一种基于边缘形状特征的字符缺陷检测算法
2023-10-09夹尚丰余振军
孙 洋 孙 林* 夹尚丰 余振军
1(山东科技大学测绘科学与工程学院 山东 青岛 266590)
2(青岛星科瑞升信息科技有限公司 山东 青岛 266590)
0 引 言
工业上字符印刷缺陷的检测有着巨大的需求。字符在印刷中容易出现漏印、错印、遮挡等问题。目前大部分工业产品的检测主要是依靠人眼检测,这样的检测方法工厂要承担巨大的人工成本和管理成本,而且检测的精度和稳定性也难以得到有效的保证。快速、准确、自动检测印刷字符的缺陷,具有重要意义[1-3]。
随着工业智能化、自动化水平的提高,图像处理技术得到了快速的发展,工业上字符缺陷检测技术也有了很大的提高。
模板匹配技术由于其原理简单、适应性强,以及处理复杂场景的能力,被广泛应用于印刷品的缺陷检测中。模板匹配是使用预先定义的模板来搜索图像以找到匹配的目标。基于匹配特征的不同,用于匹配的模板可以分为多种类型。首先发展起来的模板匹配算法以灰度特征作为匹配对象。Brown[4]提出了平均绝对差算法,该算法匹配精度高,但运算量大,抗干扰性差。Barnea等[5]提出了序贯相似性检测算法,该算法通过设置阈值终止计算的策略,有效地减少了算法的处理时间。Zitová等[6]提出了归一化互相关匹配法,根据模板图像与目标图像的互相关值来确定匹配度。该算法抗噪声干扰能力强,但是受光照影响较大。后来发展起来的模板匹配算法以形状特征作为匹配对象,通过计算模板图像与目标图像形状相似度来进行匹配。Moravec[7]提出Moravec角点检测算法,通过计算灰度方差值来提取特征点,该算法计算过程简单,但误检测率高,算法运行速度较慢。Harris等[8]提出Harris角点检测算法,是对Moravec角点检测算法进行改进,克服了Moravec角点检测算法对边缘的敏感性,提高了算法的稳定性。以及Lowe[9]在1999年提出并在2004年完善总结的Sift角点检测法,这种算法在图像发生平移、旋转、缩放时都具有良好的适应性。但是Moravec、Harris和Sift等该类点特征都存在计算特征点过于复杂、运算速度较慢的问题。
针对上述算法受光照影响大、计算过程复杂等问题,本文提出一种基于边缘形状特征匹配的算法,并应用于字符的缺陷检测。算法首先通过提取最优描述字符的轮廓点,计算轮廓点梯度与待检测图像对应点梯度的点乘值作为相似性度量,然后根据字符轮廓点相似度来定位字符缺陷。由于本文采用的相似性度量不受遮挡、混乱、线性与非线性光照变化等情况的影响,所以在光照变化环境下依然可以快速准确地定位字符印刷缺陷。
1 建立轮廓点匹配模板
在图像中检测某一特定物体最基本的方法之一是模板匹配法,这种方法如今被广泛地应用在各类工业检测系统中,也是一种典型的机器视觉检测算法,这种方法原理简单、实现容易,但是该算法的计算量相对较大。因此,在不降低可靠性的情况下,减小计算量是关键。本文通过Sobel算子滤波后得到的梯度数据为基础,根据边缘连通域长度来确定最优的边缘分割阈值,通过阈值分割得到字符轮廓点信息,来建立轮廓点匹配模板,以此减少模板中点的数量。由于待检测图像中的目标角度是随机的,因此为了精确定位到目标位置,还应当确定适当的旋转角度步长。
1.1 边缘检测
为了得到模板字符轮廓点的梯度方向向量,首先要得到字符轮廓的边缘。由于Sobel算子可以得到较为精确的图像边缘,因此本文采用Sobel算子来提取图像的边缘。该算子包含水平和竖直两个方向的3×3矩阵的卷积因子,分别与原灰度图像进行卷积运算可以得到两个方向的亮度差分近似值。
(1)
(2)
式中:A代表原始灰度图像;Gx及Gy分别代表经水平和竖直两个方向边缘检测的图像灰度值。则该点灰度的大小为:
(3)
梯度方向θ为:
(4)
1.2 边缘分割阈值的确定
由于Sobel算子得到的图像边缘会受到噪声的影响,因此为了将属于字符轮廓的边缘与噪声或纹理引起的边缘区分开,本文在Sobel算子提取图像边缘的基础上,进一步在高曲率点分割边缘区域,根据边缘平均长度确定边缘分割阈值。
(5)
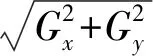
依次根据所有边缘梯度值从模板图像中提取大于该阈值的边缘经过非极大值抑制,然后在高曲率边缘点上分割边缘区域。将得到的字符边缘label值赋值为0,将背景label值赋值为-1。采用Two-Pass连通区域标记算法[10]对边缘二值图像进行处理。该算法是对分割后的边缘二值图像进行两遍扫描来确定连通区域。两遍扫描规则及步骤如下:
(1) 第一次扫描:从左到右、从上到下进行扫描,当图像像素label值为0时,则通过该像素的左邻像素和上邻像素label值进行判断。此时存在三种情况:当该像素的左邻像素和上邻像素label值均为-1时,则给该像素赋值一个新的label值,label值逐渐递加;当该像素的左邻像素和上邻像素label值有一个不为-1时,则将该位置处的label值赋值给该像素的label值;当该像素的左邻像素和上邻像素label值均不为-1时,则选取其中较小的label值赋值给该像素的label值。记录每个label值不为-1的像素点属于哪一个连通区域。
第一次扫描过程如图1所示。
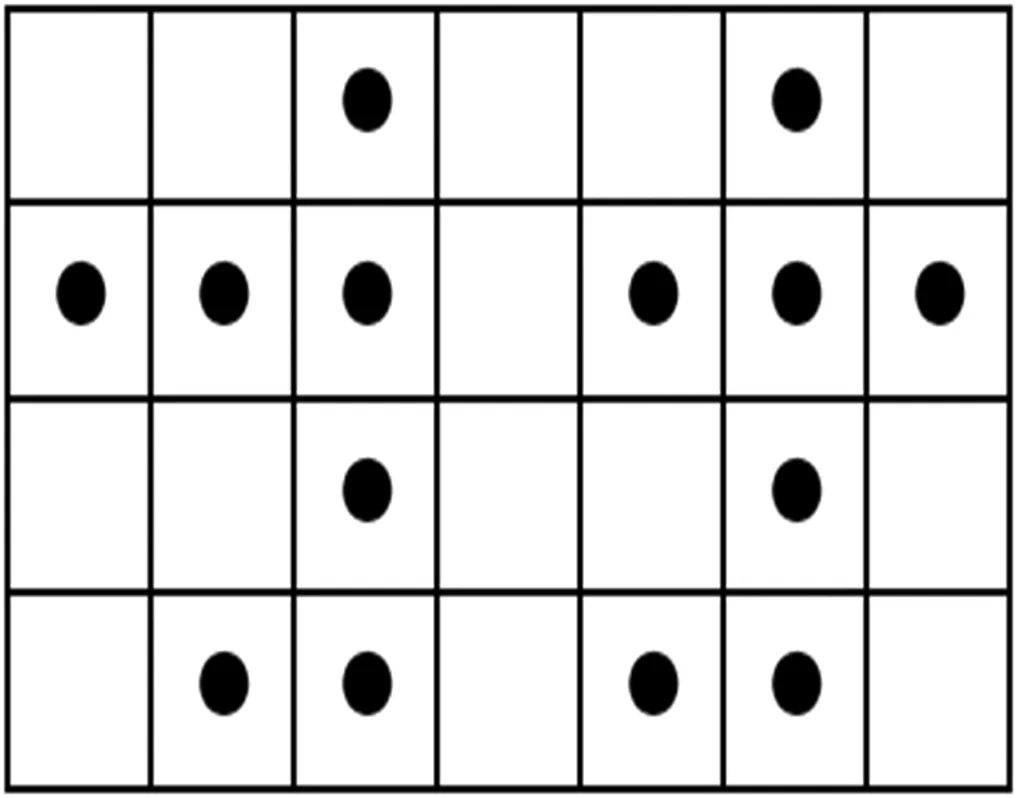
(a) 分割后的边缘二值图
(2) 第二次扫描:对于属于同一连通区域的像素点label值赋值为同属一个连通区域中最小的label值。完成扫描后,图像中具有相同label值的像素就组成了同一个连通区域。第二次扫描结果如图2所示。
经过如上连通区域标记算法来获取连通域个数,计算边缘总长度除以连通域的个数得到边缘平均长度。
(6)
式中:T表示边缘平均长度;L表示边缘总长度;N表示连通域的个数。因为通常属于对象的边缘段的长度较长,而属于图像噪声或纹理的边缘段的长度较短,故求取平均长度最大值对应的梯度幅值设为边缘分割阈值。Sobel算子提取的图像边缘及本文通过计算最优边缘分割阈值分割得到的边缘经过非极大值抑制得到的字符边缘示意图如图3所示。
根据图3可以看出Sobel算子由于受到噪声和纹理的影响,提取的边缘存在漏提和多提现象。而本文通过计算边缘连通域长度,确定最优的边缘分割阈值得到的字符边缘有效避免了噪声和纹理的影响,较好地保留了字符边缘形状特征,为接下来的边缘轮廓点匹配提供了有力的支撑。
1.3 模板旋转角度步长的确定
由于要检测的图像中的目标角度是随机的,因此为了定位到目标的精确位置,应当确定适当的旋转角度步长。本文根据余弦定理计算距模板中心最远的轮廓点绕模板中心旋转角度来求旋转角度步长。如图4所示,设点O为模板中心点,点A为最远轮廓点,点B为点A旋转后的点,设边长AB=1,OA=OB=a,由余弦定理求OA与OB夹角φ角。
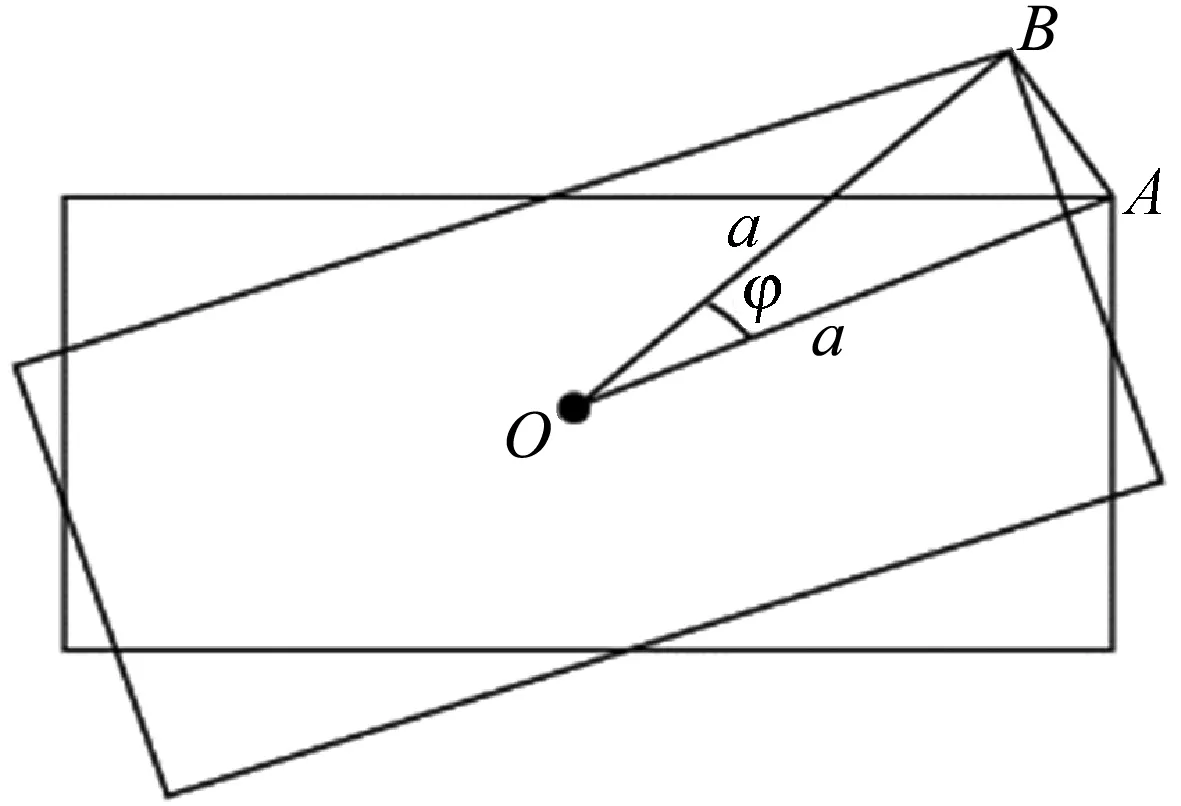
图4 旋转步长确定示意图
(7)
φ角为可保证模板旋转前后所对应的角度。为了避免匹配不上,旋转角度步长不宜设置过大,以模板轮廓图最远轮廓点距离模板中心点连线旋转2个像素对应的角度φ作为旋转步长。
2 相似性度量函数
在求得最佳边缘轮廓分割阈值后,利用得到的轮廓点坐标位置和归一化后的梯度方向向量制作模板,模板转换成由一系列字符轮廓点Pi=(Xi,Yi)T,i=1,2,…,n构成,对应于每个点求得归一化后的梯度方向向量di=(ti,ui)T。对于搜索图像使用Sobel算子滤波计算出每个点(X,Y)归一化后的梯度方向向量ex,y=(vx,y,wx,y)T。
在搜索图上遍历,根据模板字符轮廓点相对重心的位置,采取模板轮廓点和搜索图边缘点向量转换成单位向量后进行匹配。光照变化虽然会影响边缘点梯度大小,但是不会改变梯度的方向。
相似度量函数为:
(8)
在搜索图上每一个点上遍历完以后,根据搜索图上匹配度最大的点确定字符所在位置。
3 加速措施
由于遍历整幅搜索图来寻找目标耗时较多,虽然本文在搜索图上遍历过程中,只计算模板轮廓点和搜索图相对应位置点的匹配度,已经大大减少了计算量,但是当搜索图像较大时,计算量依旧很大,因此为了进一步加快算法处理速度,减少计算量。本文采取提前结束非可能目标位置的计算并结合图像金字塔的策略。
3.1 停止标准
由于在搜索图字符以外区域匹配度得分较低,因此可以采取一定的策略,在非目标点提前结束计算,进行下一个位置处的匹配。这样可以有效加快算法处理速度,减少遍历过程中的计算量,从而使算法达到工业检测中的实时性要求。根据相似性度量函数,我们可以得到相似度量的部分和公式为:
(9)
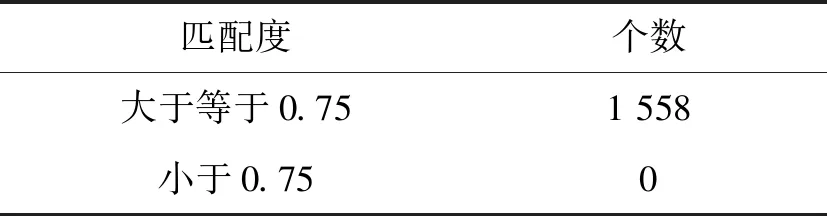
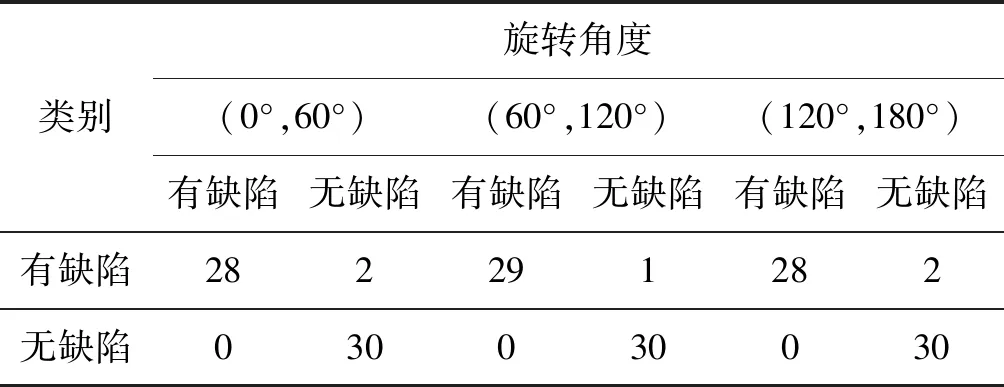
因为向量di和ex,y是归一化后的梯度方向向量,所以由公式可知,前j项的和小于j/n,那么剩余n-j项的和小于(n-j)/n=1-j/n,所以当部分和满足Sj Sj 式中:f=(1-gSmin)/(1-Smin),在这里,Smin设置为0.7,g设置为0.75。 采取设置阈值终止计算的策略可以减少算法运行时间,但是这并不会改变算法的复杂度。其算法的复杂度为O(whn),其中:w和h是搜索图像的宽和高;n是模板中点的数量。因此采用由粗到精的搜索策略可以有效降低算法的复杂度,即通过降低图像的分辨率得到一个大概的位置,再在高分辨率下得到精确位置。图像金字塔可以通过下采样获得一幅图像一系列高分辨率和低分辨率图像的集合。 图像金字塔是一个图像序列。一幅图像金字塔是对原始图像进行滤波,从而得到一系列不同尺度的影像,按照分辨率的大小根据金字塔形状进行排列。本文采用的是Gaussian金字塔。是通过对待处理图像梯次下采样获得一系列图像的集合,金字塔的底部是待处理图像的高分辨率表示,金字塔的顶部是待处理图像的低分辨率表示。以Lena图像为例的Gaussian金字塔图像序列如图5所示。 图5 Lena图像的Gaussian金字塔图像序列 本文根据边缘轮廓点的数量设置阈值来确定金字塔层数[12]。根据大量样本测试,对于大多数字符而言,当其图像金字塔在某层轮廓点数在100个左右,再高一层则小于此值时,字符图像在该层仍有较完整的轮廓特征点,我们就将该层定为图像金字塔最高层。 表1 轮廓点匹配度 图6 搜索图原图 模板字符经阈值分割以后,得到的边缘轮廓点个数总共为1 558个,在搜索图上匹配到目标位置后,匹配到的字符轮廓点中,匹配度大于等于0.75的,占了100%,匹配度小于0.75的,占了0%,说明本文采用阈值分割得到的边缘轮廓点进行匹配的算法匹配效果良好。 在轮廓匹配之后,每个轮廓点都有一个得分。在缺陷提取的过程中,采用粗筛选和精筛选相结合的方式来寻找缺陷点,基于缺陷点填充求最小外接矩形的方法来提取缺陷,具体流程如下所述。 (1) 粗筛选:将搜索图字符轮廓点得分大于等于0.75的点剔除,将得分小于0.75的点保留。 (2) 精筛选:考虑到噪点的影响,经过粗筛选得到的轮廓点可能不是真正的缺陷点,因此需要进一步筛选。考虑到噪点一般是孤立存在的,故在粗筛选得到的点的12×12区域进行遍历,如果该区域有超过19个得分小于0.75的点,则认为该点是真正的缺陷点。 (3) 基于缺陷点填充:在得到真正的缺陷点以后,因为缺陷点是离散存在的,不方便确定缺陷边界坐标。因此为了定位字符缺陷所在的区域,将缺陷点周围12×12区域内灰度值填充为255,其他位置灰度值设置为0。然后寻找二值图轮廓所在最小外接矩形,即为字符缺陷区域。 图7为常见的印刷品缺陷中漏印情况,白色方框标识区域为采集图像过程中,亮度发生变化。采用差影法会对缺陷造成误判。这主要是因为,差影法是将待检测图像与模板图像配准后进行剪影操作,最后可以根据检测结果图像灰度值不为0的点判断为缺陷点。其数学表达式为: 图7 印刷品缺陷图像实例 r(i,j)=|f(i,j)-g(i,j)| (10) 式中:f(i,j)为模板图像像素点(i,j)的灰度值;g(i,j)为搜索图像的目标区域像素点(i,j)的灰度值;r(i,j)为模板图像和搜索图像相减后的灰度值。 图8为差影法和本文算法对印刷品缺陷图像检测出的缺陷点个数曲线图,其中横坐标表示缺陷图像列坐标,纵坐标表示缺陷点个数。 可以看出,差影法虽然在字符漏印区域检测到的缺陷点比较集中,个数也比较多,但是在图像第100列到第200列光照变化区域检测出的缺陷区域也比较集中,并且检测出的缺陷点个数较多,均大于50个。从图9(a)可以看出差影法因采集图像光照发生变化,对缺陷造成误判,把光照变化区域检测为缺陷,导致检测失败。 (a) 差影法 (b) 本文算法 本文算法对印刷品缺陷图像检测出来的缺陷主要集中在字符漏印区域,还有几列在图像第100列到第200列光照变化区域,但是由于这几列是离散存在的,并且缺陷点个数均小于10,因此可以通过精确筛选给去除。从图9(b)可以清晰地看出本文算法在采集图像光照发生变化时可以正确地检测到缺陷,并准确地标记缺陷区域,没有因采集图像光照发生变化而导致检测失败,说明本文算法在复杂光照条件下对印刷品缺陷检测精度要优于差影法。 为了测试算法的稳定性,测试当待检测印刷图像出现典型的漏印、遮挡等缺陷在旋转、线性光照变化、非线性光照变化下,算法检测缺陷的效果。 图10(a)、图10(d)、图10(g)是三组标准印刷图像,图10(b)、图10(e)、图10(h)为这三组标准印刷图像出现字符漏印时,在旋转、线性光照变化、非线性光照变化下的图像,图10(c)、图10(f)、图10(i)为这三组标准印刷图像出现字符遮挡时,在旋转、线性光照变化、非线性光照变化下的图像。可以看出当待检测印刷图像出现典型的漏印、遮挡等缺陷在旋转、线性光照变化、非线性光照变化下,仍然可以准确定位字符缺陷。 (a) (b) (c) 为了测试算法在采集不同角度的图像下算法的准确率,选取180组光照发生变化的印刷品图像,分为三组,每组60幅,旋转角度范围分别在(0°,60°)、(60°,120°)、(120°,180°),每组图像无缺陷和有缺陷印刷品各30幅。 为了验证本文算法在复杂光照下,采集的旋转不同角度的图像进行测试的效果,可由真正率(Pse)、真负率(Psp)和准确率(Pac)进行评价,分别定义为: (11) (12) (13) 式中:Pse为有缺陷图像识别的准确率;Psp为无缺陷图像识别的准确率;Pac为旋转不同角度下印刷品缺陷总的准确率;PT为有缺陷图像被正确识别的数量;NF为有缺陷图像被错误识别的数量;PF为无缺陷图像被错误识别的数量;NT为无缺陷图像被正确识别的数量。 缺陷检测实验后得到的混合矩阵见表2。根据表2中的检测结果以及式(11)-式(13),可以得到真正率、真负率和准确率,结果见表3。 表2 复杂光照下旋转不同角度的印刷品缺陷 表3 复杂光照下旋转不同角度的印刷品缺陷 由表3可知在采集不同角度的图像下无缺陷的图像被错误识别为有缺陷图像的数量为0,真负率达到100%,真正率达到93%以上,准确率达到96%以上,说明本文算法在复杂光照条件下匹配效果良好,并且基于缺陷点填充求最小外接矩形的方法进行缺陷检测是可行的。在表2中,有5幅有缺陷的图像被判断错误,这是由于本文对缺陷进行检测是基于字符轮廓点匹配度进行判断,而这5幅图像的缺陷是在字符轮廓内部,所以导致检测失败。 工业检测一般要达到实时性要求,因此对算法的处理时间要求比较高,一般要求能达到毫秒级别。实验测试计算机处理器为Inter Core i5-9500 3.00 GHz,8 GB内存,在Windows 10环境下,用VS2010+OpenCV编程实现。其中模板图像大小为309 pixel×64 pixel,随机采集100幅测试图像,测试图像大小均为1 024 pixel×768 pixel。本文对本文算法与经典的归一化互相关系数匹配算法、基于形状模板匹配算法[13-17]进行比较,结果如表4所示。 表4 算法匹配时间 单位:ms 可以看出本文算法匹配速度可以达到毫秒级别,能满足工业检测的实时性要求,并且本文算法在匹配耗时上要少于经典的归一化互相关系数匹配算法和基于形状模板匹配算法,从平均匹配时间上来看大概是归一化互相关系数匹配算法的1/6,基于形状模板匹配算法的1/3。 本文提出一种适用于工业检测的基于边缘形状特征的字符缺陷检测算法。由于本文采用的相似性度量不受遮挡、混乱、线性光照变化、非线性光照变化等情况的影响,所以在复杂光照条件下依然可以准确地定位到目标位置。在定位到目标位置后,根据轮廓点的匹配度来寻找缺陷点,基于缺陷点填充求最小外接矩形的方法来提取缺陷,可以有效避免由于光照的变化,影响对缺陷的判断。由于本文采用图像金字塔算法和通过阈值判断提前结束的搜索策略,可以满足工业检测实时性要求。 本文算法存在着对个别字符内部缺陷检测效果不理想的情况,在下一阶段,根据字符轮廓判断轮廓内部的缺陷是研究的重点。3.2 图像金字塔

4 实验结果与分析
4.1 轮廓匹配
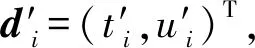

4.2 缺陷检测


4.3 算法性能测试



5 结 语
