基于YOLOv8的火灾烟雾检测算法研究
2023-10-16王晨灿
王晨灿,李 明
(重庆师范大学 计算机与信息科学学院,重庆 401331)
0 引言
近年来发生的大面积火灾主要来源于森林和工厂,对公共设施和生态资源造成了不可估量的损失。如何根据火和烟的特性来提高火灾检测的整体性能,成为当前研究的重点。目前,火灾检测研究主要是基于深度学习算法的研究,该研究大致可以分为基于目标分类模型的火灾烟雾检测算法、基于目标分割模型的火灾烟雾检测算法、基于目标检测模型的火灾烟雾检测算法[1]。
基于目标分类模型的火灾烟雾检测算法是对输入的火灾图像输出一个fire或smoke标签,用于判断图像中是否含有该类别的目标信息。陈俊周等提出了如何提取动态烟雾纹理信息的解决方案,通过将静态特征与动态特征相结合的方法,使烟雾检测的场景适应能力得到极大提升,但由于火灾早期目标比较小,检测出的背景区域较大,由此增加了模型的复杂度[2];殷亚萍等使用高斯混合模型提取目标特征,通过选择分支进行卷积操作,有效提高了模型检测的准确率,但该方法容易产生空洞现象[3];He等基于融合多尺度特征的方法提升区分小烟雾以及类烟物的能力,但该方法只适用于浓雾的火灾场景,且不能识别出烟雾的具体位置,对火灾应急救援存在一定的局限性[4]。
基于目标分割模型的火灾烟雾检测算法是根据火灾蔓延的趋势,在目标识别的基础上进一步提取烟雾和火焰的形状、大小等信息。Khan等采用轻量化的EfficientNet卷积神经网络和DeepLabv3+网络对烟雾图像进行先分割后分类,能够有效降低误检率[5-7];Pan等设计了一套森林火灾预警系统,将分类、检测和分割集成到一个混合模型中,对火灾的烟雾和火焰信息进行综合评估,再根据相应的算法得出该场景下的火灾类别,但模型比较大,训练非常复杂,不能满足火灾现场实时检测的要求[8]。
基于目标检测模型的火灾烟雾检测算法是针对多个火焰目标进行定位和图像分类,需要在原始图像中将目标用矩形框标出。Lin等结合Faster RCNN 与3DCNN 模型进行烟雾检测,提高了目标定位的准确率以及检测精度,但由于在检测过程中候选框的生成和分类是分两步进行的,因此模型较复杂、检测速度慢、模型泛化性差[9-11];Park等将Elastic融入YOLOv3网络的Backbone模块,通过随机森林分类器判别目标是否为火焰,该方法能够有效检测复杂场景下的火灾信息,但模型较大且对运算推理的算力要求高,不能满足实时机载设备巡检的要求[12];谢书翰等基于单阶段目标检测算法使用K-means聚类得到适合烟雾的锚框,避免了图像中无关信息的干扰,该方法在增加参数量和降低计算速率的条件下提升了检测精度[13];Xu等提出了一种像素级与目标级融合的显著目标检测算法,针对开放空间中的烟雾进行检测,在很大程度上保留了图像的原有特征信息,但网络本身存在特征利用不充分的情况,导致平均分类性能偏低[14]。
基于目标检测模型具有实时性强、能精准获取定位信息的优势,本实验选用典型的YOLO算法进行火灾烟雾检测研究,针对上述检测模型存在的问题,提出适用于各类场景的Fire-YOLOv8轻量化模型。
1 原始网络
继YOLOv5之后,Ultralytics公司在2023年1月发布了YOLOv8,该版本可以用于执行目标检测、实例分割和图像分类任务。整个网络结构由4部分组成:输入图像,Backbone主干网络获得图像的特征图,Head检测头预测目标对象和位置,Neck融合不同层的特征并将图像特征传递到预测层。
1.1 YOLOv8算法的优势
1)相比于YOLOv5和YOLOv7算法,YOLOv8在训练时间和检测精度上得到极大提升,而且模型的权重文件只有6 MB,可以部署到任一嵌入式设备中,它凭借自身快速、高效的性能可以很好地满足实时检测的需求。
2)由于YOLOv8算法是YOLOv5的继承版本,对应提供了N、S、M、L、X等不同尺度的模型,用于满足不同场景的需求,在精度得到大幅提升的同时,能流畅地训练,并且能安装在各种硬件平台上运行。
3)在输入端,YOLOv8算法使用了Mosaic数据增强[15]、自适应锚框计算[16]等方法。Mosaic数据增强是通过随机缩放、随机裁剪、随机排布的方式进行拼接,丰富检测数据集。自适应锚框计算是网络在初始锚框的基础上输出预测框,通过差值计算、反向更新等操作计算出最佳锚框值。
4)在输出端,YOLOv8算法使用解耦头替换了以往的耦合头[17](见图1),将分类和回归解耦为两个独立的分支,通过解耦使各个任务更加专注,从而解决复杂场景下定位不准及分类错误的问题。同时,YOLOv8算法还借用了DFL 的思想[18],采用 Anchor-free目标检测方法[19],让网络更快地聚焦到目标位置的邻近点,使预测框更接近于实际边界框区域。
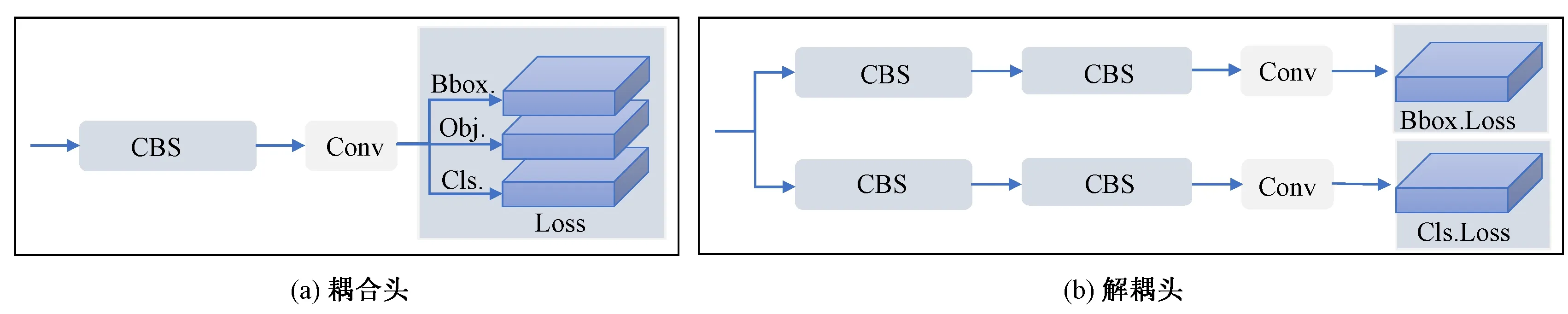
图1 YOLOv5用到的耦合头与YOLOv8用到的解耦头
1.2 YOLOv8算法在火灾检测中的问题
1)YOLOv8针对一般的物体检测没有问题,相比其他算法具有明显的优势。但火灾存在诸多不确定性,若要利用火焰及烟雾的特性提前预判火灾的扩散趋势,就需要网络在实际场景中对火焰的走势以及烟雾的变化形态不断地学习,并迭代更新网络参数,才能对火情做出更准确的判断。
2)YOLOv8原始网络在输入端共有5种尺度的检测层,但真正参与特征提取运算的只有P3~P5层,它们分别生成8、16、32倍下采样特征图信息。这3种尺度的检测层只能识别出火灾场景中分辨率为8×8以上的目标特征信息,不能有效识别分辨率小于8×8的目标信息,这在很大程度上限制了该算法对火灾早期预警的效果。
3)目前已有的火灾数据集大部分是基于火焰信息进行标注的,但对于一些复杂场景,只有火焰的特征信息很难满足实时检测任务的需求。例如,最初的小火苗很容易被其他物体遮挡,YOLOv8算法还不能穿透遮挡物体来提取特征信息。本文利用物体燃烧过程中烟雾的流动性,在数据集中增加烟雾检测特性,通过烟雾和火焰两者的特征信息进行综合判别,从而解决在复杂场景下进行火灾早期预警的问题。
2 Fire-YOLOv8网络
2.1 增加小目标检测层
目标检测层使用Anchor-free方法,其原理是直接检测物体的中心区域和边界信息,将分类和回归解耦为两个子网格,分别计算子网格中的预测像素点到真实框4条边界的直线距离,由此得到预测框的位置信息。子网格中每个点的中心度C为:
(1)
式中:l为像素点到真实框左边界的距离,r为像素点到真实框右边界的距离,t为像素点到真实框上边界的距离,b为像素点到真实框下边界的距离。
由式(1)计算可知,在进行边框回归分支训练时,像素点越远离目标中心区域,中心度的值越小,特征提取的误差将越大。
在原始YOLOv8网络中,预设了图像大小为640×640的9种不同宽高比的预选锚定框,并为每一个目标检测层分配3种锚定框,但受锚定框的尺寸限制,不能对微小的火苗进行标定。为了解决这一问题,在原始网络现有的3个目标检测层的基础上再增加一个更小的目标检测层。此检测层输出特征图的大小为160×160,可以有效提取分辨率在8×8以下的烟火图像信息,能够满足复杂场景下早期火灾预警的要求,较好地解决了YOLOv8模型不能精确识别小火焰目标的问题,效果如图2所示。

图2 不同检测层的预选锚定框
2.2 Focus层
借鉴YOLOv5版本的思路,在图像进入Backbone前对其进行focus处理,即对图像进行切片操作。在图片中每间隔1个像素取值,得到4张图片,使图片的长和宽分别减半,通道数扩展为原来的4倍。该操作类似于2倍下采样,但是可以保证图片信息不丢失(以YOLOv8网络为例,输入大小为640× 640 × 3的原始图像,通过Focus层对其进行切片操作,得到320 × 320 × 12的特征图)。在网络输入端使用一个Focus层代替三层卷积操作,经过替换后参数量变少了,从而达到提升推理速度的效果。同时,充分的特征提取能将数据多变性对mAP的影响降至最低。
2.3 BottleneckCSP模块
在网络的特征提取部分,采用BottleneckCSP模块替换之前的C2f模块(见图3)。该模块由Bottleneck和CSP结构[20]组成,能够对网络残差特征进行学习,并调整特征图的深度和宽度。与原网络中的C2f模块相比,BottleneckCSP模块能减少内存消耗和计算瓶颈。子模块Bottleneck通过卷积计算改变数据的通道数,Bottleneck的瓶颈层有多种形式,标准形式是进行一个1×1和3×3的卷积后加上其本身的短路连接,由此可以在主干特征提取阶段减少运算参数量,既保证了推理的速度和准确性,还减小了模型尺寸,使模型更加轻量化。
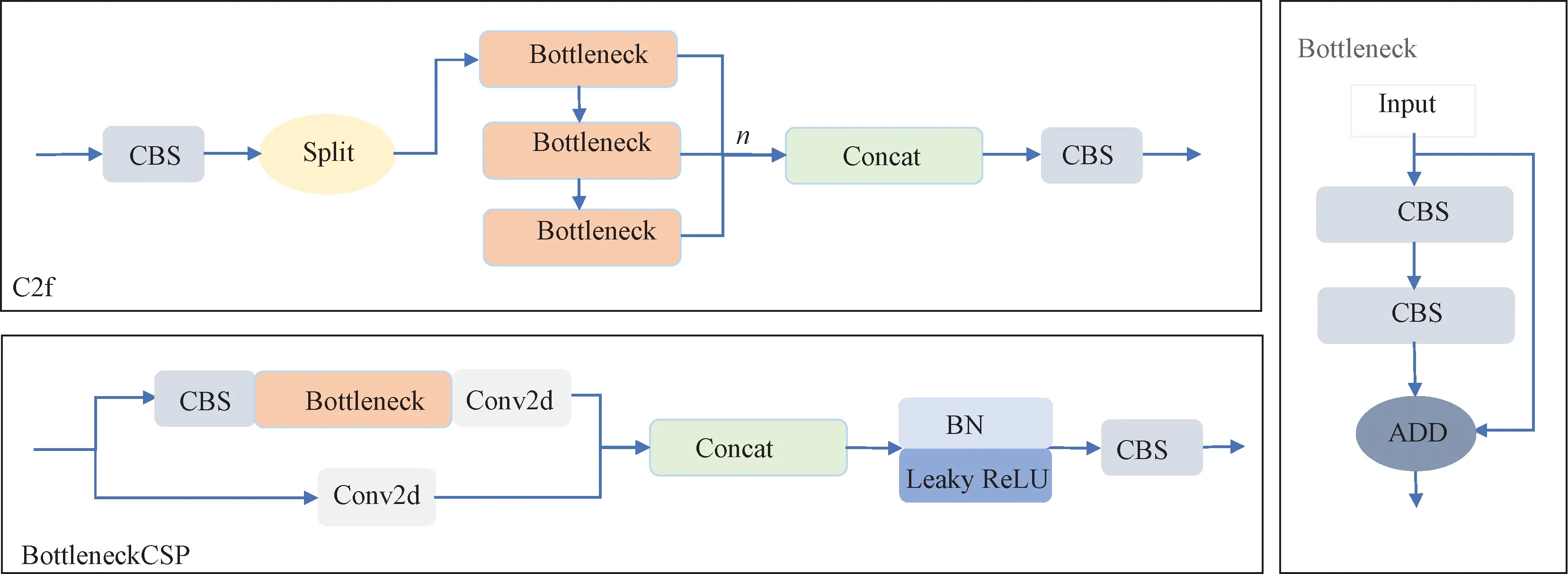
图3 BottleneckCSP与C2f模块结构
2.4 模型预训练与迁移学习
YOLO算法虽然具备很强的普适性,但在不同场景下,尤其是针对小数据量进行训练时,需要对应用场景做具体适配。迁移学习能较好地满足个性化模型的适配要求[21],即在网络预训练阶段采用迁移学习进行模型自适应调参,找到火灾场景检测的最佳权重参数,流程如图4所示。首先,将烟火样本数据集在YOLOv8模型中进行训练,训练n次后,选择最优的一组模型继承下来,确定自适应层;然后,保留确定好的各层权重信息,并迁移到Fire-YOLOv8网络中,每次解锁1个迁移层,依次微调并查看模型的提升效果;最后,将实验调试后的自适应层权重文件保留下来,与烟火数据集进行训练,生成火灾检测的权重文件:Fire-YOLOv8n.pt。以此通过自适应调整后的网络模型,可以挖掘烟雾与火焰之间的深层次关系,对于火灾的变化趋势具有一定的预测性。

图4 迁移学习自适应调参流程
2.5 构建火灾检测网络
本文在原始YOLOv8网络的基础上进行上述几个部分的设计,构建Fire-YOLOv8火灾检测网络框架(见图5),用于烟火检测的实验研究。
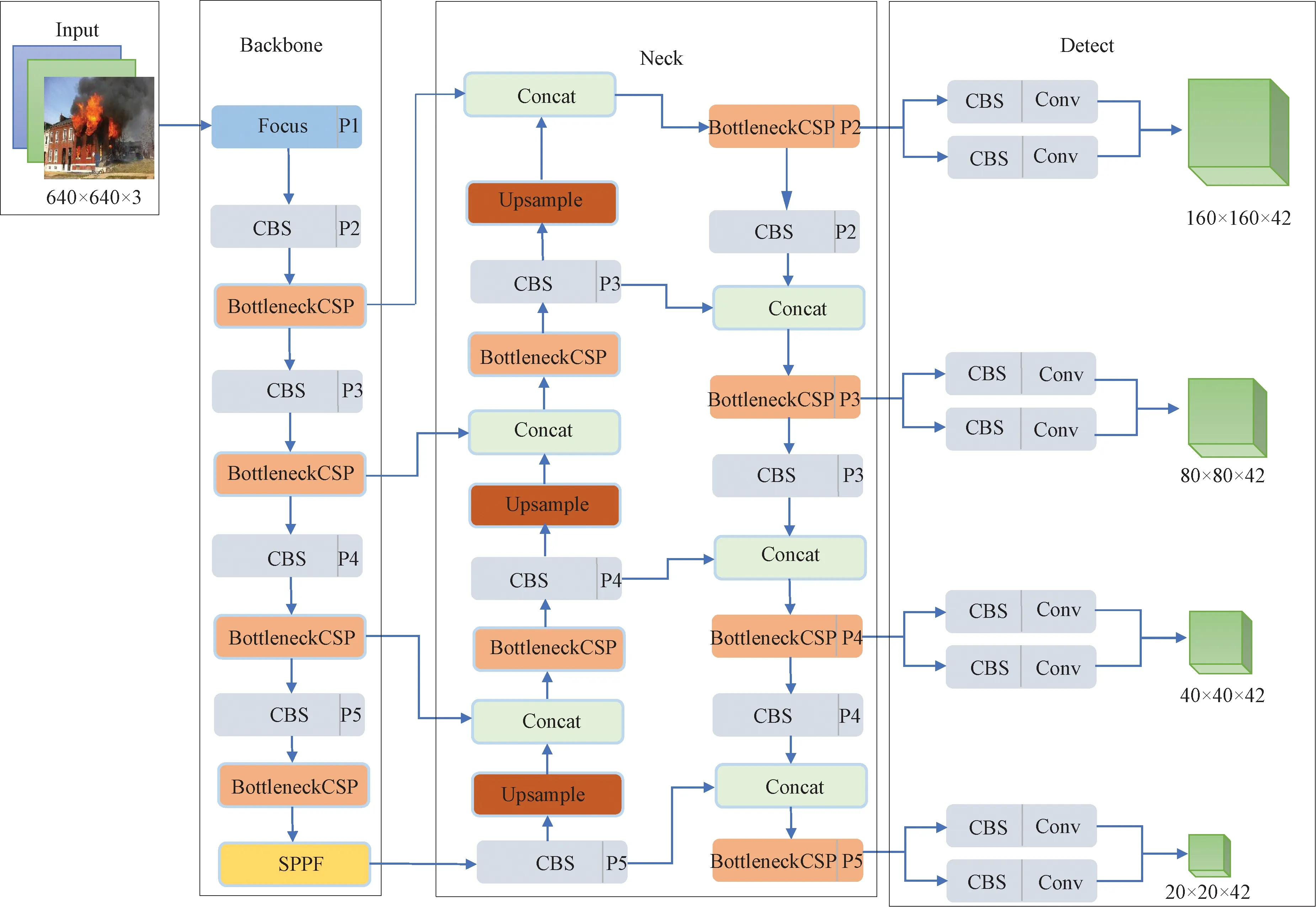
图5 Fire-YOLOv8整体网络结构
3 实验及结果分析
3.1 构建数据集
3.1.1数据集采集
为了解决现有烟火数据集存在的场景单一、类火类烟物干扰、小目标难以识别等问题,本实验运用爬虫技术收集各大网站上的火灾视频及图像,将收集到的视频进行逐帧提取,并与各类场景下的火灾和烟雾图像进行混合,制作出一个场景较为全面的数据集。该数据集既包含森林、城市、工厂等背景下的大型火灾烟雾图像,也包含打火机、蜡烛、燃气灶、香烟等背景下的小目标火焰烟雾图像。同时,为区分类火类烟的场景信息,本实验在数据集中加入10%的负样本进行参照学习,以达到降低误检率的效果。
3.1.2数据集处理
首先,将各类火灾场景图像进行去噪、增强、背景混合等处理后,共得到6 800张图像,构成本实验的烟火数据集。其次,在labelImg软件中分别对每张图像进行数据标注,根据火灾的属性将数据集分为两类,标签分别为fire、smoke。最后,将标注好的数据集按照7∶2∶1的比例划分为训练集、验证集和测试集,生成images和labels两类文件,供网络模型进行训练和验证。
除此之外,从处理后的6 800张图像中挑选出分辨率高、目标效果显著的图像,共198张,再进行亮度增强、对比度增强、旋转任意角度、复合缩放等处理,对标注信息的定位框反复校验之后,将得到的数据集作为YOLOv8模型的样本数据集。
3.2 实验设计
3.2.1实验环境
实验中采用的硬件环境包括:CPU为AMD R7-5800H,工作频率为3.20 GHz,内存大小为16 G,显卡为Nvidia GeForce RTX3050+RTX3090,摄像头为1080P全高清IR摄像头。软件环境采用Python 3.9.13、PyTorch 1.13.0,GPU加速器为CUDA 11.4。
模型预训练权重采用YOLOv8n.pt和YOLOv8s.pt,将输入图片的分辨率统一设置为640×640,训练中采用SGD函数进行参数优化,将初始学习率设置为0.01,Batch-size设置为8,每次实验设置200个epoch。
3.2.2评价指标
本研究通过实验来评估改进的Fire-YOLOv8算法,采用精确率、召回率、Fβ分数、平均准确率、平均精度均值和帧率作为算法的性能评价指标。样本分类标准如表1所示。

表1 样本分类标准
1)精确率P(Precision),又称为查准率、正确率,计算公式为
(2)
2)召回率R(Recall),又称为查全率,计算公式为
(3)
3)Fβ分数,是精确率和召回率的调和平均数,计算公式为
(4)
式中:β的取值通常为0.5、1、2。本实验中将β的值设置为1,即用F1表示,值域在[0,1]之间。
4)平均准确率AP(Average Precision),是单个类别的平均分类性能,即P-R曲线与第一象限所围成的面积,计算公式为
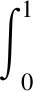
(5)
AP值越高,表示模型对这个类别的检测精度越高。
5)平均精度均值mAP(mean Average Precision),是所有类别的平均分类性能(即所有类别的AP值)的平均值,计算公式为
(6)
式中,(AP)i表示第i类的AP值,当预测框与真实框的重合度为0.5时,表示为mAP@0.5。本实验中的mAP@0.5涉及两个二分类问题的叠加,因此在推理过程中将n值取为2进行计算。
6)帧率,即每秒钟能够处理的帧数,单位为FPS (Frame Per Second),用于评估模型在实际任务中的检测速度,帧率越大,说明检测速度越快。
3.3 结果分析
3.3.1性能对比实验
本文将自建的数据集分别用在原网络的YOLOv8n与改进网络的Fire-YOLOv8n模型中进行训练,在同时训练200个epoch的情况下,得到mAP@0.5和F1变化曲线。由图6和图7可知,Fire-YOLOv8n模型的平均分类性能和F1得分曲线更加趋近于1,且在训练150个epoch后结果趋于稳定。
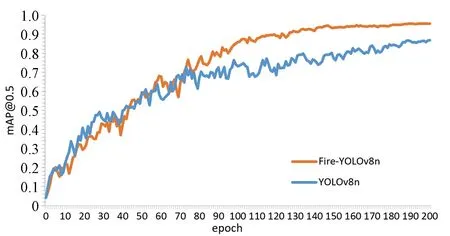
图6 模型改进前和改进后的mAP@0.5对比情况
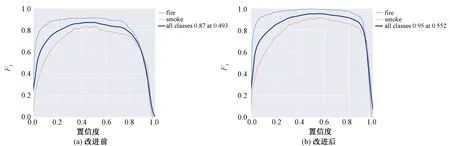
图7 模型改进前和改进后的F1变化趋势
3.3.2算法对比实验
为进一步验证改进算法与以往算法在火灾检测上的性能差异,本实验选择目标检测领域经典的SSD、YOLOv5、YOLOv7、YOLOv8、Fire SSD[22]和Fire-YOLO算法[23]进行对比实验,所有实验均在同一实验环境、同一数据集下进行,经各算法训练后的模型性能如表2所示。
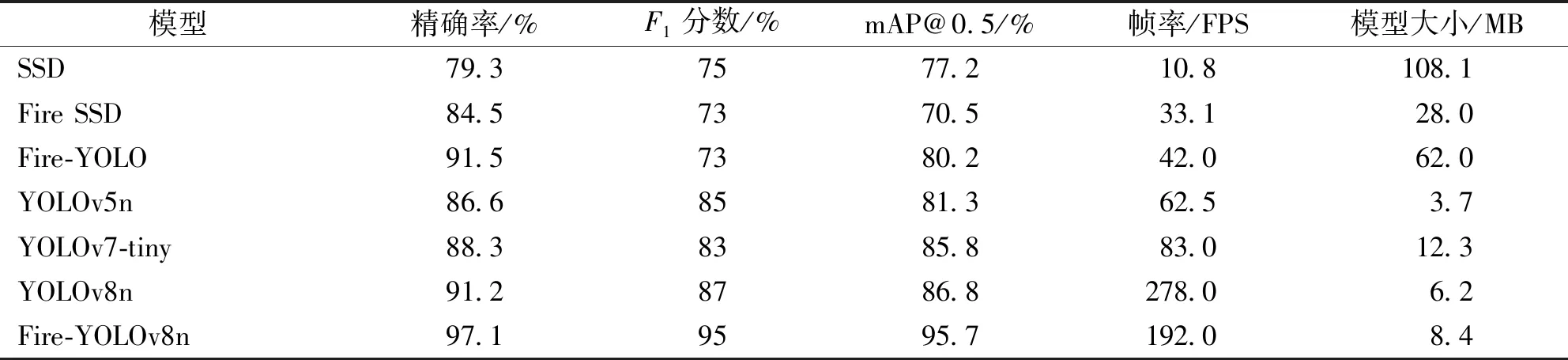
表2 不同模型的性能对比
由表2可知:相比以往改进的Fire SSD模型和Fire-YOLO模型,本文改进模型的mAP@0.5分别提高了36%和19%;相比传统的SSD算法,YOLO算法的整体性能有了显著提高,特别是在检测速度方面,YOLO目标检测算法可以在实时检测任务中进行快速部署;YOLOv8模型与之前发布的YOLOv5和YOLOv7轻量化模型相比,图像的检测速度分别提升了345%和235%;在模型的大小方面,本文改进模型的大小仅为8.4 MB,相比于SSD、Fire SSD、Fire-YOLO模型,可以很好地满足嵌入式设备对火焰检测模型轻量化的要求。
3.3.3消融实验
在实验后期阶段,为了验证采用不同改进策略对原始网络的影响程度,针对轻量化的YOLOv8n和YOLOv8s两个模型分别进行了4组消融实验,即增加小目标检测层、使用Focus层对图像进行切片操作、将特征提取模块改为BottleneckCSP、引入迁移学习,实验结果如表3和表4所示。在每组实验中,除了引用迁移学习策略时用到前期构建的样本数据集外,其余实验均在同一个烟火数据集和相同的训练参数下完成。

表3 不同改进策略对YOLOv8n模型的影响

表4 不同改进策略对YOLOv8s模型的影响
由表3可知:在网络中增加一个小目标检测层之后,原模型的各项性能均得到明显改善,mAP@0.5直接在原模型的基础上增长了5个百分点;在对模型采用样本数据集进行迁移学习之后,不仅mAP@0.5增长了2.7%,而且模型检测的精确率达到97.1%;在检测速度方面,由于将原来的3个目标检测层增加到4个,相应的网络层数有所增加,所以网络检测速度降低了,但仍然领先当下绝大部分的火灾检测模型。
在网络深度不变的情况下,本实验将网络宽度增加一倍,经训练后得到Fire-YOLOv8s模型。增加此模型是为了进一步考查网络的泛化性能,即在网络更复杂的情况下,通过添加以上4种策略是否仍然具备涨点的可能性。由表4可知:网络的整体性能与Fire-YOLOv8n相比得到进一步改善,该网络对火焰和烟雾的检测精确率达到97.2%,mAP@0.5达到96.1%。若将该模型部署到嵌入式设备中进行实时火灾检测,模型的大小、检测速度、平均分类性能等参考指标都达到较高水平。
3.3.4测试结果
相比于以往模型,该模型最大的优势体现在对类火的阳光、类烟的云层均能进行有效辨识。为了验证模型对复杂环境中的火焰和烟雾的检测效果,本文使用从网络上随机采集的多个场景图像在Fire-YOLOv8n模型中进行验证,结果如图8所示。

图8 不同场景下的检测结果
由输出结果可知:改进算法所生成的模型在烟火检测的准确度上有显著提高,而且在有环境干扰以及物体遮挡的情况下也能准确辨识火焰和烟雾的具体位置。
4 结论
将Fire-YOLOv8算法用于火灾的早期预警系统,不仅能检测出小火焰目标,还能有效区分类火、类烟等干扰信息。本文将该算法与其他算法进行对比实验,证明了该算法的先进性,结论如下:
1)改进后的算法可以通过火灾的蔓延趋势及烟雾的变化形态不断地学习,迭代网络参数,优化网络性能;融合烟雾特征的火灾检测模型能对遮挡住的早期火焰目标进行火灾识别,降低了原来由单一目标检测造成的漏检率;在网络中加入大量负样本图像进行学习后,生成的模型在实际任务中能够有效过滤灯光、云彩等类火类烟的实际场景信息,降低了由相似颜色特征造成的错检率。
2)通过增加更小的目标检测层,解决了小目标难以提取的难题;特征提取使用BottleneckCSP模块、运用样本数据集进行迁移学习等方法,使模型参数进一步减少,能在各种嵌入式设备中进行快速部署。
3)实验表明,改进后的轻量化模型Fire-YOLOv8n的检测精确率达到97.1%,F1分数达到95%,mAP@0.5达到95.7%,检测速度达到192 FPS,模型大小仅为8.4 MB。基于以上指标,该模型能满足在开放式的环境下进行实时检测的要求。
另外,由于不同材料在燃烧过程中产生的火焰和烟雾的颜色特征存在差异,可能造成模型的检测精度不理想,如塑料、石油等化工原料。我们将进一步研究颜色、形状、纹理3种特征间的关系,并通过拼接实验来提升算法性能。
