基于DBNET与CRNN-CTC的自然环境文字识别系统
2023-10-09宁初明韩寿松李华莹
郭 浩 宁初明 韩寿松 李华莹
1(六六四〇七部队 北京 100089)
2(军事科学院系统工程研究院 北京 100020)
3(陆军装甲兵学院车辆工程系 北京 100071)
0 引 言
当前,OCR技术在生活中广泛使用,并能以较高正确率识别身份证、银行卡、表格单据,为人们带来了很大的便利,同时该技术在军队信息化建设中亦存有较高的使用价值。在诸如文稿数字化保存、单据记录、装备设备铭牌识别、故障研究记录表格自动录入等领域可发挥重要作用,极大节约人力成本。其准确率的进一步提升可使人工纠错负担显著减轻,意义重大。OCR技术的技术设想早于计算机技术的出现,早在1929年,德国科学家Tausheck首先提出了OCR概念。第一套可用OCR软件是由IBM于20世纪60年代早期开发的IBM1418,但仅能识别所指定字体的数字、英文字母及部分符号[1]。随后20世纪60年代中期至70年代初期,日本东芝公司推出了基于手写体数字识别的邮政编码识别信函自动分拣系统,在手写体识别上分拣率达到92%~93%,开始了成熟的商业应用[1]。在之后一个阶段的发展中,OCR技术着力解决图像质量较低的文档与大字符集识别如多语种(如中英文)混合识别的问题,并在固定文档的识别中取得了不错的效果。而国内的OCR技术受限于计算机发展程度及中文OCR的研究难度问题,起步较晚,且发展较慢[2]。在1989年,清华大学成功推出了国内第一套中文OCR系统——清华文通TH-OCR1.0版本[2],使得印刷体汉字识别趋近于成熟,并成功走向市场。虽然这些技术都取得了一定的商业应用,但依据原理,传统OCR技术通过烦琐的文档倾斜校正、行列切分、字切分,特征提取与匹配等流程进行文档的字符级别识别,有着识别率低下,对视角、光源甚至字体要求苛刻的问题,使得应用局限于扫描文档,很难应用于相机拍摄的自然环境文字识别。尤其自然环境中存在凸凹体文字、弧形排列、字体缺损等问题,更是传统OCR技术所难以解决的。自2012年AlexNet[3]的提出使得深度学习技术取得突破以来,当前研究广泛尝试采用深度学习技术直接对自然环境文字进行识别,取得了在准确率远优于传统OCR技术的效果,但当前主流文本区域分割网络如EAST[4]网络仍存在有计算量较大,需要多次非极大抑制算法支持等问题,同时轻量的端到端网络如FOTS[4]存在有较大的精度损失问题,这些问题均限制了深度学习在自然环境OCR中的进一步应用。本文中使用DBNET[4]与CRNN-CTC[5]复合二阶段方法进行自然环境下的字符级别文本识别,仅需两阶段处理即可在多视角、复杂光源下使用,在高准确率的同时保证实时性,最后通过Flask高效后端框架、Celery高效消息队列,并结合Layui前端框架实现了基于Python原生的实用化OCR识别系统。
1 DBNET网络结构与损失函数
在两阶段的深度学习方法中,首先采用文本区域分割网络将图像中的有文字区域与无文字区域分割,随后采用基于卷积神经网络(Convolutional Neural Networks, CNN)与循环神经网络(Recurrent Neural Network, RNN)结合的CRNN网络,并以连接时态分类(Connectionist Temporal Classification,CTC)编码形式输出,通过分配识别区域、检测字符这两个过程,并交由两类特定网络处理,从而提高了识别准确率。
DBNET是当前最为高效的图像文本区域分割网络之一,分割实时率强且准确高,在一般的语义分割网络中,其概率图划分阈值对分割正确率影响较大。
DBNET采用了基于神经网络本身的自适应二值化,对于文本区域概率图进行逐像素的二值化,从而彻底将二值化环节融入神经网络之中,使得分割准确率提高的同时,进一步减少了后续流程,并使得后续CRNN识别过程得到更为准确的分割图,大幅提高了文字识别的正确率。其网络结构如图1所示。
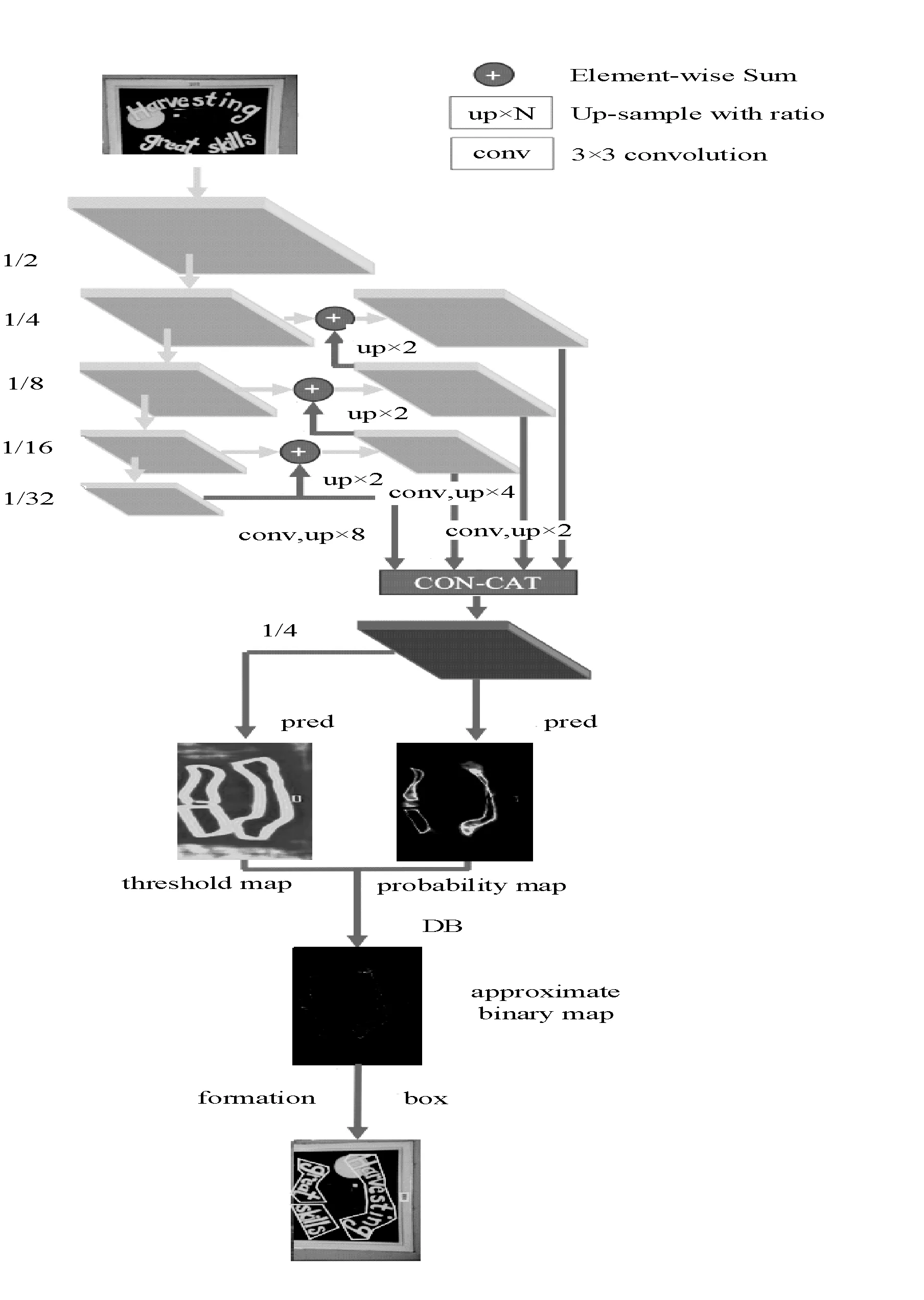
图1 DBNET网络结构示意图
图1展示了DBNET网络的一般结构[5],其结构与一般FPN(特征金字塔网络)相似,但预测环节中除分割文本核区域之外还有阈值特征图预测,其二值化公式表示为:
(1)
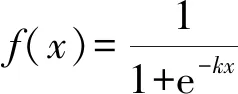

(2)
使用链式法则可得:
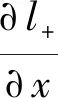
(3)
从式(3)中明显可以看出,其梯度由放大因子k增大,使得正负样本均可在反例时获取较高梯度,从而提高文本区域划分正确性。
2 CRNN+CTC实现
通过DBNET实现文本区域划分后,需采用CRNN模型及CTC编解码方式进行区域内字符级文字识别。
图2展示了划分后的图像区域通过CNN(卷积神经网络)分析后,采用LSTM(长短时记忆神经网络)进行CTC编码的过程,即CRNN+CTC方法,本文所采用的轻量CRNN结构如表1所示,输入张量尺寸为32×n×3。
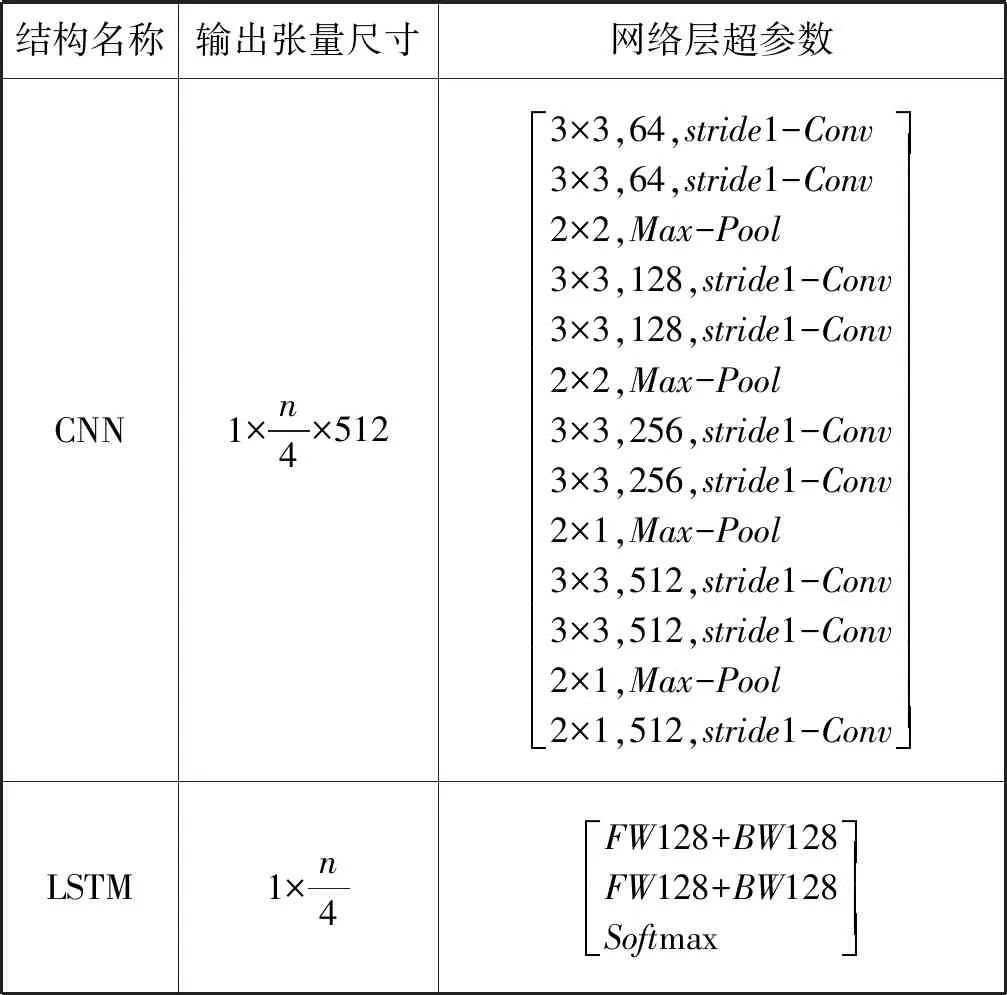
表1 CRNN模型结构参数表
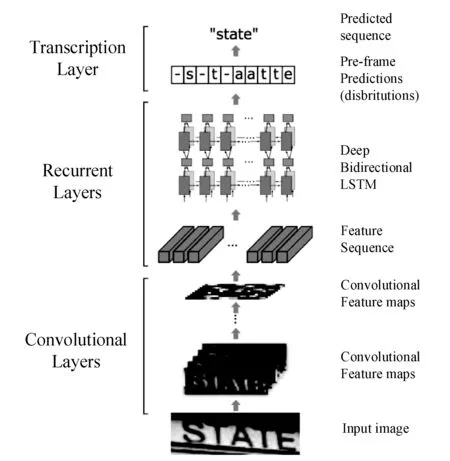
图2 CRNN+CTC工作流程图
可以看出,n表示文字区域图像宽度,理论上对于图像宽度没有限制,从而避免了长列文字识别困难的问题。对于LSTM的输出进行Softmax处理,所得到y为文本的后验概率矩阵,定义为:
y=(y1,y2,…,yt,…,yT)
(4)
式中:T指输出LSTM输出第三维度。考虑到存在空格,标点符号与空字符(因输出序列长度远远大于文字序列长度)设定字符集为:
L′=L∪{blank,punctuation}
(5)
式中:L指代通用汉字及英文字符集合,组成L′为全字符集,由此生成神经网络所预测的后验字符矩阵。
CTC解码方法通过空字符分割与重复字符抛弃的方式进行:
B(π1)=B(sst-aaa-tee-)=stateB(π2)=B(—stta-t—e)=state
(6)
式中:“—”表示blank空字符,使得LSTM的多种输出都可以得到有效解释,从而很大程度上增强了CRNN网络预测的鲁棒性。
3 DBNET与CRNN+CTC训练及效果对比
在文本检测训练中,本文采用了多种数据集融合方式进行数据增广。Chinese Text in the Wild数据集是当前数量最大的中文数据集之一,共含中文字符1 018 402个,32 285幅图像,图像来源为腾讯街景,包含中文字符类型多,且清晰度高(2 048×2 048像素)。为同时完成中英文识别任务,引入ICPR MWI 2018中英文OCR数据集作为补充,其主要由合成图像、网络广告图片组成,字体样式较为丰富。最终在ICDAR2015数据集验证其模型效果,对比EAST、PSENET算法及谷歌开源OCR引擎Tesseract如表2所示。
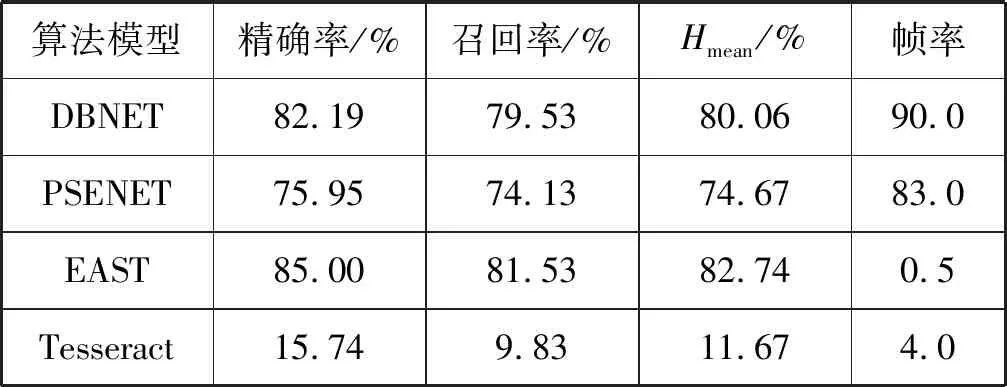
表2 ICDAR2015数据集测试结果
表2中Hmean为加权精确率与召回率的综合评价指标:
(7)
式中:β=1,表示精确率和召回率重要性相当。表2体现了DBNET与基于机器学习的OCR算法以及以往深度学习算法的比较,可以明显看出,基于DBNET的文本区域检测算法能够在保证效率的同时大幅提升运算效能,对比普通机器学习OCR算法更能在复杂环境中表现出优异的性能,对比其他大型网络如EAST时,在精确度仅微小下降时,运算效能提升幅度极大,而对比轻量网络PSENET,其精确率和实时率都有提升,运行效率更加符合服务器的使用需求,部分复杂光源环境及弯曲文本的检测效果如图3所示。

图3 DBNET与CRNN+CTC部分检测效果图
由图3可见对于弯曲或平直中英文文本区域及各类样式字体识别,该算法组合均有优良表现。
4 应用与部署
在工程应用上,由于深度学习的算法部署存在图像解码、模型运算等环节,具有计算IO资源高占用的特点,为提高并发效率,异步消息队列处理方式成为必然选择。采用异步消息队列处理的硬、软件方案部署如图4所示。
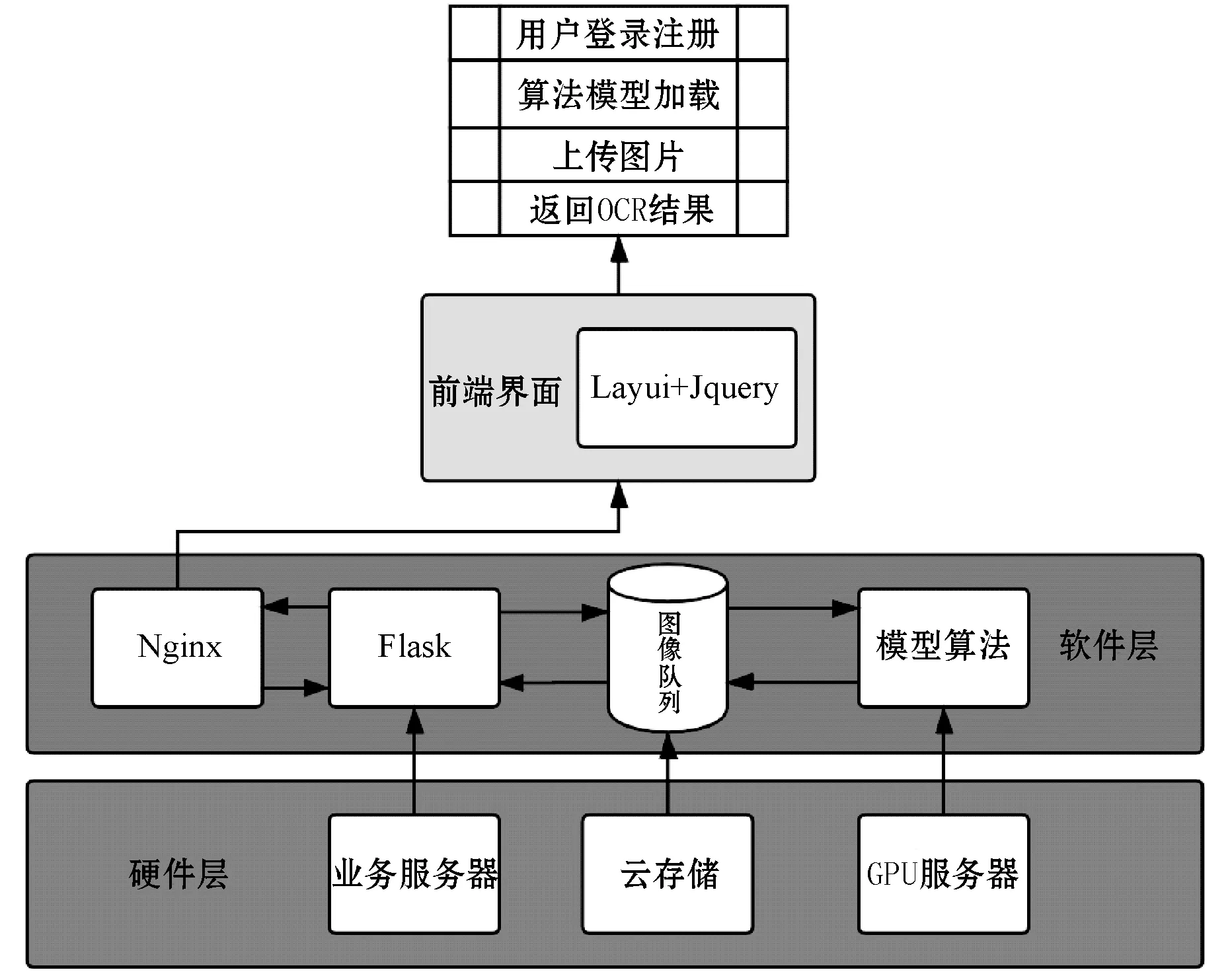
图4 OCR识别系统硬、软件方案简图
为避免过高的IO占用成为系统响应速度瓶颈,提高OCR识别系统负载能力,系统后端分别部署业务服务器与GPU服务器以及存储服务器,业务服务器采用Nginx作为高性能反向代理服务器,提供前端响应,接收上传图片并置入消息队列,随后GPU服务器通过消息队列提取云存储服务器图片数据进行异步分析,并在分析结束后将结果返回业务服务器。出于基于Python语言原生构建的需要,在软件层方面,业务服务器后端采用Flask作为Nginx反向代理所代理的Web框架,并提供基于云存储的图像存储,在此基础上采用Celery作为图像消息队列,提供业务服务器与GPU之间的通信,GPU服务器则使用TensorFlow作为算法模型部署的深度学习框架。经实际测试,该架构有良好的并行性能,能够满足中等规模(100~1 000人)的OCR使用需求。
5 结 语
针对当前传统OCR方法存在有光照、视角、字体要求苛刻的问题,本文设计了一种基于DBNET及CRNN+CTC的两阶段复合深度学习OCR方案,并在大型开源自然环境中英文检测数据集上进行训练,结果与传统OCR及其他基于深度学习的方法对比,表明该方法对于自然场景文字识别效果突出,优于其他算法且在运算效能上有着显著提升。在该技术的应用方面,创新性地进一步探究了基于异步消息队列处理的深度学习OCR系统部署方案,使得该技术进一步得到实用化。该方法未来将在军队信息化建设中发挥重要作用。
