基于注意力增强的行人与头肩级联检测算法
2023-10-10庄淑青张晓伟宋明晨
庄淑青,张晓伟,曹 帅,宋明晨
1.青岛大学 计算机科学技术学院,山东 青岛 266071
2.海信研究发展中心虚拟现实部,山东 青岛 266071
目前,行人检测技术的发展势头强劲,对智能视频监控、智能交通和自动驾驶等当今流行的智能化领域产生了极其重要的影响[1]。行人检测可以为智能化领域的发展提供安全保障,是交通安全系统中的核心技术之一。而遮挡是影响行人检测准确率的主要因素之一,有效解决遮挡问题,具有重要的研究意义和实际应用价值。
传统的行人检测[2-3]首先通过手工设计特征来提取数据的某些重要特征,再将特征数据进行分类,这样会存在误差较大的风险。同时由于其提取的特征等级相对较低,也无法准确描述行人的语义信息。当行人之间存在遮挡时,行人检测效果不理想。随着深度学习[4]概念的提出,基于深度卷积神经网络的行人检测也获得了更进一步的发展。但是,面对行人复杂的遮挡情况,仍会出现较多的漏检情况,行人检测的准确率依然不高。因此,许多用来应对行人检测中遮挡问题的算法解决方案被不断提出。针对行人检测中的遮挡问题,文献[5]从注意力机制的角度,探索了身体部位与通道特征之间是否存在相关联系,并证实了这一点。其在网络中通过添加处理遮挡的引导注意力网络,明显提升了网络对于遮挡行人的检测效果。文献[6]提出了基于遮挡情况下的感知算法,其将整个人体划分为5 个区域,根据遮挡程度对每个区域分别预测遮挡率,最终的候选区域特征由每个区域遮挡率和对应的特征区域相乘再相加得到。文献[7]针对行人与行人之间的遮挡问题,提出了一种新的损失函数,目的是让预测框在不断靠近目标标注框的同时排斥其他的标注框。文献[8]对于重叠框,引入权值函数,堆叠区域越多,算法置信度结果降低越严重。文献[9]创新性提出tube feature aggregation network这一新方法,对于被遮挡的行人,考虑从相邻帧中去寻找比较少遮挡或未被遮挡的目标,从而对被遮挡的行人起到辅助检测的作用。文献[10]提出了一种anchor-free的多视角行人检测算法,通过多视图融合和空间聚集来解决行人之间的遮挡问题。文献[11]为了共享多尺度特征信息,通过多个卷积层级联和密集连接,目的是能够利用上下文信息来解决遮挡问题。受上述文献的启发,本文分别从注意力机制和人体的特定部位角度处理行人的遮挡问题。
相较于其他行人检测模型,R-FCN(region-based,fully convolutional networks)[12]网络模型是一个检测性能更优的模型,该模型于Faster R-CNN[13]的基础上通过算法调优及模型改造得出,在检测精度与检测速度上均取得了不错的表现,拥有大的提升。但它同时也有一定的局限性:在遮挡情况下,依旧无法很好地解决行人检测的算法执行准确度。因此,为提高图片中人体在存在遮挡情况时的算法检测能力与识别效果,本文在基于Resnet50+DCN[14]特征提取网络的R-FCN模型上加入与检测任务相适应的注意力机制模块,提升模型对遮挡区域的特征学习。同时,受文献[15]启发,本文针对行人的遮挡问题,基于R-FCN 网络模型设计了行人整体与行人头肩区域的级联检测器,其中行人头肩区域检测与行人整体检测时共享检测头部特征,然后通过本文设计的行人整体与行人头肩区域匹配算法,级联两个分支的检测结果,从而确定出遮挡行人的空间位置,可以在一定程度上避免由于图片中行人的下半身遮挡带来的行人漏检问题。总体而言,本文的主要贡献及创新可以概括为以下三点:
(1)在行人检测器的行人识别阶段,针对分类任务和回归任务分别使用相契合的注意力机制,增强特征的表达能力,来优化对行人进行候选区域标定的准确率,减少遮挡行人的漏检率。
(2)设计行人整体与行人头肩区域级联检测器,在行人检测模型的基础上加入行人头肩区域检测分支,对于未检测到的行人,通过检测其头肩区域,然后根据行人固有的身体结构比例,生成行人整体包围框,从而提升行人之间相互遮挡的检测效果。
(3)在Caltech 和ETH 数据集上取得了较好的行人检测效果,尤其对行人之间存在遮挡情况时,检测效果有明显提升。
1 基于DCN的R-FCN行人检测模型
本文使用的是全卷积的R-FCN 网络模型,相比于其他网络模型,其创新性地添加了位置敏感得分图,并将其置于已训练好的卷积层(即共享卷积层)的最后一个卷积层之后,对提升模型性能起到了至关重要的作用。该部分整体的网络结构如图1 所示,对于行人检测中行人这一类别,每一个得分图用来表示人体的某部位出现在得分图某处的概率,在某部位出现的概率越大,此处就有较高的响应值。通过基于位置敏感的RoⅠpooling(position-sensitive RoⅠpooling),RoⅠ与得分图可构成一一对应的强关联关系。最终,整个模型通过softmax函数对属于每个类别的概率进行计算。对于行人这个类别,如果得分是最大的,则判定为行人。

图1 R-FCN检测框架Fig.1 R-FCN detection framework
对于特征提取网络的选择,本文在3.3.1 小节设计了ResNet50+SE[16]与Resnet50+DCN 针对行人遮挡问题的有效性实验,最终将R-FCN 特征提取网络从原有的Resnet-50[17]替换成Resnet50+DCN 网络。加入DCN(deformable convolutional network)后的网络模型可综合目标物体形状以及大小不同这两个特征,做到对感兴趣信息特征的准确提取。
2 注意力增强的行人与头肩级联检测网络
为提高在遮挡情况下的行人检测效果,本文创新性地提出了基于注意力机制的行人和头肩区域级联检测模型。此模型是在上述添加了注意力机制的R-FCN行人检测器的基础上构建了行人头肩区域检测器,该模型主要包含两个模块,具体网络结构如图2 所示,分为注意力机制模块和行人与头肩级联检测模块。由于行人检测过程本身存在不同的任务需要处理,因此针对不同的任务,相应的使用不同的通道注意力和空间注意力来进一步增强特征的表征能力。经实验验证,该级联检测器可显著地提升遮挡情况下的行人检测效果。

图2 整体网络架构Fig.2 Overall network architecture
2.1 与检测任务相适应的注意力机制模型
由于注意力机制本身的技术特性,使其成为计算机视觉领域的各种算法理论中重要的一环。注意力机制包含通道注意力和空间注意力这两种注意力机制。通道注意力机制指导网络解决“是什么”的问题,关注类别的划分,空间注意力机制指导网络解决“目标在哪”的问题,更倾向于定位目标的空间位置。而行人检测网络阶段由分类网络和回归网络组成,分类网络对行人实例的潜在区域进行判别,用来区分行人区域或非行人区域;回归网络对行人实例的区域进一步的精细化处理,使得预测的包围框紧紧包围行人。
本文探索了注意力机制添加方式对于网络的影响,如图3所示,图3(a)将注意力机制加入特征提取网络和检测头中间,以此来增强检测头部特征,此时分类网络和回归网络共享一个检测头。图3(b)将注意力机制引入到检测头之后,通道注意力与空间注意力共享检测头部特征。经实验验证,在分类子任务网络中加入通道注意力模块,以增强特征的表征能力进行分类;在网络的回归阶段,引入空间注意力机制并进行相应的实现,在抑制数据背景信息的同时,更好地突出数据前景信息,进而准确完整地定位出行人的空间位置。

图3 注意力机制添加方式Fig.3 Method of adding attention mechanism
本文设计的与检测任务相适应的注意力机制模型如图4 所示,该网络基于R-FCN 基本架构,主要由3 个模块组成,分别为Resnet50+DCN特征提取网络模块、基于RPN的候选区域提取模块和与检测任务相适应的注意力机制行人预测网络模块。Resnet50+DCN特征提取网络负责提取图片中行人特征,然后输入到RPN 网络检测出行人潜在区域,最终与检测任务相适应的注意力机制行人预测网络模块对行人潜在区域进一步精细化分类和边界框回归。整个网络可以端到端进行训练,其损失函数定义如下:
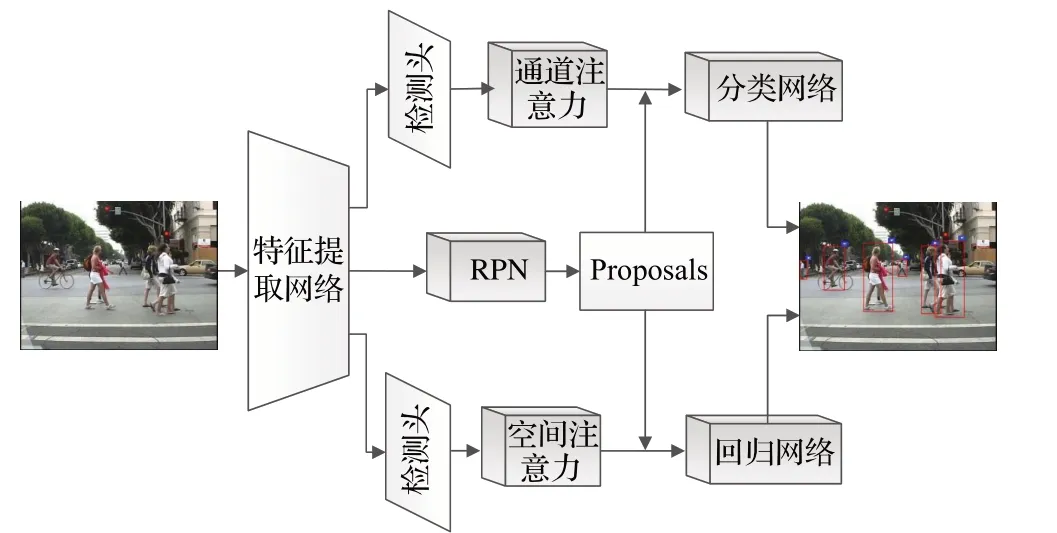
图4 与检测任务相适应的注意力机制模型Fig.4 Attention mechanism model adapted to detection task
其中,Lrpn和Lrcnn分别对应RPN 子网络和RCNN 主网络的损失函数。RPN 子网络没有区分行人整体区域类别,只区分前景和背景信息,因此RPN子网络的多任务损失函数定义如下:
其中,Lcls为交叉熵损失函数,Lreg为Smooth-L1 损失函数,φ为一个超参数,y=1 表示只对前景样本进行回归。在RCNN主网络中,对于行人整体进行精细化分类和位置回归,其损失函数定义如下:
其中,p和b为标注类别和标注包围框,p*和b*为网络预测的类别和空间位置,λ为平衡因子,本文实验中设置λ=10。
2.1.1 全卷积通道注意力机制
SE-Net(squeeze-and-excitation network)是经典的通道注意力网络,其中SE 模块通过对特征的不同通道进行加权,从而实现对不同通道特征中重要程度的计算,最终可使卷积神经网络本身性能得到增强,以获得更强的特征表达能力。如图5所示,它是利用两个全连接层来实现这一重要操作的。采用先降维再升维的方法,即第一个全连接层用来降维,第二个全连接层输出和输入特征维度一样的权重。特征图之间有着密切的关系,彼此都有交互。
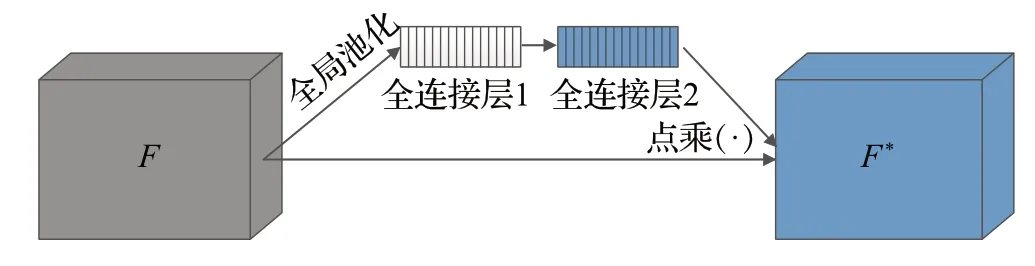
图5 SE-Net网络结构Fig.5 SE-Net network structure
但研究表明,降维操作降低了网络学习特征通道间依赖关系的能力,对通道注意力机制预测的权重产生了负影响。
因此本文提出一种全新的通道注意力机制,称为全卷积通道注意力机制。通过采用大小为1×5的卷积核,优化SE 模块的操作,能保证在不降低通道维度的前提下,减少特征图之间的全交互。这一操作可以减少参数量,高效地学习跨通道间的相关性;也可以有效减少通道注意力对预测权重的负影响。同时,本文为增强全局平均池化的聚合特征、弥补单一池化方式的不足,增加了全局最大池化分支,有利于丰富聚合特征信息,以此对遮挡处理产生帮助。在遮挡情况下,通过注意力减少遮挡区域的干扰,从而更好地关注前景区域。增强对前景区域特征地提取,从而更有针对性地处理遮挡。
为了有效减少SE-Net降维操作对预测权重的负影响。如图6 所示,对于输入特征,本文分别经过全局最大池化和全局平均池化得到聚合特征;之后,再由大小1×5 的一维卷积核获取相邻通道间的相关性;最后,两个权重向量相加,加之Sigmiod激活层进行映射,与输入特征通过点成方式,对不同通道特征进行加权,得到最终特征用于分类网络。通道注意力计算公式为:
其中,σ表示Sigmoid激活函数,AvgPool、MaxPool分别表示对特征F的平均池化、最大池化处理,f1×5表示卷积层使用1×5卷积核。
2.1.2 空间注意力机制
空间注意力机制网络能够有效学习到行人的空间位置信息,如图7所示,通过结合平均池化和最大池化,加之包含单个大卷积核的隐藏层对其进行卷积操作,使其在通道维度上与输入的特征图数据保持统一,该理论对应公式为:
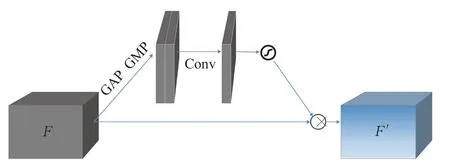
图7 空间注意力机制Fig.7 Spatial attention mechanism
与公式(1)不同的是,此处的f7×7表示卷积层使用7×7卷积核。
2.2 联合行人整体与头肩区域的级联检测器
目前一流的行人检测器均为单类检测任务,也就是在单幅图像的处理中,只对该图像的行人区域进行检测。本文在行人检测结果中发现,被判别为非行人的候选区域可能由于遮挡而发生误判,如图8 所示,图片中标注的α框是目前一流检测器检测出的行人区域,β框是由于行人之间的严重遮挡导致的行人漏检问题,γ框表示由于行人之间的部分遮挡从而导致的行人漏检问题。由于本文实验是基于车载监控视频的行人检测,通过大量的数据分析发现,行人与行人之间存在遮挡时,主要体现在行人的肢体之间存在严重的遮挡,但行人的头肩区域可拥有明显的区分。

图8 行人检测结果Fig.8 Pedestrian detection results
因此基于人体部件的行人检测早在文献[18]中被提出,其将人体分为头肩、躯干和四肢等部分,分别提取这些部分的HOG特征,进行独立建模,最终结合所有组件模型结果进一步确定行人的潜在空间区域。然而DPM 需要花费大量的时间去做模板设计,才能实现其较好的行人检测性能,限制了其在真实应用场景中的使用。因此本文基于深度卷积神经网络,在行人检测的基础上引入了可以对行人之间明显区分的头肩区域检测分支,其中行人头肩区域检测与行人检测模型共享检测头部特征,然后通过本文设计的行人整体与行人头肩区域匹配算法,级联两个分支的检测结果,通过检测行人的头肩区域来确定遮挡行人的空间位置。行人整体与头肩区域级联对遮挡区域的互相补充,在一定程度上不仅可以有效解决由于图片中行人肢体受遮挡带来的行人漏检问题,而且可以极大地降低了模型的推理时间。
2.2.1 行人与头肩级联检测模型
Song等人[19]通过确定人体上配对点连成中轴线,再根据数据集中固定的长宽比例0.41 得到行人矩形包围框。受此启发,行人的头肩区域标签可以根据行人数据集中的行人标签来制作。行人的头肩区域包含头部和肩部,在行人数据集中可以得到行人的包围框B=(x1,y1,x2,y2),其中(x1,y1)和(x2,y2)分别是行人包围框的左上角点和右下角点,由于人体的结构比例基本保持不变,可以得到行人的头肩区域为H=(x1,y1,x2,y1+h/3),其中h表示行人包围框的高度。行人整体数据集和行人头肩区域数据集示意图如图9所示,左侧为Caltech数据集中的行人图片,右侧上方是行人整体实例,右侧下方是行人头肩区域实例。

图9 人体头肩区域定义Fig.9 Human head and shoulders area definition
本文的训练过程与目标检测模型的训练过程相似,数据集图片由Resnet50+DCN特征提取网络进行特征提取,然后由RPN(region proposal network)[20]网络获取行人和头肩区域的候选区域,最后在经过通道注意力和空间注意力增强的检测头部特征上根据候选区域进行裁剪分别送入分类网络预测出行人和头肩区域类别和回归网络回归出行人和头肩区域的包围框。整个网络而言,该网络能够端到端地训练。相应的,该网络所对应训练过程中的损失函数定义如下(出发点):
Lhead_rpn和Lperson_rpn分别代表行人头肩检测分支和行人整体检测分支的RPN 子网络损失函数;Lhead_rcnn和Lperson_rcnn分别代表行人头肩检测分支和行人整体检测分支的RCNN主网络损失函数。
2.2.2 行人检测推理
首先,由于在本文的行人检测算法中,每个行人框的来源不同,因此在每个框上为其增加自定义的内容标签,分别使用WP、HS、RP表示不同含义,其全称与解释如表1所示,为了防止标签重叠,HS与RP标签于框的左上角生成,WP标签于框的右上角生成。

表1 行人框内容标签Table 1 Pedestrians box content label
接下来,根据训练好的模型,可检测出潜在的行人区域和行人头肩区域生成的检测结果,对应的行人框标记为WP与HS。
本文中两个分支分别进行头肩和整体检测,两个检测分支分别得到预测的头肩区域和行人整体区域,即为头肩区域包围框集合和行人整体包围框集合,如图10所示。从图中可以看出,预测的行人整体包围框和头肩区域包围框存在大量的重合,即标注的为同一行人,因此,本文设计行人整体与头肩的匹配算法。该算法以两个分支的检测结果作为输入,首先,将预测的行人整体包围框集合按照制作头肩区域的标签时的人体头肩区域定义的比例(1∶3)得到头肩区域2 集合,如图11 所示。然后,将头肩检测分支结果依次与头肩区域2集合计算重叠度(ⅠoU),保留ⅠoU最大值,ⅠoU计算公式如下:

图10 行人整体和头肩检测分支结果Fig.10 Whole pedestrian and head and shoulders detection branch results

图11 由行人整体得到的头肩区域2集合Fig.11 Head and shoulders area 2 set obtained by whole pedestrian
最后,判断ⅠoU 是否大于本文设定的阈值(0.8),如果大于该阈值,则说明该预测的头肩区域包围框与行人整体包围框存在高度重合,则判定为该头肩区域属于预测的行人整体的头肩区域,则匹配成功,如图12 所示,在头肩区域集合和头肩区域2 集合中分别删除所对应的包围框。如果小于阈值,则说明该预测的头肩区域包围框所表示的行人,在行人整体包围框中未找到,则可能是由于遮挡问题造成行人整体检测分支漏检的行人实例。依次遍历所有的头肩区域包围框,最终将得到未匹配成功的行人头肩区域包围框。
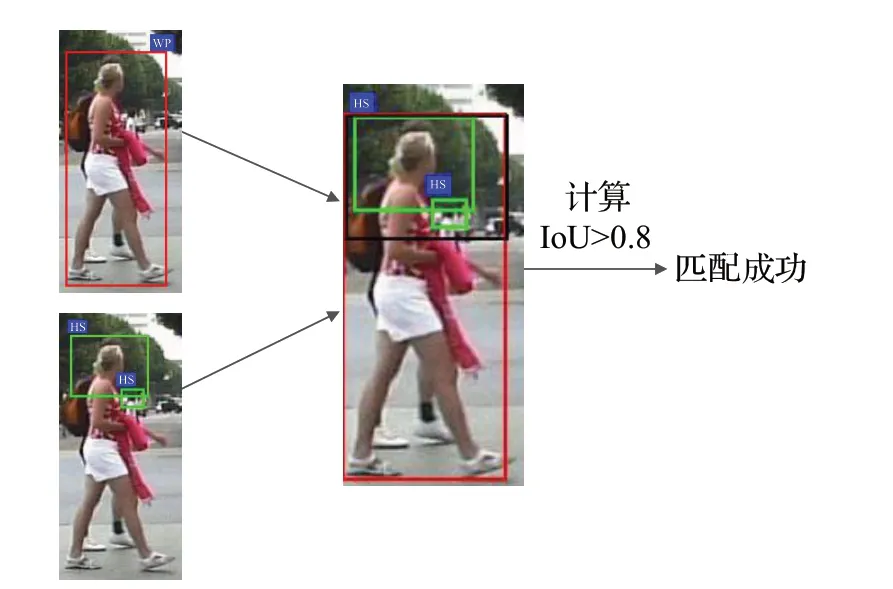
图12 头肩区域2集合与头肩检测分支结果匹配Fig.12 Head and shoulders area 2 set matched with result of head and shoulders detection branch
本文最终结果是将未匹配成功的行人头肩区域包围框按照人体头肩区域定义的比例(1∶3),得到行人整体的包围框,然后再合并到行人整体包围框集合中作为最终结果,如图13 所示。本文未使用匹配成功的头肩区域包围框,因为在实验过程发现,通过头肩区域包围框按照比例(1∶3)得到的行人整体包围框,没有直接预测的行人整体包围框准确,因此本文中直接舍弃。

图13 行人整体与头肩区域的级联检测结果Fig.13 Cascade detection results of whole pedestrian and head and shoulder area
2.2.3 行人区域推演阶段
行人整体与头肩区域级联检测的具体算法过程的伪代码如算法1所示。
头肩与整体的匹配算法:
3 实验结果及分析
3.1 数据集介绍
本文实验在Caltech 数据集[21]上进行训练测试,在Eth[22]和CityPersons 数据集上进行泛化性测试,以此来验证模型的有效性和鲁棒性。Caltech数据集是基于车载摄像头拍摄城市街道的11段视频,其中前6段视频用于模型的训练,后5 段视频用于模型测试,验证模型的准确性。Eth数据没有区分训练集和测试集,因此本文全部用来验证模型的泛化能力。Caltech 训练集设置每3帧选取1张图像[23],同时删除不包含行人的图片,Caltech测试集每10 帧选取1 张图像。测试集具体划分如表2所示,根据行人像素高度和遮挡程度设置了4个测试子集Reasonable、Occ=none、Occ=partial 和Occ=heavy。目前一流的行人检测器均用Reasonable 测试子集评估模型性能,Reasonable 子集设置为:行人数据像素高度不小于50,行人像素可见度不低于0.65。其余3个子集用来验证模型处理行人遮挡问题的性能,Occ=none 子集设置为:行人像素高度不小于50,行人像素可见度为inf;Occ=partial 子集设置为:行人像素高度不小于50,行人像素可见度介于0.65到1之间;Occ=heavy子集设置为:行人像素高度不小于50,可见度介于0.2到0.65之间。

表2 测试子集属性划分Table 2 Test subset attribute partitioning
3.2 实验设置
实验环境为搭载caffe-2 深度学习框架的Linux 系统(Ubuntu-16.04),其配置包括CUDA8.0、python2.7、NVⅠDⅠA GeForce GTX 1080Ti(数量:1),12 GB系统运行内存。训练的epoch 个数为20,学习率(learing-rate)为0.001,权重衰减(weight-decay)为0.000 5,动量因子(momentum)为0.9。本文基于Caltech 提出的行人检测的评估标准LAMR(log-average miss rate)值验证模型性能,随着LAMR值的降低,模型性能会得到更高的提升。
3.3 消融实验
3.3.1 不同网络结构特征提取模块对比
本小节为验证Resnet50+DCN网络作为处理行人遮挡问题的特征提取网络的有效性,对比了ResNet50、ResNet50+SE 和ResNet50+DCN 三种不同的特征提取网络。该实验基于R-FCN 模型,统一在Caltech 训练集进行训练,在Caltech测试集上进行测试,除特征提取网络不同外,保持所有训练参数相同。实验结果如表3所示,Resnet50+DCN在Caltech四个测试子集上的LAMR降低到了7.14%、6.11%、18.38%和32.79%。相较于ResNet50+SE,在Reasonable、none和heavy测试子集中,漏检误差分别降低了0.29、0.18、0.15个百分点。Resnet50+DCN 网络可以对前景信息特征做到准确提取,有效提升遮挡情况下的行人识别率。
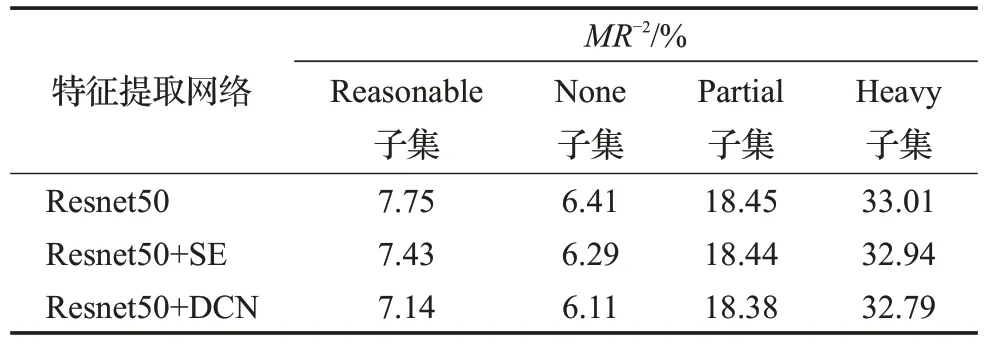
表3 Caltech数据集上不同特征提取网络的性能对比Table 3 Performance comparison of different feature extraction networks on Caltech dataset
3.3.2 注意力机制的消融实验
为验证本文注意力机制对于解决遮挡问题的有效性,本小节主要在Caltech不同测试子集上,对其有效性效果进行验证。本模块基于不同网络结构特征提取模块的对比实验分析,该实验的基线为基于Resnet50+DCN 网络的R-FCN 模型,为验证与检测任务相适应的注意力机制模块的有效性,注意力机制采用通道注意力机制SE-Net 和空间注意力机制。如图3 所示,分别以图(a)方式为在特征提取网络与检测头中间依次引入SE-Net 和空间注意力机制,图(b)方式为在检测头后的分类和回归任务中引入SE-Net和空间注意力机制。实验结果如表4 所示,相比于baseline,在网络中加入通道注意力机制SE-Net 和空间注意力机制,检测性能均得到了提升。表明加入注意力机制有利于增强有效的前景特征,从而提升检测性能。相比于图3(a)方式,图3(b)方式在Reasonable、Occ=none、Occ=partial 和Occ=heavy测试子集上LAMR降低了0.11、0.23、0.35和0.21个百分点。因此,针对不同的任务使用相适应的注意力机制能够提升模型的泛化能力以及对行人遮挡问题的检测效果。

表4 Caltech数据集上注意力在不同位置的性能对比Table 4 Performance comparison of attention at different positions on Caltech dataset
同时该小节对比了本文设计的全卷积通道注意力机制模块与经典的SE模块的性能,该实验基于与检测任务相适应的注意力机制模块的对比实验分析,实验结果如表5所示。在Reasonable、None、Partial和Heavy测试子集上,本文通道注意力机制较SE模块的LAMR降低到6.75%、5.33%、15.79%和31.44%。相比于SE-Net,本文采用1×5卷积核,同时增加全局最大池化分支。这样设计可以有效减少通道注意力对预测权重的负影响,同时丰富聚合特征信息,以此对遮挡处理产生帮助。实验表明,本文通道注意力机制模块对行人遮挡问题具有较好的表现。
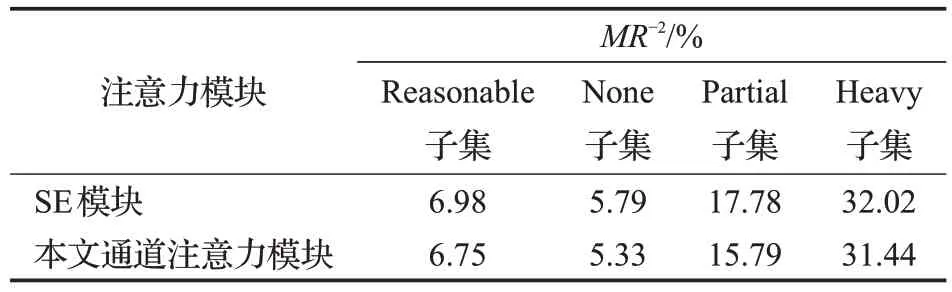
表5 Caltech数据集上选用不同注意力的性能对比Table 5 Performance comparison of different attentions on Caltech dataset
3.3.3 级联行人和头肩检测器对遮挡的有效性
为验证本文行人与头肩级联检测器对于解决遮挡问题的有效性,本小节主要在Caltech不同测试子集上,对其有效性效果进行验证。联合行人整体与头肩区域检测器的实验是在采用注意力机制的行人检测网络的基础上实验的。通过大量的研究发现,在遮挡的情况下,尤其是存在下半身严重遮挡时,可以通过头肩区域,把行人明显区分开。值得注意的是,当使用行人的头肩区域检测器来检测行人时,由于数据集中的行人实例存在骑行、下蹲等不同的行人姿态情况,导致行人的头肩区域和行人的整体比例不满足1/3,因此不能完全将头肩区域的检测结果通过1∶3的比例得到行人整体区域,作为最终结果,否则,得到的行人包围框存在很大偏差,同时,通过头肩区域来得到的行人整体区域,这样得到的包围框没有直接预测行人整体区域得到的包围框位置精确。因此本文只针对未加入头肩区域的行人整体检测模型与加入头肩区域的行人检测模型进行对比实验。与未加入头肩区域的检测模型进行对照,实验结果如表6所示,加入了头肩检测的网络在Reasonable、Occ=none、Occ=partial 和Occ=heavy 测试子集上性能均得到了显著的提升。模型在以上四个测试子集上的LAMR分别降低到5.37%、3.99%、9.67%、23.33%。因此,在行人检测的基础上加入头肩区域检测分支,在很大程度上避免了由于身体下身之间的相互遮挡导致的漏检问题。由上述实验结果,可得到以下结论:设计联合行人整体与头肩区域的级联检测器,通过行人整体与头肩区域对遮挡区域的互相补充,可以显著提升在遮挡情况下的行人识别率。

表6 Caltech数据集上行人检测器的性能对比Table 6 Performance comparison of pedestrian detectors on Caltech dataset
3.4 算法效果对比
本节分别在Caltech、Eth 和CityPersons 数据集上进行算法执行效果的检测。相较于表中出现的目前表现较好的多个行人检测器算法进行了实验对比,如表7所示,本文所表述的具体算法在Caltech 集中体现出了优秀高效的检测性能,在Caltech 四个测试子集上的LAMR 降低到了5.37%、3.99%、9.67%和23.33%。相较于行人检测器AR-Ped[24],在3 个测试子集(Reasonable、None、Partial)中,漏检误差分别降低了1.08、1.22、2.26个百分点。尤其是在Heavy 测试子集上对照当前先进的TLL-TFA[25]行人检测器,LAMR 降低了5.33 个百分点,这是由于本文算法加入了头肩区域检测分支,因此在存在遮挡的情况下,可显著的提升行人检测的算法执行效果。上述内容在量化的实验中,通过不同测试子集的对比结果如图14 所示,本文算法在存在行人遮挡的多个测试子集上表现出较好的检测效果。为形象地观测本文模型在Caltech 数据集上的检测效果,图15 显示了本文方法与当前一流行人检测方法的可视化效果对比。

表7 Caltech数据集上本文方法与目前一流方法的比较Table 7 Comparison of proposed method with some state-of-art methods on Caltech dataset
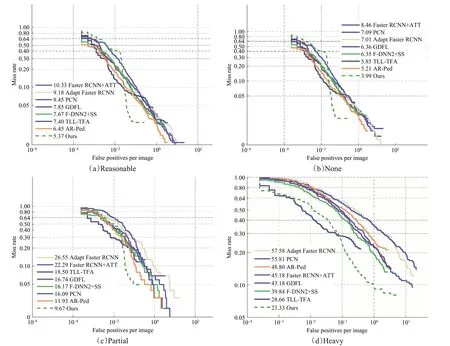
图14 Caltech测试数据集上性能对照Fig.14 Comparison with popular method on Caltech test dataset

图15 Caltech测试集上算法效果对比Fig.15 Comparison of algorithm effects on Caltech test dataset
Eth 行人数据集包含了比较密集、遮挡严重的行人实例,故可表明该数据集具有极高的可研究以及可验证性。本文分别在Reasonable和ALL(行人像素高度大于等于20 pixel,可见度大于20%)上作为测试子集,使用这两个数据集对模型的泛化能力进行测试。如图16所示,本文方法在Reasonable 和ALL 两个测试子集上的LARM分别降低到了29.23%和35.21%。与在该测试集表现较好的F-DDN2+SS行人检测器相比,在Reasonable和ALL两个测试子集上的LARM分别降低了0.79个百分点和3.87 个百分点。实验的具体结果强有力地证明了本文所描述的方法能解决行人遮挡严重情况下的算法精度问题,达到更加准确的行人检测效果。为形象地观测本文模型在ETH 数据集上的检测效果。另外,图17 对ETH 数据集中的图片进行可视化,分别采用两种主流的行人检测算法RPN+BF[30]、F-DNN2+SS与本文算法做对比,由图可见,本文算法在漏检率的降低以及行人识别率的提高上,都有更好的表现。

图16 ETH测试集上性能对比Fig.16 Performance comparison on ETH test dataset

图17 ETH测试集上算法效果对比Fig.17 Comparison of algorithm effects on ETH test dataset
为了验证本文行人整体与头肩区域级联检测模型的泛化性,本文在CityPersons 数据集上进行对比实验。CityPersons数据集是目前比较通用的行人检测数据集,是CityScapes数据集的一个子集。根据CityPersons数据集官方提供的划分标准,可划分为四个子集:Bare子集、Reasonable子集、Partial子集和Heavy子集。Reasonable子集(行人像素高度大于等于50 pixel,可见度大于65%)和Heavy子集(行人像素高度大于等于50 pixel,可见度在20%和65%之间)可以很好地用来评估算法对轻度遮挡和重度遮挡行人的检测性能,故本文使用这两个子集作为测试集对模型的泛化能力进行测试,使用对数平均漏检率作为评价指标。本文选用了在CityPersons 数据集上有代表性的CSP[31]等四种行人检测器进行对比试验。实验结果如表8 所示,本文方法在Reasonable 和Heavy两个测试子集上的LARM分别降低到了10.7%和49.1%。与在该测试集表现较好的CSP行人检测器相比,在Reasonable和Heavy两个测试子集上的LARM分别降低了0.3 个百分点和0.2 个百分点。证明了本文行人整体与头肩区域级联检测算法对解决行人遮挡问题的有效性,通过行人整体与头肩区域级联,可以很大程度上避免了由于身体下半身之间的相互遮挡导致的漏检问题。

表8 CityPersons数据集上本文方法与目前一流方法的比较Table 8 Comparison of proposed method with some state-of-art methods on CityPersons dataset
4 结束语
行人检测中的行人遮挡问题是影响行人检测性能的主要瓶颈之一,本文基于R-FCN目标检测框架,使用了能够有效处理遮挡问题的Resnet50+DCN特征提取网络提取行人特征,设计了通道注意力机制增强了高级语义特征进行分类的方法,同时引入空间注意力机制强调回归的局部细节信息,提高行人检测性能。另一方面,本文设计了行人的头肩区域检测分支,由于该分支存在与行人检测分支共享权重的优势,因此在几乎没有增加计算量的情况下提高了整体的性能。针对多分支检测结果,通过匹配算法来计算头肩区域与行人区域的一致性。实验结果表明,本文算法的实现在两个数据集中均取得了较好的表现。在未来的工作中,将从网络中损失函数的方向来优化,进一步提高对遮挡行人的检测效果。
