基于储备池计算网络的小样本图像分类方法
2023-10-13王彬兰海俞辉郭杰龙魏宪
王彬, 兰海, 俞辉,3, 郭杰龙,3, 魏宪,3*
(1.福州大学 先进制造学院, 福建 泉州 362200;2.中国科学院 福建物质结构研究所, 福建 福州 350002;3.中国福建光电信息科学与技术创新实验室(闽都创新实验室), 福建 福州 350108)
1 引言
近年来,深度学习已经广泛应用于各行各业[1-3],其凭借大规模数据大幅度提高了图像分类[4]、语义分割[5]、目标检测[6]等任务的精度,在计算机视觉领域取得了巨大的成功。然而,现实场景并不具备获得大规模可训练数据的条件,使深度学习方法容易产生过拟合、低泛化性等问题。为了能够在数据稀缺的场景下进行学习,小样本学习[7-9]成为深度学习的一个重要研究方向。
小样本学习方法通常可以分为两类:基于数据增强的方法[10]和基于学习策略的方法。第一类方法旨在生成新的样本来扩充原始样本空间或对特征空间进行增强;第二类方法可以细分为基于模型微调[11]的方法、基于元学习[12]的方法等。目前小样本学习的主要问题可以总结为特征提取网络提取的特征判别性不够充分、网络容易过拟合,模型泛化能力不足等。一些基于注意力机制的方法[13-15]被提出来整合特征信息以优化上述问题,但此类方法在领域迁移[16]等问题上仍有优化空间。
在解决小样本问题时需要关注两方面的问题:(1)更好地提取特征来指导分类;(2)缓解过拟合,提高模型泛化能力,如进行数据增强等操作。考虑到人脑是一种天然的小样本学习范式,引入类脑知识或许有助于走出小样本学习的困境,再结合过拟合问题,促使本文应用一种类脑模型——储备池计算(Reservoir Computing, RC)[17-18]来完成小样本学习任务。因为RC依靠内部复杂动力学特性而天然具有一定抗过拟合能力,能够有效表达复杂的输入信息,但在计算机视觉任务上几乎没有应用。
针对上述问题,本文提出一种基于储备池计算的小样本图像分类方法(Reservoir Computing Based Network for Few-shot Image Classification,RCFIC),将特征提取网络提取的特征输入特征增强模块(由储备池模块和基于储备池的注意力机制构成)分别进行通道级和像素级增强,然后进行特征融合得到增强特征。同时,在元学习阶段使用余弦相似度分类器,联合特征增强模块促使网络提取的特征分布具有高类间方差、低类内方差的特征,从而更好地指导分类。本文方法在公开常用的小样本图像分类数据集上的实验均达到了具有竞争力的分类精度,表明所提模型和方法具有较强的泛化能力,能够使网络学习更具判别性的特征,缓解过拟合问题,增强模型的性能。
2 基于储备池计算的小样本图像分类方法
2.1 问题定义
由于小样本学习的任务都基于少量有标签数据(称为新类或目标数据域),而少量数据难以学习到真实的数据模式,容易遇到过拟合问题。因此,一般会引入一个含有丰富标注样本(类别与新类互斥)的辅助数据集(称为基类)以帮助模型学习先验知识,然后再利用这些先验知识以在目标数据域上获得更好的任务表现。
小样本学习通常以元任务的方式进行训练和评估,每个元任务都以N-way K-shot方法获得,即每个元任务都包括N种类别的数据,每类数据只包含K个有标签的样本,同时从每类数据中抽取q个样本作为预测样本。有标签样本构成的数据集称为支持集DS,预测样本构成的数据集称为查询集DQ。即:
其中:xi和yi分别表示样本及其对应的标签类别,N表示类别数量,K为支持集中每类样本的数量,q表示查询集中每类预测样本的数量。
模型在支持集上学习后在测试集新类中采样大量的元任务来获得这些任务的平均准确率,从而评估模型在小样本学习任务上的分类性能和泛化能力。
2.2 算法框架
基于储备池计算的小样本学习模型框架如图1所示。该模型主要由3个模块组成:特征提取模块、基于储备池的特征增强模块和分类器模块。首先,通过特征提取模块f(·|θ)(卷积网络,如ResNet12和ResNet18等;θ表示该模块的可学习参数)对输入图像进行特征提取。然后,将提取的特征输入到特征增强模块。特征增强模块由储备池通道级特征增强模块和基于储备池的注意力像素级特征增强模块组成,前者对输入特征进行高维表示以提取重要的通道信息,后者对输入特征的重要像素信息进行提取。最后,将两部分特征进行融合后输出到分类器模块C(·|Wcls)(Wcls表示分类权重矩阵)得到最终的分类结果。
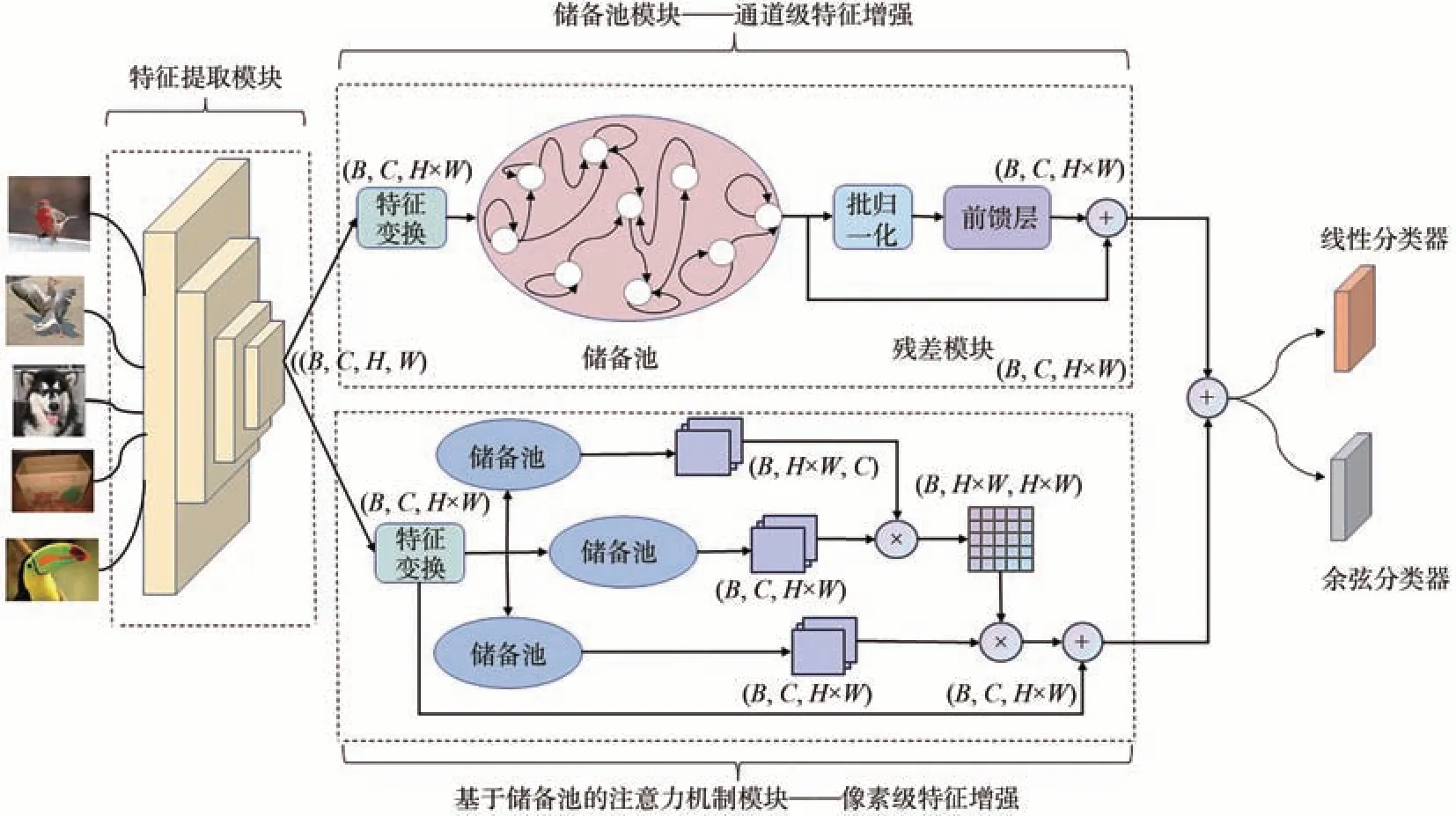
图1 基于储备池计算的小样本图像分类模型框架Fig.1 Framework of few-shot image classification model based on reservoir computing
2.3 训练方法
本文使用两阶段训练策略,如图2所示。

图2 基于储备池计算的训练方法流程图Fig.2 Flowchart of the training method based on RC
第一阶段为模型预训练。将小样本数据集的训练集按照合适的比例划分为新的训练集和验证集,模型在新划分的数据集上以传统图像分类的方式进行训练,分类器使用线性分类器,最后得到预训练模型Modelpre。该阶段使模型能够充分学习基类的特征,为接下来将学习到的知识迁移到小样本学习任务上做准备,能够有效缓解过拟合问题。
第二阶段为基于模型微调的小样本图像分类阶段。将Modelpre的分类器替换为余弦分类器,微调学习率等参数,再在原始的小样本数据集上以N-wayK-shot的元学习方式进行模型训练和评估。
2.4 特征提取模块
随着卷积网络宽度和深度的增加,网络对图像信息的提取更加充分。但由于数据样本较少带来的过拟合问题,使得在小样本学习任务中网络不能随意加深加宽,因此小样本学习领域常使用ResNet-12和ResNet-18作为特征提取网络。本文也使用这两个小样本学习任务中常用的主干网络作为特征提取模块。
通过特征提取模块f(·|θ)提取输入图像x的特征向量z1,如式(3)所示:
其中:C为特征图的通道数,H和W分别为特征图的高和宽。
2.5 特征增强模块
2.5.1 半全连接的储备池内部拓扑结构
储备池的强大性能源于其内部复杂的动力学特性,表现为储备池内部神经元之间的连接方式(连接矩阵Wres∈R()M,M,M为神经元个数),即储备池内部拓扑结构。用储备池来处理复杂的视觉信息时,需要设计一个相匹配的拓扑结构来提升储备池的性能。
本文的Wres不使用传统的随机方法生成,也不同于经典的延迟线结构、循环结构以及对称结构[19]等拓扑结构。本文提出了一种半全连接的拓扑结构,生成方式如下:
首先生成一个M·M的矩阵Wres,使其元素全为r1∈(0,1]。然后,将第一行最后一个元素和从第二行第一个元素开始的对角线元素设为r2∈(0,1],即:
式中的下标代表元素在Wres中的位置。随后从矩阵第一个元素开始,按从左到右从上往下的顺序,每隔p个元素将其值设为r3∈(0,1],当要设置的元素超出矩阵范围时停止。对于网络的随机性,本文随机选择1/4的元素及其对称位置的元素设置为0。整个连接矩阵中1/2的元素为0,其余元素为r1、r2和r3。
为了储备池能够稳定运行,Wres的谱半径ρ(Wres)应该被约束到1,即对Wres进行如式(5)所示的变换:
其中:α∈(0,1)为缩放尺度因子,|λ|max为变换前的Wres的特征值绝对值中的最大值(谱半径)。相较于其他几种经典拓扑结构,所提拓扑结构具有较好的信息流动能力和更丰富的动力学特征,更适合处理复杂的视觉数据。
2.5.2 储备池模块
储备池模块主要由半全连接拓扑结构的储备池和残差模块组成,用来提取输入特征的重要通道信息,进行通道级特征增强。在特征输入储备池之前,需要用一个线性层l1(·)对特征z1进行维度变换,使其变为适应储备池输入的维度,即z2=l1(z1)∈R(C,D),其中D=H·W,代表线性层的输出维度,也是储备池输入的维度。由于储备池计算的传统优势在于处理时序数据,而小样本图像数据不具有此种关系,因此,本文将z2按照通道维度进行划分得到了C个1·D维的数据zt∈R(1,D),将其视为C个时刻的输入。那么储备池内部神经元状态更新方程如式(6)所示:
其中:t=0,1,…,C-1。Win是输入特征到储备池的连接矩阵,其连接权重按照高斯分布生成。Wres按照本文所提的半全连接拓扑结构的方法生成。这两个矩阵按照各自的规律生成后固定不变,不需要学习。zt+1表示第t+1个输入。st+1表示第t+1个输入时储备池内部神经元的状态。F(·)表示激活函数。
储备池每个时刻的输出yt+1和整个储备池的输出yr根据式(7)和式(8)计算:
其中,”;”代表矩阵拼接操作;Wout代表储备池输出连接矩阵,本文使用一个可学习的线性层来逼近该矩阵。
储备池后接一个残差模块,残差模块内含一个批归一化层(Batch Normalization, BN)和前馈层(Feed-Forward, FF)以增加网络信息流通能力,防止网络退化。储备池通道级特征增强模块的输出yRC如式(9)所示:
2.5.3 基于储备池的注意力机制模块
在小样本学习领域,注意力机制常被用来整合特征信息。本文提出了一种新颖的基于储备池网络的注意力机制生成方式。该模块通过储备池生成新的特征图Q、K和V,然后根据式(10)计算输出像素级增强后的特征yAttn:
与yRC融合后得到最终的增强特征z3:
其中,β1、β2和β3均为可学习的标量参数。
2.6 分类器模块
增强特征z3被送入分类器计算输出最后的分类结果y:
第一阶段使用线性分类器:
第二阶段使用余弦分类器:
其中,τ是一个可学习的标量参数。
余弦分类器中的l2归一化操作促使网络提取输入图像最具代表性的特征。同时,余弦分类器结合特征增强模块使得分类前的特征分布呈现低类内方差、高类间方差的特点。储备池与余弦分类器相结合,能够更好地指导分类,提高小样本任务分类精度和模型的泛化能力。
3 实验结果及分析
3.1 数据集和实验环境
本文对所提方法和模型在Cifar-FS[20]、FC100[21]和Mini-ImageNet[22]数据集上进行了常规小样本图像分类实验。为了验证模型的泛化性能,设置了跨域场景,在Mini-ImageNet上训练模型后,在CUB-200[23]数据集上测试模型性能。
Cifar-FS和FC100均源自Cifar 100数据集。前者共包含100个类,每类有600张32×32的图像,被划分为训练集(64类)、验证集(16类)和测试集(20类);后者共包含100个类,每类有600张32×32图像。但FC100是按照超类进行划分的。FC100共20个超类,其中训练集12个超类(60类),验证集4个超类(20类),测试集4个超类(20类)。
Mini-ImageNet由ImageNet[24]数据集中选取的100个类构成,每个类别包含600张84×84的图像,被划分为训练集(64类)、验证集(16类)和测试集(20类)。
CUB-200是细粒度图像数据集,共包含200种鸟类的11 788张84×84图像,被划分为训练集(100类)、验证集(50类)和测试集(50类)。
实验配置为GTX2080Ti显卡、Linux操作系统、PyTorch深度学习框架。实验在小样本任务阶段通过5-way 1-shot和5-way 5-shot方式采样任务,最终准确率是1 500个元任务的平均分类精度。
3.2 实验结果
3.2.1 小样本图像分类
首先在公开常用的小样本数据集上进行了图像分类实验,所提方法和目前先进的小样本学习方法的实验结果对比如表1和表2所示(加粗数字表示最优结果)。从表1和表2中可以看出,与主流方法相比,以ResNet-12和ResNet-18为主干网络的所提方法均取得了最好的分类结果。

表1 Cifar-FS数据集和FC100数据集上的分类精度Tab.1 Classification accuracy on Cifar-FS dataset and FC100 dataset %
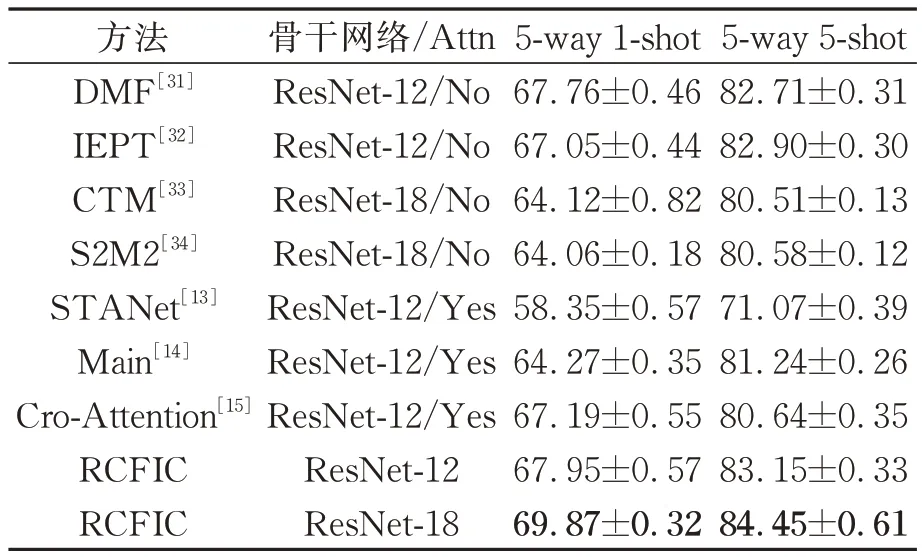
表2 在Mini-ImageNet数据集上的分类精度Tab.2 Classification accuracy on Mini-ImageNet dataset %
在Cifar-FS数据集上,5-way 1-shot和5-way 5-shot设置下的最优精度均是在以ResNet-18为特征提取网络时取得,分别为79.44%和89.86%,分别比次优网络MetaQAD高3.61%和1.07%。
在FC100数据集上,5-way 1-shot和5-way 5-shot设置下的最优精度均是在以ResNet-18为特征提取网路时取得,分别为50.49%和66.52%,分别比次优网络TPMN高3.56%和3.26%。
在Mini-ImageNet数据集上,在5-way 1-shot设置下,所提方法在ResNet-18特征提取网络下的分类准确率达到了69.87%,比次优方法DMF提高了2.11%;5-way 5-shot设置下的最高精度为84.45%,比次优方法IEPT提高了1.55%。
同时,所提方法在3个数据集上的分类精度比其他基于注意力机制的小样本图像分类方法高约2%。
实验结果说明所提方法能够有效对特征进行增强以提高分类准确率,能够有效处理小样本图像分类任务。
3.2.2 领域迁移
现实世界中基类和新类的数据模式差距一般都比较大,使得更加符合真实场景的领域迁移场景成为小样本学习领域的研究重点之一。领域迁移问题要求模型具有良好的泛化能力。为了验证所提方法的泛化性,本文设置了此类领域转移的场景:实验使用ResNet-12和ResNet-18作为特征提取的骨干网络,先在粗粒度数据集Mini-ImageNet上训练模型,然后再在细粒度数据集CUB-200上测试模型。
实验结果如表3所示(加粗数字表示最优结果)。在5-way 1-shot和5-way 5-shot两种设置下,所提方法在使用ResNet-18作为特征提取网络时均达到最优,分别为49.24%和69.07%,分别超过次优方法LFWT 1.77%和2.09%。

表3 领域迁移实验Tab.3 Cross-domain %
实验说明所提方法针对领域迁移问题有良好的表现,模型的泛化能力强。
3.3 消融实验
3.3.1 特征增强模块的影响
所提方法的特征增强模块由储存池模块和基于储存池的注意力机制模块组成。为了探究所提模块的必要性以及对结果产生的影响,以ResNet-18为特征提取网络在Cifar-FS数据集上进行了不使用特征增强模块(No Enhancement,NE)、只使用储备池模块(Only Reservoir,OR)和只使用基于储备池的注意力机制模块(Only Attention,OA)的消融实验。
实验结果如表4所示(加粗数字表示最优结果)。可以看到使用了特征增强模块的分类精度在两种设置下都高于不使用特征增强模块的网络至少3%。同时,当储备池模块和基于储备池的注意力模块联合使用时,分类精度比其单独使用至少高约0.78%。该消融实验说明了所提特征增强模块的有效性和两个模块联合使用的必要性。
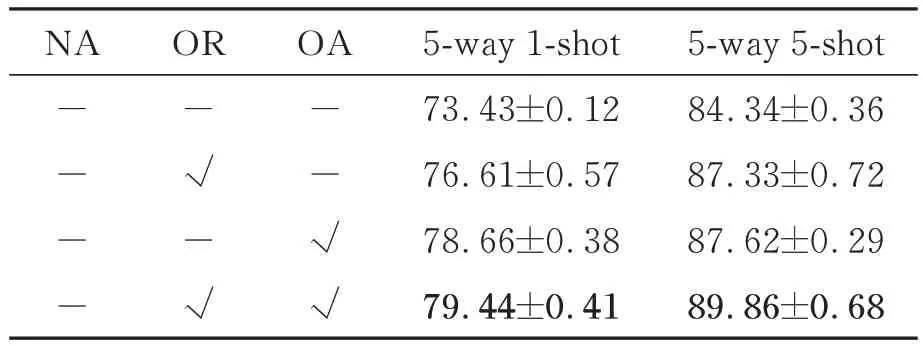
表4 特征增强模块的影响(以对Cifar-FS数据集的分类精度为例)Tab.4 Effect of feature enhancement module (taking classification accuracies on Cifar-FS for example) %
3.3.2 不同注意力机制生成方式的影响
为了说明所提方法相比于传统的线性变换或卷积操生成注意力机制的优势,在Mini-ImageNet数据集上以ResNet-18为特征提取网络进行了小样本图像分类实验。实验结果如表5所示(加粗数字表示最优结果)。可以看出使用了注意力机制比没有使用时分类效果好,因为注意力机制整合突出了重要特征信息。所提生成注意力机制方法的精度在5-way 1-shot和5-way 5-shot设置下分别达到69.87%和84.45%,优于另外两种方法至少2.12%,说明了储备池生成方法的有效性。

表5 不同注意力生成方式在Mini-ImageNet上的精度Tab.5 Classification accuracy of attention mechanisms generated by different methods on Mini-ImageNet dataset %
3.3.3 特征分布可视化
在Cifar-FS数据集上,以ResNet-18为特征提取网络对查询集的特征进行提取(q=30,共5×30张查询图像)。以不同的注意力机制进行增强后,采用t-Distributed Stochastic Neighbor Embedding(t-SNE)[38]对特征分布做可视化。
如图3所示,所提方法对特征进行增强后,特征分布相较于传统的线性变换和卷积操作生成方式而言,具有更大的类间方差和更小的类内方差,使得分类器能够更好地分类,提升小样本任务的分类精度。

图3 不同方式生成注意力机制对特征进行增强后的特征分布Fig.3 Feature distributions after the enhancement by attention mechanisms generated in different ways
3.3.4 可学习标量参数的影响
可学习标量参数主要用来进行缩放,主要体现在公式(11)的中的β2和β3、公式(14)中的τ。β2和β3主要用于权衡通道级增强模块的输出和像素级增强模块的输出对最终输出的贡献程度。因为余弦相似度的范围被固定为[-1, 1],所以用τ来控制分类器中softmax算子产生的概率分布的峰值。在Cifar-FS、Mini-ImageNet数据集上以ResNet-18为特征提取网络进行了小样本图像分类实验,讨论了是否使用β2和β3以及对τ进行不同初始化选择的影响。
如表6所示(加粗数字表示最优结果),使用β2和β3的效果优于未使用时,因为这两个参数学习如何衡量通道级增强模块和像素级增强模块的重要性比例,相较于未使用的情况更合理。同时,这两个参数都被初始化为0~1之间的数值。参数τ用来控制softmax算子的峰值,其不同初始化值对实验结果的影响如图4所示。可以发现其初始值为4时,在Cifar-FS和Mini-ImageNet数据集上的最终分类结果都比其他初始化值好,因此所做其他实验中该参数的初始值设置为4。

表6 是否使用β1、β2的影响Tab.6 Effect of whether using β1 and β2 %

图4 不同的τ初始值对分类准确度的影响Fig.4 Effect of different initial values of τ on classification accuracy
3.3.5 不同储备池内部拓扑结构的影响
储备池内部拓扑结构使其具有丰富的动力学特性来处理复杂的数据。为了直观说明所提拓扑结构的优势,在Mini-ImageNet数据集上以ResNet-18为特征提取网络进行了小样本图像分类实验。
实验结果如表7所示(加粗数字表示最优结果),所提拓扑结构在5-way 1-shot和5-way 5-shot两种设置下的分类精度均优于其他拓扑结构1%~3%,说明所提拓扑结构具有更丰富动力学特性来处理复杂信息和缓解过拟合,能够增强模型的泛化能力。

表7 不同储备池内部拓扑结构的影响Tab.7 Effect of different internal topologies of RC %
4 结论
本文提出了一种基于储备池计算的小样本图像分类方法,通过储备池模块和基于储备池模块的注意力机制对特征进行通道级和像素级增强,联合余弦分类器使得网络提取的特征分布具有高类间方差、低类内方差的特性。相较于目前流行的小样本图像分类方法,所提方法在标准的小样本图像分类任务和跨域转移场景下的分类精度至少分别高1.07%和1.77%,具有较强的泛化性。本文方法依赖于储备池内部动力学特性来缓解过拟合、增强模型泛化性能,然而其内在机制缺乏可解释性,这也将是下一步的研究重点。
