基于Transformer-LSTM模型的跨站脚本检测方法
2023-10-09赵斯祺
赵斯祺 代 红 王 伟
(辽宁科技大学计算机与软件工程学院 辽宁 鞍山 114051)
0 引 言
跨站脚本攻击(Cross Site Scripting),简称XSS攻击,是一种基于代码注入的Web安全威胁,攻击者可以通过攻击网站或Web应用程序来访问敏感信息。当使用不安全的输入或恶意的XSS链接将恶意的JavaScript代码注入到Web应用程序中时,就可能发生这类攻击[1]。这些类型的攻击可以在任何没有输入验证且对用户输入的安全性实现很差的站点上执行[2]。XSS攻击可以分为三类:反射型XSS攻击、存储型XSS攻击和基于DOM的XSS攻击[3]。传统的XSS攻击检测方法主要是基于已有特征,进行特征匹配来检测[4]。这种方法对已知攻击有较好的检测效果,但难以检测未知攻击,对于恶意变形的XSS攻击检测效果不好。随后研究者提出了机器学习的方法。吴少华等[5]将SVM算法用于XSS攻击检测。赵澄等[6]建立了一种改进后的SVM分类器识别XSS攻击,提取出典型的五维特征进行特征优化。Wang等[7]提出了一种基于分类器与改进的n-gram模型相结合的OSN中XSS检测方法。三者提出的检测方案都是基于传统的机器学习算法,对未知的XSS攻击有较好的检测效果,但对恶意变形的XSS攻击检测效果并不显著,而且研究者们所用的机器学习方法需要人工提取XSS攻击的特征,人工提取特征主观性强,容易造成特征提取不充分,影响分类结果。随着研究深入,研究者开始将深度神经网络运用到XSS攻击检测,深度学习算法可以自动学习特征,减少人工提取特征的不足。Li等[8]首次将深度学习应用到漏洞检测领域,实验结果表明,上述方法的预测精度要优于传统神经网络和机器学习算法。Fang等[9]使用长短时记忆网络(LSTM)构建分类模型,实验结果表明LSTM模型对XSS攻击检测效果较好。两者对于深度学习的应用解决了人工提取存在的不足,但对恶意变形的XSS攻击检测还要进一步提高准确性。
通过研究,为减少人工提取存在的问题,提高恶意变形的XSS攻击检测效果,本文提出一种基于Transformer-LSTM模型的跨站脚本检测方法。通过前期数据预处理,使用解码技术解决XSS攻击恶意变形问题,并利用Transformer-LSTM模型自动学习XSS攻击特征,减少人工提取特征存在的不足。实验结果表明,本文方法较传统机器学习方法和普通的深度学习方法具有更高的准确率、更好的召回率。
1 神经网络
1.1 Transformer模型
Transformer模型是一种基于自我关注机制的新颖神经网络体系结构[10]。整个结构是由编码组件、解码组件和它们之间的连接层组成。编码组件是六层编码器首尾相连堆砌而成,解码组件也是六层解码器堆砌而成,模型结构如图1所示。左边为编码器(N=6),编码器结构完全相同,但并不共享参数,每一个编码器有两个子层,为多头注意力子层和全连接的前馈神经网络层。右边为解码器(N=6),解码器同样有这两个子层,但不同的是,在这两个子层间增加了一个Masked多头注意力层[11]。为使整个模型结构达到更好的深度网络效果,在两个子层中使用一个残差连接,并进行层标准化。
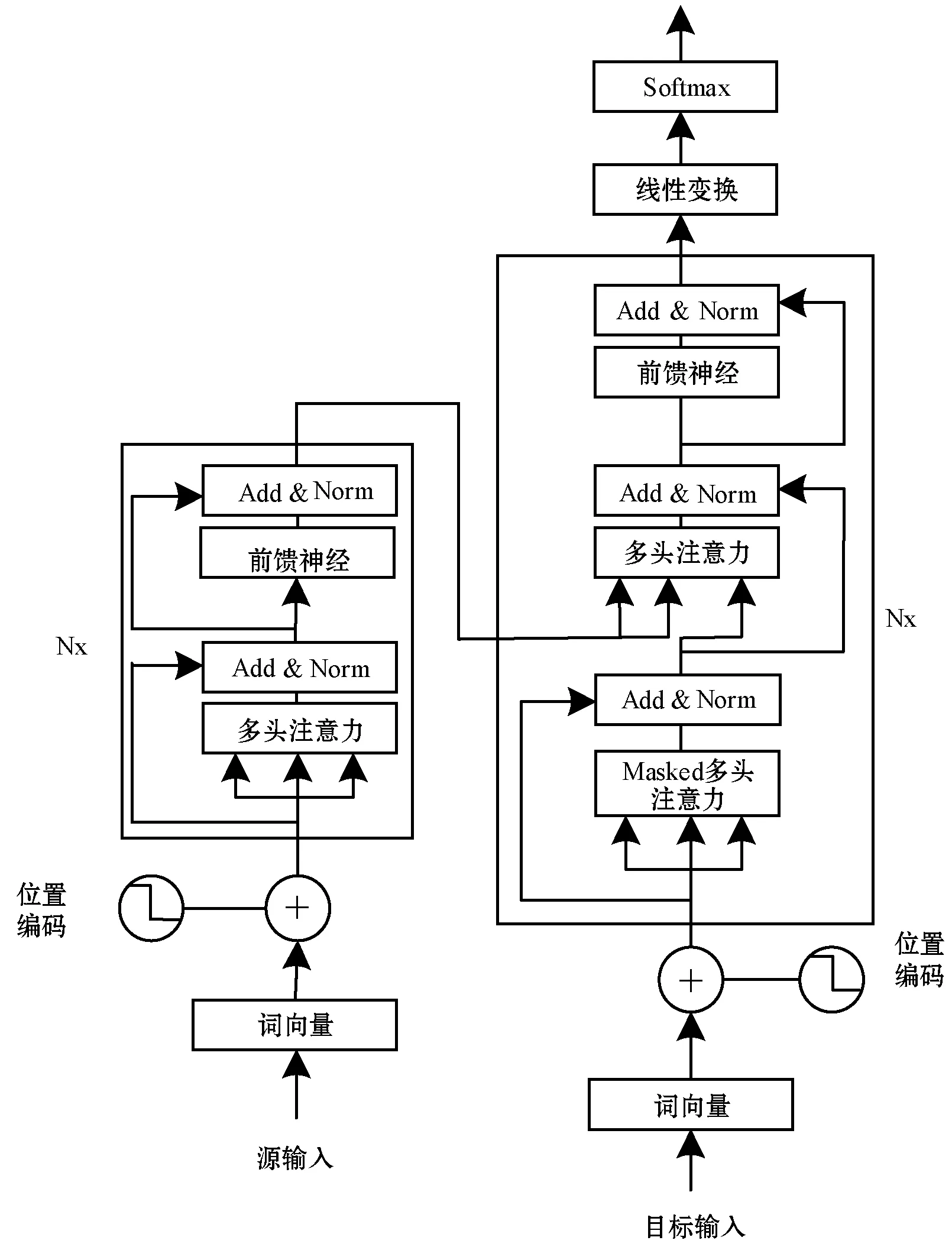
图1 Transformer模型框架
Transformer模型抛弃循环神经网络结构,完全采用Attention取而代之,词序之间的信息就会丢失,模型就无法得知每个词在句子中的相对位置和绝对位置信息。因此,有必要把词序信号加到词向量上帮助模型学习这些信息,位置编码(Positional Encoding)需要将词序信息和词向量结合起来形成一种新的表示输入给模型,这样模型就具备学习词序信息的能力。具体计算式表示为:
PE(pos,2i)=sin(pos/1 0002i/dmodel)
(1)
PE(pos,2i+1)=cos(pos/1 0002i/dmodel)
(2)
式中:PE为二维矩阵,行表示词语,列表示词向量,pos表示单词的位置索引,i表示词向量的某一维度;dmodel是词向量的维度。式(1)、式(2)表示在每个词语的词向量的偶数位置添加sin变量,奇数位置添加cos变量,以此填满PE矩阵,然后添加到嵌入层中,这样的编码方式可以得到词语之间的相对位置和绝对位置。
注意力机制描述为一个查询(query)到一组键值对(key-value)的映射,计算公式表示为:
Attention(Q,K,V)=softmax(QKT)V
(3)
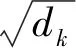
放缩点积注意力计算式表示为:
(4)
研究人员引入了多头注意力,这使得模型能够关注来自不同位置的不同表示子空间的信息,能够充分提取内部关系。多头注意力就是把多个自注意力连起来,同时,通过减低维度来减少总计算消耗,计算公式表示为:
MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO
(5)
(6)

FFN(x)=max(0,xW1+b1)W2+b2
(7)
式中:x代表输入;W1、W2表示第一次和第二次线性变换的参数矩阵;b1、b2表示第一次和第二次线性变换的偏置向量。
1.2 LSTM模型
长短时记忆模型(Long-Short Term Memory,LSTM)是一种特殊的RNN模型,是为了解决RNN模型梯度弥散问题而提出[12-13]。LSTM网络结构如图2所示。
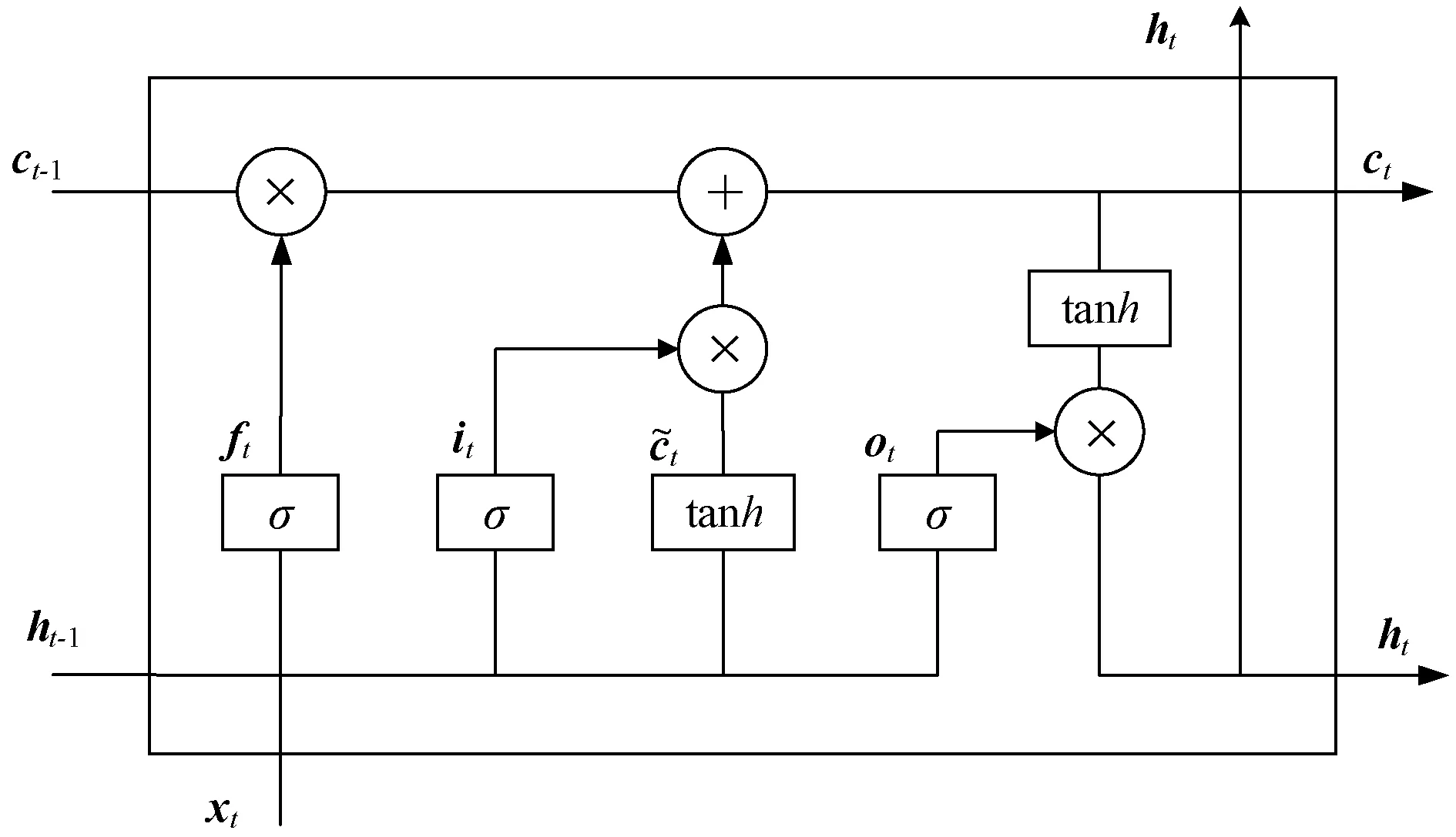
图2 LSTM网络结构
LSTM由遗忘门(forget gate)、输入门(input gate)和输出门(output gate)、单元状态(cell state)来更新和保留历史信息[14]。其中,遗忘门决定丢弃上一个单元状态ct-1传递到当前单元状态ct的部分信息[15];输入门决定了保留当前时刻网络的输入xt传递到单元状态ct部分信息;输出门决定当前输出值ht。
遗忘门的计算为:
ft=σ1(Wf·[ht-1,xt]+bf)
(8)
式中:Wf为遗忘门的权重矩阵;ht-1为上一个单元状态的输出;xt为当前细胞的输入;bf为遗忘门的偏置项;σ为sigmoid函数。
输入门的计算为:
it=σ2(Wi·[ht-1,xt]+bi)
(9)
式中:Wi是输入门的权重矩阵;bi是输入门的偏置项。
(10)
(11)
式(11)用于将旧的单元状态ct-1更新为新的单元状态ct。
输出门的计算为:
ot=σ3(Wo·[ht-1,xt]+bo)
(12)
ht=ot×tanh(ct)
(13)
最终的输出由输出门和单元状态共同决定。
2 Transformer-LSTM模型
2.1 数据预处理
实验数据分为正样本数据和负样本数据,正样本数据是利用爬虫工具从XSSed网站爬取,负样本数据是从各网络平台通过网络爬虫获得。本文对所收集的正样本数据和负样本数据进行了预处理,分为数据清洗、分词、向量化,如图3所示。
(1) 数据清洗:完整的URL请求包括协议、域名、端口、虚拟目录、文件名和参数。为了保证数据安全,只保留虚拟目录、文件名和参数。XSS攻击为了逃避检测利用编码技术恶意变形,主要有HTML编码和URL编码,因此,在分词之前需要通过解码技术进行相应的解码,提高数据质量。
(2) 分词:数据清洗之后,为了减少分词数量,需要把数字和超链接范化。将数字替换为“0”,超链接替换为“http://u”。考虑到参数内包含完整可执行的标签和事件,将同一类型标签和事件收集起来,通过正则表达式进行匹配。因此,设计了符合要求的分词规则为:单双引号里的内容,带有http/https的链接,脚本标签,标签开头,属性名,函数体。如表1所示。

表1 分词规则
(3) 向量化:XSS攻击通常执行的是HTML/JavaScript脚本,具有一些语义的关联。可以使用嵌入式词向量模型,建立一个XSS的语义模型,使机器能够理解