基于Open XML 和有限自动机的试卷自动生成系统
2023-10-09吴为民刘勇峰
林 晓,吴为民,刘勇峰
(1.福建船政交通职业学院 人事处,福建 福州 350007;2.福建船政交通职业学院 信息与智慧交通学院,福建 福州 350007)
考试作为鉴定知识水平的一种方法,已经延续了上千年。命题的全过程包括了几个重要的环节,出题、选题、组题、试卷排版、参考答案、封装。随着信息技术的不断发展,自动试卷生成机制,为命题这一复杂的事项带来了便捷。自动试卷生成机制具有系统、可靠、保密性高、可重复等优势,特别适用于笔试的出题工作。许多笔试对题库保密性要求非常高,有的甚至要求仅在出题的当天,在监督人员的监督下,由出题专家当场解封题库或者现场出题,且出题的环境与外界隔绝联系;除命题专家研究选择考题外,有时还需要工作人员将试题进行电子化转码,以及将电子试题排版、打印、装订、封袋等。在题量大、考生多的情况时,工作人员的人工工作就非常耗时,且容易出错[1]。
1 研究现状
大多数试卷生成系统基于服务器架构的设计,利用数据库对试题进行标准化处理,已有多位学者展开研究,贾寒霜等提出运用ASP.NET 开发,结合SQLSERVER 数据库,利用WEB 数据库存储技术以实现网络组卷在线考试[2];韦忠庆等提出基于SaaS模式,采用改进遗传算法的智能组卷算法实现公布式在线考试[3];韩啸等提出基因表达式编程算法,通过使用适当的遗传算子,采用线性定长的编码方式实现构造智能组卷方法[4];焦瑞等采用计算机提供的随机函数结合智能思路确定试题库结构[5];秦哲韩等为了降低组卷难度和提高组卷效率,采用PHP 技术,结合My SQL 数据库、Excel 文件及手动输入组成的试题库开发新的智能组卷系统[6];王高平等提出通过遗传算法使试卷生成结合课程以及所要考查的知识点,试卷的难度,不同题型的不同分值和数量,以及总分的限制等要求[7]。这种传统的试卷生成系统均需使用数据库软件用于存储试题,出题前期工序复杂,需要拟定大量的题库,且事先规范好格式并录入到系统中。由于在试题录入过程和数据库管理过程,都存在泄密的风险,而且数据库存储题库的可视化程度不高,如何利用计算机技术在封闭的环境下、无数据库题库软件支持、无法事先获得题目的情况下进行快速出题,既要满足考试考务工作保密性高和时间短的要求,又要克服手工操作带来的速度慢、错误多等问题,成为需要解决的问题。
2 基于OXML 的WORD 文档内容的解析与提取
Open XML(Open eXtensible Markup Language)是一种文档的国际化标准,实现文件格式的互操作性。出题人员在现场用于出题的题库资料一般都是以WORD文档的DOCX 格式存储,或者可在现场转为WORD文 档DOCX 格 式。OXML(Open eXtensible Markup Language)架构已经成为通用的标准化,被各大软件厂商所支持的文档架构,可以实现跨平台,在不同的应用中打开[8]。刘伟男对WORD 的OXML 格式进行了分析并开发了智能处理桌面系统[9];杨英等提出了一种针对复制类作弊的检测方法[10]。Open XML 标准使得DOCX 文档、XLSX 文档自动处理成为可能。利用DOCX 格式文档和XLSX 文档的Open XML 的架构,可直接对其内容和格式通过应用程序进行应用层的处理,再生成新的Open XML 文档。这样便可脱离数据库软件,实现题库信息的存储与处理,既满足笔试保密性的要求,又减少笔试出题的人力及时间成本。
WORD 的DOCX 文档以ZIP 包的形式存储,包的格式遵守ISO/IEC 29500-2 标准[11]。ZIP 包里面包含多个Open XML 格式的文件,文件内容包括了XML文档之间的关系定义、文档属性、内容数据,内容类型等,如图1 所示。最基本的DOCX 文档内容文件为document.xml 文件,其结构内容包括

图1 一个word 文档test.docx 包结构图
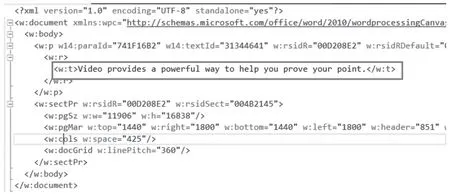
图2 一个word 文档document.xml 样例片段
由于初始的WORD 题库文档是由不同的专家或部门提供的,文档的格式存在不规范、不完全相同的情况,所以系统一开始需要对题库的WORD 文件进行预处理。预处理的内容包括多个方面,例如将DOC 文档转为DOCX 文档;对回车换行用
在预处理完成之后,系统提取出文档包含的文字内容,用正则表达式RE(Regular Expression)实现对文本内容的分割、提取和匹配。例如,规定以阿拉伯数字开始后面有跟踪分隔符的文本是题干,通过使用正则表达式分离出题号、提取关键特征词等来判断是否是题干,其中分离题号的正则表达式如下:
实现对WORD 题库文件的程序级别内容提取与分析,将产生的内容提供给下一阶段有限状态机进行处理。在最后生成试卷、答案卷和答题卡的阶段,根据Open XML 标准对已有的模板生成对应的DOCX文档,如图3 所示。
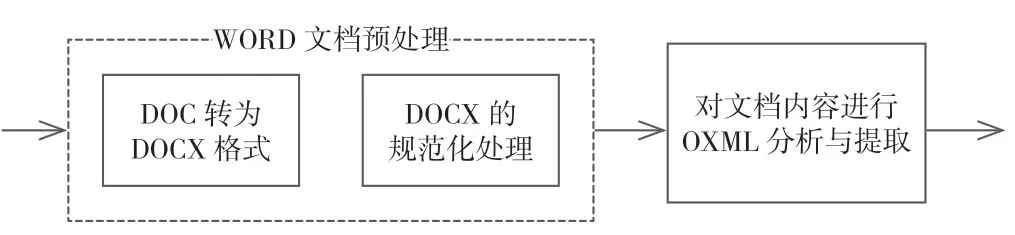
图3 试卷文档预处理流程
3 基于确定性有限状态机的试卷生成设计
通常情况下WORD 题库文件中题目和答案存在于同一个文档中,则需要对其内容进行分析判断和分类处理,再依据组卷策略生成最终需要的试卷。本研究利用有限状态自动机原理对文本的内容进行分类处理。
有限状态机(FSM,Finite State Machine)是基于单个对象状态转换序列的计算模型[12-13],对象在任意一个时刻只有一种状态,根据输入的不同,使得对象从一种状态迁移到另外一种状态,并执行不同的动作。本研究使用确定的有限状态自动机(DFA,Deterministic Finite Machine),其定义如下:
其中Q是所有状态的集合,∑是所有输入的集合,q0代表初始状态,F是接受状态的集合,δ是状态转移函数Q×∑→Q。
本研究利用确定性有限状态机对题库的读取过程进行建模。从题库的WORD 文档中提取出的段落文字按内容分为三个类别,分别是题干部分、选项部分、答案部分。每次读取word 一个段落,根据读取的内容使状态机进入不同的状态,进行相应的读写操作。根据有限状态机的定义:
表1 表示输入的动作内容列表。表2 中A代表文字内容检测结果A,B代表文字内容检测结果B,C代表代表文字内容检测结果C,D代表代表文字内容检测结果D,S0代表IDLE 状态,S1代表题干状态,S2代表选项状态,S3代表答案状态,S4代表结束状态。

表1 输入动作表

表2 状态转移函数表
本系统的确定性有限状态机模型如图4 所示,圆形代表状态,同心圆代表接受状态F。我们默认文档的第一段是题干,非题干的文字内容都略去,所以在空闲状态S0时候,检测结果A才能跳转到接受状态S1。

图4 试卷内容分类处理的有限状态机模型
当系统处于不同状态下时,依据对应的组卷策略,执行不同的动作:在提干状态按照模板写入试卷文件、在选项状态下按照格式写入选项、在答案状态下将答案按照预先设定的模板格式写入答案卷、在结束状态下,则保存关闭文件,过程图如图5 所示。
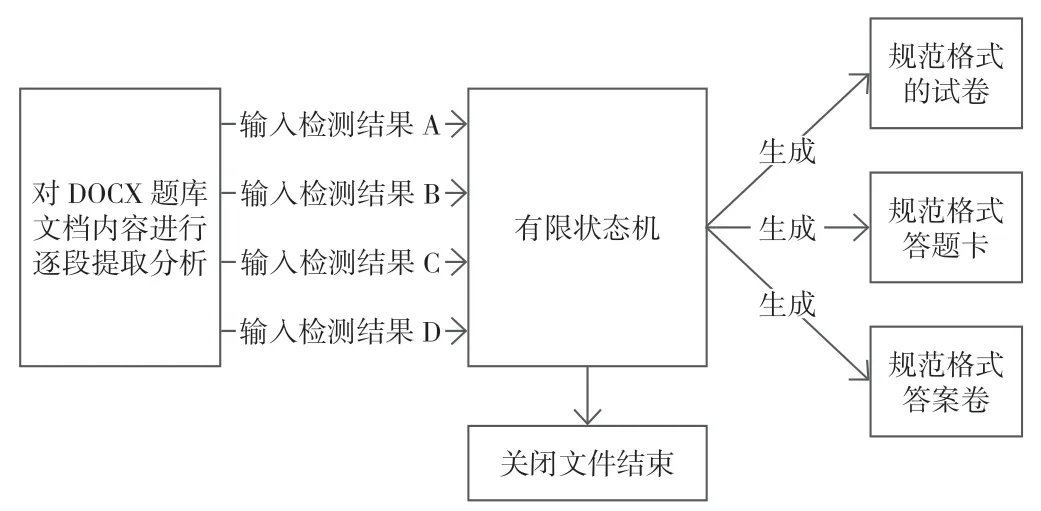
图5 基于有限状态机的系统设计
4 系统的总体设计
系统总架构图如图6 所示。系统的输入是符合Open XML 标准的DOCX 格式题库文件和EXCEL 的XLSX 格式的组卷方案文件。系统对输入的文件进行分析处理,之后按照组卷策略生成后缀名为DOCX 的试卷、答题卡和答案卷文件。系统共分为四大功能模块,分别是:试题库预处理模块、配置试卷模块、拼组试卷模块、导出试卷模块。系统功能模块设计图,如图7 所示。

图6 系统总体架构图
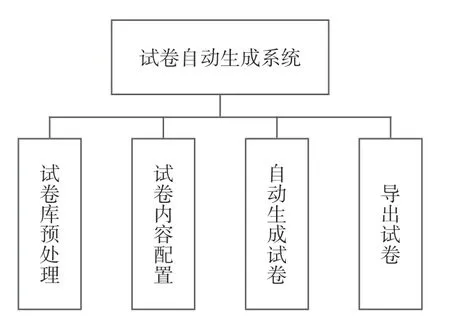
图7 系统功能模块图
5 系统的实现与测试评估
本系统的实现语言为Python,用Pyqt 库实现界面编程,通过python-docx 库,lxml 库的接口对Open XML 文档进行读取与生成。系统的主界面图如图8 所示。

图8 程序主界面
系统支持的试题题型有单选、多选、判断、填空、简答等,题型可以根据需求增加。系统需要对题库的WORD 题库文件名进行规范,规则如下:将单选题题库文件名定义为DX_[A-Z].docx,例如DX_A.docx、DX_B.docx;将多选题的题库文件文件名为MX_[A-Z].docx,例 如MX_A.docx、MX_B.docx;将填空题的题库文件定义为TK_[A-Z].docx,例如TK_A.docx、TK_B.docx。组题策略为excel 文件,例如A 卷的组题策略为A.xlsx,B.xlsx 等。组题策略文件包含题型种类、题型分值、题目编号等信息。
1)试题文件预处理。
首先需要对作为WORD 题库文档格式与内容进行预处理,预处理的内容包括:对WORD 文件格式做统一处理,一是清除有歧义的XML 元素,二是在内容上检查错误,例如删除不必要的空行、检查核对题库中的题号是否连续、题库中的题目是否都已配有参考答案、将题库中所有列表编码的格式改为文本格式等。在预处理的过程中提示预处理发现的错误,以便后续人工介入修改。如图9 所示。

图9 题库预处理提示信息界面
2)生成组卷策略文件
组卷策略文件是专家选题的结果,用XLSX 文件存储。A 卷的策略文件名为A.xlsx,B 卷的策略文件名为B.xlsx,以此类推。策略文件的样本如图10 所示。策略文件既可以机器自动生成,也可以手工填写,这样既可以实现机器抽题的随机性,又能实现试题的侧重点。
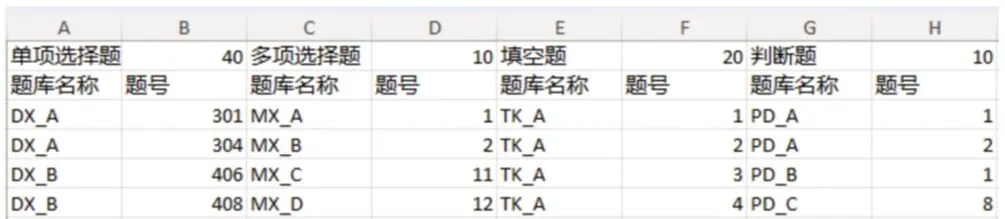
图10 组卷策略文件
3)配置卷面。
对试卷的考试科目、考试时间、试卷类别、试卷纸格式、题型、题号、题量、分值进行配置分配。如图11 所示。
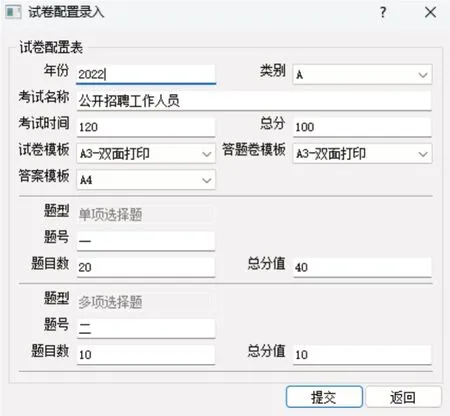
图11 配置试卷界面图
4)自动拼组试卷。
完成上述的步骤之后,进行拼组试卷并返回拼组试卷的信息。若存在拼组异常,则在反馈信息中用红色字体表示。如图12 所示。
5)试卷导出。
将系统生成的三套试卷,分别是试卷,答题卡和答案结果导出,格式为DOCX 格式,核对完交付打印。
系统测试共组织了单选题、多选、判断、填空、简答五种题型,测试题库数量统计如表3 所示。测试运行的硬件平台为CPU 为12th Gen Intel(R)Core(TM)i5-12400F、2.50 GHz、内存为16 G,软件平台为Windows 11、python3.8.10。主要测试试卷通过系统的耗时,结果如表4 所示。从测试结果可表明,通过系统自动产生的试卷规范,题目被正确地从题库中提取出来,答案卷中答案抽取正确,整个过程符合预期的目的,节省了大量的人工同时避免了人为的错误,对比如表5 所示。
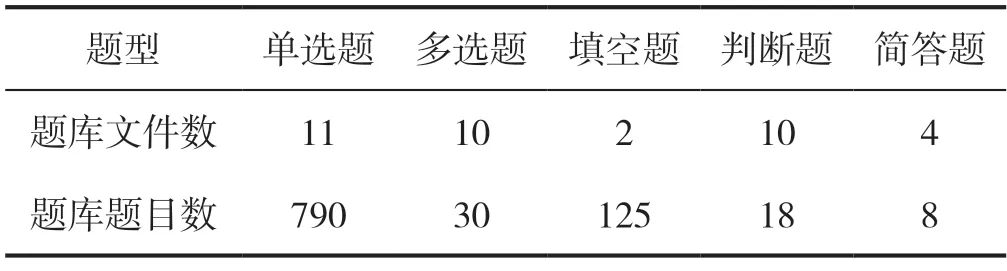
表3 测试题库数量统计

表4 试卷生成主要阶段耗时

表5 各种试卷生成方式的定性比较
6 结论
利用Open XML 文档的开源结构,直接对文档进行解析,再利用有限状态自动机原理自动生成试卷、答题卡和答案卷,不但实现组卷速度快,而且保障试卷的正确性,还节省了人工成本,同时省去了系统对数据库软件的依赖,有效地解决了笔试出题的保密性、时效性要求的问题。
