基于回归分析和神经网络模型的地下水位预测
2023-10-12茹哲敏
茹哲敏
(山西省水文水资源勘测总站,山西 太原 030001)
地下水是山西省重要的基础资源和战略资源,是城乡生活和工农业用水的重要供水水源,是生态与环境的主要控制性要素。对地下水位进行预测和分析,是地下水监督管理的重要方式,也是水利行业强监管的重要内容。定襄县盆地内地下水的补给源包括大气降水垂直入渗补给、基岩裂隙水的侧向渗透补给、农田灌溉入渗补给、河道渗漏补给等。地下水位变化特征复杂多变,需要对各影响因素进行相关性分析,确定主要的影响因素,建立模型,对地下水位进行预测。回归模型和神经网络模型是2 种较为常见的预测分析模型,2 种模型各有优缺点和适用条件,其预测结果可以相互对比和印证。2 种模型预测成果可指导和管理定襄县地下水资源的合理开发利用,对其他区域地下水位预测具有参考价值。
1 研究区域概况
定襄县位于山西省中北部,东西长48 km,南北宽36 km,滹沱河由西向东横贯全境,全县地形由东向西呈簸箕形,北、东、南三面群山环绕,西部和中部为忻定盆地,地势较为平坦,盆地面积约406 km2。境内主要河流为滹沱河、牧马河、云中河等。盆地基底为起伏不平的块状陷落和隆起,地下水位埋深较浅,地下水位年内变化较为平缓[1],含水层厚度大、颗粒粗,地下水总体由盆地周边山前倾斜平原区向冲积平原区汇集,并沿滹沱河谷区由上游向下游逐渐径流。定襄县年降水量450 mm左右,降水量较为稳定。本次研究共选取10处地下水监测站和1处雨量站的水文年鉴资料作为研究资料,地下水监测站均匀分布,监测类型全部为浅层孔隙水,开采量使用统计年报数据,采用1993—2016 年的系列资料,研究区域及监测站分布如图1所示。
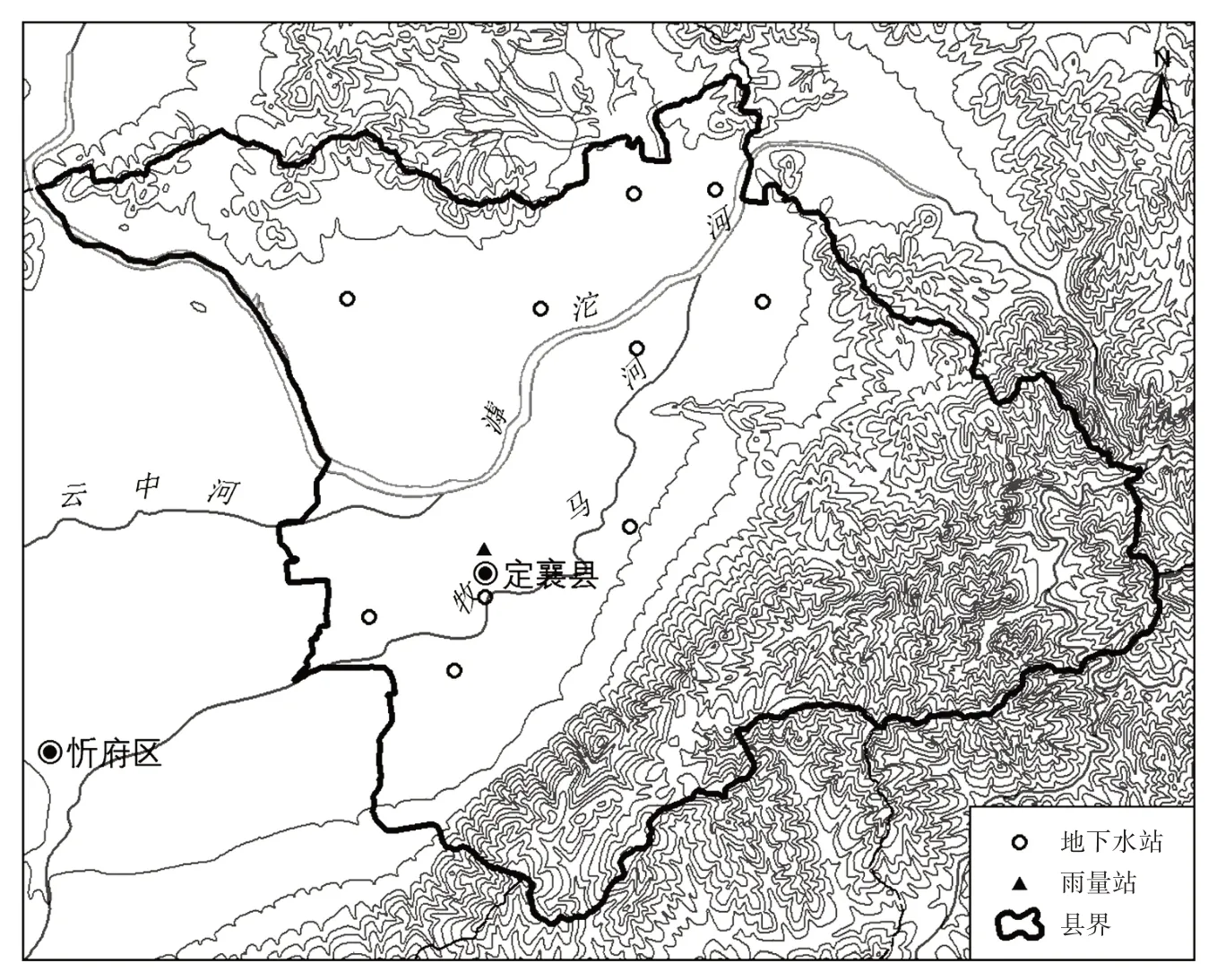
图1 研究区域示意
2 影响因素分析
地下水水位变动受降水、开采、蒸发以及补给能力等多因素影响。降水是地下水的主要补给来源[2],丰水年的地下水位一般会明显升高,而枯水年的地下水位一般会下降。在盆地区的潜水含水层,降水时间与地下水位变化的时间较为接近,水位变化相对于降水时间上的滞后现象不太明显。地表水位的变化也影响地下水位的变化,一般两者升降方向一致但存在时间滞后。人类对地下水的开采、灌溉、人工补给等活动直接影响地下水位变化,如果过量开采地下水而缺少补给,会使地下水位持续下降。
地下水位变化特征复杂多变,但也有规律可循,经初步分析可知,影响定襄县地下水位的主要因素包括上年末水位、本年降水量、上年降水量、开采量、蒸发量等。将本年与上年水位差(水位变幅)与降水量建立关系,如图2 所示,水位变幅与降水量呈正相关,说明降水量为重要影响因素。经分析本年降水量和开采量的关系发现,降水量与开采量呈负相关,说明降水量大的年份开采量减少,比较符合当地实际情况。再利用此方法分析本年末地下水位与其他因素之间的关系。结果表明,本年末地下水位与上年降水量的关系为负相关,说明降水影响地下水位的滞后性并不明显,故不考虑上年降水量;同时,蒸发对地下水位影响非常微小,故不考虑蒸发量;同时,经以上分析,本次研究将上年末水位、本年降水量、开采量等主要影响因素作为模型参数。
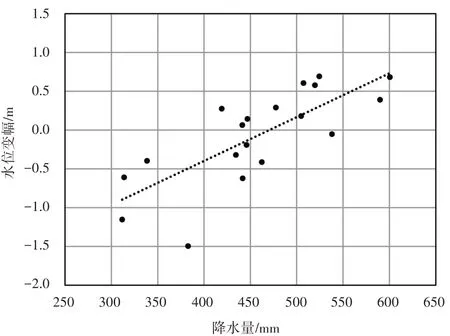
图2 水位变幅与降水量关系
3 回归模型
3.1 回归模型概述
回归分析是研究一个随机变量Y对另一组变量X1,X2,…,Xn之间的相互关系的一种统计方法,通过建立统计模型来研究这种关系,它主要通过对变量的观察所获得的统计数据来确定反映变量间关系的经验公式,并通过所得公式进行统计描述、分析和推断,从而解决预测、控制和优化问题。用来进行回归分析的数学模型方程为:
式中:Y为因变量;X1,X2,…,Xn为一组自变量。
若因变量和自变量之间是线性关系,则称为线性回归模型,只含有一个回归变量的线性回归模型为一元线性回归模型,含有多个回归变量的线性回归模型为多元线性回归模型[3]。线性回归可以通过最小二乘法求出其方程。
相关系数r可以反映变量之间相关程度。判定本年地下水位与其他因素之间是否存在相关关系,需要计算相关系数。如果相关系数接近1表示正相关,如果接近-1 表示负相关,如果接近0 表示不相关。相关系数计算公式为:
式中:Cov(X,Y)为X与Y的协方差;Var(X)为X的方差;Var(Y)为Y的方差。
3.2 回归方程确定
由于地下水位与多种因素存在关系,因此采用多元线性回归模型,影响本年末地下水位的主要因素包括上年末水位、本年降水量、开采量等。选用定襄1993—2016 年的监测数据作为分析数据,将2017、2018 年作为预测年份。利用数据分析工具建立地下水动态多元线性回归模型,根据资料情况,率定模型系数。确定后的模型方程为:
式中:Hb为本年末地下水位(m);Hs为上年末地下水位(m);Pb为本年降水量(mm);Q为开采量(万m3);a,c,d,e为模型系数,应满足以下条件:a>0,c>0,d<0。
3.3 回归模型参数及检验
回归方程中的自变量都应该与因变量是显著相关的,且各个自变量之间应该是相互独立的。统计检验是利用统计学的理论检验回归方程的可靠性,包括拟合优度检验、模型的显著性检验(F检验)和模型参数的显著性检验(t检验)等。
分析变量是否对本年地下水位有影响,可通过将本年地下水位的总离差平方和进行分解来确定各因素对本年地下水位的各样本之间的差异做出的贡献。总的离差平方和SST可分解为回归平方和SSR及残差平方和SSE,即SST=SSR+SSE。F检验统计量公式为:
式中:n为样本数量;p为自变量数量;SSR为回归平方和;SSE为残差平方和。
当假设成立时,F服从自由度为p和n-p-1的F分布。可以利用F统计量对回归方程的总体显著性进行检验。如果通过检验,说明全体自变量在整体上对本年地下水位是有影响的。显著性检验的方差分析,详见表1。
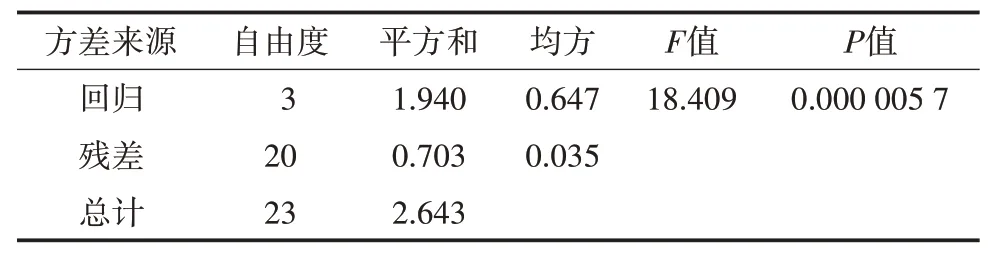
表1 显著性检验的方差分析
在通过回归方程的显著性检验后,还需要进一步对每个自变量的显著性进行t检验。如果某个自变量未通过t检验,说明其对本年地下水位影响不显著,应把此自变量从回归方程中剔除。模型计算参数,详见表2。
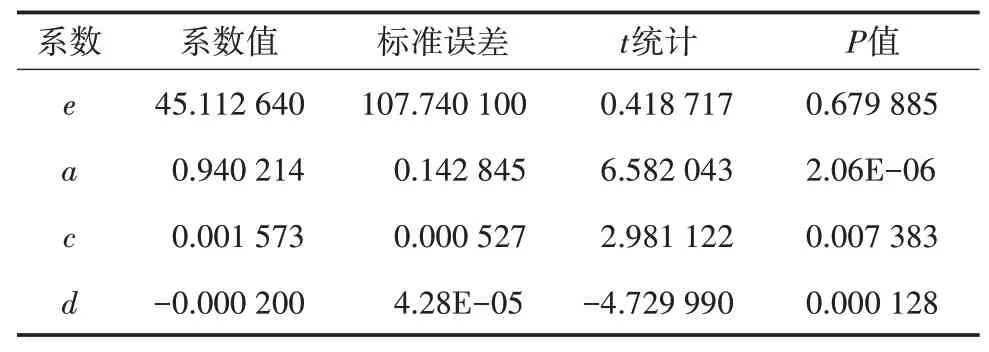
表2 模型计算参数
可决系数R2是拟合优度的度量,取值范围为[0,1],R2越接近1,说明拟合值的离差平方和占总的离差平方和的比重越大,回归拟合效果越好。可决系数分解公式为:式中:SSR为回归平方和;SSE为残差平方和;SST为总离差平方和。
复相关系数R是R2的平方根,表示回归方程对原数据拟合程度的好坏,它反映了所有自变量与因变量之间线性关系及密切程度。经计算得出复相关系数R为0.857,可决系数R2为0.734。
根据模型检验情况,可决系数R2接近1,说明实际水位与预测水位拟合效果较好。参数a>0,表示本年末地下水位与上年末地下水位正相关;参数c>0,表示本年末地下水位与本年降水量正相关,降水量的增加使地下水位上升;参数d<0表示本年末地下水位与开采量负相关,地下水的开采会导致地下水位的下降。上年末地下水位、本年降水量、开采量的t检验的P值都<0.05,则表示显著性较好。因此,这3个参数较为合理。通过各项分析,修正不合理数据,剔除不显著的变量,对剩余因素重新建立回归方程,直到通过各项检验为止。最终形成的回归方程式为:
3.4 回归模型预测
将上年末地下水位、本年降水量、开采量代入统计模型,计算出预测地下水位,再与实际地下水位相比较。2017 和2018 年预测地下水位分别为753.52和753.75 m,与实际地下水位相差分别为-0.01 和-0.14 m,预测结果较为良好。实际地下水位与预测地下水位对比情况,如图3所示。
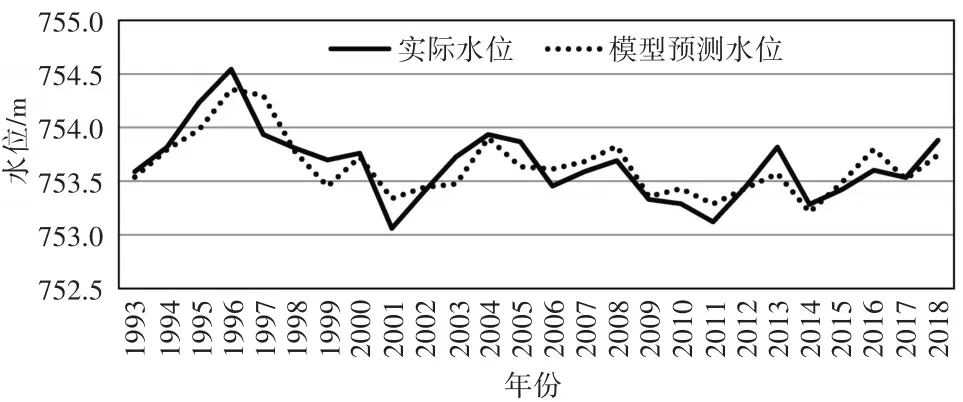
图3 实际地下水位与回归模型预测地下水位对比
4 神经网络模型
4.1 BP神经网络概述
采用误差反向传播(Error back propagation)算法的神经网络称为BP神经网络。网络由输入层、中间隐含层和输出层组成,中间层可以有一层或多层,层与层之间全连接,同一层之间的节点无连接。算法的基本过程由信号的正向传播与误差反向传播2个过程组成。正向传播时,输入数据从输入层传入,经过各隐含层处理后逐层向后传播,传向输出层。根据指定的初始化权重值和偏置值来计算输出值,若与期望输出相差过大,则转入误差的反向传播阶段。误差反向传播是将输出误差通过隐含层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层的误差信号,此误差信号即作为修正单元权值的依据。这种信号正向传播与误差反向传播的各层权值调整过程周而复始地进行,权值不断调整,一直进行到网络输出的误差减少到可预先设定的值或进行到预先设定的迭代次数为止[4]。迭代结束后,得出最优参数即性能函数取最小值的参数,包括最终权重矩阵和偏置,即可用此参数进行预测。
4.2 网络模型确定
BP 神经网络优化算法有很多,包括动量BP 法、学习率可变的BP 算法、共轭梯度法、牛顿法和拟牛顿法、Levenberg-Marquardt 算法等。选择Levenberg-Marquard 算法来计算性能函数的最小值,它类似拟牛顿算法,同时具有梯度法和牛顿法的优点,根据多次试验对比,相对于其他算法,它的收敛速度较快,不容易陷入局部最小,算法结果更合理。
网络由输入层、中间隐含层和输出层组成。将影响本年末地下水位的主要因素作为网络的输入层数据,输入层节点数为3 个,分别为上年末地下水位、本年降水量、本年开采量。输出层节点数为1个,输出层数据为本年末地下水位。采用1993—2016 年系列资料作为输入数据,将2017 和2018 年作为预测年份,分析掌握两者之间潜在的规律,最终根据这些规律来推算2017 和2018 年输出结果。通过Matlab®软件构建BP 神经网络模型,模型结构如图4所示。
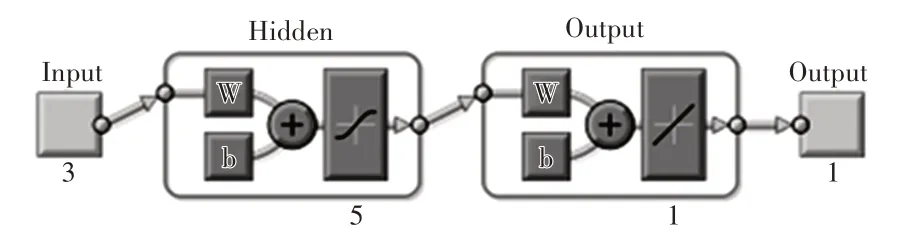
图4 BP神经网络模型结构
需要最优化的函数为性能函数,用来评价网络的精确程度。选择均方误差MSE函数作为性能函数,均方误差是指预测值与实际值之差的平方和的平均值,它包含了偏差和方差[5]。均方误差函数公式为:
式中:X'i为预测输出数据;Xi为实际监测数据;n为样本数量。
由于模型因素的数值单位不统一,为避免大数值因子弱化小数值因子,要进行归一化处理,将数据按比例缩放。当网络训练结束后,再反归一化到原始数据范围。本次采用最大最小法进行归一化,统一映射到[-1,1]区间上,归一化公式为:
式中:Xmax为原始数据的最大值;Xmin为原始数据的最小值;X为原始数据;Y为归一化后数据。
4.3 网络模型参数
构建BP 神经网络,需要对权重进行初始化,选择激活函数,设置隐含层的层数和节点数、最大迭代次数、学习率等参数。具体包括以下方面。
4.3.1 初始化权重
网络通过迭代的方式确定权重,需要一个初始值。较大的初始权重会造成大的信号传递给激活函数,导致网络饱和,从而降低网络学习到更好权重的能力。初始权重通常为较小的非零随机值,不能将权重初始化为相同的恒定值或零,否则会导致反向传播误差得到平分,使网络无法更新权重。采用Nguyen-Widrow 算法对每个权重矩阵和偏置进行初始化,使得每层节点的活动区域大致均匀地分布在输入空间上,由于很少有神经元被浪费,训练速度更快,相对于纯随机权重和偏置,此算法更具有优势[6]。
4.3.2 激活函数
激活函数可选择Sigmoid 函数、线性函数、ReLU函数、Softplus 函数等函数。隐含层选用tanSigmoid函数,输出层选用纯属线性函数。Sigmoid 函数是光滑、可微、单调的函数[7],具有非线性的放大功能,tanSigmoid 函数是双曲正切Sigmoid 函数,函数将输入从正负无穷的范围映射在(-1,1)区间,当输入的绝对值非常大时会出现饱和现象,对输入的微小变化变得不敏感。tanSigmoid函数公式为:
式中:x为自变量;e为自然常数。
4.3.3 隐含层的层数和节点数
神经网络可以包括一个或多个隐含层,并需要确定隐含层的层数。隐含层节点数对BP 神经网络的性能影响较大,一般采用经验公式来确定。设置1个隐含层和5个隐含层节点数,可以满足要求。
4.3.4 最大迭代次数
网络在训练时,如果达到最大迭代次数,即使达不到误差要求,也会终止计算。设置最大迭代次数为2 000,设置性能值为0.000 01。
4.3.5 学习率η
学习率决定了在一次学习中多大程度上更新参数。学习率过大,容易出现振荡,可能导致学习过程不稳定而不能收敛,无法达到要求的精度;学习率过小,又可能会导致训练周期增加、收敛慢。刚开始可先选择较小的学习率训练网络以保持网络稳定运行,同时密切观察误差下降曲线的变化情况,若下降较快,则说明学习率选取恰当;但若出现比较大的震荡,则说明学习率选得略大,可适当调小。学习率的选取直接影响阈值和权值的调整量,也影响网络收敛速度和精度。通过试验,学习率设置为0.001较为合适。
4.4 网络模型预测
模型参数设置完成后,将归一化处理后的训练数据输入网络,调用模型程序进行训练,训练期间沿着性能函数最快下降的方向,不断地调整网络的权重和偏置,直到性能函数值小于设置值。经过多次试算,得出最优参数即性能函数取最小值的参数,包括输入权重矩阵和偏置。输入层到中间层、中间层到输出层的权重矩阵和偏置,详见表3。
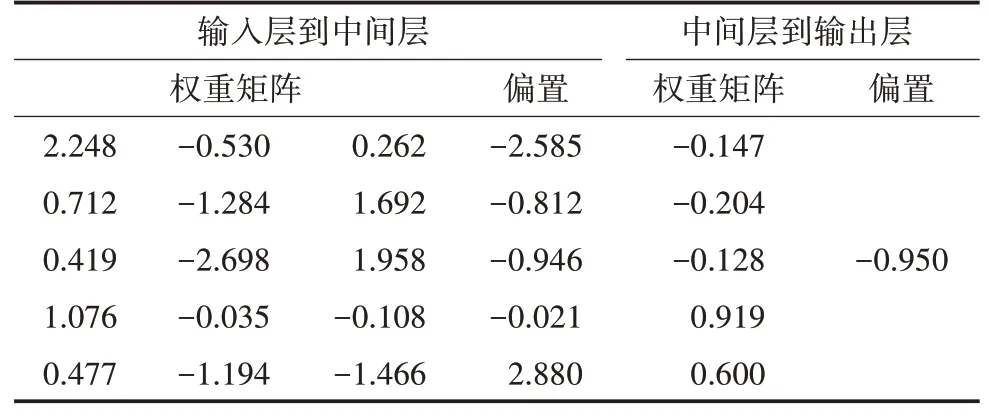
表3 权重矩阵和偏置
利用训练好的模型参数,采用神经网络算法,推算出2017、2018 年输出结果。2017、2018 年预测地下水位分别为753.58 和753.67 m,与实际地下水位相差分别为0.05 和-0.21 m,预测结果较为良好。拟合相关性如图5所示,最佳拟合由虚线表示,完美拟合(输出等于目标)由实线表示,输出和目标之间的相关系数接近1,这表明拟合较好。实际地下水位与预测地下水位对比情况,如图6所示。
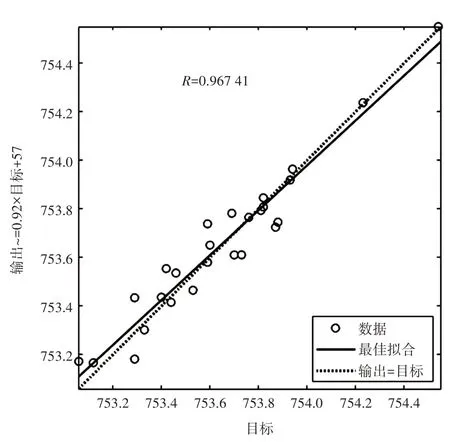
图5 拟合相关性
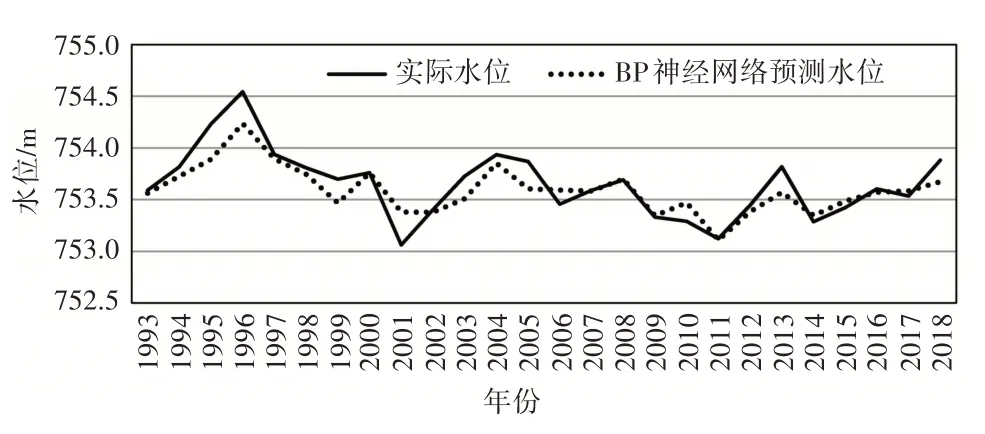
图6 实际地下水位与神经网络模型预测地下水位对比
5 模型对比分析
5.1 回归模型
回归模型可以建立因变量与自变量之间的关系,回归分析可以相对准确地计量各个因素之间的相关程度,通过标准的统计方法可以计算出唯一的结果。运用回归模型需要确定各影响因素,影响因素的选择很重要,定襄县地下水位与上年降水量的关系不大,而其他县区地下水位可能与上年降水关系密切,如果选择的因素不合适,将不能反映实际情况,需要根据不同研究区域的实际情况选择合适的自变量。当地下水位与各影响因素之间的关系较为显著时,采用回归模型较为合适。
5.2 神经网络模型
神经网络模型实现了一个从输入到输出的映射过程,它可以实现任何复杂非线性映射的功能,适合于求解内部机制复杂的问题,在函数拟合、优化计算、模式识别及聚类等多种领域应用广泛。但神经网络容易得到局部最优解,如果参与训练数据量过少,容易发生过拟合,即只能拟合训练数据,但对其他数据不能很好拟合,可以通过增加数据量以防止过度拟合;网络需要设置的参数较多,隐含层数和节点数的选择无理论依据,只能通过经验来给定一个粗略的范围;对权重初始值敏感,由于初始权重是随机给定的,网络训练具有不可重现性,每次训练的结果会不同,但可保存权重矩阵和偏置,以便下次预测重复使用。当无法确定地下水位与各影响因素之间的公式时,采用BP神经网络模型较为合适。
6 结论
(1)监测资料的可靠性对2 种模型预测的精度至关重要。降水量和地下水位监测资料的时序较长、系列资料较完整,其预测精度相对较高,而地下水开采量以收集统计为主,开采量数据应进行进一步分析和复核。选用地下水监测站水位数据应与开采层位相对应,且监测质量较好,能够代表附近水位变化情况,如果与开采层位不对应,计算结果将严重失真,不能反映区域水位变化规律。
(2)2 种模型样本的数量应足够多,否则可能会得出局部最优解,而不适用全局,对预测精度将产生不利影响。定襄县的监测资料选取1993—2016 年,资料系列年限较长,不会出现过度拟合现象,模型预测精度能够得到保证。
(3)本文建立了回归模型和神经网络模型,用这2 种模型对定襄县忻定盆地的地下水位进行了预测,预测结果基本可靠,2 种模型预测结果可以相互对比和印证,若相差较大,应详细分析原因并调整模型参数,直至结果合理。本文研究方法可指导并管理定襄县地下水资源的合理开发利用,对其他区域地下水位预测具有参考价值。
