合成孔径雷达深度学习成像研究综述
2023-10-17张宏伟倪嘉成
张 群 张宏伟 倪嘉成 罗 迎
(1.空军工程大学信息与导航学院,陕西西安 710077;2.空军工程大学研究生院,陕西西安 710077;3.信息感知技术协同创新中心,陕西西安 710077;4.复旦大学电磁波信息科学教育部重点实验室,上海 200433)
1 引言
合成孔径雷达(synthetic aperture radar,SAR)通过宽带信号脉冲压缩以及虚拟孔径合成来获得高分辨率图像,且不受时间和天气的影响[1]。目前,SAR 已经被广泛应用于各种军事和民用侦察平台,包括机载SAR、弹载SAR、星载SAR 等[2],而且SAR逐步向多极化的方向发展,按照雷达设备位置、波束扫描方式、成像目的用途等可分为适用于各种任务场景的雷达系统。从雷达设备位置分布考虑,SAR 可分为单基SAR、双基SAR、多基SAR(以星载SAR 为主),其中单基SAR 的发射机和接收机位于同一系统平台,双/多基SAR的发射机和接收机则位于不同平台[3];按照雷达运动过程中的波束扫描方式,SAR可分为条带SAR、扫描SAR、聚束SAR等[4];在成像用途方面,SAR 还包括静止场景高分辨率SAR 系统、动目标聚焦SAR 系统、三维(3D)SAR 系统、极化SAR 系统等,其中3D-SAR 系统主要由干涉SAR、层析SAR、阵列SAR、圆迹SAR 等组成[5]。受SAR 通过孔径合成实现分辨率性能提升的启发,衍生出一种针对空天运动目标的成像技术——逆合成孔径雷达(Inverse Synthetic Aperture Radar,ISAR)成像技术[6]。与SAR 原理相反,ISAR 采用目标运动而雷达静止的方式来实现孔径合成,其距离高分辨同样依靠大带宽实现,但其方位高分辨则通过目标相对雷达的转动来实现。这种成像技术可以获得空天非合作目标的二维高分辨率图像,进而通过提取目标的形状和结构等特征完成准确识别和分类,目前主要用于对空天非合作目标的探测和侦察等。
作为一种主动微波成像系统,SAR 发射一系列脉冲并通过处理接收的回波对探测区域进行二维成像,以此来获得与光学图像类似的目标场景图,便于进一步的分类和识别操作。在20 世纪50 年代,SAR 成像通过模拟域的光学透镜组来实现[7]。随着信号处理技术的成熟发展以及硬件设备的性能提升,基于模型驱动和奈奎斯特采样定理的匹配滤波(matched filter,MF)方法逐步成为SAR 成像的主要手段,如距离多普勒算法(range-Doppler algorithm,RDA)、线频调变标算法(chirp-scaling algorithm,CSA)、后向投影算法(back-projection algorithm,BPA)和Omega-K 算法(Omega-K algorithm,Omega-KA)等[8-11]。这种MF 方法不依赖于场景先验信息,通过构建观测模型对目标场景进行近似处理,所获得的成像结果分辨率较低且旁瓣干扰严重。因此,若想提升MF 聚焦算法的成像质量,则需要更高的雷达发射信号带宽以及大量的测量和数据采样,这导致系统硬件在存储和处理大规模SAR数据时负担较重。随着压缩感知(compress sensing,CS)理论和深度学习(deep learning,DL)技术的出现,SAR 成像在高维数据处理和高质量成像方面取得了明显进步,并且在遥感测绘、资源勘探、区域侦察等领域中发挥着越来越重要的作用[12]。
不同于奈奎斯特采样定理,CS提供了通过少量观测数据精确重构稀疏信号的可能性[13]。基于CS的稀疏SAR 成像作为近期的一个热点问题,已经受到广泛关注[14]。现有的文献主要利用CS 理论研究具有创新性的SAR 高分辨率成像技术及其潜在应用。已经证明,如果SAR 成像结果在空域或变换域中是稀疏信号,则可将SAR 成像构建为逆问题,利用场景先验知识对逆问题求解模型进行约束,从不完整的SAR 回波中高精度重构目标散射场[15]。这种场景散射系数在稀疏表征条件下的重构问题可以利用迭代优化算法解决,例如迭代收缩阈值算法(iterative shrinkage threshold algorithm,ISTA)、近似消息传递算法(approximate message passing,AMP)、交替方向乘法器法(alternating direction method of multipliers,ADMM)等[16-18]。虽然稀疏SAR 成像方法可以在低采样率情况下获得具有高分辨率和低旁瓣的重构图像,但其仍受限于稀疏成像方法中两个普遍存在的缺点,即难以确定的算法最优参数以及复杂且耗时的迭代成像机制。
DL 技术具有出色的特征学习以及拟合表征能力,已经在光学图像处理、语音识别、自然语言处理等领域得到了广泛研究[19]。近年来,DL 技术的不断成熟引发了众多学者对SAR 图像处理领域的进一步探索,主要集中于基于DL 的SAR 图像识别与解译[20],而基于DL 的SAR 成像研究目前仍处于起步阶段,且在近两年得到快速发展。对于SAR 学习成像而言,DL 为突破传统SAR 成像方法的局限性提供了一种新的解决手段,即采用离线训练来代替在线优化[21]。这种新颖的学习成像方法利用网络训练的方式探索输入数据到高精度成像结果的精确映射,其中网络输入数据既可以是聚焦效果不理想的图像数据,也可以是雷达观测获得的回波数据。前者在图像域内实现目标散射场景的去噪优化、特征增强和分辨率提升,称为增强成像,通常采用数据驱动DL成像技术;后者在回波域与图像域之间建立映射,实现观测数据到散射系数的高质量实时重构,称为端到端成像,包括数据驱动DL成像技术以及模型驱动同数据驱动相结合的DL成像技术。
数据驱动的思路是利用海量数据寻找和建立内部特征关系,进而完成问题求解。深度神经网络(deep neural network,DNN)作为一种以数据驱动为主的网络结构,由输入层、多级隐藏层、输出层等组成,通过隐藏层的特征学习实现输入与输出的实时转换。目前,已经开发了许多DNN 架构,包括卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)、生成对抗网络(generative adversarial network,GAN)等[22]。数据驱动DL 成像技术可应用于增强成像以及端到端成像研究,这种方法不考虑雷达成像模型,而是将DNN 视作黑盒,通过大量数据实现非线性拟合,进而学习从散焦图像或观测回波到成像结果的直接映射。除此之外,在端到端成像领域还存在另一种将模型驱动方法与数据驱动方法相结合的DL 成像技术。与传统基于模型驱动的MF 和CS 成像算法不同,这种方法将成像模型中的图像重构和参数优化等计算压力转移到数据驱动层面,训练完成的网络仅需要一次前馈运算便可实时成像。该学习成像方法弱化了模型失配的影响,同时避免了复杂的成像机制和参数选取过程[4]。综上所述,两种基于DL 的雷达成像技术具有改善聚焦性能、提升分辨率、提高计算效率等优势。
本文围绕DL 网络和成像模型之间的联系,介绍了两种DL 成像技术的网络架构。在此基础上,整理并综述了SAR 学习成像和ISAR 学习成像领域的研究现状,随后对学习成像目前亟待解决的问题和未来发展趋势进行探究,旨在帮助后续研究人员理解学习成像技术并为其提供相关思路。
2 SAR学习成像方法
SAR 学习成像能够克服传统MF 和CS 成像方法的缺点,按照应用场景可划分为2D-SAR 静止目标学习成像、2D-SAR 运动目标学习成像和3D-SAR学习成像,其中2D-SAR 静止目标学习成像按照成像目的又可划分为基于DL 的SAR 增强成像以及SAR 端到端成像。对于这些研究领域而言,尽管针对的SAR 成像问题各不相同,但其成像机制均围绕数据驱动DL 成像技术以及模型驱动同数据驱动相结合的DL成像技术进行设计。
2.1 SAR静止目标学习成像
2.1.1 基于DL的SAR增强成像
SAR 静止目标增强成像包含目标特征增强和图像去噪增强两方面。对于SAR 目标特征增强技术而言,传统的稀疏正则化目标特征增强方法(例如:l1正则化和全变分正则化等[23-24])仅能利用场景的通用特征,难以对特定区域的目标实现增强成像。2017 年,徐宗本院士和吴一戎院士等人探究了l1/2正则化理论对目标特征增强技术性能的提升[25]。2020 年,电子科技大学万群教授团队提出一种结构化目标增强成像方法,通过获取目标的属性特征参数来实现结构化散射特征增强[26]。目前,基于DL的目标特征增强技术尚处于起步阶段。2017 年,西安电子科技大学的侯彪教授团队提出一种基于无监督学习和语义信息引导的正则化目标增强重构方法,利用SAR 图像的不同语义特性完成目标增强[27]。2019 年电子科技大学师君教授团队利用DNN实现SAR散焦目标的自聚焦增强[28]。随后,该团体于2021 年提出一种基于编解码结构的SAR 特征增强网络,实现了散焦目标幅度域的快速自聚焦[29]。
SAR 图像去噪增强的目的在于去除噪声污染,实现分辨率性能提升。SAR 图像经常受到乘性噪声的影响,这种噪声污染在图像中表现为散斑,不利于SAR 图像进一步的目标识别和解译。传统的图像去噪手段(例如:基于概率窗口匹配的去噪算法(PPB)、SAR 块匹配三维去噪算法(SAR-BM3D)、SAR 块排序变换域滤波去噪算法(SAR-POTDF)等)很难做到散斑干扰去除与图像细节保护之间的折中[30],而数据驱动DL 技术对于含噪SAR 图像具有良好的细节保持能力[31]。近年来,已经有许多研究将DNN 应用于SAR 图像相干斑抑制和超分辨率重构,其中CNN模型应用最为广泛。
2017 年,CHIERCHIA 等人首次尝试采用CNN和残差学习策略实现SAR 图像去散斑[32]。该方法通过CNN 恢复图像中的乘性噪声,然后利用残差单元从低信噪比(signal-to-noise ratio,SNR)图像中减去散斑分量,获得了优于SAR-BM3D 的清晰SAR 图像。紧接着,文献[33]提出一种自动去散斑的图像去斑CNN(image despeckling CNN,ID-CNN),并采用欧式距离损失和全变差损失相结合的损失函数进行训练。与文献[32]不同的是,ID-CNN 中的残差单元通过将原始图像与CNN 输出噪声相除来恢复去噪图像。受ID-CNN 的启发,北京航空航天大学王俊教授团队提出一种去散斑网络与目标分类网络耦合的双极CNN 结构[34],用于研究散斑噪声和去散斑过程对SAR 场景中地面目标分类的影响。DL技术解决SAR 图像去噪问题可以看作一种将噪声图像映射为去噪图像的优化问题[35],DNN 正是利用其自身强大的拟合能力来学习这种复杂映射。2018年,武汉大学袁强强教授提出一种SAR 扩张残差网络(SAR dilated residual network,SAR-DRN)来学习SAR 噪声图像和干净图像之间的非线性映射[36]。DRN 用扩张卷积代替传统的卷积层,既可以扩大感受野来增强图像领域信息,又可以保持滤波器大小避免增加计算负担。仿真和真实SAR 场景实验均表明,与PPB 和SAR-POTDF 等传统方法相比,DRN 的去噪性能优势明显,尤其对于强散斑图像。在SAR-DRN 的基础上,2019 年成都电子科技大学张晓玲教授团队提出一种基于扩张卷积和残差学习的网络结构[37]。与SAR-DRN 相比,该网络层数更少、连接更为简单,在去噪性能和时间成本方面性能更优。同年,受SAR-DRN 和U-net 启发,文献[38]提出一种基于U-net 的编解码残差去噪结构,性能优于SAR-BM3D 和SAR-DRN。类似地,2020 年燕山大学史洪印团队为减轻P 波段星载SAR 图像的电离层失真,提出一种在编码器和解码器之间嵌入残差网络的改进U-net 结构[39],该网络可以实现RDA 失真成像结果到理想点目标的超分辨映射,对于电离层扰动具有较好适应性。无独有偶,同年南京航空航天大学雷达成像与微波光子技术教育部重点实验室张方正教授提出一种基于DL的快速BPA 成像方法[40],利用CNN 对BPA 的低分辨率SAR 成像结果进行去噪增强。为进一步保留SAR 图像中的重点信息,河北大学刘帅奇副教授团队在非下采样剪切波变换域(non-subsample shearlet transform,NSST)提出一种基于CNN 和连续循环平移(consistent cycle spinning,CCS)的混合SAR 图像去噪方法[41]。不同于传统的CNN去噪网络,该方法主要处理通过NSST 获得的SAR 图像低频和高频系数,利用CNN 消除低频系数中的噪声,并使用CCS 增强高频系数,以此来保留原始SAR 图像更多细节。2021 年,该课题组引入注意力机制,提出一种多块级联残差注意力去噪网络(multi-level residual attention denoising network,MRANet)[42]。MRANet 通过残差通道注意力关注重点特征,并利用卷积层和残差学习策略实现图像去噪,该网络在抑制噪声的同时,可以保留SAR 图像轮廓和边缘细节。在此基础上,该团队于2022年提出一种多尺度残差密集双注意力网络(multiscale residual dense dual attention network,MRDDAN)[43],利用通道注意力和像素注意力两种模块更加准确地学习SAR 图像关键信息,进一步平衡纹理信息保护与图像去噪之间的关系。
除CNN 以外,GAN 同样被应用于SAR 图像去噪研究。2017 年,Patel 等人首次基于GAN 提出SAR 图像去斑网络,称为ID-GAN[44]。2019 年,中国科学院大学张红研究员等人提出一种基于GAN 的SAR 超分辨率图像增强方法[45],旨在重构接近真实SAR 场景的超分辨率图像,其中生成器用于SAR 低分辨率图像去噪并生成伪超分辨率SAR 图像,鉴别器用于区分伪超分辨率图像和真实高分辨率图像。2020 年,文献[46]在GAN 去噪网络的基础上,引入全变差损失来保护图像细节,并通过轻量级鉴别器指导生成器的方式,进一步提高计算效率。
大量实验证明,对于各种SAR 增强成像问题,上述采用有监督训练的DNN 效果显著。要想通过监督手段学习去噪过程中的复杂映射,数据集需要由噪声图像和去噪图像成对组成,即需要对应的标签数据。但是不同于计算机视觉,在实际情况中,获得大量SAR 场景的清晰标签图像通常是十分困难的。针对训练数据集构建困难这一问题,在目前的研究文献中有三种求解思路:
1)无监督训练方法:为了使基于DL 的SAR 图像增强技术更加实用,文献[47]通过改进U-net 结构提出一种仅使用SAR 含噪数据来训练网络而不需要干净图像作为参考的图像去噪方法。文献[48]同样对无监督去噪手段进行探索,提出一种不需要参考图像的去斑神经网络,该网络采用与参考图像独立的统计特性损失函数来计算估计噪声与模拟噪声之间的Kullback-Leibler(KL)散度,有助于消除无监督神经网络的研究瓶颈。受盲点去噪网络的启发[49],MOLINI 等人提出基于无监督学习的贝叶斯去噪方法[50-51],仅使用真实SAR 含噪图像进行训练,而不需要利用由光学图像合成的含噪数据。
2)预训练网络模型:为了避免收集大量清晰SAR 图像数据集,文献[52]将预训练的CNN 模型直接嵌入到用于SAR 去散斑的多通道对数和高斯降噪(multi-channel logarithm and Gaussian denoising,MuLoG)框架中,其中CNN 由包含AWGN 的数据集训练,在SAR 图像中可以获得满意的去噪性能。然而,该方法的预训练模型仅针对特定噪声等级,当测试图像的实际噪声等级不在预设范围内时,网络输出结果会出现过度平滑和欠平滑现象。为解决这个问题,文献[53]引入一种新的预训练CNN 模型——快速灵活去噪CNN(fast and flexible denoising CNN,FFDNet[54])。FFDNet 将噪声等级作为网络训练输入,对于任意噪声等级,FFDNet 都可以实现精确去散斑。将MuLoG 与预训练的FFDNet 相结合,能够对单通道甚至多通道SAR图像进行降噪。
3)人工构建数据集:现有研究通常使用具有乘性噪声的光学照片来模拟噪声SAR 图像,以此构建包含噪声图像与干净图像的成对训练集。但是,这将导致所构建数据的噪声统计特性较为单一,且网络模型只能学习固定的噪声分布。为解决这一问题,张红研究员等人引入动态加噪策略和纹理级别图(texture level map,TLM)概念[55],其中TLM可以显示噪声图像中图案分布的随机性、均匀性和尺度。在此基础上,提出一种双极全卷积网络,包含纹理估计子网络和噪声去除子网络,前者用于产生TLM,后者利用SAR 噪声图像和对应的TLM 完成图像去噪。引入TLM 改善了人工模拟噪声图像的缺点,赋予网络处理变化噪声的能力,而且在散斑抑制和细节保护两者之间实现了更好的折中。此外,文献[56]利用GAN 从预先存在的有限数据集中生成新的SAR图像,并设计了一种新颖的CNN来定量验证GAN 生成图像的有效性。2020 年DABHI 等人通过模拟真实SAR 数据生成,提出一种包含多种噪声参数设置的SAR数据合成方法[57],旨在推动DNN对SAR图像去噪技术的研究。
2.1.2 基于DL的SAR端到端成像
在2.1.1节中,数据驱动DL技术通过与传统成像手段相配合共同实现SAR 增强成像。从成像过程的局部角度出发,DNN 在这些研究中仅实现图像域到图像域的优化提升。接下来,本节将从SAR 成像全局角度出发,介绍DL 技术在SAR 端到端(回波域到图像域)成像中的研究现状。
1)数据驱动DL成像技术
已有研究证明,DNN 能够表示包括CS 优化问题在内的许多凸/非凸数学模型以及非线性数学模型[58]。基于这一事实,越来越多的研究引入DNN来求解逆问题,取代了传统的凸优化和贪婪算法。2015 年,MOUSAVI 等人首次采用DL 技术从相应的欠采样测量中恢复结构化信号[59];2017 年,CHANG等人通过DNN学习近端算子来解决线性逆问题[60];除此之外,还包括DeepInverse[61]、深度残差重构网络[62]、基于生成模型的CS[63]等具有代表性的数据驱动DL 方法。雷达成像模型按数据维度可划分为一维精确观测模型和二维近似观测模型,前者需要对数据进行矢量化操作,而后者可直接运算二维矩阵。接下来,以SAR 一维成像模型为例,分析DNN求解稀疏SAR成像问题的可行性。
假设采用正侧视条带模式SAR 系统进行成像,成像系统的几何结构如图1所示。SAR 成像场景的观测区域可被视为由位于P×Q网格上的一系列散射中心构成,其中沿距离向(x轴)和方位向(y轴)的网格坐标分别为p=1,2,…,P和q=1,2,…,Q,且每个网格上距离和方位采样点分别为m=1,2,…,M和n=1,2,…,N。
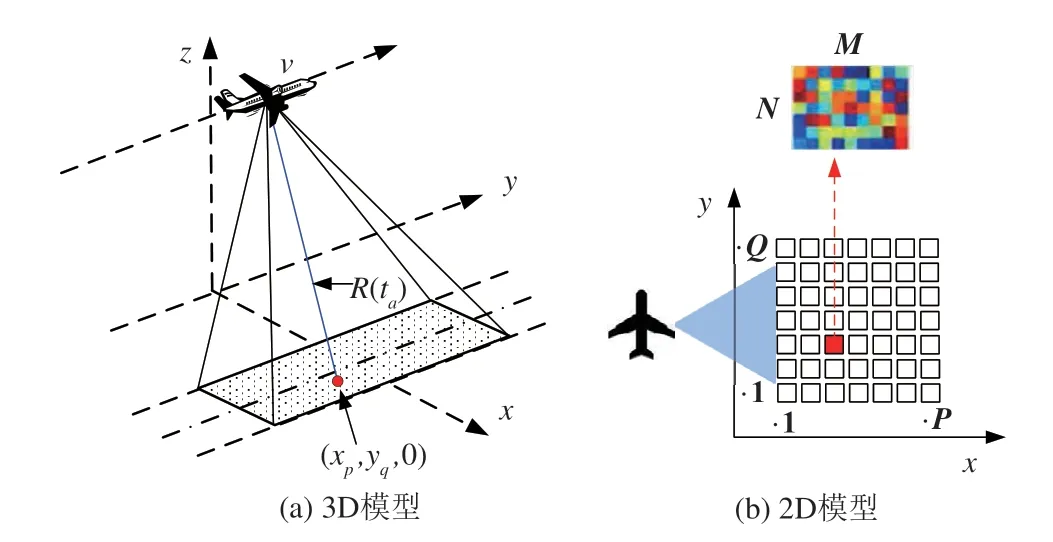
图1 SAR成像系统的几何结构Fig.1 Geometric structure of SAR imaging system
因此,成像场景的散射系数可以表示为如下散射系数矩阵
稀疏SAR 成像的一维精确观测模型反映了SAR 回波信号与成像场景散射分布之间的关系。通过对接收到的二维回波数据进行矢量化操作,回波信号的降采样观测模型可表示为
其 中s0∈CMN×1是矢量化的原始回波信号,s∈CMN×1是降采样后的复值回波向量,n0是噪声向量,Ψ∈RM′N′×MN表示降采样矩阵,Φ∈CMN×PQ为包含相位的观测矩阵,σ=vec(Ξ)∈CPQ×1是散射系数向量。
在稀疏SAR 成像中,如果成像场景空域稀疏,且观测矩阵Φ满足约束等距性质(restricted isometry property,RIP)[2],则通过求解以下基于l1解耦的优化问题,可从已知回波中s重构未知SAR图像σ
其中为重构的散射系数,‖·‖2为基于加性高斯白噪声(additional white Gaussian noise,AWGN)假设下的欧氏距离,用于度量s与ΨΦσ之间的误差,λ‖·‖1表示正则化约束项,λ是预定义的正则化参数,‖·‖1为l1范数。利用迭代优化算法求解优化问题(3)可实现σ的精确重构,以ISTA 为例,其迭代步骤为算子更新和非线性变换,两者的第l次迭代可分别表示为
其中l表示迭代索引,μ表示影响ISTA 收敛的步长参数,rl为第l次迭代中算子更新阶段的运算结果,(·)H表示共轭转置,soft(·;·)表示与基于l1范数正则化器相对应的软阈值函数,sign(·)表示符号函数,T为由λ和μ合并构成的阈值参数,即T=λμ。令U=I-μ(ΨΦ)H(ΨΦ),v=μ(ΨΦ)Hs,则式(4)和(5)的迭代运算可简化为
对于一个具有L层结构的DNN 而言,其单层神经网络结构可表示为典型的“权重+偏置”形式,即将数据与权重的内积加上偏置作为每个神经元的输入,DNN第l层神经网络的前馈运算表达式为
其中h(l-1)表示第l层的输入,W(Γ)是隐藏层的权重项,b(Γ)是偏置项,F(·)表示修正线性单元(rectified linear unit,ReLU)激活函数,Γ 表示DNN 的网络参数集。
显然,式(7)中DNN 第l层网络模型与式(6)中简化稀疏成像模型的计算过程非常相似,ISTA 中的U与DNN 中的权重矩阵W相对应,同理v与偏置向量b相对应。虽然两者存在不同之处,即DNN 引入ReLU 激活函数,ISTA 采用软阈值函数,但这两个函数都是非线性函数,且具有类似的性质。因此,可认为DNN 的第l层更新在某种程度上类似于ISTA的第l次迭代,即ISTA 的多次迭代等效于DNN 的多个隐藏层。值得注意的是,相比于ISTA 迭代运算,DNN隐藏层中的神经元数量庞大,具体表现为DNN权重矩阵W的维数远大于ISTA中矩阵U的维数,这表明神经网络具有更强的逆问题求解能力。此外,ISTA中U和v在迭代期间通常保持共享且固定。相反,DNN 各个隐藏层中的权重W和偏置b非共享且随训练过程变化,这些网络参数通过反向传播不断向最优值逼近。综上所述,DNN 可适用于SAR 稀疏重构且性能优于基于CS 的稀疏成像方法。当采用DNN 求解式(3)中的SAR 成像逆问题时,第L层的最终输出结果可表示为:
上述可行性分析证明了DNN 除应用于SAR 增强成像外,还可用于求解从SAR 观测信号到场景散射系数的成像逆问题,即反演模型。2018年,西安电子科技大学刘艳提出一种基于GAN 的SAR 成像方法[64],其中生成器直接从降采样回波中重构SAR 图像,鉴别器用于判别重构图像与真实场景是否一致。2020年,南加州大学信息科学研究所ANDREW等人提出一种通过集成神经网络实现SAR 成像的研究方案[65]:首先利用深度卷积编码器实现从回波数据到聚焦图像的第一次映射,然后采用RDA成像结果作为训练标签,通过深度残差网络实现从低分辨率到高分辨率的第二次映射,这种集成网络框架可以获得近似于RDA 的成像性能。2021 年,英国伦敦大学学院的PU 研究员提出一种数据驱动的SAR 端到端成像方法[66],该方法基于CNN 构建自编码器,用于充分探索散射系数矩阵的冗余信息,并利用全连接层实现散射系数到降采样回波的映射。在此基础上,将SAR 平台运动误差引入观测矩阵,通过优化降采样回波的重构损失函数,实现自编码器参数更新以及运动补偿后的高精度成像。
上述研究通过大量实验证明了所提方法可以有效求解端到端成像问题,但是现阶段的数据驱动DL 成像技术在解决雷达成像问题时还存在一些局限性。一方面,其可解释性和普适性较弱。数据驱动方法对于一般的图像处理而言,简单高效且性能优越。但是,雷达成像系统包含复杂的雷达参数、运动轨迹、相位信息等,任意一种因素都会影响成像结果,尤其是相位信息,对于目标重构结果的准确性起着至关重要的作用。由于数据驱动成像方法忽略了成像模型对相位等信息的保护和恢复,且没有明确探索场景的稀疏性,因此该方法缺乏可解释性。此外,尽管经过训练的DNN可以实现雷达回波到重构图像的映射,但是这种离线成像网络仅适用于特定成像场景,并不具备传统在线成像算法的普适性。另一方面,雷达数据集完备性较弱。对于雷达系统而言,非合作目标数据获取困难,目前支撑SAR/ISAR 成像研究的公开数据较少,尤其是回波数据和带标注的清晰场景图像。常见的公开回波数据包括“RADARSAT-1 回波(静止目标)[67]”、“GF-3 星载SAR 回波(包含动目标)[68]”、“高分辨毫米波雷达回波数据(3D成像)[69]”等。为解决缺乏实测数据所造成的局限性,现有研究大多采用仿真数据代替实测数据,但其与真实雷达数据差异明显,以动目标成像为例,仿真数据难以保证目标在运动轨迹和运动参数等方面的完备性。因此,当前数据驱动方法面临特征学习的小样本难题,且数据集的收集和标注会大幅提升研究成本,严重约束数据驱动DL技术在雷达成像中的应用。
2)模型驱动和数据驱动相结合的DL成像技术
相比之下,将模型驱动和数据驱动相结合的DL成像技术应用于SAR 端到端成像能够有效地改善上述问题。这种DL 成像技术利用数据驱动的概念实现成像模型中的参数优化、自适应去噪、稀疏表示等子程序,提升网络可解释性的同时避免了大量的样本需求。目前,该研究主要集中于深度展开网络(deep unfolded network,DUN)[70]以及基于即插即用(plug-and-play,PnP)框架的成像网络[71]。
基于DUN 的SAR 学习成像方法首先将传统的模型驱动成像方法扩展为深度网络,然后仅利用少量训练样本学习模型中可调参数的最优值,最后通过训练好的网络输出未知目标的聚焦图像。这种方法利用有限的层次结构实现了模型驱动方法的大量迭代运算,有效地解决了以下困难:(1)为模型驱动方法设置最优参数;(2)为深度网络的成像机制提供可解释性;(3)避免数据集的约束和数据驱动方法的过拟合。2017 年,美国伦斯勒理工学院MASON 等人首次在雷达成像研究中引入这种模型驱动与数据驱动结合的思想[72-73],该团队基于ISTA将雷达成像模型嵌入到RNN结构中,通过网络训练实现对回波信号的高精度成像。随后,该团队还将这种设计思路应用于无源SAR成像研究[74-75]。以文献[74]为例,该团队首先将基于ISTA 展开的RNN设计为编码器;然后采用正演模型将编码器输出的散射系数演绎到回波域,并将该步骤定义为解码器;最后,将RNN 编码器与解码器通过级联组成从回波到回波的自编码器,旨在构建一种采用无监督训练的无源SAR成像求解方案。
受该团队将ISTA 嵌入到RNN 的启发,本课题组在文献[4]中介绍了一种基于“数据驱动+智能学习”的SAR 深度展开成像框架,为便于后续分析,在下文中将其称为ISTA-Net。该网络基于SAR 的一维精确观测模型进行设计,其单层拓扑结构由式(4)和(5)中的ISTA迭代步骤扩展构成。假设ISTANet为固定数量的L层网络结构,其中每一层网络包含两个模块:线性模块R和非线性模块N,分别对应ISTA 的算子更新和非线性变换,ISTA-Net 第l层的运算表达式为
其中r(l)表示第l层的线性重构结果,μ(l)和T(l)表示第l层中的可学习参数,这些参数在传统ISTA 中往往是预先设定的且最优值难以确定。图2 为所提ISTA-Net 的拓扑结构,该网络可拓展应用于其他成像雷达,仅需要依据对应的雷达系统参数重新计算具有相同尺寸的观测矩阵Φ即可,这表明相比于数据驱动方法,DUN 可以在实际应用中避免冗余的训练和计算,具有良好的普适性。
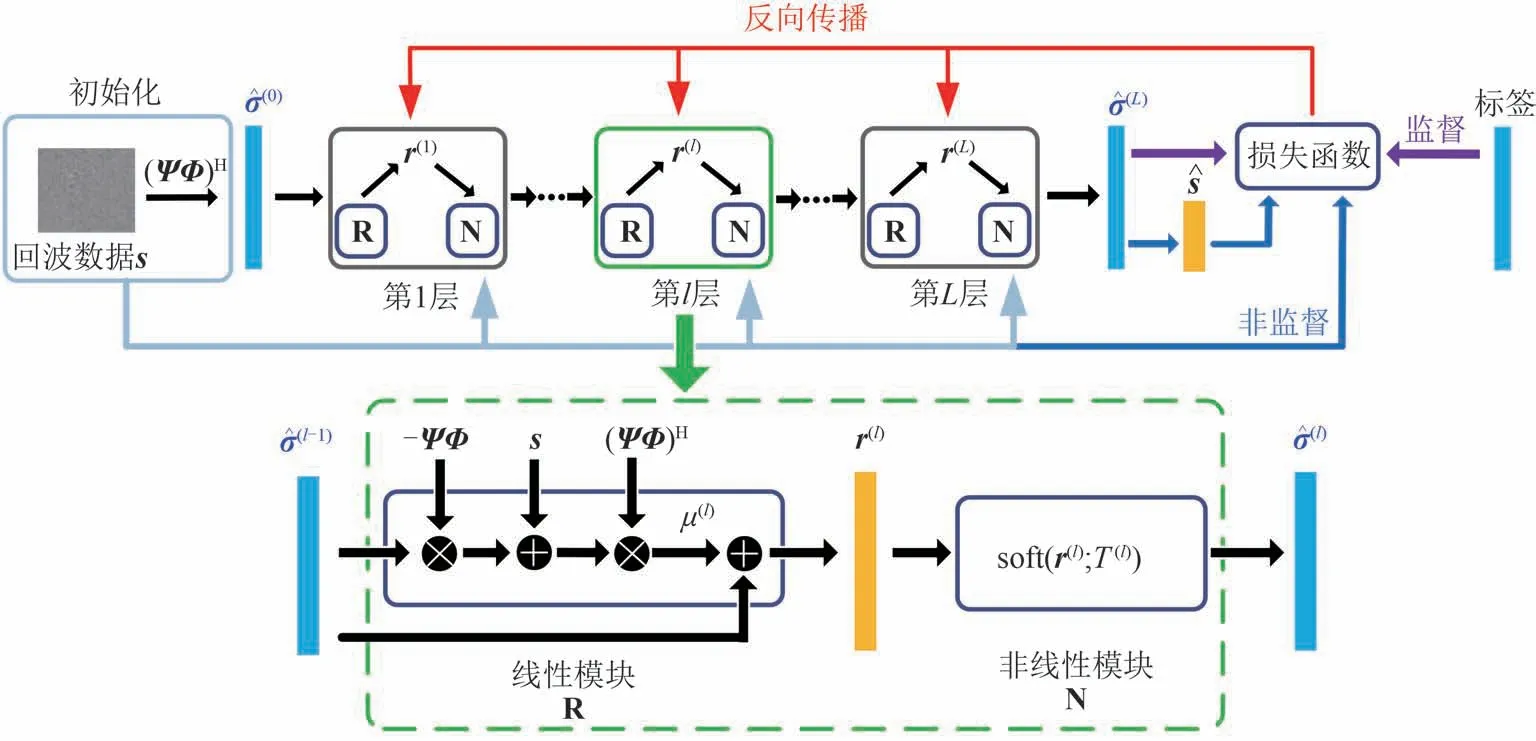
图2 ISTA-Net拓扑结构Fig.2 Topology architecture of ISTA-Net
然而,地面复杂场景的散射系数通常为非稀疏或弱稀疏的,直接使用CS 理论或ISTA-Net 在低采样率下难以获得高质量的SAR 图像。传统的变换域CS-SAR 成像方法通常采用合适的稀疏表示字典来实现非稀疏场景的高质量重构,如离散余弦变换(discrete cosine transform,DCT)、小波变换(wavelet transform,WT)和曲波变换(curvelet transform,CT)[76]。本团队在文献[4]的基础上,将DUN 与CNN 相结合,提出一种应用于非稀疏复杂场景的SAR 学习成像方法——基于稀疏表示的ISTA-Net(sparse representation-based ISTA-Net,SR-ISTANet)[76]。该方法首先推导了一维SAR 成像模型的稀疏表征形式,然后将ISTA求解过程展开为双路径成像网络框架,并引入CNN 模块替代传统的稀疏表示函数。该网络可以直接处理非稀疏场景条件下的复值信号和复图像,其单层拓扑结构如图3。
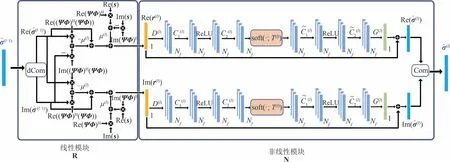
图3 SR-ISTA-Net单层拓扑结构Fig.3 Single layer topology architecture of SR-ISTA-Net
在实验中,利用RADARSAT-1 卫星实测数据进行有效性验证,并采用MF、基于变换域的CS 和ISTA-Net 作为对比方法,图4 给出全采样和50%采样时,四种成像算法相应的重构结果。结果表明SR-ISTA-Net 在两种采样情况下均能获得最优成像性能,基于变换域的CS 方法性能次优,而没有考虑稀疏表示的MF 和ISTA-Net 并不适用于非稀疏场景降采样重构。在50%欠采样条件下,与基于变换域的CS 相比,SR-ISTA-Net 的峰值信噪比(PSNR)提高4 dB,成像时间提升2个数量级。

图4 全采样和稀疏采样时,四种算法的成像结果[76]Fig.4 Imaging results of four algorithms in full sampling and sparse sampling[76]
上述成像网络均基于一维精确观测模型进行设计,会产生大规模计算负担。为解决这一问题,本课题组于2022年提出一种基于RDA和ISTA深度展开的2D-SAR 成像方法(RDA-Net)[77]。首先利用克罗内克积分解理论分析RDA 成像过程并构建二维近似观测成像算子,避免了雷达信号的矢量化处理,有效降低了计算成本。然后,基于RDA 成像算子和ISTA 设计DUN,并与正演模型相结合构建自编码器,利用无监督学习提升网络成像质量和成像效率。在仿真实验中,成像场景尺寸设定为256×256,回波矩阵大小为360×720,采用10000 组二维回波作为实验样本,其中80%为训练集,20%为测试集。分别采用全采样回波和稀疏采样回波对RDA、ISTA 和RDA-Net在真实场景下的成像性能进行测试,对比结果如图5。实验证明所提方法可以直接处理较大规模回波矩阵,且在全采样和稀疏采样条件下都能获得最优性能。随后,为进一步提升斜视情况下的成像性能,本团队在RDA-Net 的基础上,提出一种基于可学习RDA的斜视SAR成像网络(Learnable Range Doppler,LRD)[78]。图6给出45°条件下LRD 与传统斜视成像算法(Omega-KA、非线性CSA)的实验对比结果,提出的LRD 在聚焦性能和旁瓣抑制效果方面优于传统方法,方位向峰值旁瓣比(PSLR)提升3~6 dB。

图5 全采样和稀疏采样时,真实场景成像结果[77]Fig.5 Imaging results of real SAR scene in full sampling and sparse sampling[77]
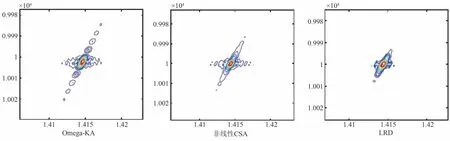
图6 斜视场景成像结果对比[78]Fig.6 Imaging results of squint mode[78]
近两年,除ISTA 之外,其他迭代优化算法同样被应用于SAR 学习成像研究,如ADMM[79]、分裂布雷格曼算法[80]、AMP[81]等,其中ADMM 研究相对成熟且被应用于各种SAR 成像问题。2021年,北京理工大学丁泽刚教授团队提出一种基于ADMM 深度展开的SAR 学习成像方法,称为参数化超分辨率成像网络(parametric super-resolution imaging network,PSRI-Net)[82]。该方法首先突破了传统的点散射模型,通过引入线目标和面目标来构建混合回波模型,使其更接近真实的复杂SAR 场景。然后,将SAR超分辨率成像表述为CS稀疏重构问题,引入三个罚参数分别探索点线面的稀疏性。最后,利用多元ADMM 求解稀疏优化问题,并展开为成像网络。仿真和真实数据实验均表明,与传统成像方法相比,该方法可以提升包含点线面的复杂SAR 图像质量。同年,英国伦敦大学学院的PU 研究员提出一种基于ADMM 的稀疏自编码网络(sparse autoencoder network,SAE-Net)[83],旨在同时实现SAR 成像和自聚焦。该方法中解码器通过展开ADMM 进行稀疏成像,编码器通过线性映射实现回波正演,并联合回波重构损失和图像熵损失对SAE-Net进行无监督训练。成都电子科技大学的武俊杰教授团队同样将基于ADMM 展开的深度网络应用于解决SAR 成像中的不同问题。首先在2021 年提出匹配滤波ADMM 网络(MF-ADMM-Net)[84],用于从背景杂波中突出目标信息,但是MF-ADMM-Net 仅针对空域稀疏场景。为进一步实现非稀疏场景的网络学习成像,该团队于2022年分别提出基于稀疏识别总最小二乘的线性ADMM 网络(sparsity-cognizant total least-square linearized ADMM network,STLSLADMM-Net)[85]以及基于低秩稀疏恢复的ADMM网络(low-rank and sparse recovery ADMM network,LRSR-ADMM-Net)[86]。其 中,STLS-LADMM-Net 在更新重构图像的同时,利用相位误差估计模块执行运动补偿,并引入特征变换算子来表示非稀疏场景先验知识。LRSR-ADMM-Net 在其基础上,将非稀疏SAR 成像问题构建为低秩矩阵和稀疏矩阵的联合恢复问题,通过监督训练学习网络中的迭代参数以及每层中低秩部分和稀疏部分的权重参数。大量的实验结果表明,相比于传统的迭代重构方法,上述DUN 在其各自针对的SAR 成像问题中均具有优越的重建性能。而且,对于DUN 而言,其迭代过程由预设的网络层数控制,而不是传统迭代步骤中的收敛条件或最大迭代步长,这避免了因大量迭代所导致的算法复杂性,提升了计算效率。
除DUN之外,最近出现了另一种模型驱动与数据驱动相结合的DL 成像技术——基于PnP 框架的成像网络,这种方法允许成像模型与网络先验模型相匹配,通过迭代调用合适的神经网络作为优化算法的降噪器,以此来实现成像性能的有效提升。现有的CS 重建方法使用正则化去噪器来处理病态的成像逆问题,例如成像模型(3)中的ℓ1范数。然而,这些正则化器要么因为过于简单而无法捕获复杂的空间特征,要么会导致难以最小化的非二次损失函数。PnP先验技术是一种将成像系统前向模型与先进正则化器集成的灵活框架[87],基于PnP 框架的成像网络也正是受此启发而提出的一种DL 成像技术。与CS 和DUN 相比,这种PnP 成像网络最明显的优势在于其构建了一种每一次迭代都可以自适应学习场景先验信息的神经网络去噪器。2020 年ALVER 等人提出一种用于聚束SAR 的PnP 成像框架[88]。该方法首先通过训练CNN 实现真实场景与合成场景的图像去噪,然后将训练好的CNN 作为先验模型嵌入到ADMM 求解器中,用于替换传统的正则化去噪器。实验表明这种基于CNN 的PnP 框架在图像视觉质量方面优于传统的非二次正则化成像方法以及基于BM3D 的PnP 成像框架。值得注意的是,由于PnP 网络框架是在成像模型的基础上引入PnP 先验技术来构建的,因此PnP 网络框架同样可以扩展为基于深度展开架构的学习成像网络。
2.2 SAR运动目标学习成像
对于地面运动目标(ground moving target,GMT)而言,其距离向速度将引起多普勒频移,方位向速度会造成方位调频率变化。前者会导致成像结果发生方位向偏移错位,后者会引发方位向模糊拖尾[89]。由于非合作目标存在未知运动参数,采用针对静止目标的SAR 学习成像方法处理GMT 回波信号时往往难以获得高质量聚焦图像。因此,基于DL的SAR-GMT 学习成像方法研究在近期受到广泛关注[90]。
基于数据驱动的SAR-GMT 成像过程如图7 所示,该方案无法直接学习运动目标回波信号与聚焦结果之间的映射,仅利用神经网络处理散焦的GMT图像,即在图像域通过训练大量数据来实现GMT的高分辨率聚焦和杂波抑制。作为SAR成像的重要应用之一,GMT 成像要解决的关键技术是如何精确补偿包含运动参数的残余相位误差[91]。目前传统的SAR-GMT 成像算法存在复杂度高、旁瓣干扰严重、成像效率低等问题。基于数据驱动的SAR-GMT 成像方法可以利用DNN来完成“从散焦图像到聚焦图像”这一关键步骤,避免了运动参数估计和相位补偿[92],同时缩短了成像时间并降低了算法复杂度。
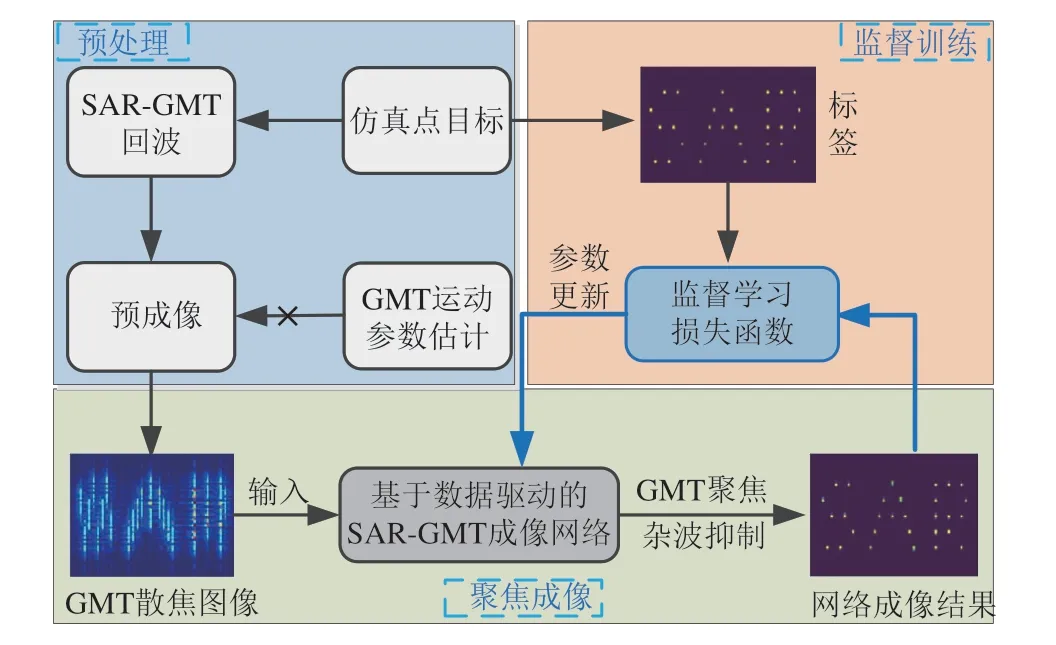
图7 基于数据驱动的SAR-GMT成像流程图Fig.7 Flow chart of data driven SAR-GMT imaging
2020 年史洪印团队首次将DNN 应用于GMT 散焦图像的重新聚焦[93],提出一种结合RDA 和CNN的SAR 运动目标成像方法。该方法首先利用RDA对回波数据进行预成像,然后将获得的散焦成像结果输入到训练完备的U-net 中实现高分辨率聚焦。为了避免GMT 方位偏移对U-net 聚焦性能的影响,实验中采用的训练集数据仅考虑方位向速度。通过提取3000 个样本的结构信息,U-net 获得良好的重新聚焦能力,提升了GMT 分辨率。但是,该网络并没有考虑噪声干扰对GMT聚焦的影响,且网络输入为实值图像。为此,哈尔滨工业大学张云团队针对强背景杂波污染情况,提出一种包含残差单元的全卷积层架构,称为DeepImaging[94]。首先基于传统成像方法获得GMT散焦复图像,然后将其实部和虚部作为实数域网络的双通道输入,通过特征提取模块和图像生成模块学习隐式成像模型。在该实验中,通过仿真产生包含5×105个样本的训练集和包含1.6×105个样本的测试集,同样假设GMT 的距离向速度为零,采用监督学习手段对网络进行训练。仿真数据和Gotcha 实测数据均证明DeepImaging 在提升GMT 聚焦分辨率的同时,可以实现背景杂波消除。由于DeepImaging 对存在较小距离向速度的慢速GMT无法聚焦,该团队进一步研究在杂波干扰和复数域情况下的慢速GMT成像,提出一种基于复值CNN(complex-valued CNN,CV-CNN)的GMT成像方法,称为CV-GMTINet[95]。该复数域成像网络通过充分利用目标的幅度和相位信息,学习存在杂波干扰的多通道SAR 图像与仅包含聚焦GMT 的SAR图像两者之间的映射关系。此外,CV-GMTINet采用密集残差块(Residual Dense Block,RDB)学习单通道特征以及通道之间的有效特征,其中RDB 结合了ResNet[96]和DenseNet[97]的思想,RDB 的结构将在后续3.1 节中给出。该研究基于TerraSAR-X 数据进行实测实验,结果表明经过训练的CVGMTINet 能够分离GMT 与强背景杂波,同时重新聚焦存在模糊拖尾的慢速GMT。除应用于GMT 图像聚焦之外,CNN 同样可用于估计GMT 的运动参数,文献[98]通过微调预训练的AlexNet 结构[99],并采用迁移学习[100]来估计GMT 距离向速度。将基于DL 的运动参数估计方法与传统成像模型相结合能够提升GMT 聚焦或定位的效率和精度,在未来的SAR-GMT成像领域有望成为热点问题。
依据上述分析可知,对于从回波数据到聚焦GMT的成像全过程,CNN 通常只能实现局部功能映射,例如图像聚焦、杂波抑制、参数估计等,而无法完成端到端成像。本课题组首次将模型驱动同数据驱动结合的研究思路引入SAR-GMT 成像,旨在探索基于SAR 成像观测模型的端到端GMT 稀疏成像方法[101-102]。文献[101]提出一种基于可训练Omega-KA 和稀疏优化的SAR-GMT 成像网络(Omega-KA-net),不同于以往采用穷举算法、最小熵算法或稀疏约束算法来估计运动参数的工作,该方法通过网络训练对包含运动参数的补偿矩阵进行学习。Omega-KA-net 的设计过程如下:首先,对回波数据进行2D-FFT 和一致压缩补偿,提取GMT的感兴趣区域(region of interest,ROI),并基于Omega-KA 设计SAR-GMT 成像过程。然后,根据GMT聚焦过程推导出二维稀疏成像模型,并将ISTA迭代求解GMT 成像模型的过程展开为成像网络。Omega-KA-net 的网络拓扑结构如图8 所示,共包含L层,且每一层由三个子层构成,分别对应迭代过程的三个步骤。G(·)和E(·)分别表示基于Omega-KA推导得出的GMT二维观测算子和成像算子,H2为包含运动参数的补偿矩阵,当采用批量训练方法时,该矩阵在网络中被设定为可学习的3D张量。
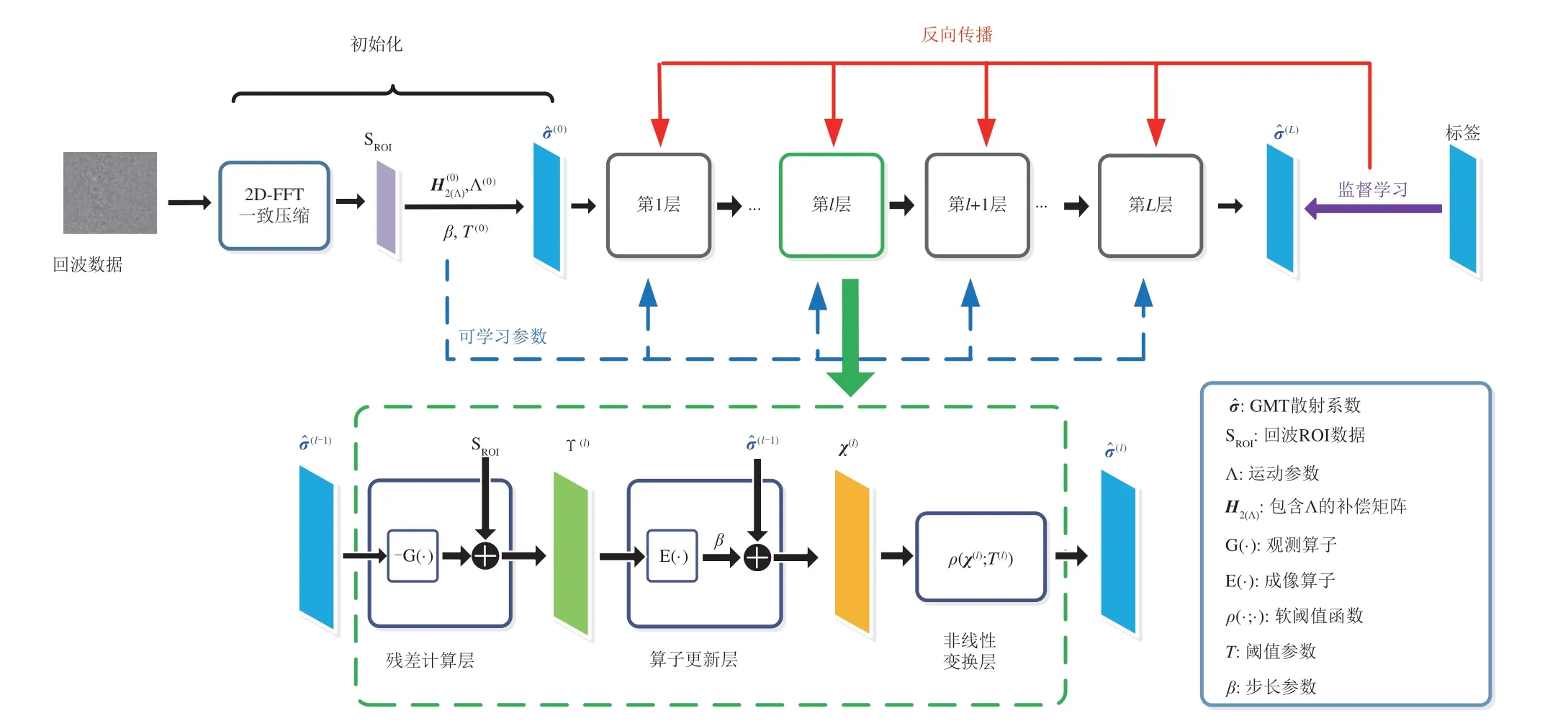
图8 Omega-KA-net拓扑结构Fig.8 Topology architecture of Omega-KA-net
在本实验中,采用降采样以及在回波中添加AWGN 的方法来生成训练集,样本总数为3000,每个样本由多个随机分布的点目标组成。在训练集中,GMT 的距离向速度在5~10 m/s 范围内随机分布,方位角速度在10~20 m/s 范围内随机分布。经过训练的Omega-KA-net 可应用于降采样和噪声干扰下的正侧视与小斜视模式成像,实现了ROI 数据空间到GMT 散射系数的直接映射。图9 为GF-3 卫星某海面场景成像结果,其中T1、T2、T3 为散焦的舰船目标,分别采用穷举搜索[103]、迭代最小熵算法[68]、Omega-KA-net 对舰船目标ROI 数据进行聚焦成像,成像结果如图10。实验结果表明,Omega-KAnet 在成像质量和效率上优于穷举搜索和迭代最小熵等传统GMT 成像算法,其中图像熵减少约50%,成像效率比迭代最小熵提升约2个数量级。

图9 GF-3卫星某海面场景[101];(a)海面成像结果;(b)~(d)T1、T2、T3舰船散焦图像Fig.9 Sea surface scene of GF-3 satellite[101];(a)Sea surface imaging result;(b)~(d)Defocused images of T1,T2 and T3 ships
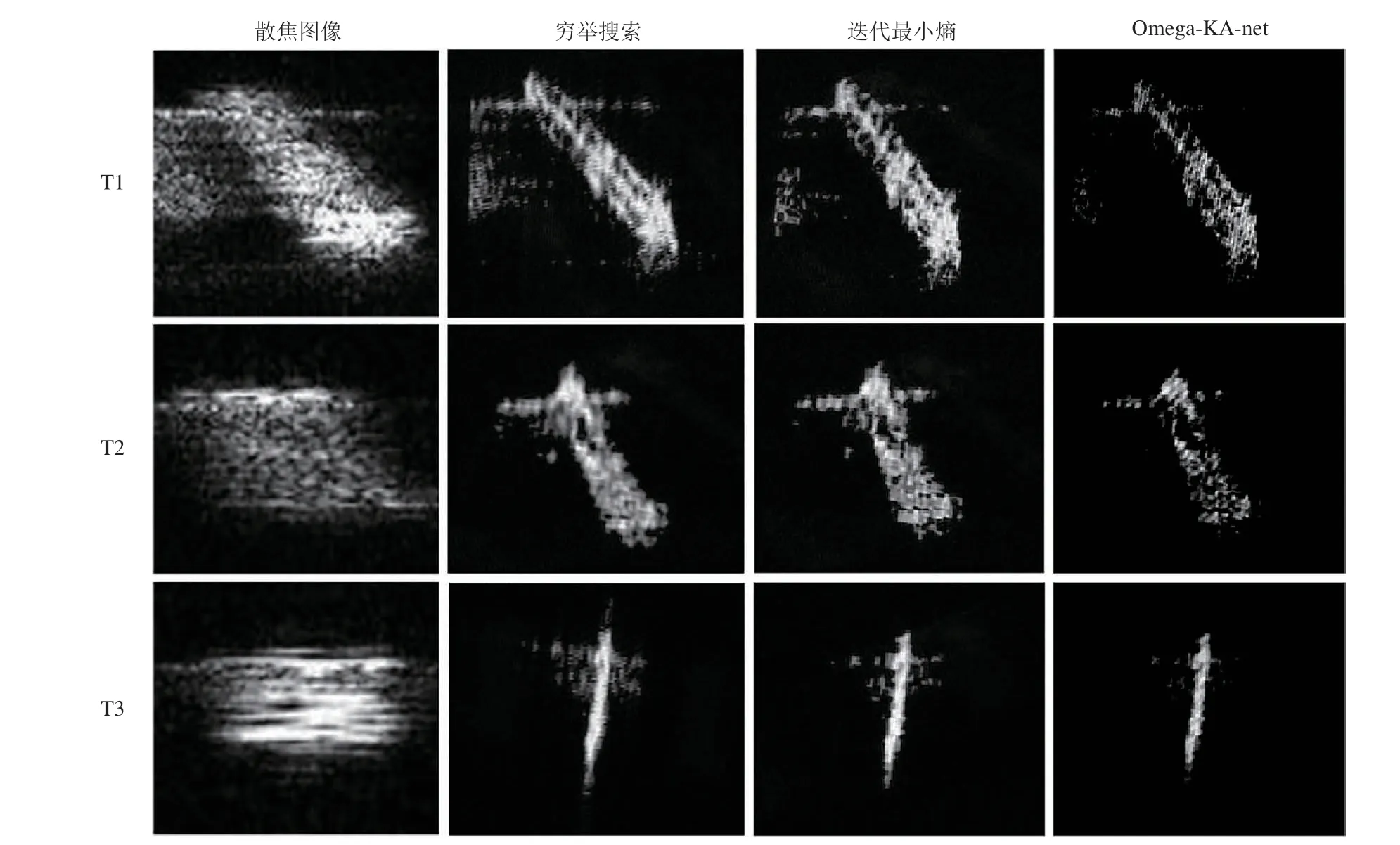
图10 GF-3卫星数据的SAR-GMT成像结果对比[101]Fig.10 Comparison of SAR-GMT imaging results based on GF-3 satellite data[101]
2.3 SAR三维学习成像
3D-SAR 成像技术在地形测绘,城市监测等方面发挥着重要作用。与前文介绍的二维静止目标或GMT 成像方法相比,3D 成像可以获得目标的更多信息。然而,基于MF方法和CS理论的传统3D成像算法存在回波数据体量大、天线元件过多、成像分辨率低等问题。近年来,DL在该领域的发展有效解决了高精度3D-SAR 快速成像所面临的主要难点[104],基于DL的3D-SAR成像流程如图11。
图11 基于DL的3D-SAR成像流程Fig.11 3D-SAR imaging process based on DL
层析SAR(Tomographic SAR,TomoSAR)成像技术被广泛应用于城区密集环境下目标的3D 重构。2019 年,BUDILLON 等人首次尝试将DL 应用于3DSAR 成像领域[105],主要探索CNN 面对3D-TomoSAR重建模型不精确时的处理能力。该方法利用基于CNN 构建的TomoSAR 神经网络在每个分辨率单元中检测单个散射体并估算其高度。由于仿真数据与实测数据差异大,导致该方法在真实场景的3DSAR 重构中鲁棒性低。为解决该问题,德国慕尼黑工业大学的朱晓香团队提出一种高效率的通用深度学习TomoSAR 算法——γ-Net[106],利用复值ISTA来实现稀疏重建中的迭代优化,可以实现真实城区目标的高质量3D重构。同样,北京理工大学信息与电子学院雷达技术研究所的曾涛团队提出一种真实场景下重构精度高的3D-TomoSAR 成像方法——基于奇异值分解的信号空间归一化超分辨网络(singular value decomposition-based signal-space normalization super-resolution net,SVD-SRNet)[107]。无人机实测数据的实验结果表明,SVD-SRNet 与ISTA 和ISTA-Net 相比,3D 成像精度分别提升25%和30%。然而,基于DL 的层析SAR 成像研究很可能产生模型失配问题。为此,该团队提出一种用于实现3DTomoSAR 学习成像的自适应网络(model-adaptive network,MAda-NET)[108],采用自适应模型求解(adaptive model-solving,AMS)模块来解决真实空间变化模型和近似固定模型之间存在的观测模型失配问题,并利用无人机SAR 实测数据验证了该网络的有效性。
2020 年,上海交通大学郁文贤教授团队提出一种基于CS和DNN的超分辨率3D成像结构[109],应用于多输入多输出(multiple input multiple output,MIMO)阵列SAR。该方法设计了一种基于CS 的空间滤波方法和一组并行的端到端DNN 回归模型来实现高程方向的超分辨率,其中空间滤波目的在于仅保留来自特定子区域的信号,而DNN则用于处理非线性凸优化问题——每个子区域的稀疏重构。实验结果表明,即使在SNR 较低或天线元件较少的情况下,该方法也可以通过比传统方法更快的速度实现超分辨率成像。
同年,张晓玲教授团队将DNN 与DUN 相结合,提出一种用于3D-SAR 稀疏成像的复值稀疏重构网络(complex-valued sparse reconstruction network,CSR-Net)[110],将快速ISTA(fast ISTA,FISTA)求解凸优化重构模型的迭代步骤展开为网络层,并引入CNN 来表示最优稀疏基。该团队首先将3D 数据解耦为二维切片,采用相位校正方案来固定每个切片的相位差;然后利用CSR-Net 并行重建对应的目标图像;最后,融合所有二维图像获得3D 重构结果,并通过实验证明了CSR-Net 在3D-SAR 成像中的有效性。考虑到AMP 算法收敛速度优于FISTA,2021年该团队提出一种基于AMP 的双路径SAR 稀疏成像网络(two-path SAR sparse imaging network,TPSSINet)[111],同样应用于3D-SAR 成像。与CSR-Net 相比,该网络收敛速度更快,并且通过双路径策略将损失函数的对称约束转移到通道层面,从而便于处理复值优化问题。此外,TPSSI-Net通过在实部路径和虚部路径中共享网络参数来确保参数总量与CSR-Net 相同,即额外的路径并没有增加TPSSI-Net的计算复杂度。文献[110]和[111]中两种3D 成像网络的实验对比如图12,TPSSI-Net 的成像性能优于CSA-Net,且在SNR较低时更加明显。
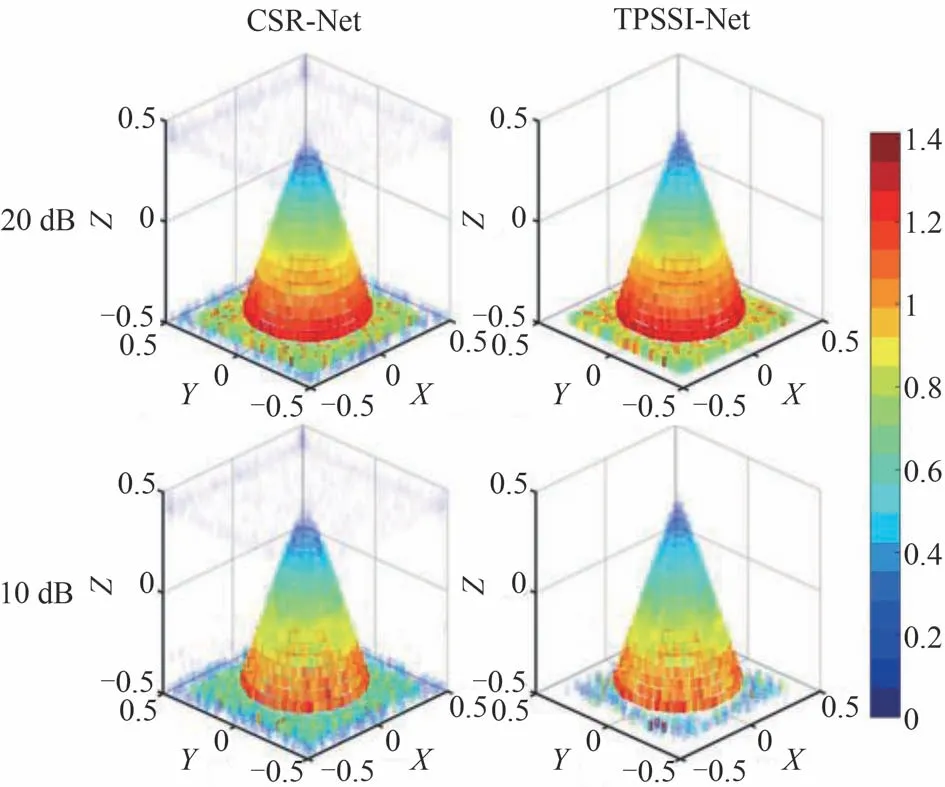
图12 TPSSI-Net与CSR-Net成像结果对比[111]Fig.12 Imaging comparison between TPSSI-Net and CSR-Net[111]
上述CSR-Net 和TPSSI-Net 均采用基于矩阵向量形式的一维精确观测模型,这种向量化处理雷达信号的成像模型将导致观测矩阵规模较大以及高维度运算。针对这一问题,该团队将MF 算法衍生的近似观测模型设计为二维成像算子,并通过深度展开的方式提出两种基于ISTA 的3D-SAR 成像网络:基于距离徙动核的ISTA 网络(range migration kernel-based ISTA network,RMIST-Net)[112]和可学习的稀疏驱动ISTA(Learned sparsity-driven ISTA,LSISTA)[113]。相比于CSR-Net 和TPSSI-Net,RMISTNet 和LSISTA 可以直接运算二维回波切片,提升了计算效率,减轻了数据处理压力,同时也更适用于大规模成像场景。
3 ISAR学习成像方法
在ISAR 成像应用中,MF 算法在小角度假设下对平稳目标有效,但对于机动目标则不再适用[114]。这是因为机动目标的旋转分量不再等同于均匀旋转,多普勒频率将随时间发生变化。此外,ISAR 目标的回波往往不够完整,这进一步降低了MF 算法的成像质量。CS 方法虽然可以在一定程度上提升成像性能,但是其成像质量往往受限于稀疏观测模型,当模型失配时,同样会影响图像分辨率。另外,CS 方法还存在计算复杂度高及难以实时成像等缺点。综上所述,由于空天目标的非合作特性以及存在噪声干扰等因素,传统方法通常难以获得高质量ISAR成像结果,具体表现为明显的模糊现象以及有限的分辨率。因此,寻找一种提高ISAR 分辨率和成像效率的方法对于突破现阶段ISAR 成像研究瓶颈至关重要。最近,DL 打破了传统ISAR 成像方法的桎梏,展示出巨大潜力[115]。ISAR 学习成像研究可分为基于DL 的ISAR 增强成像以及ISAR 端到端成像。
3.1 基于DL的ISAR增强成像
现有的基于DL 的ISAR 增强成像研究主要集中于通过数据驱动实现ISAR 低分辨率图像的增强重构[116]。DNN 具有强大的特征学习能力,因此被应用于ISAR 图像增强,通过对大量数据进行监督学习,实现分辨率性能提升甚至超分辨率[117]。这种ISAR 增强成像技术首先利用传统方法对回波进行预成像,例如距离压缩、运动补偿、2D-FFT 等。然后,将得到的低分辨率成像结果作为网络输入,利用DNN 获得去噪声和抗干扰的高分辨率ISAR 图像。由于该方法将ISAR 增强成像过程分为两个阶段,且数据驱动DL 技术仅用于完成第二阶段的图像分辨率增强,因此,这种基于数据驱动的ISAR 增强成像方法在获得高质量图像的同时,避免了模型失配的影响,具有较好的普适性。ISAR增强成像的流程如图13所示。
图13 ISAR增强成像流程图Fig.13 Flow chart of ISAR enhanced imaging
3.1.1 平稳目标
从2019 年开始,陆续出现相关研究将DNN 应用于ISAR 平稳运动目标的增强成像,其中CNN 是最早探索该领域的网络模型。传统线性成像方法无法处理ISAR 信号测量中的乘性噪声或杂波,MITCHELL 等人引入CNN 模型来处理这个问题[118]。实验结果表明虽然时变乘性噪声会导致传统方法的成像结果具有失真或空间卷积伪影,但引入DL 可以消除乘性噪声干扰并精确提取目标位置。然而,要想获得性能良好的CNN 结构,带有标签的完备训练集往往起着关键作用。不同于计算机视觉领域,雷达成像领域通常难以获得大量的训练数据,这严重限制了CNN 在雷达成像领域的广泛应用。为解决数据缺乏对ISAR 成像造成的困难,2020 年南京航空航天大学雷达成像与微波光子技术教育部重点实验室的朱岱寅教授团队提出一种用于ISAR 学习成像的FCNN(Fully CNN)结构[119],这种网络具有多级分解和多通道滤波结构,且没有全连接层。利用不同时间、不同形状下采集的两个同目标实测数据集对网络性能进行分析,得出的实验结果证明了FCNN 仅需要少量的训练样本便可实现ISAR 增强成像。国防科技大学黎湘教授团队同样致力于研究DL 技术在提升ISAR 成像分辨率性能方面的应用,该团队采用ResNet 作为成像框架,通过仿真生成包含低分辨率图像和高分辨率图像的数据集,直接学习两者之间相对于点扩散函数的映射[120-121]。
值得注意的是,上述基于CNN 的ISAR 增强成像研究都集中于均方误差(mean-square-error,MSE)的最小化约束,这会造成重建图像分辨率增幅受限,并丢失诸如弱散射点之类的图像细节。此外,采用MSE 作为损失函数还会导致ISAR 成像结果过度平滑,影响ISAR 图像的进一步识别与分类。为解决该问题,黎湘教授团队提出一种基于GAN 的ISAR 增强成像框架[122],并结合网络结构特点提出由绝对损失和对抗损失组成的组合损失函数。其中,绝对损失确保成像结果不会过度平滑,对抗损失则促使该框架对弱散射点的幅度和位置进行准确恢复。相比于传统ISAR 成像方法和基于CNN 的增强成像方法,基于GAN的成像框架可以明显消除旁瓣,并且恢复更多的弱点散射和目标细节。在此基础上,本课题组于2022 年提出一种基于改进GAN的ISAR增强成像框架[123]。该方法利用特征损失来保持ISAR 图像主要特征,与绝对损失和对抗损失一同构成损失函数,并引入残差密集块(Residual-in-Residual Dense Block,RRDB)对文献[122]中GAN 的生成器进行改进。文献[122]和[123]中两种GAN 的结构对比如图14,其中文献[122]的GAN 由图14(a)和图14(b)构成,文献[123]中的改进GAN 由图14(c)和图14(b)构成。图14(c)中RRDB 为双层残差结构,由1 个残差跳跃连接和3 个RDB 构成,残差参数β用于维持稳定性。
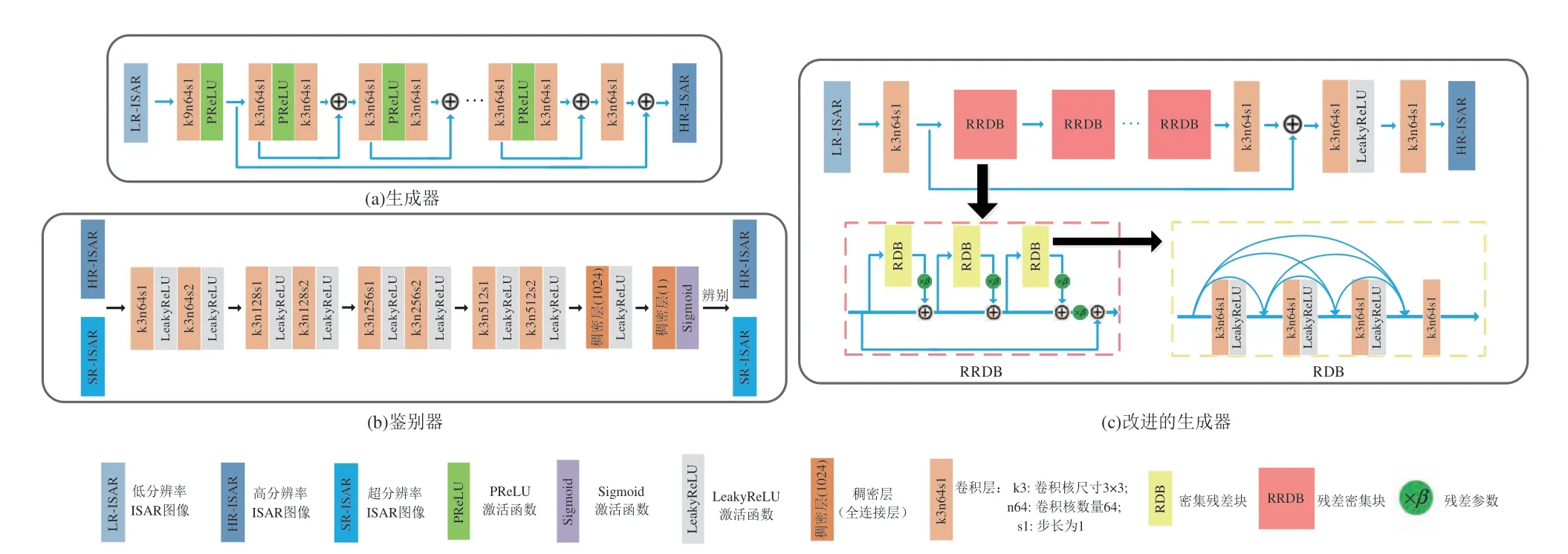
图14 文献[122]和[123]中GAN结构对比Fig.14 Structure comparison of GAN in [122]and [123]
在实验环节,文献[123]通过MATLAB 仿真获得低分辨率和高分辨率 ISAR 图像,每张图像由10~200个随机散射点构成,采用10000组低分辨率/高分辨率 ISAR 图像对网络进行训练。在SNR=-4 dB 和0.875 降采样情况下,文献[122]和[123]中基于GAN 的ISAR 成像结果对比如图15 和图16 所示。实验结果表明,提出的改进GAN框架在一定程度上提升了ISAR 学习成像的分辨率性能。其中,改进GAN 的PSNR 在SNR=-4 dB 条件下提升约4 dB,在采样率=0.875条件下提升约3.5 dB。
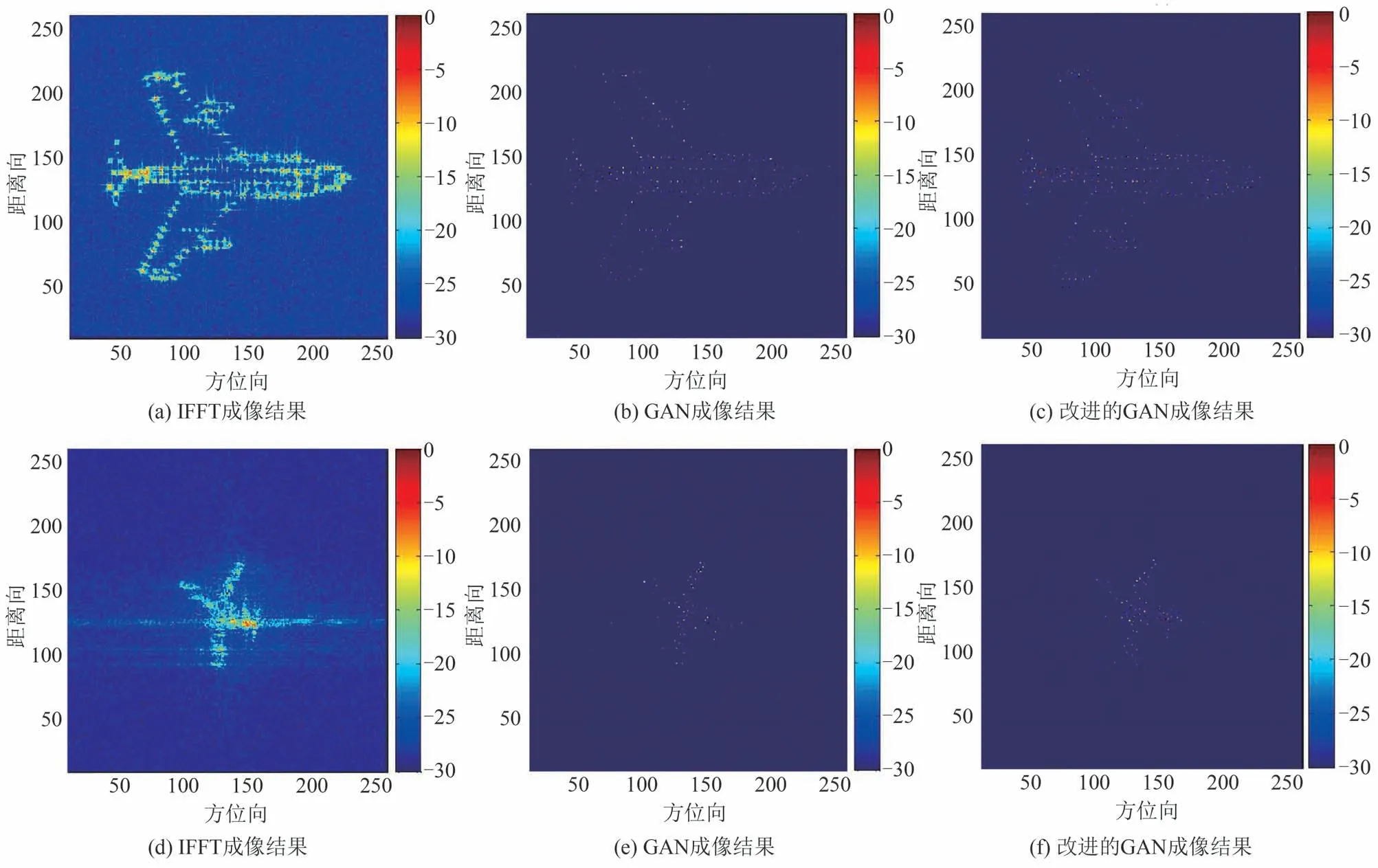
图15 文献[122]和[123]方法对比[123],SNR=-4 dB;(a)~(c):仿真数据;(d)~(f):实测数据Fig.15 Comparison of methods in [122]and [123][123],SNR=-4 dB;(a)~(c):Simulation data;(d)~(f):Measured data
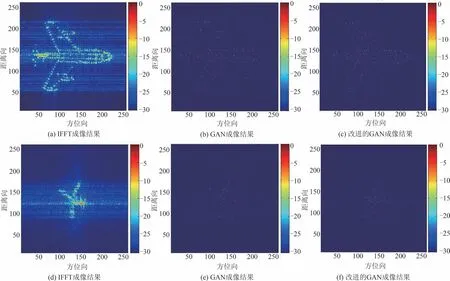
图16 文献[122]和[123]方法对比[123],采样率为0.875;(a)~(c):仿真数据;(d)~(f):实测数据Fig.16 Comparison of methods in [122]and [123][123],sampling rate is 0.875;(a)~(c):Simulation data;(d)~(f):Measured data
随后,本团队还通过引入注意力机制,提出一种基于注意力GAN(attention GAN,AGAN)的新型ISAR 成像方法[124],其中注意力机制采用由空间注意力和通道注意力共同构成的卷积注意模块(convolutional block attention module,CBAM)[125],其结构如图17 所示。该方法利用CBAM 选择对成像贡献较大的特征图,并促使网络更加关注强散射点,这有助于ISAR成像质量的进一步提升。
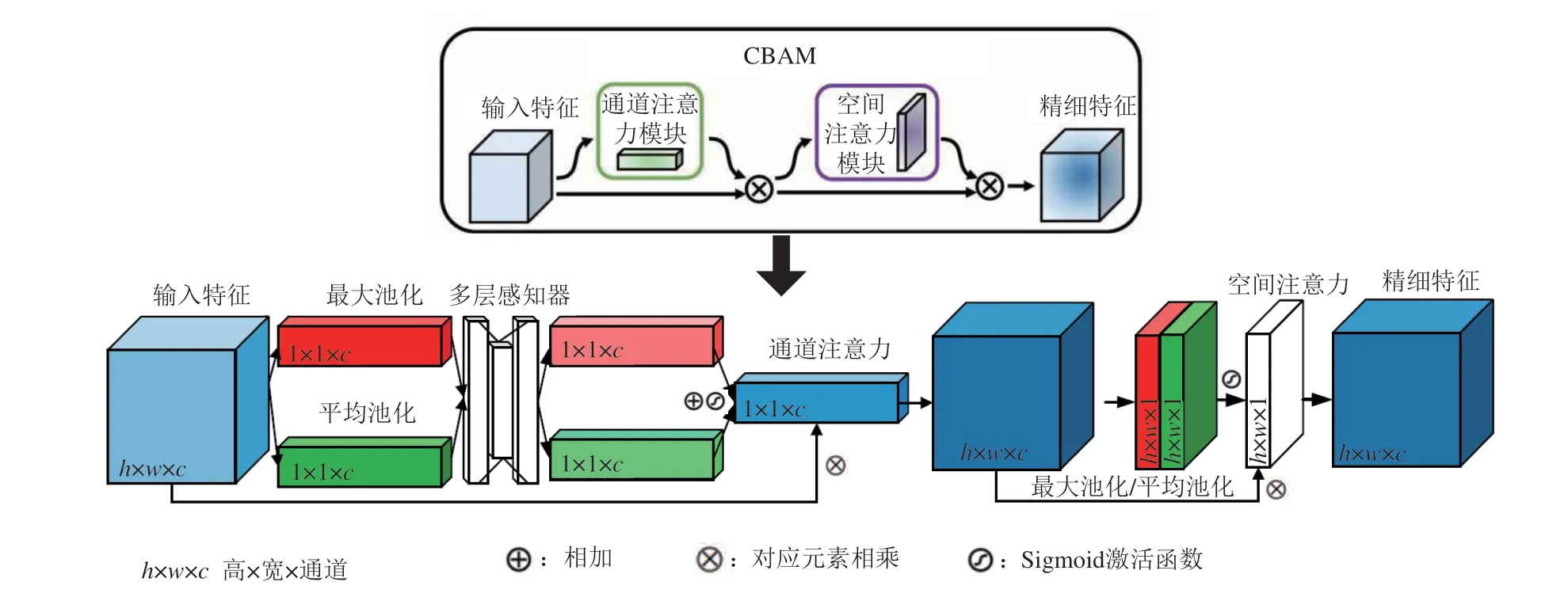
图17 注意力机制CBAM结构图Fig.17 Structure of attention mechanism CBAM
3.1.2 机动目标
上述基于数据驱动的ISAR 增强成像方法主要针对平稳运动目标,这些方法在提升分辨率和去除噪声方面性能出众,但在还原图像的纹理细节和结构信息方面能力较弱。当面对机动目标成像时,单独使用这些DNN 无法获得去模糊的ISAR 图像。为此,史洪印教授团队针对旋转角度较大的机动目标提出一种将DL 与keystone 变换相结合的ISAR 机动目标自聚焦成像算法[126]。该方法首先通过keystone 变换粗略补偿机动目标平移和旋转产生的相位误差,获得初步成像结果,然后利用U-net 实现超分辨率增强成像。实验中采用仿真生成的1000 个数据样本对网络进行训练,与FFT 和keystone 变换算法相比,该方法具有更优的聚焦性能和峰值旁瓣比。此外,由于时频分析(time-frequency analysis,TFA)具有较高的计算效率,最新基于DL 的TFA 方法在机动目标ISAR 成像研究中同样展现出良好性能。2019 年成都电子科技大学钱江教授团队提出了一种基于机动目标TFA 的ISAR 学习成像方法[127],该方法将低分辨率短时傅里叶变换(shorttime Fourier transform,STFT)作为网络输入,充分利用CNN 的学习特性来获得高分辨率的时频分布。然后,采用传统的距离-瞬时多普勒(rangeinstantaneous Doppler,RID)成像方法,堆叠来自不同距离单元的高分辨率瞬时多普勒线,完成机动目标的高分辨率ISAR 成像。为进一步研究机动目标的超分辨率ISAR 成像和噪声抑制,该团队于2021年提出一种用于机动目标超分辨率重构和去噪的DL-RID 成像方法[128]。该方法采用基于STFT 的Unet(STFT-U-net)辅助TFA 实现高分辨率谱估计,并在U-net 中引入卷积上采样层和ℓ1范数损失函数来实现超分辨率和噪声抑制。仿真和实测实验表明经过训练的STFT-U-net 在预测高分辨率频谱的同时,不仅不会出现任何不良交叉项,还可以抑制背景噪声。
然而,上述针对机动目标的ISAR 成像研究均需要依赖传统方法处理由机动引起的图像模糊,成像过程繁琐复杂,不利于实时成像。另外,大部分现有的基于数据驱动的ISAR 增强成像网络直接采用随机点目标进行训练,这将导致测试结果通常只能保留幅值较大的散射点,从而忽略了ISAR 目标的块稀疏特性,造成大量细节和纹理信息丢失。针对这些问题,本团队在文献[129]中首先提出一种基于DeepLabv3+和Diamond-Square 的块稀疏目标仿真数据生成方法,用于构建贴近实测数据电磁散射特性的训练集,图18给出数据生成流程以及构建的部分标签图像。
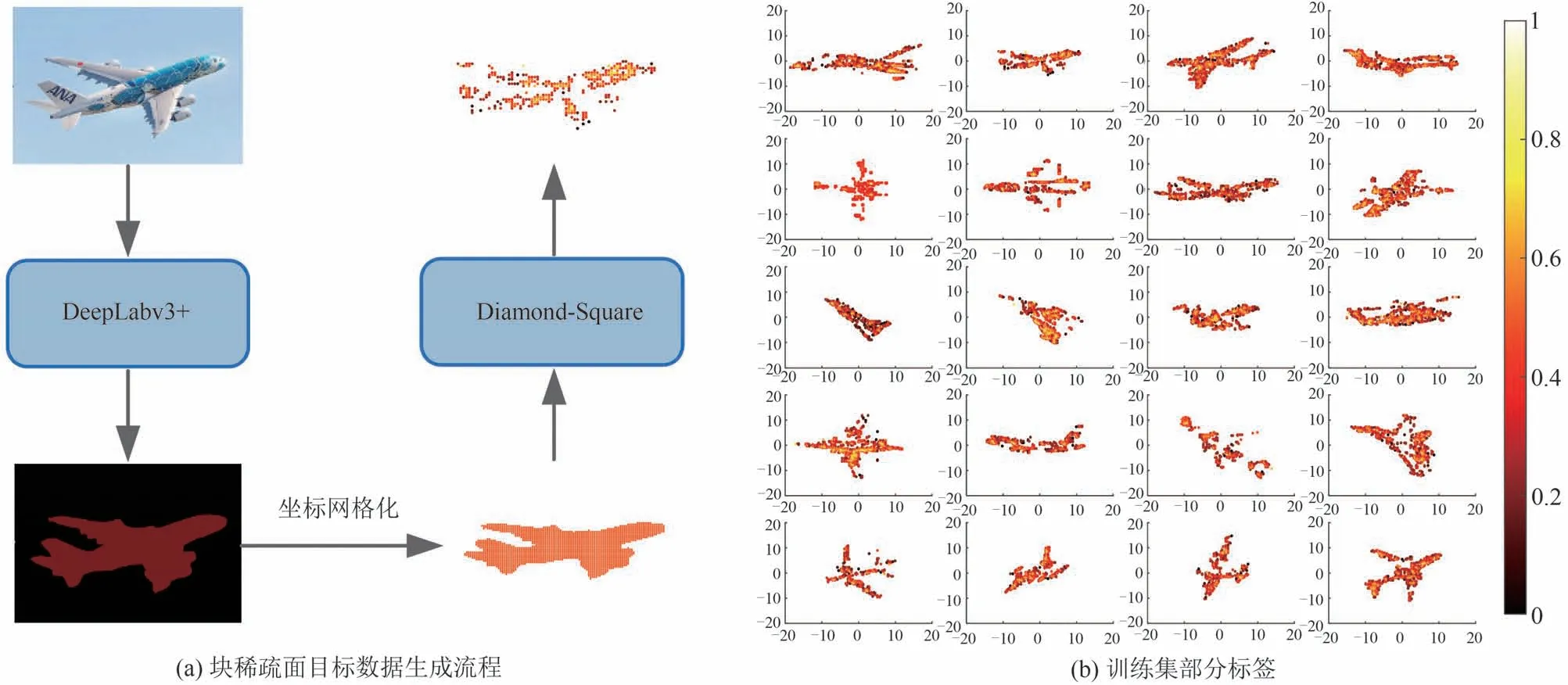
图18 面目标数据生成方案及仿真结果Fig.18 Area target data generation scheme and simulation results
然后,在该数据生成方案的辅助下,提出一种基于先进Transformer 结构的GAN(Uformer-based GAN,UFGAN)框架,其中生成器由基于局部增强窗口(locally-enhanced window,LeWin)的Transformer模块和多尺度恢复调制器构建,鉴别器通过结合PatchGAN 和全局GAN 来实现局部信息和全局信息的融合,这种设计能够提供对图像整体的综合评估以及局部细节的一致性评价。经过具有块稀疏特性的数据集训练后,UFGAN可以直接实现机动目标模糊图像到高质量ISAR 图像的映射,而不需要传统成像方法的辅助。在实测实验中,为检验UFGAN面对实测机动目标数据的成像性能,利用傅里叶插值重采样方法从Yak-42 回波数据中获得等效的机动Yak-42 回波数据。图19 给出分别采用RDA、STFT、基于点目标训练的改进GAN[123]和UFGAN 四种方法所获得的实测数据成像结果,相比于无法处理机动相位误差的RDA、STFT和改进GAN,UFGAN保证了ISAR 目标的块稀疏结构特性,同时实现了机动目标的去模糊成像,恢复了机动目标的更多纹理细节和结构信息。这是Transformer 在ISAR 成像应用中的第一次尝试,所构建的网络在成像性能和成像效率方面远超传统的机动目标成像方法。
3.1.3 平动补偿
此外,与传统方法在图像域利用DL 执行增强成像的研究思路不同,本课题组另辟蹊径,利用DNN 提升ISAR 回波的包络对齐效果,从回波域优化运动补偿的角度来增强ISAR 成像性能。传统的包络对齐方法依赖于高SNR 和相邻脉冲的相关性,因此无法在低SNR 和稀疏孔径条件下准确完成。本团队首先针对低SNR 问题,在文献[130]中提出一种基于RNN 架构的包络对齐方案,这是ISAR 成像研究领域首次尝试通过DL 技术解决平动补偿问题。该方案虽然可以在低SNR 情况下取得优于传统方法的包络对齐效果,但是仍然无法解决稀疏孔径对包络对齐的影响。考虑到CNN 与RNN 相结合的方案可以实现图像特征之间的相互补充[131],本团队随后针对低SNR 和稀疏孔径问题,在文献[132]中提出一种结合CNN、RNN 与注意力机制的包络对齐网络,其中注意力机制用于整合CNN 与RNN 提取的区域和时序特征。本课题组提出的两种平动补偿网络均采用监督训练的方式学习从未对齐回波到对齐回波的映射,图20 给出文献[130]和文献[132]两种网络在低SNR 和稀疏孔径条件下的输出结果。实验表明,文献[130]所提方案可以处理背景噪声,但无法实现稀疏孔径下的包络对齐。相反,文献[132]所提网络能够有效地实现非合作目标在低SNR和稀疏孔径条件下的包络对齐。
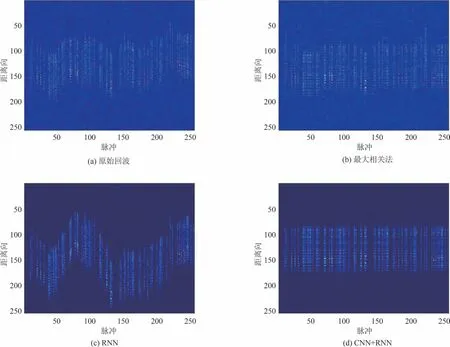
图20 35%降采样、SNR=-5 dB条件下不同方法的包络对齐结果[132]Fig.20 Envelope alignment results of different methods with 35% down-sampling and SNR=-5 dB[132]
3.2 基于DL的ISAR端到端成像
近年来,已有研究提出直接利用DNN 实现从ISAR 回波到图像的映射。2018 年,黎湘教授团队在该方向做出首次尝试[133],提出一种基于CV-CNN的端到端ISAR 成像网络。该网络在复数域进行训练,其输入为复值回波信号,利用全连接层实现FFT,且网络结构中包含相位传播。前文已经表明这种数据驱动DL 成像技术存在明显缺点,因此,模型驱动和数据驱动相结合的DL 成像技术同样被应用于ISAR 端到端成像领域[134],这种方法除了具有可解释性以及能够解决数据壁垒之外,其模型驱动的思路在一定程度上也可以保护ISAR 图像的固有结构信息。
ISAR 端到端成像网络同样采用将凸优化算法求解成像模型的迭代步骤嵌入到DL 网络中的方式进行构建,其中ADMM 在ISAR 学习成像中应用最为广泛。基于ADMM 的DUN 网络(Deep-ADMMNet)最早被应用于核磁共振成像的稀疏重建[135]。2019年,朱岱寅教授团队将改进的Deep-ADMM-Net应用于ISAR 成像领域[136],并证明该端到端成像网络在图像重建质量和计算效率上都优于CS 方法。但是,Deep-ADMM-Net 也存在明显的局限性:1)该网络对雷达信号进行矢量化操作,属于1D-ADMMNet,需要消耗更多的计算资源。2)Deep-ADMMNet忽略了ISAR回波的复数特性,属于实值ADMMNet,且没有考虑ISAR自聚焦。针对上述问题,西安电子科技大学雷达信号处理国家级重点实验室的白雪茹教授团队提出在复数域中反向传播训练的2D-ADMM-Net[137],用于提升ISAR 成像网络处理大规模回波矩阵的能力。
2020 年,黎湘教授团队提出一种二维复值ADMM-Net(CV-ADMMN)来提高ADMM 的稳定性[138]。该网络引入基于熵最小化的自聚焦模块,可以实现ISAR 自聚焦和稀疏成像,仿真和实测数据的实验结果表明CV-ADMMN 比传统ADMM 方法具有更好的成像性能,图21 给出CV-ADMMN 和不考虑自聚焦模块的ADMM-Net之间的结构对比。对于ISAR自聚焦方法而言,基于熵最小化的自聚焦会受到熵计算负担的限制,基于CS的自聚焦方法同样具有较大计算量。为提升稀疏孔径ISAR 自聚焦的计算效率,促进其实际应用,该团队提出一种基于ADMM 的稀疏贝叶斯学习(sparse Bayesian learning,SBL)方法[139],并通过实验证明该方法可以比传统基于SBL 的ISAR 自聚焦方法[140]速率提升20~30倍。类似地,2021 年张晓玲教授团队提出一种基于AMP 迭代的ISAR 学习成像方法,称为自聚焦AMP网 络(autofocusing AMP network,AF-AMPNet)[141],该自聚焦成像网络在实现稀疏成像的同时还引入了相位误差估计,进一步确保了图像质量。
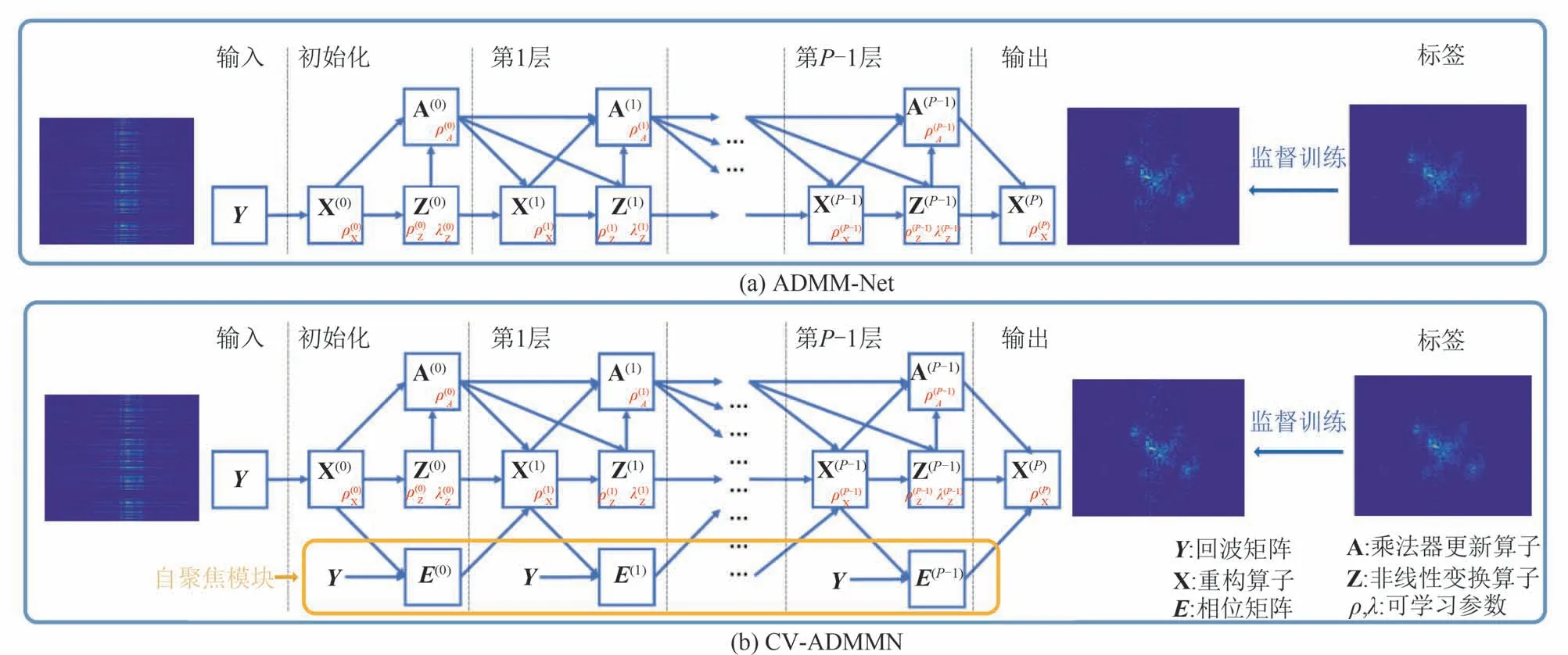
图21 ADMM-Net和CV-ADMMN结构对比Fig.21 Structure comparison between ADMM-Net and CV-ADMMN
此外,为同时处理ISAR 成像中的大转角和稀疏重构难题,复旦大学金亚秋教授团队于2022年提出一种模型驱动学习成像网络(model-driven learning imaging network,MDLI-Net)[142]。该网络由两个子网络组成:稀疏重构网络和图像转换网络。前者通过深度展开ISTA进行构建,旨在从稀疏采样数据中恢复完整采样回波,获得初步的成像结果,后者由U-net 网络组成,致力于校准大转角引起的散焦。对于经过训练的MDLI-Net,在输入稀疏采样回波后,可直接输出高分辨率的聚焦ISAR图像。
值得注意的是,ISAR 图像除了具有稀疏性外,还表现出一些固有的结构特性。例如,一些复杂结构的散射能量往往分布在一些相互靠近的ISAR 图像像素中。基于DUN 的ISAR 学习成像方法往往通过正则化将先验信息引入稀疏孔径ISAR 成像任务。然而,单一的正则化器不能捕获目标的复杂结构信息,相应的先验模块也不能准确反映目标先验信息。
因此,最近有学者围绕ISAR 图像的块稀疏结构特性展开研究。考虑到SBL 能够以概率方式提供结构稀疏先验[143],文献[144]提出一种结合模式耦合SBL 和广义AMP 的深度展开框架,将其用于ISAR 图像的块稀疏结构特征学习以及高效成像。文献[145]将深度展开与神经网络相结合,提出一种采用PnP 框架的块稀疏ISAR 成像网络。该方法利用复值U-net(CV-U-net)学习先验信息,将基于CV-U-net 的去噪先验模型嵌入到ADMM 中来代替传统的正则化器,随后通过深度展开将其构建为成像网络,称为U-ADMMNet。这种整合DUN 和CNN的创新思路可以弥补模型驱动方法和数据驱动方法的弱点,有效解决传统迭代过程采用单一正则化去噪器的局限性。图22 给出基于l1正则化器的ADMM、基于PnP 框架的ADMM 以及U-ADMMNet三种成像方法的结果对比,实验结果表明UADMMNet不仅可以利用先进的去噪技术提高ISAR成像质量,还可以从训练数据中学习目标的结构先验信息,进而恢复更多细节。张晓玲教授团队同样针对ISAR 的结构特性,将基于ISTA 的DUN 与CNN相结合,提出一种ISAR 高效稀疏成像方法——卷积迭代收缩阈值(convolution IST,CIST)网络[146]。CIST 与U-ADMMNet 的设计思路区别在于CIST 并不是将神经网络用于替换传统的正则化器,而是利用非线性卷积运算来实现稀疏表示。CIST 中的非线性变换和迭代参数可以在训练过程中自适应学习,这提高了块稀疏信号恢复的灵活性和鲁棒性。
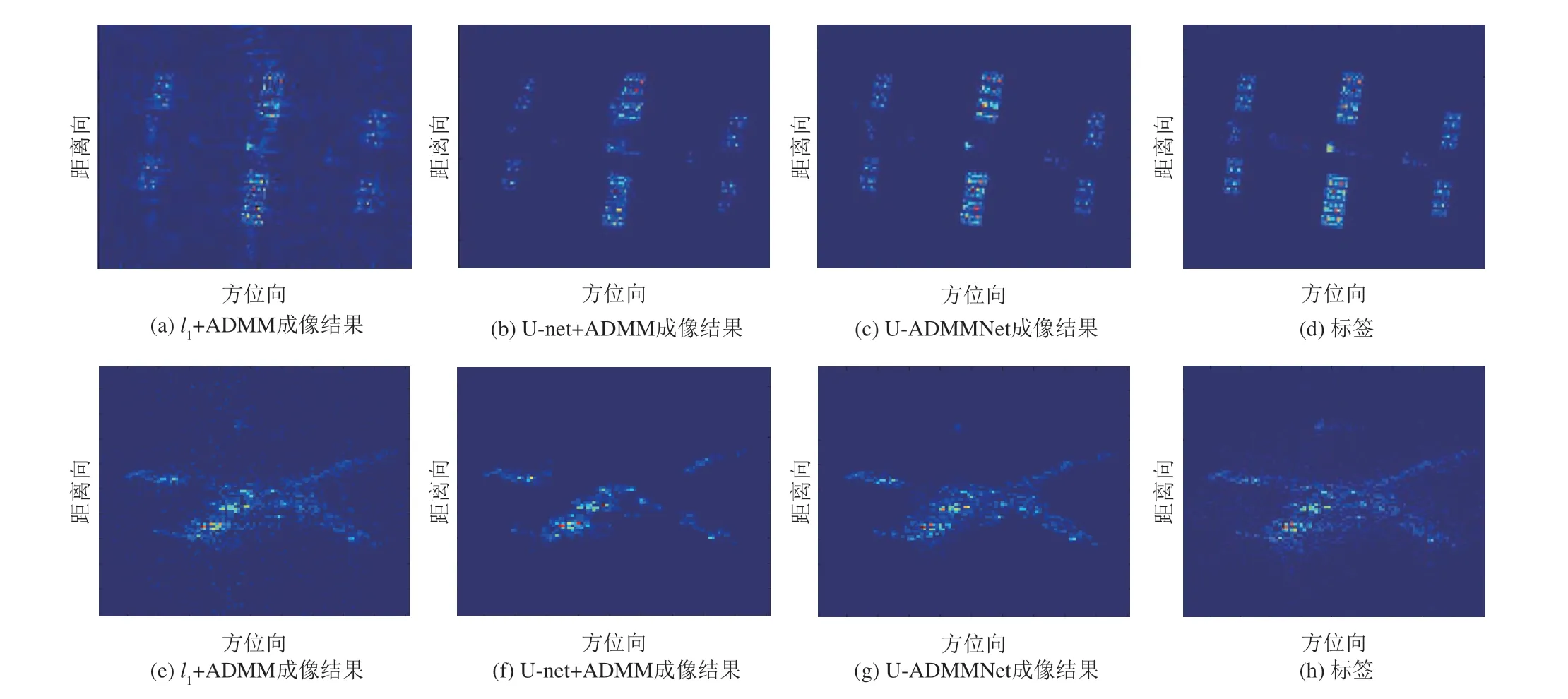
图22 l1+ADMM、U-net+ADMM和U-ADMMNet成像结果[145];(a)~(d):仿真数据;(e)~(h):实测数据Fig.22 Imaging results of l1+ADMM,U-net+ADMM,and U-ADMMNet[145];(a)~(d):Simulation data;(e)~(h):Measured data
4 总结与展望
本文围绕DL 理论和SAR/ISAR 成像机制展开研究,主要关注DL 手段如何解决SAR/ISAR 图像去噪、图像超分辨、图像恢复等逆问题,旨在构建雷达智能成像的初步研究框架。此外,为了清楚地梳理目前DL 技术在SAR/ISAR 成像领域的研究现状,本文针对不同的成像问题以时间轴为主导,对本课题组以及国内外众多团队在相关领域的研究成果进行详细阐述和对比分析。
值得注意的是,虽然DL 成像技术在雷达图像重构质量和效率方面明显优于传统方案,但该方法目前还处于实验探索阶段,未来仍需要对关键的DL成像技术进行不断研究和突破:
1)数据驱动DL 成像技术:在基于数据驱动的学习成像方法中,深度网络仅用于实现部分功能,需要依赖传统方法辅助才能完成端到端的图像恢复和图像增强,因此该方法不利于所接收回波的实时处理。此外,雷达成像和分辨率提升的目的是为下一步目标识别和解译做准备,然而大部分数据驱动方法获得的SAR/ISAR 图像容易丢失目标结构特征,并未从本质上解决雷达图像解译以及重点目标识别困难等关键性问题。
针对上述问题,未来需要研究网络的级联技术。考虑到网络的模块化功能,可以将雷达成像识别全流程中的回波预成像、图像去噪、图像超分辨率、图像解译识别等阶段均设计为对应的网络模块,然后将训练完成的网络级联到一起。这种级联网络不仅可以提升实时性,还可以通过全局调优改善目标的分类和识别性能。例如当解译网络对车辆、舰船等目标分类时,可以指导成像网络提取相应的目标特征,输出目标增强且背景弱化的图像;当解译网络用于检测GMT时,可以调整成像网络以突出GMT与静止目标之间的差异,提升识别精度。
2)模型驱动与数据驱动相结合的DL 成像技术:DUN 在保持良好计算效率和可解释性的同时显示出优异的图像重构性能,但也存在一些缺陷:一方面,DUN 对雷达工作模式和成像模型十分敏感,不同工作机制下的观测任务存在明显区别,一旦成像模型发生改变,可能需要对网络重新设计并训练。而且,由于DUN主要通过将传统迭代优化算法展开为深度网络来实现,其成像性能依赖于算法的补偿设计以及该算法是否适用于网络展开,所以一般的网络结构无法处理大斜视、大转角、机动目标等条件下的雷达聚焦成像问题。另一方面,DUN 在学习回波数据域到目标图像域的映射关系时,对回波数据要求较高。首先,仿真回波数据与实测回波数据存在一定偏差,这会导致实测数据的成像性能受到一定影响。其次,真实场景的回波数据维度非常庞大,在训练过程中会造成内存负担严重、网络收敛速度慢以及梯度消失等问题。降采样数据虽然可以减少内存占用,但是如何实现数据量与成像精度之间的权衡仍存在很大难度。
为有效解决这些问题,未来应重点关注DL 模型的鲁棒性研究以及小样本学习研究。类脑神经网络具备多通道协同处理能力,大量的知识储备使其通过提升DL 模型的可持续学习能力来应对变化的任务[147]。因此,结合类脑神经网络和相应的训练方式有望改善DL 成像模型泛化性能较差的现状。此外,基于预训练网络微调以及迁移学习的小样本模型和算法目前已经在计算机视觉任务中取得较好效果。因此,小样本学习在降低雷达成像网络的训练样本需求和利用先验特征约束成像网络等方面具有广阔的研究前景。
