基于数据中心的能耗测试有效查询优化技术研究
2023-10-18葛警军邢金芳
葛警军,王 更,邢金芳
(机械工业第六设计研究院有限公司,河南 郑州)
低碳社会的建设已成为全世界所有国家的共识,研究低能耗、低成本的计算系统级模型,已成为未来技术重大的挑战,目前对于研究低能耗数据库系统在数据中心中不但有着很大的社会意义,还有着显著的应用价值,另外,其对数据库领域的发展能够起到很大的促进意义[1]。
1 相关工作
1.1 能耗有效的数据库查询处理技术
设计能耗有效的数据库管理系统,在大大降低系统能耗的同时要保证性能退化尽可能的少,另外对系统可靠性及扩展性也不会造成影响。在设计查询优化器时间能耗因素加入其中,这需要设计能耗有效的数据库管理系统时建立两个模型:①能耗模型,将能耗模型加入到优化器中,在评估查询计划代价时能考虑到能耗的因素。②总代价模型,查询计划的总代价通过新加的性能与能耗模型能够得出,由此对最优的查询计划进行选择。在对查询优化改进时,其总代价与能耗模型的良好建立是重点所在。因此,需对系统能耗与性能的联系以及硬件的性能与操作特性进行了解。
1.2 数据库系统的资源预测模型
在数据库系统中,对于系统性能来讲,SQL 查询资料消耗是重点工作。将代价模型建立在优化器中,能估计给定查询基势。这方面有直方图以及基于采样的方法等很多工作。对于查询执行时间通过混合模型来进行预测,但是混合模型使用的输入特征均来自数据库内部数据,对于系统层的影响没有进行考虑。
2 能耗有效的查询优化框架
不同于目前已有的执行时间预测模型,本篇文章主要来研究查询执行中平均功耗的预测,而这样选择的目的主要是对以下两个方面进行考虑:(1) 假如对能耗直接进行预测,其问题非常的复杂,而通过计算执行平均功耗以及机选查询执行时间得到查询操作的能耗[2]。因为这两个环节都是相互独立的,因此可以有效避免传递估计误差,且可以将一个复杂问题分成简单的两个问题,从而便于问题的实现和讨论[3]。(2) 数据中心的功耗是一个最重要的优化目标,冷却系统的耗能随着系统在低功耗运行时也会随着降低。所以,需先对功耗预测模型进行建立,以此为基础,将功耗预测模型融入到查询计划计算模型中,最后选择的查询计划其能耗有效性最好[4]。
2.1 总体方案
性能模型通过时间模型来进行表示,用来对查询计划的执行时间进行估计,能耗模型度量单位为焦耳,用来对执行计划的能耗大小进行估计[5]。功耗模型的度量单位为瓦特,用来对执行计划中的系统功耗进行估计。时间模型与功耗模型之间是相对独立的,但对于查询计划实际执行时间目前已有的时间模型不能给定,因此,在实际中,不能用功耗*时间=能耗这种简单方式来进行度量,而是要对时间与功耗的权重通过定义合理的值来进行调节,以此能耗模型才能更加的合理[6]。
2.2 数据采集方案
有研究表明[7],不同的操作符,其功耗在相同CPU 使用率下也是不同的,其功耗最大也会有百分之六十的差异。所以,对于单个数据库的执行功耗,不但要对内存以及CPU使用情况进行考虑,还要对数据库的运行情况进行考虑。最终收集的数据有执行的功耗数据、系统当前运行状态的表征数据以及操作符读取的页面数据等三个部分数据组成。把数据库与系统内部表征数据在功耗模型建立中作为输入来对功耗进行预测。
可以收集的系统信息有:系统热设计功耗值、内存以及CPU使用率。其中系统热设计功耗值是常量值,是系统运行的功耗上限,能够对CUP 使用率以及内存使用率实时进行获取,在Linux操作系统当中,对于内存及CPU 使用率可通过读取meminfo 文件、proc 文件、stat 文件以及proc 文件的内容来进行确定。CPU所有的活动信息都包含在stat 文件当中,stat 文件中所有值从启动系统之后一直到当前时刻,stat、proc 以及cat 执行后的内容如表1 所示。
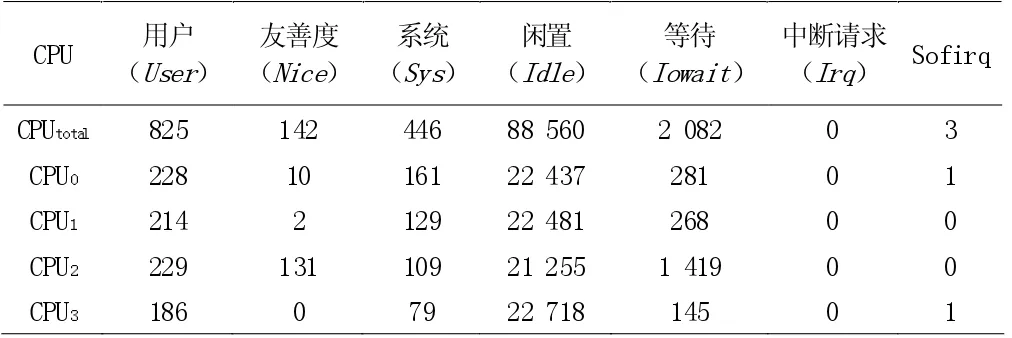
表1 CPU 的运行信息
对文件的内容选择两个时刻来进行读取,这段时间内的CPU使用率通过计算能够得到,即
从meminfo 文件中提取内存总量以及内存使用量两个数据来计算内存使用量,其如公式(2)所示。
对于数据库信息,在数据库系统内通过分类方式列出了可获取的参数与含义,如表2 与表3 所示。

表2 所有物理操作符的共同特征
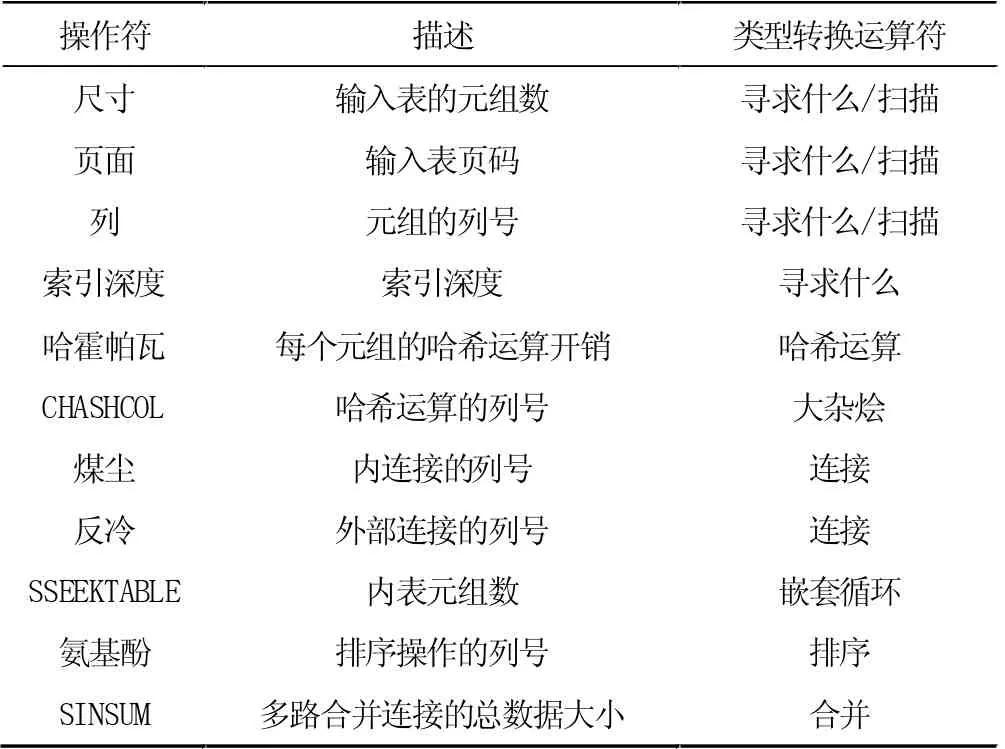
表3 基于特定操作符的特征
需要对内核中的relation.h、plannodes.h、explain.c、createplan.c 以及costsize.c 等文件进行修改才能在PostgreSQL 中具体实现。结构体plan 通过对relation.h与plannodes.h 文件进行修改,path 定义添加相应类型字段来对信息进行记录,可通过explain+SQL查询方式在PostgreSQL数据库中显示SQL查询执行计划树。
需有相应负载才能进行数据采集工作,在查询负载运行中收集数据。因为TPC-H 由一系列操作符组成执行树,是复查查询,在采集数据中,会遇到下面两个问题:
(1) 在测试平台中,虽然能够实时的监按测试机的运行功耗,但因物理操作符不确定的执行时序,对每个操作的执行时段很难确定,所以对其运行功耗也很难确定。(2) 系统信息采集对于单个操作符有着较大的误差,这是因为对meminfo文件、proc 文件等段时间内频繁的读取导致的。
由此,本文对于数据的收集提出简单负载原则通过查询负载进行有效的收集,另外对操作符真实功耗通过数据有效的进行反映。在运行负载设计时,尽可能的使不同查询不存在操作符交集、单个查询涉及较少操作符、尽可能的整个负载包括所有类型操作符。
2.3 执行计划的功耗模型
根据训练数据集,对操作符层功耗模型采取回归分析法来进行建立,对于单个物理操作符采取两个特征数据来得到预测功能模型:(1) 在DBMS 内部,对执行时的元组数目、选择读以及读取页面数目等信息进行采集。(2) 目前CPU使用率,单个操作符预测功耗为:
对于F 通过训练数据集来进行回归分析,计算复杂度在实际使用中要进行考虑,总误差率值为f,误差率
作为目标函数。
下一步,对于查询计划平均功耗由单个物理操作预测功耗来进行估计,由物理操作符构成的执行计划树能够作为任意一个查询,一个合法的执行计划树都是由每组操作符有序执行的结果。tO在传统代价估计中表示操作符时间估计,TQ表示执行计划时间估计,如公式(5)所示。
总时间可通过时间累加表示,但是功耗累加没有任何意义。本篇文章来加权累加每一个操作符的功耗,而不是对操作符直接进行叠加,其得到的查询功耗,如公式(6)与公式(7)所示。
在上述公式中,Tmp 表示中间变量,计算操作符时间和功耗的乘积。
3 分析TPC-H 基准测试结果
3.1 预测精度
对于TPC-H 基准在两种不同系统下进行测试,在生成的数据集中对TPC-H 测试查询语句分别运行,对于查询执行平均功耗通过能耗测试平台进行计算统计,以此对模型精度进行计算。
对竞争运行环境与静态运行环境下的性能进行测试,静态因依次单个执行测试查询,独占系统,竞争不是独占系统资源,存在其他应用,通过Web 服务程序来进行模拟。
3.2 能耗有效查询优化的总体性能
时间性能随着α 的增加而变差,且平均功耗降低,符合预期。查询优化器在功耗与性能间的均衡通过α能够有效的进行调节,如果α 的值设置的较大,那么就会偏向功耗低的执行计划,由此会降低执行的时间性能,实验中能够得出,能耗有效性在α 值为0 到0.30 时比较好。
4 分析TPC-C 基准测试结果
TPC-C是联机事务处理的基准测试,能耗有效查询优化策略通过使用TPC-C 来对联机事务处理性能进行测试,实验中定义能耗有效性为:
通过测试结果能够得出:对于能耗通过将功耗代价添加到查询优化器中而能够进行优化,但是不能只对功耗进行优化,而对性能选择忽视。
结束语
本篇文章在优化器中将能耗代价引入其中,并对功耗预测提出回归分析操作符方法。此外,查询代价模型在引入性能退化调节因子后能够兼顾性能与能耗,对于能耗有效查询优化器在在PostgreSQL上进行实现。能耗有效查询优化技术的可行性以及实用性通过TPC-C 和TPC-H 结果得到了验证。
在本次实验中,对于能耗与性能测试根据开源的PostgreSQL 进行开展,目前商用DBMS 采用了类似PostgreSQL 的查询优化技术。所以本次结果具有普适应,能在其他关系型数据库中进行推广应用。
未来对于聚集、连接等复杂查询操作符的功耗代价估计方法进行研究,针对性的提出能耗有效查询优化的方法。另外,目前通常以服务器集群的方式来对数据中心进行部署,数据中心在能耗方面不但会受服务器节点的影响,其也会因集群中的数据迁移与分布式调度等情况而受到影响,对于以后的工作,能耗有效的解决方案可通过数据中心的任务调度以及分布式查询处理等进行研究。
