集自注意力与边卷积的点云分类分割模型
2023-10-10杨家志周国清霍佳欣陈梦强于广旺张玉阳
沈 露,杨家志,2,周国清,2,霍佳欣,陈梦强,于广旺,张玉阳
1.桂林理工大学 信息科学与工程学院,广西 桂林 541006
2.广西嵌入式技术与智能系统重点实验室,广西 桂林 541006
3.哈尔滨市城市通智能卡有限责任公司,哈尔滨 150000
随着3D点云数据采样技术的快速发展,3D点云数据广泛应用在机器人技术[1]、自动驾驶[2]、虚拟现实[3]等领域,3D 点云数据分类与分割是以上领域中点云数据处理的关键步骤。因此,对点云数据分类与分割的研究具有重要的意义。
近年来,随着卷积神经网络(CNN)在二维图像数据的分类分割中取得了显著的成绩[4],一些学者也尝试将神经网络运用到3D点云数据中。然而,3D点云数据的结构与二维图像数据有所不同,3D 点云数据具有离散分布、非结构化、无序性的特点,给神经网络运用到3D点云数据中带来了挑战。
为了应对这个挑战,一些学者将不规则的点云数据转化到特定的规则区域中以便于用现有的深度网络进行特征学习。Maturana 等[5]提出了基于体素化的方法VoxNet,将点云数据转换到三维体素空间,利用三维卷积进行特征提取,缺点是三维卷积会耗费大量的计算空间与内存。为了解决此问题,Riegler 等[6]提出了OctNet网络,动态地调整分辨率以减少内存的消耗。文献[7]和文献[8]提出了多视图的方法,将3D点云数据投影到二维空间中,利用二维卷积来减少计算量,但在数据转换的过程中,往往会破坏数据的结构,导致显示信息的丢失。针对此问题,Qi等[9]提出的PointNet网络,利用多层感知器与对称函数在原始点云数据上对每个点的特征进行单独提取,缺点是忽略了局部特征。随后,学者们开始研究对点云数据的局部特征的提取,例如,Point-Net++[10]使用最远距离采样和球半径方法和动态图卷积(dynamic graph CNN for learning on point clouds,DGCNN)[11]采用K临近算法(K-nearest neighbor,KNN)来构造局部区域,并提取单个局部领域特征,但忽略了邻域与邻域之间的特征。
针对以上问题,本文根据Transformer[12]中自注意力模块的特性设计出了适合点云数据的自注意力模块,且成功与边卷积模块相结合,提出了集中注意力与边卷积相结合的分类分割网络——Self Attention DGCNN。该模型通过边卷积模块提取每个小的点云局部特征,有效弥补了PointNet算法中忽略点云局部特征的问题,通过设计的自注意力模块提取点云上下文特征并与边卷积模块相结合,有效地弥补了DGCNN模型中忽略了领域与领域之间的特征问题。Self Attention DGCN网络通过自注意力模块根据全局上下文特征生成细化的注意特征和边卷积模块获取的局部特征,再经过多层感知器将这两部分特征进行融合,有效地解决了无法捕获点之间的局部结构信息和邻域之间的特征信息,提高了模型的精度以及模型的鲁棒性。
1 Self Attention DGCNN网络介绍
Self Attention DGCNN 网络由多个边卷积模块和自注意力模块构成。其中边卷积模块主要用以获取点云的局部特征,自注意力模块主要用于获取点云各点的上下文特征,最后经过最大池化层和平均池化层得到两个高维的特征向量再进行拼接操作得到一维全局特征,并通过三个全连接网络得到预测的特征向量。下面将具体介绍边卷积模块和自注意力模块的设计,以及根据这两个模块所构成的分类与分割网络模型。Self Attention DGCNN 网络的总体架构如图1 所示,Self Attention DGCNN 分类网络如图2 所示,Self Attention DGCNN分割网络如图3所示。

图1 Self Attention DGCNN网络总体结构Fig.1 Self Attention DGCNN network general structure

图2 Self Attention DGCNN分类网络模型结构Fig.2 Self Attention DGCNN classfication network model structure

图3 Self Attention DGCNN分割网络模型结构Fig.3 Self Attention DGCNN segmentation network model structure
1.1 Self Attention DGCNN分类网络设计
如图2 是本文提出的Self Attention DGCNN 点云分类网络模型结构图。主要由三个SAConv块组成,每一个SAConv块由一个自注意力块和边卷积块所构成,其详细构成方式如图4所示。SAConv块的输入是n×f的特征向量,同时经过自注意力块输出点的上下文特征n×sout和边卷积块输出局域特征n×eout,其中sout和eout相同,再将得到的上下文特征和区域特征经过concat操作连接在一起,经过多层感知器MLP(multilayer perceptron)输出融合后的特征n×fout,其中fout为sout和eout之和,然后将融合的特征传递到下一个SAConv 块中形成动态特征更新。为了获取最终的特征描述f,本文将最终的全局特征经过最大池化层和平均池化层得到两个高维的特征向量再进行concat 操作得到最后的特征f,将f输入到3 层全连接网络中,用于最终的分类结果。前两层全连接网络采用随机丢弃神经节点技术,丢弃的概率设置成50%,最后一层输出目标预测的最终得分。MLP代表多层感知器,C表示concat表示连接操作,maxpool 表示最大池化层,avgpool 表示平均池化层,FC 表示全连接层(fully connected layers),result表示分类的类别数,n表示输入点云的数量,3表示点云的坐标轴(x,y,z)。

图4 SAConv网络结构Fig.4 SAConv network structure
整个过程的数学描述如公式(1)所示:
1.2 Self Attention DGCNN分割网络设计
Self Attention DGCNN 分割网络结构如图3 所示,它和分类网络结构很相似,采用三个SAConv块来获取整个点云的全局特征,用三层多层感知器来进行不同特征的融合,多层感知器节点数设置为{128,256,512},将全局特征经过平均池化层和最大池化层,通过concat操作连接成一个n×2 048特征向量,再将连接形成的特征向量,全局特征向量与部件特征向量进行concat 操作,形成最终的用于部件分割的特征描述g。将g输入到三层全连接网络中,用于最终的分类结果。
1.3 自注意力层网络模块
受到Transformer[12]中自注意力的启发,本文设计了一个基于3D点云数据的自注意力模块,具体流程如图5所示,F(Q,K,V)具体结构如图6 所示。MLP 代表多层感知器,sub 代表求差,sum 代表求和,transpose 代表维度转换,multiple代表乘法。
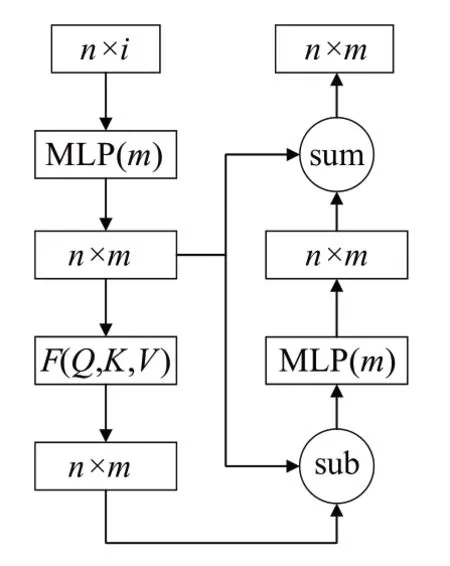
图5 自注意力模块Fig.5 Self-attention module

图6 F(Q,K,V)网络结构Fig.6 F(Q,K,V) network structure
将上一层输出的结经过多层感知器(MLP)得到Nin∈Rn×m,Nin经过设计的自注意力层(SA 层),得到细化的注意特征,详细过程描述如公式(2):
其中,Q是查询矩阵,K是键矩阵,V是值矩阵,Wq、Wk、Wv是可以学习的权重,c是Q和K的维数,l是V的维数,且在设计中,c=l/4,n是输入的点云数量。
先对查询矩阵(Q)和键矩阵(K)进行点积,得到注意力权重σ:
对得到的权重信息进行归一化操作得到θ:
再将得到的θ与值向量的加权和得到自我注意力特征φ:
最后将Nin与φ作差,并将值送入多层感知器并与Nin求和,从而得到最终的结果SAout:
1.4 边卷积网络模块EdgeConv
将上一层的输出作为边卷积层的输入,设Pi∈Rn×f。n为上一层输出的点云数据的点数,f为上一层的特征维数。根据动态图卷积网络原始论文对边卷积(edge Conv)的描述以及实验情况,构建了一个更加详细的边卷积网络,如图7所示。maxpool代表最大池化层。

图7 边卷积网络Fig.7 Edge convolutional network
Xi∈Pi,Xi通过KNN算法获得与Xi最近的K个临近点X(i,j)∈Pi的局部图结构,如图8 所示,具体操作如公式(7)所示:

图8 KNN临近点Fig.8 KNN proximity points
∏表示欧几里德范数,点云数据通过KNN 算法后通过多层感知器抽取出每个点的边缘特征,最后通过maxpool函数得到边卷积的输出结果EAout:
其中,W为该卷积核的权重,ρ为中心点云经过KNN算法后构建的中心点与邻近点的集合,EAout为边卷积块的输出。
2 实验
2.1 数据集与实验参数
本文采用的分类的数据集为ModelNet40[13]与ModelNet10[13],部件分割的数据集为ShapeNet[14]。Model-Net40 数据集有40 个类别分类,一共有12 311 个模型,其中9 843 个模型用于训练,2 468 个模型用于测试。ModelNet10该数据集有10个类别分类,一共有4 899个模型,其中3 991 个模型用于训练,908 个模型用于测试。ShapeNet数据集一共有16个大的类别和50个小的部件类别,一共有16 881个数据模型。
本文实验在以下环境中进行:NVⅠDⅠA RTX 3060 GPU,Windows10 专业版下的Pycharm,python 版本为3.9.7,CUDA 版本为11.3,pytorch 版本为1.10.2;采用随机梯度下降(stochastic gradient descent,SGD)优化器进行优化,训练的周期为300,批量大小为10,初始化学习率为0.1,动量系数为0.9;采用间隔调整学习率,其中step_size 设置成50,gamma 设置成0.3,KNN 中的K设置成20。在数据增强方面,采用0.80~1.25 的点云随机缩放,0~12.5%的随机丢弃,N(0,0.01)随机抖动的数据增强方法。
2.2 实验结果与分析
2.2.1 分类结果分析
为了验证分类模型的效果,在公开数据集Model-Net40 和ModelNet10 上分别做实验。本文采取和其他算法一致的评判规则,计算平均分类率(mean class accuracy,mAcc)和总体准确率(overall accuracy,OA),与近几年来一些基于深度学习的点云分类方法做了比较。比较的算法有:PointNet、PointNet++、3D-GCN、DGCNN、PointCNN、PointASNL、Point Cloud Transformer、PointWeb、MANet、GCN3D、PCNN、KD-Net、JUSTLOOKUP、Point2Sequences、LFT-Net、3DMedPT、DTNet、RCNet-E、A-CNN,比较结果如表1、2所示。

表1 不同方法在ModelNet40数据集上分类的精度Table 1 Accuracy of different methods for classification on ModelNet40 dataset 单位:%
由表1可知,本文方法在ModelNet40数据集上的平均精度(mAcc)达到了90.8%,总体精度(OA)达到了93.5%。在总体精度上比表中近三年基于深度学习的方法3D-GCN、PointASNL、Point Cloud Transformer、MANet、GCN3D、LFT-Net、3DMedPT、DTNet 分别高出1.4、0.3、0.3、1.0、0.5、0.3、0.1、0.6 个百分点;比经典算法PointNet、PointNet++分别高出4.3、2.8 个百分点。在平均精度上比表中近三年基于深度学习的方法GCN3D、LFT-Net、DTNet分别高出0.5、1.1、0.4个百分点;比经典算法PointNet高出4.6个百分点。由表2可知,本文方法在ModelNet10 数据集上的平均精度(mAcc)达到了95.8%,总体精度(OA)达到了95.9%。在总体精度上比表中近三年基于深度学习的方法PointASNL、A-CNN分别高出0.2、0.4个百分点;在平均精度上比表中近三年基于深度学习的方法A-CNN 高出0.5 个百分点。由表1、表2可见,Self Attention DGCN分类网络在ModelNet40与ModelNet10数据集上相比其他网络模型有更好的精度表现。
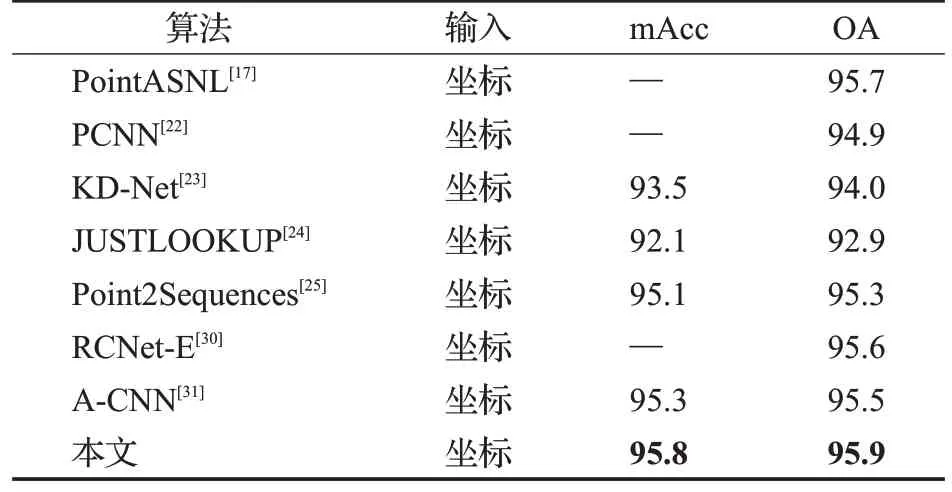
表2 不同方法在ModelNet10数据集上分类的精度Table 2 Accuracy of different methods for classification on ModelNet10 dataset 单位:%
2.2.2 部件分割结果分析
为了验证分割模型的效果,在公开数据集ShapeNet上进行了大量实验。本文采取和其他算法一致的评判规则,计算平均并交比(mean intersection over union,mⅠoU)和各物体单类的并交比(intersection over union,ⅠoU),与近几年来一些基于深度学习的点云分类方法做了比较。比较的算法有:PointNet、PointNet++、3D-GCN、DGCNN、GCN3D、PointConv、3D-GCN、DTNet,比较结果如表3所示,部分物品分割可视化结果如图9所示。
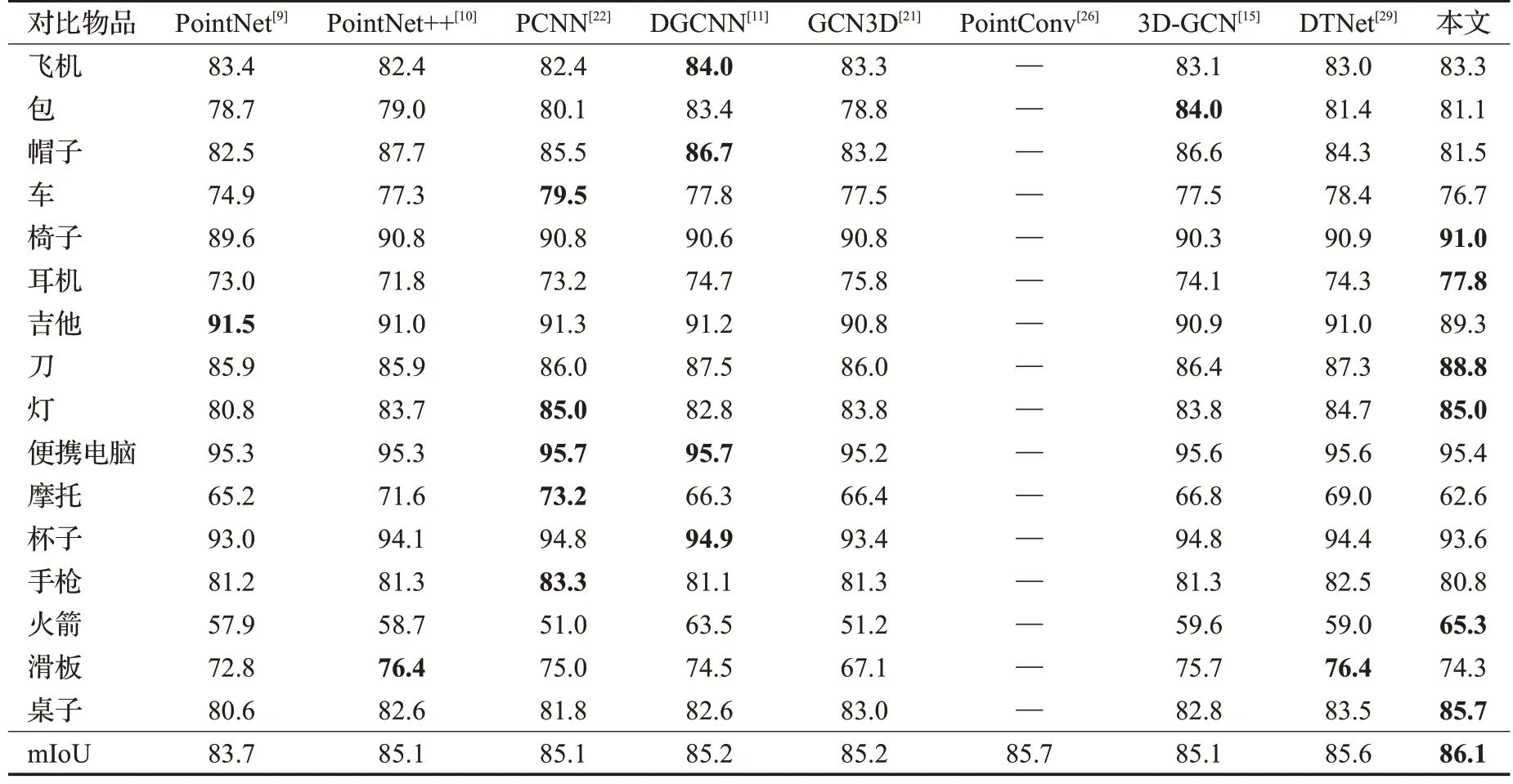
表3 不同方法在ShapeNet数据集上部件分割的精度Table 3 Accuracy of different methods for part segmentation on ShapeNet dataset 单位:%

图9 Self Attention DGCNN分割网络可视化结果Fig.9 Self Attention DGCNN segmentation network visualization results
由表3可见,本文方法在ShapeNet数据集上的平均并交比达到了86.1%,比表中PointConv网络高出0.4个百分点,比最低的PointNet网络高2.4个百分点,比近三年基于深度学习的方法GCN3D、3D-GCN、DTNet 分别高出0.9、1.0、0.5 个百分点。Self Attention DGCNN 分割网络在椅子、耳机、刀、灯、火箭、桌子类别的分割效果很好,从这几类的并交比上看,均高于表中其他方法。图9 从上到下,第一行为原始点云分割可视化结果,第二行为网络测试分割可视化结果。通过表3数据和图9可视化结果可知,Self Attention DGCNN 分割网络在ShapeNet数据集上有很好的分割效果。
2.3 消融实验
本文采用自注意模块提取点的上下文特征和边卷积模块提取局部特征。为了验证这两个模块的有效性和特征融合的有效性,本文在点云分类和部件分割上做了如下实验。
2.3.1 点云分类消融实验
Self Attention DGCNN分类模型包含三层SAConv模块,第一层、二层、三层SAConv 模块的维度分别为128、256、512,每一个SAConv 模块包含一个自注意力模块和边卷积模块。本文通过减少SAConv 模块的数量和减少SAConv 模块中的自注意力模块和边卷积模块来验证各个模块对点云分类任务的有效性。具体实验设置以及实验结果如表4所示。
通过表4 的结果可见,当三层SAConv 模块中只包含自注意力模块时平均精度(mAcc)为84.5%,总体精度(OA)为89.5%,只包含边卷积模块时平均精度(mAcc)为89.9%,总体精度(OA)为92.7%。当只有一层SAConv模块时平均精度(mAcc)为89.3%,总体精度(OA)为92.3%,当增加一层SAConv(256)时,平均精度和总体精度相较一层SAConv(128)提升了1.4 个百分点和0.7 个百分点,当有三层SAConv(128,256,512)时,相较只有两层SAConv(128,256)平均精度(mAcc)提升了0.1 个百分点,总体精度(OA)提升了0.5 个百分点,相较于三层SAConv模块中无自注意力块平均精度提升了0.9个百分点,总体精度提升了0.8 个百分点,相较于三层SAConv 模块中无边卷积块平均精度提升了6.3 个百分点,总体精度提升了4.0个百分点。实验结果表明,自注意力块和边卷积块融合的SAConv 块对点云模型分类性能有显著的提升。
2.3.2 点云部件分割消融实验
Self Attention DGCNN 部分分割模型包含三层SAConv 模块,每个SAConv 块的输出节点数与分类模型基本一致,验证各模块的有效性设置方法与分类一致。具体实验设置以及实验结果如表5所示。

表5 点云部件分割消融实验Table 5 Ablation experiment of point cloud part segmentation 单位:%
通过表5实验结果可知,三层SAConv时,平均交并比(mⅠoU)为86.1%,相较于不同模块设置拥有不同程度的提升,可以看出SAConv模块对点云部分分割性能有着明显的改善。
2.4 鲁棒性实验
为了验证Self Attention DGCNN 网络模型具有较好的鲁棒性,在ShapeNet 数据集和ModelNet40 数据集上对输入点云数量为1 024个点得到的数据模型做{256,512,768,1 024}数量的点云的输入实验。在ModelNet40数据集上的实验结果如表6所示,在ShapeNet数据集上的实验结果如图9所示,ShapeNet数据集上可视化如图10所示。

表6 输入不同点云数量在ModelNet40数据集上分类精度Table 6 Classification accuracy on ModelNet40 dataset with different numbers of point clouds 单位:%
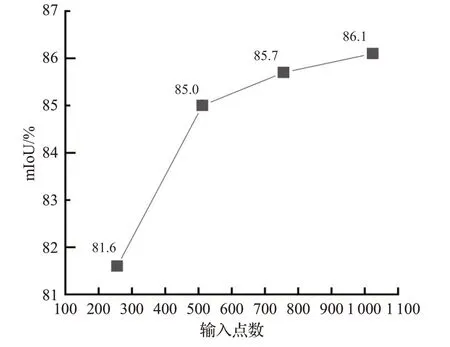
图10 不同点云数量在ShapeNet数据集上分割精度Fig.10 Segmentation accuracy on ShapeNet dataset with different numbers of point clouds
从表6 可见,Self Attention DGCNN 分类网络在数据集ModelNet40上,输入不同数量的点云,在总体精度和平均精度上都是高于DGCNN网络,而且Self Attention DGCNN 分类网络在输入点云只有原模型的四分之一时,平均精度(mAcc)能达到87.7%,总体精度(OA)能达到91.0%,说明本文的分类网络具有较好的鲁棒性。
从图10 可见,Self Attention DGCNN 分割网络在输入点数为256、512、768、1 024时,平均交并比(mⅠoU)分别为81.6%、85.0%、85.7%、86.1%。如图11 从上至下依次为刀、杯子、耳机,从左到右依次的采样点数为256、512、768、1 024。通过可视化和数据对比得知,本文的分割网络在稀疏点云上依旧有较好的鲁棒性。

图11 不同点云数量在ShapeNet数据集上可视化结果Fig.11 Visualization results of different numbers of point clouds on ShapeNet dataset
2.5 超参数实验
在本节中讨论了KNN 算法中的K的取值对模型性能的影响。在ModelNet40数据集上,对输入1 024个点,迭代300 轮的情况下对不同的K值做了详细的测试。测试精度以及测试一轮的耗时结果如表7所示。
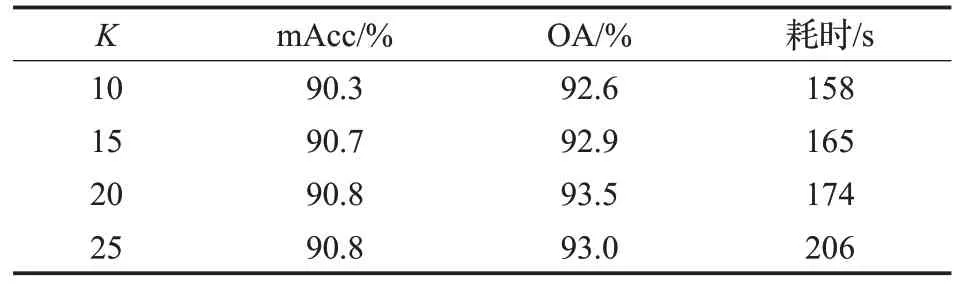
表7 不同K值对网络模型的影响Table 7 Effects of different K values on network model
由表7可知,不同的K值选择对精度和训练时间会有一定的影响,K值太小会使模型的感受野很小,不能很好地捕捉中心点云与周围点云的特征,如果K值太大也会使得模型的精度有所降低,K值越大训练时间也越长。根据以上实验结果图的对比分析并平衡精度和训练时间,本文选择合适的K=20 值来进行模型训练。
2.6 模型复杂度实验
为了验证Self Attention DGCNN 网络模型具有较好实用性,对Self Attention DGCNN网络模型的模型大小及训练耗时进行了对比实验。为了实验的公平性,参与对比的方法均采用相同的设置—训练的周期为300,批量大小为10,初始化学习率为0.1,动量系数为0.9;采用间隔调整学习率,其中step_size 设置成50,gamma 设置成0.3。在ModelNet40数据集上的实验结果如表8所示。

表8 不同网络模型在ModelNet40数据集上性能对比Table 8 Performance comparison of different network models on ModelNet40 dataset
由表8可知,本文提出的Self Attention DGCNN方法在ModelNet40数据集上训练一轮大约需要耗时223 s,训练得到的模型大小为22.2 MB,总体精度(OA)为93.5%。因为本文算法在每一个边卷积模块上添加了自注意力模块,所以在模型大小上比表中其他方法都大。由于自注意模块基本上都是由多层感知器构成且自注意力模块可以有效的获取点云数据中的上下文特征,所以在每一轮耗时上比表中大多数网络都少,在总体精度上比表中所有方法都高。通过对表8分析得知,本文模型具有较好的实用性。
3 结束语
本文设计了适合处理点云数据的自注意力模块和提出了新的网络架构——Self Attention DGCNN。该模型考虑了细化的注意特征和局部特征在点云数据分类与分割中的作用,通过自注意力模块提取细化的注意力特征,边卷积模块提取局部特征,对细化的注意力特征和局部特征进行融合,提升网络的鲁棒性和准确率。Self Attention DGCNN网络在分类数据集:ModelNet10、ModelNet40,分割数据集:ShapeNet上,与经典或者最新的基于深度学习的方法相比,取得了领先或者相当的精度效果。本文提出的算法成功将自注意力模块与边卷积相结合,为后面3D 点云数据分类提供了新的思路与解决方案。当然,Self Attention DGCNN网络仍有很大的提升空间,如更加合理地设计自注意力模块,使得模型的参数量减少,这是将来的研究方向。
