面向自动驾驶的轻量级道路场景语义分割
2023-10-10李顺新
李顺新,吴 桐
1.武汉科技大学 计算机科学与技术学院,武汉 430065
2.武汉科技大学 大数据科学与工程研究院,武汉 430065
3.湖北智能信息处理与实时工业系统重点实验室,武汉 430065
随着计算机视觉领域的发展,基于深度学习的细分方法极大提高了语义分割的准确性和收敛速度[1]。语义分割作为视觉智能领域的一个重要研究方向,可以在像素层面上将图像按照语义分割为不同颜色的图像区域,并根据语义类别标记图像中的不同区域,然后获得具有像素语义标注的图像。因此将语义分割应用于自动驾驶,能帮助车辆感知并获得周围的道路环境信息,从而提高行驶安全[2]。
自动驾驶过程中需要不断地收集道路及周围的环境、人群、建筑等图像。传统算法对这些类别不同、大小不一、无结构、无规则的图像进行分析和处理时会产生实时性低、准确度低等问题[3]。因此,如何兼顾道路场景识别结果的实时性与可靠性,对车辆精准、高效地感知道路环境信息具有重要的研究意义。目前流行的众多道路场景语义分割模型,在分割城市道路场景图像方面已经取得了一些的成果,但也存在占用系统资源巨大、算法收敛速度慢、无法满足自动驾驶的实时性要求和准确度低等问题,无法适用于复杂的道路场景分割[4]。
在已有的文献中,早先图像语义分割(image semantic segmentation,ⅠSS)[5]技术一般采用纹理基元森林(texton forest,TF)或随机森林(random forest,RF)等方法构建语义分割的分类器[6]。全卷积网络(fully convolutional network,FCN),将传统卷积网络中的全连接层全部替换为卷积层,提高了图像分割的准确性和效率[7]。但为了提取更细致的特征,FCN需进行多次下采样并保留池化过程中所舍弃的位置信息,会造成较大的空间信息损失。针对这一问题,提出了编码-解码(encoder-decoder,ED)体系结构,使用编码网络获取图片的高层语义特征图,并在解码部分,还原图像的细节特征和空间尺寸大小,最终实现同等分辨率的输入与输出[8]。同样的,SegNet网络[8]和U-Net网络[9]都使用了ED结构来捕获丰富的空间信息。
为了进一步提升语义分割精度,提出了DeepLabV3+模型[10-12],将ED 结构与空洞卷积空间金字塔(atrous spatial pyramid pooling,ASPP)模块结合[13],以捕获足够的浅层空间信息,从而更精准、全面地恢复目标图像细节,并将注意力机制引入到计算机视觉领域[14]。但是注意力机制忽视了信道和位置的空间信息对高层特征提取的影响。为了解决此问题,Fu等[15]提出双注意力机制(double attention mechanism,DAM)模块,提升了语义分割效果。例如,张汉等[16]将Resnet-50与双注意力机制模块相结合获得了很好的效果。
语义分割技术向轻量化、实时性方向也有过尝试,例如,提出的MobileNet 系列模型。其中MobileNetV1模型采用深度可分离卷积提取特征,以提升模型的计算效率,而MobileNetV2 模型在MobileNetV1 模型的基础上引入了具有反向残差和线性瓶颈的资源高效区块,进一步优化了模型[17-18]。马书浩等[19]通过改进DeepLabV2进行实时图像语义分割。与传统的卷积模型比较,都大幅度降低了模型计算量和参数量,而且极大程度减少了操作数量和实际测量的延迟,但其在分割精度方面无法适配自动驾驶领域。王欣等[20]在U-Net 中引入Mobile-NetV2 与注意力机制,在实时性和分割精度上都有较好表现,但应用的注意力机制缺少对其他维度特征的关注,并且只讨论了人像分割等用途单一的应用场景,没有涉及道路场景这种具有高复杂度、多影响因素的应用。
针对以上不足,本文提出了一种参数量小、实时性高、图像分割精准的并行轻量级模型(parallel lightweight model,PLM)来应对自动驾驶过程中的复杂道路场景。该模型以DeepLabV3+模型为基础,采用MobileNetV2 作为主干网络,并设计特有并行特征处理结构。MobileNetV2 使模型计算过程更加集中,能减少获得分割结果的时间,并且会大幅减少参数量,使模型更加轻量。并行特征处理结构则提高了图像分割的精准度。实验结果表明,该模型能够兼顾图形分割精度和实时性,更加适应自动驾驶过程中复杂道路环境。
1 PLM模型
1.1 PLM模型整体结构
PLM 模型(如图1 所示)基于DeepLabV3+,首先采用MobileNetV2 为主干网络;其次将MobileNetV2 与由ASPP和DAM组成的并行特征处理结构相结合,以完成对图像特征的提取;然后将提取出的高级特征图先后进行双线性插值上采样和特征融合;最后对融合结果上采样,得到最终分割图像。PLM模型中的MobileNetV2部分能以少量的参数和集中的计算过程精准且高效地完成模型初始特征提取,同时其并行特征处理结构对输入图像的重要区域和类别重点关注,并优化物体分割边界,提高分割精度。两者结合使得模型能更好地理解道路场景图像内容。
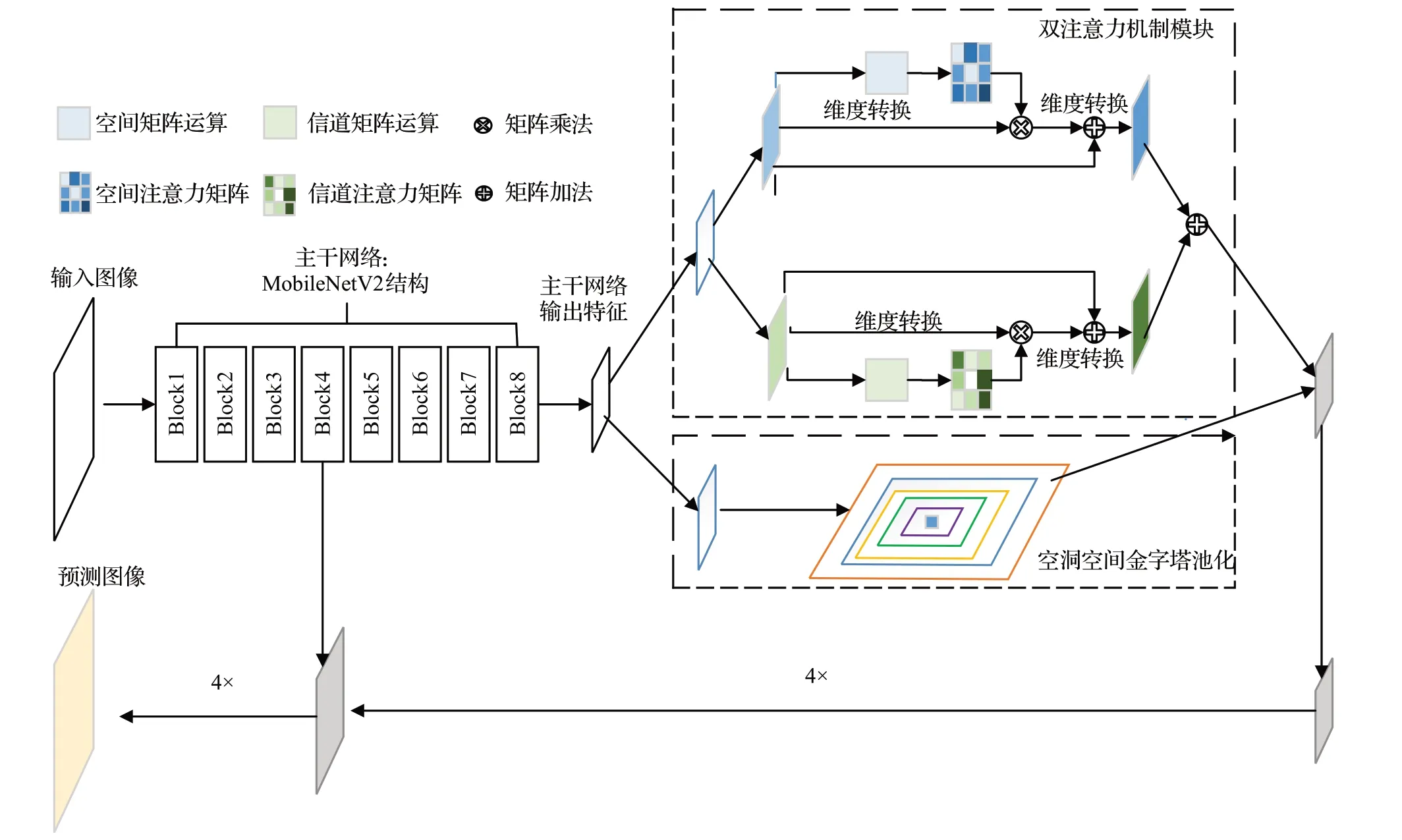
图1 PLM模型整体结构Fig.1 Overall structure of PLM model
1.2 基于MobileNetV2的初始特征提取
DeepLabV3+模型的主干结构为Xception。Xception计算过程较为零散,整体结构体量大,参数量较多,导致其系统开销较大。而MobileNet系列网络主要采用深度可分离卷积,其中MobileNetV2具有线性瓶颈的逆残差结构进一步提高了网络性能。因此,MobileNetV2在结构上比Xception更加轻量,计算过程更加集中。将其应用在自动驾驶邻域中能够在保持分割准确度的同时,减少10倍左右的系统资源消耗。
表1 是DeepLabV3+主干网络Xception 结构。其中通道数表示神经网络每层输入通道数;操作主要有以下几种:卷积、极致的Ⅰnception以及平均池化;输出步长表示输入图像与当前特征图大小的比值;Count 表示输出通道数;n表示该层重复次数;Stride表示卷积的步幅。

表1 DeepLabV3+主干网络Xception结构Table 1 DeepLabV3+ backbone network Xception structure
Xception中极致的Ⅰnception模块的输出卷积图,设Stride为1,padding如(1)所示:
其计算量为:DK×DK×M×N×DF×DF,M表示输入通道数,N表示输出通道数,DK表示卷积核大小,DF表示输出特征图大小。
MobileNetV2 的深度可分离卷积对每个通道使用一种卷积核,padding可以写为:
其计算量为:DK×DK×M×DF×DF,经过逐点卷积以后,深度可分离卷积的计算量变为:DK×DK×M×DF×DF+M×N×DF×DF。分析两者计算量可得:MobileNetV2相较于Xception少了8~9倍的计算量。
为了进一步提高实时性,且使MobileNetV2更加契合分割任务,在MobileNetV2 的基础上截取其前八层,以减少特征图的通道数量,从而降低资源消耗,提高实时性。将MobileNetV2 七层和八层的普通卷积换为空洞卷积,并把第七层的步长改为1。优化后的Mobile-NetV2网络结构如表2所示。
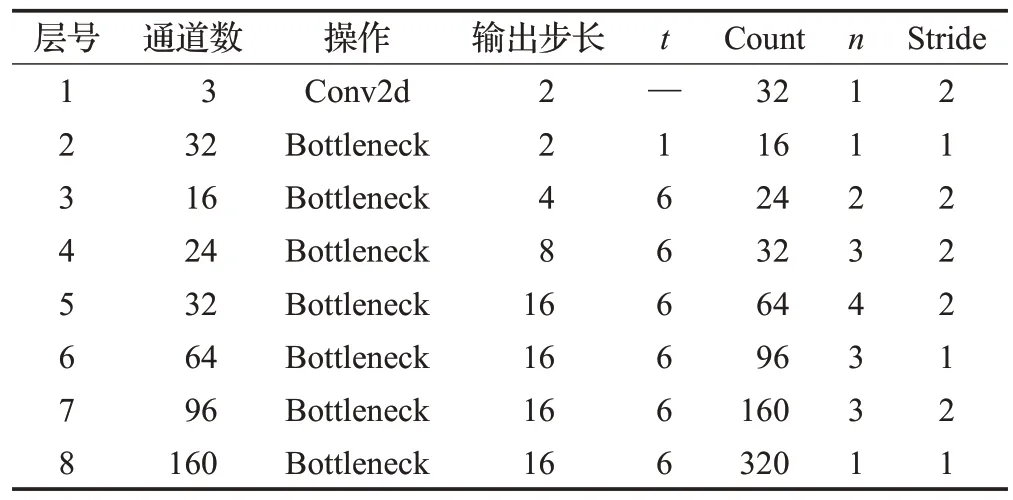
表2 优化后的MobileNetV2网络各层结构Table 2 Ⅰmproved layer structure of MobileNetV2 networks
其释义与表1相同。对比表1和表2可得出以下结论:
(1)DeepLabV3+模型原有主干结构Xception 的通道数最高可达2 048,而改进后的MobileNetV2 模块各层通道数明显减少,最高仅达到320,因此能极大地减少开销,增加实时性。
(2)Xception模块计算过程零散,特征提取效率较低,而改进后的MobileNetV2模块层数相对较少,计算过程相对聚集,可以更快收敛,有助于网络的迁移和训练。
因此,采用MobileNetV2作为PLM的主干网络更符合自动驾驶高精度、低消耗和高实时性的要求。
1.3 并行特征处理结构
自动驾驶过程中有大量不规则图像数据需要处理,因此高精度和实时性都需要得到更好的保障,以此保证驾驶安全。为此PLM引入了双注意力机制,计算分配注意力权重以指导特征学习,在极大增加模型特征表达能力的同时,重点关注重要特征和类别,抑制非必要的特征与类别。并将双注意力模块与ASPP并行放置组成并行特征处理结构,使PLM在保留ASPP模块多个比例捕捉图像信息的同时,选择性地聚合每个位置的特征以及再分配卷积信道之间的资源。图2为并行特征处理结构图。

图2 并行特征处理结构图Fig.2 Parallel feature extraction structure diagram
位置注意力模块(position attention module,PAM)计算过程如下式:
最终输出特征Pj除了其原始特征外,还聚合了特征图位置的特征,使得网络即使没有学习到新的特征也不会丢失原始特征信息。
信道注意力模块(channel attention module,CAM)计算过程表示如下式:
每个卷积核对应通道的最终结果特征Pj是所有通道的特征与从原始骨干网获得的局部特征的集成。CAM可以利用所有通道的空间信息之间的相关性和依赖性来重新调整特征图,以增强特征的可辨别性。
综上所述,PLM 模型通过双注意力机制模块和ASPP模块,可以更有效地学习环境特征,提高图像的分割精度,从而更好地保障自动驾驶行驶安全。
2 实验设计与结果分析
2.1 实验环境及参数设置
实验采用公开数据集Cityscapes,使用深度学习框架Pytorch,实验的软硬件配置如表3所示。

表3 实验软硬件配置Table 3 Experimental hardware and software configuration
2.2 定量评估指标
使用平均交并比(mⅠoU)、类别平均像素准确率(MPA)、时延(latency)作为定量指标。下面分别对这三个指标进行介绍。
(1)平均交并比(mⅠoU)
该指标分别对每个标注类别计算其交并比(ⅠoU),然后再求所有类别的交并比的平均值。mⅠoU的值越大,代表分割精度越高。mⅠoU的计算公式如式(7)所示:
(2)类别平均像素准确率(MPA)
MPA 分别对每个标注类别计算像素准确率,然后再对所有类别的像素准确率求均值。MPA 的值越大,图像分割性能越好。MPA的计算公式如式(8)所示:
(3)时延(latency)
在表3所列的软硬件配置下,模型对图像进行分割的平均耗时。
2.3 实验设计
实验设计共分为三个部分:
(1)分析模型整体结构,对不同模型结构进行对比分析。
(2)为了验证改进后的网络模型分割性能,在相同的实验环境下,对改进前后的模型进行对比。
(3)将PLM 与近年来提出的经典语义分割模型进行定量对比。
2.3.1 模型结构分析
模型的结构、各模块间的相互位置以及模型的参数都会严重影响最终的分割效果。因此本小节针对以上这些影响因素进行了对比实验及分析,具体如下:
(1)DAM模块与ASPP模块的连接方式会直接影响模型对特征的提取效果,进而影响最终分割结果的准确性。表4是两个模块不同连接方式的对比。
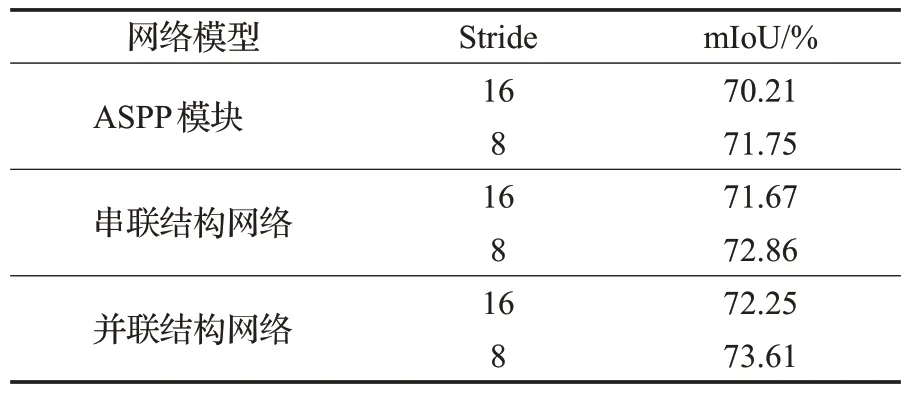
表4 不同方式连接DAM与ASPP的性能对比Table 4 Comparison of DAM and ASPP performance under different connections
由表4 可知,无论DAM 与ASPP 是串联还是并联,对模型性能都有促进作用,且并联结构性能优于串联结构。当Stride 为8 时,DAM 对网络的提升比Stride 为16时更加明显。所以PLM选择Stride为8的并联结构。
(2)ASPP 模块的rate 值会直接影响空洞卷积中各个元素之间的距离,进而影响分割精准度,而模型的参数量也会受到ASPP 通道数量的影响。因此,为了降低消耗、提高实时性,对ASPP中的rate组合和通道数量进行了实验,如表5所示。
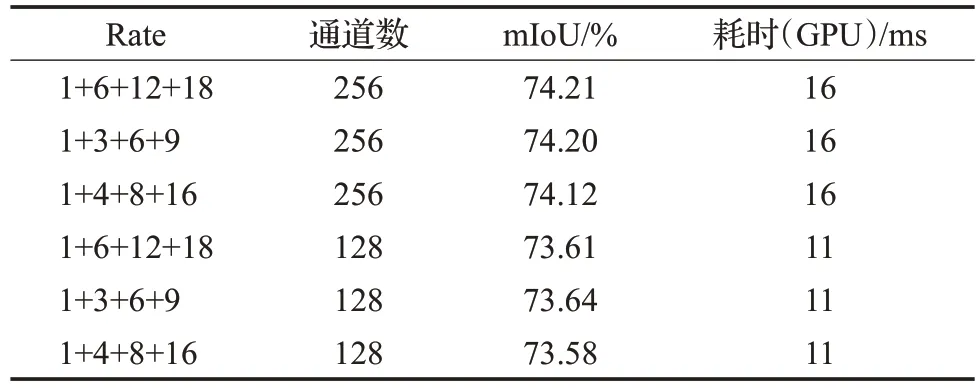
表5 ASPP不同rate值下性能对比Table 5 ASPP performance comparison of different rates
由表5可知,rate值的改变对模型性能影响不大,而通道数量对模型性能有较大影响。当通道数从256 减少为128 时,模型性能稍有下降,但参数量仅为原参数量的二分之一,使得所占用的系统资源和时间也极大减少。通过分析实验数据可得,当rate为1、6、12、18,通道数为128时,PLM整体性能最好。
2.3.2 模块性能分析
为了更好地体现PLM 各模块的作用,实验中将模型分为三类,分别是Xception+ASPP(DeeplabV3+)、MobileNetV2+ASPP 以及MobileNetV2+PFES(PLM),并对这三类模型分别进行比较和分析。
PLM在Cityscapes数据集上进行训练时,其损失函数和mⅠoU的变化分别如图3、4所示。
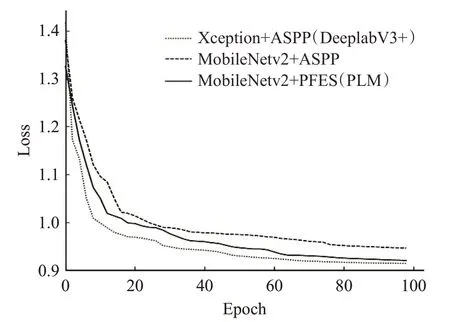
图3 损失函数变化曲线Fig.3 Loss function change curve
由图3 所知,损失值在40 轮迭代后趋于稳定,其中MobileNetv2+ASPP 模型最终损失值最大,PLM 次之,而Xception+ASPP模型最终损失值最小。同时分析图4可以得出,在Cityscapes 数据集上,MobileNetV2+ASPP模型mⅠoU 达到了70.59%,Xception+ASPP 模型达到了74.35%。而在此基础上,通过并行特征提取结构以及MobileNetV2 模块用很小的计算代价使mⅠoU 提升到73.61%。

图4 mⅠoU变化曲线Fig.4 mⅠoU change curve
表6是三种模型在分割精度、存储空间以及平均时延等三个方面的实验对比数据。从表6 可知,PLM 模型相比MobileNetV2+ASPP模型mⅠoU提升了3.02个百分点。而在存储空间和平均时延方面,PLM 比Mobile-NetV2+ASPP 模型多了55.94 MB 的存储空间和7 ms 的时延,比Xception+ASPP 模型减少3 083.26 MB 的存储空间和225 ms的时延。

表6 三种模型性能指标对比Table 6 Comparison of performance indicators of three models
结合图3、4 以及表6 分析可知,使用MobileNetV2作为主干模型可以在保持精度的同时,大幅度减少模型参数量、时延和系统性能消耗,提高了实时性。并且本文所提出的并行特征提取结构对模型的分割精度和整体性能都有较大提升。
2.3.3 本文模型与经典模型的定量对比
将PLM与FCN、DFN 和PSPNet[21]等模型在分割精度与实时性方面进行定量对比。在Cityscapes 数据集下,不同模型得到的mⅠoU、类别平均像素准确率和时延结果,如表7所示。

表7 本文模型与经典模型对比Table 7 Comparison of proposed model with classical model
在对比实验中,统一输入图像像素为512×512,DeeplabV3+、MobileNetV2+ASPP以及PLM的mⅠoU分别排在第3、4、6名,但在实时性要求(>30 FPS)和时延方面,MobileNetV2+ASPP和PLM表现优于其他模型。表7中mⅠoU最高的是PSPNet模型,但其时延高达3 384 ms,实时帧率仅0.3,DFN 也是如此,时延高达1 248 ms,这都远远达不到实时处理要求。而PLM 能够将mⅠoU 保持在73.61%的情况下,达到39.7 FPS 的实时帧率,所消耗的时间仅为PSPNet的0.74%,DFN的2.00%。且对于其他经典模型,无论是在分割精度还是实时处理方面,PLM 模型都更为出色。因此,PLM 模型更适用于自动驾驶这种需要兼顾高精度和高实时性的复杂情形。
3 总结
本文设计了轻量级交通场景图像分割模型PLM,该模型能在保证语义分割高精度的情况下,极大地减少模型参数量以及语义分割所消耗的系统资源与时间。首先,使用MobileNetV2 进行初级特征处理,精简上采样过程,有效减少网络参数量,以便于网络迁移和训练;然后,引入双注意力机制选择性地聚合每个位置的特征,并再分配卷积信道之间的资源,最后设计并行特征提取结构,多个比例捕捉图像信息,更有效地学习环境特征。实验结果表明,PLM模型在Cityscapes数据集下mⅠoU 达到73.61%,处理一张512×512 的图片仅需25 ms,相较于传统语义分割模型极大地减少了网络参数量与消耗时间。
