基于知识蒸馏和模型剪枝的轻量化模型植物病害识别
2023-10-12刘媛媛王定坤黄德昌
刘媛媛,王定坤,邬 雷,黄德昌,朱 路
(华东交通大学 信息工程学院,江西 南昌 330013)
病害严重影响植物的外观和品质。一旦发现植物感染病害,如果能及时做出应对措施,即可以防止病害的进一步扩大;因此,对植物病害的精准识别至关重要。然而,传统的识别方法主要依赖于专家的专业知识或农民的经验等,存在效率低、成本高、主观性强等问题。为了克服这一问题,研究人员引入图像处理和机器视觉等技术对植物病害进行识别研究。
近年来,卷积神经网络(convolutional neural network, CNN)已成为计算机视觉任务的主要方法,在目标识别、图像分割、图像分类等领域取得了显著的效果。随着研究的深入,CNN也开始应用于农业领域[1-3],如粮食[4-5]、水果[6-7]、蔬菜[8-9]等农产品的目标检测和质量评价等方面。张建华等[10]将改进的VGG-16卷积神经网络用于棉花病害识别,对棉花5种病害的识别准确率达89.51%;杨森等[11]将深度卷积神经网络Faster R-CNN与复合特征字典结合起来,对3种马铃薯病虫害进行识别,平均准确率为90.83%。
ResNet作为具有代表性的卷积神经网络之一[12],有着非常广泛的应用。刘翱宇等[13]在ResNet50网络的基础上引入Focal Loss函数,提出一种基于深度残差网络的玉米病害识别网络TFL-ResNet,并用其对3种玉米病害进行识别,平均准确率为98.96%。孔建磊等[14]在ResNet50模型的基础上,提出了多流高斯概率融合网络(multi-stream Gaussian probability fusion network, MPFN)的病虫害细粒度识别模型,该模型在12.2万张、181类病虫害图像中的平均准确率达到93.18%。上述研究虽然取得了较好的识别效果,但是模型参数多、计算量大。农业物联网的终端通常是嵌入式设备,其计算资源有限;因此,这些复杂模型难以直接在终端设备上部署以识别植物病害。
ResNet网络模型中的一些连接和计算是冗余或非关键的,因此模型剪枝可以在不显著降低性能的情况下压缩冗余,减少模型参数[15]。Li等[16]提出,在经过训练的网络上修剪不重要的通道,然后微调网络,可以恢复性能。Changpinyo等[17]在其研究中引入了网络稀疏化,虽然网络稀疏化导致网络性能损失,但能获得一个较小的网络。为了挖掘结构化剪枝的非重要性部分,还有研究人员采用结构化稀疏正则化进行稀疏训练:Wen等[18]提出结构化稀疏性学习和对通道比例因子的稀疏性惩罚;Liu等[19]提出一种简单有效的通道剪枝方法——网络瘦身(network slimming)。模型剪枝虽然可以减少模型参数,但剪枝后的模型精度往往不如原模型;因此,选择合适的策略训练预剪枝模型和重训练剪枝模型也是非常重要的。知识蒸馏旨在通过教师模型对学生模型的损失函数增加一个术语,鼓励学生模仿老师的行为,使得知识从一个大的教师模型提炼到一个小的学生模型[20-21]。Ba等[22]研究表明,如果教师模型的网络参数数量和学生模型相同的话,设计更浅的学生模型将使每一层变宽。Romero等[23]使用回归器连接教师和学生的中间层,证实深的学生模型分类效果更好。Czarnecki等[24]将目标函数的导数融入神经网络的训练中,使得损失的教师和学生导数之间的差异与教师预测的差异最小化。He等[25]提出一种有效的语义分割知识蒸馏方法,在不引入额外参数或计算的情况下,能提高学生模型的能力,并以更少的计算开销获得了更好的结果。知识蒸馏将教师模型的知识迁移到学生模型中,使学生模型达到与教师模型相当的性能。但如何选择合适的学生模型网络结构,帮助该模型更好地学习教师模型的知识,是知识蒸馏需进一步研究的问题。总的来看,上述研究的压缩与加速方法只是单独使用,虽然也能够获得一定的效果,但都存在各自的局限性。本文融合了这两种方法,提出一种基于知识蒸馏和模型剪枝的轻量化模型用于植物病害识别。通过改进ResNet模型,在知识蒸馏中引入助教网络[26]进行训练,利用模型剪枝得出轻量化的学生网络,再使用助教网络和学习率倒带(learning rate rewinding)[27]进行重训练。结果表明,在一定剪枝率下,该方法不仅减小了模型的规模,也提高了模型的精度,可为实际农业场景下使用移动端识别植物病害提供可行方案。
1 材料与方法
1.1 植物病害数据集
本研究所采用的多类植物病害数据集为New Plant Diseases Dataset,来源于PlantVillage数据集(https://www.kaggle.com)。New Plant Diseases Dataset拥有14类植物,包含26种病害图像和12种健康图像(表1),部分数据集简图如图1所示。New Plant Diseases Dataset总共由87 867张RGB图像组成。本实验将图像统一调整为224 pixel×224 pixel×3通道,并将数据集依照80%和20%的比例分成训练集和测试集,训练集和测试集分别有70 295张和17 572张图像。
1.2 单类植物病害数据集
本研究选定的单类植物病害为苹果叶病害,数据集主要由Kaggle竞赛所用数据整理而来,包含4种病害图像和1种健康图像,数据图像样本如图2所示。苹果叶数据集总共由15 675张RGB图像组成,本实验将图像统一调整为224 pixel×224 pixel×3通道,并将数据集同样依照80%和20%的比例分成训练集和测试集,共有12 538张训练集图片和3 137张测试集图片。与New Plant Diseases Dataset相比,苹果叶病害数据集的背景复杂多样。

图2 苹果叶病害图像样本Fig.2 Samples of apple leaf diseases pictures
1.3 算法流程
本文算法包括数据预处理、ResNet网络结构改进、教师网络设计、助教网络设计、稀疏化训练、模型通道剪枝,以及结合学习率倒带和助教网络蒸馏进行重训练7个部分(图3)。以下对算法中的关键部分进行详细叙述。
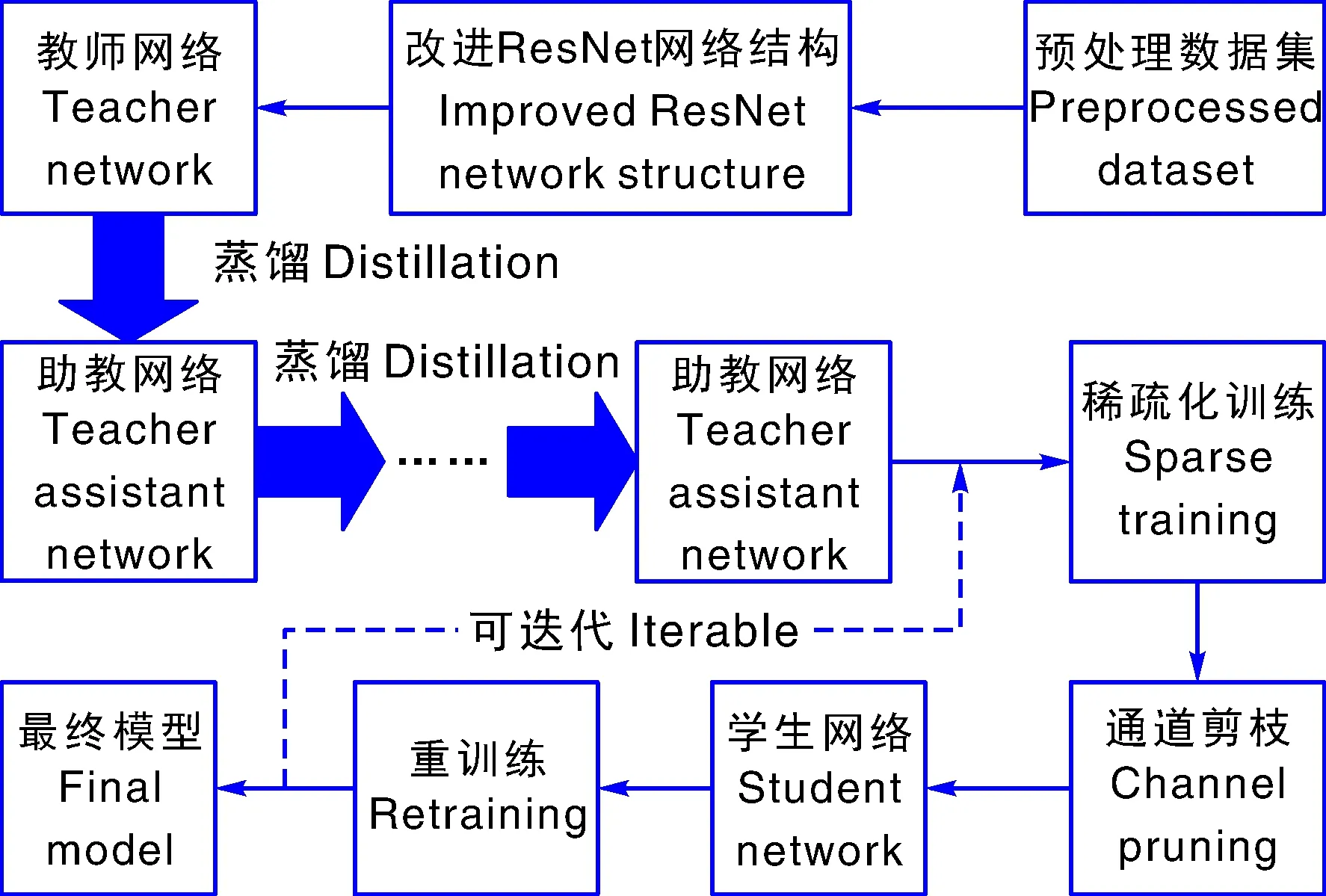
图3 算法流程图Fig.3 Algorithm flow chart
1.3.1 ResNet网络结构改进
ResNet是一种跳跃连接和预激活设计的网络,即一个层的输出可以被视为多个后续层的输入,如果直接对其剪枝会导致后续层的不匹配问题;因此,在对ResNet剪枝之前需要调整该模型结构。同时,为了在测试时减少参数和节省运行时间,需要放置一个通道选择层(channel selection)鉴别出模型的重要通道,通过保留这些重要通道以提高模型的性能。此外,当教师网络和学生网络之间的差距过大时,还需要引入一个或多个合适深度的助教网络。本文通过修改残差块数量实现各种深度的ResNet网络。将各种深度的具体网络结构整理于表2。

表2 模型结构
对于轻量网络,实验使用ResNet-(9*n+2)网络模型,9*n+2表示模型深度,n的大小表示每一层(layer)的残差块(residual block)个数,共有3个layer。例如,对于ResNet-56,取n为6;而对于ResNet-74,n则为8。
对于复杂网络,实验使用ResNet-(12*n+2)网络模型,12*n+2表示模型深度,n表示每一个layer的残差块个数,共有4个layer。例如,对于ResNet-50,取n为4;而对于ResNet-74,n则为6。
1.3.2 知识蒸馏
为了获得更好的轻量化模型性能,本文使用改进的ResNet,通过知识蒸馏策略来训练模型。知识蒸馏是利用复杂的教师模型指导简单的学生模型训练,把知识迁移到学生模型中,使学生模型达到与教师模型相当的性能。
知识蒸馏训练与传统的模型训练不同。传统模型使用Softmax作为输出层以输出类别概率。当Softmax输出的概率分布熵相对较小时,负标签的值都接近0,此时,负标签对损失函数的贡献非常小,几乎可以忽略不计。然而,负标签也带有大量的信息,如某些负标签对应的概率远大于其他负标签,甚至会蕴含比正标签更多的信息。为了获得更多的负标签信息,知识蒸馏在原始Softmax函数中引入温度变量T,T值越大,则Softmax的输出概率分布熵越大,从而使得负标签携带的信息被相对放大。
(1)
式(1)中:qi为“软化”后的概率向量;zi为当前类的logit值;j为输出节点的个数,即分类的类别个数;zj为全连接层输出的每类的logit值。当T=1时,该函数就是原始Softmax函数。
知识蒸馏的过程如图4所示,图中C表示卷积层,P表示池化层,FC表示全连接层,软标签表示经过调整的标签值,硬标签表示实际的标签值(也就是真实标签),软预测表示经过调整的Softmax输出向量,硬预测表示原始的Softmax输出向量。知识蒸馏首先训练教师网络模型。教师网络中的logit输出除以T参数之后做Softmax计算,得到软标签值;然后,将数据集输入到学生网络中,重复教师网络相同的操作并得到logit输出。
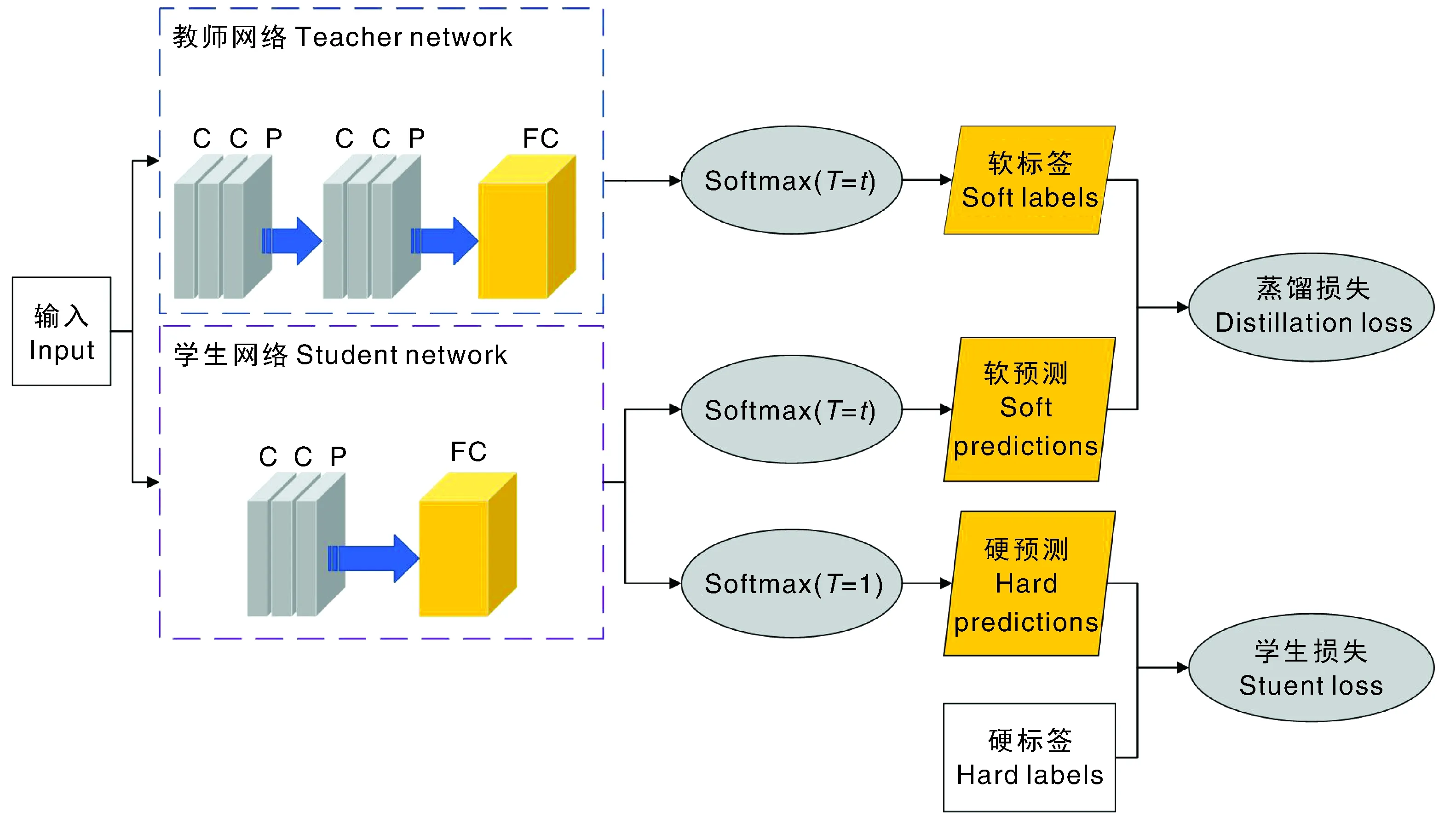
C,卷积层;P,池化层,FC,全连接层。下同。C, Convolution layer; P, Pooling layer; FC, Fully connected layer. The same as below.图4 知识蒸馏过程示意图Fig.4 Diagram of knowledge distillation
之后,分成两步计算:一是除以与教师模型相同的T参数之后做Softmax计算,得到软预测,将此输出与软标签进行比较,用蒸馏损失函数衡量两个概率分布的差异;二是做Softmax计算后,得出硬预测值,将硬预测值与硬标签进行比较,用学生损失函数衡量二者之间的差异。两部分损失函数相加,得到总的损失函数,计算公式为
Vloss=(1-a)Vloss-SL+aT2Vloss-KD。
(2)
式(2)中:Vloss为总损失函数的值;Vloss-SL为学生损失函数的值;Vloss-KD为蒸馏损失函数的值;a为比例系数,是控制两个损失函数的超参数。当a=0时,相当于网络没有经过蒸馏。
1.3.3 助教网络
为了能将模型部署在终端设备上,学生网络的大小通常是固定的。如果把一个预先训练好的大型教师网络的知识提炼到一个固定的、非常小的学生网络,那么其过大的差距将导致知识提炼的效果不如预期。为了解决这一问题,本文在教师网络和学生网络之间,插入一个中等规模的助教网络(图5)来弥补它们之间的空白。
助教网络是从教师网络上提炼出来的,用以扮演老师的角色指导训练学生。当教师模型和学生模型的差距很大时,还可以让助教变成新的教师,以此来减小教师模型和学生模型之间的差距。助教网络的方法能够重复使用,即在教师网络和学生网络之间可以存在多个助教网络,从而有效解决教师模型和学生模型规模差距过大影响蒸馏效率的问题。本文使用知识蒸馏策略,将教师网络模型的软知识不断提炼到一个或多个较小的助教网络模型中,使得助教网络模型的精度更佳。
1.3.4 稀疏化训练
为了减小通道剪枝对模型效果的影响,模型在通道剪枝之前还需要进行稀疏化训练。本文通过对BN(batch normalization)层[28]的尺度因子γ施加l1正则化来进行稀疏化训练。BN层首先对每一批量的输入特征进行白化操作:
(3)
(4)
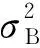
然后,进行去均值方差操作:
(5)
白化操作虽然能在一定程度上解决梯度过饱和的问题,但会忽略浅层网络学习到的信息。为了解决该问题,增加一个线性变换操作,计算公式为
(6)
式(6)中:yi为BN层的输出;γ和β为可训练的仿射变换参数,用于重新缩放和调整归一化值。
模型的稀疏化可以在训练时引入l1正则化进行,也可以在训练后通过少量训练加正则化获得。本文使用后一种方案,即在模型训练后进行稀疏正则化训练。在稀疏化训练中,为每个通道引入一个尺度因子γ,该比例因子可以与每一个通道的输出相乘,然后联合训练模型的权重和尺度因子γ,并对后者进行稀疏正则化。目标损失函数L的计算公式为
(7)
式(7)中:x为训练输入;y为训练目标;W为可训练权重;λ为平衡前后损失的超参数;Γ为缩放层的参数;g(γ)=|γ|,是对尺度因子γ的稀疏诱导惩罚;l()代表CNN正常训练的损失。本文使用l1范数,对于非光滑的l1惩罚项,采用次梯度下降法进行优化。通过稀疏化训练,尺度因子γ在训练过程中逐渐趋近于0。将最接近于0的尺度因子γ所对应的这部分通道剪掉,对模型效果的影响很小。
1.3.5 通道剪枝
稀疏化后,对所有的尺度因子γ进行统计和排序,设定剪枝率。将低于剪枝率比例的尺度因子γ所对应的这部分通道剪掉,即等价于把相对不重要的通道剪掉。通道剪枝过程如图6所示。
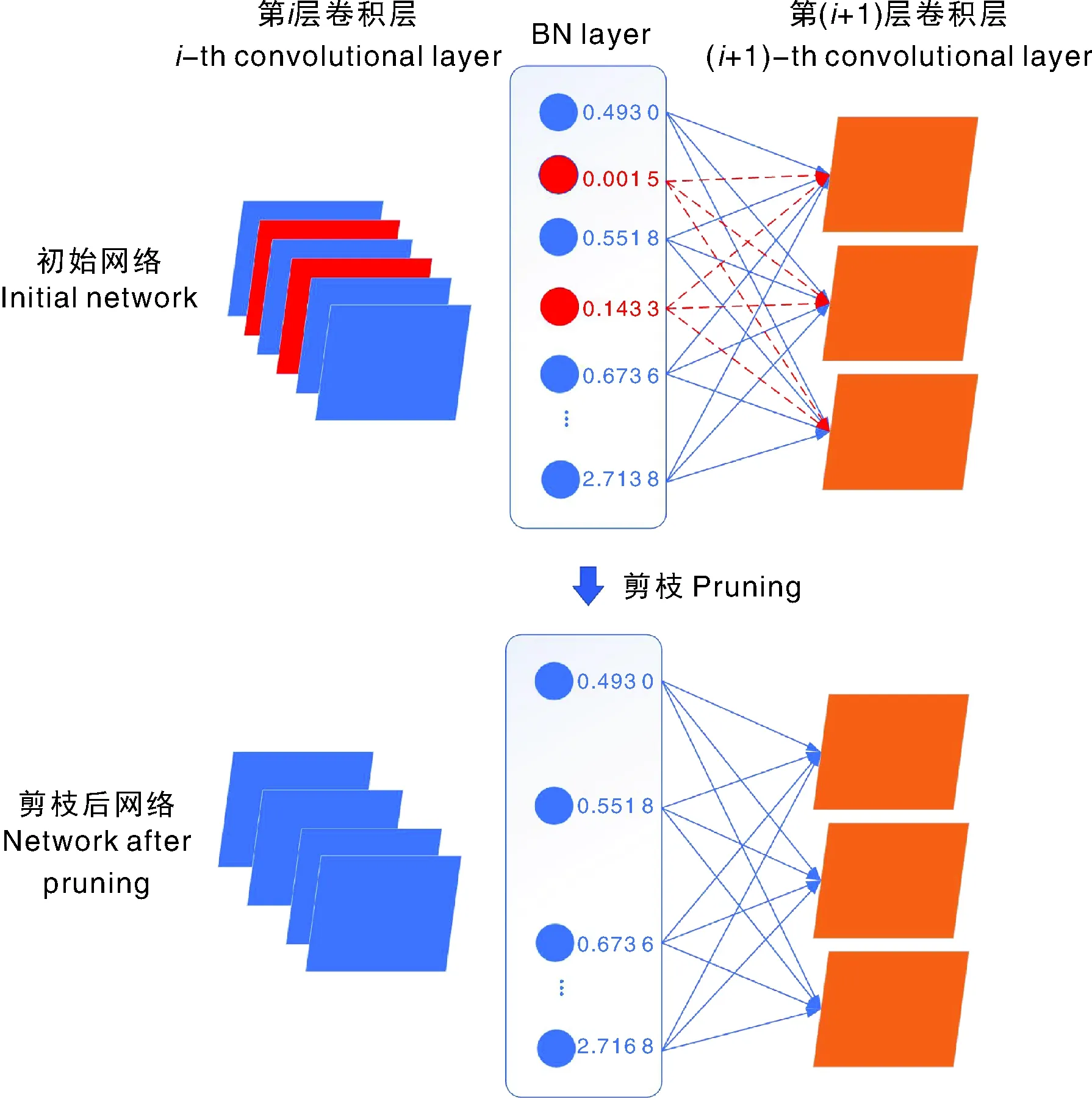
图6 通道剪枝示意图Fig.6 Diagram of channel pruning
本实验在剪枝之前已对模型进行了稀疏化训练,这使得在一定限度的剪枝率内,模型剪枝不会导致模型性能有太大的损失。通过修剪通道,可以获得更轻量化的网络,即更少的参数和计算量。值得注意的是,当剪枝率过高时,可能产生完全剪枝某一层所有通道的现象,这种情况将完全破坏模型结构,从而导致模型性能大大降低。因此,若存在某一层被完全剪枝的情况,应保留该层的最大尺度因子所对应的通道,以保证模型的完整性。
1.3.6 重训练
模型剪枝之后,模型的性能通常会降低;因此,需要重新训练剩余的模型结构以恢复模型性能,从而解决模型复杂度与性能矛盾的问题。常用的重训练包括微调、权重倒带(weight rewinding)[29]、学习率倒带。学习率倒带是微调和权重倒带的混合体。与微调一样,它使用训练结束时的最终权重值。然而,当重新训练t个epoch时,学习率倒带使用的是训练的最后t个epoch的学习率而不是训练的最终学习率。当t过小时,学习率倒带等同于微调。学习率倒带在所有情况下都与权重倒带的效果相当,甚至优于权重倒带。本实验使用学习率倒带来代替原本的微调。由于剪枝前后的网络模型结构相似,因此本文创新性地将助教网络蒸馏和学习率倒带结合起来,使用助教学习率倒带进行重训练。
1.4 实验环境
实验采用Python编程语言实现,操作系统是Window 10,GPU是NVIDIA GTX2080TI,显存11 GB,CUDA 10.0,使用的深度学习框架版本为PyTorch 1.10。Android开发软件为Android Studio,SDK(软件开发工具包)的版本号为32,PyTorch Android Lite的版本号为1.10.0。
1.5 实验设置
教师网络训练:模型训练中,设置批次大小(batch)为8,迭代次数(epoch)为100,初始学习率为0.1,当epoch达到50时设置学习率为0.01,当epoch达到75时设置学习率为0.001。
助教网络训练:设置温度变量T为5,比例系数a为0.5,其他优化设置与教师网络训练相同。
稀疏化训练:得到最终的助教网络模型后,再通过少量训练加l1正则化获得稀疏化的模型,此时少量训练的本质是使BN层的γ系数稀疏化,并且尽量不破坏卷积核权重的分布,因此训练的迭代次数不应过大。经实验分析后,本文使用0.001作为稀疏率,迭代次数为60,初始学习率设置为0.1,当epoch达到30时设置学习率为0.01,当epoch达到45时设置学习为0.001。其他优化设置与教师网络训练相同。
通道剪枝:分别以90%、70%和50%的剪枝率对ResNet-50、ResNet-26和ResNet-14进行修剪。为了保证模型的完整性,保留剪枝因子最大的通道。
重训练:本实验使用助教网络模型来指导学生网络模型的重训练,将助教学习率倒带的迭代次数设置为助教网络训练的一半,也就是50,前25次使用0.01的学习率,后25次使用0.001的学习率。其他优化设置与助教网络训练相同。
2 结果与分析
2.1 在多类植物病害数据集上的实验结果
在New Plant Diseases Dataset上,使用ResNet-(12*n+2)网络模型,训练ResNet-74为教师网络。参照文献[26]并经过实验发现,当模型的规模差距在2倍左右时效果较好,因此分别使用ResNet-50、ResNet-26和ResNet-14为最终的助教网络模型进行剪枝,并与同为轻量化设计的MobileNetV2模型进行对比。训练流程如图7所示。

图7 训练流程图Fig.7 Training flow chart
在ResNet-50模型上训练得到准确率为96.29%的模型(表3),剪枝90%后使用学习率倒带得到的模型准确率为95.65%。对于教师学习率倒带,把原ResNet-50网络当作教师网络,把剪枝90%后的网络当作学生网络,经过相同的配置重训练后,模型性能恢复的效果比学习率倒带更好,甚至超过了原模型的精度,通过教师学习率倒带恢复模型精度的模型准确率为96.52%。对于助教学习率倒带,训练ResNet-74为教师网络,由教师网络提炼出助教网络ResNet-50,对助教网络ResNet-50剪枝90%后得出学生网络,使用助教网络指导学生网络ResNet-50(剪枝后)的重训练,得到准确率为97.78%的模型,效果与教师学习率倒带相比有明显提高。
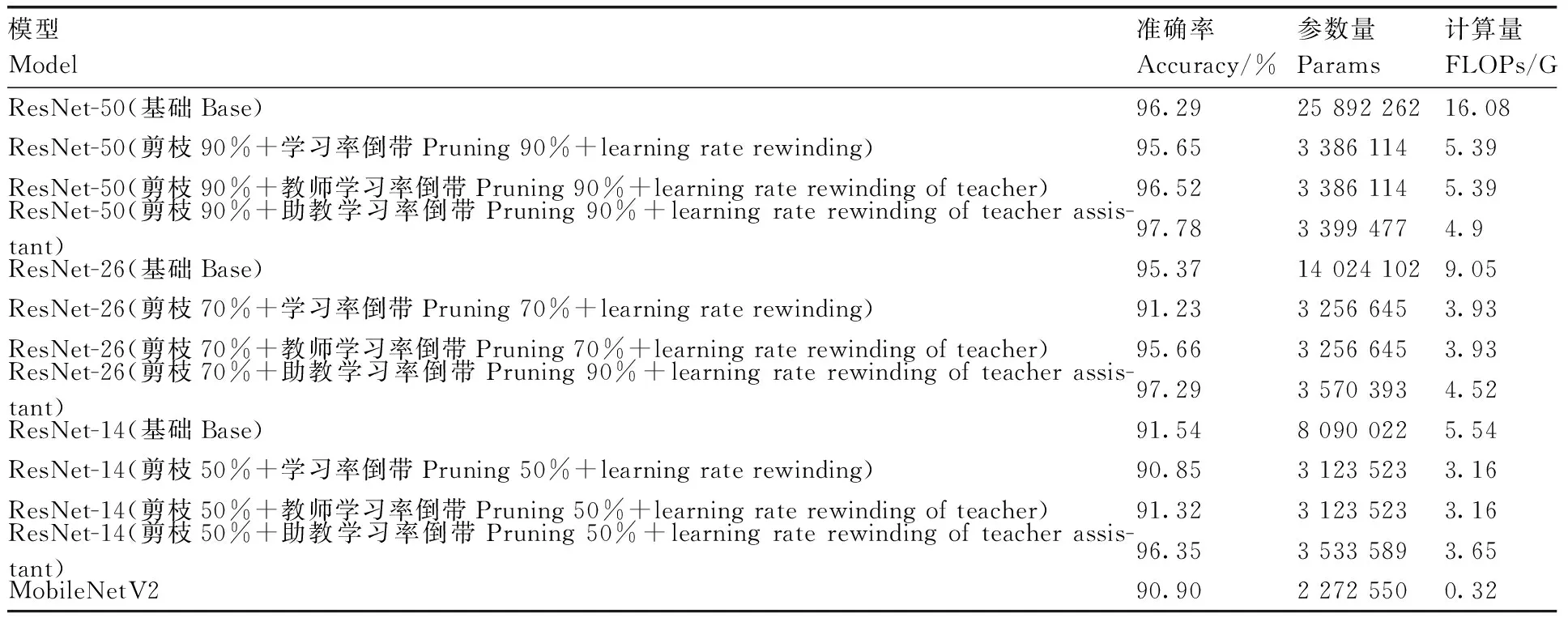
表3 在New Plant Diseases Dataset上的实验结果
在ResNet-26模型上训练得到准确率为95.37%的模型,剪枝70%后使用学习率倒带得到的模型准确率为91.23%。对于教师学习率倒带,把原ResNet-26网络当作教师网络,而把剪枝70%后的网络当作学生网络,经过相同的配置重训练后,模型准确率为95.66%。对于助教学习率倒带,训练ResNet-74为教师网络,由教师网络依次提炼出助教网络ResNet-50、ResNet-26,对助教网络ResNet-26剪枝70%后得出学生网络,使用助教网络指导学生网络ResNet-26(剪枝后)的重训练,最终得到准确率为97.29%的模型。
在ResNet-14模型上训练得到准确率为91.54%的模型,剪枝50%后使用学习率倒带得到的模型准确率为90.85%。对于教师学习率倒带,把ResNet-26网络当作教师网络,而把剪枝50%后的网络当作学生网络,经过相同的配置重训练后,模型准确率为91.32%。对于助教学习率倒带,训练ResNet-74为教师网络,由教师网络依次提炼出助教网络ResNet-50、ResNet-26、ResNet-14,对助教网络ResNet-14剪枝50%后得出学生网络,使用助教网络指导学生网络ResNet-14(剪枝后)的重训练,最终得到准确率为96.35%的模型。在MobileNetV2模型上训练得到的准确率为90.90%。
对比3种深度的模型剪枝实验发现:ResNet-50剪枝90%比ResNet-14剪枝50%后的参数量更小,模型效果更佳;使用大模型进行大剪枝率的剪枝效果比使用小模型进行小剪枝率的剪枝效果更好。因此,先训练大型模型,然后使用模型剪枝来将模型缩小是可行的。
为了将模型移植到移动终端,实验首先将原模型转换为Android可以调用的模型文件,再对模型进行移动终端优化,减少模型推理时间,最终导出lite解释器版本模型,保存模型,将其移植在Android平台上,实验效果展示如图8所示,表明模型能够移植在Android平台上并有效运行,为嵌入式终端精准识别植物病害提供了新方案。

图8 Android平台上识别多类植物病害数据集的效果照片Fig.8 Photos of the identification effect on the multiple plant disease dataset on the Android platform
2.2 在单类植物病害数据集上的实验结果
在苹果叶病害数据集上,使用ResNet-(12*n+2)网络模型,训练ResNet-74为教师网络、ResNet-26为最终助教网络进行剪枝,并与MobileNetV2模型进行对比。实验设置批次大小为4,其他优化设置与在New Plant Diseases Dataset上的实验相同。
训练ResNet-26模型,其准确率为87.09%(表4),剪枝70%后使用学习率倒带得到的模型准确率为89.10%。对于教师学习率倒带,把ResNet-26网络当作教师网络,而把剪枝70%后的网络当作学生网络,经过相同的配置重训练后,模型准确率为89.32%。对于助教学习率倒带,训练ResNet-74为教师网络,由教师网络依次提炼出助教网络ResNet-50、ResNet-26,对助教网络ResNet-26剪枝70%后得出学生网络,使用助教网络指导学生网络ResNet-26(剪枝后)的重训练,最终得到准确率为91.94%的模型。在MobileNetV2模型上训练得到的准确率为33.57%,模型效果不佳。分析发现,轻量化模型MobileNetV2欠拟合,拟合程度不高,模型简单,无法应对复杂的任务。苹果叶病害数据集中的所有病害叶片图像均在自然光照下拍摄,且背景复杂,而New Plant Diseases Dataset中的图像均是在室内拍摄,拍摄规范,背景简单。对比表2和表3数据可知,复杂背景会影响模型对植物叶片病害的识别效果,导致模型识别的错误率整体升高。在Androide平台上的实验效果展示如图9所示。
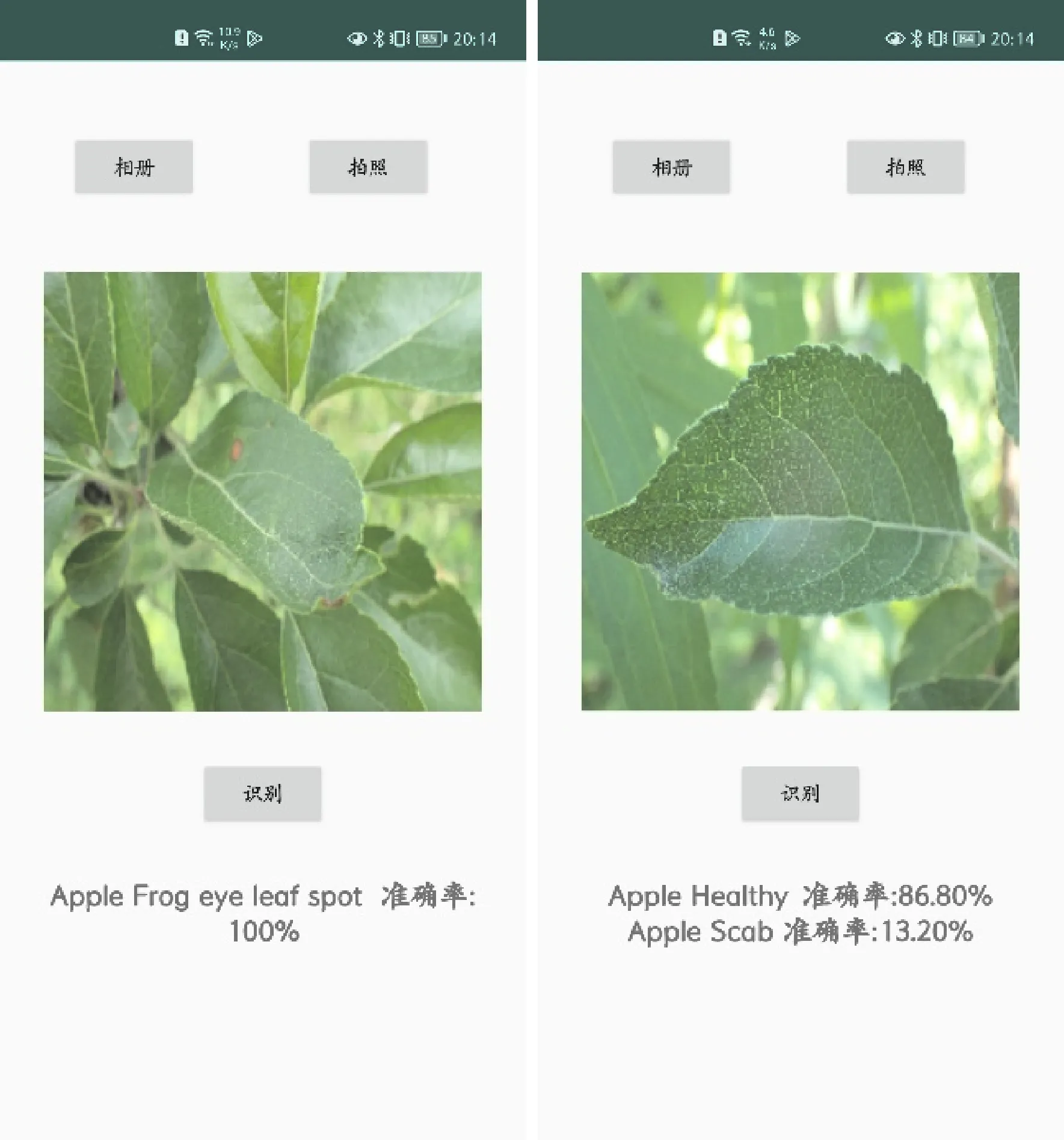
图9 Android平台上识别苹果叶数据集的效果照片Fig.9 Photos of the identification effect on the apple leaf data on the Android platform

表4 在苹果叶病害数据集上的实验结果
2.3 稀疏度设置对模型的影响
稀疏化训练是精度和稀疏度的一个平衡过程,如何寻找好的策略让稀疏后的模型在保持高精度的同时实现高稀疏度是值得研究的问题,尤其是当模型训练的时间过长的时候。
为了训练方便,模型使用更为轻量的ResNet-(9*n+2)训练ResNet-56模型,数据集使用CIFAR-10。CIFAR-10是一个用于识别普适物体的小型数据集,一共包含10个类别的RGB图片,每个图片的尺寸为32 pixel×32 pixel,每个类别有6 000张图像,数据集中一共有50 000张训练图片和10 000张测试图片。实验分别设置稀疏度为0.000 1和0.001,批次大小为16。其余设置与在New Plant Diseases Dataset上的实验相同。
在迭代次数为200的稀疏化训练中:在0.001的稀疏度下,一开始精度会有明显的急剧下降,之后有两次精度回升的节点(图10);在0.000 1的稀疏度下,精度先缓步下降,后期渐趋平稳。在迭代次数分别为100、60、40的稀疏化训练中:在0.001的稀疏度下,一开始精度会明显急剧下降,之后有一次精度回升的节点;在0.000 1的稀疏度下,精度先缓步下降,后期渐趋平稳。迭代200次后,0.001稀疏度下的训练精度比0.000 1稀疏度下的训练精度高;迭代100次后,0.001和0.000 1稀疏度下的稀疏化训练精度相仿;迭代60或40次,0.001稀疏度下的稀疏化训练精度均比0.000 1稀疏度下的训练精度低。
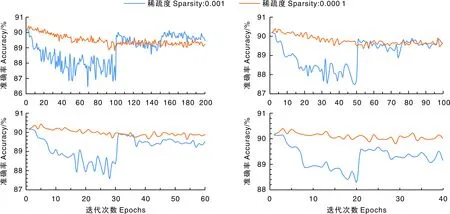
图10 不同稀疏度下模型准确率的变化Fig.10 Dynamic of accuracy under different sparsities
实验发现,在迭代次数为200的稀疏化训练中,两次精度回升刚好对应着两次学习率的调小变化;在迭代次数分别为100、60、40的稀疏化训练中,精度回升的位置都对应于迭代次数的50%,即学习率从0.1变化为0.01的时候。当使用大稀疏度时,虽然稀疏较快,但精度掉落得也快,之后随着训练的进行,精度会有一定的恢复,即前期配合大学习率会加快稀疏,后期改用小学习率有助于精度回升;当使用小稀疏度时,虽然稀疏较慢,但精度掉得也慢,较为平稳。
稀疏过程是个博弈过程,不仅期望较高的稀疏度,还希望在学习率下降后恢复足够的精度。经对比,本文使用迭代次数60、稀疏度0.001来进行稀疏化训练。
2.4 剪枝率设置对模型的影响
在模型剪枝中,剪枝率设置是非常关键的:如果删除了太少的通道,模型大小的减少非常有限;如果删除了太多的通道,可能会对模型造成严重的破坏,导致模型无法通过重训练恢复其准确性。本文通过在CIFAR-10数据集上分别使用ResNet-50和轻量化ResNet-56模型进行训练,来分析剪枝率对模型效果的影响。实验设置与在New Plant Diseases Dataset上的实验相同。
在对ResNet-56模型和ResNet-50模型的稀疏化训练采用0.001稀疏度、迭代60次完成后,对ResNet-56分别设置30%、40%、50%、60%的剪枝率,然后用助教学习率倒带进行重训练以恢复模型性能,恢复后的准确率依次为89.54%、91.41%、91.31%、90.19%(表5)。可以清楚地看到,剪枝30%时还有冗余参数,剪枝40%时效果相对最好,之后随着剪枝率上升,模型损伤越来越大。对ResNet-50模型分别设置50%、60%、70%、80%的剪枝率,然后用助教学习率倒带进行重训练以恢复模型性能,恢复后的准确率依次为85.99%、85.81%、85.59%、85.37%。可以看出,在一定的剪枝率内,剪掉冗余参数并不会降低模型精度,但当超过一定范围后,随着剪枝率的上升,对模型的损伤也进一步提高。
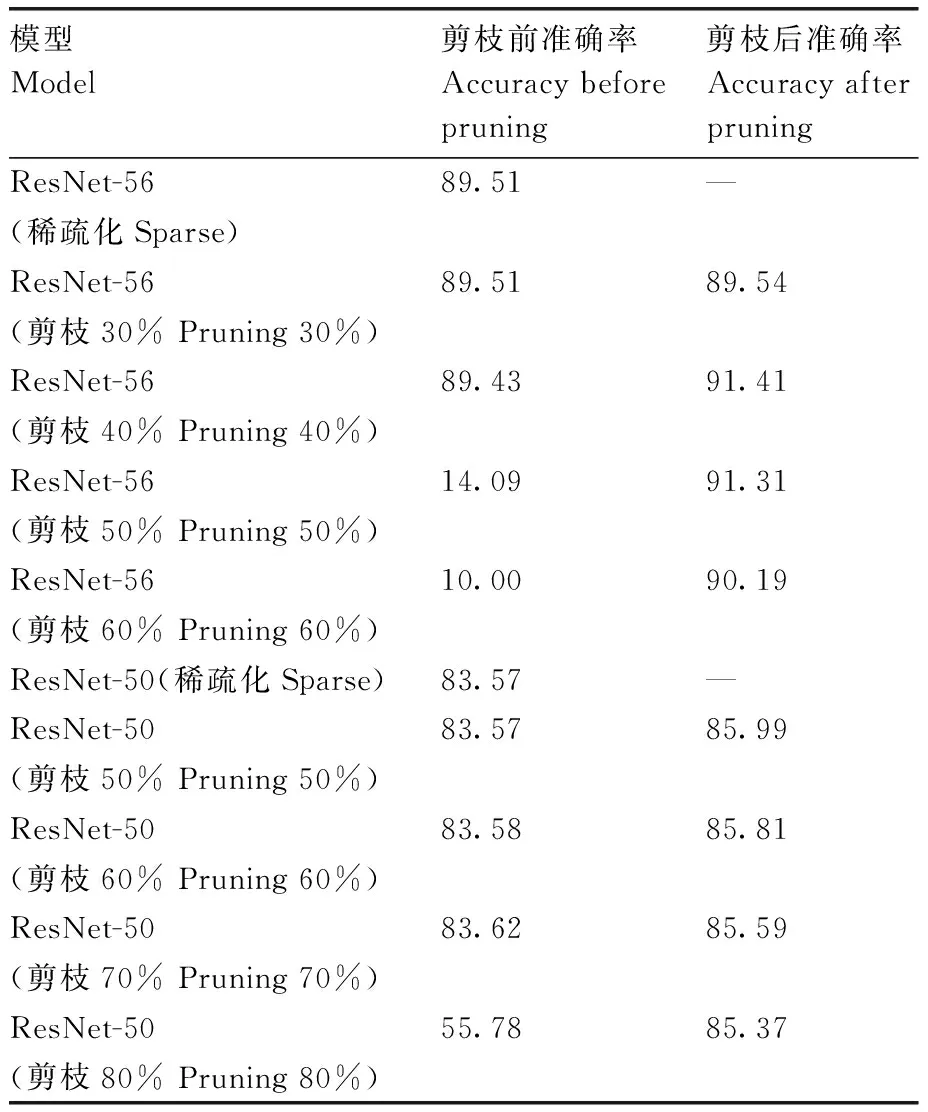
表5 剪枝率对模型的影响
2.5 各类植物病害的识别效果
为了分析ResNet模型对New Plant Diseases Dataset中不同类别植物病害的识别效果,以及结合使用知识蒸馏和学习率倒带的有效性,本文测试了模型对各个植物病害的识别结果(图11、图12)。
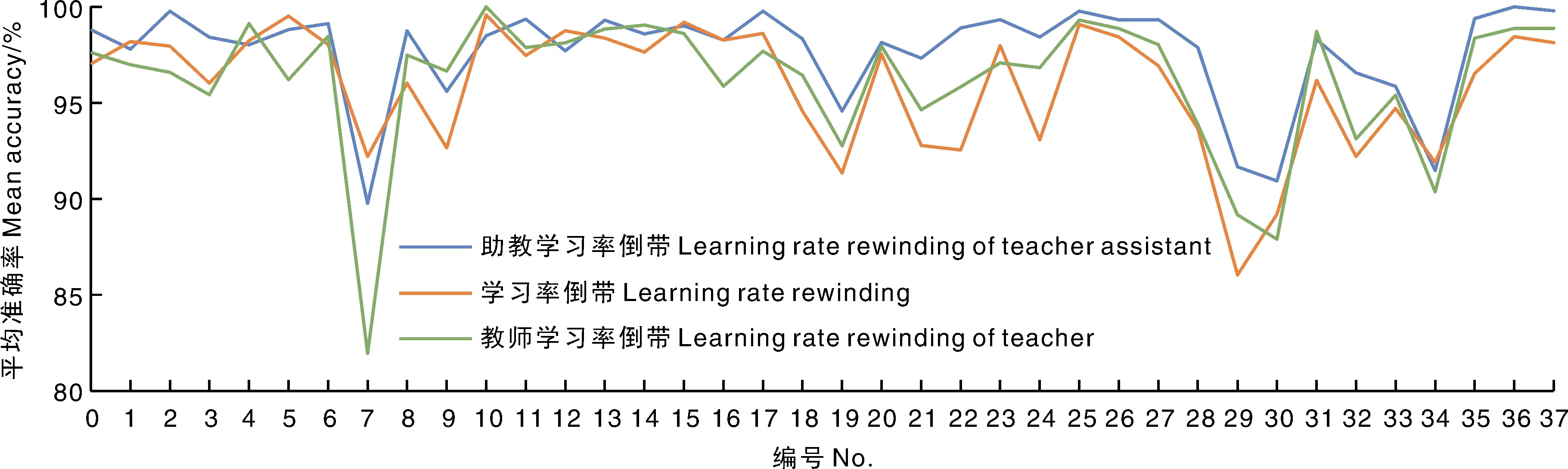
0,苹果疮痂病;1,苹果黑腐病;2,苹果锈病;3,健康苹果;4,健康草莓;5,樱桃白粉病;6,健康樱桃;7,玉米灰叶斑病;8,玉米锈病;9,玉米北方叶枯病;10,健康玉米;11,葡萄黑腐病;12,葡萄黑麻疹;13,葡萄叶枯病;14,健康葡萄;15,橘子黄龙病;16,桃菌斑;17,健康桃;18,胡椒铃菌斑;19,健康胡椒;20,马铃薯早疫病;21,马铃薯晚疫病;22,健康马铃薯;23,健康树莓;24,健康黄豆;25,南瓜白粉病;26,草莓叶焦病;27,健康草莓;28,番茄细菌斑;29,番茄早疫病;30,番茄晚疫病;31,番茄叶霉病;32,番茄叶斑病;33,番茄二斑叶螨病;34,番茄轮斑病;35,番茄黄曲叶病;36,番茄花叶病;37,健康番茄。下同。0, Apple scab; 1, Apple black rot; 2, Apple cedar rust; 3, Healty apple; 4, Healthy blueberry; 5, Cherry powdery mildew; 6, Healthy cherry; 7, Maize gray leaf spot; 8, Maize common rust; 9, Maize northern leaf blight; 10, Healthy maize; 11, Grape black rot; 12, Grape black measles; 13, Grape leaf blight; 14, Healthy grape; 15, Orange Huanglongbing; 16, Peach bacterial spot; 17, Healthy peach; 18, Pepper bacterial spot; 19, Healthy pepper; 20, Potato early blight; 21, Potato late blight; 22, Healthy potato; 23, Healthy raspberry; 24, Healthy soybean; 25, Squash powdery mildew; 26, Strawberry leaf scorch; 27, Healthy strawberry; 28, Tomato bacterial spot; 29, Tomato early bilght; 30, Tomato late blight; 31, Tomato leaf mold; 32, Tomato septoria leaf spot; 33, Tomato two-spotted spider mite; 34, Tomato target spot; 35, Tomato yellow leaf curl virus; 36, Tomato mosaic virus; 37, Healthy tomato. The same as below.图11 模型对各类病害的识别准确率Fig.11 Identification accuracy of ravious diseases by the proposed model
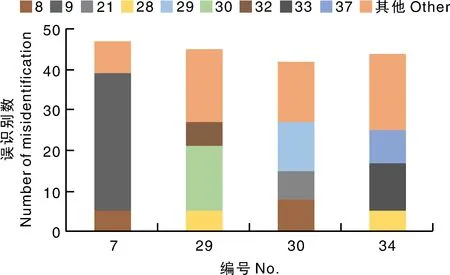
图12 错误率最高的4种病害在测试集上的误识别数量分布Fig.12 Quantity distribution of misidentifications of 4 diseases with the highest error rate
通过助教学习率倒带恢复的模型比学习率倒带和教师学习率倒带的效果更好。在对时间不敏感的情况下,助教学习率倒带与教师学习率倒带相比更有优势。结果表明,用助教学习率倒带来代替微调的方案是可行的,且效果普遍更好。
具体到各类病害上,模型对玉米灰叶斑病、番茄早疫病、番茄晚疫病和番茄轮斑病的识别准确率较低。玉米灰叶斑病很容易与玉米北方叶枯病混淆,后者占前者整体误识别数的大部分(占比72.34%)。究其原因,二者的叶片病斑均是沿叶脉方向扩展成长条斑或呈矩形,病斑颜色为灰褐色,相似度很高,易造成模型误识别。番茄早疫病容易被误识别为番茄细菌斑、番茄晚疫病和番茄叶斑病,这几种病害分别占前者整体误识别率的11.11%、35.56%、13.33%。究其原因,番茄早疫病和番茄晚疫病均是在叶尖处颜色开始发黑并腐烂,症状相似,易造成模型的误识别。番茄晚疫病也很容易被误识别为番茄早疫病。番茄轮斑病容易被误识别为番茄细菌斑、番茄二斑叶螨病或健康番茄,这几种情况分别占前者整体误识别率的11.36%、27.28%和18.19%。其原因是,番茄轮斑病的叶面有红褐色斑点,但并不明显;番茄二斑叶螨病主要是由二斑叶螨寄生在叶片的背面取食造成,二斑叶螨会使叶片变成暗褐色,两者叶片在病害特征上相近,叶片纹理相似,容易误判。番茄轮斑病的斑点并不明显,因此也很容易与健康番茄混淆,从而造成模型的误识别。
3 讨论
本文针对卷积神经网络模型存在冗余参数和推断时间长,难以直接应用于嵌入式终端的情况,提出了基于知识蒸馏和模型剪枝的轻量化模型植物病害识别方法,并使用改进后的ResNet网络结构在植物病害数据集上进行训练。主要结论如下:1)在知识蒸馏中引入一个或者多个助教网络,并通过对助教网络进行剪枝,可得出合适规模的学生网络。2)使用大模型进行剪枝的效果比小模型直接训练更佳,也比使用小模型进行小剪枝率的剪枝效果更优。3)学习率倒带的效果优于微调,结合助教网络蒸馏,剪枝后的模型性能比原模型更好。4)将原模型转换并保存为Android可以调用的模型文件,模型能够移植在Android平台上并有效运行。5)本方法可以灵活地根据需求缩减模型的大小,并通过助教学习率倒带恢复模型性能。在一定程度上对模型进行剪枝,不仅缩减了模型的大小,还提高了模型的性能,为模型应用在嵌入式终端上精准识别植物病害提供了可行方案。
本文提出的方法在两种数据集中完成实验,其中,New Plant Diseases Dataset的背景简单,效果较好;苹果叶病害数据集背景复杂,受到光照等复杂环境的影响,效果相对略差。但这两种数据集都是由公开数据集整理而成的,下一步,可以利用无人机或者边缘设备采集实际生活中的植物叶片数据进行处理和测试。此外,基于知识蒸馏和模型剪枝的轻量化模型植物病害识别可以与传统或者最新的深度学习方法相结合,以找到最适于边缘设备采集植物叶片的方法。
