基于最大熵与相关性分析的非负矩阵分解
2023-10-09冯本勇徐勇军
冯本勇 徐勇军
1(石家庄工商职业学院 河北 石家庄 050000)
2(中国科学院计算技术研究所 北京 100190)
0 引 言
矩阵分解(MF)模型是多元分析中降维和特征学习的有效方法,高维数据样本被格式化为矩阵,然后分解成低维矩阵的乘积[1]。非负矩阵分解(NMF)是最流行的矩阵分解模型之一,它允许将一个非负输入矩阵分解成两个低阶非负矩阵,通过原始特征的分布因子分解,样本由学习的潜在因子的相加组合重构,该方法由于其泛化能力较强得到了广泛的应用[2-3]。
为了学习高质量的潜在因子,学者在许多类MF模型中研究了潜在因子的性质。主流研究学派建议减少共适应,以便有效地捕捉数据中罕见的隐藏模式。黄卫春等[4]提出了一种正交约束非负矩阵三因子分解(NMTF),使潜在因子的多样性最大化,从而得到严格的聚类解释。Chen提出在奇异值分解(SVD)中为学习的潜在因子分配权重,而不是矩阵项。余江兰等[5]提出了非负多矩阵分解(NMMF),它将用户项矩阵与两个辅助矩阵一起分解,以合并边界信息。徐霜等[6]提出了一种改进NMF(ENMF)来进一步从一系列矩阵中提取知识。然而,上述方法受到硬几何约束的巨大计算量的限制,并且这些经典的方法主要集中在如何整合更多的辅助信息和领域知识上,而对学习的潜在因子的特性关注较少[7]。
为此,本文提出一种多分量NMF同时学习多组潜在因子,并使用Hilbert-Schmidt独立性准则来发现多样性信息,从而可以对数据的多方面进行探索。刘国庆等[8]利用大锥罚函数寻找具有大互角的潜在因子,可以很好地推广到其他不可知的数据中。另外,为了有效地分解高度混合的数据,李向利等[9]提出了一种最小体积约束的NMF(MVCNMF)来学习彼此相对相似的潜在因子,MVCNMF模型也成功地应用于高相关度的人脸图像处理。但是上述方法未能解决各因素的相关性进行建模,并且缺乏对词或像素等原始输入特征应如何分布的因子内分析。
为解决上述问题,提出一种基于最大熵与相关性分析的非负矩阵分解方法(MECNMF),利用最大熵原理描述非负矩阵分解中的潜在因子分布,以捕捉语义质量的潜在因子特性,并提出一种基于相似性的方法来度量差异性。另外,将自适应加权策略引入因子间的相互关系,使得每个潜在因子能够无监督地获得自适应权重。在多个数据集上的实验结果表明,本文方法具有良好的性能。
1 研究方法
1.1 非负矩阵分解
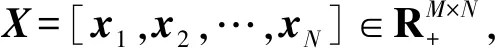
X=UV
(1)

(2)
NMF的损失函数测量X和UV之间的重构误差。平方欧几里得距离和广义Kullback-Leibler散度是最常用的距离度量[4]。平方欧几里得距离损失函数为:
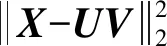
(3)
1.2 最大熵理论
1.2.1分布状态分析
NMF框架中的关键问题是找出哪些潜在因子对数据的语义重构贡献更大,从而更好地拟合输入矩阵X。如图1所示,从式(2)的数据重构角度来看,NMF可以类比为一种深度神经网络(DNN)模型的作用。
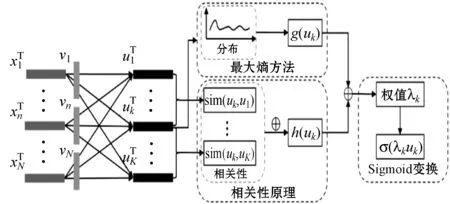
图1 NMF框架
在图1的左半部分,输入样本xns被转换成K个潜在因子的组合uks,其中表示向量vns作为网络权重。与DNN的区别有三个方面:首先,将所有样本数据同时送入NMF,而DNN是将样本数据分批送入;其次,uks是无监督自动学习的,不需要任何指导性标签数据;最后,NMF无非线性激活函数。
在这种无监督学习环境下,本文提出两种基于对潜在因子的直观分析的自适应加权策略,如图1的右侧所示。首先,一个潜在因子应该对更多原始特征中的语义进行编码。如果uk的分布主要集中在一些原始特征上,那么它很可能产生过拟合现象,并且设置的权重应该更小。为此,本文提出一种最大熵测量方法g(uk)来定量分析潜在因子的分布状态。其次,如果uk与其他潜在因子区别较大,那么uk很可能会受噪声和离群值的影响,从而在语义重构过程中无法与其他潜在因子进行良好的协作。因此,提出一种互相关测量方法h(uk)来定量分析潜在因子分布之间的关系。然后,将两个测量值整合,分配给各个潜在因子的自适应权重中。最后,进行Sigmoid变换,进一步增强了处理非线性数据的能力。
为了改善数据表示,每一个潜在因子首先需要传达完整的语义。在NMF中,一个潜在因子uk表示为原始输入特征的分布,每个条目umk表示第m个原始特征对uk的重要性。根据以上分析,需要定量地测量uk的分布状态。
信息熵是对事件状态的不可预测性的度量[8]。在此,潜在因子uk相当于一个“事件”,原始特征表示可能存在的状态,uk关于它们的归一化分布表示可能性,其表示为:
(4)
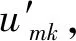
(5)
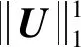
1.2.2相关性分析
从上述分析来看,既要考虑到要素的分布特征,又要考虑它们之间的相关性。如果uk在M维特征空间中分布较稀疏,就会形成一个相对松散的语义空间,其中可能混杂噪声。相反,紧凑的语义空间着重于大多数数据点,因此应适当促进潜在因子之间的相关性,这种自适应协作可以揭示不同潜在主题之间的协方差结构[7]。
针对潜在因子提出各种相关措施[8],采用了广泛使用的分布向量间的余弦相似性,但用其他相似性度量标准也是可行的。即uk与其他语言的整体语义相关性被定义为余弦相似度的总和,其计算式为:
(6)
式中:绝对值|umk|表示uk对第m个原始特征的权重,整体语义相关性的范围为[0,K]。若h(uk)的值较高,表明uk与其他潜在因子相关性较好。随着重构误差减小,增加h(uk)将促进潜在因子之间的相互协作,并加强学习语义空间的紧凑性。
1.2.3加权转换
根据上述对潜在因子的分析,除了最小化分解损失之外,还有两个项可以如式(5)和式(6)中那样进行最大化。一种方法是将它们规范化,然后附加到损失函数中,但也存在较明显的缺陷。首先,为了将损耗最小化问题与两个目标最大化相结合,需要通过一些减法操作和两个超参数来平衡它们。但是,参数调整过程非常困难,因为这三个项的取值范围彼此相差较大。另外,最大熵和互相关约束不会直接施加在单个潜在因子上,而是间接地作为除了重构误差之外的损失。因此,本文提出一种自适应加权策略,将两种测量结果以紧密耦合的方式集成到重构损耗中。
对目标矩阵X的行、列甚至向量分配特定权重的常规加权策略,MECNMF通过对语义重构的贡献来权衡单个uk。对于每个潜在因子uk,为其分配一个非负权重变量λk。随着λk的变大,uk在表示学习中的作用越来越重要。λk=0说明uk因其较差的表达能力而被完全删除。
根据分布状态分析,如果uk具有较高的g(uk)值,则其分布更可靠并且可以更好地编码语义信息,即权重λk与测量值g(uk)之间存在正相关。因此,与g(uk)相对应的权重部分的计算式为:
(7)
式中:f(·)是双曲正切函数f(z)=tanh(z),有平滑数据的作用,然后除以最大值f(log2M),此时取值范围扩大到[0,1]。
如果uk具有较高的h(uk)值,则它可以更好地与其他部分协作并增强语义空间的紧凑性。所以λk和h(uk)之间存在的相关性程度较高。与h(uk)相对应的权重部分的计算式为:
(8)
除以最大值f(K)后,其取值范围可以扩大到[0,1]。使用可调超参数α,可将这两个权重值可以整合到一起,并且可以计算出λk:
(9)
式中:0≤α≤1。利用上述权重变量λk,可以用其加权形式λkuk来改进uk。此外,除了自适应权值λk所传递的最大熵和互相关度量外,还需要提高uk处理非线性数据的能力。作为深度神经网络的基本组成部分,渐近激活函数已经具备能够使神经网络逼近任何函数的能力。因此,用激活函数进一步加强uk:
(10)
式中:σ(·)是Sigmoid函数。因此,式(2)中输入样本向量xn的线性重构可以转化为:
(11)
一个新的损失函数可表示为:
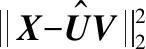
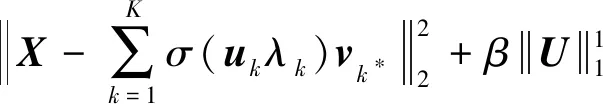
(12)

注意,MECNMF不同于传统的加权NMF,因为分配给潜在因子的权重是通过两个建议的测量值进行自适应学习,而不需要先验知识。式(12)中的最终损失函数与NMTF中的类似,因为输入矩阵X被分解为三个矩阵。然而,矩阵Λ中的元素不再是自由参数,而是以非线性的方式从矩阵U进行自适应学习。
1.3 算法优化
1.3.1对V进行优化
(13)
通过采用与文献[5]相同的办法,可以采用乘法运算得到V:
(14)
1.3.2对U进行优化
由于包含非线性分析函数g(·)和h(·),L对U求导比较复杂。因此,本设计采用经典梯度法对U进行优化,当L对U求偏导数时,首先求解对角权矩阵Λ对U的梯度,因为这是其中最复杂的部分。λk对uij求偏导数公式如下:
(15)
f(g(uk))对uij求偏导数公式如下:
(16)
(17)
(18)
式中:sign(·)是符号函数。f(h(uk))对uij求偏导数公式如下:
(19)
(20)
(21)
给定上述对角线权重矩阵的导数,可以很容易求出L对uij的偏导数:
4(σ(UΛ)VVT⊗σ′(UΛ)ΛT)ij+βsign(uij)
(22)
式中:σ′(·)是σ(·)函数的导数;⊗表示逐点矩阵乘法。在给定步长η的情况下,可以通过向其梯度相反的方向移动来更新U:
(23)
根据以上分析,本文提出一种如算法1中描述的迭代优化算法。在每一次迭代中,使用式(14)中的乘法更新规则来更新矩阵V,如第4行所示。还有一个内部迭代,用式(23)更新矩阵U,如第6-12行所示。外迭代和内迭代的最大次数分别为T和S。在实际应用中,选择合适的步长η有些困难,因为当η值不适合时,优化过程要么存在收敛慢的问题,要么出现来回振动问题。通过文献[8]中的自适应调整规则,引用文中的衰减策略:
η(t)=η(0)×γt
(24)
式中:γ是衰减率。当输出矩阵收敛或达到最大迭代次数时,将结束迭代。
算法1MECNMF优化算法
输入:数据矩阵X,潜在因子数K,超参数α、β。
输出:基本矩阵U,表示矩阵V。
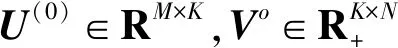
2.fort=1→Tdo
3.(1) 根据式(14)更新V:
5.(2) 根据式(23)更新U:
6.fors=1→Sdo
8.if 收敛 then
9. break
10. end if
11. end for
12.U(t)←U(t,s)
13.if 收敛 then
14. break
15. end if
16. end for
17.U←U(t),V←V(t)
1.3.3收敛性分析
为了达到优化目的,提出了算法1,它是传统的NMF乘法更新算法和梯度下降算法的结合,证明这种新算法的收敛性很重要。令L(t)表示为第t次迭代后的损失,改进的优化过程在运行时会产生一系列损失:
L(0),L(1),…,L(t-1),L(t),L(t+1),…,L(T)
(25)
式中:L(0)是初始损失。如果可以证明上述序列是单调递减的,由于损失函数值总是非负的,那么经过足够的迭代次数,优化过程无疑会收敛到某一点,最终结果至少是一个局部最优解。
在算法1中,每个迭代步骤都包含两个子步骤,分别是V和U的优化。因此,每一步损失L(t)可以进一步分为两个子损失:
…,L(t-1,v),L(t-1,u),L(t,v),L(t,u),L(t+1,v),L(t+1,u),…
(26)
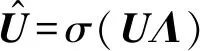
1.4 复杂性分析
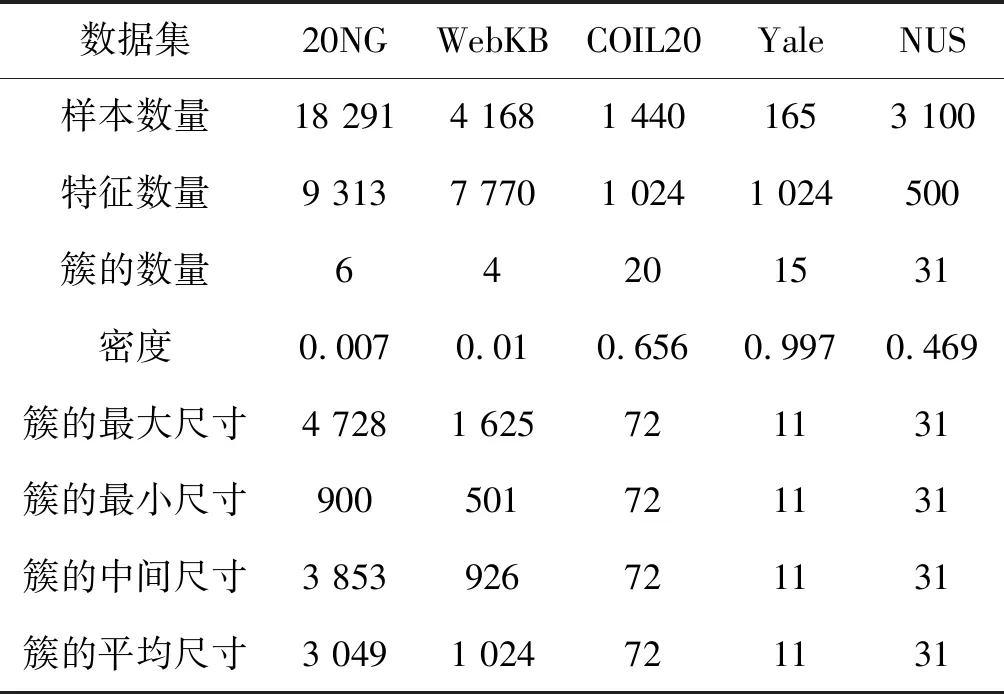
T代表外部最大迭代次数,S代表内部最大迭代次数,M、N、K分别代表输入样本数量、原始特征、潜在因子。
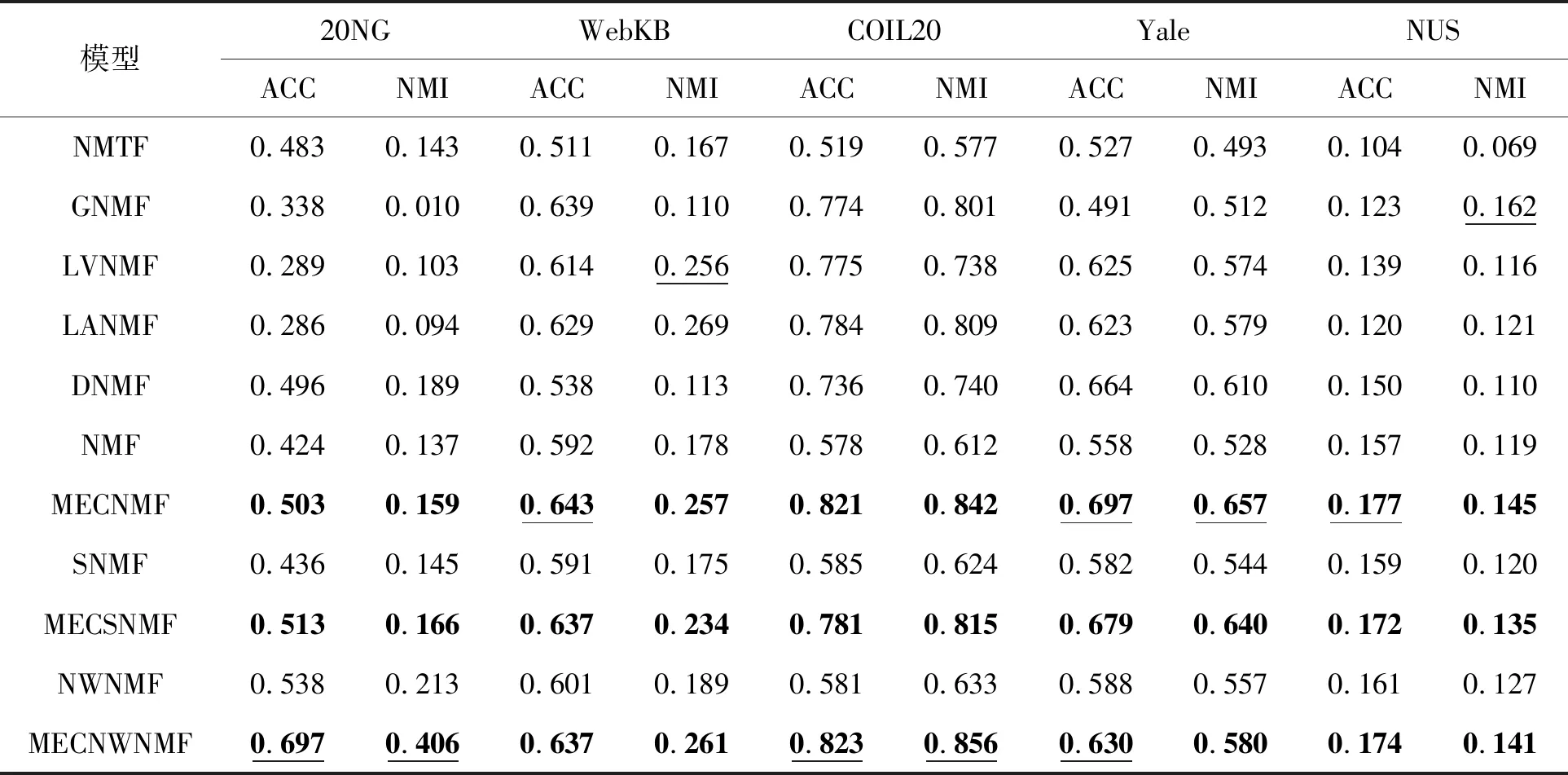
在算法1中,主要的运算是求导和矩阵运算。为了方便起见,本文假设所有浮点运算的时间复杂度都是相同的。根据迭代公式,可以得出NMF和MECNMF的计算复杂度如表1所示。可以看出,当K< 表1 NMF和MECNMF的计算复杂性 此次实验使用了5个数据集,其中2个是文档数据集,另外3个是图像集。表2统计了贡献度较高的数据。 表2 数据集统计 (1) 20NG:20新闻组语料库是一个约20 000个新闻文件的集合,分为20个不同的组和6个普通类别。它包含18 291个文档和9 313个经过预处理的常用词。本文把普通类别作为聚类的基本依据。 (2) WebKB:WebKB语料库包含4所大学计算机科学系的人工分类网页。网页分为7个类别,删除了其中的3个类别,这些删除的类别包含很少的样本,或者没有特定的含义,其余4个类别共4 168页、7 770个术语。 (3) COIL20:COIL20是一个图像数据集,包含20个对象从不同角度的形态,图像是像素大小为32×32的灰度图像,每个对象有72幅不同的图像,每个对象的图像归为一个簇。 (4) Yale:Yale是一个包含15个人、像素大小为32×32灰度图像的人脸图像数据集。每个实验对象有11幅不同面部表情或形态的图像。每个人的所有图像归为一个簇。 (5) NUS-WIDE-OBJECT(简称NUS):NUS-WIDE-OBJECT数据集是NUS-WIDE的一个子集,它是一个真实的Web图像数据集,它包含了31个类别的30 000幅图片。参考文献[9]后,本文移除了带有多个标签的图像,并从每个类别中随机选择了100幅图像。每个图像由500个维度BoW向量表示。 MECNMF是NMF及其变形的一种通用方法。将所提出的加权策略和非线性变换应用于具有代表性的NMF基线,以验证其灵活性。还将MECNMF与最近提出的NMF方法进行了比较,以说明其优越性。所有算法的比较结果及说明如下: (1) NMF[2]:通过使用式(3)中的平方欧几里得距离损失函数实现NMF。将输入矩阵X分解为子矩阵U和V,其中V是输入样本的潜在表示。 (2) MECNMF[10]:MECNMF通过在因子分解过程中自适应学习潜在因子的权重来改进NMF。通过分布状态分析、相关分析和非线性变换,改进了表示矩阵V。 (3) SNMF[11]:正则化NMF最常采用稀疏NMF(SNMF)。矩阵V的L1范数被附加到式(3)中,用于表示稀疏数据。 (4) MECSNMF[12]:与MECNMF类似,最大熵相关稀疏矩阵分解(MECSNMF)通过在因子分解过程中自适应学习潜在因子的权重来改进SNMF,非线性变换进一步提高了对数据非线性建模的能力。 (5) NWNMF[13]:Ncut-weighted NMF(NWNMF)使用特征相似图计算X的权重,然后将NMF应用于加权X以学习数据表示。 (6) MECNWNMF[14]:最大熵相关Ncut-weighted MF(MECNWNMF)通过应用状态分布分析、相关分析和非线性变换改进了NWNMF,增强了数据表示。 (7) NMTF[15]:非负矩阵三因子分解(NMTF)将输入矩阵X分解为三个子矩阵,X=USV,其中V为表示矩阵。 (8) GNMF[16]:图正则化NMF(GNMF)构造了一个相似图来编码数据样本之间的几何关系,并进一步令相似样本在表示空间中处于相邻位置。 (9) LCNMF[17]:相反在MECNMF的外部分析中,Large-Cone NMF(LCNMF)采用了促进潜在因子多样性的large-cone惩罚。large-cone惩罚分为两种形式,一种是由这些因素形成的平行面体积,另一种是它们成对夹角的总和。因此,LCNMF有两种变体,大体积NMF(LVNMF)和大角度NMF(LANMF)都与MECNMF进行了比较。 (10) DNMF[18]:Dropout NMF(DNMF)试图通过以一定概率随机删除潜在因子来促进其语义独立性。与MECNMF和LCNMF不同,潜在因子之间的相关性和多样性对它并没有很大影响。 在分析实验结果之前,本文比较并解释了不同算法间的参数设置。在所有三个MECNMF中,对于20NG、WebKB、COIL20、Yale和NUS数据集,平衡参数α设置为0.5,β分别设置为1、10-1、10-3、10-3和10-2。优化参数设置如下:(1) 优化U的初始步长η(0),令20NG为50,令WebKB为10,令COIL20、Yale和NUS均为1;(2) 将所有数据集的衰减率γ设置为0.999 9;(3) 这些数据集的最大外部迭代数T为500;(4) 所有数据集的最大内部迭代数S为15。 对于所有5个数据集中的11个NMF变体,潜在因子K的数量设置为50。SNMF和MECSNMF中稀疏项的平衡参数的取值范围是{10-3,10-2,…,103}。在NMTF中,虽然U和V的潜在维度可能不同,但值都设置为50。为了与MECNMF进行比较,进一步将NMTF的内矩阵S设为对角矩阵。对于GNMF、LVNMF、LANMF和DNMF,按照原文件中的参数值设置超参数。当NMF、MECNMF、SNMF、MECSNMF、NWNMF、MECNWNMF和NMTF收敛速度过快时,将最大迭代次数T设置为100,而将GNMF、LVNMF、LANMF和DNMF的值设置为1 000,因为它们的收敛速度很慢。MECNMF、MECSNMF和MECNWNMF的最大内部迭代次数S为15。对于所有的NMF方法,本文计算聚类结果的方法是在表示矩阵上采用K-Means算法。 本文采用聚类准确度(ACC)和归一化互信息(NMI)进行评价。用an和ln表示xn的原始聚类标记和预测聚类标记。ACC计算公式如下: (27) 式中:map(l)=argkmax(|{xi|li=l,ai=k}|)将簇标签映射到相应的原始标签;δ(·,·)检查两个标签是否相等,若相等则ACC为1,否则为0。互信息(MI)是决定集群划分的方法: (28) 式中:C和C′是同一样本集的两个不同的聚类;p(ci)测量了分配给聚类ci的整组样本的比例;p(ci,cj)是联合概率。为了更进一步直观了解,通过采用熵来规范化MI(C,C′): (29) 式中:H(C)表示聚类熵。 表3涵盖了以上5个数据集上所有算法的聚类结果。用黑体表示原始NMFs和相应MECNMFs之间较好的结果,并且在所有参与比较的方法中最好的结果下加下划线。可以发现: 表3 各个模型在不同数据集上的表现 与大多数算法相比,MECNMF在所有5个数据集上都表现出更好的性能,并且MECNMF(MECNMF、MECSNMF和MECNWNMF)始终优于原始算法(NMF、SNMF和NWNMF)。这有力地证明了对于具有代表性的NMF模型,本文算法比其他算法的性能较优越以及更能广泛被运用。因此,与传统的加权NWNMF相比,该策略能有效地提高潜在因子的权重。MECNMF在所有数据集上表现的性能都优于LVNMF和LANMF。此外,LVNMF和LANMF在数据集20NG上表现的性能比NMF要差,其原因在于紧凑的论题可以更好地适应输入数据。20NG数据集是一个松散分类的新闻语料库,数据中存在噪声和冗余。如果不考虑潜在因子之间的关系,学习到的语义空间很容易被误导。然而,MECNMF通过提高语义空间的紧凑性可以解决这个问题。DNMF性能优于NMF,但比MECNMF差。这说明对学习过程中潜在因子之间的关系进行建模确实可以改善NMF,并且MECNMF的显式分析比DNMF中的内部丢弃表现得更好。最后,所有的MECNMF总是比NMTF表现更好,因此所提出的加权策略发挥了作用,而不是简单地在因子分解中插入一个对角矩阵。 2.6.1α敏感性分析 图2 平衡参数α分析 2.6.2β敏感性分析 图3 平衡参数β分析 2.6.3K的敏感性分析 影响NMF性能的另一个参数是潜在因子K的数量。对于一个给定的数据集,潜在因子的数量不能预先精确估计。较小的K值不能学习数据中全部的信息,而较高的K值会增加计算复杂度和学习参数的难度。因此,有必要分析该算法对K的敏感性,为此本文进行了当K∈{20,30,40,50,60,70,80,90,100}时的实验。图4描绘了当K取不同值时4种算法的聚类结果变化情况。理想情况下,随着K的增加,聚类结果变得更好。然而,在实验过程中,曲线是波动的,但总体趋势是向上的。不稳定的主要原因可能是本文采用梯度下降法对算法进行了优化,算法往往受到初始化值等因素的影响,有可能陷入局部优化。此外,参数的随机性也会导致曲线波动。然而,无论K值如何变化,本文提出的改进算法(MECNMF和MECNWNMF)总是比原算法(NMF和NWNMF)性能更好。考虑到性能和时间消耗,综上所述,将K设置为50。 图4 平衡参数K分析 首先,MECNMF考虑了潜在因子的分布状态,并强制它们从原始特征中编码更多的信息,以减少语义歧义。g(·)函数用来衡量一个潜在因子对语义的编码程度。当α=1(表示为MECNMF-g)时,它是影响权重的唯一因素。如果有效地降低模糊度,uk的分布将集中在更多的原始特征上,并且g(uk)需要取较高的值。图5描绘了MECNMF、MECNMF-g和NMF收敛后g(·)函数的值。为了便于说明,潜在因子按g(·)值的升序排列,仅取前15个值。可以看出,MECNMF和MECNMF-g的g(·)值均比NMF的大,因为它们可以编码更多的原始语义以减少歧义。尽管不明显,MECNMF-g的g(·)值略大于MECNMF,因为它的加权策略只考虑了最大熵度量。 图5 信息熵函数分析 其次,MECNMF还考虑了潜在因子之间的相关性,并将其归纳为一个紧凑的语义空间,过滤掉异常值和噪声。用h(·)函数来度量语义空间的紧密性,当α=0(表示为MECNMF-h)时,它是权重中唯一需要考虑的因素。当MECNMF、MECNMF-h和NMF收敛后,在图6中绘制出h(·)的值。为了便于说明,潜在因子按h(·)的升序排列,仅描绘了前15个值。很明显,MECNMF和MECNMF-h都比NMF有更大的h(·)值,因为潜在因子需要学习一个紧凑的语义空间。另外,由于MECNMF-h的加权策略只考虑了语义的紧凑性,所以它的h(·)值比MECNMF大。总之,分布状态函数g(·)和相关函数h(·)在MECNMF学习过程中都起着举足轻重的作用,而且二者的融合进一步提高了系统的性能。 图6 因子相关函数分析 进行了证明算法的收敛性和收敛速度的实验。图7描绘了上述数据集的收敛曲线,x轴表示迭代次数,y轴表示目标函数值。可以看到,本文算法在上述5个数据集上经过大约200次迭代后达到收敛,这说明本文算法收敛速度很快。 图7 收敛函数 如表1所示,当K< 为解决传统非负矩阵分解不考虑潜在因子的相关性与分布特征等缺点,提出一种基于最大熵与相关性分析的非负矩阵分解方法。通过多个数据集的实验可得出如下结论: (1) 对于具有代表性的NMF模型,MECNMF比其他算法的性能更优越,且具备更好的泛化能力,另外,算法的收敛速度很快。 (2) MECNMF通过提高语义空间的紧凑性可以提高潜在因子的权重,有效地解决语义空间容易被误导的问题,并且MECNMF的显式分析比DNMF中的内部丢弃表现得更好。 (3) 分布状态函数和相关函数在MECNMF学习过程中都起着举足轻重的作用,而且二者的融合进一步提高了系统的性能。
2 实验与结果分析
2.1 数据集
2.2 不同算法间比较
2.3 实验参数设置
2.4 评价指标
2.5 聚类结果
2.6 参数分析
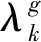
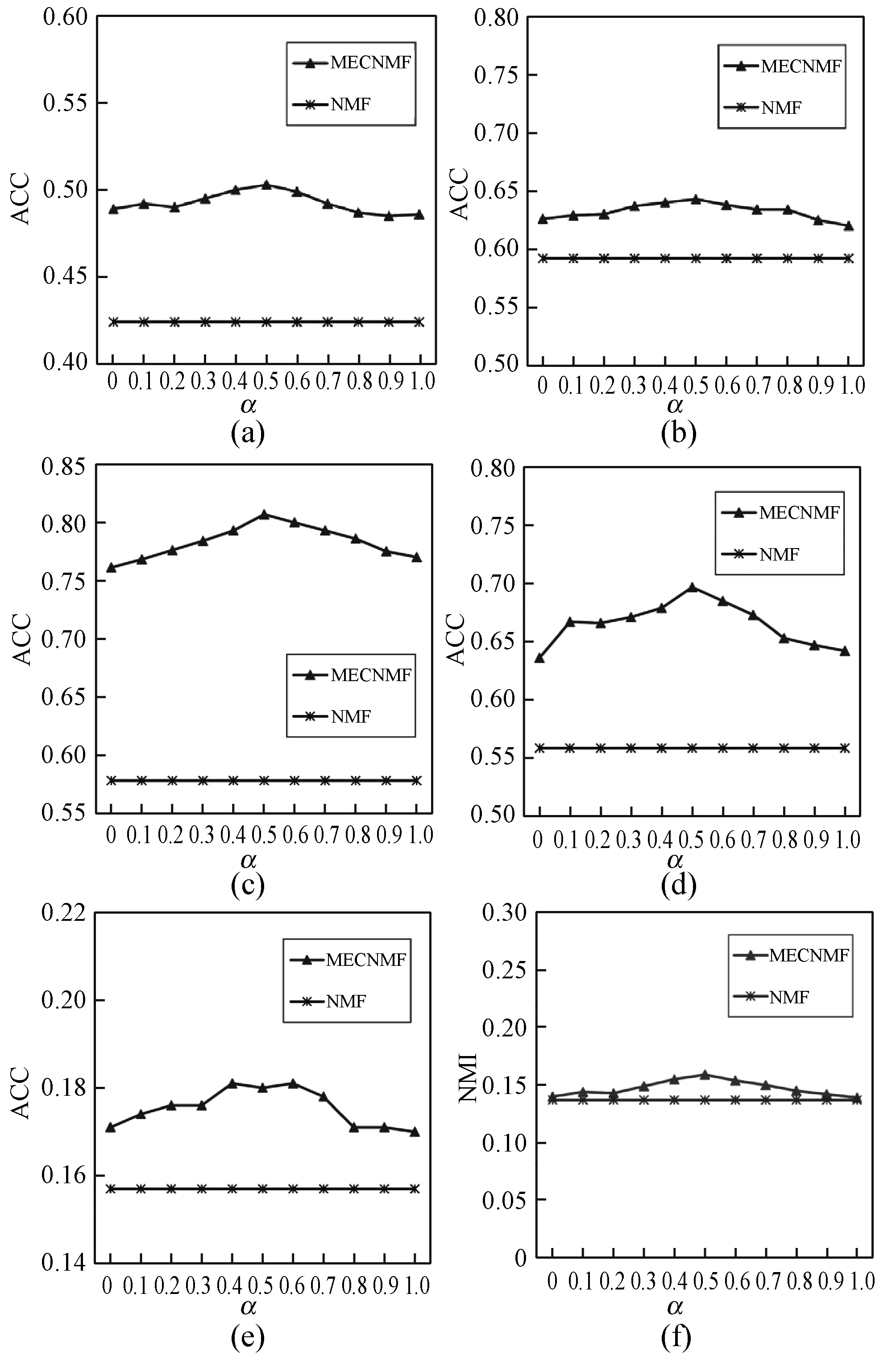
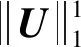
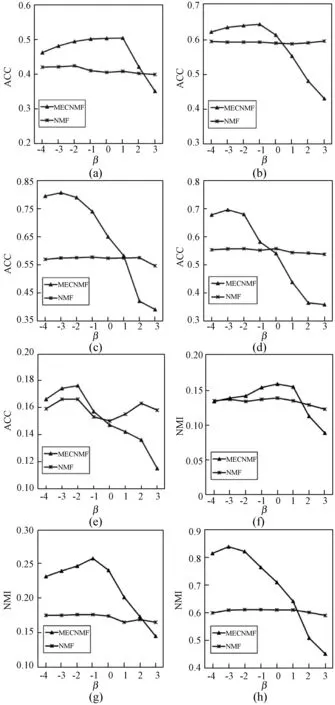
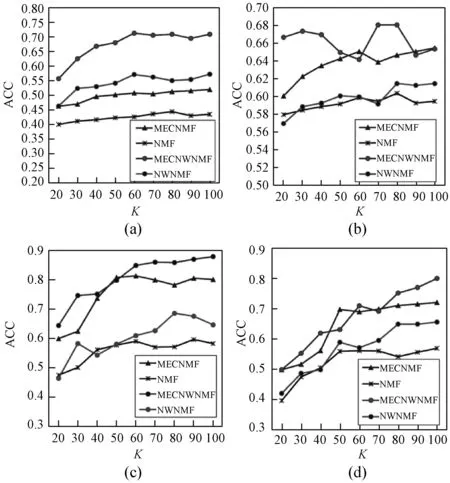
2.7 语义空间分析
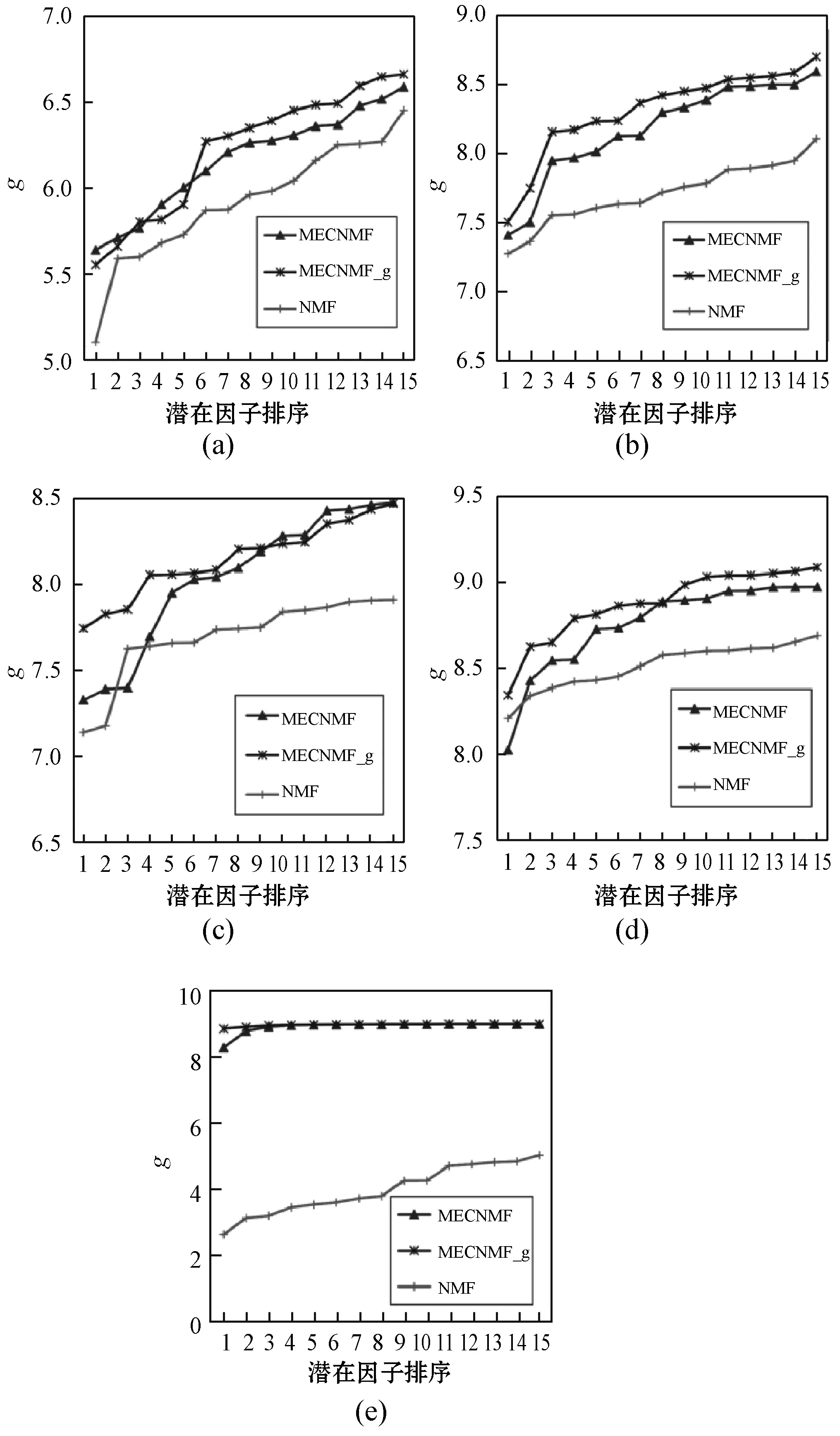
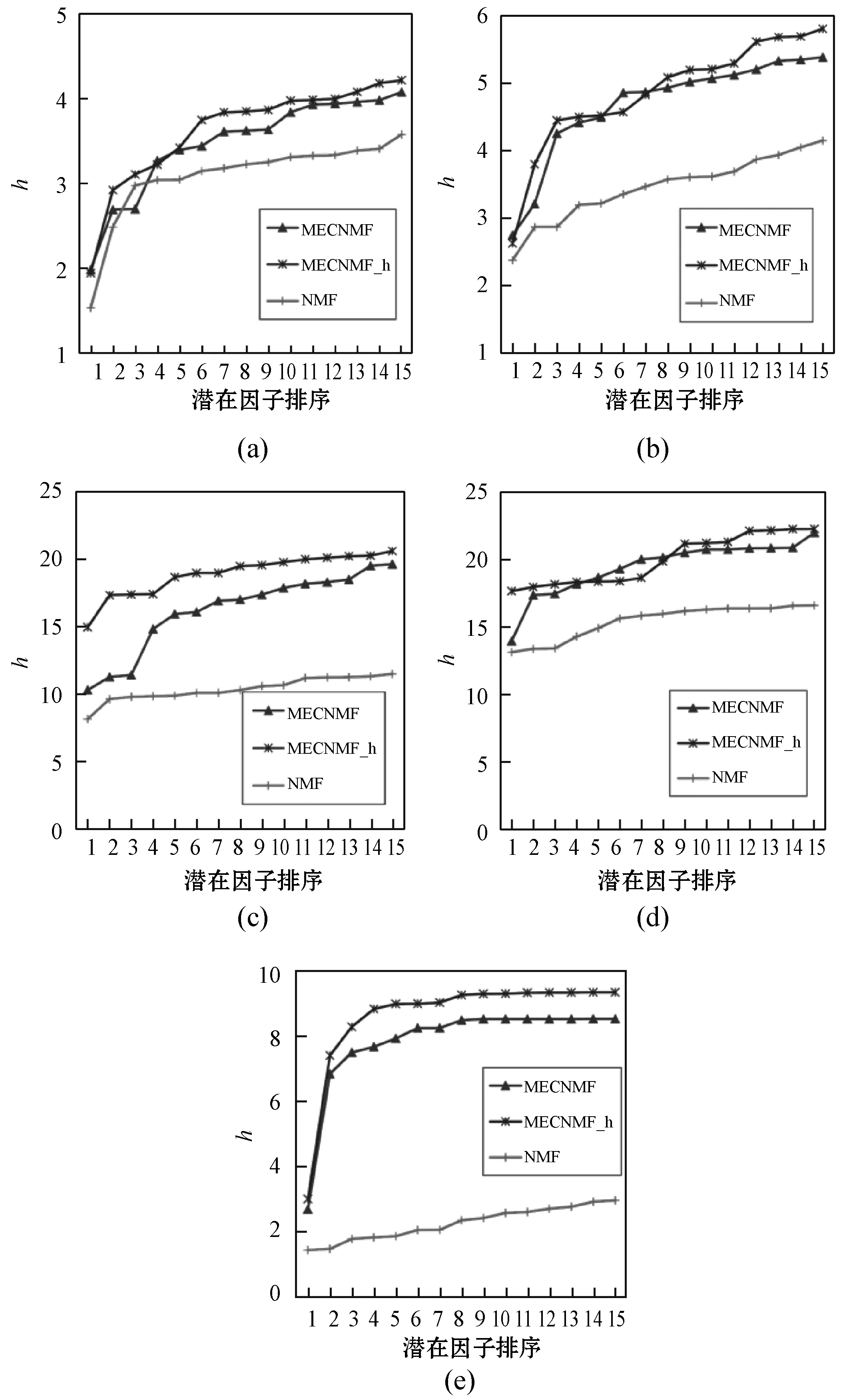
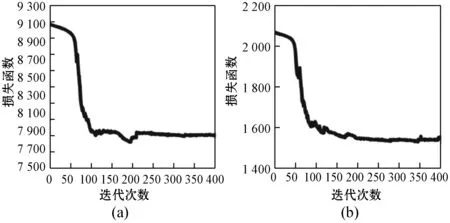
2.8 收敛性与计算效率
3 结 语
