,为骑行者出行路径规划提供参考。
1 系统总体设计
1.1 系统架构
基于Ubuntu22.04 安装开源路由器OSRM,结合云计算技术开发与地理信息数据库,实现数据云存储、云数据定期更新,提供舒适、高效、数字化的骑行舒适路线规划模式。
系统通过终端设备智能化采集户外骑行轨迹数据,实现位置经纬度定位、轨迹数据采集、三轴速度与加速度实时获取和计算等功能,存储数据至云端;采用阿里云服务器搭建路径推荐服务平台,实现记录轨迹数据、推荐舒适路径等功能,支持存储地图路网数据、用户骑行数据;用户端显示当前定位,并根据起止点推荐舒适路径。
系统整体框架如图1 所示,包含六个层次:运行环境、数据库、数据层、业务层、传输层和终端接入层。本系统部署在阿里云服务器,使用PostgreSQL 存储地图数据。PostgreSQL[2]是一个功能强大、源代码开放的客户/服务器关系型数据库管理系统,在PostgreSQL 中构建地理信息数据库(GIS database)和地理编码数据库(Nomination database),其中Nomination database主要用于搜索功能;数据层主要实现对路网数据、轨迹数据的处理,需要增加路段或路网发生改变时,及时进行数据更新;业务层提供用户位置的实时定位、骑行数据分析、舒适路径推荐、显示路径详细信息、设备管理等功能;通过全球定位系统和公网通信实现数据传输,为终端用户提供城市交通管理、骑行质量调查以及路线规划服务。

图1 系统架构
1.2 路径推荐系统的功能模块
本系统主要研究利用GPS 定位实现对用户的位置信息服务。系统的功能设计如图2所示。

图2 系统功能设计
(1)路网数据预处理。本系统采用的原始路网数据来自开源地图网站OpenStreetMap[3]。为了实现路段分割,首先,从获取到的路网地图中筛选出与骑行道路相关的Ways 元素;其次,对筛选出的Ways 元素在交点处进行分割,使其具有向左右行驶的拓扑结构。
(2)轨迹与路网匹配。GPS 点采样过程存在误差导致采样点发生位置的偏移[4],从而该轨迹点所对应的骑行数据不能对应到正确的路段上,这对我们衡量路段的舒适度造成一定的干扰。因此本系统通过路网匹配算法对其进行纠偏[5],使轨迹点对应到正确的路段上。
(3)构建舒适度评价指标体系。在云平台技术和交通大数据广泛应用的条件下,骑行轨迹数据为舒适度评价提供了数据依据,同时,道路设施、环境条件等客观因素对舒适度也有较大影响,因此将骑行轨迹数据与影响骑行的客观因素相结合探索骑行质量分析与评价方法。同时收集300份调查问卷,使用主成分分析法计算每个指标的影响权重。
(4)路径推荐。根据熵权法计算每条路段最终的舒适度值,将其赋值到处理过的路网地图上,采用多级迪杰斯特拉算法进行舒适路径的推荐。
2 骑行舒适度评价体系构建
2.1 评价指标的选取
选择合适的舒适度评价方法是评价道路骑行质量的关键,骑行路段的舒适度与道路基建、交通情况、自然环境相关,需要综合考虑骑行者的感知水平和道路设施、环境条件等客观因素。本文选取了通过路口等待时间、并行机动车流量、道路遮荫率、道路几何线性、车道隔离栏设置和道路平整程度作为评价舒适度的指标。
指标具体含义解释如下:
(1)过街等待时间:指骑行经过“十”字路口或“丁”字路口时等待交通信号灯的平均时长;
(2)并行机动车流量:指与非机动车道相邻的机动车道上机动车的流量;
(3)遮荫率:指正午时分非机动车道两侧乔木投下的阴影面积占非机动车道面积的比例;
(4)道路几何线性:指道路是否笔直以及转弯情况;
(5)车道隔离栏设置:指非机动车道与机动车道设置隔离栏情况;
(6)道路平整度:指骑行车道是否平整,即是否存在大面积的凹陷、隆起或局部的坑洼。
2.2 指标的量化方式
在选取的六个指标中,前五个为道路客观实际情况,利用实地考察和AR 实景地图观察等方式获取路段实际情况,并对其进行分级量化。第六个指标,道路平整度的计算是通过收集骑行者的骑行数据,将轨迹点匹配至路网上,计算每条路段对应的垂直加速度的方差CovRt,计算如公式(1):
其中:ai表示路段上各点加速度,a表示路段平均加速度,n表示路段轨迹点数量。路段的方差越大表明该路段垂直加速度越不稳定,道路越颠簸,道路平整度越差;路段的方差越小则说明该道路平整度越好。具体的量化方式见表1,量化值5 表明舒适度最高,量化值1 表明舒适度最低。

表1 舒适度指标分级量化标准
为了数据计算的方便和去除量纲影响,对前5 个指标采用公式(2)进行正向化处理,对最后一项指标采用公式(3)进行逆向化处理。
2.3 基于主成分分析法的权重计算
设计舒适度指标影响程度打分问卷,分别将上述六个指标设置1~9 分的影响程度,1 分为完全无关,9 分为极度相关。通过“问卷星”平台收集到约300份问卷量后,利用探索性因子分析法和验证性因子分析法统计问卷结果,并用主成分分析法计算各项指标的权重。主成分分析法(principal component analysis,PCA)是一种统计方法,将原来变量重新组合成一组新的相互无关的综合变量,同时根据实际需要从中取出几个较少的综合变量尽可能多地反映原来变量的信息。设a个需要分析的目标与b个指标构成的矩阵Xa×b为样本矩阵,主成分分析法计算步骤如下。
Step 1.对样本矩阵进行标准化处理,Zij为对Xij进行标准化处理后的指标,如公式(4)所示:
其中:μj和σij的计算方式如公式(5)所示:
Step 2. 计算评价指标的参数矩阵、指标矩阵T特征值的方差的贡献比率和贡献比率总和。如果贡献比率总和高于85%,那么确定主要参数值符合计算获得的参数矩阵。
Step 3.参数旋转,计算主要参数权值,计算过程如公式(6)所示,采用线性回归方程对主参数进行回归计算。
Step 4.计算评价目标的总权值,如公式(7)所示:
权重计算结果见表2。
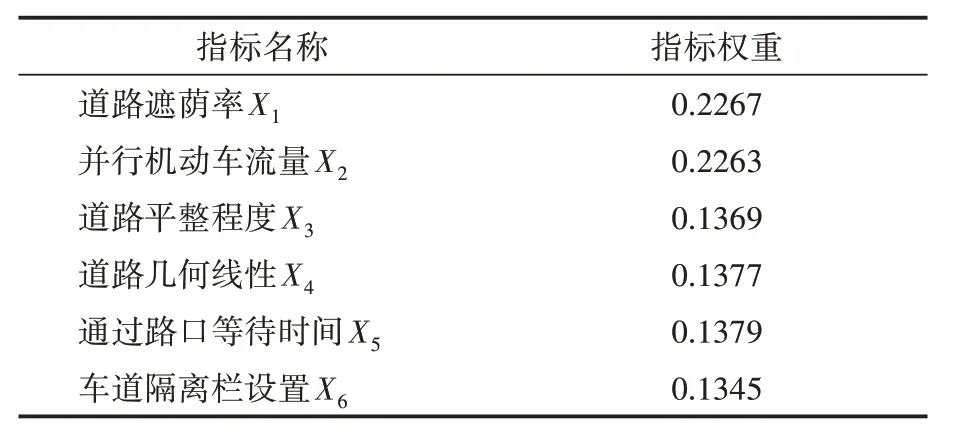
表2 舒适度指标权重计算结果
采用熵权法将计算出的权重与各路段的指标值计算得到最终的舒适度值,并赋值给分割好的路网地图。
3 路网预处理及路网匹配
3.1 路网地图预处理
OSM 本身带有相应的API 接口供开发者使用,将OSM 格式地图下载到本地,使用ArcMap地图软件对其进行分割,然后进行轨迹和路网匹配。
从OSM 项目获取到的道路数据采用了基于XML的拓扑数据结构,包含三种基本数据类型,即点(Nodes)、路(Ways)和关系(Relations)。其中Nodes 标识了空间中点的位置;Ways 标识了道路;Relations 标识了元素间的关系。本系统筛选出与骑行道路相关的Ways 元素,在道路交点处进行路段的分割,使其具有拓扑结构,在交点处能够向左向右行驶,更加接近真实情况。图3为道路分割示意图。
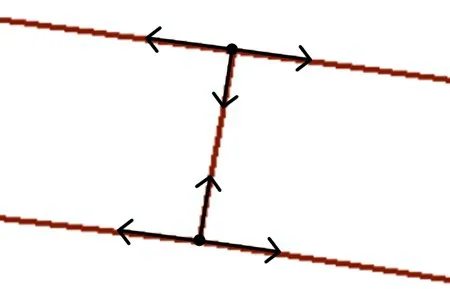
图3 道路分割示意图
3.2 轨迹数据与路网地图匹配
本系统使用隐马尔可夫(HMM)模型进行轨迹和路网的匹配。HMM 模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测值而产生观测随机序列的过程。将该算法应用在路网匹配领域,可以将带有误差的自行车骑行GPS 轨迹点成功匹配到电子路网地图的相应位置,形成连续的行车轨迹。
该模型可以用5 个元素来描述,包括2 个状态集合和3 个概率矩阵,分别为隐含状态S、可观测状态O、状态转移概率矩阵A、观测状态概率矩阵B和初始状态概率矩阵π[6]。
在路网匹配过程中,首先根据待匹配GPS轨迹点的位置在路网地图中找出可能该点正在行驶的路段集合,即候选路段集合;然后根据匹配算法计算各候选点将各候选路段作为匹配路径的概率,修正没有定位在实际道路上的GPS 定位点;最后使用维特比算法,根据观测概率模型和状态转移概率模型计算出概率最大的路段,求解出最优路径。HMM 路网匹配算法如下:

对轨迹点的处理结果如图4 所示。图4(a)中将轨迹点数据直接映射在路网上,可见轨迹点分布不均匀并且有部分缺失,对其进行线性插值处理后如图4(b)所示,轨迹点分布更加密集,将提高后续匹配算法的准确率;HMM 算法匹配结果如图4(c)所示,轨迹点在匹配后精准投影到路网上。

图4 骑行轨迹点处理结果
利用路网匹配算法对轨迹点进行纠偏后,可以通过轨迹点对应的垂直加速度值计算出该轨迹点所在路段的垂直加速度方差。
4 基于带权路网推荐舒适路径
4.1 舒适度赋值路网地图
根据表2计算得到的权重结果,将各指标按照对应权重加权求和,得到舒适度的综合评分Z,如公式(8)所示:
将计算得到的舒适度值划分为四个等级:不舒适(0~0.25)、舒适(0.25~0.5)、比较舒适(0.5~0.75)、非常舒适(0.75~1)。其中部分路段赋值结果如图5所示。

图5 舒适度指标赋值路网
4.2 基于多级迪杰斯特拉算法推荐路径
多级迪杰斯特拉算法(Multi-level Dijkstra,MLD)是一种多层次覆盖图的路径规划算法,可以快速处理不同的度量,用以解决赋权图的单源最短路径问题[7]。MLD 算法在CRP 算法基础上发展而来,由Delling 等[8]进行优化,例如改进局部性、对搜索图进行剪枝、多源执行等,它可以使用用户定制的度量,也可以动态更新路况。
MLD算法的实现可以分为以下三个步骤:
(1)与度量无关的预处理。为了减小图的规模,加速搜索过程,将图G划分为不同的层次,每个层次包含一些顶点V和边W。分层的公式如公式(9)所示:
其中:Gi表示第i层的图,Pi表示第i层的划分方法。分层的方法有多种,具体来说,就是在每个层次上将一些相邻的顶点和边合成一个新的顶点和边,从而得到一个更小的图。层次越高,包含的顶点和边越少,越能反映图的全局结构。将分层的过程重复多次以后,将得到一个足够小的图。分层后的图之间存在一种映射关系,可以在不同层次上进行搜索和优化。图6(a)是原始单元格图,预处理完成后,每个子图中的每两个边界节点之间的最短路径形成团集,如图6(b)所示,团集将以矩阵的方式存储。

图6 原始单元格图、团集和骨架图
(2)依赖度量的自定义。在划分好的每个层次上,为每个顶点计算该顶点到其他顶点舒适度值、最舒适路径树等辅助信息,这些信息可以在查询时快速地访问和利用,减少时间和空间开销。将舒适度值作为顶点之间的权重,计算每个顶点到目标顶点的最舒适路径的过程如公式(10)所示:
其中ComfotI(v,w)表示第I层上顶点v和w之间的最大舒适度值;ComfotI(v,I)表示第I层上顶点v和地标I之间的最大舒适度值;ComfotI(I,w)表示第I层上地标I和顶点w之间的最大舒适度值。每个子图中的每个边界结点到其他边界结点的最舒适路径形成一个并集,构成骨架图,如图6(c)所示,骨架图可以为查询缩减搜索空间和时间。
(3)查询路径。利用预处理分层和自定义处理后得到的信息,对给定的源点和目标点采用双向的Dijkstra 算法在骨架图中进行查询。从最高层开始,在每个层次,从源点和目标点分别开始搜索,利用地标和三角不等式估计任意两个顶点之间的舒适度值,选择舒适度值最大进行扩展,当两个搜索方向相遇时,即为一条候选路径。然后在下一个层次上继续搜索,直至找到最优的路径。
MLD算法具体实现流程如下:
输入:一个图G,一个起点s,一个终点t
输出:从s到t的最舒适路径
Step 1. 将图G分割为不同等级的层次提取出每层的顶点V和边W。每个子图中每两个边界顶点之间形成团集。
Step 2.对每个团集中的顶点,找到它到其他边界顶点的最短路径,然后将这些最短路径作为边,连接起来,形成一个覆盖图。一个团集到另一个团集的最短距离为一个快捷路径。
Step 3.对覆盖图进行剪枝,删除不是快捷路径的边,得到骨架图。骨架图是由每个团集到其他团集的最短路径树组成的并集。
Step 4.对每个层次的骨架图进行定制,根据舒适度值计算每个快捷路径的权值,并进行存储。
Step 5.对每个层次的骨架图进行搜索,从最高层开始,利用双向Dijkstra 算法找到源点s 到目标点t 的最舒适路径,然后在下一层细化这条路径,直到在最底层得到最终的舒适路径。
MLD 算法能够快速处理不同的度量,并且可以动态更新路况和用户定制的度量,利用多层次的图划分,可以减少搜索空间和时间。另外,它可以并行化地执行,每层的查询可以独立进行,提高效率和可扩展性。
4.3 推荐路径结果展示与分析
通过对河海大学(常州校区)及其周边区域实地勘测并采集骑行数据,构建舒适度评价体系,实现最舒适路径、用时最少路径、距离最短路径推荐,结果如图7和图8所示。
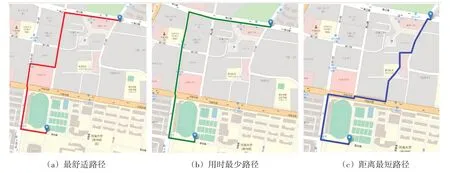
图8 三种推荐方式结果对比(二)
图7结果显示,最舒适路径和用时最少路径推荐结果相同,虽然(c)方案距离最短,但存在并行车流量大、路面设置隔离栏因素,导致舒适度等级降低,所以不作为舒适路径首选。而(a)和(b)方案的结果一致,表明该路径不仅舒适度等级高,用时也短。
图8结果显示,三种方案推荐的路径各不相同,由于(b)方案中存在并行机动车流量大、设置车道隔离栏的路段,(c)方案中存在路面平整度低、道路几何线性复杂等问题,所以两者的舒适度等级不如(a)方案高。
5 结语
本文基于舒适度评价体系设计并开发一套骑行路径推荐系统。该系统综合客观环境因素与主观骑行体验,选择通过路口等待时间、并行机动车流量、道路遮荫率、道路几何线性、车道隔离栏设置和道路平整程度六个评价指标,计算出各路段的舒适度权重。针对带权路网地图,采用多级迪杰斯特拉算法查询出最优路径,完成路径推荐。本系统旨在将传统的出行方式与互联网系统结合,为选择骑行出行的人们规划舒适安全的路径提供参考。
