基于事件的视觉SLAM综述
2023-10-12邹浩东郭金库白俊强
邹浩东,昌 敏,2*,郭金库,白俊强
(1. 西北工业大学无人系统技术研究院,西安 710072;2. 西北工业大学深圳研究院,深圳 518057)
1 引 言
近年来,无人机因其高机动性和日益完备的功能性而备受关注。但在一些复杂环境中,传统的传感器通信和感知能力都被严重限制,这导致无人机往往无法准确感知周围环境并做出正确的行动,因此,高性能的鲁棒的自主导航能力对于无人机的发展和应用具有重要意义。
同步定位与建图(Simultaneous Localization And Mapping,SLAM)是一种能够让机器人独立估计出自身在环境中的位置并同步构建出周围环境地图的技术,由Smith 在1986 年首次提出,后被广泛应用于增强现实、自动驾驶等领域。相机作为一种价格低廉、小体积、易部署、信息丰富的传感器,已成功应用于SLAM技术中,仅使用或主要使用相机作为传感器的SLAM 被称为视觉SLAM(Visual SLAM,VSLAM)。如无特指,本文中出现的SLAM均指视觉SLAM。
近些年,许多学者在视觉SLAM领域进行了大量研究,并取得了很多成果,提出的一些方案在定位精度、建图效果和鲁棒性等方面也有较好的效果,比如间接法方案ORB-SLAM3[1]、直接法方案DSO[2]以及半直接法方案SVO[3],支持多传感器融合的VINS-Fusion[4]等,都能鲁棒地完成实时自身定位与环境地图构建。但在高速、高动态范围等挑战性场景中,传统相机并不能很好地捕获环境信息,进而影响视觉SLAM方案的准确性和实时性。
事件相机(Event Camera)[5]是一种新兴的仿生传感器,其与传统相机最大的不同在于它并不以固定的帧率捕获图像,而是异步地响应视场范围内每个像素的亮度变化,这种输出被称为“事件”。一个“事件”一般包含亮度发生变化的位置、时间和极性。此外,比起传统相机,事件相机具有高时间分辨率(µs 级)、低功耗、高动态范围(140 dB)和高像素带宽(kHz 级)等优秀特性,从而可以减少运动模糊。因此,事件相机在无人机感知方面具有很大的潜力,目前事件相机已经应用于许多领域,如可在不受控的照明、延迟和电源下操作的可穿戴电子设备[6-7];目标跟踪、检测和识别[8-12];深度估计、结构光3D 扫描、光流估计[13-19];高动态范围(High Dynamic Range,HDR)图像重建[20-22]等。由于输出形式的特殊性,需要新的方法来处理“事件”这一形式的输出,从而释放其潜力。
本文首先对SLAM 技术进行概述,介绍当前比较成熟的事件相机种类,并简述其传感原理。然后,列举事件数据的不同表示方法,梳理基于事件的视觉SLAM 技术发展历程。最后,对基于事件的视觉SLAM 作了总结并展望了未来发展趋势。
2 SLAM技术及事件相机概述
2.1 SLAM技术概述
SLAM 的目标是自身定位与增量式环境构建,主要解决在未知环境中移动机器人的自主感知问题。SLAM 的主流技术框架如图1 所示,主要步骤包括:前端视觉里程计(Visual Odometry,VO)、后端优化、回环检测、建图。以下分别对这几个步骤进行概述。
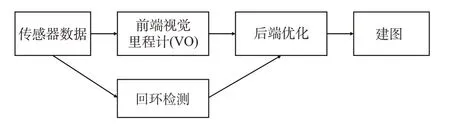
图1 SLAM技术框架Fig.1 Pipeline of SLAM
前端视觉里程计根据若干个连续时刻的传感器观测数据,给出当前时刻自身运动的估计,作为后端优化的初值。根据优化过程中误差的不同定义方式可将SLAM 方案大致分为间接法(Indirect Method)SLAM[23]和直接法(Direct Method)SLAM[2]。间接法也称为特征法(Feature-based Method),需要从相机捕获的图片中选出一定数量具有代表性的点或线,称为特征,再在不同帧中进行特征检测和基于相同特征描述子的特征描述与匹配(如图2 所示),以特征的重投影误差为优化目标进行相机的相对位姿优化,因此,当环境中纹理较少,特征不足的时候间接法容易失效。直接法则通过最小化光度误差对位姿和地图进行优化,不同于间接法只使用特征进行位姿估计,直接法往往会利用图像上大量像素点的光度信息,因此不需要对图像进行预处理,但此方法基于一个强假设,即灰度不变假设,因此在前后帧光照相差较大时直接法容易失效。一些学者结合两者优点,提出了半直接法前端视觉里程计算法[3]。

图2 当前双目图像对(下)与最新关键帧(上)的匹配[24]Fig.2 Match between the current stereo image pair (bottom)and the latest keyframe (top)[24]
后端优化就是对前端视觉里程计估计的状态进行进一步优化。SLAM 后端往往会把所有待优化变量放进一个统一的优化框架进行同时优化,问题可以简单表述为“从带噪声的观测求解状态的最优估计”。从实现手段的角度,后端优化主要分为滤波器法和非线性优化法。滤波器法基于马尔可夫假设,认为当前时刻状态仅基于上一时刻状态,核心在于对状态量不断进行更新和迭代。非线性优化法则同时考虑所有待优化的状态变量,最大化其后验概率。一般包括自身位姿和地图点的位置,对于一些特殊的系统而言,一些传感器参数也会加入优化过程。非线性优化法的核心在于构建一个以自身位姿、地图点位置为优化变量,以噪声方差为优化目标的最小二乘问题,这类似于恢复运动结构(Structure From Motion,SFM) 中的光束法平差(Bundle Adjustment,BA)。在早期,这种考虑所有状态的全局优化方法并不适用于SLAM,而后状态量之间的信息矩阵的稀疏性被发现,此方法也开始应用。
地图的内容主要取决于任务需求,主要有栅格地图、直接表征地图、点云地图以及拓扑地图等。
回环检测是让机器人能够识别出曾经到过的场景从而消除累计误差的步骤。在大场景中,这种只靠自身传感器实现定位的方法会存在越来越大的累计误差,对于单目系统甚至会出现尺度的累计误差。回环检测就是让机器人在运动到之前到过的位置的时候能够意识到自己到过,从而对系统的历史轨迹、地图等状态量做一次系统的修正,遏制更大的累计误差,目前比较成熟的回环检测方法是基于词袋模型(Bag-of-Words,BoW)进行判别。
2.2 事件相机概述
事件相机的前身是硅视网膜(Silicon Retina),自出现以来,已经有了多种商业化产品,其中最成熟、最典型的事件相机主要包括动态视觉传感器(Dynamic Viston Sensor,DVS)[25]、基于异步时间的图像传感器(Asynchronous Time-based Image Sensor,ATIS)[26]和动态有源像素视觉传感器(Dynamic and Active Pixel Vision Sensor,DAVIS)[27-28]三种,以下对这三种主要的事件相机进行介绍。
2.2.1 DVS
2008 年,Lichtstiner 提出第一个商用事件相机DVS,DVS 的每个像素在连续时间内独立量化局部相对强度变化,从而产生峰值事件,图3 展示了其事件生成原理。
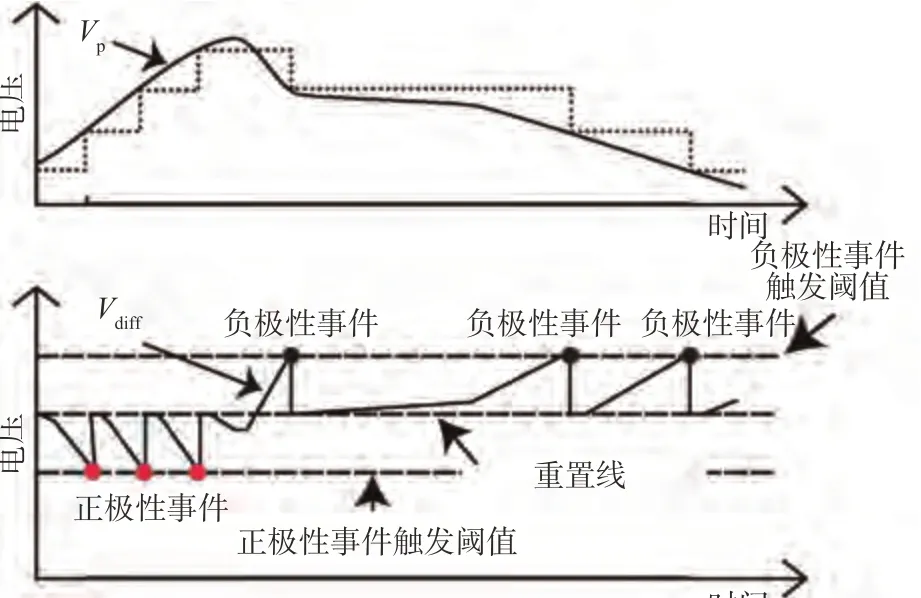
图3 DVS工作原理[25]Fig.3 Principle of DVS[25]
它将有源连续时间对数光感受器(Active Continuous-time Front-end Logarithmic Photoreceptor)、自定时开关电容差分电路(Self-timed Switchedcapacitor Differencing Circuit)和双晶体管比较器(Two-transistor Comparators)相结合,从而实现像素区域内的低错配、宽动态范围和低延迟。
2.2.2 ATIS
2011年,Posch等提出ATIS。ATIS基于有源像素阵列,其中每个像素包含基于事件的变化检测单元和基于脉冲宽度调制(Pulse-Width-Modulation,PWM)的曝光测量单元。其基于事件的变化检测电路基于DVS 像素单元,因此功能也是等价的。此外,当某像素的变化检测单元检测到一定幅度的亮度变化时,曝光测量单元就会启动新的测量从而得到强度信息,具体来说,当该像素上出现光照变化,其电容两端的电压下降,从高电平降至低电平的时间长短就代表该像素的强度大小。ATIS 只会在有光照变化,产生事件的像素输出强度信息,进一步提炼了视觉数据。
2.2.3 DAVIS
2014 年,Brandli 等提出DAVIS。DAVIS 的出现是为了将事件相机的高动态范围、亚毫秒级延迟等优秀特性应用于一些基于图像绝对强度信息的算法中。DAVIS 对DVS 和有源像素传感器(Active Pixel Sensor,APS) 进行了像素级的结合,以固定频率输出强度帧同时异步输出事件,如图4 所示。其与ATIS 的不同首先在像素的结构上,DAVIS 像素实现事件和强度帧共同输出的结构共用一个光电二极管,因此像素区域更小,更大的区别在于像素强度的捕获上,DAVIS 使用APS 同步曝光,而ATIS 则是事件驱动。表1 中比较了这几种事件相机的代表机型的性能。

表1 常见事件相机比较Table 1 Comparison between common events camera
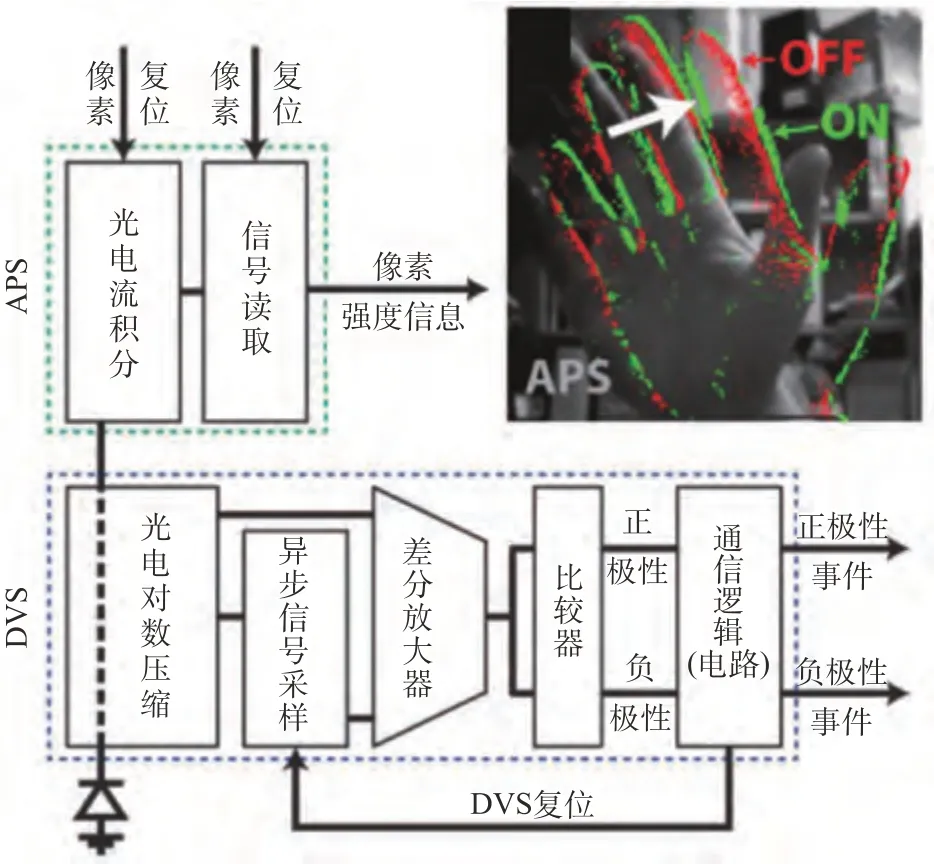
图4 DAVIS输出模式[27-28]Fig.4 Output mode of DAVIS[27-28]
3 基于事件的SLAM性能评估方法
3.1 SLAM性能指标
最常用的评估SLAM估计误差的指标是绝对轨迹误差(Absolute Trajectory Error,ATE)和相对误差(Relative Error,RE),本小节将对这两种误差作简要介绍并进行比较,同时一种更直观的可视化表示如图5所示。
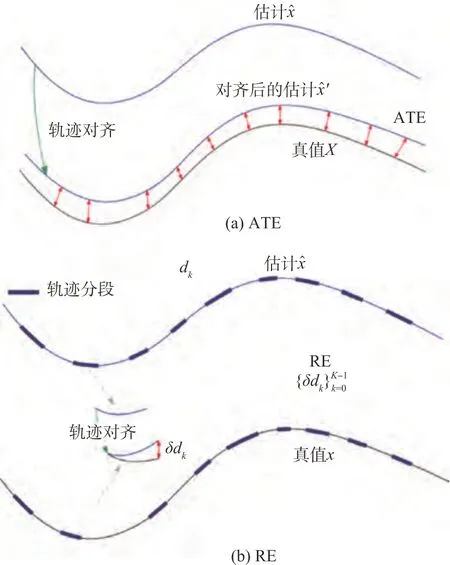
图5 绝对轨迹误差和相对误差图解[31]Fig.5 Illustration of ATE and RE[31]
3.1.1 ATE
其中,估计值与真值之间的相对旋转ΔRi、相对位置Δpi、相对速度Δvi可表示为
为了量化整个轨迹的误差水平,通常使用均方根误差(Root Mean Square Error,RMES)。
式中,∠(·)代表将旋转矩阵转换为角轴表示。
ATE 可以直接反映位置、旋转和速度误差的绝对大小,并且可以较容易地用于比较,但它对错误发生的时间很敏感,比如在轨迹伊始的旋转估计的误差比起结束时往往给出更大的ATE。因此,除了ATE,RE也被广泛用于SLAM的性能评估。
3.1.2 RE
VIO 系统是加入IMU (Inertial Measurement Unit)测量的VO系统,对于一个VO/VIO系统,全局位置和偏航角往往是不可获得的,因此可以通过测量不同时刻的状态之间的相对关系来评估状态估计的质量。
具体而言,对于一段轨迹,可以通过一些标准从所有状态量中选取几对状态
式中,e>s,每一对状态对应一段子轨迹。对于每个dk,相对误差δdk的计算方式与绝对轨迹误差类似。具体地说,定义和之间的误差需要先将进行轨迹对齐,该步骤通常通过Umeyama方法[32]完成
式中,{s′,R′,t′}代表轨迹对齐变换,满足
此时相对误差δdk可以定义为
因此,全部的状态对之间的总误差可以表示为
RE 的计算并不只生成一个数字来表征误差的大小,而是生成所有满足特定标准的子轨迹的误差集合,因此可以计算其中位数、平均值或RMSE 值等统计数据,相对于ATE 提供了更多的信息。通过定义不同的标准来选择加入误差计算的状态对,RE 可以具有不同的含义。一种常见的做法是选择沿着轨迹间隔一定距离的状态对,空间距离上接近的状态对的RE 反映了局部一致性,而空间距离较大的状态对的RE 则反映了系统长期运行的精度。RE 的缺点在于计算相对复杂。
3.2 事件数据集
SLAM 方案的研究和开发在很大程度上依赖于公开可用的数据集的数量以及质量,由于事件相机这种传感器的发展时间还比较短,带有事件数据的可用于SLAM的数据集也相对较少,本节对目前可用的包含事件数据的数据集进行了总结和对比,以便针对不同任务需求和基于不同硬件水平开展基于事件的视觉SLAM研究,具体信息见表2。

表2 包含事件的数据集对比Table 2 Comparison of datasets containing events
4 事件数据的处理方法
由于事件流这种特别的异步输出形式很难直接用于当前成熟的计算机视觉算法,为了从事件数据中提取到更多更有意义的信息从而完成后续任务,近年来许多学者根据不同的任务需求,用不同的方式表示或处理事件数据。现有的事件数据处理方法主要包括逐事件直接处理法、事件包处理法、事件流寿命估计处理法、事件帧处理法、时间平面处理法和运动补偿事件帧处理法,以下对这些处理方法进行整理。
逐事件直接处理法不对事件做预处理,直接投入后续步骤。以逐个事件作为输入的方法一般包括使用概率滤波器或者使用脉冲神经网络(Spiking Neural Networks,SNN),它们将一些由过去的事件构建的附加信息与新传入的事件数据异步融合以产生输出。SNN 是一种生物网络,专门处理以峰值形式而不是数值形式传递的信息。因其基于峰值的计算模型,可以处理来自基于事件的异步传感器的输出,而不需要任何预处理,与标准的人工神经网络(Artificial Neural Network,ANN)不同,功率极低。2018 年,Gallego 等设计了一种鲁棒的滤波器[42],直接以逐个事件作为输入,同时将贝叶斯估计、后验逼近和指数族分布与传感器模型相结合,将问题建模成一个时变系统,状态量包括事件相机的运动学描述,贝叶斯滤波器从观测数据递归地估计系统状态。2020 年,Gehrig 等首次提出了从事件相机给定事件的数值的时间回归问题[43],专门研究了带有SNN 的旋转事件相机的3 自由度(Degree Of Freedom,DOF)角速度的预测,该方法直接根据不规则的异步事件输入预测角速度,因此事件相机的高时间分辨率、高动态范围、无运动模糊的优点得以保留。
事件包处理法是一种汇集一批事件集中处理的方法。单个事件所携带的信息十分有限,所以汇集一批事件再进行统一处理是一种很自然的思想。实际上,汇集事件的方法往往是选取一个时间段,将这个时间段内的所有事件汇集成一个事件“包”,再交由后续处理。2012 年,Rogister 等所提出的一种解决运动物体上的立体匹配问题的算法[44]就是基于这种形式的事件数据处理。2016年,Rebecq 等提出EMVS (Event-based Multi-View Stereo)方法[16],采用事件包处理法解决了从一组已知视点估计密集3D 结构的问题(如图6 所示)。由于每个事件计算一次真实相机的位置再反投影的计算代价太大,该方法同样是将很多事件累积起来,进行批量的反投影计算。
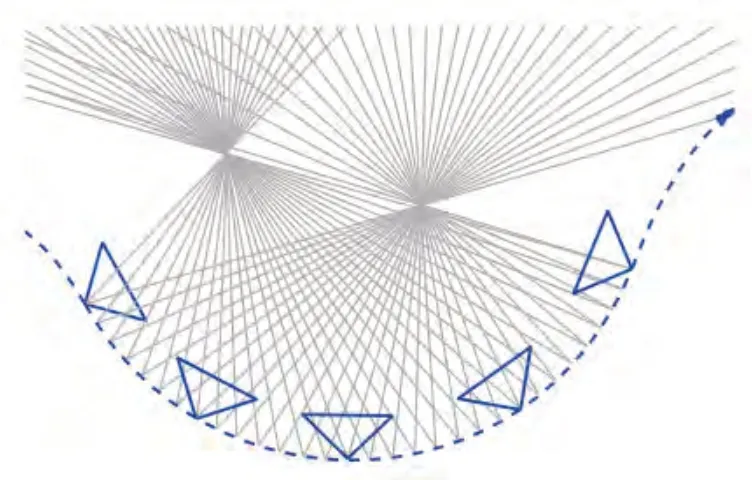
图6 EMVS恢复3D结构[16]Fig.6 3D reconstruction by EMVS[16]
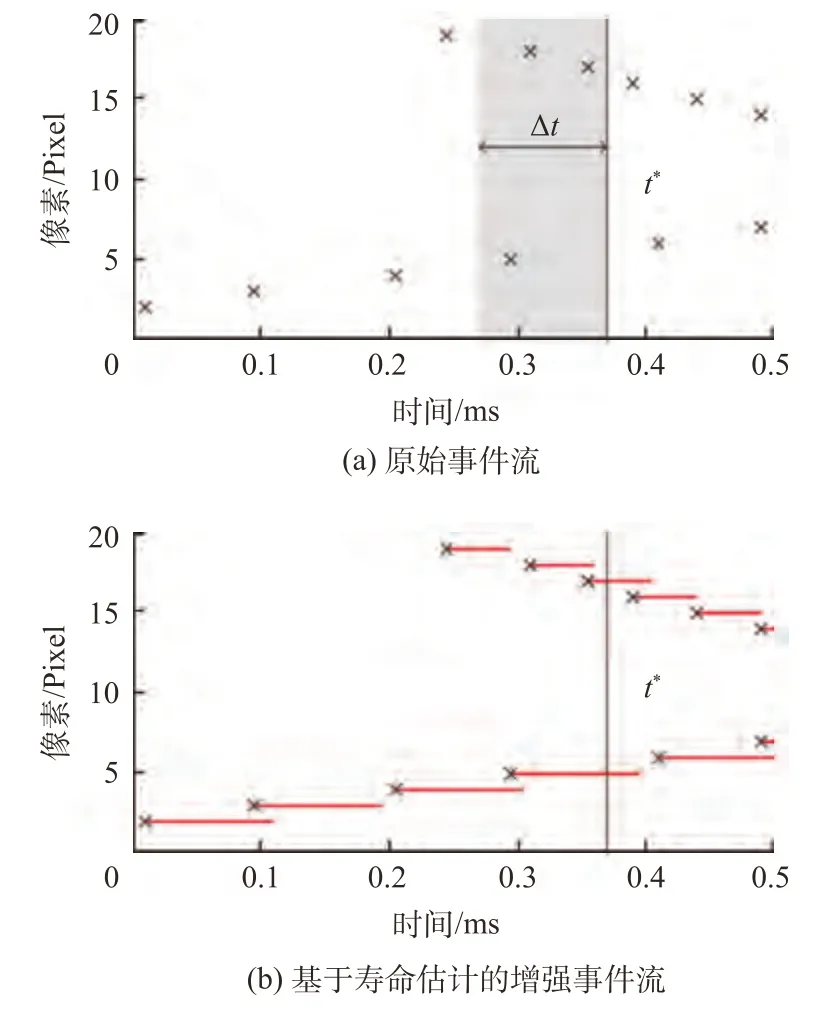
图7 事件的寿命估计[45]Fig.7 Lifetime estimation of the event[45]
事件流寿命估计处理法是一种将异步稀疏事件流变为时间上连续的增强事件流的方法。2015 年,Mueggler 等借鉴了基于事件的光流估计方法,开发了一种基于光流估计的事件流增强算法,其利用光流得到事件在图像平面上的速度,再基于运动速度扩展每个事件的生命周期,从而生成时间上的连续的增强事件流[45]。在此方法中(如图 7),生命周期τ表示当前事件位置的亮度梯度需要多长时间才能触发邻近像素中的新事件,对于噪声,生命周期为0。因此在这种表示法中,一个事件可表示为(xk,yk,tk,pk,τ,vx,vy),其中,xk,yk代表事件触发的像素位置,tk代表事件触发的时间戳,pk代表时间极性,τ代表该事件的生命周期,vx,vy代表事件在图像平面上的速度。即使对于某个时刻,输出也会包含附近时间段的所有事件同时还避免了运动模糊。通过这种表示方法,事件流的处理既可以使用传统的计算机视觉的方法,同时还避免了时间窗口的选择与优化。事件流变成了时间连续的,后续的事件处理算法可以以特定的时间间隔(时间窗口的起点和终点都可以任意选择)或选取某确定的时刻提取出事件进行处理。
事件帧处理法是一种将多个事件融合成一个图像帧的方法,融合得到的图像帧称为事件帧。这种方法以类似于传统强度帧的方式作为后续输入,从而适配成熟的基于传统图像帧的计算机视觉算法。2017 年,Rebecq 等提出的VIO 系统[46]中,通过选取时间窗口的方式将事件流分开,再将每个时间窗口内的事件融合成一个事件帧参与后续状态估计(如图8所示)。
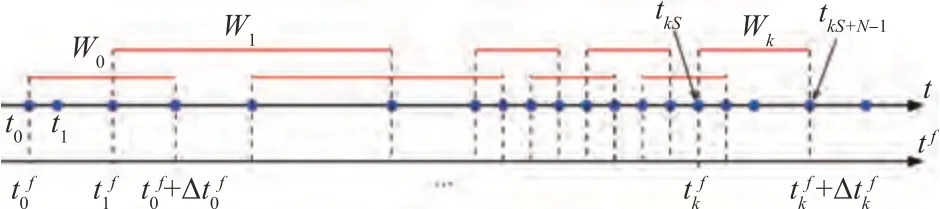
图8 通过选取时间窗口合成事件帧[46]Fig.8 Event frames by selecting a time window[46]
2018年,Liu等提出一种自适应切片累积方法实现多个事件融合成事件帧[47],此方案基于块匹配光流(Block-Matching Optical Flow,BMOF),方案流程如图9 所示,先将事件存储为2D 事件直方图,当有新事件触发,通过增加像素值将新事件累计到当前切片,累计结束之后,将每个切片的第一个事件的时间戳和最后一个事件的时间戳的平均值作为这个切片的时间戳,使用另外的两个切片根据当前事件位置计算光流(Optical Flow,OF)。此外,为使得单个切片上的事件的位移较小同时保证切片上事件不至太稀疏,该方案提出了一种新的切片轮转的方法,即同时利用前馈和反馈的方式控制来调整切片时间。其中,前馈切片轮转基于区域事件数量(Area Event Number),其规则是在区域的任何一个事件数超过阈值时触发切片轮转,这样更适应于动态场景,而反馈切片轮转的逻辑是在每次切片轮转之后创建一个空白的OF 分布直方图,然后用它来收集OF 结果,直到下一次切片轮转。反馈切片轮转的核心是计算直方图的平均匹配距离,如果大于搜索半径的一半,表示切片持续时间太长,从而降低切片阈值,反之增加。通过这种方式,切片时机随当前动态程度自适应调整,单个事件帧包含的信息足够丰富,亦能减少运动模糊。
图9 自适应切片轮转法[47]Fig.9 Adaptive slice rotation[47]
时间平面(Time-Surface)表示法是一种基于事件的二维地图表示,其中每个像素位置存放一个与时间相关的值,一般而言,这个值是该位置运动历史的函数,往往越大的值对应着越新的事件。2017 年,Lagorce 等首次提出事件的时间平面表示法[48],这种时间平面的生成过程大致如图10所示,图中(a)、(b)、(c)分别代表不同的运动,第一列代表运动方式,第二列代表ATIS 的响应数据,其中白点为“ON”事件,黑点为“OFF”事件,第三列则表示由第二列红圈中的事件获得的Time-Surface。使用这种表示法的优点是可以显式地体现事件的丰富的时间信息,并且可以实现异步更新,缺点在于因其高度压缩信息,每个像素只保留一个时间戳,因此对于像素频繁峰值的纹理场景,有效性会降低。与之类似,2018 年,Sironi 等提出一种方法将事件流转换为平均时间表面直方图[49],具体方法是使用本地内存单元来存储过去的时间信息,其应用是送入支持向量机(Support Vector Machine,SVM) 完成目标检测和识别。这种表示法可以认为丢弃了时间维度,但能做到异步更新。2021 年,Zhou 等提出一个双目事件相机系统[50],基于时间平面表示法,利用相机图像平面上事件的时空一致性(Spatio-temporal Consistency)来解决视觉里程计的定位和建图子问题。
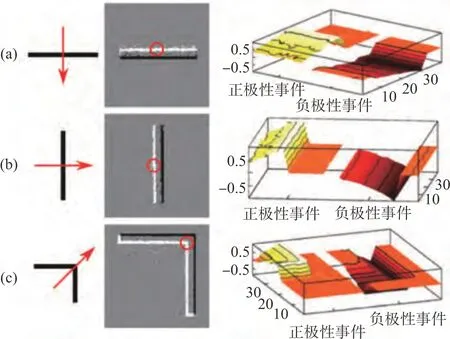
图10 事件的时间平面表示[48]Fig.10 Time-surface of events[48]
运动补偿事件帧表示法是一种基于相机自身运动估计的改进的事件帧表示法。普通的事件帧表示法是把大量异步事件融合之后得到一帧图像作为后续输入,这种简单的融合增加了信噪比,集成了大量信息,但在这些融合的事件中,有很多事件是“同源”的,即由同一物体在不同时间触发的事件,这种情况下,如果一个事件帧内融合的事件太多,就会导致运动模糊[46](如图11所示,左上图为标准图像,右上图为3000 事件合成的事件帧,信噪比较低,左下图为30000事件合成的事件帧,存在运动模糊,右下图是带有运动补偿的30000事件合成的事件帧),针对这种因同源事件产生的运动模糊,一个直接有效的方法是估计相机运动,对事件帧进行运动补偿。2017 年,Gallego 等提出一种运动补偿的思想[51],其认为当边缘在图像平面上运动时,它会在所遍历的像素上触发事件,因此可以将同源事件扭曲到同一个参考时间,再将其对齐进行最大化(即让其尽可能重合)从而估计边缘与相机本身的相对运动,进而产生扭曲事件的清晰图像。这种表示有一个衡量事件与候选运动拟合程度的标准,即扭曲事件产生的边缘越清晰,拟合效果越好。同年,Rebecq 等受这种方法的启发,利用IMU 实现事件帧的运动补偿,从而避免了因累积事件导致的运动模糊[46]。2019 年,Gallego等针对运动补偿,提出了22 种损失函数以分析运动补偿方法中的事件对齐,并在公开数据集上比较了这些损失函数的准确性和运行性能[52]。此外,由于这种运动补偿的思想是朴素的,所以除了应用于事件帧,还有学者将其运用在一些其他的事件数据表示法中,从而产生了基于运动补偿的点集表示法[53-54]以及基于运动补偿的时间平面表示法[55-56]。

图11 事件帧的运动模糊[46]Fig.11 Motion blur of the event frame[46]
5 基于事件的视觉SLAM技术
传统的视觉SLAM基于传统相机输出的强度图像帧,帧率较低,每一帧信息丰富,每个像素都有一个或多个数值代表不同通道的光强。基于此,传统的视觉SLAM技术针对这种输出形式发展出了很多特有的方法和概念,如特征检测、图像对齐等。事件与传统图像帧有着本质的不同,这也就导致这些方法和概念的不直接适用,因此,基于事件的视觉SLAM 算法往往和传统算法有较大差别。新的数据形式导致了传统算法的应用较为困难,但事件相机本身的高动态范围、低延迟、低功耗等优秀特性代表了其对运动和变化的高度敏感性,因此,其非常适用于视觉SLAM领域。本小节主要对基于事件的视觉SLAM技术进行回顾和梳理,表3 中对一些主要的框架进行了汇总。同时,本章分别对仅基于事件的SLAM和主要基于事件的多传感器融合SLAM的发展过程中的重要节点进行了梳理。
表3 一些基于事件的SLAM方案比较Table 3 Comparison of some event-based SLAM
5.1 仅基于事件的视觉SLAM
SLAM问题可以拆分成自身定位和环境构建两个子问题,在前期,事件数据的其他表示法还不成熟,基于事件的算法对两个子问题还不能兼顾,而是先聚焦于自身的6DOF定位,其中,最先发展起来的是对相机纯旋转问题的3DOF 估计。2011年,Cook 等提出一种在交互网络中通用的信息传递算法[21],不考虑平移,针对无人机的纯旋转问题,从事件流中同时估计自身运动、图像强度和光流。2012 年,Weikersdorfer 等提出一种基于事件的粒子滤波算法[57],这也是首个基于事件相机的姿态跟踪。该系统是实时运行的,并且只需要与使用的粒子数量成比例的最小内存要求。但在这项工作中,地图是需要提前构建和固定的,这对于现实世界的应用是一个严重的限制,地图应该由系统直接生成而不需要人工干预或提前准备。2013 年,Weikersdorfer 等提出一种基于事件的SLAM 方案[58],应用于二维场景,具体来说,其针对平面运动,即一个机器人在地面移动,并利用天花板上的特征完成自身定位(如图12 所示)。该方案在完成自身定位的过程中自动生成地图,是真正意义上基于事件的视觉SLAM系统。但这种方法基于一种过时的、低分辨率的事件相机模型,并依赖于完全体素化的尺寸有限的环境,这类概率方法的准确性高度依赖于深度更新的频率,因此限制了运动的速度。2014 年,Kim 等提出一种针对纯旋转的状态估计方法[22],其基于概率滤波、基于逐个事件实现相机自身的3D 姿态估计和场景的高分辨率高动态范围全景图生成。
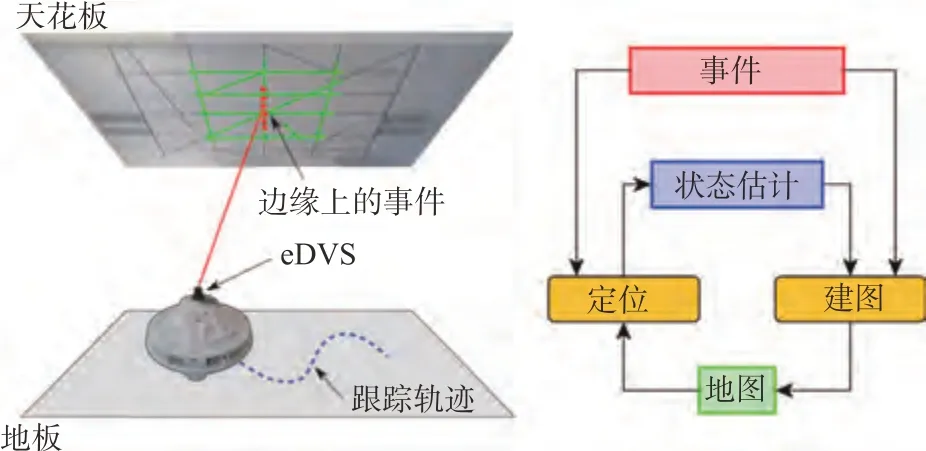
图12 基于事件的2D-SLAM[58]Fig.12 Event-based 2D-SLAM[58]
2017 年,Gallego 等提出一种估计自身旋转的方法,核心是以对比度最大化(Contrast Maximization)的方式通过边缘对齐进行运动估计,如图13 所示。该方案在百万级事件数据集中得到了验证,角速度误差大约为2%(标准偏差)和8%(最大偏差),并且可以跟踪非常高速的运动(≈1000°/s)。因为应用了滑动窗口方法[24],该方法可以以事件分辨率对应的速率提供角速度估计(1 µs)。

图13 最大化对比度估计旋转[51]Fig.13 Estimation rotation by Contrast Maximization[51]
2014 年,Mueggler 等提出一种位姿跟踪方案[60],仅使用DVS 完成自身完整的6DOF 位姿估计,成功演示了在高达1200°/s 的转速下成功的位姿跟踪;2015 年,Conradt 提出一种简单的从事件信息中提取光流的混合算法[72],这种算法将生物启发式的低级传感器和生物学信息编码与一种灵活的非大脑式(Non-Brain-Style)算法相结合,计算空间相邻像素之间的时间差来推测运动,作者将其应用于相机自身的运动估计,首先计算光流,然后计算角速度。
随着相关技术的不断发展,利用事件相机执行位姿跟踪所需的算力也在不断降低,在中央处理器(Central Processing Unit,CPU)上实时运行的位姿跟踪方案逐渐变得可行,构建地图所需的大量算力则主要依靠图形处理器(Graphics Processing Unit,GPU)提供。
2016 年,Kim 等提出了第一个仅依赖事件流实现6DOF 位姿跟踪和三维重建的方法[61]。该方案是一个基于三个解耦的概率滤波器的系统,实现6DOF 姿态跟踪、相对于关键帧的场景逆深度估计和场景对数强度梯度估计,此外,该方案将每个关键帧的梯度估计升级为强度图像,并允许从低比特率输入事件流中恢复具有空间和时间的超分辨率的实时视频强度序列。方案算力要求较高,需要GPU 实时恢复图像强度和深度,且在初始化阶段需要平面运动假设等深度估计约束,不适用于纯旋转估计。2017 年,Reinbacher 等提出一种使用事件相机实现全景建图和跟踪的方法[73],方法灵感来源于DTAM、LSD-SLAM、DSO[2]这类直接对齐方法,即最小化当前帧与世界地图之间的光度误差。其将跟踪描述为一个优化问题,利用类似于Kim 等在2014年提出的方法[22]中一样的全景图,通过跟踪摄像机在全景空间上的轨迹来估计旋转运动,可以在CPU 上实时运行,所提出的建图方案可以准确地表示每个位置生成事件的概率,但地图更新和梯度计算是由GPU 完成的。2017 年,Rebecq 等提出EVO[63],这是一个不依赖其他传感器,仅利用事件实现无人机的6DOF 运动和自然场景的三维SLAM 系统,方案流程如图14 所示,其将构建出来的事件帧与当前空间地图对齐,对事件边缘进行跟踪,同时将光度误差替换为事件图像和地图模板两个边缘图像之间的几何误差,建图模块则基于EMVS 方法[16]生成视差空间图像(Disparity Space Image,DSI),构建了具有可靠深度的三维边缘图。该方法不需要进行图像强度的恢复就可以估计深度。EVO 平均每秒可以处理150 万事件,在中速情况下比实时快1.25~3 倍,在较高速情况下比实时慢2 倍。该方法同样在初始化阶段需要平面运动假设等深度估计约束,不适用于纯旋转估计。
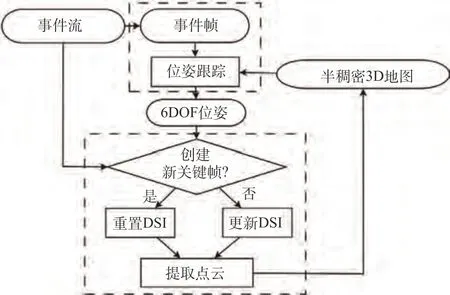
图14 EVO流程框图[63]Fig.14 Pipeline of EVO[63]
目前基于事件的视觉SLAM 方案以单目为主。虽然对于传统的视觉SLAM而言,双目意味着深度的确定,但异步事件的双目匹配并不简单,因此基于双目事件的SLAM 方案较少。2021 年,Zhou等提出ESVO[50],这是第一个基于事件的双目VO系统,采用事件数据的Time-Surface表示法,整体方案致力于最高限度地提高双目事件流的时空一致性,如图15 所示。在姿态跟踪方面,其将地图在左目的投影与事件的逆时间平面耦合从而完成位姿优化,在建图方面,它通过融合来自多个视点的深度估计来构建基于概率的半稠密3D 地图。该方案可以实现CPU上的实时运行。
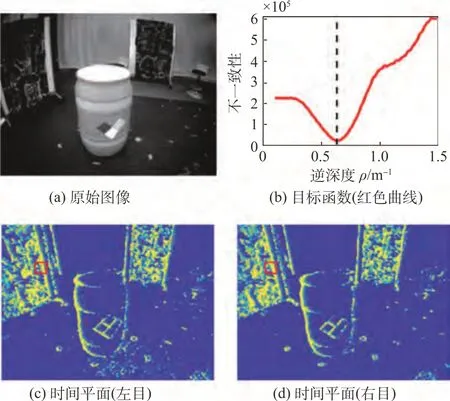
图15 基于双目事件的时空一致性优化[50]Fig.15 Event-based Stereo Spatiotemporal consistency optimization[50]

图16 运动补偿效果对比[74]Fig.16 Comparison of motion compensation[74]
2021 年,Hadviger 等提出一种基于特征检测和匹配的双目事件视觉里程计[66]。通过最小化重投影误差来实现位姿估计。该方法比起ESVO有两个重要的优点:一是可以使跟踪频率适应异步事件速率(跟踪频率无需预定义),相较之下,ESVO 有固定的预定义频率,当没有足够的传入事件时需要重新初始化;二是不需要初始化,相较之下,ESVO 则依赖于在事件的时间平面上成功地执行半全局匹配来初始化点云。该方案在一些公开数据集上表现出与ESVO 相同的性能。
在基于事件的SLAM方案里,运动补偿是一种常见的策略,旨在最大化运动补偿事件帧的清晰度来估计在事件流中捕获的运动,减少运动模糊,运动补偿方法中使用最多的就是最大化对比度,近些年也有许多学者针对最大化对比度这个思想展开了研究。
一般而言,为实现对比度最大化都是采用迭代优化算法如共轭梯度,这就需要良好的初始化,2020 年,Liu 等提出一种新的基于分支定界(Branch-and-bound,BnB)的全局最优事件估计算法[74],专门用以估计3DOF 的旋转,并证明其在求解质量上大大优于之前的局部优化方法(图 16)。这种方法能够在约300 s 内处理约50000 个事件(对于同样的输入,局部最优求解器约需要30 s),不能达到实时要求,但也许可以通过GPU 加速的方式得到更好的性能。2021 年,Kim 等提出一种新的最大化对比度的思路用于旋转和速度估计[75],不仅最大限度地提高单个时间窗口内事件图像的对比度,而且最大限度地提高随时间观察到的事件图像的对比度,可以在笔记本上用单核CPU 实时运行,且在公共数据集和真实数据集上证明了其最大误差在3°以内。
对比度最大化的方法能够很大程度上减少运动模糊,但随着图像分辨率和时间分辨率的增加,对比度最大化的方法产生的计算开销太大。因此也有学者寻求其他减少运动模糊的方法。
2021 年, Liu 等提出时空配准(Spatiotemporal Registration,STR)用以估计基于事件的旋转运动[76],这种方法还能直接生成特征轨迹,直接有利于后续基于图的运动优化,甚至可以用于后续的回环问题,其与最大化对比度方法的效果对比如图17 所示。2022 年,Wang 等提出将最大化对比度的思想扩展到三维[77],其认为运动本身一般是包含平移和旋转的,而这些变换发生在任意结构的环境中,因此图像匹配可能不再由低维单应性扭曲表示,从而使常用的扭曲事件图像(Image of Warped Events,IWE)的应用复杂化。基于此,该方法将每个事件转化为起点和方向依赖于连续轨迹参数的空间射线,不再评估图像中像素点的密度,而是评估参考视图前体积中离散位置的射线密度,这个体积称为扭曲事件体积(Volume of Warped Events,VWE)。
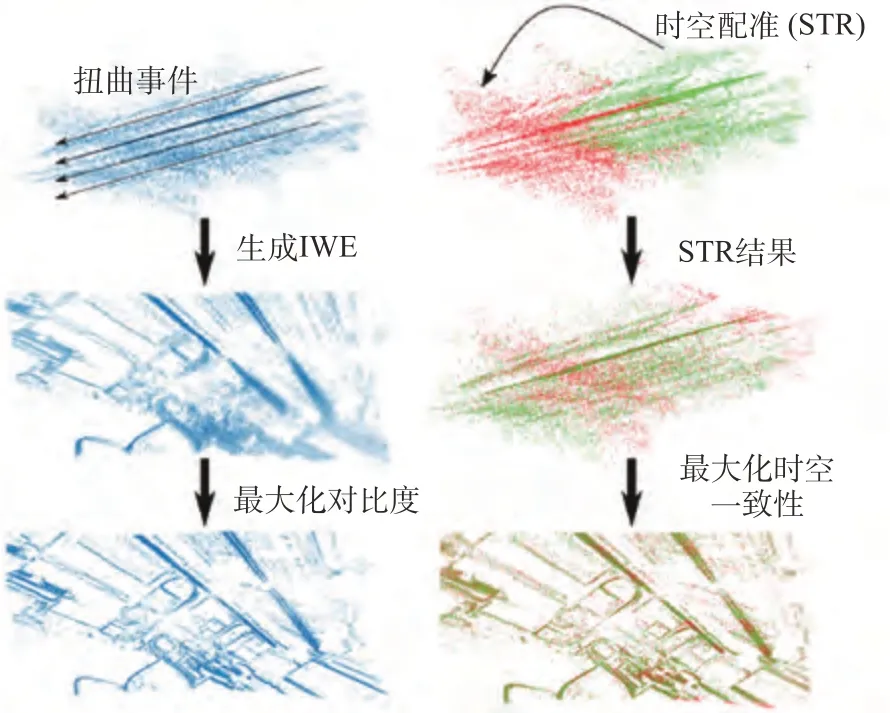
图17 最大化对比度(左)和时空配准(右)[76]Fig.17 Contrast Maximization(left) vs Spatiotemporal Registration(right)[76]
传统视觉SLAM 方案中基于特征的方案有的把线、面等作为特征进行匹配参与后续状态估计和建图,而事件数据本身就对边缘有更明显和集中的映射,因此基于线特征来完成事件SLAM 也是可行的。2022 年,Chamorro 等提出一种基于线特征、基于事件的SLAM 系统[68],该系统基于PTAM,面向具有突出的直线形状的人造场景,特别的是,该方案中的跟踪和建图线程以显著不同的速度进行并通过机器人操作系统(Robot Operating System,ROS) 环境进行信息交互。跟踪模块使用小事件窗口,旨在以高速率实现6DOF 姿态和速度估计,为避免瞬时的大算力消耗,建图模块使用估计的相机姿态从场景中恢复3D 线。在这种方法中,跟踪模块只使用事件数据,而不创建事件帧或从每个窗口提取特征,建图模块也只使用事件和估计的相机位姿恢复3D 线。该方案可在高密度线环境中实时运行。
综上,对仅基于事件的SLAM发展过程中的重要节点梳理如图18所示。
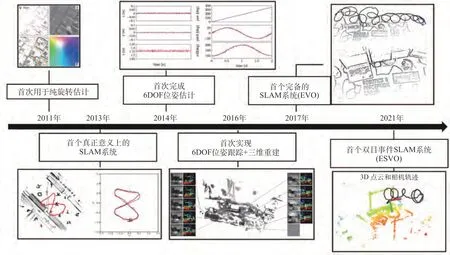
图18 仅基于事件的SLAM方案发展节点梳理Fig.18 Milestone nodes in the development of event-only-based SLAM
5.2 主要基于事件的多传感器融合SLAM
事件相机输出的异步事件流往往难以得到足够的信息。正如一些新型的事件相机正在融合其他传感器从而成为一个输出信息更全面的传感器,基于事件的SLAM 系统也在谋求多传感器的融合从而更实时、更鲁棒地完成定位与建图任务。
5.2.1 事件相机融合IMU
传统视觉SLAM的发展已经证明IMU的融合可以帮助SLAM 系统实现更准确和鲁棒的定位和建图,近些年也有许多学者将基于事件的SLAM 与IMU 融合,搭建了性能更好的基于事件的VIO 框架,以下对这些工作进行梳理。
2017 年,Zhu 等提出第一个基于事件的VIO,称为“EVIO”[54],其算法框架如图19 所示,使用两个最大期望算法(Maximum Expectation,EM)估计特征的光流及特征与事件之间的仿射变换,基于卡尔曼滤波融合基于IMU 的预测更新和特征轨迹。但最大期望算法的算力要求较高,系统无法满足实时性。2020 年,Friedel等[78]对EVIO 进行扩展,提出一种基于经过卷积神经网络 (Convolutional Neural Network,CNN)训练后的特征检测和描述的EVIO,其前端利用神经网络从异步的时间数据中生成图像帧,这些帧被馈送到一个多状态约束卡尔曼滤波 器 (Multi-State Constraint Kalman Filter,MSCKF)后端,后端再使用开发的CNN 的输出来执行状态更新。
2017 年,Rebecq 等受Gallego 等之前提出的角速度估计方案[51]的启发,利用IMU实现事件帧的运动补偿[46],从而避免了因累积事件导致的运动模糊,事件帧的特征检测和跟踪通过常规的FAST角点检测和LK 光流实现,算法的后端基于OKVIS[24]的方法,将IMU 误差和特征的重投影误差投入非线性优化框架实现位姿估计和优化。该系统可以完成CPU 上的实时(在笔记本上比实时平均快50%)6DOF 位姿估计和稀疏建图,并且精度和效率都比EVIO 更好。该方案除在常规事件数据集上进行了验证,还在一个极高速数据集(boxes_6dof,3.2 million events/s)上验证了可行性。2018 年,Mueggler 等提出一种基于事件的连续时间表示法的VIO[79],这种表示方法可以原则性地处理事件的异步性质并利用IMU 的高频率特性。该方法使用三次样条将自身轨迹近似为刚体运动空间中的平滑曲线,并根据图像平面中具有几何意义的误差测量和惯性测量来优化轨迹。但系统的计算消耗较大,比实时方法慢3~13 倍,可通过增加GPU优化。
2020 年,Gentil 等提出一种基于线特征的VIO 系统[80],称为“IDOL”,该方法的前端提取环境中线段的事件集群,后端通过最小化单个事件和线在图像空间中的投影之间的点到线的距离来估计系统沿着线的3D 位置的轨迹。提出了一种新的吸引/排斥机制以准确估计线的末端,避免它们在事件数据中的显式检测。结果表明该方法在大多数数据集上的性能与当时最先进的视觉惯性里程计框架(ROVIO)在同一个数量级上,这对DVS 的新算法发展有很大影响。
5.2.2 事件相机融合其他传感器
事件相机无法单独获取深度,因此与事件相机融合最多的是深度相机。2014年,Weikersdorfer等对自己在2013 年提出的方案[58]进行了3D 扩展[33],依靠额外的RGB-D相机完成深度估计,从而构建用于位姿跟踪的体素网格地图。算法效率较高,运行速度比实时快20 倍,以数百赫兹提供位姿更新。2018 年,Gallego 等提出一种6DOF 相机位姿跟踪方法[42],其利用RGB-D 相机应用现有的稠密重建方法构建了深度光度图,再利用带有光度图的事件相机估计6DOF 运动,此方法的后端是一个鲁棒的滤波器,同时将贝叶斯估计、后验逼近和指数族分布与传感器模型相结合,不仅跟踪事件相机的运动状态,还同时估计一些传感器参数,如事件触发阈值,这种方法在初始化阶段需要平面运动假设等深度估计约束,不适用于纯旋转估计。2022 年,Zuo 等提出一种新的针对深度和事件相机的混合双目装置的实时VO 系统[69],称为“DEVO”,其对事件数据采用Time-Surface 表示法,并同时用于跟踪和建图线程,两线程并行。DEVO 的跟踪线程只处理事件,并通过有效的3D-2D 边缘对齐来增量式地估计6DOF 姿态,而局部半稠密深度地图在建图线程中以较低帧率更新,这通过从时间平面图中提取半稠密边缘图和从深度相机读数中分配深度值完成。
除了附加深度相机,也有一些方案将事件相机与传统相机结合。2014 年,Censi 等将DVS 和一个普通CMOS 相机结合,提出一个基于事件的概率框架[59],通过单独处理每个事件,利用事件估计自上一个CMOS 帧以来的相对位移,该方法估计旋转效果很好,但因产生的事件过少而不能用于估计平移。2016 年,Kueng 等提出第一个基于特征跟踪的、基于事件的VO 系统[62],该系统是一个跟踪和地图构建并行的可视化系统,其对传统图像帧进行特征检测,然后通过使用事件流来异步跟踪稀疏的特征。该算法紧密地结合了位姿优化和基于概率的建图,实现了自然场景中的自身6DOF 运动估计。该算法每秒平均能够处理16 万事件,而正常的运动可能每秒产生105~106事件,更快的运动则会引起数百万的事件,因此该方法的应用场景也受运动速度的限制。
基于特征的方法适用于标准相机,噪声强度小,特征易于检测和跟踪,而直接法使用所有可用的数据,包括不符合特征定义的像素,对于事件相机而言,事件外观取决于运动和纹理,所以不容易检测和跟踪[5](如图20 所示)。2022 年,Hidalgo-Carrió 等提出第一个基于单目事件和传统图像帧的6DOF 直接法VO 方案[70],利用事件生成模型来补充图像帧,跟踪传统图像帧间盲时间的运动。克服了间接法中外观失去运动一致性的问题。方案效果在当时最佳,在相同误差允许范围内也能做到帧率更低,功耗更低,其中传统图像帧按需触发,该方法向低功耗跟踪更近了一步。

图20 不同运动导致的外观改变[5]Fig.20 Changes in appearance due to different movements[5]
除了与常规的传统相机或深度相机融合,也有学者将事件与雷达信息融合,完成SLAM。2021年,Safa 等提出一种事件和雷达信息融合的系统[67],该系统使用带有脉冲时序依赖可塑性(Spike Timing Dependent Plasticity,STDP)学习的SNN,将DVS 和更稀疏的雷达探测融合(如图21所示),提出的持续学习系统不需要任何离线训练阶段,可在不可见的环境中部署,而不需要事先捕获工作环境的数据集。
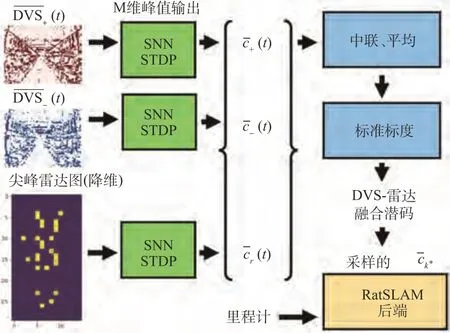
图21 DVS和雷达融合的SLAM系统[67]Fig.21 DVS-Radar SLAM[67]
5.2.3 事件相机、IMU和传统相机融合
2018 年,Vidal 等在2017 年Rebecq 等的工作[46]基础上提出第一个同时结合事件相机、IMU和传统相机的紧耦合SLAM 系统[64],称为“Ultimate SLAM”,该方法利用传统相机和事件相机的互补优势,不仅维护来自事件帧的特征轨迹,还同时维护来自传统图像帧的特征轨迹。然后将来自这两个异构源(事件帧和传统图像帧)的特征轨迹提供给优化模块,从而同时利用事件、传统图像帧和IMU 优化相机位姿。如图22 所示,该方案完成了真机部署,分别在室内飞行过程中开灯和关灯(关灯状态下传统图像帧几乎为全黑)和在光照不足的环境中进行快速飞行(传统帧出现严重的运动模糊)的情况下进行了方案的验证。

图22 结合事件相机、IMU、传统相机的Ultimate SLAM[64]Fig.22 Ultimate SLAM combines event cameras,IMUs,and traditional cameras[64]
2020 年,Jung 等提出一种基于滤波融合事件相机、IMU 和传统相机的位姿估计方法[65],其算法流程如图23 所示,视觉前端使用传统的图像处理技术对强度图像进行特征提取等得到特征轨迹,事件前端通过最大期望算法(Expectation Maximization,EM)求解时间光流,估计器根据环境的先验约束场景深度的范围。该方案与EVIO 相比,在基准数据集上的位置误差降低了49.9%,但未能满足实时性要求。
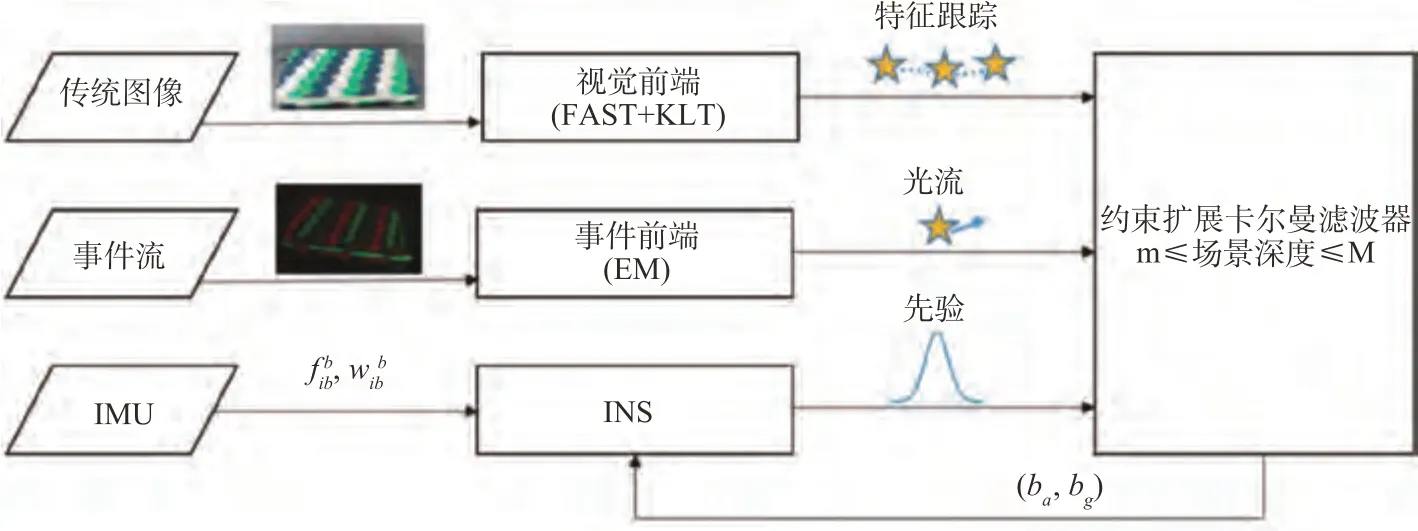
图23 基于滤波的事件相机、IMU、传统相机融合方案Fig.23 Event camera, IMU and traditional camera fusion scheme based on filter
2022 年,Chen 等提出第一个基于事件的、同时结合事件相机、IMU 和传统相机的双目VIO 系统[71],方案通过运动补偿对原始事件流进行预处理,最终实现了连续双目事件流之间的时间跟踪和瞬时匹配,得到了鲁棒的实时状态估计。此方法应用于低照度环境下的四旋翼飞行,同时还进行了真实世界的大规模环境实验,证明了其长期有效性。
综上,对主要基于事件的多传感器融合SLAM发展过程中的重要节点梳理如图24所示。
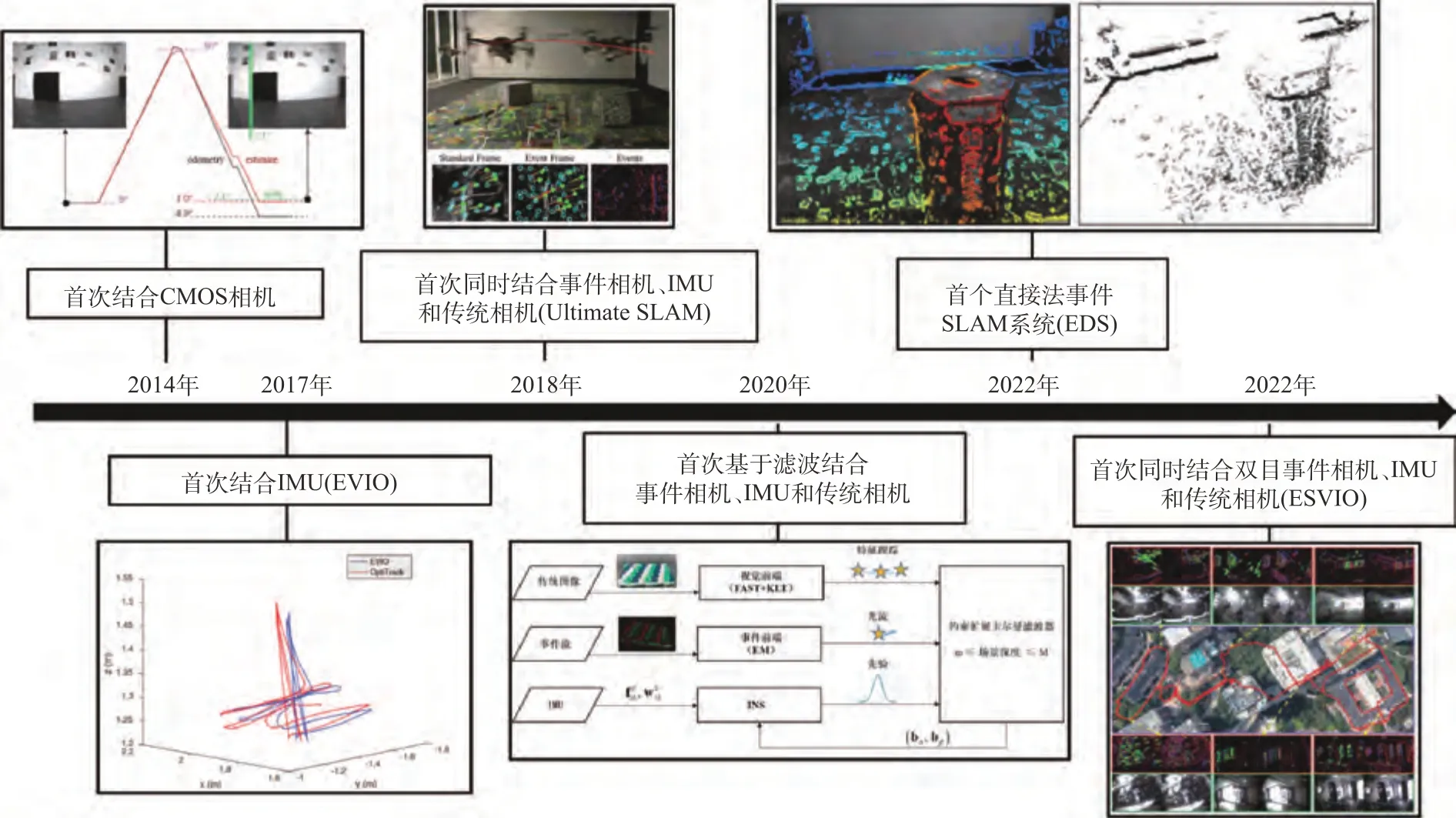
图24 主要基于事件的多传感器融合SLAM方案发展节点梳理Fig.24 Milestone nodes in the development of multi-sensor fusion SLAM mainly based on events
最后,对一些成熟的框架进行性能对比,对比结果如表4所示。
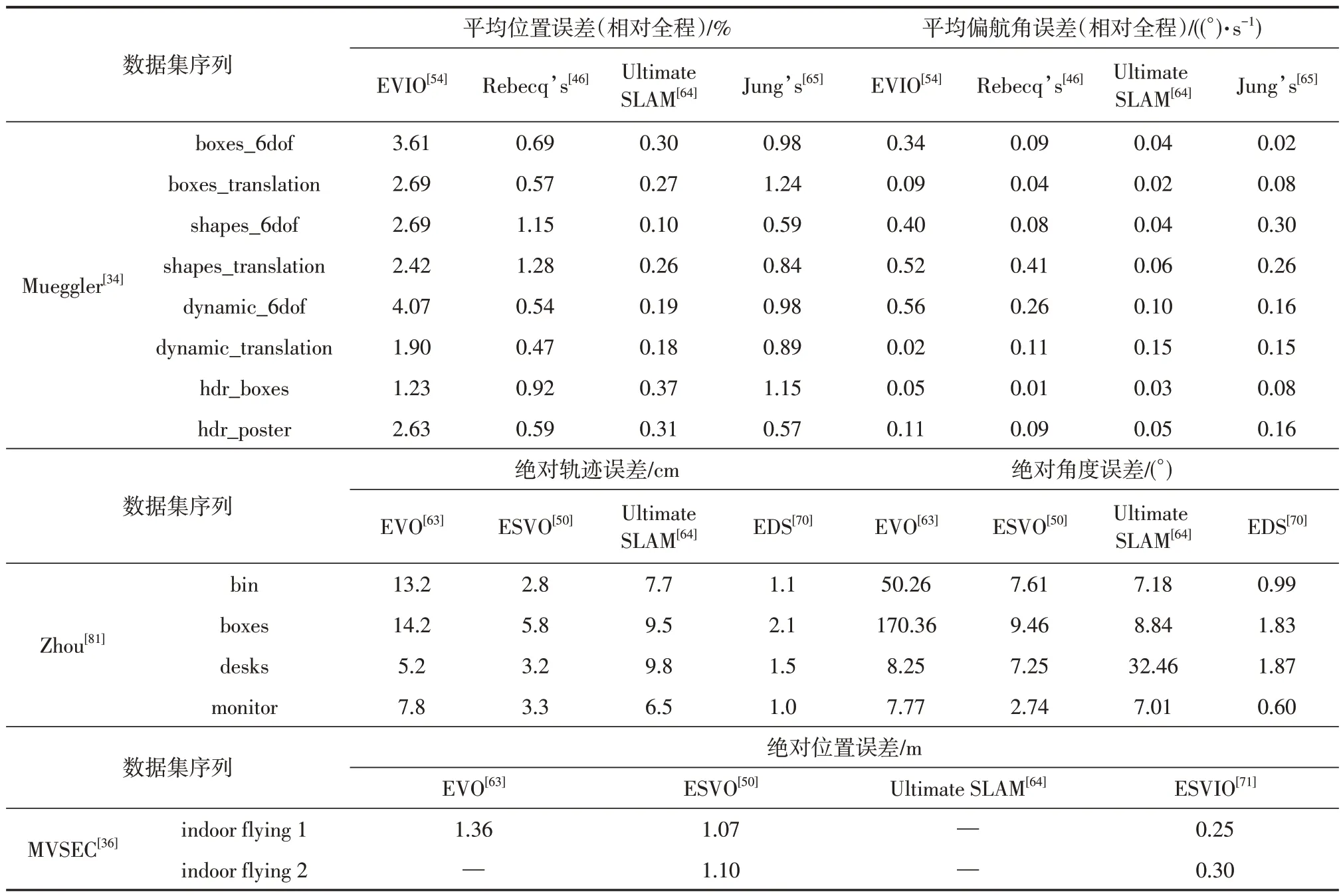
表4 一些基于事件的SLAM方案性能对比Table 4 Accuracy comparison of some event-based SLAM
6 结束语
本文首先介绍了SLAM技术的基本流程,然后介绍了典型的事件相机,列举了基于事件的SLAM 性能评估方法,梳理了事件数据的不同处理方式,着重介绍了事件相机在视觉SLAM 领域的应用研究。事件相机的低延迟、高动态范围、高时间分辨率等特性都表明其在视觉SLAM 领域的适用性,但新的数据形式和尚不成熟的硬件体系限制了其应用,因此,无论是事件相机本身还是基于事件的智能感知算法都有着巨大的进步空间,未来的基于事件的SLAM 可以围绕以下主题开展进一步研究。
(1)新的基于事件的传感器的研发:无论是ATIS 还是DAVIS,或是之后的一些新的基于事件的传感器出现,都将事件这一数据形式拓向了更宽的应用场景,而目前的主流的基于事件的传感器仅仅是将传统CMOS 相机与事件结合,未来的结合必然会更多元化,针对不同的应用场景与不同的传感器进行结合将会事半功倍。
(2)新的处理事件数据的方法:事件数据本身的特殊性,决定了在发展前期只能通过一些累积手段形成各种类型的图像(如事件帧),进而去适应成熟的算法体系。这种做法放弃了自身的诸多优点,没有从根本上改变图像处理的范式。后续研究可以针对这种异步输出形式,设计事件数据的算法,从而释放事件相机的潜能。
(3)基于事件的SLAM与深度学习的结合:大量的研究成果已经表明,事件相机会将SLAM 推向更快、更精确的领域。而此前一些与深度学习相结合的SLAM 方案,也已经证明在算力允许的前提下,无论是前端视觉里程计还是后端优化,深度学习的加入均会带来效果、效率上较大的提升。此外,一些特殊的网络如SNN,可以直接以事件作为输入,最大程度地保留事件相机的优秀特性。因此,基于事件的SLAM与深度学习的结合是一个值得开发的领域。
(4)基于双目事件的SLAM:目前,基于事件的单目视觉SLAM已经有了很多成熟的方案,但双目系统的研究较少,从传统的视觉SLAM技术发展历程来看,在做好数据融合的前提下,双目的加持会进一步提升系统的性能。
