基于XGBoost的二轮车碾压事故致因研究
2023-10-09殷豪,林淼,王鹏,魏雯,朱彤*
殷 豪,林 淼,王 鹏,魏 雯,朱 彤*
(1.长安大学运输工程学院,陕西 西安 710064;2.中国汽车技术研究中心有限公司,天津 300300)
道路交通事故是造成人员死亡或严重伤害的重要原因。据世界卫生组织(WHO)发布的报告显示,全球每年有约130万人死于交通事故,2 000万至5 000万人受伤,各国每年因交通事故造成的经济损失约占其生产总值的3%[1]。在各类交通参与者中,二轮车骑乘人员承受着更高的死亡风险,其事故死亡人数占到了交通事故死亡人数的40%[2]。我国是二轮车使用率较高的国家,有庞大的使用人口基数。据中国自行车协会数据显示:2021年上半年,自行车规模以上企业产量为2 518.7万辆,同比增长19.7%;电动自行车规模以上企业产量为1 620.2万辆,同比增长33.6%[3]。尽管在工程和管理层面采取了很多预防措施,但二轮车交通事故造成的人员伤害仍然较为严重,因此需要进一步研究事故致因,以为精准防控提供导向。
二轮车被卷入机动车底部是一种非常危险的交通事故形式。Fredriksson等[4]在对两轮车致命事故的研究中发现,二轮车骑行者因撞到迎面而来的车辆前部或侧面或被其碾压而滑入车底,是二轮车致命事故中3个最为常见的事故场景之一,如果在机动车与二轮车运行速度不高时,能够避免二轮车骑行者卷入机动车底部,则可以大幅减轻骑行者的伤害乃至避免死亡;此外,Fredriksson等[5]还指出,如果汽车或重型车辆可以设计保护装置以防止碾过二轮车骑行者,将会解决4%的严重交通事故。
目前,对于二轮车交通事故的研究主要集中于事故场景划分、伤害严重程度等方面。如:Pan等[6]将碰撞事件、视线障碍、碰撞前机动车和二轮车的运动状态及相对运动状态、道路及二轮车类型作为聚类变量,得到机动车与二轮车碰撞事故中的典型危险场景;周华等[7]基于国家车辆事故深度调查体系(NAIS)数据库中乘用车与二轮车发生在十字路口的交通事故数据,通过统计分类、聚类分析和运动学模型叠加推演方法,得到了5类符合中国道路交通情况的乘用车与二轮车十字路口交通事故典型危险场景;Patrizia等[8]研究发现,高骑行暴露、男性骑行者、出行目的通勤是二轮车交通事故高风险因素;李英帅等[9]研究认为,影响二轮车交通事故严重程度的最主要因素依次为车辆间事故类型、骑行者受伤部位、道路物理隔离类型等;杨辉等[10]借助实车碰撞试验和LS-DYNA有限元仿真研究发现,货车后下部防护装置虽然结构简单,但对于轿车乘员可起到很好的保护作用。此外,大量汽车碰撞防护装置被以专利形式提出[11-13]。
综上可知,尽管汽车在车辆设计阶段对于防碾压有一定的考虑,也有车主在使用中采用了改装措施,但对于导致二轮车碾压事故的机理仍缺乏研究,使相关措施缺乏导向性、精准性与验证。从研究方法的角度,传统的统计模型假设自变量与因变量之间为线性关系,如果线性关系不成立,就很容易导致有偏差甚至是错误模型推断。此外,数据中未观察到的异质性和多重共线性也会影响模型估计。为了克服统计方法的缺点,越来越多的学者利用不同的机器学习模型来探索交通事故诱因与事故后果间潜在的非线性关系。而机器学习模型对于处理异常值、噪声或缺失数据具有更高的适应性,对于没有预先假设的输入变量处理更加灵活[14]。但以往的机器学习和安全性研究都集中在提高模型预测的准确性和模型比较方面,为了指导交通安全实践,模型可解释性方法成为量化各种风险因素的影响及其共同影响的有力手段。
据此,本文以中国交通事故深度调查(CIDAS)数据库中二轮车与机动车碰撞事故案例为基础,采用多种机器学习方法分析了二轮车碾压事故原因并予以验证,同时运用可解释性方法深入挖掘二轮车碾压事故致因与机理,以为二轮车碾压事故防控提供依据。
1 数据来源与处理
1.1 数据来源及特征分析
本研究基于2014年至2018年中国交通事故深度调查(CIDAS)数据库中数据,通过对数据进行清洗后,选取2 627起二轮车与四轮机动车碰撞事故案例为研究对象,其中二轮车被四轮机动车碾压事故为129起,占事故总数的4.9%,并对二轮车与四轮机动车相撞事故中二轮车骑行者受伤情况进行了统计,其统计结果如图1所示。

图1 二轮车与四轮机动车碰撞事故中二轮车骑行者受伤情况统计图Fig.1 Distribution of injuries to two-wheeler riders in collision accidents between two-wheelers and four-wheelers
由图1可知,在二轮车被四轮机动车碾压的事故中二轮车骑行者未受伤和轻伤事故的占比较小,而重伤和死亡事故的占比分别为19.4%和35.7%,比二轮车未被四轮机动车碾压事故分别高出2.8%和25.3%,这说明二轮车被四轮机动车碾压会使二轮车骑行者面临更高的重伤尤其是死亡风险。
此外,本文还统计了二轮车被四轮机动车碾压事故的22个相关因素数据,包括事故环境信息、四轮机动车信息和二轮车信息3类,其中连续型数值变量13个、分类型数值变量9个。
1.2 数据预处理技术
考虑到连续型数值变量可能会对后续自变量与因变量之间的非线性关系分析造成不便以及原始数据中二轮车是否被四轮机动车碾压这两类事故数据之间存在高度不平衡性,本文提出了数据分箱技术和数据平衡技术对原始数据做进一步处理。
1.2.1 数据分箱技术
数据分箱(Binning)技术本质上是将数据进行分组。对连续型数据的分箱又分为无监督分箱和有监督分箱两类:无监督分箱包括等频分箱和等距分箱;有监督分箱包括决策树分箱、best-ks分箱和卡方分箱等。
数据分箱一般遵循组内差异小、组间差异大、每组不小于5%的原则,且对于二分类问题而言,数据分箱后每组数据中都会有好、坏两类标签的数据。将数据进行分箱处理后,会使得数据特征包容异常值的能力增强,模型的稳定性和鲁棒性增强;数据特征所提供信息的精准度降低,模型的泛化能力得以提高,防止出现过拟合现象;模型的复杂性降低,训练速度加快。
本研究中采用的决策树分箱即利用决策树模型,使离散化的单变量与目标变量拟合,并将内部节点的阈值作为分箱的切点。通常采用证据权重(WOE)和信息量(IV)来评估对于某个数据特征分箱结果的好坏,具体计算公式如下:
(1)
(2)
式中:WOEx为第x组数据的证据权重;gx为第x组数据中标签为好的数据量,gT为数据集中标签为好的数据总量;同理,bx为第x组数据中标签为坏的数据量,bT为数据集中标签为坏的数据总量;X为分箱个数;IV为信息量,可以用来衡量变量的预测能力,当IV小于0.03时认为该特征没有对数据标签的预测能力。
1.2.2 数据平衡技术
针对数据标签不平衡的现象,提出了过采样和欠采样技术以产生一个平衡数据集来训练预测模型,而合成少数过采样技术(SMOTE)在以往的研究中被证明优于随机过采样和过采样方法[15]。在随机过采样技术中,少数类在训练数据集中被随机重复,而欠采样形式则会随机删除多数类。SMOTE利用随机欠采样和合成过采样,通过测量少数类中两点之间的距离,并随机生成它们之间新的数据点,合成了接近少数类数据的人工数据点。
1.3 数据处理结果
本文利用决策树分箱技术对13个连续型数值变量进行离散化,最终的特征变量包括无序分类型变量和离散数值型变量两类,具体变量信息如表1所示。

表1 二轮车碾压事故特征变量信息表
以碰撞时二轮车总质量为例,其分箱结果如图2所示。本研究中数据标签为二轮车是否被四轮机动车碾压,图2中横坐标为分箱后每组样本的数据范围,柱状图展现了每组样本中样本数及其占总体样本的比例,折线图展现了每组样本中二轮车被四轮机动车碾压样本所占比例。对碰撞时二轮车总质量这一因素进行分箱后得到的信息量IV值为0.186,对其他12个连续型数值变量进行分箱后得到的信息量IV值均大于0.03,表明本研究所涉及的13个连续型数值变量的分箱结果对二轮车被四轮机动车碾压事故都有较好的预测能力。
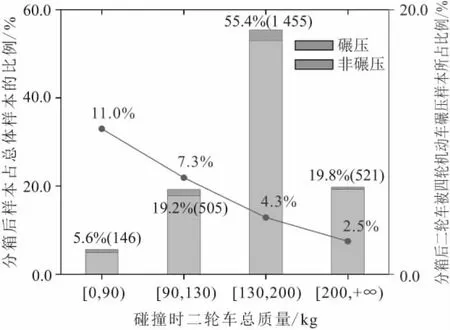
注:括号内数据为分箱后样本数(起)。图2 碰撞时二轮车总质量分箱结果图Fig.2 Binning diagram of two-wheelers’ total mass during collision
2 二轮车碾压事故预测的研究方法
2.1 XGBoost模型
本研究主要采用XGBoost(extreme gradient boosting)模型对二轮车卷入机动车车底事故预测进行建模。XGBoost模型是一种梯度增强决策树(gradient boosting decision tree,GBDT)的改进算法,于2016年被提出[16]。该算法的核心是优化目标函数的值,并在梯度增强的框架下实现机器学习算法。
XGBoost模型的目标函数由训练损失函数和正则化惩罚项两部分组成,即:
Obj(θ)=L(θ)+Ω(θ)
(3)
式中:L(θ)为训练损失函数,用于衡量模型对训练数据的性能;Ω(θ)为正则化惩罚项,旨在控制模型的复杂性。
每棵树的复杂度通过下式计算:
(4)
式中:T为叶子节点数;wj为叶子节点j的权重;λ为正则化惩罚项系数;γ为最小训练损失函数下降值。
经过对训练损失函数和正则化惩罚项的优化,得到最终XGBoost模型的目标函数如下:
(5)
式中:Gj、Hj分别为叶子节点j所包含样本的一阶偏导和二阶偏导之和。
2.2 SHAP可解释性方法
SHAP(shapley additive explanations)是一种博弈论方法,它的核心思想是计算特征对模型输出的边际贡献,再从全局和局部两个层面对“黑盒模型”进行解释[17]。该方法可以对不同的机器学习模型进行解释。在SHAP可解释性方法中,每个特征对模型输出的贡献是根据它们的边际贡献来分配的。SHAP值由下式表示:
(6)
式中:φi为特征i的SHAP值,即特征i的贡献;N表示需要解释的样本特征向量;|N|表示N的维数;S表示样本特征向量N中不包含特征i的特征组合向量;|S|表示S的维数;v(S∪{i})、v(S)分别为有、无特征i作用下的模型输出值。
3 模型建立
3.1 模型预测性能评估
为了评估模型的预测性能,本研究采用的模型评价指标包括准确率(Accuracy)、查准率(Precision)和查全率(Recall)等,具体含义及评估标准如表2所示。

表2 二分类问题评价指标及含义
将XGBoost模型的预测性能与其他6种流行的机器学习模型进行比较,为了确保公平,7种机器学习模型的训练及测试都基于相同的数据集,随机选取70%的数据进行模型训练,剩余30%的数据用来对模型的预测性能进行测试。针对70%的训练数据,采用SMOTE数据平衡技术处理生成占比均衡的正负样本,平衡分布的样本可使模型训练免受样本分布不均的影响。数据平衡处理中使用默认参数。数据平衡处理前后样本的分布特征对比如图3所示。在同一次分类任务中,高查准率要求提高二分类器预测正例门槛,使得二分类器预测的正例尽可能是真实正例;高查全率要求降低二分类器预测正例门槛,使得二分类器尽可能将真实的正例挑选出来。本研究中更希望模型有较高的查全率,即尽可能预测出所有二轮车被机动车碾压事故以降低损失,故以查全率、F1-Score为评价指标对7种机器学习模型的预测性能进行了比较,见图4。
图3 数据平衡处理前后样本分布特征对比图Fig.3 Comparison of sample distribution features before and after data balancing
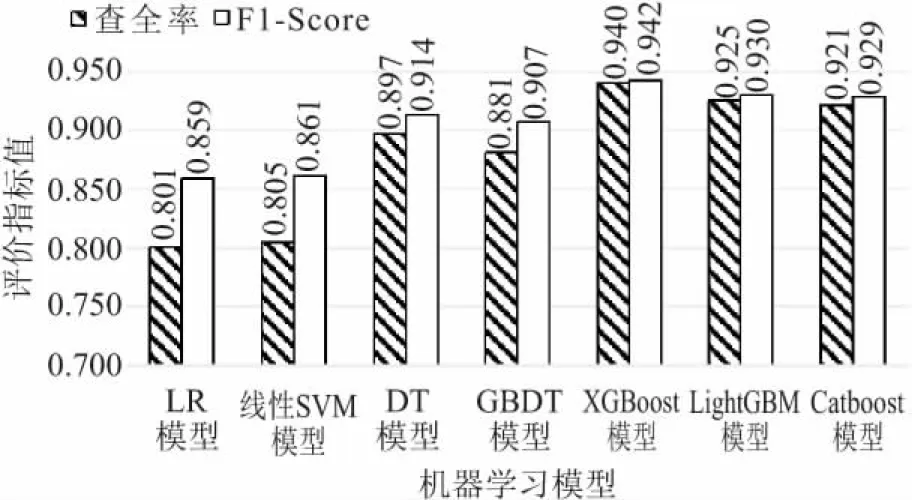
图4 机器学习模型预测性能对比图Fig.4 Comparison diagram of model prediction performance of machine learning models
由图4可知:7种机器学习模型中,XGBoost模型的查全率和F1-Score评价指标值最高,说明XGBoost模型的综合预测性能最优。
3.2 XGBoost模型建立
在XGBoost模型中,需要选择几个参数来使模型的预测性能最大化。参数调优可以防止模型过拟合和过于复杂,本文采用网格搜索法对XGBoost模型参数进行优化,其结果如表3所示。其他未提及的参数使用默认值。
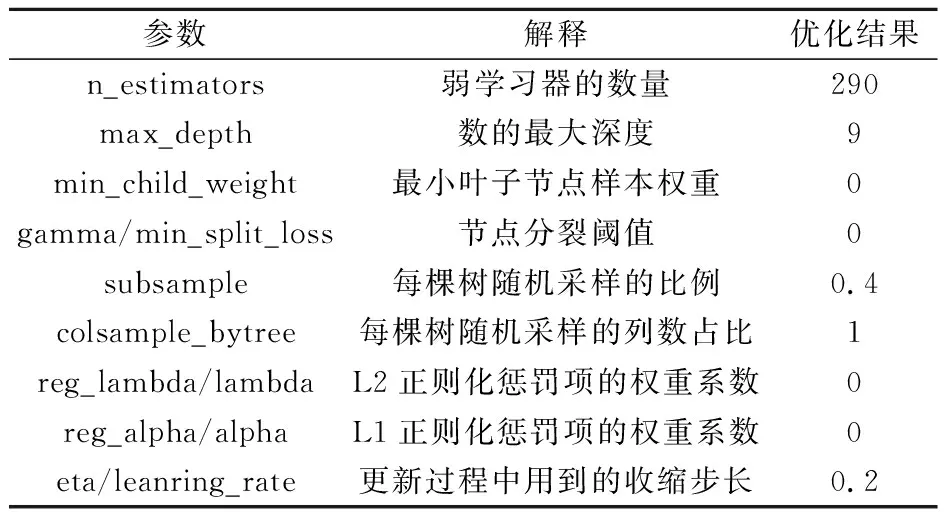
表3 XGBoost模型参数优化结果
在k折交叉验证中,数据集被分割成k个子集。k折交叉验证遵循以下步骤:使用(k-1)折作为训练数据来训练一个模型,所得到的模型在数据的剩余一折上进行验证(即剩余的一折数据被用作测试集来计算模型性能度量)。该方法与重复随机子采样相比具有明显优势,因为所有的样本都用于训练和验证,其中每个样本都有一次机会用于验证。图5显示了查准率(Precision)、查全率(Recall)和F1-Score这3种模型预测性能评价指标的10折交叉验证结果。
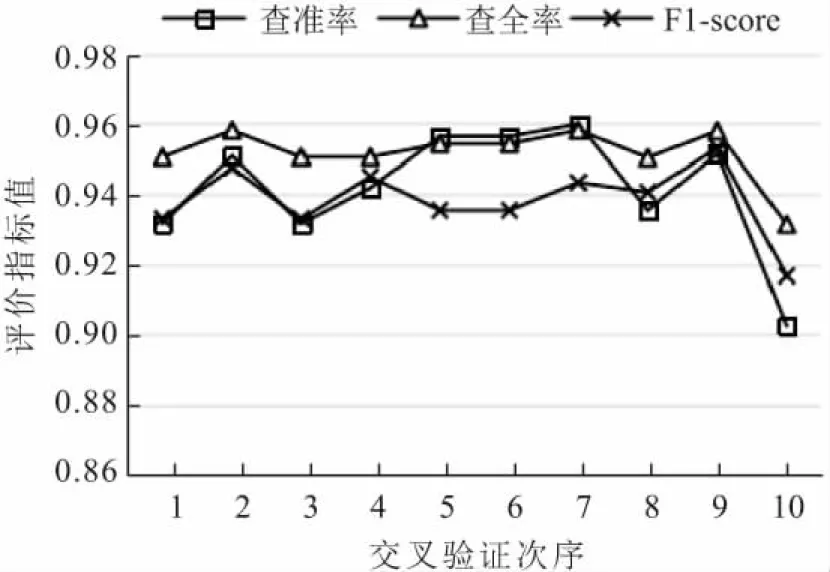
图5 模型10折交叉验证结果Fig.5 Model cross-validation results
由图5可以看出:用于10折交叉验证的10个数据子集的查准率在90%~96%之间变化,查全率普遍较高,均大于93%,且F1-Score值在91%~95%之间变化,总体上看,这些评价指标均较高且稳定,表明XGBoost模型可以用于二轮车被四轮机动车碾压事故的预测。通过将调参后的XGBoost模型在完整的70%的训练集上进行再训练,并在30%的测试集上进行测试,最终测得的模型预测性能评价指标如下:准确率为93.93%,查准率为94.62%,查全率为93.93%,F1-Score为94.78%,这再次表明XGBoost模型具有较好的预测性能。此外,XGBoost模型稳定的低误报率也在其他研究中得到了测试和验证[18]。
4 研究结果与讨论
4.1 事故影响因素重要度排序
以XGBoost分类模型适配SHAP模型解释器,根据二轮车碾压事故特征变量的SHAP平均绝对值排序并进行可视化,得到反映事故各特征变量对事故预测结果贡献程度的SHAP平均影响排序图,如图6(a)所示。
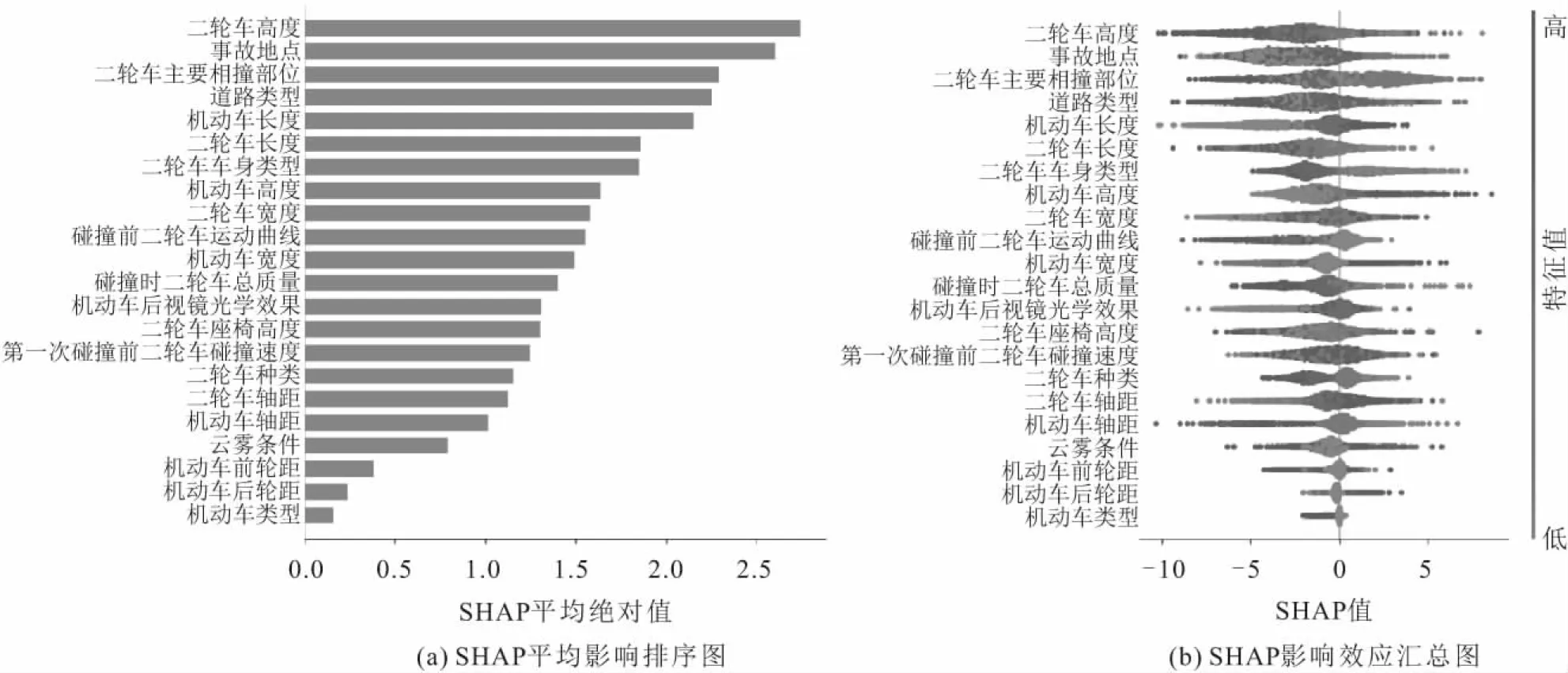
图6 基于XGBoost模型的二轮车碾压事故特征变量SHAP值Fig.6 SHAP values of characteristic variables of two-wheeler run-over accidents based on XGBoost model
由图6(a)可以看出:二轮车高度、事故地点、二轮车主要相撞部位等特征变量是影响二轮车被四轮机动车碾压的重要因素。图6(b)的SHAP影响效应汇总图定性描述了二轮车碾压事故与事故特征变量之间的总体关系。在图6(b)中,每个点代表一个样本,样本点多少可以反映出每个特征变量各取值的占比,好的特征变量应该将样本明显分散开来;不同颜色代表当前特征变量取值高低;横坐标为SHAP值,其大小代表特征变量对结果的影响程度,SHAP值为正代表该特征变量对二轮车碾压事故的发生有促进作用,SHAP值为负代表该特征变量对二轮车碾压事故的发生有抑制作用。此外,由于车辆轴距与车长密切相关,而前、后轮距则与车宽密切相关,故由图6(b)可知,机动车及二轮车的轴距和轮距相关特征变量在SHAP值排序中相对靠后,所以在后续分析中将不再涉及轴距和轮距相关特征。
4.2 事故环境影响因素分析
为了量化单个特征变量是如何影响XGBoost模型输出的,本文绘制了部分依赖图来显示单个特征变量的边际效应,图7为二轮车碾压事故有关环境特征变量的SHAP依赖图。
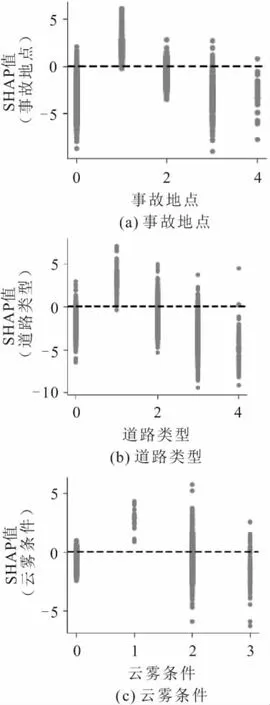
图7 二轮车碾压事故有关环境特征变量的SHAP依赖图Fig.7 SHAP dependence plots of the environment characteristic variables of two-wheeler run-over accidents
由图7(a)可知,当二轮车碾压事故地点在工业区时SHAP值几乎均为正,事故地点在郊区时SHAP正值区域聚集程度也接近一半,这意味着工业区、郊区事故地点对二轮车被碾压事故有显著的促进作用。这是因为相比城市和村庄,道路参与方尤其是机动车在工业区和郊区会保持较高车速,且一般情况下城市和村庄大型货车的进入也有严格限制,这些因素都加大了工业区、郊区等地点发生二轮车碾压事故的风险。
由图7(b)可知,在弯道发生二轮车碾压事故的风险最高,交叉路口次之。这是因为弯道或交叉路口的交通情况较为复杂,且驾驶人视线被遮挡的可能更大,更易发生事故;十字路口事故风险相对较低则可能是因为这些路段有更为严格的交通管控。
由图7(c)可知,在多云、有雾条件下二轮车碾压事故发生的概率较大,尤其是雾天,道路能见度显著降低,是造成二轮车碾压事故的重要因素。
4.3 事故二轮车影响因素分析
图8为二轮车碾压事故有关二轮车特征变量的SHAP依赖图,本次主要选取在SHAP影响效应图中表现较好的二轮车特征变量进行分析。

图8 二轮车碾压事故有关二轮车特征变量的SHAP依赖图Fig.8 SHAP dependence plots of the two-wheeler charac- teristic variables of two-wheeler run-over accidents
与碰撞场景有关的因素有二轮车主要相撞部位和第一次碰撞前二轮车碰撞速度。图8(a)显示正面碰撞的SHAP值为负,其正值出现在其他方向的碰撞中,这意味着发生在二轮车侧面和尾部的碰撞更容易使其被卷入四轮机动车车底,这是由于侧面和尾部碰撞时,机动车驾驶人缺乏对事故的预先感知,未能及时做出适当的避险操作,增加了二轮车碾压事故的风险。以与乘用车前部相撞为例,二轮车相撞部位示意图如图9所示。图8(b)显示的第一次碰撞前二轮车碰撞速度表明,二轮车车速越快越不容易被四轮机动车碾压,说明在快速运动状态下的碰撞很可能会造成对二轮车骑行者的抛出而非碾压。

图9 二轮车相撞部位示意图Fig.9 Schematic figure of collision site of a two-wheeler
与二轮车本身参数有关的特征包括车辆尺寸参数、车辆质量及种类等。图8(c)显示二轮车种类为自行车和电动两轮车时SHAP值几乎为正,而大多数摩托车样本的SHAP值小于0,这是因为自行车和电动两轮车车身较小,在碾压事故中更容易被卷入机动车车底。关于二轮车车身类型的解释如图8(d)所示,骑跨式和弯梁式车辆相比踏板式车辆更容易被碾压,原因可能是骑行者更容易操控踏板式车辆,用脚支撑或者下车都更为方便,降低了发生碾压事故的风险。以摩托车为例,各种车身类型如图10所示。此外,二轮车座位高度与二轮车高度紧密相关,对二轮车的长、宽、高等参数进行分析后可知,二轮车车辆越小越容易被大车碾压,在此不再赘述。

图10 摩托车车身类型图例Fig.10 Sample figures of motorcycle body type
4.4 事故四轮机动车影响因素分析
图11为二轮车碾压事故有关四轮机动车特征变量的SHAP依赖图,本次主要选取SHAP值排名前两位的四轮机动车特征变量进行分析。

图11 二轮车碾压事故有关四轮机动车特征变量的 SHAP依赖图Fig.11 SHAP dependence plots of the four-wheel vehicle characteristic variables of two-wheeler run-over accidents
图11(a)显示四轮机动车越高越容易将二轮车卷入车底,这是由于四轮机动车车辆越高,驾驶室的位置越高,会造成司机更大的视觉盲区。另外,随着四轮机动车车辆长度增加、转弯半径增大,二轮车驶入大车转弯内侧半径由内轮差造成的视觉盲区是二轮车碾压事故的高发因素,图11(b)显示四轮机动车长度的SHAP依赖图验证了这一观点,即四轮机动车长度的增加带来其轴距的增加,使二轮车更易被卷入四轮机动车车底。
5 结论与建议
1) 基于CIDAS数据集,提取22个二轮车被碾压事故相关影响因素,利用XGBoost方法建立二轮车碾压事故预测模型,并采用SHAP可解释性方法分析二轮车碾压事故与各影响因素之间的非线性关系。
2) 通过对二轮车与四轮机动车相撞事故中二轮车骑行者受伤情况进行统计发现,二轮车被四轮机动车碾压的事故比未被碾压事故的致死率高出25.3%,这说明二轮车被四轮机动车碾压会使二轮车骑行者面临更高的死亡风险。XGBoost模型在7种机器学习模型中分类性能最优,模型参数优化后准确率为93.93%,查准率为94.62%,查全率为93.93%,F1-Score为94.78%,该模型具有较好的预测性能。
3) 模型能够准确解析二轮车碾压事故的风险因素,说明二轮车碾压事故与非碾压事故之间存在明显的区别。但二轮车车速的增加反而导致碾压事故风险的降低,这与非碾压事故中的规律明显不同,因此在研究中应将二轮车碾压事故予以区别和单独分析。
4) 在与二轮车碾压事故相关的环境因素中,工业区、郊区以及弯道、交叉口发生二轮车碾压事故的风险较大,雾天加大了二轮车碾压事故的风险;与碰撞场景相关的因素中,二轮车侧面或尾部碰撞以及二轮车较低的车速均会在一定程度上增加二轮车碾压事故发生的可能性;关于二轮车车辆类型,摩托车以及踏板式二轮车更不易被四轮机动车碾压;此外,二轮车车身越小,四轮机动车更高、更长时,更容易发生二轮车碾压事故。
5) 二轮车骑行者在骑行过程中应格外注意侧面及后方交通状况,尤其是在弯道、交叉口等交通情况复杂路段以及雨天、雾天等恶劣天气条件下更应谨慎出行;同时,二轮车骑行者在骑行过程中应尽量远离大型车辆,尤其是在郊区、工业区等大型车辆更易出现的路域,以避免被碾压而造成严重的伤害;此外,非常有必要采用机动车与二轮车隔离的交通设施,且在运行速度较低的情况下也不例外,并应对广大居民加强交通安全宣传与教育。
