一种自适应图像插值算法及加速引擎的协同设计
2023-10-17严忻恺丁晟
严忻恺 丁晟
①(浙江大学 杭州 310015)
②(江苏省专用集成电路设计重点实验室(无锡) 无锡 214153)
1 引言
在图形图像处理领域,像素性能常常是芯片系统的性能瓶颈,减轻图形渲染的计算和访存负载对于提升图形芯片性能有重大帮助。将图形图像先进行低分辩率渲染后由算法重建放大至期望分辨率的超分辨率重建技术已经成为主要的性能优化手段。它被广泛应用于现代社会中的各个领域,如多媒体传输、大型游戏、医疗图像、公共安全等,它是信息学、计算机视觉和机器学习等学科的结合。同时随着5G技术和计算机硬件的不断进步,图像传输的质量也不断提高,支持高清(1080×720)、全高清(1920×1080)、超高清(3840×2160)图像或视频的实时性应用变得越来越广泛,这对网络带宽和硬件设备都产生了巨大的压力。单帧图像或多帧图像的重建根据方法不同可以分为基于插值的图像重建[1–8]、基于学习的图像重建[9–11],以及基于深度学习的图像重建[12–16]等。
基于插值的图像重建算法利用新像素和原始像素的线性/非线性关系,根据放大因子在已有图像像素中插入固定数量的新像素来补充高分辨率图像缺失的像素,基于插值的图像重建算法具有算法简单、适合并行、运算速度快的特点,但是随着图像放大因子的增加,重建图像会出现模糊、振铃效应、锯齿效应和边缘平滑等问题;基于深度学习的图像重建算法利用卷积运算可以更有效地自动提取图像细节特征,解决底层视觉问题,生成质量更优的高分辨率图像(例如降噪、去模糊等),比如使用残差网络来增强层间连接,将低分辨率图像特征信息传到更深层,缓解梯度消失和特征丢失问题,使用生成对抗网络中多个生成器的感知损失和对抗损失信息,提升高分辨率图片的真实感。不过基于深度学习的图像重建算法也存在一定的场景约束,比如监督学习网络需要图像训练和测试数据集支持,无监督学习网络需要算法迭代导致实时性较弱等。
因此基于插值的图像重建算法比较适合对实时性要求相对较高,对放大因子要求较小,对图像重建质量要求也相对较低的场景。在以上场景中基于插值的图像重建算法仍被广泛使用和研究,如AMD公司和NVDIA公司也先后推出了基于图像插值算法的游戏加速插件FSR[17]和NIS[18],以及基于插值算法的硬件加速结构研究[19–22]。所以针对特定场景,研究基于插值的图像重建算法和硬件加速结构来提高高分辨率图像质量,加快计算速度,减少硬件开销仍然非常必要。
本文提出了一种自适应图像插值算法和加速引擎的协同设计,算法得到的图像质量相比于双线性插值分别在平均峰值信噪比(Peak Signal to Noise Ratio, PSNR)、结构相似度(Structural SIMilarity,SSIM)和图像感知相似度(Learned Perceptual Image Patch Similarity, LPIPS)上可以提高1.1 dB,0.025和0.051;相比于双三次插值分别在PSNR,SSIM和LPIPS上可以提高0.34 dB, 0.01和0.033。本文提出的加速引擎具有高并行高可扩展的特点,并且通过数据重用和参数优化,能够提升加速引擎的能效比,节省硬件开销。
本文的组织结构如下:第2节介绍图像插值概述,主要包括Lanczos插值和边缘检测;第3节详细介绍提出的自适应图像插值算法;第4节详细介绍加速引擎架构设计;第5节给出图像质量比较结果;第6节得出结论。
2 图像插值概述
图像插值技术一直是图像处理领域中的研究热点,从经典的基于局部数据的线性插值算法,如双线性插值算法[1]、双三次插值算法[2],到近些年关注基于样例的非线性插值算法如基于边缘导向的插值算法[4]、软判决自适应插值算法[6]、对比度引导法等插值算法[7]等。
2.1 Lanczos插值
Lanczos插值算法是图像线性插值算法的一种,它是Lanczos窗函数在图像处理领域的应用,Lanczos插值算法是对图像在X轴和Y轴分别进行插值处理。由于Lanczos插值算法的系数在缩放大小确定后是固定值,硬件可以通过IO寄存器写入固定的存储器中使用,从而进行插值操作,而不需要在计算过程中生成相关系数。Lanczos插值对于减少振铃效应、锯齿效应有较好的效果,它的计算公式为
其中,d表示带插值像素点到原像素点的距离,r表示插值窗半径。由于本文选取缩放因子4,所以待插值像素点到原像素点在X方向和Y方向的距离d={0.125,0.375,0.625,0.875},r=4。
2.2 边缘检测
由于图像特征中边缘的重要性以及人眼系统对图像边缘的敏感性,而传统插值算法对图像边缘的处理效果并不理想,所以针对图像边缘进行优化和提高图像质量是图像插值的一个重要研究方向[7,23]。基于边缘优化的图像插值算法一般流程如图1所示:
边缘检测一般用于灰度像素,彩色图像转换为灰度图像的过程如式(2):
常见的边缘检测算子有1阶算子(Sobel, Prewitt,Roberts, Canny)和2阶算子(拉普拉斯、高斯、LOG)。对于图像处理而言实际边缘情况较为复杂,但为了减少计算复杂度通常只检测0°/45°/90°/135° 4种边缘方向情况。但基于边缘检测的图像算法仍存在例如对彩色图像效果不佳、计算复杂度高、计算时长较长等问题。
2.3 协同设计分析
由于图像插值算法的复杂度直接影响硬件实现的复杂性和运算速度,因此需要协同设计图像插值算法和加速插值引擎。例如一些基于迭代更新的插值算法会显著增加算法运行时间和硬件存储开销;基于浮点运算的插值算法会引入浮点乘法部件,增加硬件开销;基于分步的算法将整个插值过程分为插值和锐化两个步骤,会导致硬件开销增加和算法运行时间的增加;基于边缘插值的算法有基础插值和边缘插值两个计算部分,这会增加乘法器资源的消耗。所以本文探索软硬件协同设计空间,寻找通过增加对硬件友好的少量加法操作和存储空间而不增加乘法器资源的方式实现加速引擎设计。
3 自适应图像插值算法
考虑到计算复杂度、存储复杂度和实时性需求,本文提出了一种基于边缘对比度的自适应图像插值算法,采用4种边缘方向的对比度探测,根据全局阈值和局部阈值来精确定位边缘;同时综合4个方向边缘检测的对比度计算结果,自适应地选择不同系数Lanczos窗函数生成的插值系数,对图像区域进行插值:
(1)对于平坦区域,采用式(1)产生的系数进行插值。
(2)对于边缘区域,根据不同边缘方向和对比度值,综合选择式(3)不同β值产生的系数进行插值。
当β>1时,Lanczos窗函数更尖锐,中心像素点的插值比例更高,本算法中r=4时根据对比度的不同,取βr=4=1.18,βr=4=1.22,βr=4=1.25。
考虑到高分辨率图像质量、算法复杂度和硬件复杂度的相互关系,本算法首先选择r=4时4级Lanczos 4窗函数(8×8个原始像素点)来增强生成高分辨像素点所需的局部信息;然后考虑到图像边缘情况的复杂性,相比于只计算像素中心点的边缘信息,本算法使用原像素中心点临近4×4区域像素点的灰度信息计算边缘计算所需的局部阈值以及计算原像素中心点临近2×2区域的边缘梯度,通过结果边缘梯度矩阵来提高边缘检测的准确度,以此实现不同感受野内的图像信息特征获取,从而提高生成的高分辨率图像质量。由于人眼对彩色图像中绿色分量最敏感,所以本算法使用式(4)取代式(2)来计算像素的近似灰度来进行边缘检测。通过近似灰度的方式,不仅可以节省分别对RGB分量进行串行边缘检测所需的算法运行时间或对RGB分量进行并行计算所需的硬件资源,还可以将定点乘加操作转换为整数加法操作,进一步节省硬件资源。
3.1 总体算法
本文算法步骤如下:
输入:低分辨率RGB彩色图像IMG_L。
输出:高分辨率RGB彩色图像IMG_H。
步骤1 读入图像,选取待插值点的8×8 Lanczos原像素点矩阵。
步骤2 进行边缘检测。
步骤2.1 将中央4×4像素点矩阵使用式(4)将彩色转换成像素近似灰度。
步骤2.2 用4个方向的Prewitt算子分别计算原像素中心点 (i,j) 和相邻(i+1,j), (i,j+1), (i+1,j+1)共4个点的梯度。
步骤2.3 将4个方向梯度和不同阈值进行比较,产生边缘对比度结果矩阵
步骤3 进行插值计算。
步骤3.1 插值系数选择,根据边缘对比度结果矩阵选择不同系数的Lanczos系数进行插值,按照边缘区域对比度结果,由高到低依次选择式(3)中不同β值产生的插值系数,对于平坦区域选择式(1)产生的插值系数。
步骤3.2 使用步骤3.1选择的系数,对低分辨图像8×8像素点进行插值计算,生成待插值点像素。
步骤4 将插值计算结果输出,得到最终高分辨率图像。
3.2 自适应边缘检测
在步骤2.2中,使用4个方向的Prewitt算子进行梯度计算,得到θ0,θ90,θ45,θ135,然后根据式(5)进行判断,得到二值化的边缘标志。
其中, TH=max(thg,thl) ,全局阈值t hg可以通过寄存器配置得到,本文中默认值为15, 127和255,局部阈值 thl由4×4近似灰度矩阵中的最大灰度和最小灰度的差值得到。
在步骤3.2中,算法根据中心像素点 (i,j)相邻的多级二值边缘标志矩阵组合成3维标志矩阵edge_flagdir,从而生成对应的插值系数选择。最终插值结果根据式(6)进行计算
其中:
(1) 当 edgeflag3(0,90,45,135)≥3时,采用式(3)且βr=4=1.25 产生的系数a lpha3,beta3;
(2) 当 edgeflag2(0,90,45,135)≥2时,采用式(3)且βr=4=1.22 产生的系数a lpha2,beta2;
(3) 当 edgeflag1(0,90,45,135)≥1时,采用式(3)βr=4=1.18 产生的系数a lpha1,beta1;
(4) 否则采用式(1) 产生的系数a lpha0,beta0。
最终基于2×2,4×4和8×8的不同感受野的插值合并过程如图2所示,通过合并大感受野的局部像素信息和小感受野的边缘细节信息,同时增加灰度感受野来提高边缘精确度,从而提高图像插值质量。
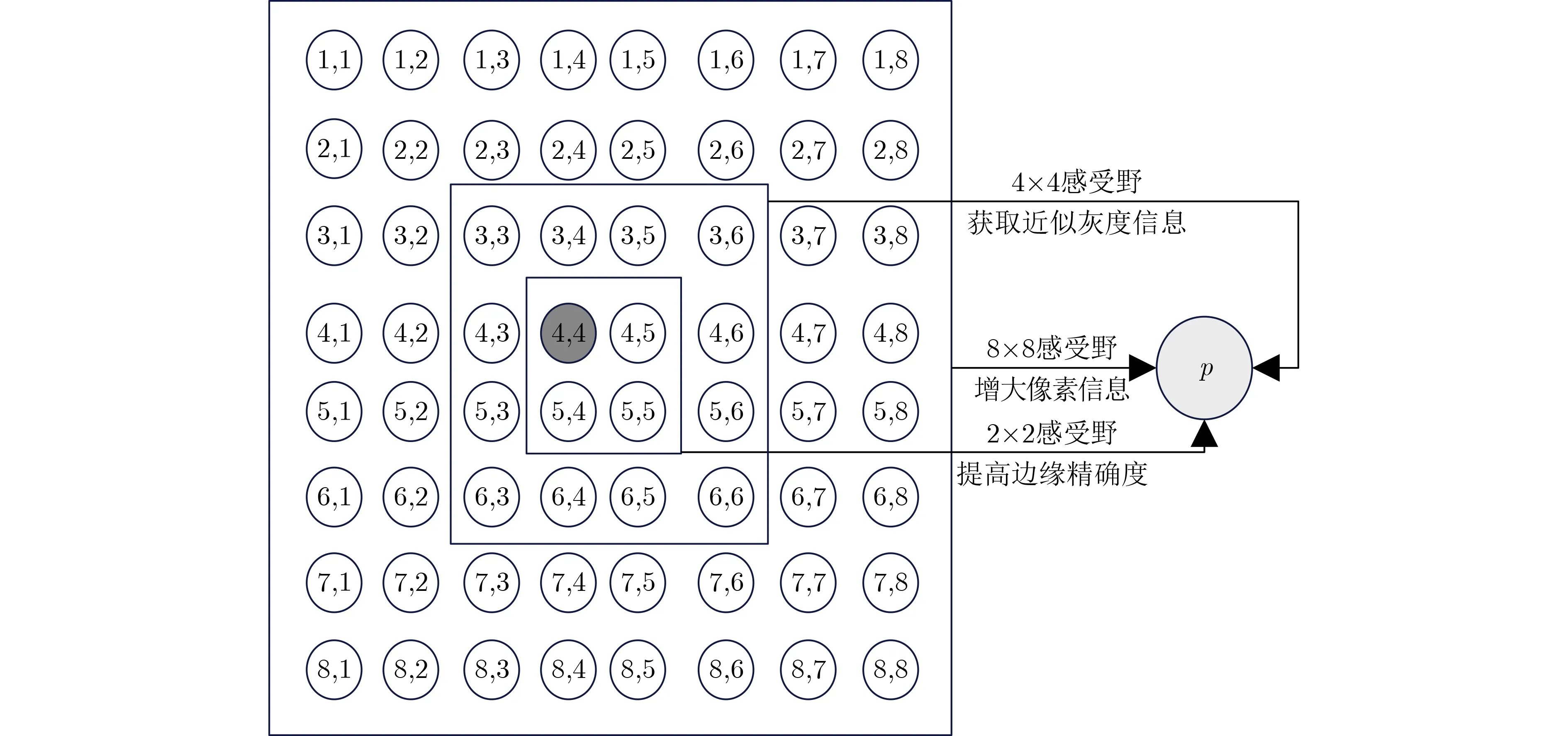
图2 各级感受野像素的合并插值示意图
4 加速引擎设计
加速引擎的总体架构如图3所示,主要由计算模块(插值引擎)和调度模块两部分组成,完成整个自适应图像插值算法的加速计算。

图3 加速引擎总体架构示意图
其中调度模块负责通过总线和内存进行数据交互,启动并分配调度插值引擎工作;计算模块负责实现自适应图像插值算法的硬件加速。
4.1 计算调度
通过在插值引擎中展开或折叠乘加运算,可以实现资源与处理时间的折中;同时Lanczos像素窗具有像素重叠特性,可以通过并行多个插值引擎实现较高的数据重用,从而减少访存需求和处理时间。本设计使用插值引擎内像素移窗和插值引擎间像素并行多播两级数据重用来减轻访存压力,同时减少行buffer和结果buffer的RAM开销。
4.1.1 像素移窗
在插值引擎内,像素处理遵循以下原则:
(1) 单个插值引擎1次处理 1 ×4个原始像素点,需要输入8 ×11个 像素点,输出4 ×16个插值像素点;
(2) 调度模块按图像垂直方向调度插值引擎,除图像上边缘外,每轮只输入11个像素点;
(3) 计算模块每轮处理的图像行宽为 4N(其中N为插值引擎个数)。
对于当前处理的原始像素点窗,在8×1 1个像素点的处理中有8×5的像素点是每轮都可以水平重用;而对于下一轮处理的原始像素点窗,在8×11个像素点的处理中有7×11的像素点可以垂直重用。除图像上边缘外,插值引擎每轮工作像素点的数据重用率超过80%。
4.1.2 并行多播
基于插值引擎内的水平方向数据重用原理,将其推广至多插值引擎的并行化处理,从而实现行buffer数据的并行多播和插值引擎间的数据重用。行buffer中的像素可以多播给并行的多个插值引擎,例如像素6会同时多播给插值引擎1, 2, 3使用。此外由于加速引擎采用图像列向处理顺序,所以行buffer无需开设大缓冲,能够节省片上存储资源。
4.2 插值引擎设计
插值引擎的结构总体框图如图4所示,它主要由5部分组成:
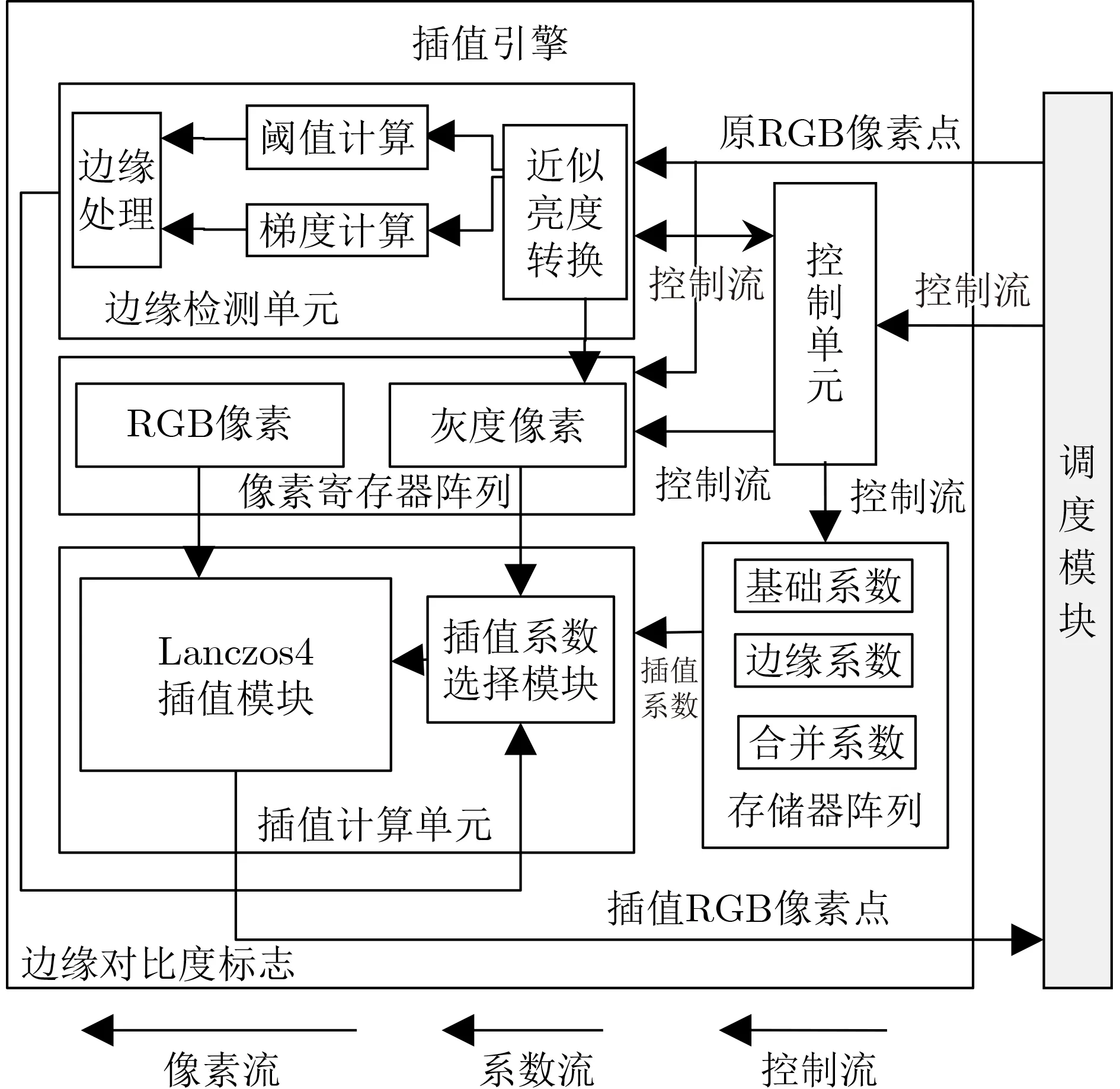
图4 插值引擎总体结构框图
(1) 控制单元:负责控制调度引擎,包含引擎控制模块;
(2) 像素阵列:负责储存像素信息,主要包含8×11 像 素点寄存器阵列和6 ×7像素近似亮度寄存器阵列;
(3) 存储器阵列:负责存储插值所需的权值,主要包含不同插值系数的RAM;
(4) 边缘检测单元:负责像素的边缘检测和边缘对比度标志矩阵生成,主要包含似亮度转换单元、梯度计算单元、阈值计算单元;
(5) 插值计算单元:负责各类计算处理,主要包含插值计算模块和插值系数选择模块。
4.2.1 工作模式
插值引擎支持按功能分为两种工作模式:基础工作模式和完全工作模式.
(1) 基础工作模式,即只采用插值计算插值点输出,关闭边缘检测单元;
(2) 完全工作模式,即按照先边缘检测,再生成对比度标志矩阵进行插值计算,最后将插值结果输出。
插值引擎支持块处理和行处理两种处理流程。块模式用于处理首次输入像素块或更新输入,行模式用于连续处理像素行的情形。调度模块1次输入1行RGB像素点,像素点存入像素阵列,且属于像素点窗中心4×4的像素点被同时送入边缘检测单元进行近似灰度转换,而后存入近似灰度阵列并送入下一级模块进行边缘计算。块模式下插值引擎接收8行像素点后开始插值计算,行模式下插值引擎接收1行像素点后开始插值计算。插值像素点按像素块从左到右顺序输出,每个像素块内按先行后列输出像素点。
4.2.2 边缘检测
边缘检测单元由阈值计算单元、梯度计算单元和边缘处理单元组成,如图5所示。整个边缘检测单元采用全流水结构设计,流水站台为4级。当调度模块输入像素点完毕后,控制单元分别将近似灰度矩阵中的1 ×4的中心像素点所需的4×4灰度像素送入边缘检测单元中进行计算,得到中心像素点(i,j)相邻二值边缘标志矩阵,包含0°, 45° , 90°, 135°在三级阈值下的4个二值边缘标志,用于索引插值系数RAM中对应的条目。

图5 边缘检测单元结构图
阈值计算单元负责计算原像素中心点临近4×4区域内的最大和最小近似灰度像素,并与预配置的全局阈值进行比较得到本次边缘计算所需的最大和最小阈值。图5(a)中阈值计算单元由3级全流水结构组成,第1级站台计算4×4近似灰度矩阵内各行的最大/最小值;第2级站台对得到的4组最大/最小值进行比较计算,得到4×4区域内的最大/最小值;第3级站台将区域最大/最小值和全局阈值进行比较,得到最终所需的阈值,发送到边缘处理单元中使用。
梯度计算单元负责计算原像素中心点临近2×2区域4个像素点的4个方向梯度计算。图5(b)中梯度计算单元由3级全流水结构组成,第1级站台并行计算1个像素点在4个方向上的近似灰度差值,本设计采用中间结果合并计算方式,将原本需要20个9位加法器的开销缩减到4个9位加法器和8个10位加法器;第2级站台计算4个方向的最终梯度结果;第3级站台计算0°~90°方向的最大/最小梯度和45°~135°方向的最大/最小梯度,发送到边缘处理单元中使用。
边缘处理单元负责计算二值边缘标志矩阵。图5(c)中边缘处理单元由1级站台结构组成,根据阈值计算单元和梯度计算单元的数据输入计算出0°, 45°, 90°, 135°的二值边缘标志矩阵,将结果发送到索引插值系数RAM中对应的条目中存储。
4.2.3 插值计算
考虑到Lanczos的算法特性以及计算并行度、硬件开销和功耗,本文设计了一种高能效的插值计算单元,图6给出了插值计算单元结构图。

图6 插值计算单元结构图
从图中看到,插值计算单元由9个MAC乘累加单元和寄存器组成,其中水平方向插值计算单元包含8个乘累加单元,竖直方向插值计算单元包含1个乘累加单元。插值计算单元的设计思路如下:
(1) Lanczos插值算法按照先水平方向后垂直方向的插值顺序,所以水平方向插值计算单元先接收像素点输入。
(2) 在Lanczos插值算法中所有水平方向的各行像素点共用一套插值系数(8个int16整数),所以将水平方向插值计算模块设计为权值传递,像素点并发的方式,减少对RAM的访问;
(3) 水平方向插值计算单元有8个独立的像素乘累加单元。每个乘累加单元分别处理1行像素点,按从左到右顺序依次按拍输入像素;8个乘累加单元的像素点从左到右依次错1拍输入,从而和对应位置系数相乘;
(4) 每个乘累加单元包含3个16×16+32的有符号乘累加,分别计算r, g, b 3个通道的像素,得到水平插值结果h1~h8;
(5) Lanczos插值算法的垂直方向插值计算将8个水平方向的乘累加结果分别和对应的系数相乘并累加;
(6) 水平方向插值计算的8个结果是连续8拍输出,所以垂直方向只需要1套乘累加计算模块。
4.2.4 延迟和吞吐率
假设乘累加单元的延迟为p( 其中p=pmul+padd),所以块模式时整个启动开销为N+n+3p+8拍,其中N为像素加载延迟,n为边缘检测延迟,3p为水平乘累加、垂直乘累加和合并插值的延迟。像素输出频率为每8拍输出1个插值像素点,所以块模式时需要8 +n+3p+128拍输出完成16个插值像素点计算输出,需要8 +n+3p+512拍输出完成64个插值像素点计算输出;行模式时需要1+n+3p+128拍输出完成16个插值像素点计算输出,需要1+n+3p+512拍输出完成64个插值像素点计算输出。
4.3 资源开销
4.3.1 乘累加单元
乘累加单元是插值引擎中占用硬件资源最多的逻辑器件,插值引擎中乘累加单元的数量如表1所示。在2 GHz时钟频率约束的16 nm综合结果中,若使用int8×int16+int24的乘加器实现,则使用组合逻辑数量为12 474,时序逻辑数量为1 296;若使用int16×int16+int32的乘加器实现,则使用组合逻辑数量为20 520,时序逻辑数量为1 728。
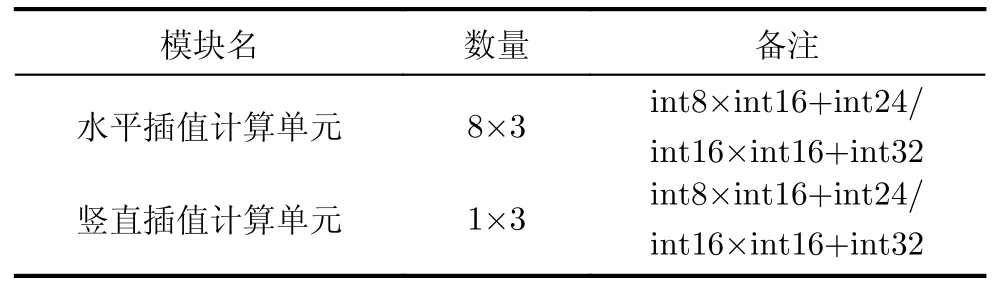
表1 乘加器单元数目
4.3.2 加法器单元
加法器单元是插值引擎中边缘检测单元主要占用的硬件资源,插值引擎中加法器单元的数量如表2所示。在2 GHz时钟频率约束的16 nm综合结果中,加法器单元共使用组合逻辑数量为1 445,时序逻辑数量为366。

表2 加法器单元数目
4.3.3 RAM
插值引擎中的RAM用于存放插值系数,单个插值引擎中的RAM容量如表3所示。其中插值系数RAM保存4组Lanczos4插值系数(分别为βr=4=1,βr=4=1.18 ,βr=4=1.22 ,βr=4=1.25产 生 的 系数),每组插值系数由4(间隔)×8(系数)组成,每个系数为int16类型。
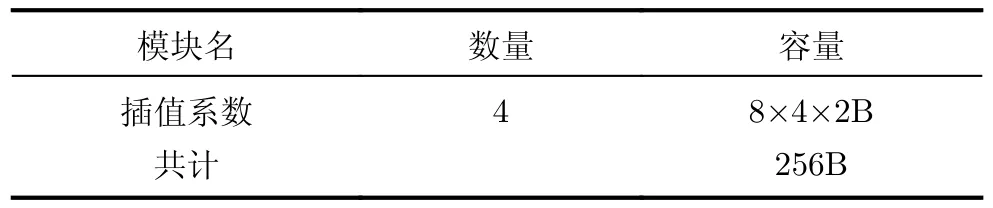
表3 插值引擎的RAM容量表
4.3.4 寄存器阵列
插值引擎中的寄存器阵列用于存放原始像素点、近似灰度像素、乘累加单元结果缓存、流水线站台和控制寄存器等,表4列出插值引擎中主要的寄存器数量。
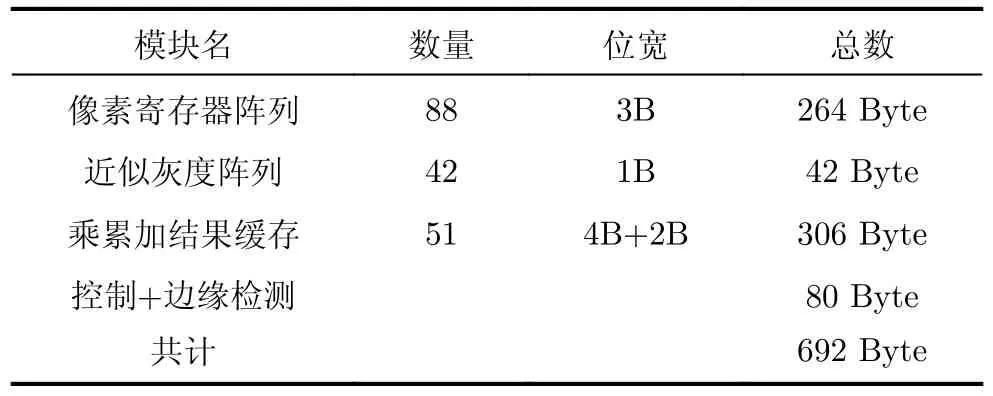
表4 插值引擎的寄存器数目表
4.4 FPGA仿真
本文设计的加速引擎在Xilinx Zynq Ultra scale+xczu15eg进行仿真,使用FPGA内置的DSP48单元中3拍流水乘法器实现乘累加部件,插值引擎的综合频率可以达到200MHz。实例化24个插值引擎进行并行处理,对缩放因子为4,分辨率为960×540图像的插值总处理时长为15.24 ms,处理帧率(fps)达到60。本文设计的插值加速引擎在UVM验证环境进行测试激励仿真以及FPGA仿真的结果输出和CPU软件算法输出保持一致,无像素差异。
5 实验结果
5.1 实验环境
图像插值算法客观评价指标是指原始图像降采样处理后再通过图像插值获取高分辨图像,比较降采样处理前和插值处理后图像间的偏差,通过偏差值来判断图像质量的优劣。为了测评本文提出的自适应图像插值算法,选用了MATLAB提供的3种代表性算法(双线性插值法(bilinear)、双三次插值法(bicubic)和Lanczos3插值法)和OpenCV提供的Lanczos4插值法作为比较,实验环境如下:程序编写所基于的平台是 MATLAB,版本是R2022a,测试数据集由47张3D游戏图像组成,每张高分辨率原图大小为3 840×2160,均值下采样后每张低分辨率图像大小为9 60×540。
5.2 算法结果对比
实验分别采用峰值信噪比(PSNR)、结构相似度(SSIM)和图像感知相似度(LPIPS)[24]作为图像质量评价标准,图像插值结果与原图进行对比。表5给出了本文算法和双线性插值、双三次插值和Lanczos3/4插值法计算单个插值点的复杂度对比。实验对比结果如表6~表8所示。由于PSNR仅计算图像之间的灰度值差异,并没有考虑到图像之间的结构关系,而SSIM从亮度、对比度和结构3个方面分别进行比较,所以增加LPIPS比较,因为LPIPS更符合人眼系统的评价标准。

表5 不同算法的复杂度对比
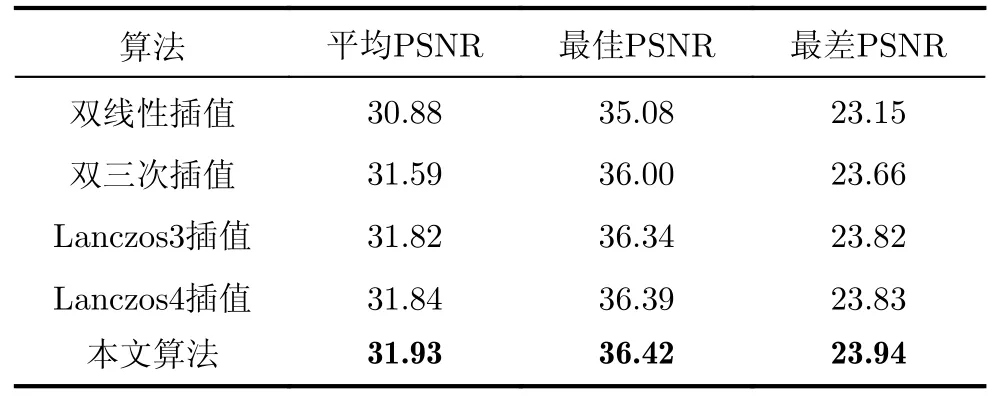
表6 不同算法的PSNR对比(dB)
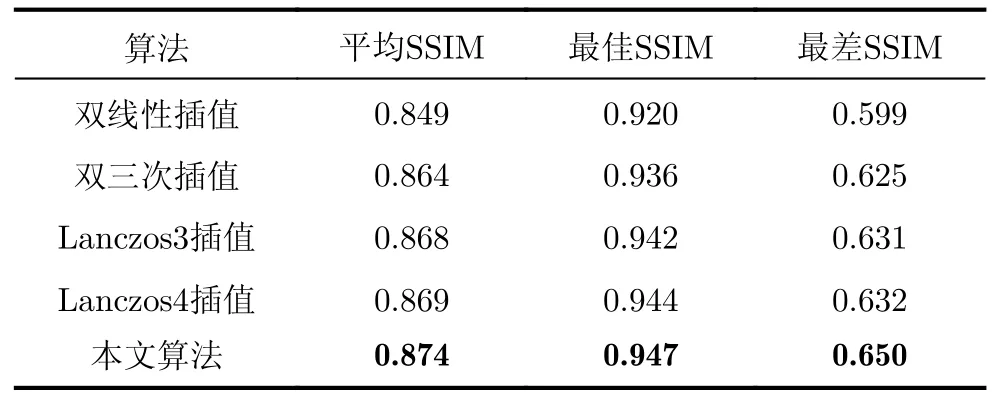
表7 不同算法的SSIM对比
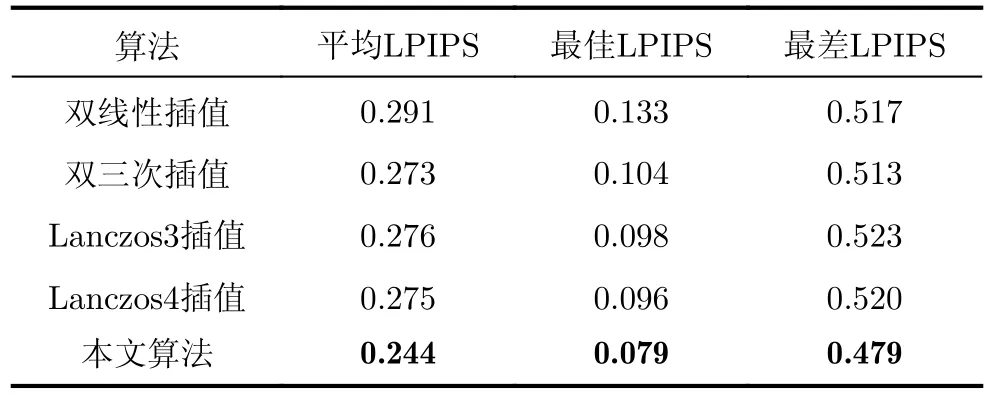
表8 不同算法的LPIPS对比
从表6~表8中可以看出本文算法相比于双线性插值、双三次插值和Lanczos3/4插值法在各项图像评价指标上均有明显提升,相比于双三次插值,本文算法在P S N R 上提升较为明显,相比于Lanczos3/4算法,本文在LPIPS上提升较为明显。此外通过分析测试集中图像质量相对较差的图像,本文算法在图像包含大量杂乱纹理和阴影时处理效果提升相对较少。
5.3 硬件指标对比
本文选取基于插值算法的FPGA硬件实现进行比较,比较结果如表9所示。同时由于基于FPGA平台的硬件实现大多面向低分辨率的灰度图像,所以本文进一步选取支持高清分辨率彩色图像放大的ASIC硬件实现进行比较,硬件指标结果对比如表10所示。
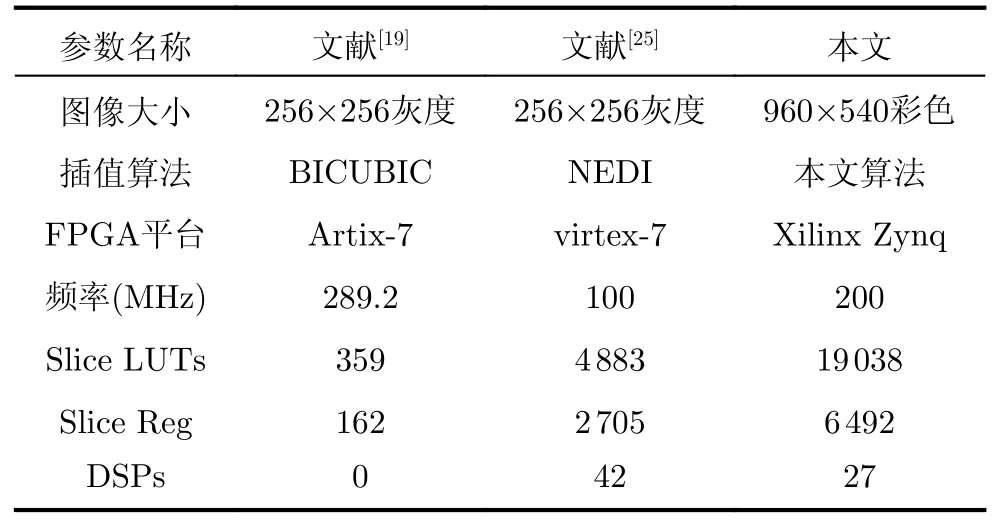
表9 FPGA硬件实现的指标对比

表10 ASIC硬件实现的指标对比
从表9可以看出由于本文算法使用的Lanczos4窗函数需要8×8像素空间信息和4×4近似灰度像素空间信息,这会增加硬件寄存器开销;由于本文硬件实现支持缩放因子为4的彩色高清图像并进行边缘检测,所以增加了LUT硬件资源开销。假定16 nm工艺相比于40 nm/65 nm工艺分别有2代和3代的性能/面积提升(每代提升1.4倍),从表10可以看出相比于基于卷积和学习的硬件实现方式,本文硬件实现采用的优化技术可以明显减少RAM开销和逻辑门数量,所以本文提出的硬件结构对于实时性要求高、硬件开销低且对彩色高清图像重建质量要求相对较低的场景具有较好的适配性。
6 结束语
本文对图像插值算法和加速引擎进行协同设计,提出了一种基于边缘对比度的新型自适应图像插值算法和高并行高能效的插值引擎,主要应用于单帧高清彩色图像放大。本文提出的算法使用边缘对比度检测和不同尺度的感受野来自适应选择Lanczos插值的系数,自适应性和不同感受野可以进一步提升图像放大质量。此外本文通过协同软硬件协同设计,只通过增加少量加法器和RAM存储空间而不增加乘法器资源的方式实现加速引擎设计。同时本文设计的加速引擎能够通过像素移窗和像素多播的两级数据重用来减少行buffer容量和降低访存需求,根据算法特性采用权值传递的全流水插值计算单元来减少RAM访问功耗,提高插值引擎的能效比。未来将着重研究更优的边缘检测算法来提升高清彩色图像的超分辨重建效果。
