多类场景下无人机航拍视频烟雾检测算法
2023-10-13王殿伟赵文博许志杰
王殿伟,赵文博,房 杰,许志杰
(1.西安邮电大学 通信与信息工程学院,西安 710121; 2.哈德斯菲尔德大学 计算机与工程学院,哈德斯菲尔德HD1 3DH,英国)
烟雾是火灾的主要伴生现象,具有更明显的可观测性[1],因此开展烟雾智能检测对消防减灾具有重要的意义。无人机具有机动性强、可视范围广和行进速度快等特点[2-3],在烟雾检测领域中有明显的优势。因此,开展无人机航拍视频烟雾检测技术研究对于消防减灾具有重要的意义,已经成为计算机视觉领域的一个新的研究热点[4]。
传统烟雾检测算法大多是围绕着手工提取各种烟雾特征进行研究,检测精度不高。而卷积神经网络因具有强大的特征表征能力,已被广泛应用于烟雾检测领域。文献[5-6]使用YOLO系列算法进行烟雾检测,但在多类场景下准确率不高。文献[7]提出了烟雾检测和分割框架;文献[8]提出了两级烟雾检测算法,都提升了算法精度,但增加了计算量,导致算法检测速度慢。文献[9]提出一种新的注意机制模块,但训练数据过少导致算法性能不佳。为此,文献[10-11]利用人工合成烟雾图像解决缺乏训练数据的问题,但人工合成的烟雾图像真实性差导致算法鲁棒性低。文献[12]提出火焰和烟雾统一检测的方法;文献[13]提出基于深度可分离卷积神经网络的烟雾检测算法;文献[14]提出YdUaVa颜色模型和改进的MobileNetV3网络结构,但在多类场景下烟雾检测效果都不好。文献[15]提出的YOLOv4算法和文献[16]提出的改进的YOLOv5算法都对烟雾检测算法轻量化做出了贡献;文献[17]提出的SparseR-CNN算法在应用于烟雾检测领域时明显提升了准确率,但算法实时性不高。文献[18]提出YOLOx目标检测算法,在YOLOv3[19]的基础上新增了Decoupled Head和Anchor-free等结构,算法精确度显著提升,但在应用于无人机视角下的多类场景时,检测准确率降低。
针对以上算法出现的训练数据少、场景种类单一和检测精度低等问题,本文建立了一个多类场景下的无人机航拍烟雾数据集(UAV smoke dataset,USD),从注意力机制、双向特征融合模块和损失函数3个角度出发改进YOLOx算法,提升了算法在面对多类场景下无人机航拍视频的烟雾检测精度,并具有实时检测的能力。
1 无人机航拍烟雾数据集USD的建立
现有的无人机视频烟雾检测算法使用的训练数据集多为普通视角下的单一场景烟雾数据集,这导致训练出的网络模型不能适用于多类场景下的无人机烟雾检测任务。目前最常使用的公共数据集有两个:1)上海师范大学袁非牛团队公布的烟雾图像和非烟雾图像数据集VSD[20],该数据集包含了6 323张各种颜色的烟雾图像,但该数据集包含的烟雾图像质量较差,分辨率低,且烟雾目标在整幅图像中占据了较大的面积,对网络模型的检测性能有很大影响;2)韩国启明大学计算机视觉与模式识别实验室(CVPR)联合美国NIST火灾研究实验室以及Bilkent信号处理小组公开的烟雾数据集KMU[21],其中共包含了11段有烟视频和9段非烟雾视频,加入了大量白色灯光和自然天气下的云等负样本信息,但该数据集的视频分辨率较低,且只包含森林和室内两种场景,很难训练出具有较强泛化能力的网络。
数据集的建立应包含图像信息多和场景覆盖性广两个方面,因此采用自己拍摄和网络收集等方法,创建了一个新的多类场景下的无人机航拍烟雾数据集,该数据集包含了81个无人机烟雾视频,对这81个视频进行每隔100帧提取一次图像,共提取30 000张无人机烟雾图像,并使用LabelImg软件对30 000张图像进行标注,标注方法为最大外接矩形框标注。数据集中所有视频都是由无人机在高空50~500 m之间拍摄完成,包含了森林、农场、居民楼、学校、工厂和海岸等19种场景,且视频的分辨率大小都为1 280×720,烟雾区域更加清晰,见表1。部分场景的烟雾图像见图1。
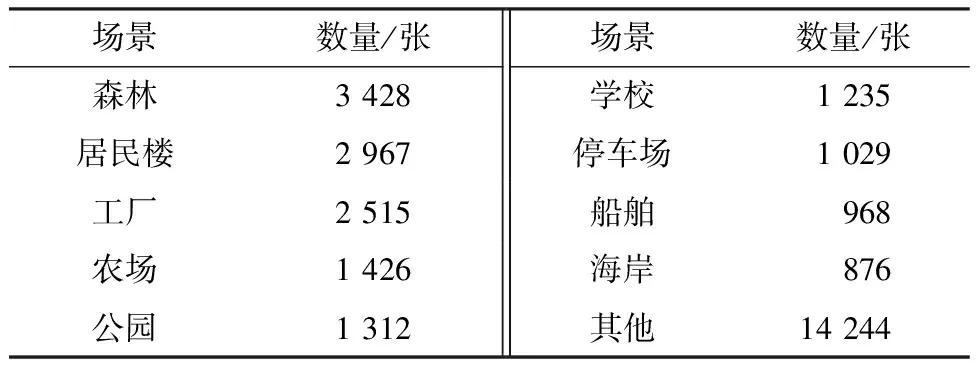
表1 USD数据集中的场景类别
由表1可以看出,在USD烟雾数据集中,森林、居民楼和工厂3个场景的图像占比最多,十分符合现实情况。相比于普通视角下的烟雾数据集,本文自建的USD烟雾数据集,包含场景多、数量多、分辨率高,图像中的烟雾形状更加多变,烟雾特征也更加丰富,与算法的应用场景非常贴切。
2 改进YOLOx的无人机视频烟雾检测算法
2.1 网络结构
为了更好地实现在多类场景下对无人机航拍视频的烟雾检测,设计了一个基于YOLOx-s的轻量级的端到端烟雾检测网络,采用改进的注意力机制模块和多尺度特征融合模块降低场景信息对烟雾检测准确率的影响,并提升网络对小目标烟雾的检测能力。网络结构见图2。

图2 本文算法网络模型
由图2可知,本文的烟雾检测网络主要由4部分组成:1)特征提取网络;2)注意力机制模块;3)双向特征融合模块(bidirectional feature fusion module);4)预测网络。特征提取网络由4个CBS单元(卷积层+BN层+Silu激活函数)、1个SPP单元、1个Focus单元和3个CSP结构组成。预测网络由Decoupled Head模块以及Transpose结构组成。为了提高本算法对小目标烟雾的检测能力,本文提出的双向特征融合模块在多尺度特征融合的基础上加入了一条额外支路,该支路能使FPN结构学习到更多的小目标烟雾特征,从而增强网络对小目标烟雾的学习能力。为了解决多类场景下算法检测准确率低的问题,引入改进的烟雾协调注意力(smoke coordinate attention,SCA)[22],该模块是一种适用于轻量级网络的烟雾注意力机制,能使网络更加关注特征图中的烟雾区域,并对不同通道的烟雾特征以及不同大小的烟雾特征进行重新加权计算。最后本文引入了Focal-EIOU[23]损失函数,解决了正负样本不平衡的问题以及预测框和真实框不相交时无法反映两个框的距离远近以及重合度大小的问题。
2.1.1 注意力机制模块
鉴于多类场景下无人机烟雾视频图像的复杂性,本文增加改进的注意力机制模块来提升算法对烟雾特征的提取能力,其结构见图3(a)。首先,利用2个不同方向的全局平均池化生成包含特征通道信息的描述符,经过1个拼接操作和1个共享的卷积层,再经过1个批量归一化处理,得到的特征图最终经过1个全连接层和Sigmoid激活函数。在该注意力机制模块中,本文将烟雾的位置信息嵌入到通道注意力中,并且沿着高度和宽度2个方向生成一对特征图,分别为方向感知图和位置感知图,最终将这一对特征图加权融合到原始输入特征图中,其加权公式为
(1)
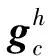
(2)
(3)
式中:σ为Sigmoid函数;Fh和Fw分别为1×1的卷积变换;fh和fw为输入图像在高度和宽度上生成的注意力特征图,注意力生成公式为
(4)
式中:f为生成的注意力特征图;δ为非线性激活函数;xc为大小为H×W×C的输入特征图;F1为批量归一化操作。
2.1.2 双向特征融合模块
在YOLOx-s的网络中,特征融合模块采用的是FPN+PAN[24]结构,该结构融合了80×80、40×40和20×20三种不同大小的特征图。为了增强网络对烟雾小目标的检测能力,适应无人机视角下火灾早期烟雾主要为小目标的实际情况,受BiFPN[25]结构的启发,本文设计了一个额外的融合支路加入到多尺度特征融合模块,其结构见图3(b)。双向特征融合加权计算为
(5)
(6)
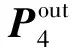
在双向特征融合模块中,本文在PAN结构的N4层额外加入了原始的40×40大小的特征图,新加入的特征与P4层的输出和N3层经过下采样得到的特征共同输入到N4层,随后再经过下采样输入到N5层。可以看出,这使得N5层相比原来获得了更多的小目标特征,并且新加入的注意力机制模块将不同层和不同大小的烟雾特征进行重新分配权重,再将得到的烟雾特征连接到一起,最终输入到Decoupled Head模块进行分类和检测。
2.1.3 损失函数
在无人机拍摄的烟雾视频图像中,烟雾所占图像比例远小于其他负样本信息所占的比例,这就造成了算法训练过程中存在正负样本不平衡的问题。为此,本文引入LFocal-EIOU[23]损失函数,其中LFocal损失函数可以解决训练过程中正负样本不平衡的问题。同时,在烟雾图像中,烟雾的形状多变且不规则,可能导致模型的真实框和预测框不相交的问题,为了解决这一问题,本文在计算IOU[26]损失时引入LEIOU损失函数。该损失函数考虑了预测框和真实框的重叠面积、中心点距离、长宽边长真实差,可以解决预测框和真实框不相交时无法反映两个框的距离远近以及重合度大小的问题。LFocal-EIOU损失函数计算步骤为
(7)
式中:γ为控制异常值抑制程度的参数;IIOU为真实框和预测框的交并比;LIOU为IOU损失;LEIOU为EIOU损失,其中IIOU和LEIOU损失计算为
(8)
LEIOU=LIOU+Ldis+Lasp
(9)
(10)
式中:A和B分别为预测框和真实框;LIOU、Ldis和Lasp分别为IIOU损失、中心距离损失和宽高损失;ρ是预测框和真实框中心点间的欧氏距离;b和bgt分别为预测框和真实框的中心点;w和wgt分别为预测框和真实框的宽度;h和hgt分别为预测框和真实框的高度;cw和ch分别为两个框的最小外接框的宽度和高度。
3 实验与结果分析
3.1 实验平台、参数设置与评价指标
本文算法研究的硬件平台为CPU(Intel(R) Core(TM) i7-12700K 3.61 GHz),GPU(Nvidia Titan XP),CUDA版本为11.1,实验环境为Python3.7和PyTorch框架1.8.1版本。无人机型号为大疆精灵4 Pro,最大飞行高度6 000 m,拍摄视频和照片的最大分辨率为4 000×3 000。
本文使用自建的多类场景无人机航拍烟雾视频图像数据集USD作为训练数据集,按照8∶1∶1的比例随机选取了其中24 000张图片作为训练集,3 000张图片作为验证集,3 000张图片作为测试集。训练开始时,使用多尺度缩放将原始1 280×720大小的图像缩小到640×640大小的图像并作为输入,训练过程中采用了随机梯度下降法(stochastic gradient descent,SGD)。经过实验,当Batch size设置为8,初始学习率设置为0.01,余弦衰减权重系数设置为0.000 5时,得到的模型为最优。本文共训练了300个epoch,其中每10个epoch进行一次验证,训练总耗时52 h 34 min,最终模型大小为70.24 MB。
本文使用准确率P(precision)、召回率R(recall)、类别精度A(average precision)作为检测算法有效性的评价指标,为了更进一步的评价本文算法的适用性,另加入每秒检测帧数FFPS(frames per second)作为参考对比。
3.2 对比实验及分析
本文选用USD烟雾数据集中的24 000张和3 000张分别用作本文算法的训练集和测试集A。为了验证本文算法的泛化性,利用网络收集的方法额外建立了1个普通视角下的测试集B,并用现有的2个公开数据集制作了测试集C和测试集D。测试集B包含3 864张普通视角下的烟雾图像,测试集C包含袁非牛团队公开的VSD[20]烟雾数据集中的2 000张普通烟雾图像,测试集D包含从CVPR实验室联合NIST火灾研究实验室火灾研究部以及Bilkent信号处理小组公开的KMU[21]烟雾数据集中提取的1 000张烟雾图像。
本文将所提算法在自建烟雾数据集以及2个经典烟雾数据集上进行测试,为了验证本文自建烟雾数据集的有效性和本文所提算法在多类场景下无人机视频烟雾检测的优势,本文选用YOLOv4[15]、YOLOv5-s[16]、SparseR-CNN[17]3种经典的目标检测算法作对照实验,另选用最新的烟雾检测模型DeepSmoke[7]进行对比实验。为了保证实验环境的一致性,所有算法均在相同的实验环境下运行实现,实验结果见表2。
由表2可以看出,在VSD[20]和KMU[21]等公开数据集上,场景种类少,图像复杂度不高,本文算法取得了96%以上的准确率,相比于YOLOv4、YOLOV5-s和DeepSmoke算法,本文算法在准确率、召回率和类别精度都有很大的领先。在自建的USD烟雾数据集中,由于该数据集包含的无人机视角烟雾场景多,烟雾特征更加复杂,导致所有算法均出现了准确率降低的现象,但本文所提算法对比于原算法YOLOx-s仍然提升了2.7%的准确率和2.5%的精度,并且FFPS达到了73.6,表明本文算法在面对多类场景下的无人机航拍烟雾检测时,比原算法YOLOx-s和其他现有算法更有优势。本文算法的检测准确率略低于SparseR-CNN算法,但SparseR-CNN算法的FFPS只有6.2帧/s,明显达不到实时检测的要求。另外,本文展示了本文算法在USD烟雾数据集、测试集B、测试集C和测试集D上的部分可视化结果,见图4和图5。

图4 本文算法在USD数据集上的部分检测结果

图5 本文算法在不同测试集上的部分检测结果
由图4的可视化检测结果可以看出,本文算法在面对不同场景下的无人机烟雾检测任务时,都能以最大框准确地标示出图像中烟雾区域外沿,证明了本文算法的有效性。从图5的可视化检测结果可以看出,在测试集B中,烟雾像素占据整幅图像近一半的像素,导致烟雾特征过于明显;在测试集C中,图像主要由像素大小为100×100的烟雾块组成,没有复杂的场景信息干扰;在测试集D中,该测试集中出现了雾天、淡烟和大量的天空区域,烟雾特征不明显,导致算法出现了漏检和误检现象,本文列出了不同算法在测试集D中(a)、(b)两组场景中漏检和误检的可视化结果,见图6。

图6 不同算法在测试集D上的漏检和误检结果
由图6可以看出,在图6(a)和图6(b)两组场景的可视化结果中,不同算法都出现了漏检和误检现象(图中烟雾区域由红框标出)。在图6(a)场景中,出现了有雾天气,烟雾所占像素小且出现了颜色失真,导致所有算法都出现了漏检现象;在图6(b)场景中,出现了大量含云的天空区域,导致SparseR-CNN算法出现了误检现象,YOLOv5-s算法和YOLOx-s算法都出现了漏检现象,本文算法虽然准确地检测出了烟雾区域,但同样也误检了天空中含云的区域,这是因为本文所用训练集USD中的图像主要为无人机对地视角,包含多云的场景较少,导致算法模型对假烟物体敏感,出现误检现象。
为了评价本算法和其他算法对不同场景无人机烟雾视频的检测效果,选取USD数据集中5个不同场景的无人机烟雾视频,每个场景包含2 000帧的连续视频图像,对共计10 000帧的烟雾和非烟雾视频进行测试,测试结果见表3。可以看出,本文算法检测准确率对比YOLOx-s算法在不同场景下都取得了提升。对比DeepSmoke算法、YOLOv5-s算法和YOLOv4s算法,本文算法在5个不同场景下都取得了最高的检测准确率,且平均准确率达到了92.3%以上。
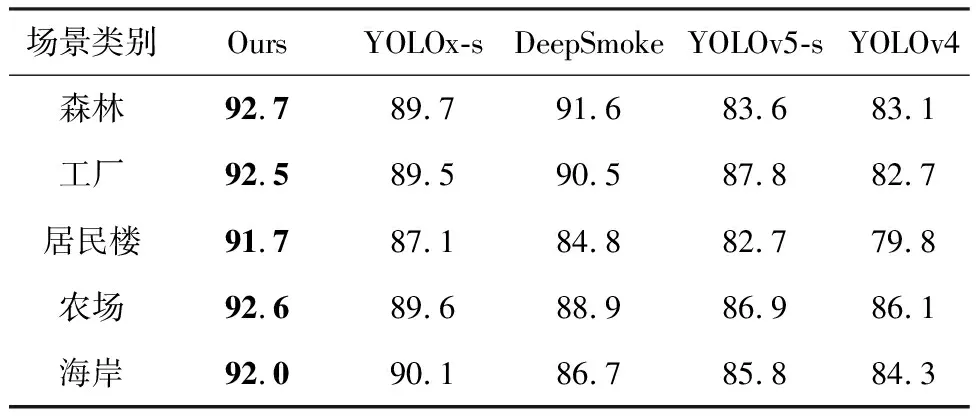
表3 不同视频下的检测准确率对比
3.3 消融实验
消融实验的对象主要包括SCA注意力模块、双向特征融合模块和Focal-EIOU损失函数,实验结果见表4。本文算法所提出的改进对检测准确率都有所提升,其中对算法检测准确度提升最大的是SCA模块,检测精度提升了1.9%,证明改进的注意力机制有效的增强了算法对烟雾特征的提取能力。单一的双向特征融合模块同样使算法检测准确度提升1.6%,证明改进的双向特征融合模块能有效地增强FPN结构对小目标烟雾特征的融合能力。引进的Focal-EIOU损失函数也对算法检测准确度有所提升,证明该损失函数解决了网络训练过程中正负样本不平衡的问题和预测框与真实框不相交时无法反映两个框的距离远近以及重合度大小的问题。

表4 消融实验
4 结 论
针对现有烟雾检测算法在多类场景下无人机航拍视角中表现不佳的问题,本文自建了一个包含多类场景的无人机航拍视频烟雾数据集USD,并提出了一种改进YOLOx的无人机视频烟雾检测算法,得出结论如下:
1)对现有的烟雾数据集进行分析,建立一个多类场景下的无人机航拍视频烟雾数据集USD,该数据集包含了从81个无人机烟雾视频中提取出的30 000张无人机烟雾图像,总共包含了19类场景,在场景类别、图像质量和图像数量上远优于其他现有的烟雾数据集。
2)对现有烟雾检测算法在应用到无人机视角的多类场景时出现的检测率低、速度慢等问题进行了分析,针对火灾初期烟雾多为小目标的问题,提出改进的双向特征融合模块和注意力机制模块。对网络训练过程中出现的正负样本不平衡问题进行分析,并对预测框和真实框不相交时无法反映两个框的距离远近以及重合度大小的问题进行了研究,引入了Focal-EIOU损失函数。
3)在自建数据集USD以及国内外常用烟雾数据集上进行实验分析,并与现有算法对比,证明了本文各个模块能有效解决多类场景下无人机航拍烟雾检测领域中的常见问题,有效提升了本文算法的检测性能。
4)本文算法在面对多雾、多云和光照不良等极端场景时会出现检测准确率下降的情况,这是由于训练数据集中缺少极端场景下的烟雾图像,导致算法出现漏检和误检,下一步我们将从两个方面继续深化完善本文算法:1)扩充数据集,加入更多极端场景下的烟雾图像,提升算法在更复杂的场景中的准确率;2)研究算法的时间复杂度和空间复杂度,在不降低准确率的条件下,利用更加轻量化的网络构架,提升算法的实用性和适用性。
