弱光条件下猪舍清洗目标检测
2023-10-12李煜哲
李 颀,李煜哲
(陕西科技大学 电子信息与人工智能学院,陕西 西安 710021)
猪舍清洗是现代化养猪生产不可或缺的重要部分,目前国内畜牧业的智能化程度还处于低级阶段,对猪舍的清洗大部分仍是由人工完成的,耗费人力,效率较低。现有的智能清洗设备多依赖于进口且成本高,设备普及率低,不具有自适应性,且无法进行全方位清洗。因此,高效率、低成本、适应性广的猪舍清洗智能设备的开发是研究的热点之一。猪舍的清洗目标包括地面、墙面、栅栏、挡板、喂料器等,猪舍清洗设备结合清洗目标检测技术将会成为一个全新的技术点,根据检测到猪舍清洗目标的不同采取不同的清洗方式,使猪舍的清洗变得更加智能化。
因为猪舍内光线较弱,对比度差,所提取的清洗目标的特征信息不能有效利用,并且猪舍内清洗目标和背景的颜色较为相似,造成检测准确率低;因此,弱光条件下对猪舍清洗目标的检测存在一定的困难。目标检测算法分为2类,传统的目标检测算法和基于深度学习的目标检测算法。传统的目标检测提出的方法大多基于人工的特征提取,在计算复杂度高和场景复杂的情况下鲁棒性差。基于深度学习的目标检测算法是利用深度学习技术自动抽取输入图像的隐藏特征信息,对样本进行更高精度的分类和预测,与传统算法相比,基于深度学习的目标检测算法具有速度快、准确率强、鲁棒性高的特点。目前基于深度学习的目标检测算法分为两阶段(two-stage)目标检测算法和一阶段(one-stage)目标检测算法[1]。两阶段目标检测算法在第一阶段生成区域建议,在第二阶段对感兴趣区域的内容进行分类和回归,对目标的识别精度较高但是速度较慢,常见的算法有R-CNN(region-convolutional neural network,区域卷积神经网络)[2]、SPP-Net(spatial pyramid pooling network)[3]、Fast-RCNN[4]、Faster-RCNN[5]等。一阶段目标检测算法将目标任务看作是对整幅图像的回归任务,相比于两阶段算法识别精度低,但是速度快,常见的算法有YOLO(you only look once)系列的算法[6-8]、SSD(single shot multibox detector)算法[9]。
猪舍的清洗目标包括地面、墙面、挡板、栅栏、喂料器等,本文主要对栅栏、挡板、喂料器这3种清洗目标进行检测识别。针对猪舍环境光线较弱导致检测准确率下降的问题,本文采用基于双边滤波的retinex算法在输入检测网络之前对输入图像进行预处理,减小弱光条件对猪舍内图像检测的影响[10]。由于在猪舍进行清洗时对设备的实时性要求较高,本文采用一阶段目标检测算法Yolov5对猪舍内的清洗目标进行检测识别。猪舍环境中,清洗目标和背景颜色相近,导致猪舍背景下清洗目标特征不明显、检测准确率低,本文采用改进的YOLOv5网络,在主干网络(backbone)中引入卷积注意力机制模块和通道注意力机制(convolutional block attention module,CBAM)以增强清洗目标在猪舍背景下的显著度[11],提高清洗目标的检测精度。在摄像头采集猪舍内图像的时候,由于拍摄角度问题,存在栅栏、挡板、喂料器之间的相互遮挡,导致漏检。本文对非极大值抑制(non-maximum suppression, NMS)算法进行改进,采用DIoU-NMS算法筛选出候选框,提高在遮挡情况下猪舍清洗目标检测的准确率。
1 YOLOv5目标检测算法
YOLOv5分为输入端(input)、主干网络、颈部网络(neck)、预测端(prediction)4个部分[12]。
input输入端采用mosaic数据增强的方式,自适应锚框计算和自适应图片缩放。mosaic数据增强采用4张图片通过缩放、裁剪、随机排布的方式进行拼接,丰富了数据集,增加了很多小目标,提高了鲁棒性;针对不同的数据集,设置初始的锚框值,在网络训练中,在初始锚框的基础上输出预测框,进而和真实值进行比对,计算两者差距,再反向更新,迭代网络参数,获得最佳锚框值。YOLOv5中锚框的初始设定值默认为(10、13、16、30、33、23 pixel),(30、61、62、45、59、119 pixel),(116、90、156、198、373、326 pixel)。在目标检测任务中,大特征图含有更多小目标信息,通常在大特征图上检测小目标,因此大特征图上的锚框数值通常设置为小数值,小特征图上数值设置为大数值检测大的目标。在目标检测算法中,根据图片大小不同,进行自适应图片的缩放填充,能够提升网络的推理速度。
backbone主干网络包含切片结构(focus)、卷积块(CBL)、跨阶段局部网络(cross stage partial networks, CSPNet)模块和空间金字塔池化(spatial pyramid pooling, SPP)模块。通过切片结构对图片进行切片操作,将高分辨率的特征图拆分成多个低分辨率的特征图,减少下采样带来的信息损失,在YOLOv5中将608 pixel×608 pixel×3 pixel的图片拆分成304 pixel×304 pixel×12 pixel的特征图,经过32个卷积核卷积得到304 pixel×304 pixel×32 pixel的特征图。在主干网络中卷积层(Conv)、归一化层(batch normalization, BN)、激活函数(leaky relu)构成了卷积块CBL。CSP模块是将原输入分支之后再进行concat操作,使模型能学习更多的特征,在降低计算量的同时保证准确性。YOLOv5设计了2种CSP结构:CSP1_X应用于主干网络中,CSP1_X将原输入分成2个分支,一个分支进行卷积操作使得通道数减半,另一个分支进行残差操作,然后连接(concat)2个分支,使输入与输出大小相同,同时学习到更多的特征;CSP2_X应用于颈部网络neck中,由于neck网络深度较浅,CSP2_X将CSP1_X中的resunit换成了2×X个CBL。空间金字塔池化SPP结构使用最大池化方式对不同尺度的特征图进行融合,提高感受野的尺寸,提取猪舍清洗目标的重要特征,节省计算成本。
neck采用特征金字塔(feature pyramid networks, FPN)结构和金字塔注意网络(pyramid attention network, PAN)结构,如图1所示。YOLOv5使用3种特征图(19 pixel×19 pixel、38 pixel×38 pixel、76 pixel×76 pixel)进行多尺度检测。FPN通过上采样的方式传递自顶向下的强语义特征,PAN通过下采样的方式传递自底向上的强定位特征,从不同的主干层对不同的检测层进行参数聚合,实现不同尺度的特征融合,将主干网络所提取的特征进行增强处理,对猪舍清洗目标的预测更加精准。
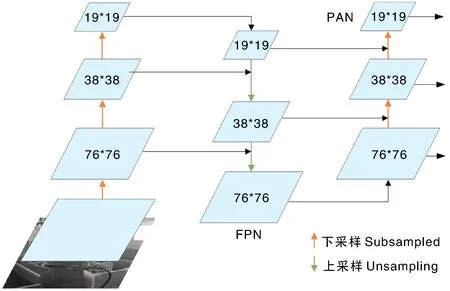
图1 特征金字塔(FPN)+金字塔注意网络(PAN)结构Fig.1 The structure of feature pyramide network (FPN)+pyramid attention network (PAN)
prediction通过损失函数和非极大值抑制预测目标边框。使用CIoU_Loss算法计算边界框回归损失,非极大值抑制(NMS)用于去除重叠的检测框,保留概率最大的候选框作为最终的预测框,输出包含预测图像中的清洗目标位置和分类信息向量。
2 改进的YOLOv5猪舍清洗目标检测算法
本文对弱光条件下猪舍的栅栏、挡板、喂料器进行检测,清洗目标如图2所示。在输入YOLOv5网络之前先采用基于双边滤波的retinex算法对采集的猪舍内图像进行增强,减小弱光条件下对猪舍内图像的影响,经过预处理后将处理过的图片送入目标检测网络。将CBAM模块引入YOLOv5模型的backbone主干网络中,增强清洗目标在猪舍背景下的显著度,使网络能够提取出更多特征信息,提高对清洗目标的检测准确率。为处理遮挡的问题,边界框回归损失选用CIoU损失函数对模型进行收敛,采用改进的DIoU-NMS算法筛选出候选框。改进的YOLOv5算法框架如图3所示。

图2 猪舍清洗目标Fig.2 Piggery cleaning target
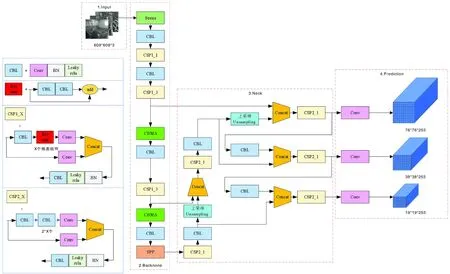
Conv,卷积;BN,归一化;CBL,卷积块;CSPNet,跨阶段局部网络;SPP,空间金字塔池化;Concat,张量拼接;Leaky relu,激活函数;Res unit,残差组件;CBAM,轻量级的卷积注意力模块。Conv, Convolution; BN, Batch normalization; CBL, Convolution block; CSPNet, Cross stage partial networks; SPP, Spatial pyramid pooling; Concat, Concatenates tensors; Leaky relu, Activation function; Res unit, Residual component; CBAM, Convolutional block attention module.图3 本文改进的YOLOv5算法框架Fig.3 Algorithm framework of the improved YOLOv5 network
2.1 基于双边滤波的Retinex猪舍图像增强
Retinex是一种通过模拟人的视觉系统调节图像颜色和亮度的图像增强方法[13],若原始图像为S(x,y),亮度图像为L(x,y),反射图像为R(x,y),由于人的视觉模型和对数域模型相似,可以得到单尺度的Retinex算法公式,如式(1)所示。
Ri(x,y)=logSi(x,y)-log[G(x,y)*Si(x,y)]。
(1)
式(1)中:i是第i个颜色通道,单通道图像的i=1,*表示卷积运算;G(x,y)为标准高斯环绕函数,其计算方法如式(2)所示。
(2)
式(2)中:λ满足∬G(x,y)dxdy=1;σ是尺度参数。
双边滤波(bilateral filter)的核函数是空间域核和像素范围域核的综合结果,能够较好保存边缘效果。双边滤波定义如式(3)所示。
(3)
归一化参数如式(4)所示。
(4)
式(3)、(4)中:c(ξ,x)表示临近点ξ与中心点x之间的距离;s[f(ξ),f(x)]表示临近点ξ与中心点x之间的亮度相似度如式(6)所示;f(x)和h(x)分别表示输入和输出图像在中心点x的亮度值。
将双边滤波扩展到高斯核:
(5)
(6)
式(5)、(6)中:d(ξ,x)表示2点之间的欧氏距离;δ[f(ξ),f(x)]表示2个亮度值之差。
基于双边滤波的Retinex算法实现首先是在输入图像到网络之前,通过单尺度Retinex算法对猪舍内图像取对数,然后做局部对比度增强,提高图像的对比度,为更好地控制图像亮度效果,同时对取对数后的猪舍图像采用基于双边滤波的亮度估计方法估计亮度。基于双边滤波的Retinex算法工作流程如图4所示。

图4 基于双边滤波的Retinex猪舍图像增强算法Fig.4 Retinex piggery image enhancement algorithm based on bilateral filtering
利用基于双边滤波的Retinex图像增强算法,对弱光条件下猪舍的图像进行增强处理,效果如图5所示。

a,图像增强前;b,图像增强后。a, Before image enhancement; b, After image enhancement.图5 猪舍弱光图像增强Fig.5 Low-light image enhancement in the piggery
2.2 backbone主干网络引入注意力模块
由于猪舍环境中清洗目标和背景颜色相似,清洗目标的特征不明显,对猪舍清洗目标的检测较为困难。为加强对猪舍清洗目标的检测能力,通过在YOLOv5模型的backbone结构中引入注意力机制,节省计算资源,加强算法对清洗目标的特征提取,关注重要特征,对一些不必要特征进行过滤,引入的CBAM结构如图6所示。
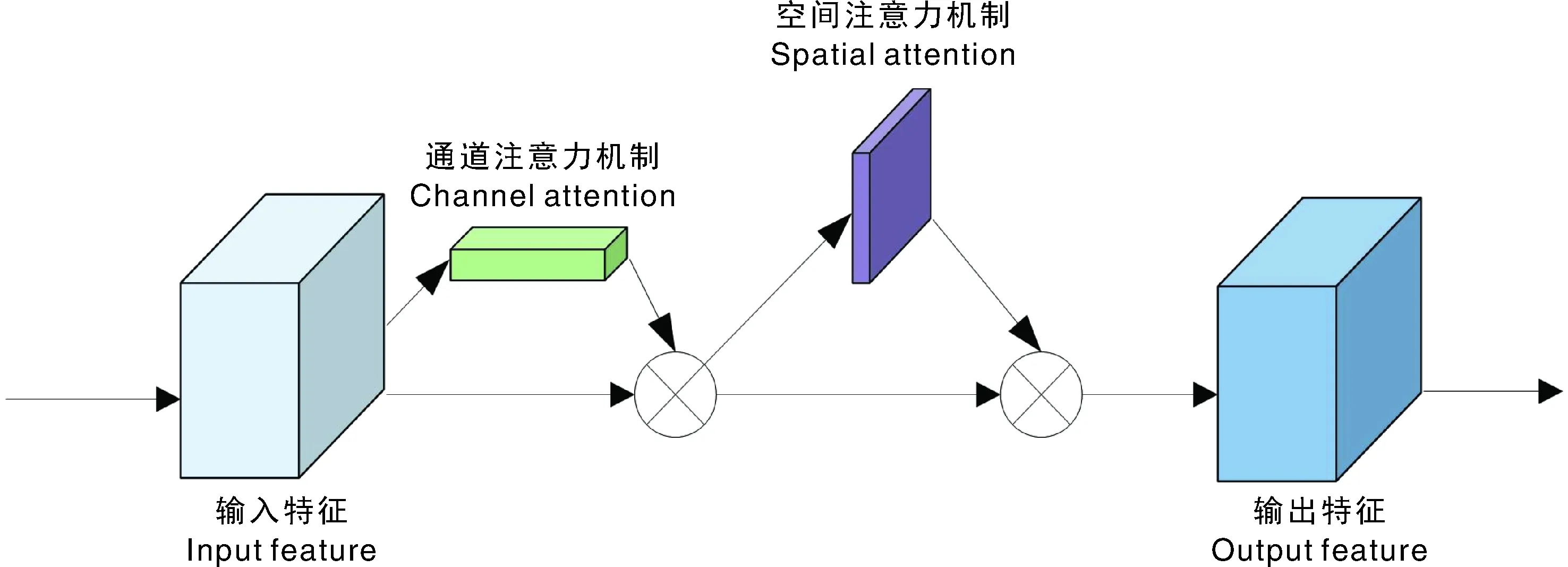
图6 CBAM模块基本结构Fig.6 The structure of CBMA model
通道注意力机制通过特征内部之间的关系来实现。特征图的每个通道都被视作一个特征检测器,所以通道特征聚焦的是图像中有用的信息是什么。为更高效地计算通道注意力特征,压缩特征图的空间维度,将输入的特征图经过并行的平均池化(AvgPool)和最大池化(MaxPool)层,使提取到的猪舍清洗目标特征更全面、更丰富,通道注意力机制公式如式(7)所示。
Mc(F)=σ{MLP[APool(F)]+MLP[MPool(F)]}
(7)
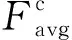
空间注意力机制通过对特征图空间内部的关系来产生空间注意力特征图,空间注意力聚焦于特征图上的有效信息在哪里。为计算空间注意力,首先在通道维度平均池化和最大池化,然后将他们产生的特征图拼接起来,在拼接后的特征图上,使用卷积操作来产生最终的空间注意力特征图,计算如式(8)所示,f7×7是7×7大小的卷积核。
Ms(F)=σ{f7×7[APool(F);MPool(F)]}
(8)
式(8)中Ms(F)表示空间注意力特征。
2.3 改进边框回归损失函数
CIoU_Loss考虑目标框回归函数的3个重要几何因素——重叠面积、中心点距离和长宽比。CIoU损失函数如式(9)所示,b和bgt是两个矩形框的中心点,ρ表示两个矩形框的欧氏距离,c表示两个矩形框的对角线距离,v是衡量长宽比一致性的参数。
(9)
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要NMS操作。对于猪舍内出现的清洗目标,类似于挡板、栅栏、喂料器相互重叠或者遮挡的情况,本文采用DIoU-NMS的方式,通过考虑边界框中心的位置信息中心点较远的box可能位于不同的对象上,处理遮挡问题,效果优于NMS。DIoU-NMS的si决定一个box是否被删除,公式如式(10)所示。
(10)
式(10)中:si是分类得分;ε是NMS阈值;RDIoU是2个box中心点之间的距离。
3 结果与分析
3.1 实验数据与环境
由于本研究应用于畜牧清洗自动驾驶车,猪舍清洗目标的数据集来自河南新大牧业股份有限公司,每张图片中应至少包含所要检测的栅栏、挡板、喂料器这3种清洗目标中的1种,数据集中存在光线变化和清洗目标相互遮挡的场景。对采集到的数据做平移、旋转、变换操作,丰富数据集,提高模型的泛化能力与鲁棒性。数据集总共有30 000张,其中训练集有21 000张,测试集5 000张,验证集4 000张。将图片尺寸缩放为608 pixel×608 pixel,利用Imglabel软件对图片中的清洗目标进行标注。
本文的算法是在深度学习框架Pytorch上实现的,实验所用硬件为单个具有16 GB内存的NVIDIA GeForce RTX 2080Ti GPU,操作系统为Ubuntu18.04,算法开发基于Python语言。本文实验过程中的网络模型参数设置:Batch_size为64,权重衰减因子为0.000 1,训练迭代次数为300,学习率初值为0.001。
3.2 评价指标
本实验中采取的猪舍清洗目标检测的评价标准包括检测准确率(预测结果为正类的样本占被预测为正类的样本的比例,precision,P)、平均准确度(mean average precision, mAP)、召回率(正确预测的正类样本所占原样本的比例,recall,R)。
(11)
(12)
(13)
式(11)~(13)中:P表示检测准确率;R表示召回率;PmA表示平均准确度;PT(true positives)表示实际为清洗目标且识别正确的个数;PF(false positives)表示实际为非清洗目标但被错误识别为清洗目标的个数;NF(false negatives)表示实际为清洗目标但是未检测为清洗目标的个数;AP(average precision)为精度-召回率曲线下的面积,表示在不同召回率上的平均精度;C是类别个数。
3.3 实验结果
对改进的YOLOv5算法进行训练,训练完成后绘制模型的损失函数变化曲线图,结果如图7所示,100次迭代后损失函数值剧烈下降,后200次迭代将学习率降为0.000 1,当迭代到300轮时趋于稳定,收敛在0.06左右,改进后模型的学习效果较为理想。
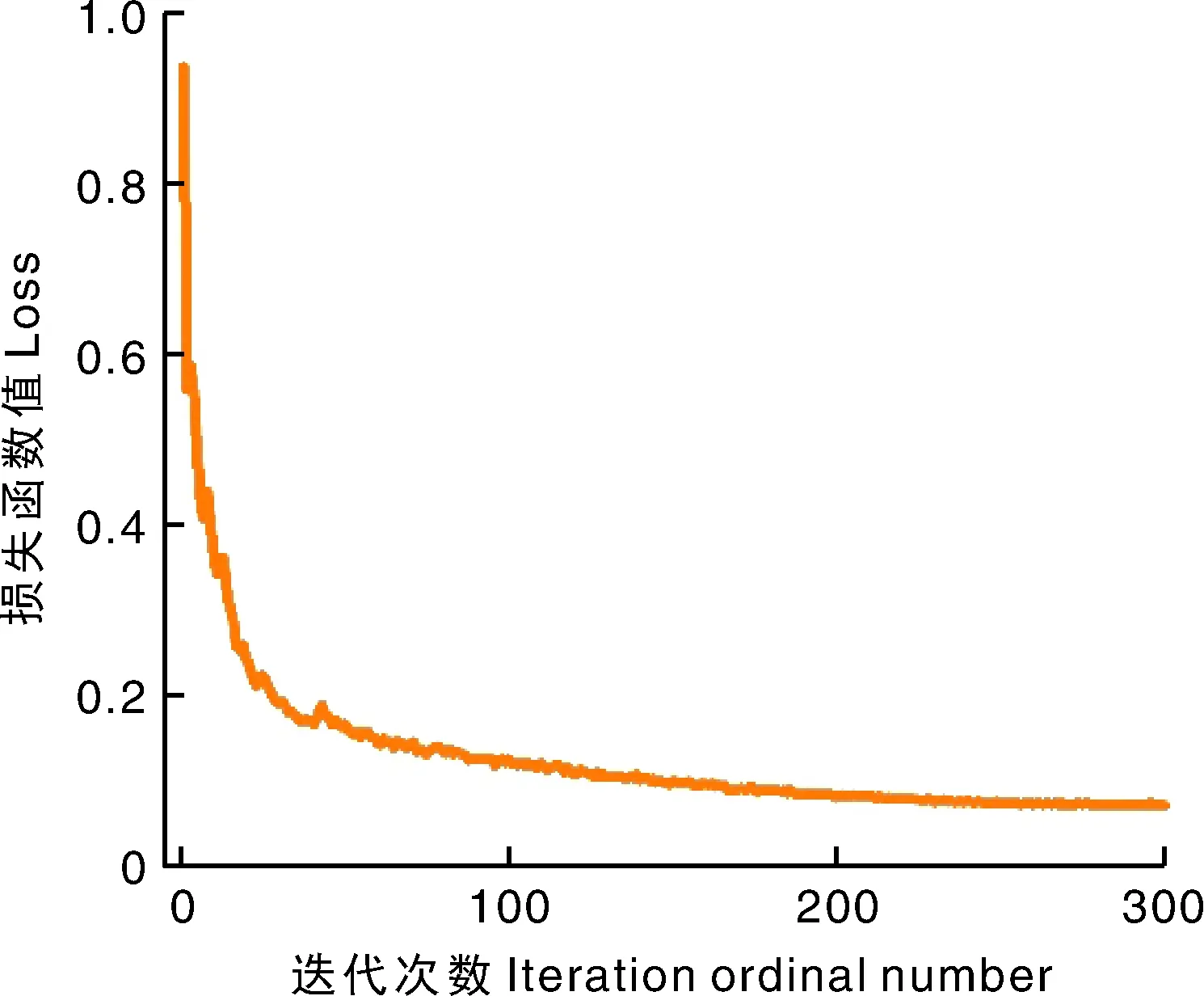
图7 模型的损失函数变化曲线Fig.7 Loss function change curve of model
为方便对改进效果进行分析,本文设计消融实验以验证各项改进的有效性,结果如表1所示。由表1可知,进行图像增强、添加CBAM模块和修改边框回归损失函数都提高了检测性能。在采集到的猪舍内图像输入检测网络之前进行图像增强,减小光线较差时对检测精度的影响,使模型的mAP提升了1.2百分点;通过加入CBAM模块,融合了沿通道和空间两种维度上的注意力权重,增大网络的感受野,加强了模型对于特征图中关键信息的关注,有利于特征图信息的表达,使网络学习到更多有效信息,网络模型的mAP指标提升了4.0百分点;最后将CIoU_loss作为目标边界框回归的损失函数,用DIoU-NMS算法筛选出候选框,使得在清洗目标部分遮挡时模型的定位更加精准,模型在原基础上mAP提高了0.5百分点。3种改进方法都会使模型的mAP有所提升,结合3种改进方式改进后的模型mAP为96.8%,相较于原YOLOv5的mAP提升了7.1百分点。证明该改进方法对于光线较弱、存在遮挡的清洗目标具有较好的检测效果。
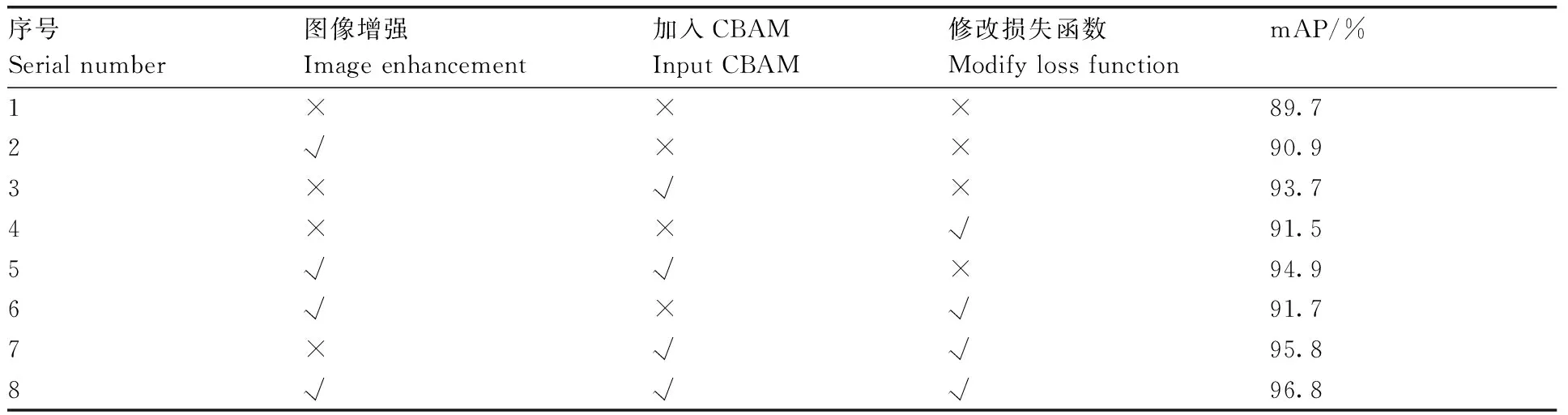
表1 消融实验结果
使用本文自采的猪舍清洗目标测试集,将本文算法同Faster R-CNN、SSD主流的检测网络模型做对比验证,得到的结果如表2所示。从表2可以看出,Faster R-CNN是两阶段网络,检测精度会比一阶段网络高,但是实时性较差,一阶段SSD网络的检测精度较低,但是检测速度方面高于Faster R-CNN。本文算法在检测速度上也有所提高,检测准确率和召回率上均有所提升,相较于双阶段目标检测网络Faster R-CNN平均准确度提高了2.7百分点,检测速度提升了17 FPS;相较于一阶段的SSD检测网络平均准确度提高了13.9百分点;相较于原始YOLOv5算法,检测准确率和召回率分别提高7.3和7.6百分点,平均准确度提高7.1百分点。在本文数据集上本文算法取得实验结果好于Faster R-CNN、SSD和原始YOLOv5算法。
为验证对猪舍图像的预处理是否能提高猪舍内清洗目标检测率,本文取存在光照较差、清洗目标存在栅栏和挡板之间部分遮挡情况的猪舍内场景视频进行检测。检测平均速度为30 FPS,弱光预处理前和预处理后检测对比结果如图8所示,对栅栏和挡板的检测置信度平均提高了0.03%。

图8 预处理前后清洗目标检测结果Fig.8 Target test results before and after pretreatment
为验证引入注意力机制改进YOLOv5算法和对改进后的YOLOv5算法边框回归损失函数对遮挡清洗目标检测准确率的提升,将FasterR-CNN、SSD、YOLOv5和改进前后的算法中存在遮挡情况的数据集进行对比,检测结果如图9所示。

a,无遮挡;b,部分遮挡且背景复杂;c,部分遮挡且背景简单。a, No occlusion; b, Partial occlusion and complex background; c, Partial occlusion and simple background.图9 不同算法遮挡情况清洗目标检测结果Fig.9 Clean target detection results for different algorithms
实验(a):目标无遮挡情况下,Faster R-CNN和改进后的YOLOv5算法对清洗目标的检测准确率高于YOLOv5和SSD算法。
实验(b):清洗目标部分遮挡并且背景复杂的情况下,相比于改进后的YOLOv5算法检测结果,SSD算法未能检测出遮挡的栅栏和挡板,YOLOv5算法未能检测出遮挡的栅栏,Faster R-CNN没有检测出遮挡面积较大的挡板。
实验(c):清洗目标部分遮挡并且背景简单的情况下,由于清洗目标与背景颜色较为相近,Faster R-CNN、SSD、YOLOv5对于遮挡的目标都存在漏检的情况,改进后的YOLOv5算法通过加入CBAM模块,提高了清洗目标的检测精度,较好地解决了漏检的情况。
当出现遮挡时,被遮挡的清洗目标部分特征消失,在遮挡发生的过程中,可对遮挡面积小于80%的清洗目标进行准确检测。从图9中可以看出本文方法对遮挡场景中栅栏和挡板可实现高精度的检测,由此可证明本文算法提高了检测的精度与鲁棒性。
4 结论
本文对猪舍中栅栏、挡板、喂料器3种清洗目标检测问题进行探究,首先,通过在河南新大牧业股份有限公司采集猪舍场景数据,构建了较为全面的清洗目标数据集,同时对采集的数据集进行扩充,将数据分为训练集、验证集和测试集;然后,为提高在弱光条件下对猪舍清洗目标的检测能力,采用基于双边滤波的Retinex算法对输入图像进行预处理,减小弱光条件对猪舍内图像的影响;最后,通过对YOLOv5算法的改进,在backbone中引入CBAM注意力机制来增强清洗目标在猪舍背景下的显著度,提高清洗目标的检测精度,采用DIoU-NMS算法筛选出候选框,提高清洗目标相互遮挡情况下猪舍清洗目标的检测准确率。实验结果表明,相较于YOLOv5算法,改进后的YOLOv5网络模型在弱光条件下和目标部分遮挡的情况下有更好的适应性,清洗目标检测的平均精度为96.8%,检测平均速度为30 FPS,满足猪舍进行清洗时对目标检测的实时性要求,为后续将猪舍清洗目标检测应用到畜牧自动清洗车中提供了良好的基础。
