基于深度学习的字轮式水表读数检测与识别
2023-10-09陈妃奋张红梅张向利
陈妃奋 苏 健 张红梅 张向利
1(桂林电子科技大学信息与通信学院 广西 桂林 541004)
2(广西上善若水发展有限公司 广西 南宁 530029)
0 引 言
近年来,由于智能水表取代传统机械式水表仍然存在成本较高的问题,很多地区还是使用传统的机械水表,而图像识别为人工抄表提供了一个低成本的解决方案。然而,现有的方案在识别不同种类和不同拍摄角度的字轮式水表读数时仍存在不足。文献[1]使用霍夫直线检测来对读数区域进行检测,采用模板匹配方法对单个字符进行识别,但对于不同的字轮式水表的读数区域检测能力较差,字符识别准确率较低。文献[2]提出使用Canny边缘检测算法检测出读数区域,用卷积神经网络来对字符数字进行识别。虽然卷积神经网络相对于模板匹配具有更好的识别效果,但Canny边缘检测算法检测出来的图像中可能存在其他直线或噪点,容易导致最后结果出现误检。对于这个问题,文献[3]采用Hough矩形边缘检测算法对水表读数区域进行检测,进一步提高了读数区域检测的准确性,但不同种类的字轮式水表读数区域的边缘特征差异较大,导致该方法的检测能力仍然存在不足,泛化能力较差。
与边缘检测的方法相比,基于深度学习的水表读数区域检测与识别对不同的字轮式水表具有更好的泛化能力。不同种类和不同拍摄角度的字轮式水表的读数区域存在不同的长宽比例,并且具有方向性。文献[4]提出了一个新的连接主义文本建议网络(Connectionist Text Proposal Network,CTPN),实现对文本区域的检测,但CTPN网络模型只能对水平方向的水表读数区域进行检测。为了实现对不同方向的文本检测,文献[5]利用一个完全卷积网络模型对文本区域、字符及其关系进行预测,从而实现对不同方向的文本区域检测。但该模型由多个阶段组成,中间过程过于繁琐导致检测效率低。为了提高检测效率,文献[6]提出了一种快速高效的文本检测算法模型(Efficient and Accurate Scene Text Detector,EAST),直接通过消除中间候选区域聚合和文本分割来实现对文本区域的预测,但该方法对长文本检测存在一定的局限性。基于深度学习的分类模型,文献[7]使用序列识别网络来对水表读数进行识别。该方法虽然不需要分割单个字符,但对于不同种类的水表读数识别需要大量的数据集来对模型进行训练,且模型对运行设备性能要求较高。
目前对字轮式水表读数区域检测与识别方法的研究虽然取得了一些成果,但一般都只是针对于某种类型的字轮式水表提出相应的读数检测与识别方法,缺乏普遍性,易受环境干扰,且识别模型对运行识别性能要求较高。此外,对于深度学习模型对运行设备性能的要求较高的问题,文献[8]提出了一种高效率的卷积神经网络架构,在保持精度的同时,降低了计算成本,但该模型依然较大。文献[9]提出了一种轻量级的神经网络模型,计算量比传统的卷积神经网络减少90%左右,识别精度较高,但该模型输入张量较大,训练和测试时间过长。
针对上述问题,本文提出一种针对不同种类和不同拍摄角度的字轮式水表检测与识别方法。主要创新点如下。
(1) 在图像预处理阶段根据图像均值变化来调节图像的对比度和亮度,提高了水表圆盘检测率,为后面的读数区域旋转矫正和分割提供条件。
(2) 改进文献[6]中存在对多位数的读数区域预测的局限性。本文采用读数区域两端的像素点预测出读数区域的顶点坐标,提高了对不同类型水表的读数区域的检测能力。同时,提出一种图像旋转矫正算法,实现对任意旋转角度下的读数区域的矫正与分割。
(3) 对文献[9]中的网络模型进行降维,重新对中间层进行设计,减少中间层的计算量,采用最大池化来保留更多的字符特征,加速训练过程的同时减小了模型大小,保持较高的识别精度。
1 研究方法
本文提出的字轮式水表读数检测与识别方法具体过程如图1所示,包括水表图像预处理、读数区域检测与矫正、读数识别三个部分。
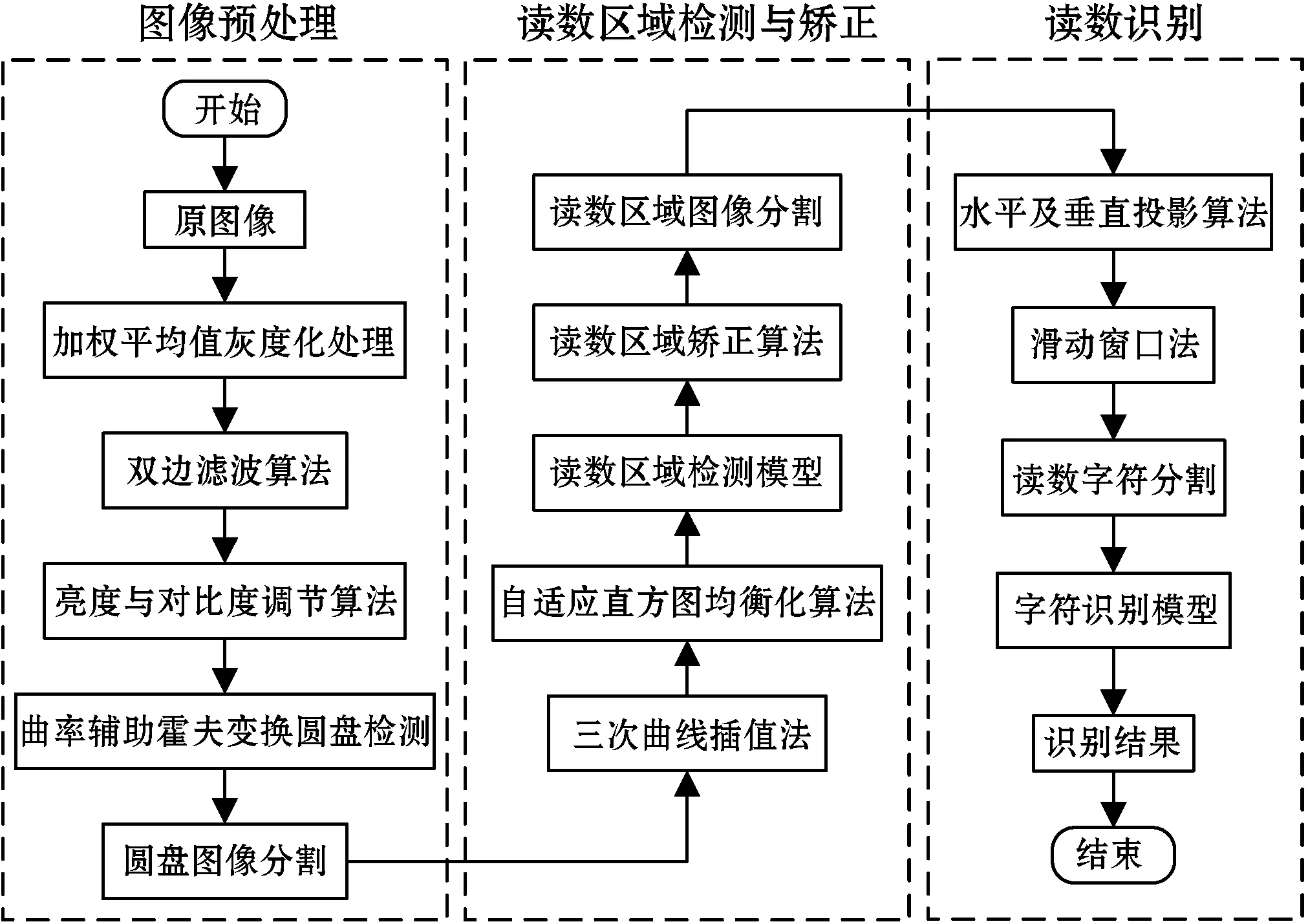
图1 水表读数检测与识别流程
1.1 图像预处理
本文采用加权平均值法对水表原图像进行灰度化处理,使用双边滤波算法[10]消除干扰噪声,在文献[11]方法的基础上,根据水表图像的均值,加入了亮度与对比度调节算法,提高对不同环境下的水表圆盘的检测率,有利于后面水表读数区域的矫正与分割,如式(1)所示。
O=I·α+B·β+γ
(1)
式中:I表示原图像数据矩阵;B表示与I同维度的零矩阵;权重α(α=k/m)调节图像对比度,m表示图像均值,k表示调节系数;权重γ调节图像亮度;α权重和β关系为β=1-α;O表示调节后的图像数据。
对调节后的图像O采用Sobel算子进行边缘检测,通过连通性分析将圆盘边缘曲线间隙不超过1个像素点的曲线进行合并。使用文献[11]中曲率辅助霍夫变换的方法对水表圆盘进行检测,根据检测得到的圆盘中心坐标以及半径,分割出圆盘区域的内切圆正方形,分别用H和W表示正方形的长和宽。
1.2 水表读数区域检测
不同的水表图像可能存在不同的尺寸大小,为了提高检测模型对读数区域的检测能力,使用三次曲线插值法将分割出来的圆盘图像缩放为2r×2r,r表示圆盘的半径,并采用自适应直方图均衡化方法[12]来增强图像的清晰度。通过前面的圆盘检测、分割以及缩放处理之后,减小了水表图像读数区域的尺寸变化,有助于提高检测模型的检测精度。
1.2.1检测模型
读数区域检测模型采用文献[6]的方法对读数区域的特征进行提取,同时对不同层的特征信息进行融合,提高网络模型对不同位数的水表读数区域的检测能力。文献[6]使用每个文本区域的像素点对文本框进行预测,但是每个像素点都有感受野的限制,导致用一端的像素点去预测到另一端的边距时,就会出现检测不到的情况,使模型在长文本的检测上存在一定的局限性。为了提高对更多位数的水表读数区域的检测能力,本文采用读数区域两端的像素点分别对读数区域两端的顶点坐标进行预测,从而计算出读数区域的顶点坐标。即分别使用1×1的卷积核将合并输出的特征通道映射为1个通道的像素分数图的置信度Y和多个通道的读数区域信息。由分数图置信度Y筛选出属于读数区域的信息。输出的读数区域信息由两个通道的边界元素信息G和四个通道的顶点坐标偏移量D表示,如式(2)-式(3)所示。
G={S,F}
(2)
D={(dxi,dyi)|i∈1,2}
(3)
式中:S表示边界元素的置信度;F表示读数区域的首/尾部元素(F中0表示首部元素,1表示尾部元素);(dxi,dyi)表示首或尾部元素顶点坐标偏移量,预测的读数区域矩形框四个顶点坐标计算如式(4)所示。
(4)
1.2.2损失函数
每个读数区域损失包括分数图损失和读数区域信息损失,定义为:
(5)
式中:Ls表示分数图损失函数;Lg表示读数区域信息损失函数。分数图损失主要采用文献[13]中的类平衡交叉熵进行计算,定义为:
(6)

(7)
对于读数区域信息的损失函数,包括顶点坐标偏移量损失和边界元素信息损失,由文献[14]提出的smoothed-L1损失来计算顶点坐标偏移量损失,该方法可以将L1范数和L2范数的优点相结合,使得损失对离群点具有更强的鲁棒性。读数区域信息的损失函数定义为:
(8)
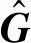
(9)
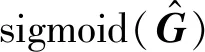
(10)
1.3 旋转矫正与分割
水表图像的读数区域可能存在不同的旋转角度,本文将其分为四个部分来分析,如图2所示。
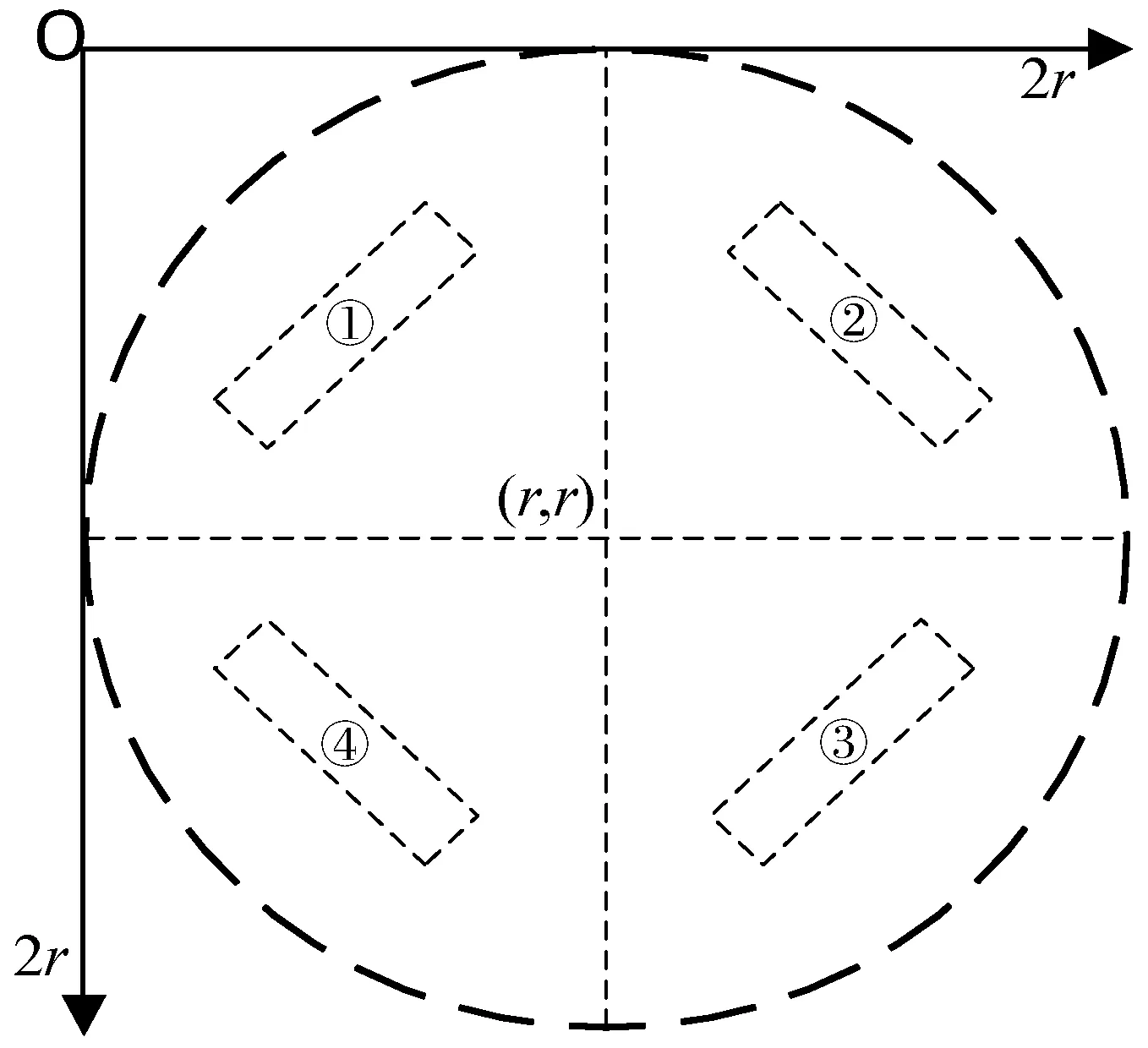
图2 尺寸为2r×2r的水表图像示意图
每个部分的水表读数区域可能存在多种情况。因此,本文提出了一种图像旋转矫正与分割算法,如算法1所示。计算出不同旋转角度下的水表图像需要矫正的角度值θ(负值表示顺时针旋转,正值表示逆时针旋转)以及分割出读数区域图像A。
算法1计算矫正图像的角度值θ和分割出读数区域图像A算法
输入:{(xi,yi)|i∈1,2,3,4}。
输出:θ,A。
1.初始化圆形图像半径r,计算出矩形读数区域中心坐标(xc,yc)、水平夹角angle、长宽l和w,以及短边的中心坐标值x12、x34、y14、y23。
2.由水平夹角angle判断读数区域框水平还是倾斜状态。
3.若处于水平状态,由读数区域中心坐标计算出角度值θ。
如:function1(angle=0°或90°)
ifxc>rthenθ=90°
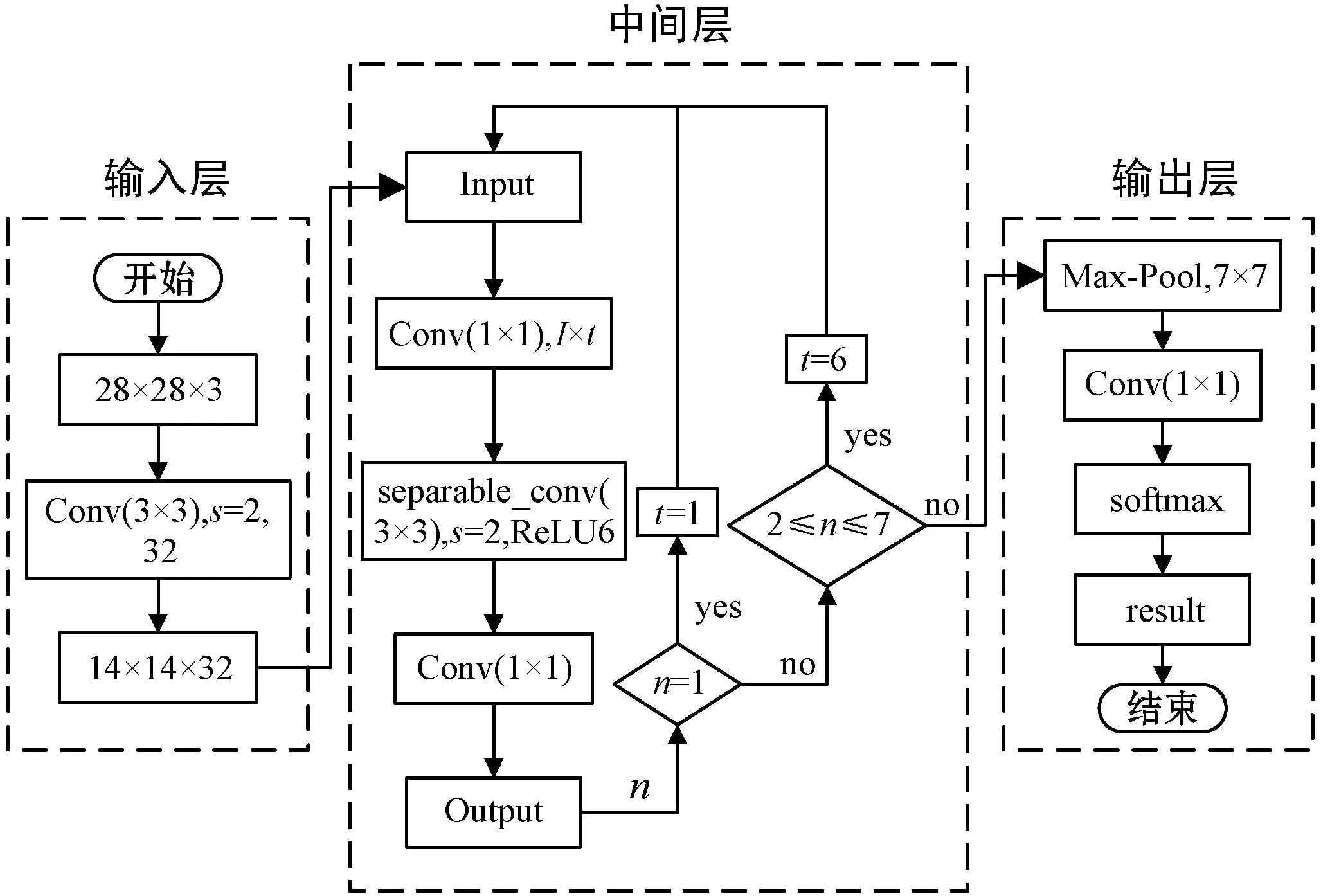
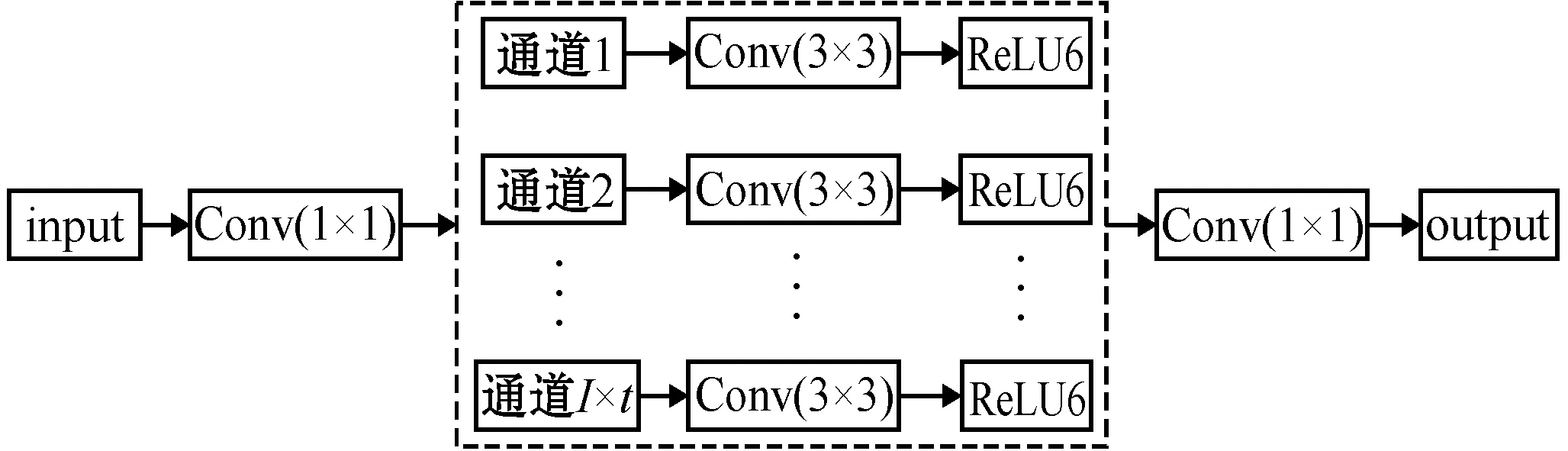
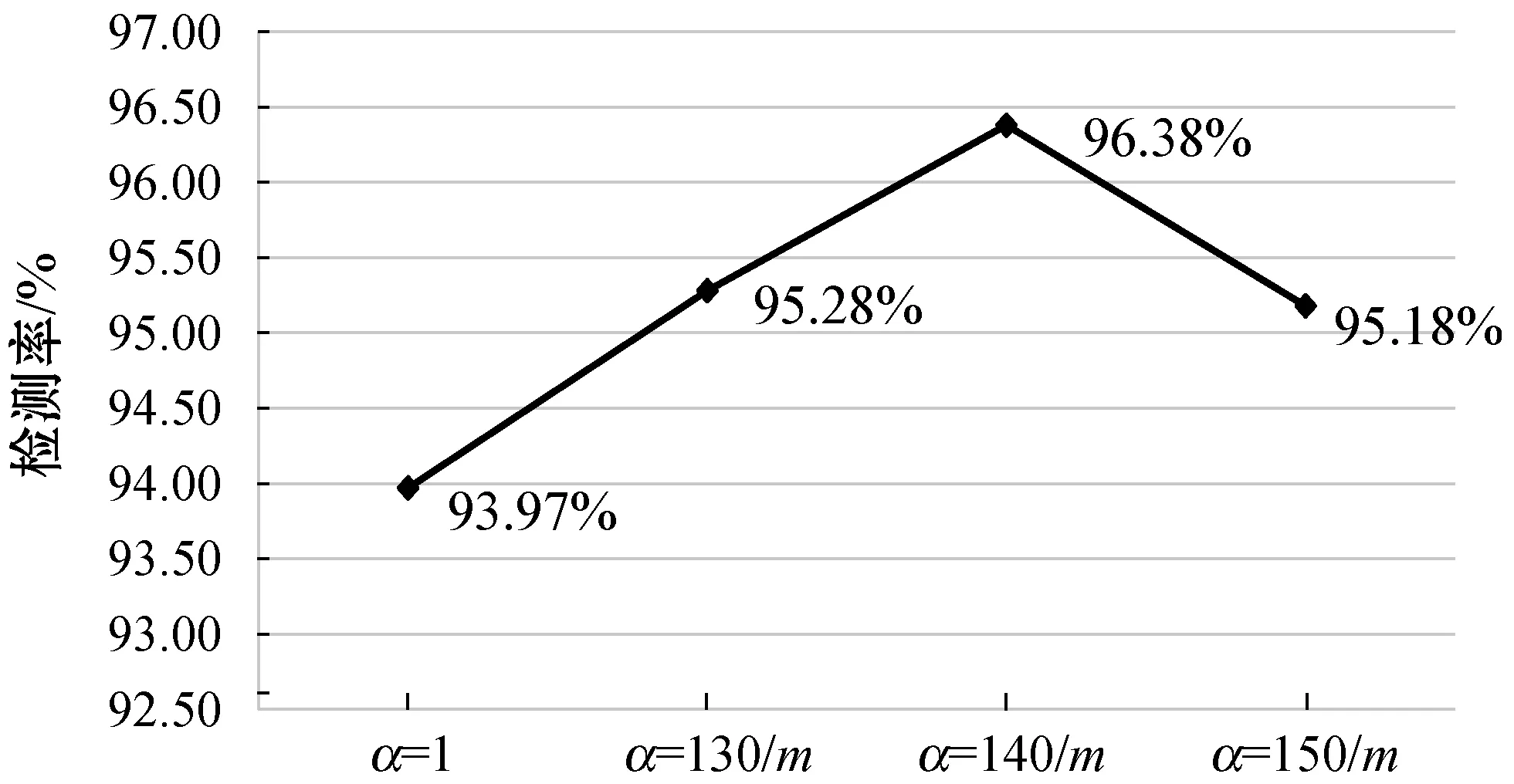
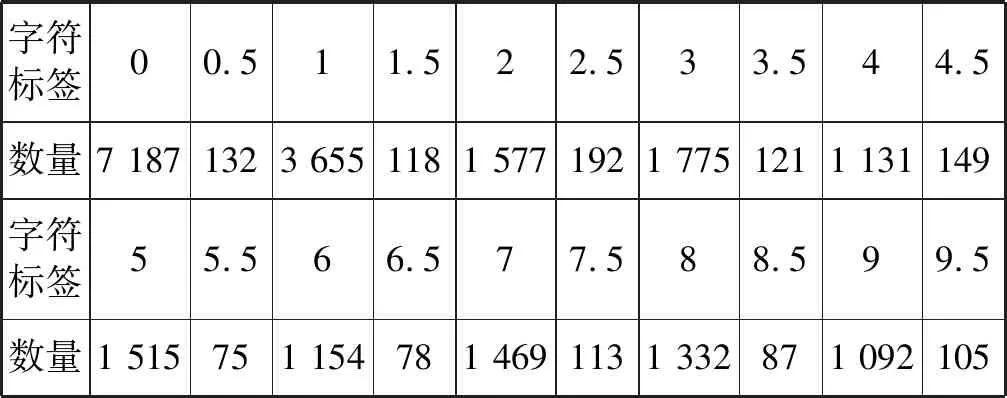
elseifxc elseifyc>rthenθ=180° elseifyc returnθ endfunction1 4.若处于倾斜状态,由xc≤r和yc≤r,推断出读数区域框处于图2中的①部分,计算出角度值θ。 如:function2(angle≠0°或90°) ifl elseifl elseifl>wandy14>y23thenθ=-angle elseifl>wandy14>y23thenθ=angle returnθ endfunction2 5.重复步骤4,修改相应的判断条件,即可计算出读数区域框在图2中②、③、④情况下的角度值θ。 6.根据角度值θ及矫正前读数区域中心坐标值(xc,yc),计算矫正后读数区域中心坐标值(xnc,ync),分割出读数区域图像A。如: function3(θ,xc,yc) xnc=(yc-r)×sin(θ)+(xc-r)×cos(θ)+r ync=(yc-r)×cos(θ)-(xc-r)×sin(θ)+r wmax=max(l,w),lmin=min(l,w) A={(x,y)|x∈[xnc-wmax,xnc+wmax], y∈[ync-lmin,ync+wmin]} returnA endfunction3 不同的水表图像在图像预处理后得到相同的尺寸大小,使得读数区域矩形框的长边与读数的位数成正比例关系。因此,为了更好地保留读数区域中字符的特征信息,消除其他无用信息,提高读数识别模型的准确度,本文将投影法和滑动窗口法相结合,实现对单个字符的分割,过程如算法2所示。 算法2字符分割算法 输入:lmin,wmax,A。 输出:字符集合C。 1.使用水平投影和垂直投影法去除尺寸为lmin×wmax的读数区域图像周围的无关信息,得到尺寸为l*×w*的读数区域图像。 2.设y=bx,x为读数个数,b(b>0)为比例系数,单个字符宽度为bx=w*/x。 3.使用滑动窗口的方法提取出单个字符。 如:function4(l*,bx,x) forj=0;j≤x;j++ do c=A[0:l*,bx×j:bx×(j+1)] C.append(c) returnC endfunction4 4.使用三次曲线插值法将字符集合C中的字符图像缩放为28×28。 由于文献[9]中的网络模型输入张量大,训练及测试时间过长,因此设计一种轻量级的网络模型用于水表读数的识别,模型框架如图3所示。 图3 字符识别模型框架 根据分割出来的字符尺寸的特点,将网络模型的输入张量设计为(28,28,3)。先采用卷积核Conv(3×3)对输入图像的特征进行粗提取,s表示卷积步长。由于输入层的特征维度较低,如果中间层直接对低纬度进行特征信息提取,可能无法获得足够多的特性信息。因此,中间层主要采用深度可分离卷积的方法,具体过程如图4所示。 图4 深度可分离卷积 使用Conv(1×1)的卷积核对输入层输出的特征信息进行维度扩展,I×t表示对输入通道数I扩展t倍。然后用Conv(3×3)的卷积核分别对每一个通道提取特征信息,再采用半波整流器ReLU6来保留更多特征信息。最后用卷积核Conv(1×1)将高维特征信息转为低维输出。n表示中间层需要迭代的次数,本文中n取值范围为1~7,即表示中间层的输入到输出循环7次。当n=1时,扩展倍数t=1;当2≤n≤7时,扩展倍数t=6。为了解决由高维转低维导致字符特征信息保留不充分的问题,在输出层中使用最大池化(Max-Pooling)来进行池化操作,保留更多的字符特征信息,提高网络识别性能。最后使用softmax激活函数输出模型的分类结果。softmax激活函数定义为: (11) 式中:i表示中的某个分类;zi表示该分类的值;N表示分类数。损失函数采用式(6)进行计算。 本文实验环境的硬件环境为6核Intel(R) Core(TM)CPU@3.60 GHz处理器,16 GB内存;NVIDIA GeForce GTX 1 070的GPU,内存为8 GB;软件环境为Windows 10操作系统,Anaconda 4.7.12,Python 3.6,CUDA 10.0。 为了验证本文方法的有效性,本文收集了7 494幅水表原图像,包括不同环境、不同旋转角度、不同的尺寸大小的水表图像。取γ=1,α取值与水表圆盘检测率的关系如图5所示,m为图像均值。 图5 水表圆盘检测率 其中,α=1为文献[11]的圆盘检测率,其他为加入自动调节算法的圆盘检测率。实验结果表明,α=140/m时,水表圆盘检测率从原来的93.97%提高到了96.38%。 本实验设H=W=2r=512,如图6所示。 图6 图像预处理 对原始的水表图像进行预处理,并将水表图像的读数区域对应的标签数据保存为txt文件。为了提高识别模型的泛化能力,除了水表原图像数据集,本文还收集了6 000多个不同环境下的读数区域数据集用于识别模型的训练,对其进行单个字符分割处理,将每个字符进行分类以及标记上对应的标签,数据集和分类标签如表1所示。 表1 水表字符标签数据集 本文使用ICDAR评估协议对水表读数区域检测模型算法进行评估,交并比(Intersection-over-Union,IoU)是指预测的读数区域框与原先标记框的交叠率,即用交集和并集的比值来反映出预测的准确性。 (12) (13) (14) (15) 式中:T表示检测水表图像的总数。各模型算法的检测效果如表2、表3所示。表2是对一种水表图像进行检测,表3是对多种水表图像进行检测。 表2 基于ICDAR评估协议的模型算法对比(单)(%) 表3 基于ICDAR评估协议的模型算法对比(多)(%) 本文方法对不同水表的读数区域进行检测的结果如图7所示,可以看出对不同位数、不同旋转角度的水表读数区域都有很好的检测效果。 图7 不同水表读数区域检测结果 从表2、表3中的对比结果可以看出,文献[3]的矩形边缘检测方法对一种水表图像的读数区域检测效果较好,但对不同水表图像的读数区域检测效果较差。这是因为不同水表具有不同的边缘特征信息和背景环境,导致泛化能力较差。由于CTPN方法只能检测水平方向的读数区域,使得检测效果一般。EAST方法的检测效果较好,但缺乏对更多位数的检测能力。本文方法具备对更多位数的检测能力,因此优于其他方法。 根据读数区域检测结果,使用算法1对水表读数区域图像进行矫正和分割,如图8所示。 图8 水表读数区域检测、矫正以及分割 使用算法2对读数区域图像进行单个字符分割,并将单个字符图像的尺寸缩放为28×28,如图9所示。 图9 单个字符分割及缩放 实验中,将水表字符数据集按9∶1随机划分为训练集和测试集,水表读数识别模型的输入张量为(28,28,3),经过对网络模型的分析和测试,中间层n取值范围为1~7,每一层的扩展倍数t与n的关系如下: (16) 本文识别模型与其他轻量级网络模型对比如表4所示。可以看出本文识别模型大小小于其他模型,而且识别精度较高,训练和测试时间短,进一步降低了对运行设备性能的要求。 表4 水表读数识别模型方法的对比 对于现有的水表读数检测与识别方法不太适用于不同类型和不同拍摄角度下的水表读数检测与识别问题,本文提出一种水表读数检测与识别方法。采用一种改进的水表读数区域检测方法,提高对不同位数和不同旋转方向的读数区域的检测能力。同时提出一种图像旋转矫正算法,实现对读数区域的正确矫正与分割;设计一种轻量级的神经网络读数识别模型,降低对设备性能要求的同时,保持较高的识别精度。实验结 果表明,本文方法对不同字轮式水表在不同的旋转角度下都有较好的检测和识别效果。下一步工作的重点,考虑在读数区域出现严重受损的情况下进一步提高模型的检测与识别能力,使该方法具有更强的泛化能力。1.4 水表读数识别
2 实 验
2.1 数据集预处理

2.2 检测模型评价
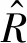


2.3 旋转矫正与分割


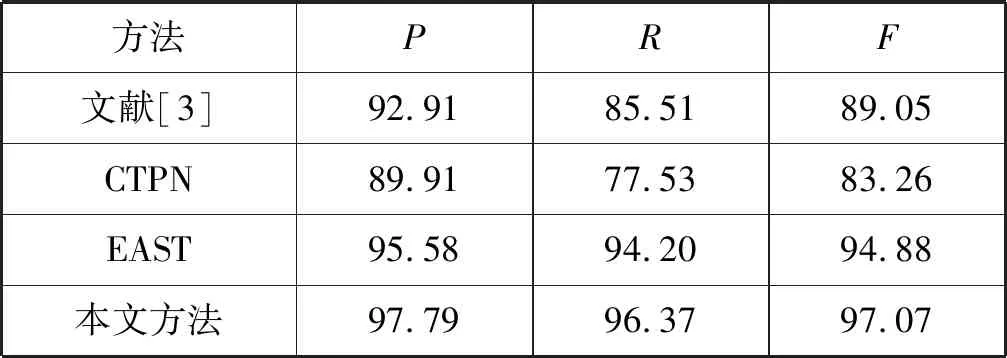
2.4 识别模型评价
3 结 语
