基于改进HED网络的重叠葡萄果粒轮廓特征提取
2023-10-09苗玉彬
张 舒 苗玉彬
(上海交通大学机械与动力工程学院 上海 200240)
0 引 言
葡萄果粒大小和糖含量等果实品质是每天生长积累的结果,精细确定果实发育关键阶段的灌溉指标,合理调控果实在不同生长阶段对不同程度水分胁迫的反应,可以调控树体营养生长与生殖生长之间的平衡,获得较高的经济产量和品质。植物水势、蒸腾速率、液流、茎干直径和果粒大小变化等果树需水信号是指导灌溉的基础指标,其中通过视觉测量实时获取果粒几何尺寸和昼夜变化规律对于生产操作更有实践意义[1-3]。但由于在自然场景中葡萄果穗普遍存在果粒重叠现象,如何准确检测边缘轮廓成为亟待解决的问题。
利用视觉测量技术实时获取葡萄果粒的几何尺寸和昼夜变化规律对灌溉等生产操作具有很强的实践指导意义[1-3]。但由于自然场景中葡萄果穗普遍存在果粒重叠现象,准确检测果粒边缘轮廓成为亟待解决的难题。在果粒的轮廓检测和分割问题上,国内外相关文献基于传统机器视觉技术进行了若干研究并取得了一定成果。
针对非完整果粒的轮廓检测和分割问题,国内外相关文献基于传统机器视觉技术进行了若干研究并取得了一定成果。金燕[4]利用改进的Hough变换对葡萄果粒进行分割,但精度较低,且在葡萄重叠的情况下容易漏检。Arefi等[5]利用分水岭算法对重叠番茄进行分割,识别准确率达到96.36%,但易造成过分割。谢忠红等[6]提出了基于凹点搜索的重叠果粒目标定位和检测方法,但多果粘连重叠时会造成轮廓识别丢失。项荣等[7]提出了一种基于边缘曲率分析的重叠番茄识别方法,对轻微遮挡的重叠番茄识别准确率达到90.9%,但是当果实遮挡率较高时,识别准确率降低。王巧华等[8]利用曲率角、突变点等特征提取葡萄果粒大小尺寸。总之,传统机器视觉方法虽然在一定程度上对葡萄、番茄等重叠果实的分割处理取得了较好的效果,但仍具有以下局限性:(1) 传统果粒分割过程通常是多阶段的,需进行繁冗的前、后处理步骤,效率较低。由于大多数前、后处理步骤不具有普适性,当环境参数或果实颜色发生变化时,处理流程中的相关参数需要反复进行微调以达到最佳效果。(2) 复杂背景下,常规检测算法对图像伪边缘、噪点抵抗能力较弱,果实的准确测量易受干扰。(3) 对存在重叠现象的果实而言,重叠部分的边缘通常难以检测,结果可能存在边缘不明显、不连续或缺失等问题。
近年来,神经网络和深度学习发展迅速,在图像处理上显现了巨大的优越性。通过神经网络对目标物体的轮廓进行高维度特征提取,使复杂条件下重叠果实的轮廓特征提取成为可能。目前,基于深度学习的边缘检测算法主要分为两类,一类是基于局部区域的轮廓检测算法,标志性的算法如N4-field[9]、DeepEdge[10]和DeepContour[11]等。其核心思想是以像素为中心提取像素块,通过CNN提取特征,将特征与真实轮廓比较并输出像素块对应像素为轮廓的概率。上述算法能够较好地识别物体轮廓,但由于存在局部区域采样,计算时间较长,也增加了空间成本。另一类是端到端的轮廓检测算法,代表性的算法有HED[12]、RCF[13]、CEDN[14]等。其主要思想是利用CNN直接预测图像中每个像素点是否为轮廓的概率,与第一类算法相比,流程简单高效,检测精度较高。
本文在HED网络的基础上,首先改进网络结构使其融合更多卷积层的输出,改进原有损失函数以提升轮廓检测的精度和完整度,减少结果中噪点与伪边缘的干扰。同时还对不同光照条件的葡萄果实分别进行轮廓检测实验,以验证算法轮廓提取的有效性。
1 本文算法与实现
HED网络通过自动学习丰富的图像层次来解决边缘检测中产生的歧义问题,它对图像中每个像素进行标记,能够对整幅图像进行端到端的训练和预测。HED网络能检测出图像中绝大多数边缘,但检测出的边缘较厚、存在毛刺现象,对于图像颜色对比度较低的物体边缘还会产生漏检现象,影响了后续的葡萄表型参数测量精度。针对上述问题,考虑对HED网络的各个部分进行针对性改进:(1) 引入更多侧输出网络结构,融合更多不同层次的边缘预测图,从而更有利于提取细节特征;(2) 通过引入Dice损失函数[16]改进原有加权交叉熵损失函数,从而有效地提高边缘清晰度;(3) 利用多尺度边缘预测提高轮廓的准确度。算法的流程如图1所示。
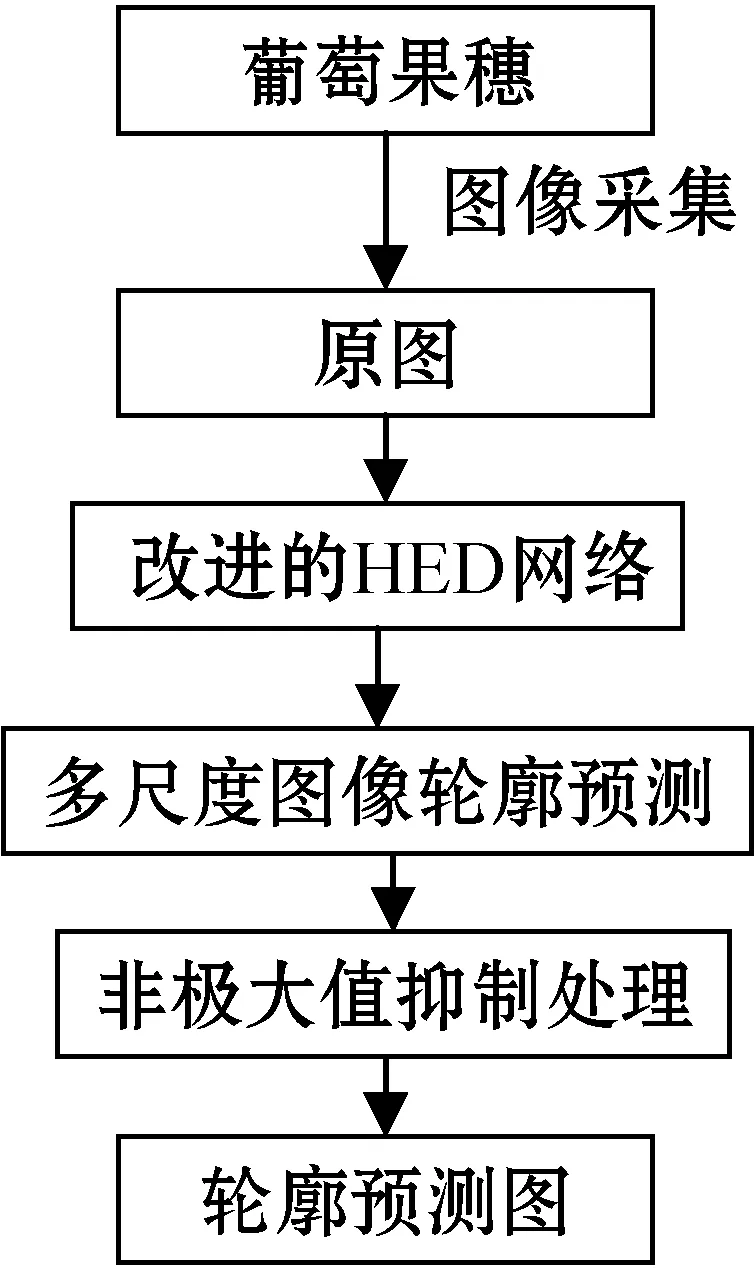
图1 轮廓检测流程
1.1 网络结构优化
如图2所示,本文HED模型的主干网络以VGG16的主干网络为基础,共有13个卷积层,分为五个阶段,其中第一、二阶段各有两个卷积层,最后三个阶段各有三个卷积层,每个阶段的卷积核大小均为3×3。每个阶段中最后一个卷积层引入了2×2最大池化层,由于池化层的下采样作用,图像每经过一个阶段,其面积缩小为原图像的四分之一,所以在后续的图像融合中,需要对每个阶段的侧输出图像进行上采样,以获得与原图像相同大小的边缘预测图。侧输出负责预测图像的边缘图,各个阶段的边缘图进行上采样后进行融合以得到最终的边缘图。
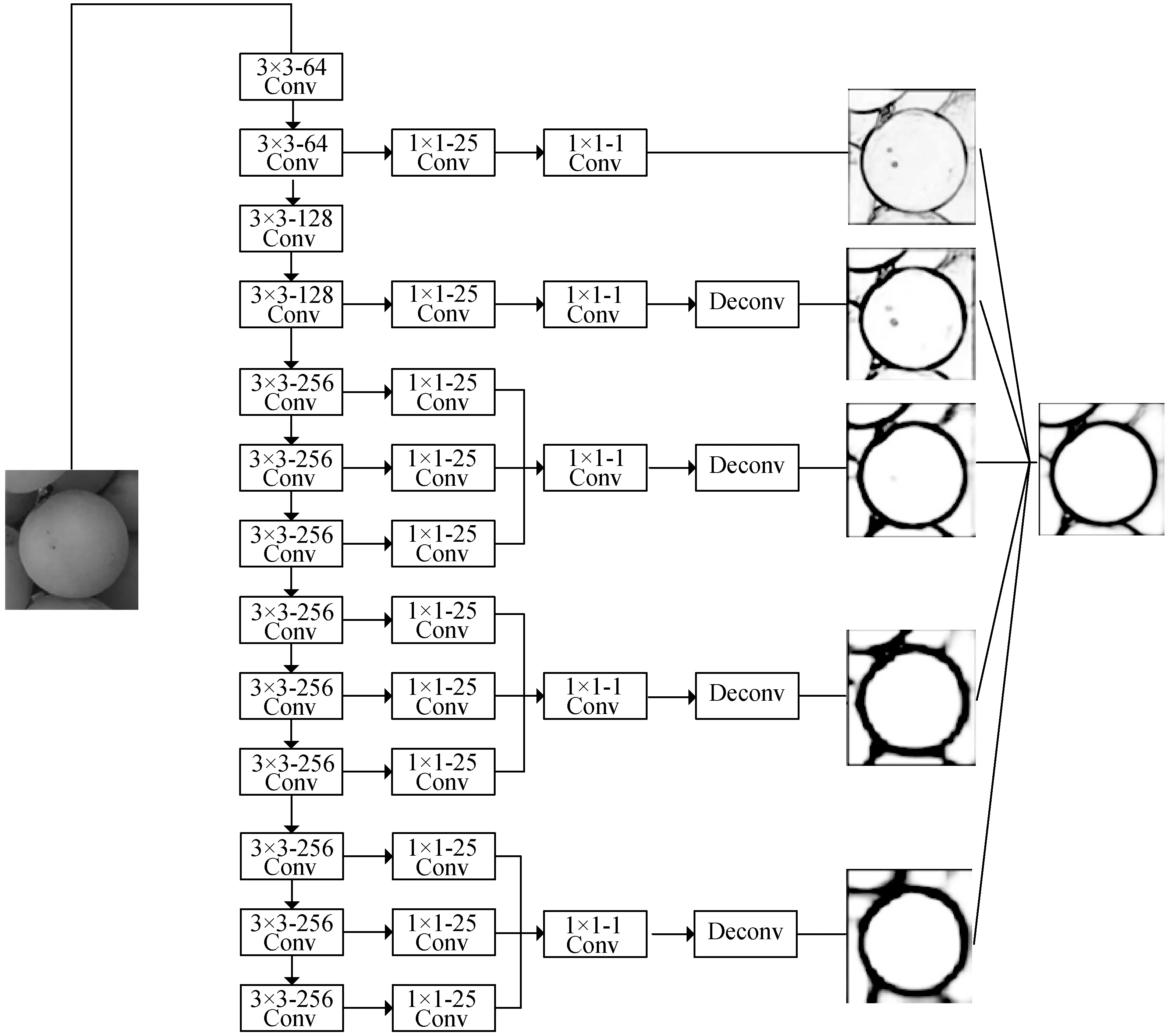
图2 改进的HED网络结构
改进后的模型与常规HED网络不同的地方是:常规HED仅在每个阶段的最后一个卷积层引出侧输出层,这种结构没有充分利用其他卷积层含有的边缘信息。为此,本文将第三阶段至第五阶段中所有的卷积层均连入侧输出层,以充分利用神经网络中的高维度特征图。以第三阶段为例,每个卷积层分别引出侧输出层,卷积核尺寸为1×1,通道深度为25。每个阶段产生的特征图叠加后连接1×1-1的卷积层。上采样采用双线性插值方法将预测图还原到原图大小,即得到该阶段的边缘预测图。将五个阶段的特征图进行融合可以输出最终的边缘图。
1.2 损失函数优化
在一般的二分类问题中,通常使用交叉熵函数作为卷积神经网络的损失函数。由于图像的绝大部分像素都属于非边缘像素,边缘/非边缘像素点的分布非常不平衡[17],因此一般的交叉熵损失函数难以训练模型。为解决此问题,HED网络使用了加权交叉熵损失函数:
(1)
式中:Y+和Y-分别表示图片中边缘像素的集合与非边缘像素的集合;β=|Y-|/|Y+|,1-β=|Y+|/|Y|;X为输入的图片;Pr(yj|X;W,w)由像素点j经过Sigmoid函数(σ(·))计算得到。
加权交叉熵损失函数中的权重系数β能够解决图片像素分布不平衡所带来的训练不收敛问题,但β的引入会造成预测结果中边缘不清晰。为了解决权重系数引起的矛盾,这里引入Dice系数作为损失函数:
(2)
式中:G是图像的实际边缘图;P是预测图;pi和gi分别表示在预测图和实际边缘图中第i点像素的像素值。
#Dice损失函数实现如下:
smooth=1
inputs=torch.sigmoid(preds)
input_flat=inputs.view(-1)
target_flat=edges.view(-1)
intersecion=input_flat*target_flat
unionsection=input_flat.pow(2).sum()+target_flat.pow(2).sum()+smooth
dice_loss=unionsection/(2*intersecion.sum()+smooth)
Dice系数是边缘预测图和实际边缘图相似性的度量,其作为损失函数时,比较的是边缘像素预测值与实际值的相似度大小,并进一步最小化它们在训练集上的差距。因而使用Dice系数时,图片像素分布的不平衡问题得以解决,模型在收敛的同时能预测更加细薄、准确的边界。在模型的实际训练中,将加权交叉熵损失函数和Dice损失函数结合可以得到更好的效果:
L(P,G)=αLD(P,G)+(1-α)Lw(P,G)
(3)
式中:LD(P,G)是Dice损失函数;Lw(P,G)是加权交叉熵损失函数。
1.3 多尺度轮廓预测
葡萄果实在监测图像中通常以小尺度的形式存在,为了更精确地识别葡萄果实轮廓,在模型测试阶段使用了图像金字塔以增强模型在不同尺度下对葡萄轮廓特征的表达能力。具体来说,将图片输入网络之前通过双线性插值方式调整图像的大小,从而构建一个图像金字塔,每幅图像分别输入到模型中进行独立的预测。然后使用双线性插值将所有得到的边缘概率图通过上采样调整为原始图像的大小。最后将这些图像进行融合得到最终预测图,如图3所示。
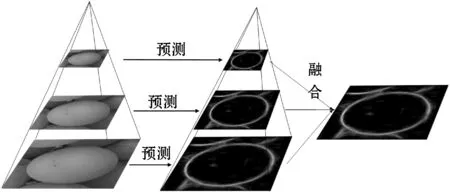
图3 多尺度轮廓预测
多尺度轮廓预测代码如下:
scale=[0.5,1,1.5]
for k in range(0,len(scale)):
im=cv2.resize(image_in,None,fx=scale[k],fy=scale[k],interpolation=cv2.INTER_LINEAR)
im=im.transpose((2,0,1))results=model(torch.unsqueeze(torch.from_numpy(im).cuda(),0))
result=torch.squeeze(results[1].detach()).cpu().numpy()
fuse=cv2.resize(result,(W,H),interpolation=cv2.INTER_LINEAR)
multi_fuse+=fuse
multi_fuse=multi_fuse/len(scale)
2 实验设计
2.1 实验数据的采集
实验于2019年在上海交通大学现代农业工程训练中心大棚(31°11′N,121°29′E)进行。图像采集选用OLYMPUS SP-510UZ相机, 其CCD感光尺寸为1/2.5英寸,具有定时拍照功能。系统采用高频环形荧光光源以获得高对比度清晰图像,并采用时间继电器控制光源开关,以减少光源持续照明对葡萄生长可能产生的影响。
选择的供试葡萄品种为阳光玫瑰。图4(a)、图4(b)和图4(c)分别为侧光、顺光和逆光条件下的膨大期阳光玫瑰果实照片。测试时在顺光、逆光、侧光三种条件下分别拍摄50幅照片,图像分辨率为3 072像素×2 304像素(相机默认分辨率),图像格式为三通道RGB。在顺光和逆光条件下,由于光照条件不佳,图像中分布有椒盐噪声。

(a) 阳光玫瑰(侧光) (b) 阳光玫瑰(顺光) (c) 阳光玫瑰(逆光)
2.2 实验运行平台
训练测试所用计算机的主要配置为Intel Core(TM) i5-7300HQ CPU@2.50 GHz、4 GB显存的GPU GeForce GTX 1050Ti和16 GB RAM。程序由Python 3.6编写并调用CUDA 10.1、Cudnn 7.5.1、OPENCV运行。
模型使用VGG16作为主干网络。优化器采用随机梯度下降法,优化器的Mini-Batch过大会降低训练速度,并且GPU资源也无法负担,Mini-Batch过小则会导致收敛困难,经过参数调优,将Mini-Batch设置为4。为了加快训练速度并防止过拟合,学习率(learning rate)设置1E-6,动量(Momentum)设置为0.9,权重衰减值(decay)设置2E-4,每迭代5 000次学习率减小10倍[12]。通过比较不同α下模型的准确率,将损失函数中的α设为0.3。
2.3 样本采集和处理
采集不同背景、环境条件下的单粒阳光玫瑰葡萄照片共100幅,相机默认拍摄像素为3 072像素×2 304像素。为了提高模型训练的效率,参照BSDS-500图像分割数据集的尺寸,将图片统一缩小为384像素×544像素,利用人工方式对葡萄轮廓进行标记,并生成样本的实际轮廓照片,如图5所示。
为了扩充训练样本,将葡萄分割数据集与伯克利分割数据集BSDS-500[18]合并,共600幅图片,其中:400幅用于训练模型;100幅用于验证模型;100幅用于测试模型。为避免训练过程中出现过拟合对数据集进行了增强,将400幅图片通过旋转、缩放、翻转的方式扩充96倍,具体方法是每隔22.5°旋转一次、放大1.5倍、缩小1倍、左右镜像翻转。增强后的数据集达到38 400幅图片。
2.4 模型测试与评估
最终模型一共训练了25 000次,耗时27 h,其损失值变化如图6所示。可以看出模型在前2 000次迭代中损失值下降较快,收敛迅速。在10 000次迭代后损失值趋于稳定。在模型训练中,迭代次数增大模型的损失值会降低,但过多的训练可能会导致模型过拟合,需对训练得到的模型进行评估。本文采用全局最佳(ODS)、单图最佳(OIS)、平均精度(AP)作为图像边缘检测指标,其中全局最佳指所有测试集图片采用同一个固定阈值时的检测得分;单图最佳指对测试集中每一幅图片采用最佳阈值时的检测得分。边缘检测前,需先对边缘预测图进行非极大值抑制(NMS)[19],然后利用Edge box[20]进行指标测试。
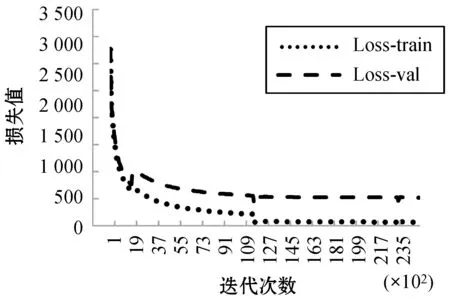
图6 损失值随迭代次数的变化曲线
3 实验结果与分析
3.1 不同网络结构的检测结果对比
为了对比原始HED网络结构与改进HED网络结构的边缘检测效果,在测试集上分别进行检测,测试指标为ODS、OIS与AP。为了控制变量,网络均采用优化的损失函数,参数α设定为0.6。对边缘进行细化处理。检测结果如表1所示。可以看出,改进HED结构在三项指标评分上均高于原始模型结构,其中:ODS提高了0.02;OIS提高了0.015。AP提高了0.003。改进模型的精度得到了一定提升。

表1 不同网络结构检测结果对比
3.2 损失函数的参数寻优
模型训练完成后需要对其参数进行调整,以提高模型性能。本节将ODS与OIS作为模型参数评价指标,比较损失函数不同α参数下模型的性能,以获得最优模型。
由图7可知,当α=0时,融合损失函数损失退化为加权交叉熵损失函数。当α在0~0.6范围内增大时,模型准确率随之上升。当α>0.6后,模型精度反而下降。损失函数参数α=0.6时,模型的ODS、OIS和AP指标分别达到0.801、0.817和0.817,模型表现最好。

图7 不同α参数对应的模型性能变化
3.3 实际效果检验

(4)
(5)
(6)
式中:X为模型输出的轮廓预测图;Y为图像的实际轮廓图;TP为果粒像素正确划分的个数;FN为果粒像素被错误划分为背景像素的个数;Count(X)为模型输出的轮廓预测图中边缘像素总个数。本文利用人工标记方法对葡萄轮廓进行评估。
3.3.1不同光照角度的检测对比实验
自然环境中光照条件变化多样,会对葡萄边缘检测的效果产生影响。为了探究葡萄边缘检测的最佳光照条件,本节实验将拍摄葡萄时的光照角度作为控制变量,比较在侧光、顺光、逆光下不同算法的边缘检测效果。本文取侧光、顺光、逆光条件下的葡萄图像各60幅,总计180幅图像,研究对比不同光照条件对算法检测效果的影响,如图8所示。

(a) 原图
可以看出,侧光下葡萄果粒边缘清晰易分,表面光照均匀,边缘检测比较容易。逆光条件下,果粒表面光照强度较弱,边缘比较模糊,重叠部分的边缘难以用肉眼分辨。顺光条件下,反光导致果粒表面部分区域形成白色亮斑,部分边缘与背景颜色相近,难以区分。
由图8可以看出,本文算法检测出的重叠葡萄边缘锐利显著,侧光条件下轮廓完整性较高,逆光和顺光条件下未遮挡葡萄果粒轮廓识别完整,但内部被遮挡时果粒轮廓存在一定缺失。Canny算法检测出的葡萄轮廓锐利,缺点是会引入较多噪点和伪边缘,在顺光和逆光环境下噪声更加明显。常规HED算法能够基本检测出不同光照条件下的葡萄轮廓,缺点是边缘不清晰、边界丰厚,对后续表型测量的准确性造成影响。DeepEdge算法检出结果存在较多轮廓丢失现象。
由表2可以看出,本文算法的Dice系数高于其他算法0.06以上,查全率高于其他算法0.02以上。不同光照条件下模型预测葡萄轮廓的冗余率比其他算法低2百分点至19百分点。在侧光条件下,不同算法的Dice系数和查全率高于在逆光和顺光条件下的检测结果。
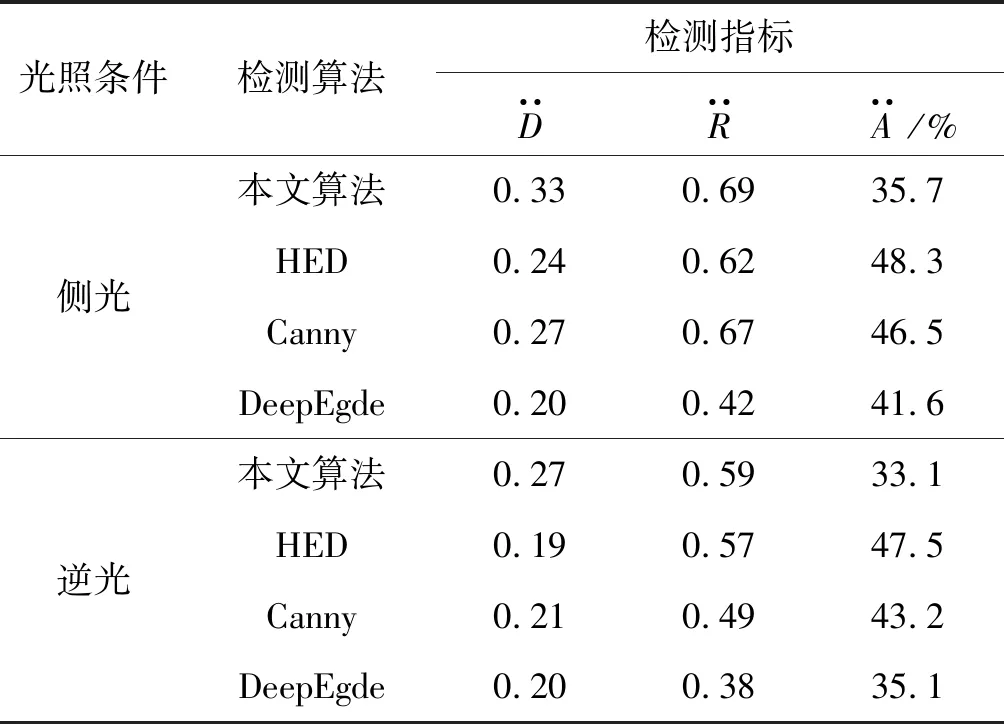
表2 四种算法对不同光照条件下葡萄的实验结果
3.3.2果实生长速率监测
葡萄生长周期中存在两个快速生长期,这两个时期是果实发育的关键时期。研究表明果实第一次快速生长期的水分亏缺会造成果实品质和产量的下降,且这种影响即使在后期进行充分灌水也是不可恢复的;而过多的水分供给又容易造成新梢的过旺生长,对果实的膨大不利[23]。葡萄果实生长带来的投影面积变化趋势能够反映葡萄的生长状态和阶段,通过监测果粒面积变化可以为灌溉时机的选择提供依据。本文以阳光玫瑰为例,研究检测其果实生长过程中的面积变化。对封闭的葡萄果实轮廓,采用区域生长法计算轮廓内部像素个数。若存在轮廓不连续的情况,则利用人工标记的方式在轮廓上选取至少5个像素点,并利用最小二乘椭圆拟合算法对缺失轮廓部分进行拟合,再利用区域生长法计算果实投影面积。
测试获取的阳光玫瑰葡萄花后13天至成熟期的葡萄果实面积变化曲线如图9所示。可以看出果粒大小变化规律呈现双“S”曲线,测量值的变化趋势基本符合实际值。从花后到硬核期30天果实增长速度较快,随后变慢,从花后50天开始再次快速生长,真实反映了果实的两个快速生长期。

图9 葡萄生长过程中果粒大小变化
4 结 语
1) 本文提出一种改进的HED检测模型,通过在网络中引入更多的侧输出,融合更多特征图提高检测精度,引入Dice系数改进损失函数,提升边缘图的质量,算法获取了更高质量、更完整的葡萄边缘轮廓图。模型在验证集上ODS和OIS分别达到0.801和0.817。
2) 与Canny、HED和DeepEdge算法在不同光照条件下的检测结果相比,改进后算法的Dice系数高于其他算法近5百分点,查全率高于其他算法近5百分点。在复杂背景下,算法轮廓检测的冗余率更低,产生的葡萄轮廓预测图含有的非目标轮廓或噪声数量更少,对复杂背景下的重叠葡萄检测优势较为明显。
3) 对阳光玫瑰葡萄果粒投影面积进行了连续的生长监测,生长曲线符合双“S”型规律。本文研究成果为有效监测葡萄生长阶段、实现准确灌溉提供了参考依据。
