多样细粒度特征与关系网络驱动的行人重识别
2023-10-10许茹玉粟兴旺黄金玻王晓明
许茹玉,吴 琳,粟兴旺,黄金玻,王晓明
西华大学 计算机与软件工程学院,成都 610039
行人重识别(person re-identification)是计算机视觉方向用来判断一组由多个摄像机拍摄的图像或视频序列中是否存在某特定行人的检索技术[1]。近年来随着深度学习的快速发展,行人重识别方法在卷积神经网络中得到了广泛应用,并在智慧城市、人机交互、虚拟现实、监控安防等现实背景下加以使用,给人类生活带来了便利。但摄像机位于不同角度拍摄图片、拍摄时行人的姿态不同、不同摄像机所拍摄图像的尺寸及分辨率不同、行人图片里的遮挡问题、拍摄时的光线问题、跨模态的异构数据问题,这些困难使得行人重识别成为了具有巨大挑战的研究课题[2]。
传统的行人重识别技术都在探究手工生成的低级视觉图像特征以及如何更好地表示特征与特征间的相似性度量计算方法[3-6]。而在深度学习出现后,利用深度神经网络的模型在行人重识别领域开始广泛应用[7-9]。深度学习与传统的手工设计方法完全不同,基于深度学习的行人重识别方法可以通过神经网络模型自动地提取行人图片的特征,并通过损失函数学习到不错的相似性度量结果,即将提取行人特征与度量学习的相似性对比融合在一个模块。
早期将深度学习引入行人重识别领域时,全局特征作为首要选择。Wang等人[10]使用卷积神经网络将一张图片直接输入卷积网络提取特征,该方式无法关注到行人的显著特征,因此性能提升并不高。随后,为提高算法的鲁棒性能,Zhang等人[11]则从全局模块出发,设计了全局注意力模块(RGA),该模块既包含了局部特征,又包含了全局特征间的关系特征,使网络可以提取更具区分度的特征,但该方法造成了计算量的骤增。Sun 等[12]将图片输入骨干网络resnet50 后,将特征图水平且均匀的分割成6 部分,使用注意力机制RPP(refined part pooling)进行分块后的语义信息校准。但由于没有考虑相邻块间的联系,易丢失判别性信息。这种使用切片特征的方法具有很高的灵活性。但是遇到背景噪声过大、遮挡现象严重的问题时会相对敏感。Zhao 等人[13]首次考虑人体结构信息,提出帮助对齐局部信息的主轴网络(spindle net)。Wang 等[14]则引入姿态估计来解决图片中物体遮挡问题,聚焦未遮挡区域。但引入人体结构信息的姿态估计方法需要额外的姿态估计模型进行辅助,同时会产生大量噪声。Wang等人[15]提出了多粒度网络(mutiple granularity network,MGN),使用了一种将全局信息与细粒度局部信息结合的端到端的特征学习策略,但该模型的泛化能力不足,只在部分数据集上表现较好。随后,Park等人[16]提出了一种新的关系网络结构(relation network for person re-identification,RRⅠD)。该关系网络利用身体单个部位与其他剩余部位之间的关系进行特征表示,虽然提高了区分性,但难以挖掘更多关于特征的细节信息。
基于上述问题,本文提出一种端到端的多分支深度网络模型DFFRRⅠD,用来解决特征提取过程中细节信息挖掘不充分造成的识别精度低的问题。该方法从全局特征与局部特征的角度共同出发,设计了一种涵盖多重粒度的关系网络,充分挖掘全局特征、局部特征以及局部特征间的关联性特征,使得提取的特征更具全面性。该模型包含了三个分支:第一个分支提取粗糙的全局特征;第二个分支采用水平切块的方式,提取细粒度特征信息;第三个分支则考虑人体各个部位与其他部位的关系,使提取的特征更具区分性。三个分支协作,丰富特征图信息,便于选择更具判别性的身体特征,从而提高网络模型的识别精度以及泛化能力。
1 基本原理
1.1 本文方法
多粒度网络MGN 使用了全局与局部特征相结合的特征提取策略,设计了一个全局分支,两个局部分支,通过将特征图按照不同尺度划分为一块、两块和三块,在三个分支中获得不同粒度的特征信息,利用等分后的局部特征进行独立学习,得到了较好的效果,但没有考虑局部信息间的关联性。RRⅠD 网络中的关系模型(one-vs.rest)则考虑了人体局部与剩余局部的关系,但局部特征的信息没有充分利用,难以挖掘更多的显著性细节信息。
本文借鉴了MGN与RRⅠD中关系模型(one-vs.rest)的思想,设计了多样化细粒度特征与关系网络的深度网络结构(DFFRRⅠD)。总体结构设计如图1 所示。首先将行人图片通过backbone网络提取出大小为H×W×C的特征图,其中H、W、C分别代表高度、宽度和通道数。生成的特征图被水平等分成6块,随后经过全局特征分支和局部特征分支进一步处理特征。设计全局特征分支的目的是提取粗略的特征,以捕捉不同行人之间最明显的差异去代表某个特定行人,例如衣服的颜色、纹理特征以及包含语义信息的形状特征等。但提取的全局特征没有位置信息,无法分辨出前景与背景,会受到背景噪声的干扰,因此设计了两个局部特征分支。在第一个局部分支中,水平分块的局部特征图里每一部分只包含这一部分的局部信息,并不会受到其他局部信息的干扰。这样就可以使局部特征集中于关注本块内部的信息,当遇到遮挡问题时,一些局部特征也稳定存在,从而使特征信息仍具有区分性。另外的局部特征分支则考虑身体局部与其他部位之间的关系,结合了局部与其他剩余局部的特征。其作为第一个局部分支的补充,防止由于相应部分具有相似的行人特征属性,混淆了不同行人,影响网络的判别能力。在测试阶段把沿着通道维度连接的全局与局部特征作为行人特征的最终表示。结合了局部特征和全局特征的信息经过不断地学习,可以完善特征的全面性。本文使用交叉熵损失、标签平滑交叉熵损失和难样本三元组损失对设计的模型进行端到端的训练,实现网络模型的优化。

图1 原始模型与本文所设计的网络对比框图Fig.1 Block diagram of original model compared to network designed in this paper
1.2 算法结构
本文使用经过ⅠmageNet[17]分类训练的ResNet-50[18]作为主干网络,并移除ResNet-50 网络最后的全连接层。将输入的原始行人图片经过该网络,提取初始特征图。DFFRRⅠD网络总体框图如图2所示。

图2 本文所设计的网络总体框图Fig.2 Overall block diagram of network designed in this paper
1.2.1 全局模块
全局模块学习行人特征的整体属性,不需要任何分块信息。通过主干网络提取最初的全局特征,此时的特征维度为2 048 维,再经过一个卷积层将特征图降维至256 维,并利用后接的非线性激活函数ReLU 增加非线性特性。使用1×1卷积核[19]降维,可以使网络结构更加紧凑,同时又可以减少参数量,增强跨通道之间的交互性。使用全局最大池化的方法将降维至256 的特征图进一步处理得到1×1×c的特征q0。
1.2.2 多样化细粒度特征提取模块
多样化细粒度局部模块中初始特征具体划分为2块、4 块和6 块,并独立学习局部特征。具体划分如图3所示,不同数量的分区带来了不同的内容粒度。将左列中原始的行人图片视为最粗粒度级别,从左向右依次为原始图片分成2块、4块和6块的行人分区。图像水平分割的块数越多,分割得到的粒度就越细。划分后的每个区域仅包括整个身体的局部信息,过滤了其他不相关块中信息的干扰。在全局特征学习中由于特征图位置信息被忽略所导致的类间相似性难以适应及类内差异较大的问题由细粒度局部模块来解决。通过不同粒度特征在有限信息内的学习,具有最显著性的细节就会被挖掘出来。

图3 身体划分由粗到细的粒度Fig.3 Body divided into coarse to fine particle sizes
由于将特征图分块后,进行后续处理的操作是一致的,因此只介绍将原始特征图分为6块后得到的细粒度特征提取操作。将原始图像经过主干网络提取的初始特征水平划分为6个区域,每个区域的通道维数为2 048维。每个局部分区都使用全局最大池化的方式进行处理,并使用一个带有批量归一化和ReLU 的1×1 卷积层将2 048 维特征降维,减少至256 维,得到大小为1×1×256的特征qi(i=1,2,…,6) 。
需要注意的是:该模块的所有局部特征只进行分类学习,不进行度量学习。这是因为理论上将图片分为上下两块后,上半部分是行人上半身,下半部分是行人下半身。但在实际图片中,有可能行人位于下半部分,上半部分都是背景信息。假设将背景信息进行度量学习,就会产生无实际意义的数据污点,污点数据学习到错误信息会导致模型崩溃,引起预测错误。因此,本模块仅使用交叉熵损失和标签平滑交叉熵损失进行分类学习。
1.2.3 局部与剩余局部关系模块
由于多样化细粒度特征提取模块中各个部分都是孤立的,没有考虑身体局部与其他部分之间的关系,这干扰了不是同一行人但拥有相似性局部特征的相似性计算,造成预测错误。因此将局部与剩余局部关系模块作为细粒度特征提取模块的重要补充。通过结合局部特征与剩余局部特征的信息,保持特征间的紧凑性,增强对遮挡问题的区分性及鲁棒性,从而提高网络学习的判别能力。经过主干网络的行人图片同样被划分为6块、4 块和2 块,经过全局最大池化后,每一个局部特征都处理为1×1×2 048大小的特征图,由于后续操作相同,因此本节只介绍特征图被划分为6 个局部区域的特征提取方法。
具体操作如图4 所示。one-vs.rest[16]使用大小为1×1×2 048 的pi(i=1,2,…,6) 表示局部特征,本文则选取pi,i+1,即pi与pi+1之和,作为本模块使用的局部特征。增大局部特征区域,缩小剩余部分特征区域,可以更好地表示局部与剩余局部间的关系。本文2.4.1小节对one-vs.rest模块与本文改进后的局部与剩余部分模块two-vs.rest进行了对比实验,以证明改进的有效性。
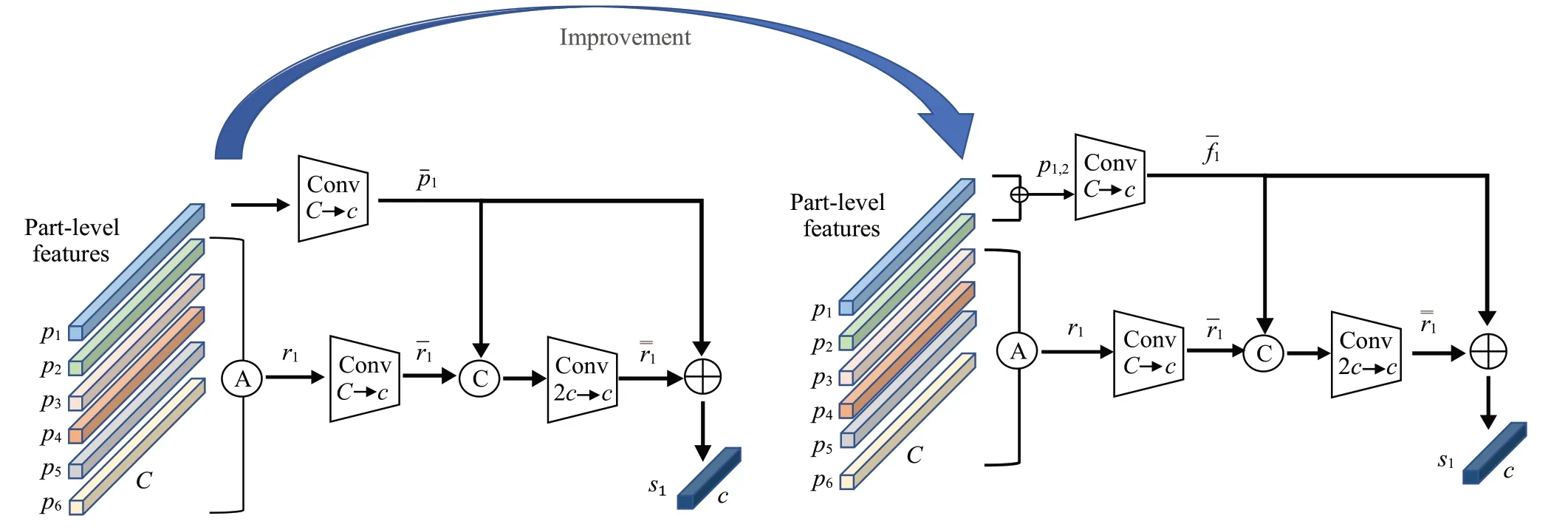
图4 身体局部与剩余部分关系网络改进后的结构图Fig.4 Structure diagram of network of relationships between parts of body and rest of body
对于选定的某个局部特征pi,i+1,经过1×1卷积层、批量归一化和ReLU进行降维与非线性激活,将通道维度降至256维,得到大小为1×1×256的局部特征。剩余部分特征pj使用平均池化的方法得到大小为1×1×256的特征ri,具体公式可以表示为:
利用公式(1)得到的排除某一局部特征后剩余部分特征ri,经过1×1卷积层后得到1×1×256大小的特征。特征与特征rˉi进行拼接,由此得到身体局部与剩余局部间的关系。拼接后得到的维度是直接相加的,特征变为512 维。之后再使用1×1 卷积层将特征大小变换为1×1×256。通道降维至256维的目的是将含有局部与剩余局部关系信息的特征与局部特征进行残差连接,将二者之间的关系信息转移至si,其过程可以表示为:
式中,Rp为由1×1 卷积、批量归一化以及激活函数ReLU所组成的子网络;T表示特征间的串联。
引入残差连接的作用是在训练中复杂的关系特征学习效果不好的情况下,局部特征仍然可以不受特征干扰不断学习,增强对遮挡问题的区分性及鲁棒性,且保持了特征间的紧凑性。本文考虑了当特征被切分为两块时,不能使用相加操作处理pi与pi+1,因此选取pi(i=1) 作为局部特征,pi+1作为剩余部分特征。特征进行水平分割后,选取局部特征与剩余局部特征的方法如图5 所示,特征图划分为几块,则有几种选取方式。
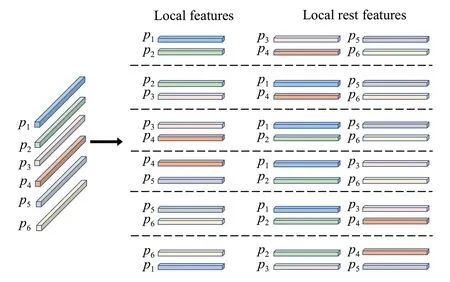
图5 局部特征与剩余部分特征选取图Fig.5 Diagram of local and residual feature selection
1.3 损失函数
本文网络利用行人图像的真实标签进行有监督的表征学习。使用交叉熵损失、标签平滑交叉熵损失与难样本三元组损失来训练网络模型,并引入参数λ对这三个损失进行平衡。具体公式表示为:
式中,Lce表示交叉熵损失;Llsce表示标签平滑交叉熵损失;Ltriplet表示三元组损失。
交叉熵损失函数可以解决多分类问题,是深度学习领域广泛应用的损失函数。该损失函数采用了类间竞争机制,更加关心正确标签预测结果的准确性。因此擅长学习类间的信息,忽略了对错误标签的损失计算,引起预测错误率增加。但交叉熵损失使用硬标签作为优化目标,不易造成信息损失。
标签平滑交叉熵损失函数[20]利用正则化技术将硬标签转化为软标签对图像进行分类。采用软标签分类可以使同一类聚集得更紧凑,降低模型预测的确定性,防止模型过拟合。但在一定程度上会损失信息,抹去一些关键的区分信息。考虑到这个问题,本文采用交叉熵损失与标签平滑交叉熵损失相结合的方式进行分类计算。一定程度上减少了信息损失,又可以预防模型过度自信,从而更好地优化网络。
交叉熵损失函数与标签平滑交叉熵损失函数被定义为:
式中,N表示训练过程中梯度下降的小批量样本数;K表示数据集中行人图片的标签数量;ε表示平滑因子;yn表示行人图像的真实标签样本数;表示每个特征qi和si预测的标签。具体被定义为:
式中,Wk i表示全连接层中标签为k的第i个行人类别的权重向量;qi表示使用网络模型最终提取的行人特征。
三元组损失函数[21]是在深度学习中广泛使用的度量计算函数。其原理是缩小正样本对间的距离,增大负样本对间的距离,使得同类样本在特征空间聚集。但只能对简单的样本进行区分,并不利于网络的训练学习。
所以本文使用改进后的难样本三元组损失函数[22]进行度量学习。改进后的损失函数在每一个训练批次都选择距离最远的正样本图片和距离最近的负样本图片训练网络模型,使网络通过学习得到更佳的特征表示,增强网络模型的泛化能力。具体的公式被定义为:
式中,NK表示一个批量里选取的行人数量;NM表示一个批量里对每个行人所选取的图片数量;N=NK NM,表示一个批量的大小;α表示边缘参数,用于控制特征空间里正负样本对的距离,使用欧氏距离计算;qiA,j表示锚定图片(anchor)的特征;qiP,j表示正样本图片的特征;qiN,j表示负样本图片的特征。
2 实验结果与分析
2.1 数据集
本文使用行人重识别领域公开的CUHK03[23]、Market1501[24]、DukeMTMC-ReⅠD[25]这三个大型数据集进行充分的实验,以证明本文提出的DFFRRⅠD 模型的有效性。三个数据集的属性信息如表1所示。
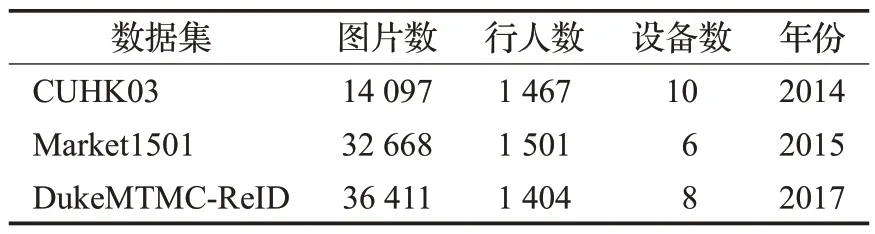
表1 数据集基本属性信息Table 1 Dataset basic property information
CUHK03 数据集提供了由5 对摄像机采集的1 467个行人,共含有14 097 张图片。通过手工裁剪和DPM(deformable part model)自动检测这两种方法框出行人。将其分成两部分,一部分用于训练,包含767 个行人,共7 365张图片,另一部分用于测试和查询,含有767个行人,共6 732张图片。
Market1501数据集使用5个高清摄像头和1个低清摄像头,共6 个摄像机所捕获的包含1 501 个行人的共32 668 张图像。使用相同的方法从拍摄图像中切割出行人。数据集中的751个行人,共12 936张图片用于训练,另外的750 个行人,其中3 368 张图片用于查询,19 732张图片则用来测试。
DukeMTMC-ReⅠD数据集包含了由8个摄像机拍摄的1 401 个行人,共36 411 张行人图片。其中702 个行人,共16 522 张图片用于训练,剩余702 个行人图片中有2 228张用于查询,17 661张图片用于测试。
2.2 实验环境与设置
本文的算法在深度学习框架pytorch上进行训练及测试,以证实训练好的网络模型可以提高行人分类的准确性。其实验环境如表2所示。

表2 实验环境基本信息Table 2 Basic information about experimental environment
使用MSRA[26]方法进行网络权重的初始化。将数据集的所有图片裁剪为384×128。本文使用水平翻转和随机擦除的方法对数据集进行扩充。实验使用动量为0.9 的随机梯度下降法(SGD)作为优化器,权重衰减系数设定为0.000 5进行模型的优化。在训练集里随机选择16 个行人,每个行人选择4 张图片作为小批量样本,batchsize 的大小设定为64。主干网络resnet50 的初始学习率设置为1×10-3,其他模块的初始学习率设置为1×10-2。模型需要80个epochs进行训练,从第40个epochs,每20 个epochs 学习率衰减10 倍。在所有实验中,权重参数λ采用经验值的方式固定设置为2。
2.3 实验评价标准
本文模型使用rank-n和mAP 评估方法的性能。rank-n表示搜索结果中置信度最高的前n张图片,计算n张图片中含有正确结果的概率,反映出检索的精度。mAP 表示平均精度的均值,计算的是测试集提取样本中正确结果的概率,反映出检索的平均正确率。
2.4 实验仿真与结果分析
2.4.1 模型有效性验证
为了验证本文所设计算法的有效性,使用Market1501和DukeMTMC-ReⅠD这两个数据集,将改进的关系模块与RRⅠD 的one-vs.rest 模块进行比较,同时将设计的三个模块进行组合实验。Ⅰ表示本文设计的全局模块,Ⅱ表示本文设计的多样化细粒度特征提取模块,Ⅲ表示RRⅠD的one-vs.rest模块,Ⅳ表示本文对one-vs.rest改进后的two-vs.rest关系模块。
表3 展示了原本关系模块与改进后关系模块的复杂度计算量。由表3可知:与原本的关系模块相比,twovs.rest 在Market1501 数据集上,mAP 提高了0.3 个百分点,rank-1 提高了0.3 个百分点,rank-5 精度则持平。使用DukeMTMC-ReⅠD数据集进行实验,mAP较原本模块提高了0.2个百分点,rank-1与rank-5分别提高了-0.2个百分点、0.2个百分点。表3中的实验数据表明本文基于one-vs.rest 关系模块所改进的two-vs.rest 关系模块所包含的关系信息更具有区分性,证明了改进的有效性。

表3 one-vs.rest与two-vs.rest的对比结果Table 3 Comparison results of one-vs.rest and two-vs.rest 单位:%
表4展示了本文设计的三个模块相互组合后,所需要的参数量及浮点计算量。由表4可知:只使用关系模型two-vs.rest 的单分支网络模型所得到的实验数据精度是最低的;使用关系网络two-vs.rest与其他两个模块相结合的双分支网络模型比原有的单分支网络模型所得到的实验数据精度高一些;将三个模块相组合的三分支网络模型所得的数据精度又优于单分支网络模型和双分支网络结构模型。这说明三个模块可以相互补充,使模型提取到显著性更强的细节信息,从而使三个模块相组合构成的网络模型得到的各项数据精度达到了最高。

表4 四种网络结构的对比结果Table 4 Comparison results of four network structures 单位:%
2.4.2 损失有效性验证
为了验证本文使用交叉熵损失与标签平滑损失共同进行分类比单独使用一个损失分类的效果更佳。在Market1501 数据集上将设计好的网络模型使用单个或组合的交叉熵损失进行了对比实验。Cross-entroy表示交叉熵损失。LabelSmooth 表示标签平滑交叉熵损失,Cross-entroy+LabelSmooth 表示交叉熵损失与标签平滑交叉熵损失相加的损失。具体实验结果如图6所示。

图6 损失函数的对比结果Fig.6 Comparison results of loss functions
针对分类损失的实验结果,印证了本文的猜想:交叉熵损失会降低模型预测准确率,但一定程度保持了信息的完整性;标签平滑交叉熵损失会提高模型预测精度,但造成了信息损失。因此将二者联合作为本文的分类损失,模型的预测精度会进一步提高。
2.4.3 与其他先进算法对比
本文所提方法DFFRRⅠD与部分先进的行人重识别方法进行了比较。首先选取部分主流算法与本文方法在参数规模与复杂度方面进行了对比,选取的部分主流算法包含了SNR、PCB、MGN、RRⅠD、Triplet、SVDNet、BigTricks、AlignedReid、HPM。具体对比结果如图7 所示,本文算法相较于RRⅠD,参数量减少了2.96,复杂度则持平,而MGN的参数规模与复杂度都是极高的。

图7 本文算法与主流算法复杂度的对比结果Fig.7 Comparison results between proposed algorithm and mainstream algorithm of complexity
之后使用Market1501 和DukeMTMC-ReⅠD 这两个数据集进行实验,实验结果如表5 所示。对比方法包含:基于全局特征的Triplet[21]、SVDNet[27]、BigTricks[28]、Self-supervised[29];基于注意力机制的Mancs[30]、DuATM[31]、AANet[32];基于局部特征的PCB[12]、HOReⅠD[14]、MGN[15]、RRⅠD[16]、SCPNet[33]、AlignedReⅠD[34]、HPM[35](本文的实验数据依据2.2 节的实验环境复现源代码所得)。在Market1501 数据集上,DFFRRⅠD 模型mAP 精度达到88.6%,优于其他先进方法,rank-1精度为95.3%,低于了MGN方法,高于对比的其他主流算法。在DukeMTMCReⅠD 数 据 集 上,DFFRRⅠD 模 型 的mAP 精 度 达 到 了78.9%,rank-1 精度为89.3%,优于本文所对比的其他先进方法。

表5 本文算法与主流算法在Market1501和DukeMTMC-ReⅠD数据集对比结果Table 5 Comparison results of proposed algorithm compared with mainstream algorithm on Market1501 and DukeMTMC-ReⅠD datasets 单位:%
为了进一步证明本文方法的有效性,本文在CUHK03数据集上与一些先进算法做了对比,具体实验数据如表6 所示。由于该数据集的行人标注框可分为手工标注和检测器自动标注两种方式,因此又细分为Labeled 与Detected 这两种情况。本文DFFRRⅠD 与RRⅠD 相比,mAP与rank-1在Labeled标注情况下,分别提高了1.9个百分点和2.6 个百分点;在Detected 自动检测的数据集下,分别提高了0.8 个百分点和1.4 个百分点,且明显高于进行对比的其他算法。使用CUHK03 数据集进一步验证了本文方法的泛化能力及鉴别能力。
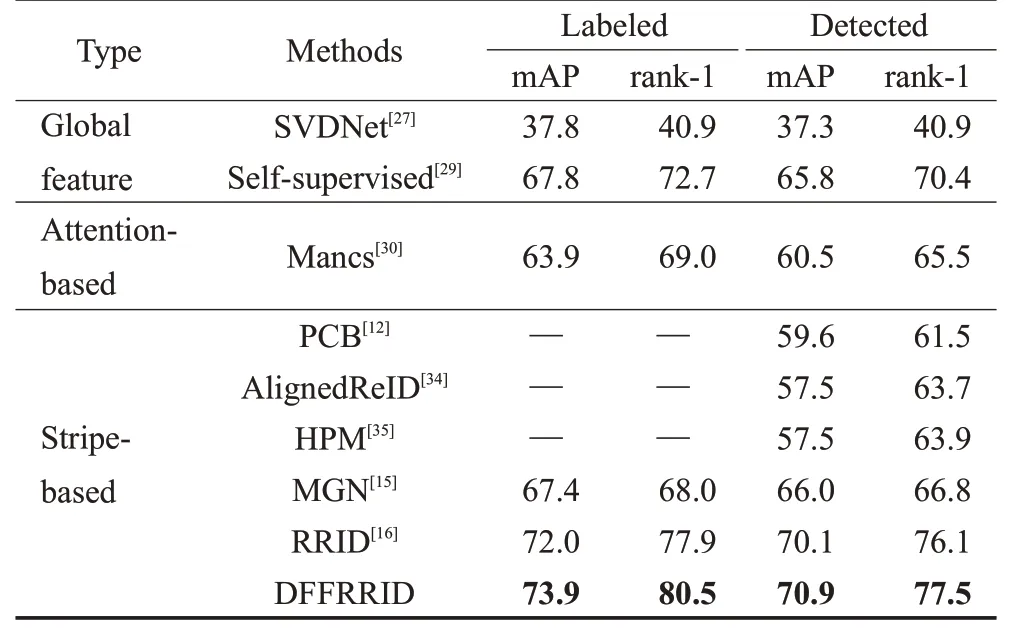
表6 本文算法在CUHK03数据集上与主流算法对比结果Table 6 Comparison results of proposed algorithm compared with mainstream algorithm on CUHK03 dataset单位:%
问题的复杂度、模型的复杂度、可用的训练数据量都会影响算法的高效性能。复杂的问题需要使用复杂的模型进行解决,而模型的性能好坏又需要大量且有效的数据集去支撑。可以通过数据增强的方式获取更多数据,大量的数据可以提升模型的泛化能力,预防模型过拟合。相比于Market1501数据集,DukeMTMC-ReⅠD和CUHK03数据集中的行人图片,其行人通常有较大的姿势变化,同时背景杂乱,遮挡更严重。因此行人图像更难检索,检索精度相较Market1501数据集准确率也要低很多。
3 结论
本文所提出的DFFRRⅠD模型更加关注显著性的细节信息及关联性特征。首先,设计了一个全局模块,用于提取粗糙的整体特征。其次,将多样化细粒度特征提取模块作为全局模块的补充,通过由粗到细的粒度切分,获得显著性细节信息。之后考虑到局部特征间的关联性,改进了one-vs.rest模块,将改进后的two-vs.rest模块作为细粒度特征提取模块的有效辅助。随后将三个模块提取的所有特征集成到分类网络。利用交叉熵损失、标签平滑交叉熵损失和三元组损失共同训练网络,以保持信息的完整性,提取出最具区分性的特征。最后,通过对比实验证实了DFFRRⅠD 模型的竞争力。本文方法更加关注行人主体,网络更具鉴别力,但遮挡问题仍给行人重识别研究带来了巨大挑战。本文虽然在数据集预处理阶段使用随机擦除的方式缓解了其他物体对行人的遮挡问题,但行人间的遮挡问题并未解决。在后期研究中,将引入姿态估计模型对行人图像提取关键点信息,并与本文方法相结合用于指导网络特征提取,使模型可以正确地关注目标行人,进而缓和行人间的遮挡造成的识别错误问题。
