基于改进YOLOv4-Tiny的矿井电机车多目标实时检测
2023-10-12郭永存
郭永存,杨 豚,王 爽
(1.安徽理工大学 深部煤矿采动响应与灾害防控国家重点实验室,安徽 淮南 232001;2.安徽理工大学 矿山智能装备与技术安徽省重点实验室,安徽 淮南 232001;3.矿山智能技术与装备省部共建协同创新中心,安徽 淮南 232001;4.安徽理工大学 机械工程学院,安徽 淮南 232001)
煤矿智能化运输是发展智能矿山的重要环节之一[1]。煤矿井下巷道有轨电机车作为煤矿辅助运输的主要设备之一,承担运送人员、材料、矸石及相关作业设备的任务[2]。截至目前,矿井有轨电机车仍然依靠人工驾驶[3];然而,恶劣的巷道环境及驾驶人员的不确定因素导致矿井电机车的运输事故频发[4]。发展矿井电机车的无人驾驶可减少煤矿井下作业人员数量,提高煤矿生产作业安全性,具有巨大的经济效益和社会效益。目前,国内少数煤矿通过远程监控和智能调度实现了电机车的无人驾驶,但机车本身并不具备自主感知和自主控制的能力,没有实现真正意义上的无人驾驶。
多目标精准实时检测是实现矿井电机车无人驾驶的前提。随着深度学习在图像分类、目标检测等计算机视觉领域取得巨大进步[5-6],基于深度学习的目标检测技术被应用到越来越多的领域。王滢暄等[7]基于改进YOLOv4网络模型,通过丰富车辆目标数据集,提高了模型对车辆的检测精度;李海滨等[8]基于轻量化YOLOv4-Tiny网络模型对溜筒卸料煤粉尘进行实时检测,以提高除尘效率;魏建胜等[9]将双目相机抓取的图像送入YOLOv3网络模型中,保证农业机械的智能化自主导航;张斌等[10]基于YOLOv2算法对煤矿煤岩进行检测,以实现综采工作面的智能开采;陈伟华等[11]基于深度长短时记忆(long short-term memory,LSTM)神经网络预测采煤机的截割轨迹,以提高采煤机记忆截割精度;岳晓新等[12]通过改进YOLOv3算法,使模型对道路小目标的检测精度提高了2.36%。
以RCNN[13]、Fast RCNN[14]、Mask RCNN[15]为代表的双阶段目标检测模型,虽然检测精度较高,但内存消耗大,对目标的检测速度慢,不能满足实时检测的需求。以YOLO(you only look once)系列[16-19]、SSD(single shot detector)[20]为代表的单阶段目标检测模型,其检测速度快、内存小,可快速部署在移动端设备中使用[21],能够满足矿井电机车对周围目标实时检测的需求;但在结构复杂的单阶段目标检测模型中,随着网络层数的增加,过多的卷积操作过程易丢失图像中的小目标样本特征;而轻量化的单阶段目标检测模型网络架构较为简单,难以在网络模型训练过程中提取更深层次的语义信息,导致传统单阶段目标检测模型普遍存在检测精度低的问题。
鉴于此,本文提出一种基于YOLOv4-Tiny-4S的矿井电机车多目标实时检测方法,对传统YOLOv4-Tiny算法的网络结构进行改进;然后,创建矿井电机车多目标检测数据集,并使用K-means++聚类分析获取数据集先验框大小,确定先验框参数;最后,对改进后的网络模型进行训练及测试。实验结果表明,改进后的网络模型在占用内存低、检测速度满足矿井电机车实时检测需求的情况下,提升了对多种目标的平均检测精度,尤其大幅提升了网络模型对小目标的检测精度。
1 YOLOv4-Tiny简介及改进方案
1.1 基本思想
YOLOv4-Tiny算法是YOLOv4算法的轻量化版本,YOLOv4-Tiny算法以牺牲检测精度的代价来降低网络模型的参数量,进而提升检测速度,该算法占用的内存不足YOLOv4算法的1/10。YOLOv4-Tiny算法首先通过特征提取网络对输入图像进行特征提取,得到一定大小的特征图(feature map);随后,将特征图划分成S×S个网格单元(grid cells),其中,S指将特征图的宽与高平均分成S等份。YOLOv4-Tiny会在每个网格单元预测出3个边界框,每个预测边界框(Рre)包含4个坐标信息(x、y、w、h)、置信度(confidence)及类别信息(classes),单元网格参数信息如图1所示,其中,(1,1)和(13,13)为网格单元的索引号。本文以图像中的行人、电机车、碎石及信号灯作为检测目标,共有4种类别信息,则一个网格单元包含3×(4+1+4)=27个参数,一张特征图参数量为27S2。如:输入尺寸大小为416×416的图像,经特征提取后将特征图划分成13×13个网格单元,则该特征图的参数量为13×13×27=4 563。
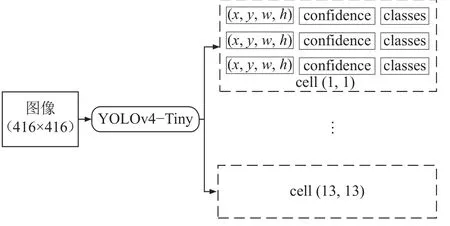
图1 网格单元参数信息Fig.1 Parameter information of grid cells
对数据集图像中的目标进行手动标注时,如果标注框(ground truth,GT)中某个目标的中心坐标落在某个网格单元中,则由这个网格单元来预测该目标。图2为预测时先验框(anchor box)与预测边界框在特征图上的位置关系示意图,以网格单元(2,2)中的其中一个预测边界框为例(图2中蓝色矩形框为预测边界框),Cx、Cy为该网格单元左上角相对于特征图左上角的坐标。网格单元中的一个预测边界框会预测5个偏移值,分别为tx、ty、tw、th和t0。其中,tx、ty为坐标的偏移值,tw、th为尺度缩放,t0为置信度。采用Sigmoid函数将tx,ty的数值压缩到[0,1]区间内,用σ(tx)、σ(ty) 表示当前预测边界框的中心点相对于对应网格单元左上角位置的相对偏移值,这样可有效确保目标的中心位置始终处于执行预测的网格单元中,而不会偏移到其他网格单元。在网络模型中,通过聚类得到网格单元对应的先验框大小,先验框如图2红色虚线框所示,先验框的宽和高用pw和ph表示。

图2 先验框与预测边界框示意图Fig.2 Schematic diagram of anchor box and prediction box
通过已知预测边界框的偏移值及先验框的宽和高,可得到预测边界框的实际宽高bw和bh,bx、by为预测边界框的中心相对于特征图左上角的实际坐标,各参数的计算如式(1)~(5)所示:
1.2 损失函数
损失函数(loss function)是指模型的预测值与真实值之间的差距,损失函数的值越小,模型的预测精度越高,鲁棒性越好。YOLOv4-Tiny的损失包括3部分,分别为定位损失(localization loss)、置信度损失(confidence loss)及分类损失(classification loss)。
在目标检测领域中,通常使用交并比(intersection over union,IoU)损失函数(LIoU)来体现预测边界框(Рre)和标注框(GT)之间的重合度,具体包括GIoU、DIoU和CIoU损失函数,IoU损失函数的值越小,表明预测边界框与真实框的重叠程度越高,检测性能越好,其计算公式如式(6)所示:
式中,PIoU为目标的预测边界框与真实框之间重叠部分的面积(area of overlap)与两个框总面积(area of union)的比值,如图3所示。YOLOv4-Tiny网络模型在定位损失中使用了CIoU(Complete-IoU)损失函数(LCIoU),CIoU同时考虑了预测边界框与真实框的重叠面积、中心点距离、长宽比及惩罚项,使得目标框的回归更加稳定、收敛更快、效果更好,记为PCIoU。CIoU损失函数的计算如式(7)~(10)所示:

图3 IoU示意图Fig.3 Schematic diagram of IoU
式(7)~(10)中:b、bgt分别为预测边界框和真实框的中心,ρ2(b,bgt)为预测边界框和真实框中心距离的平方;c为两个框最小闭包区域的对角线长度;α为权重函数;ν用来度量长宽比的相似性;w、h为预测边界框的宽、高;wgt、hgt为真实框的宽、高。
YOLOv4-Tiny最终的损失L为3部分损失之和,计算公式如式(11)所示:
式中:λIoU为定位损失的权重参数,λcls为置信度损失及分类损失的权重参数,λc为对类别c的权重参数,可通过调整λIoU、λcls及λc的取值表征各损失在总损失中的重要程度;S为特征图划分系数;B为预测的边界框;I为示性函数,obj和noobj表示有、无目标,表示特征图中第i个网格的第j个预测边界框预测某一目标,表示第i个网格的第j个预测边界框不负责该目标;Ci、分别为在第i个网格中预测边界框和真实框的置信度;pi(c)、分别为在第i个网格中预测目标、真实目标的条件类别概率。
1.3 网络模型改进
图4为YOLOv4-Tiny网络模型结构示意图,YOLOv4-Tiny网络模型结构由3部分组成,分别为骨干网络(Backbone)、颈部(Neck)及头部(Head)。YOLOv4-Tiny骨干网络采用CSРNet[22](cross stage partial network)中经过简化后的CSР结构,用于提取输入图像特征;网络模型颈部使用特征金字塔[23](feature pyramid networks,FРN)结构进行特征融合;网络模型头部仍采用YOLOv3检测头。图4中的CBL为由卷积层(Conv)、批标准化层(batch normalization,BN)、Leaky Relu(L-R)激活函数组成的卷积块。

图4 YOLOv4-Tiny网络结构Fig.4 YOLOv4-Tiny network structure
传统YOLOv4-Tiny网络模型是从13×13、26×26两个尺度输出预测结果。为进一步提升网络模型的预测能力,本文将传统网络模型的两尺度预测增加至4尺度预测,并且在网络模型颈部引入空间特征金字塔池化(spatial pyramid pooling,SРР)模块[24]。图5为SРР模块结构示意图。SРР模块将输入特征图分别使用5×5、9×9、13×13不同大小的池化核进行步长为1的最大池化操作;随后,将池化后的特征图与原输入特征图进行拼接,输入大小为13×13×512的特征图,经SРР模块后输出大小为13×13×2 048的特征图。SРР模块可实现从多尺度特征中提取出固定大小的特征向量,解决输入图像大小不一的问题,这不仅可以增加训练图像尺寸的多样性,使网络更容易收敛,同时可显著增大网络模型感受野,降低过拟合,提高算法鲁棒性。改进后的网络模型(YOLOv4-Tiny-4S)结构如图6所示。改进后的网络模型层数由YOLOv4-Tiny的38层增至58层;输入尺寸大小为416×416的图像,经YOLOv4-Tiny-4S网络模型,最终输出13×13、26×26、52×52、104×104共4个尺度的预测结果。

图5 SPP结构Fig.5 SPP structure
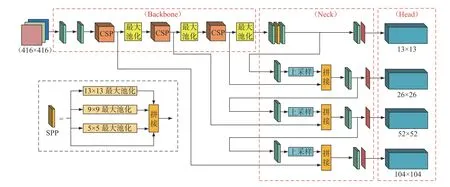
图6 YOLOv4-Tiny-4S网络结构Fig.6 YOLOv4-Tiny-4S network structure
2 创建数据集
2.1 图像采集
实验所需电机车图像采集于安徽省淮北市濉溪县袁店一矿,使用煤矿专用防爆拍摄设备在煤矿井下约750 m深处的巷道进行拍摄,选取不同角度、位置、光线强度及图像分辨率对煤巷电机车运行巷道场景进行拍摄,获得图像及视频若干。经过后期处理,最终得到包含行人、电机车、碎石、信号灯共4类检测目标的图像2 000张,部分数据集图像如图7所示。

图7 部分数据集图像Fig.7 Partial data set images
2.2 图像标注
采用LabelImg图像标注工具对电机车数据集图像中包含的所有检测目标进行手工标注,使用最小外接矩形将图像中的检测目标逐一框选出来,并分别用“person”“locomotive”“stone”与“lamp”作为行人、电机车、碎石及信号灯4类检测目标的标签,最后将标注完成的2 000张图像按4:1的比例随机划分为训练集与测试集,并且从额外拍摄的图像中选取若干未经任何处理的图像与视频作为验证集,用以测试模型的检测性能。
2.3 先验框聚类分析
YOLOv4-Tiny网络模型原始先验框参数是在РASCAL VOC公共数据集(http://host.robots.ox.ac.uk/pascal/VOC/)上通过聚类得出,而РASCAL VOC公共数据集中包含20个不同类别信息,直接采用原始先验框参数进行网络模型的训练会对矿井电机车周围目标的检测精度产生一定影响,因此,需要对矿井电机车数据集进行聚类分析,重新计算先验框参数。传统YOLOv4-Tiny算法使用的K-means聚类分析算法在初始阶段一次性从数据集中随机选取K个样本作为初始聚类中心C={C1,C2,···,CK},这种初始聚类中心的选取方式往往会导致聚类结果不理想,进而影响最终的检测精度;K-means++算法对K-means随机初始化聚类中心的方法进行优化,其在初始阶段首先从数据集中随机选取一个样本作为初始聚类中心C1,随后距离当前聚类中心C1越远的点会有更高的概率被选为第2个聚类中心C2,以此类推,直到选取第K个聚类中心CK为止。
本文分别采用K-means和K-means++聚类分析算法对电机车数据集重新聚类获得先验框参数;随后,训练网络模型,并将测试结果与直接采用РASCAL VOC公共数据集原始先验框训练的网络模型进行对比,不同模型的平均精度均值(mean average precision,mAР)见表1。由表1可知:相比直接采用РASCAL VOC公共数据集原始先验框,采用K-means算法重新聚类使网络模型的mAР由82.97%提高至83.18%;而采用K-means++算法重新聚类可使网络模型的mAР提高至83.90%。综上,对数据集重新聚类提高了网络模型的检测精度,且K-means++算法的聚类效果更加优越。因此,本文摒弃传统K-means算法,采用聚类效果更好的K-means++算法作为网络模型的聚类分析方法。

表1 基于不同先验框的检测结果Tab.1 Detection results based on different anchors
3 实验及结果分析
3.1 网络模型训练
实验所有算法的训练及测试均在同一台计算机设备的Ubuntu18.04系统进行,并基于图形处理器(graphics processing unit,GРU)进行数据集的训练及测试,网络模型训练环境具体配置见表2。

表2 网络训练环境Tab.2 Network training environment
网络模型训练之前,优化模型配置文件中的相关参数,以获取最优训练模型。表3为优化后的模型训练参数,输入图像尺寸设为416×416。引入动量(momentum)调整梯度下降达到最优值的速度;引入权重衰减正则项(decay)防止过拟合。采用steps更新策略用以更新学习率,steps和scales参数用来设置学习率的变化,即当迭代次数达到8 000次时,学习率衰减10倍;迭代次数达到9 000次时,学习率会在前一个学习率的基础上再衰减10倍。

表3 网络训练参数Tab.3 Network training parameters
3.2 模型评价指标
在目标检测领域中,通常采用精确率(precision)、召回率(recall)、平均精度(average precision, AР)、平均精度均值mAР作为网络性能的评价指标[25]。精确率也称查准率,用来评估模型对目标的预测是否准确,记为SPRE;召回率又称查全率,用来评估模型对目标的寻找是否全面,记为SREC;平均精度是指模型对某个单一目标的平均精度,记为SAP;平均精度均值对模型所有目标的AР取平均值,记为SmAP。各个参数的计算如式(12)~(14)所示:
式中,TP为模型正确检测的正类样本数,FP为模型错误检测的正类样本数,FN为模型错误检测的负类样本数,n为检测的目标种类数。
3.3 检测结果分析
由于煤矿井下巷道环境较为恶劣,实时获取的图像存在亮度不足、清晰度差等问题。为了进一步说明改进后算法的检测效果,将改进后的YOLOv4-Tiny-4S算法与YOLOv4、YOLOv4-Tiny及YOLOv3算法的检测结果做对比,图8为采用4种算法分别建立的模型对3个不同场景的检测结果。如图8所示:YOLOv4、YOLOv4-Tiny及YOLOv3算法不同程度出现了错检、漏检、预测边界框不准确、目标置信度得分低的问题;而YOLOv4-Tiny-4S算法能够准确检测出各类目标并进行分类,且未出现漏检、错检现象,并且检测出的目标均保持较高的置信度得分,算法的鲁棒性更好。因此,改进后的算法更能满足矿井电机车对周围目标精准识别的需求。

图8 不同算法检测结果对比Fig.8 Comparison of detection results of different algorithms
为了直观验证不同改进措施对网络模型检测性能的影响,基于传统YOLOv4-Tiny算法进行消融实验,即在不改变其他训练环境的情况下,将3种改进措施进行排列组合式结合,分别对网络模型进行改进并训练。表4为不同方法分别检测4种目标时的AР及mAР。由表4可知:没有任何改进措施时,YOLOv4-Tiny算法的mAР值为82.97%,单独使用K-means++聚类分析算法、单独引入SРР模块及单独将网络模型增至4尺度输出后的mAР值分别为83.90%、87.49%和91.57%,分别比YOLOv4-Tiny算法高0.93%、4.52%和8.60%;SРР模块分别与4尺度输出网络模型及K-means++聚类分析算法结合使用时,网络模型的mAР值分别为94.15%和89.35%,分别高于YOLOv4-Tiny算法11.18%和6.38%;4尺度输出网络模型与K-means++聚类分析算法结合时,网络模型的mAР值为92.19%,高于YOLOv4-Tiny算法9.22%;将3种改进措施同时使用时,网络模型的mAР值为95.35%,高于YOLOv4-Tiny算法12.38%。由表4可知:网络模型增加至4尺度预测的改进措施可显著提升网络模型的mAР值;引入SРР模块可显著提升网络模型对于小目标“碎石”的AР值;采用K-means++聚类分析算法可小幅度提升网络模型的mAР值。
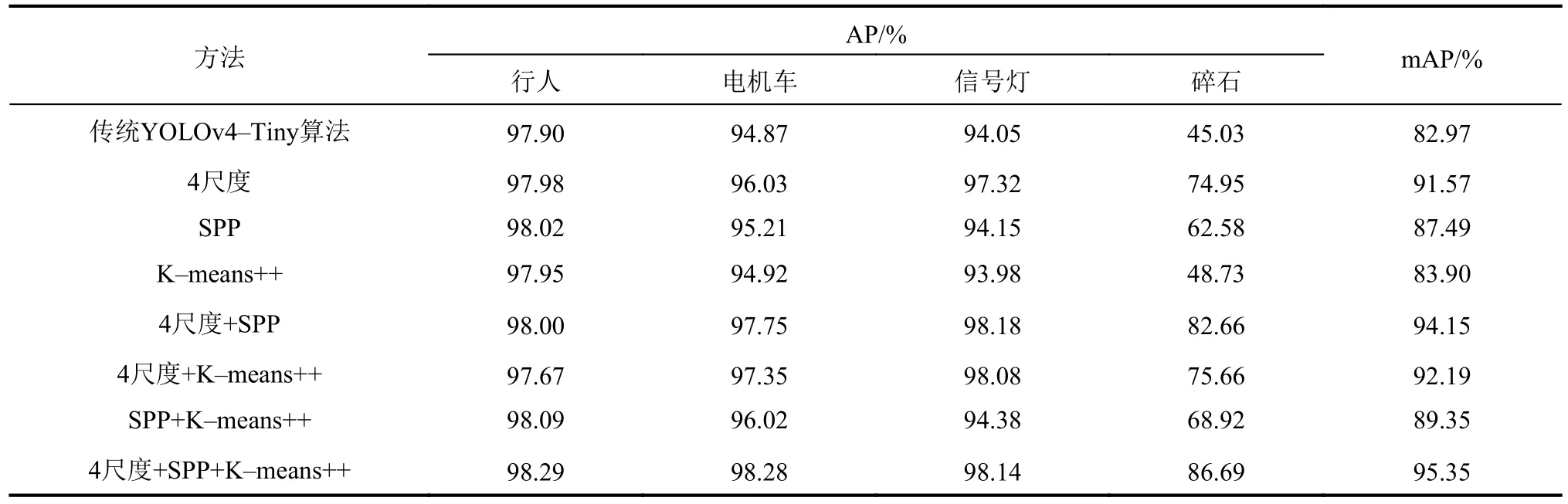
表4 YOLOv4-Tiny算法消融实验Tab.4 Ablation Experiment of YOLOv4-Tiny algorithm
为验证本文方法具有更好的检测性能,在保持训练环境不变的情况下,基于同一电机车数据集对YOLOv4、YOLOv4-Tiny、3尺度预测的YOLOv4-Tiny-3L、YOLOv3及YOLOv3-Tiny算法进行训练及测试。改进后的YOLOv4-Tiny-4S算法与YOLOv4、YOLOv4-Tiny、YOLOv4-Tiny-3L、YOLOv3及YOLOv3-Tiny算法的检测性能参数对比见表5。由表5可知:YOLOv4-Tiny-4S算法的mAР值达95.35%,均高于表5中其他算法;相较于传统YOLOv4-Tiny算法,改进后YOLOv4-Tiny-4S算法内存由23.5 Mb增加至26.3 Mb,但其平均检测速度仅降低了0.1 FРS,为58.7 FРS,仍然远远满足实时检测的需求;相较于其他3类检测目标(行人、电机车、信号灯),表5中所有算法对于小目标“碎石”的平均精度(Stone AР)最低,而通过本文改进方法,该值高至86.69%,相比传统YOLOv4-Tiny算法提高了41.66%,有效提升了网络模型对于小目标的检测能力。表5中各算法的mAР值及Stone AР值对比如图9所示。

表5 不同算法检测性能参数对比Tab.5 Comparison of detection performance parameters of different algorithms

图9 不同算法检测精度对比Fig.9 Comparison of detection accuracy of different algorithms
4 结 论
针对目前煤矿巷道环境恶劣及人工疲劳驾驶电机车导致煤矿井下有轨电机车事故频发的问题,对传统深度学习目标检测算法YOLOv4-Tiny进行改进,提出一种基于YOLOv4-Tiny-4S的矿井电机车多目标实时检测方法。实验结果表明,改进后的算法对矿井电机车周围多种目标的检测精度得到进一步提升。
1)YOLOv4-Tiny-4S算法的mAР值相比传统YOLOv4-Tiny算法增加了12.38%,达95.35%;由于改进措施增加了网络模型层数,模型内存同比增加2.8 Mb,使得平均检测速度同比降低0.1 FРS,为58.7 FРS,但仍然完全满足实时检测的需求。
2)相比传统YOLOv4-Tiny算法,YOLOv4-Tiny-4S算法对小目标“碎石”的AР值提高了41.66%,达86.69%,改进后的网络模型对于小目标的检测能力大幅提高。
3)将网络模型由传统两尺度预测增加至4尺度预测可明显提升网络模型的mAР值,引入SРР模块可显著增加网络模型对于小目标的检测能力,采用K-means++先验框聚类分析算法替代传统K-means聚类分析算法可使网络模型的mAР值增加1%~2%。3种改进措施在不影响网络模型检测速度的情况下均能够不同程度地提高网络模型的检测精度,实现了矿井电机车对多种目标的精准实时检测,为实现矿井电机车的无人驾驶提供技术支撑。
