基于最大信息挖掘广域学习系统的混沌时间序列预测
2023-10-09闫机超郑静雅孙胜耀
闫机超 郑静雅 孙胜耀
1(郑州职业技术学院软件工程系 河南 郑州 450121)
2(河南大学计算机学院 河南 开封 475000)
0 引 言
混沌时间序列预测对于许多领域都是十分重要的技术手段,比如天气预测、价格预测和成绩预测等,因此得到了广泛的关注[1-2]。然而,线性方法不足以学习时间序列的非线性模式,因此学者们开始将注意力放在非线性模型混沌时间序列预测的研究上[3]。
混沌动力系统中,由于各种因素的影响,存在着不稳定的因素:线性相关、非线性决定机制、混沌机制、噪声等。最大化信息开发(MIE)可以看作是充分提取数据中的特征并充分利用它们[4]。随着神经网络和深度学习的发展,MIE是学者们研究和追求的目标。反向传播算法利用反向传播误差来更新权重以减少输出误差,在一定程度上可以看作是MIE的早期阶段[5]。此外,学者们开始关注网络架构的研究,以达到最大的功能利用率。文献[6]近年来提出了密集网络布局的层叠结构,通过创建更复杂的特征检测器来追求信息的充分利用。文献[7]提出了使用“门通道”来控制原始信息的传输,以避免信息丢失。文献[8]提出的密集卷积网络(DenseNet)保证了各层信息的直接连接,减少了特征的丢失。这些方法通过建立快捷连接来确保信息的完整性,但是为了获得较好的预测效果,上述方法训练时间较长,需要的样本较多,且模型的可解释性较差。
为此,文献[9]提出了广义学习系统(BLS),该系统也使用层叠结构来实现信息挖掘并进行动态更新,因此,它不会经历长时间的训练过程。结构化流形BLS(SM-BLS)则基于流形学习的无监督人工学习和非均匀嵌入提取特征,挖掘时间序列潜在的确定性演化信息,提高模型的可解释性[10]。文献[11]提出了一种新的基于随机扰动近似的正则化方法,并将其应用于鲁棒流形BLS中,用于噪声时间序列的预测。考虑到时间序列的时间特性,在BLS的特征节点中引入了一种储层结构,用于时间序列的动态模式提取。虽然这几种方法有效解决了训练时间与模型解释性问题,但是仍旧未能充分挖掘混沌系统的演化信息,使得预测精度的提升有限。
为了解决上述问题,提出一种基于最大信息挖掘广域学习系统的混沌时间序列预测模型,并在四个大规模数据集进行了实验,结果证明了本文方法能够有效提升预测效果。
1 相关研究
1.1 漏积分器回波状态网络
一个典型的回波状态网络(Echo State Networks,ESN)包含一个输入层、一个输出层和一个称为池化层的隐藏层。从输入层到隐藏层的权重Win和动态隐藏层的权重Wres是随机生成的,而从隐藏层到输出层Wout的权重矩阵是通过监督学习得到的。令v(t)=[v1(t),v2(t),…,vN(t)]T,t=1,2,…,T表示为输入时间序列,假设u(t)=v(t)为输入序列,y(t)=v(t+τ)为输出序列。改变步长τ可以实现不同时间域的预测。基本状态方程可以表示为:
x(t+1)=f[Winu(t+1)+Wresx(t)]
(1)
式中:x(t)∈RS×1表示网络的第t步时间状态,S是隐藏层的维度;f(·)是输出层的激活函数,通常采用双曲函数。当t增大到无穷大时,当前状态对初始状态的依赖性减小。
LIESNs是回声状态网络ESN的一个变形网络。其基本结构与ESN相似。唯一的区别是,LIESNs的隐藏层包含泄漏的积分神经元,这使得它能够保持前一时刻的激活状态。LIESNs的状态方程如下:
x(t+1)=(1-a)f(Wresx(t)+Winu(t+1)+
Wbacky+ax(t))
(2)
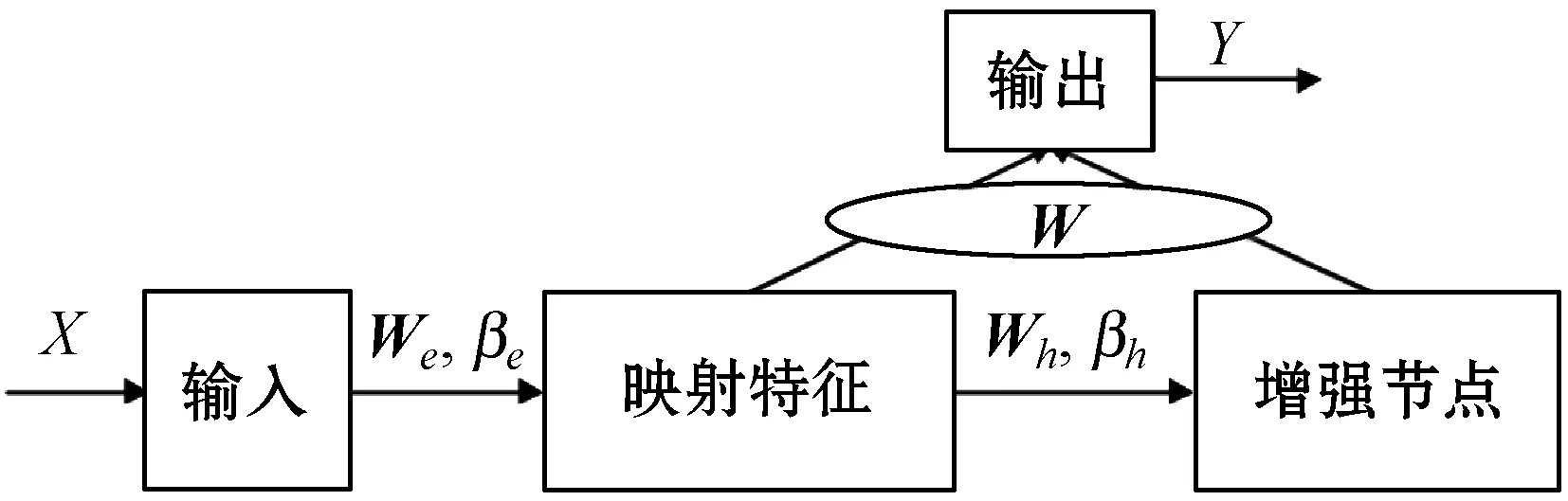
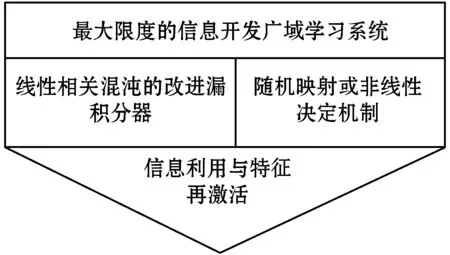
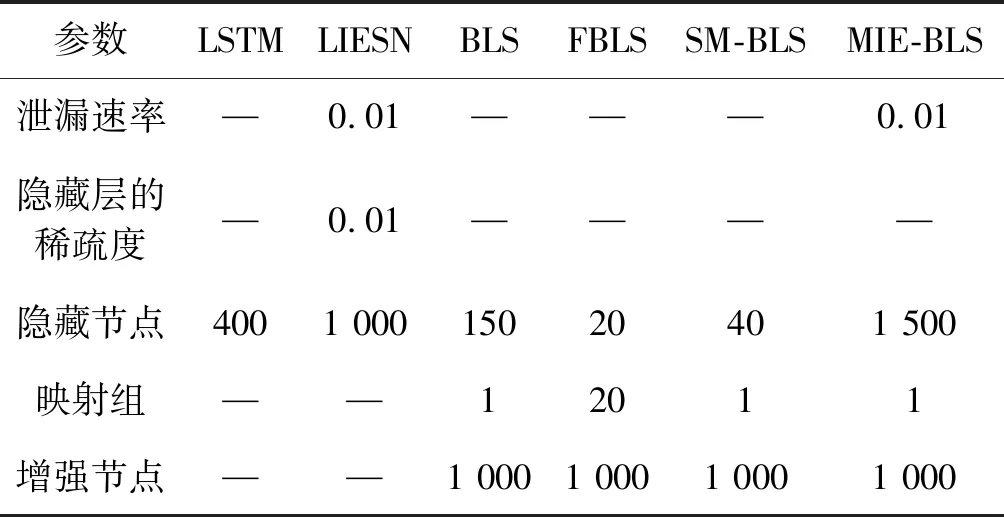
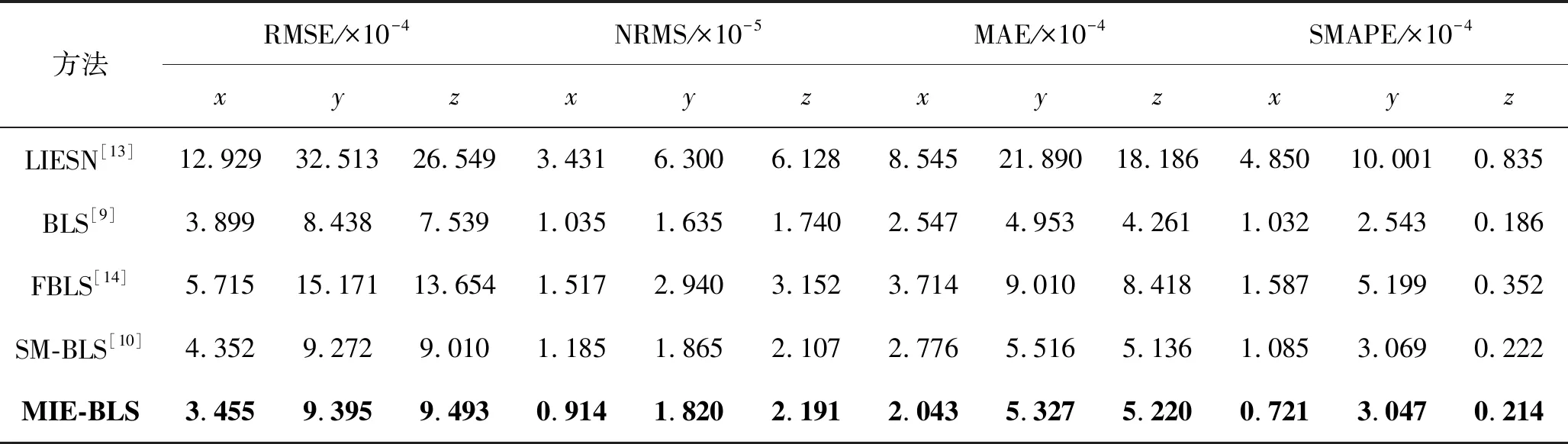
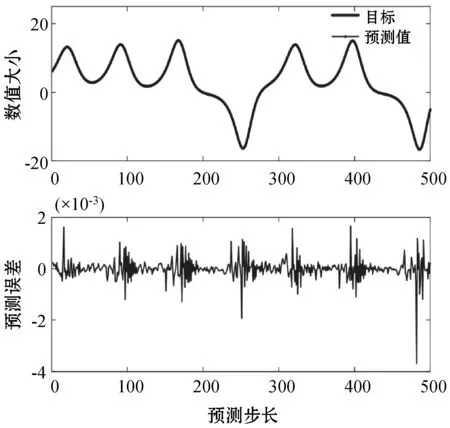
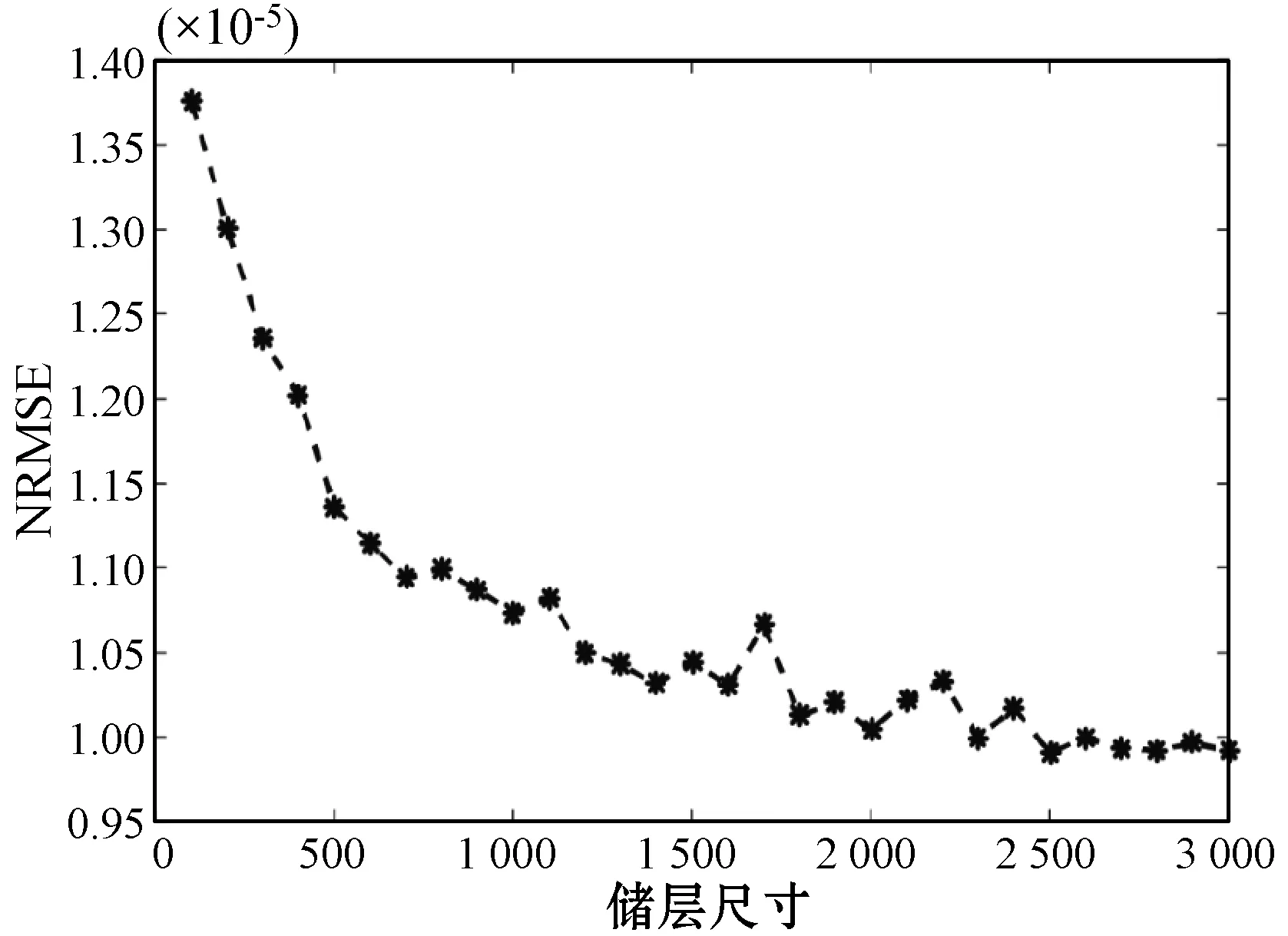
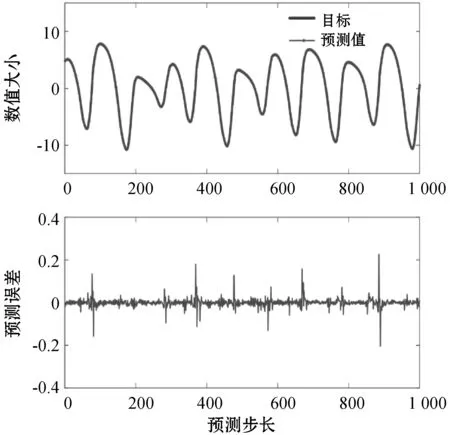
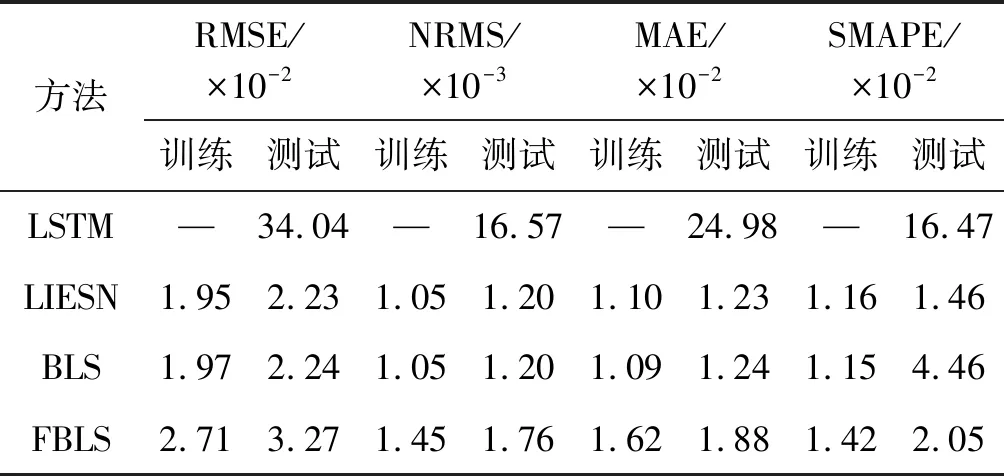
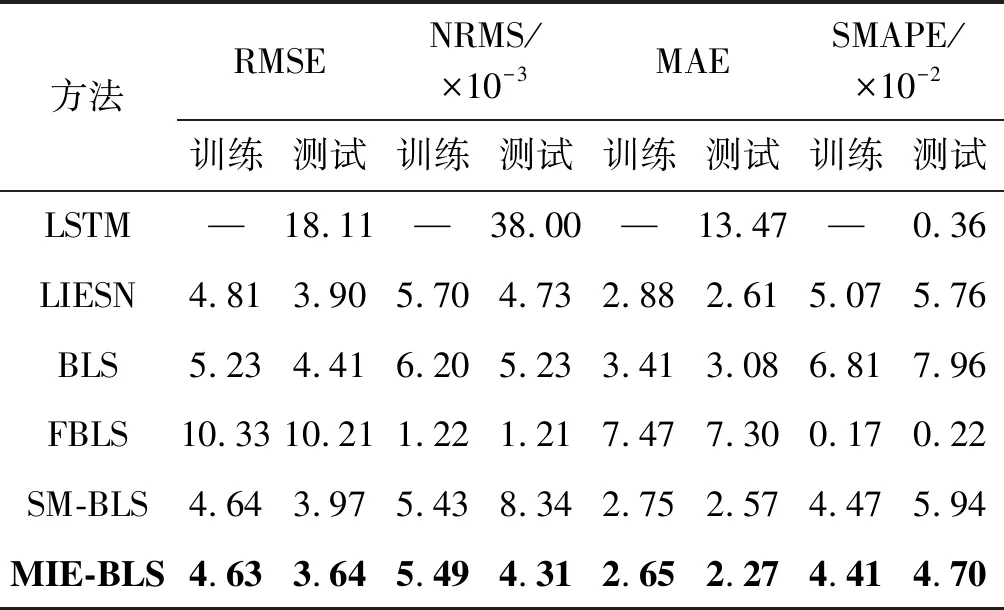
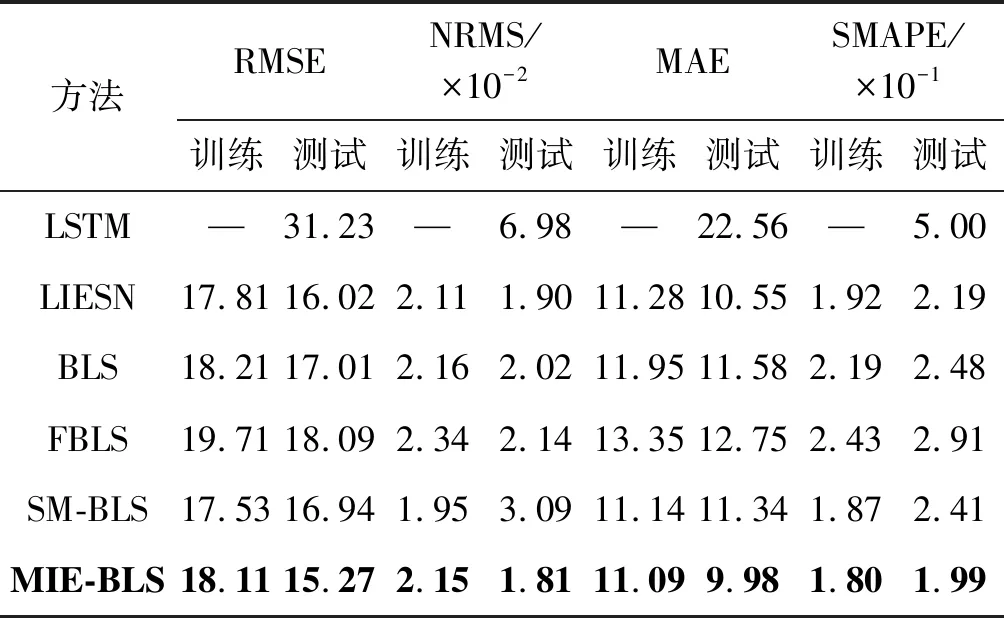
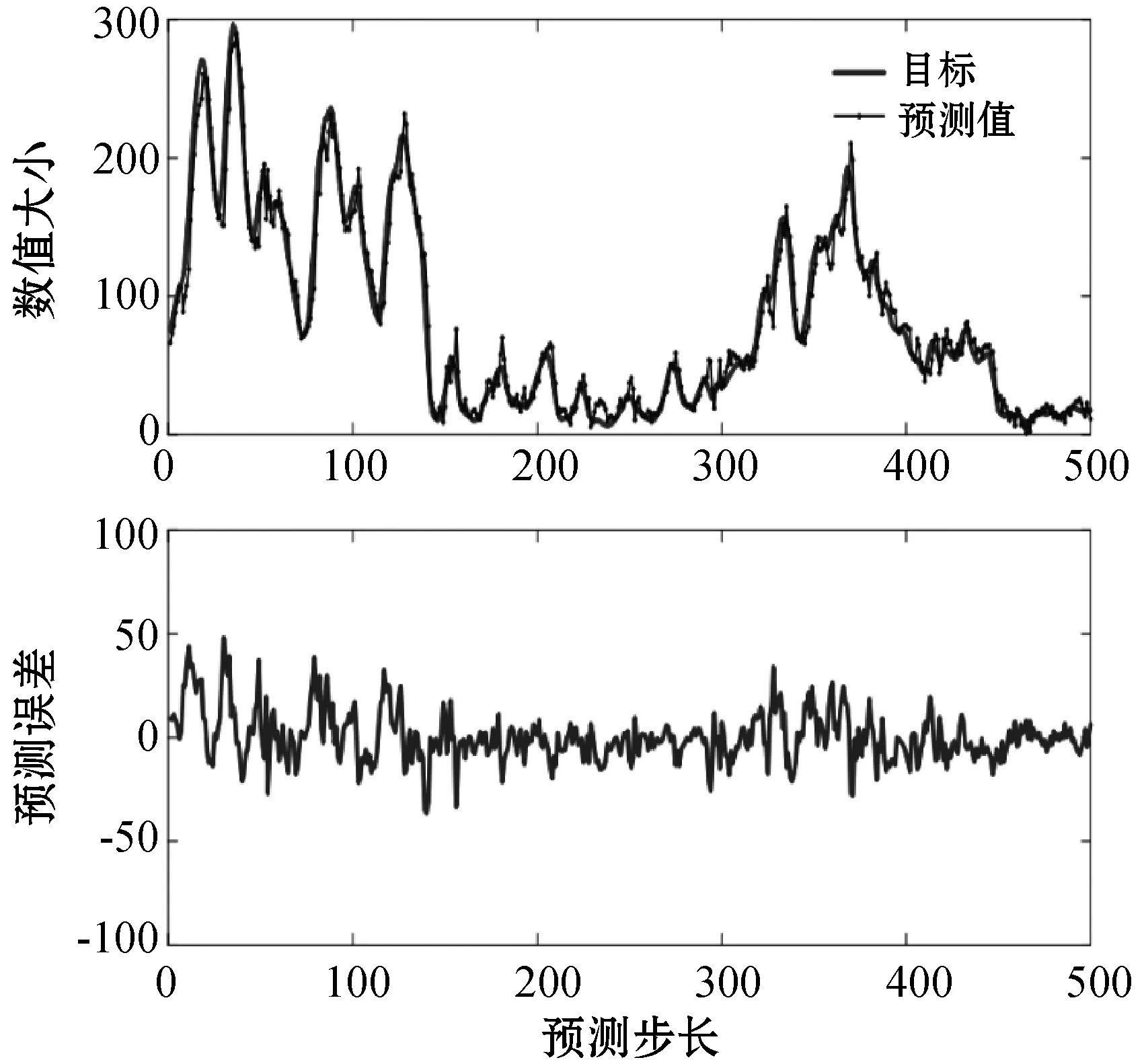
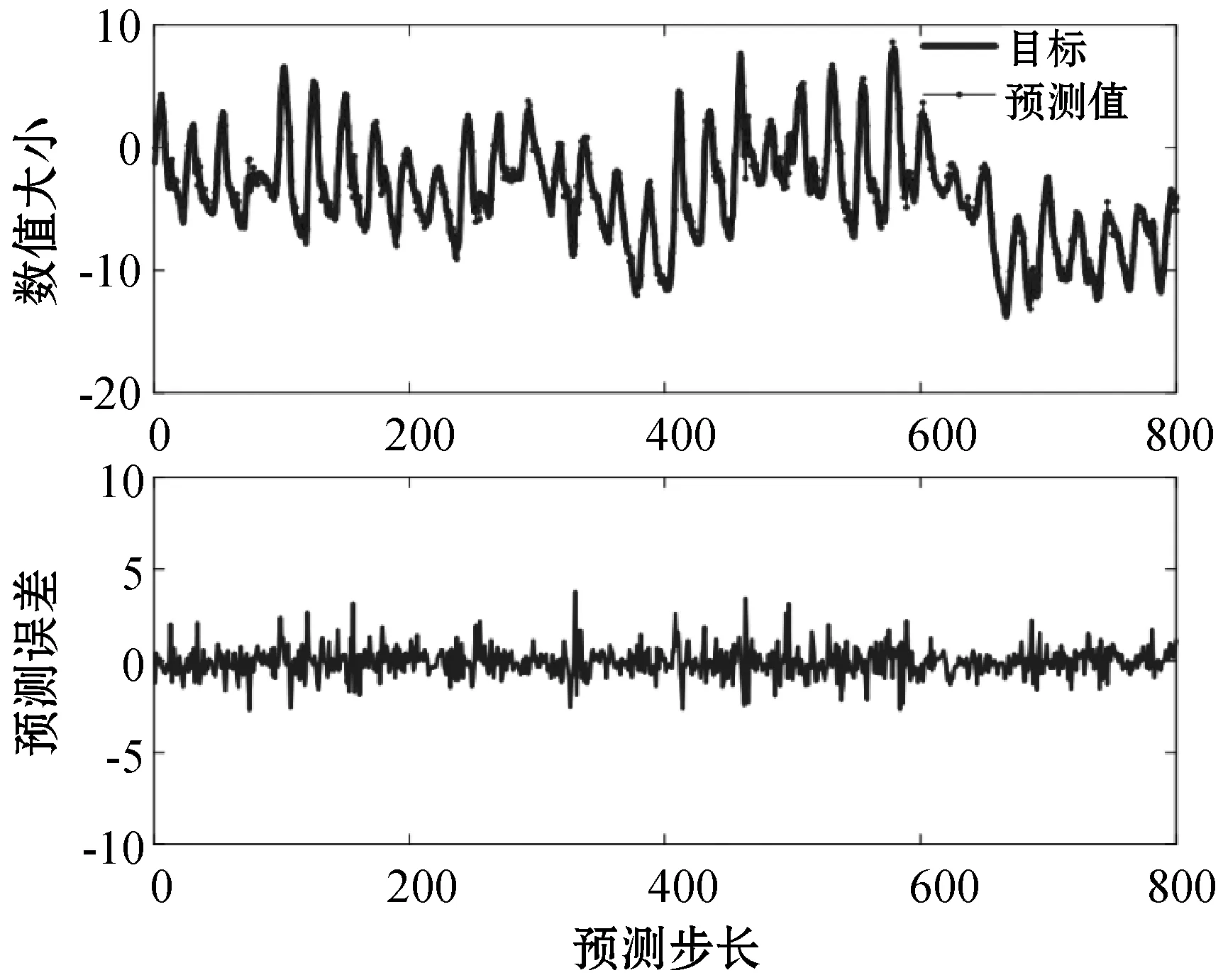
式中:0 (3) No-prop算法是克服局部最优问题的一种有效算法,BLS是no-prop算法的一个演化,它可以动态更新且不需要重新训练。图1描绘了BLS的结构,展示了信息传播的方式以及不同权重的影响。 图1 BLS结构 在特征学习阶段,将输入转换为特征节点并生成特征映射。假设一个BLS包含n组特征节点并且输入为U,则特征映射为: Zi=∅(UWei+βei)i=1,2,…,n (4) 式中:Wei和βei表示第i个特征映射节点的权重和偏差;∅(·)表示特征映射节点的激活函数。将特征映射的输出作为P=[Z1,Z2,…,Zn],P表示不同生成模式下的所有特征映射。特征提取中的非线性学习能力由增强型节点来补偿。这些特征被随机映射到增强节点。假设增强层中有m个节点,则公式如下: Hj=ξj(PWhj+βhj)j=1,2,…,m (5) 式中:特征和第j层的增强节点之间的权重Whj和偏差βhj是随机产生的,且具有适当的维数;ξj(·)表示第j个节点的激活函数。本文中激活函数为Sigmoid函数。增强层的整体输出可以表示为: Hm=[H1,H2,…,Hm] (6) 则BLS被定义为: Y=[Z1,Z2,…,Zn|H1,H2,…,Hm]W=[P|Hm]W (7) 式中:W是BLS的输出权重。 提出的MIE-BLS主要可以分为两部分:基于改进泄漏积分型隐藏层系统演化模式的发现和基于随机映射的非线性动态特征的重新激活。首先,采用没有非线性激活的改进泄漏积分型动态隐藏层将系统的当前状态和历史状态进行整合。其次,将模拟系统隐藏层的状态发送到增强层,以提取非线性信息,并在大规模时间序列预测应用中快速建模。此外,动态隐藏层和随机非线性增强特征与输出层同时连接。 假设重建的输入数据矩阵为U=[u1,u2,…,uN]T∈RN×K,其中:N为样本大小;K为输入维数。为了模拟输入时间序列的状态演化信息,本文引入了一种改进的泄漏积分型隐藏层来动态捕获特征。渗漏积分神经元的动态隐藏层状态更新公式为: x(t+1)=(1-a)f(Wresx(t)+Winu(t+1)+ax(t)) (8) 为了最大程度地挖掘信息,避免不同层之间的信息传递出现损失,在状态更新公式中用一个完全线性传递方法代替非线性激活。 x(t+1)=(1-a)(Wresx(t)+Winu(t+1)+ax(t)) (9) 此线性传递方法使动态系统中的信息流最大化,激活了新状态和历史状态之间的相互作用。为了避免隐藏层稀疏性带来的不确定性,在模型中引入了全连接层。将所有更新后的隐藏层状态定义为: P=[x(1),x(2),…,x(N)]T (10) 线性激活函数没有复杂的映射功能,因此本文利用泄漏积分型隐藏层到增强层的随机映射进行复杂映射和快速建模,表示为: Hj=ξ(PWhj+βhj)j=1,2,…,m (11) 式中:Whj和βhj是随机生成的,表示权重和偏差;P是隐藏层状态;m是增强节点的个数。增强层的输出为Hm=[H1,H2,…,Hm]。Hj表示为映射值,假设U对应的输出为Y,则设计的模型的输出可以表示为: Y=[P|Hm]W=AW (12) 式中:W是MIE-BLS的输出权重;A=[P|Hm]W∈RN×(n+m)。层叠机制实现了将线性和非线性特征与输出直接连接,恢复了增强层在传输中丢失的信息,弥补了网络中的信息偏差。这里采用岭回归算法求出输出矩阵: W=(ATA+λI)-1ATY (13) 式中:λ是正则化参数。岭回归用于计算输出权重,因为它可以有效地防止过拟合现象。 传统的前向神经网络可以看作是面向状态的计算技术。状态在不同层之间传输。每层状态的变化记录了需要保留的信息。不同层之间传输存在信息丢失,这是不可避免的。所有的特征学习方法都可以看作是提取回归/分类的本质特征,避免信息丢失。从混沌时间序列预测的角度来看,MIE应该最终利用混沌时间序列中的线性相关性、非线性确定性和混沌性。如图2所示,采用了两种基本机制来保证混沌动力学系统的MIE:改进的泄漏积分隐藏层代表相互作用机制和具有随机映射的增强层代表层叠机制。这两项技术增强了MIE且将功能重新激活。 图2 MIE理论描述 LIESNs隐藏层的结构与ESN相似。在典型的ESN中,没有单位内存,并且隐藏层中的状态取决于先前的非线性状态。在LIESNs中,隐藏层中的状态也依赖于历史状态,同时保留了更多的时间演化动态,便于时间序列预测。因此,泄漏积分型机制比标准ESN更适合于时间序列的动态建模。为了模拟混沌系统的动态演化过程,引入了改进的泄漏积分型隐藏层。式(9)表明,隐藏层的泄漏积分型神经元衡量历史状态和当前状态,实现最后状态和更新状态之间的相互作用和相互补充。 隐藏层特征节点与输出之间的增强层对提取的动态特征进行非线性映射。然后,增强层和泄漏积分型动态特征传输到输出层。增强层可以利用动态特征,且能够容易地实现对非线性信息的探索和动态特征的重新激活。建立一条直接连接特征和输出的短路径,以补偿传输中不可避免的信息丢失。采用层叠机制促进信息的传播和重利用,恢复传输时在不同层之间丢失的信息,并探索最大数量的信息。 (1) 与DenseNet的异同:本文提出的MIE-BLS与DenseNet在结构上相似。两者网络的各层之间均采用层叠的方式。不同之处在于它们使用了不同的特征映射方法:DenseNet利用卷积神经单元进行图像应用,而MIE-BLS使用泄漏积分型神经元进行混沌动态发现。从结构方面比较,MIE-BLS小得多,在某些情况下仅等效于四层密集模块。 (2) 与HighwayNet的异同:在HighwayNet中有一个从输入信号到隐藏层的门控通道。隐藏层不仅可以学习上一层的非线性激活信息,还可以通过快捷连接访问原始信息。但是,MIE-BLS始终可以学习输入的完整线性映射。而且,HighwayNet的权重需要训练和学习,而MIE-BLS不需要。 (3) 与ResNet的异同:从特征重用的角度来看,提取恒等映射可以使网络不必学习恒等映射,可以直接学习剩余部分,从而简化了学习目的和难度,减少了信息的冗余。但是有可能只有少数几个模块学习了有用的表示,或者许多模块共享很少的信息,从而对最终目标的贡献很小。 HighwayNet、ResNet和DenseNet都包含不同层之间的信息。与这三个网络相比,本文提出的模型更适合于动力学建模和大规模混沌时间序列预测。除了信息利用层叠机制之外,这些网络中还应用了信息交互和探索的迭代机制。 假设高维特征为u∈Rm,低维特征为v∈Rn,随机矩阵为A∈Rn×m,n< (14) 式中:δ是非常小的正数。压缩感知理论中的有限等距性质证明存在一个满足式(14)的固定随机矩阵。同样,JL定理也为上述结果提供了理论支持。 JL定理:假设存在U=[u1,u2,…,ud]∈Rm×d且0<δ<1,β>0,令: (15) 对于U中的任何两个向量ui、uj(i≠j),都有一个映射f:Rm→Rn。将映射f定义为随机矩阵A,并将矩阵中的元素定义为A(i,j)=aij,此时,需要满足: (16) 文献[8]证明了随机高斯矩阵满足条件。高斯随机矩阵映射可以使向量之间保持适当的距离。从本质上讲,所有由随机投影实现的降维技术都是基于JL变换得到的。本文考虑在增强层中使用随机高斯矩阵进行映射,以保持隐藏层原始的动态关系。 算法1基于最大信息挖掘广域学习系统的混沌时间序列预测算法 输入:训练数据,测试数据。 输出:预测结果。 1.参数初始化:给定泄漏速率、隐藏节点、增强节点和迭代次数初始值; 2.首先构建最大信息挖掘广域学习系统; 3.输入训练数据进行系统训练: 4.重建的输入数据矩阵为U=[u1,u2,…,uN]T∈RN×K 5.根据式(9)状态更新; 6.利用随机映射式(11)进行复杂映射和快速建模; 7.按照式(12)计算模型的输出; 8.采用岭回归算法,即式(13)求出输出矩阵W; 9.并训练得到相应的特征映射节点的权重Wei和偏差βei以及增强节点之间的权重Whj和偏差βhj; 10.训练过程结束,得到训练的最大信息挖掘广域学习系统模型; 11.将测试数据作为最大信息挖掘广域学习系统模型的输入; 12.输出预测结果。 本文收集了四个混沌时间序列数据集。通过计算最大Lyapunov指数,验证了两个真实数据集的混沌特性。 (1) 洛伦兹时间序列: (17) 当α=10、β=8/3、γ=28时,系统表现出混沌特性。实验模拟数据有50 000个样本组。用嵌入维数[20,20,20]和延迟时间[1,1,1]分别将Lorenz时间序列重构到相空间中。 (2) Rossler时间序列: (18) 当b=0.2、c=0.2、d=5.7时,系统表现出混沌特征。本实验用初始状态[1,1,1]生成30 000组数据,均匀嵌入维数为40,延迟时间为1。 (3) 北京空气质量指数:北京每小时空气质量指数(AQI)数据采集地点是北京首都国际机场。2010年1月2日至2014年12月31日共采集43 824个小时的样本,每组数据包括5个参数:PM2.5、压力、风速、露点和温度。将嵌入维数设置为[40,40,40,40,40],在PSR过程中延迟时间为[1,1,1,1,1]。 (4) 北京气象数据:这组数据是从2018年SIGGDD比赛中下载的。记录了北京顺义8782集团2017年1月30日16:00至2018年1月31日15:00期间的气象数据,有温度、压力、湿度、风向和风速5个变量。对于缺失的值,采用三次样条插值进行填充。将嵌入维数和延迟时间分别设置为40和1。 实验中,所有数据集按9∶1的比例分成训练集和测试集。本文选择了一些其他方法进行比较:长短期记忆网络(LSTM)[12]、LIESN[13]、BLS[9]、FBLS[14]和SM-BLS[10]。用均方根误差(RMSE)、归一化均方根误差(NRMSE)、平均绝对误差(MAE)和对称平均绝对百分比误差(SMAPE)四个指标来评价预测性能。 在实验中,泄漏积分型隐藏层的初始状态被设为0。表1给出了一些重要的参数设置,其中隐藏节点包括LSTM的隐藏节点、LIESN和MIE-BLS中的隐藏层大小、SM-BLS中流形嵌入后的维数、FBLS中各模糊子系统中的规则、BLS中的特征节点。映射组是指FBLS中的模糊子系统和BLS、SM-BLS和MIE-BLS中的特征映射组。符号“-”表示对应的参数无效。 表1 模拟实验参数设置 表2列出了Lorenz时间序列每一步预测的比较结果。结果表明,在Lorenz-x的预测中,MIE-BLS的效果优于其他方法。在Lorenz-y和Lorenz-z的预测中,本文模型性能较好。Lorenz时间序列的每一步预测曲线如图3所示。为了清楚地了解泄漏型隐藏层规模及其漏失率对Lorenz时间序列一步预测结果的影响,本文将其绘制成NRMSE的三维图,如图4所示。从图4(a)可以清楚地了解到,随着储层尺寸的增加,总体NRMSE呈下降趋势。此外,当隐藏层的大小超过1 500时,NRMSE下降缓慢,并且总体下降幅度较小,训练时间迅速增加。因此,在图4(c)中,当隐藏层大小为1 500时,将NRMSE绘制为泄漏率的函数。通常,随着泄漏率的降低,NRMSE逐渐减小。图5的右上方显示了最低NRMSE所在区域的曲线。可以看出,最小值是在1-a=0.99(a是泄漏率)下获得的,它与表1中的参数相对应。 表2 时间序列每一步预测的比较结果 (a) Lorenz-x (a) 储层尺寸与NRMSE 图5 MIE-BLS对Rossler-v的一步预报结果 除了Lorenz时间序列模拟外,另一个有关Rossler时间序列的基准问题测试实验验证了模型的有效性。其y序列的一步预测结果如表3所示。在本实验中,MIE-BLS的预测性能最好。图5显示了它的预测曲线和误差,可以看出,误差值基本不超过0.2。 表3 ROSSLER-y时间序列的一步预测性能的比较 本文还对北京市的两组数据集进行了MIE-BLS的进一步验证。将PM2.5作为预测变量,北京市空气质量指数的一步预测对比结果见表4,三步预测结果对比见表5,可以看出,MIE-BLS在实际数据集的训练和测试过程中都取得了最好的效果。在表4和表5的大多数实验数据表明,测试集的训练结果优于训练集。这对时间序列的分析是合理且实用的。与图像不同,时间序列包含着丰富的动态信息。此外,混沌时间序列的演化不是一成不变的,它表现为线性相关、非线性确定性和混沌性。该数据集的时间跨度很长,训练集占总数据量的90%,包含有较大的波动和噪声。而测试集的波动相对较小,比训练数据包含的噪声少。相应的三步预测曲线如图6所示。虽然预测动态波动剧烈时的结果准确率不高,但预测误差在可接受范围内。 表4 北京市空气质量指数的一步预测性能的比较 表5 北京市空气质量指数的三步预测性能的比较 图6 MIE-BI三步预测PM2.5的结果 北京市气象资料进一步证明了该方法的实用性和有效性。以温度为预测变量,其预测误差曲线如图7所示。显然,预测曲线基本符合原始数据曲线,误差在可接受范围内,无较大偏差。本文方法的一步预测结果与其他方法的比较如表6所示。可以看出,尽管两种方法的RMSE没有太大差别,但SM-BLS的NRMSE是MIE-BLS的两倍多。原因可能是本文方法可以动态捕捉时间信息,并成功地捕捉到混沌时间序列的峰值。 图7 MIE-BLS一步预报温度结果 LSTM的性能并不令人满意。一方面,LSTM的时间复杂度高、训练难度大;另一方面,由于递归网络的结构,LSTM虽然具有短期记忆能力,但特征信息的有效利用对预测也起着重要作用。与深层神经网络相比,MIE-BLS具有快速训练的特点。MIE-BLS的性能优于LIESN。这主要是因为特征和增强层输出之间的层叠补偿了在传输过程中丢失的信息及具有特征重利用功能。虽然LIESN能够捕捉到输入的有效特征,但在描述输入和输出之间的关系方面不如MIE-BLS。此外,FBLS还应用于图像分类和时间序列预测。为了平衡图像信息的处理,这种方法可能缺乏一种独特的时间序列处理机制,因此通常应用于多个实验中。与本文方法中最大化信息利用的思想不同,SM-BLS主要用于提取时间序列的多种信息,并选择一些包含更多动态信息的流形特征,这些特征值通常较小。因此,忽视了信息的完整性。与其他基于BLS的方法相比,本文方法更注重特征信息的利用,特别是混沌时间序列信息的利用。本文方法既考虑了混沌时间序列的时间特性,又最大程度地利用了演化信息。 为了进一步挖掘混沌系统的演化信息,提升预测精度,减少训练时间,提出一种基于最大信息挖掘广域学习系统的大规模混沌时间序列预测模型。通过四个大规模数据集实验得出如下结论: (1) 与深层神经网络相比,MIE-BLS具有快速训练的特点,能够有效地减少训练时间,为在大规模数据集上的应用提供了可能。 (2) 因为特征和增强层输出之间的层叠补偿了在传输过程中丢失的信息,本文方法更注重特征信息的利用,特别是混沌时间序列信息的利用,能够有效解决混沌时间序列预测问题。 (3) 本文方法既考虑了混沌时间序列的时间特性,又最大程度地利用了演化信息,有效地实现了充分的信息挖掘,提升了预测的精度。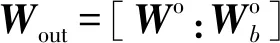
1.2 宽度学习系统
2 最大信息挖掘广域学习系统
2.1 MIE-BLS
2.2 最大程度利用信息
2.3 与DenseNet、HighwayNet和ResNet的异同
2.4 随机映射分析
3 实 验
3.1 数据集和实验方法
3.2 实验结果分析
4 结 语
