基于依存关系的医疗自然语言统计问答
2023-10-09金季豪黄越祈刘旭利高大启
金季豪 黄越祈 刘旭利 高大启
(华东理工大学信息科学与工程学院 上海 200237)
0 引 言
随着医疗信息系统的广泛应用,诸多大型医疗机构已经积累了大量的电子病历(Electronic Health Record,HER)数据。通过对这些电子病历数据进行医疗统计分析,可以帮助临床医生进行临床研究。对此,本文提出了基于依存关系的医疗自然语言统计问答,临床医生能够直接使用自然语言提问,得到相应的统计结果。
目前,对于自然语言统计型问答的研究仍相对较少,医疗统计问题也需要用到复杂的逻辑限制,如“服用百令胶囊和冬凌草片且没有患有冠心病的肺癌患者的疾病分布是怎样的?”,包含了与、非等逻辑限制。目前基于知识库的问答工作,大量集中在类三元组的简单问题上,不涉及复杂逻辑关系与数学计算。ESWC 2016针对统计型问答举办了基于RDF数据立方(RDF Data Cube)的评测竞赛。该竞赛的RDF数据使用3个维度来刻画数据,数据结构相对简单,对应的评测问题也不需要复杂的逻辑限制。最近流行的自然语言查询(NL2SQL)研究工作[1-3],由于SQL本身固有的特点,目前的任务大多都集中在单表查询上,而本文的统计必定会涉及到概念之间的多对多关系。在本文作者之前的工作中[4],利用上下文无关文法进行自然语言问题到图数据库查询语言(Cypher)的转换,并返回对应的查询结果,可以表达丰富的业务需求。但由于自然语言表达非常丰富,文法规则越来越多,给从文法到Cypher的正确转换带来了困难。
为解决上述问题,本文通过基于转移的依存关系生成方式(Transition-Based Parsing),并且利用基于Blending的融合模型,将自然语言问题转换成对应的依存关系树,并将解析结果映射成语义表达式,然后翻译得到Cypher查询语句,最后返回查询的结果。实验表明,模型的UAS(Unlabeled Attachment Score)达到了96.45%,LAS(Labeled Attachment Score)达到了96.01%,系统的问题覆盖率达到了81.61%。相较于端对端利用seq2seq的方式直接翻译成查询语言来讲,本文的方法能够更好地处理包含复杂逻辑结构和时间先后关系的问题,而且在翻译成查询语言步骤时,可解释性更强,并且可以对应地改进翻译策略,提高系统精度。同时,本文在文献[4]的基础上,能够处理的问题句式更为灵活,具体本文共有以下几点贡献点:
(1) 本文针对医疗领域定义了电子病历语义模型以及对应的依存关系,能够清晰完整地表述实体之间的语义关系,且可扩充性强,能处理的问题句式也更为灵活。
(2) 论文提出了基于神经网络与XGBoost的依存关系融合模型。实验证明,本文所提出的模型,在UAS以及LAS这两个评价指标上,都比单模型的结果有了一定的提升。
(3) 本文通过基于转换的方法,利用融合模型预测得到自然语言问题的依存关系树,并将其映射至语义表达式上,接着通过启发式规则将语义表达式翻译成对应的Cypher查询语句。实验证明本文的查询正确率比现有方法有了一定的提升。
1 相关工作
自然语言问答一直是自然语言处理研究的热点之一。本文从早期的自然语言问答技术到基于知识库的问答系统(KB-Based QA),再到面向统计关联数据的问答系统再到面向自然语言的SQL转化。
基于知识库问答系统的传统做法是语义解析[5-12]先将自然语言问题解析成逻辑表达式,再将逻辑表达式转换为结构化查询语言,再通过查询语言从知识库查询得到答案并返回其结果。文献[11]利用整型线性规划的方法来进行联合消歧。文献[12]为了更好地表示问题,提出了语义查询图概念,将问题简化为子图匹配查询。利用这种方法,解决了歧义的问题,但是这种方法的搜索空间往往是指数级的,响应速度缓慢。Joseph等[13]提出了一个系统,可以输入英文语句,然后将它们翻译成XQuery表达式。Bais等[14]介绍了基于关系数据库的机器学习方法在通用自然语言接口上的实现。
另一种基于知识库的问答方法是将问题和答案转换成向量表示,并比较两个向量的相似度。随着词向量学习的普及,知识表示任务也随之变得更加容易。早期如文献[15-16]简单地把问题用词袋模型进行编码,而在最近的工作中,利用了更多的结构化信息。文献[17]利用多层卷积神经网络从答案的路径、答案的上下文和答案的类型三个方面来表示问题。
在面向统计关联数据的问答系统方面,比较知名的是ESWC举办的QALD评测。QALD-6有一个任务是基于统计关联数据的问答[18],该应用场景与本文任务十分相似。但是,QALD-6任务中的查询是基于RDF数据立方(RDF Data Cube),仅使用3个维度来刻画数据,数据结构相对简单,对应的评测问题也不需要复杂的逻辑限制。对此,文献[18]设计了CubeQA算法,在文献[19]的基础上,基于模板规则,在QALD6T3-test评测中得到了0.43的全局F1值。
在自然语言转换为结构查询语言(SQL)方面,文献[1]提出了一种将深度学习技术与传统查询解析技术平滑结合的新方法——编码器-解码器框架。文献[2]提出了通过结合自然语言处理,程序综合和自动程序修复来实现从自然语言自动合成SQL查询的方法。文献[3]提出了一种新颖的方法TYPESQL,将自然语言转化为SQL视为插槽填充任务。
2 方法描述
目前的统计型问答系统,数据结构相对简单,不能解决复杂的逻辑限制关系和时间限制关系,更不能理解复杂问句中的隐藏语义。因此,本文提出了基于医疗领域的电子病历语义模型,以及对应的依存关系。同时利用Blending的方式训练了依存关系融合模型。对于输入的自然语言,首先会利用模型预测其依存关系树,并结合定义好的语义模型将其映射至语义表达式中,接着转换成Neo4j查询语句Cypher,最后以图表形式将查询结果返回给用户。
2.1 总体流程
本文方法的总体流程如图1所示。首先本文分析发现医生所提出的医疗统计需求均是以“病人”这个主体进行提问的,问题中的各成分会对“病人”进行语义上的约束。因此,本文构建了面向医疗统计型问答的电子病历语义模型以及对应的依存关系。
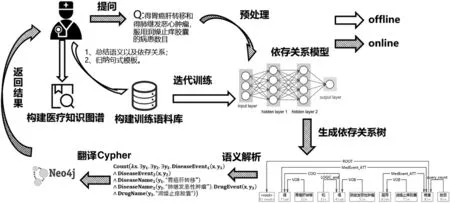
图1 本文方法总体流程
在系统实际运行时,对于医生提出的自然语言问题,系统首先利用jieba分词工具对问句进行分词及预处理。在删除出现的停用词和标点后,对每个词赋予其词性,同时将其作为特征输入到依存关系模型中,预测得到该问句对应的依存关系树,并将其映射到对应的语义逻辑表达式中,再翻译成Cypher语句,最后以图表形式返回结果。
2.2 电子病历语义模型及医疗依存关系的定义
对于电子病历语义模型的定义,本文分析临床医生的需求,发现这些需求均围绕着“病人”展开,而问题中的其他部分则对其进行了语义上的约束,具体可以利用语义逻辑表达式的形式将这些需求问题的语义表示出来。因此本文在归纳总结后,构建了一个电子病历语义模型,能够覆盖本文医疗统计分析问题任务语境下的所有语义,一共有以下7种语义。其中,本文的语义表达式中用到的变量如表1所示。
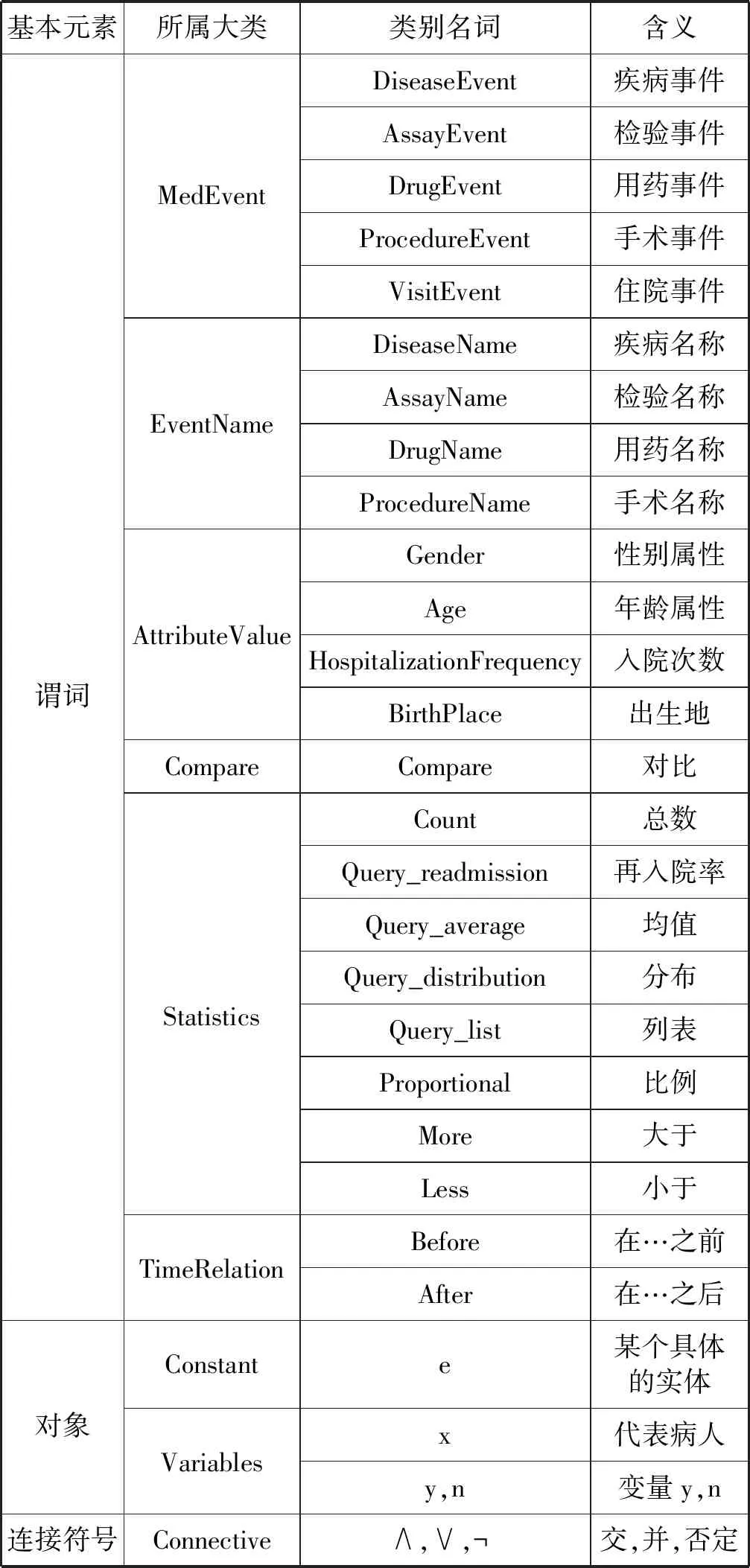
表1 变量符号表
(1) 医疗事件约束。指对曾发生过某条具体医疗事件记录的“病人”进行约束,其语义表达式为λx.∃y.MedEvent(x,y)∧EventName(y,e)。例如“得了高血压的病人”,表达式为λx.∃y.DiseaseEvent(x,y)∧DiseaseName(y,″高血压″)。
(2) 病人属性约束。指对病人的某项属性进行约束,其语义表达式为λx.Value(x,e)。例如“男性病人”,表达式为λx.Gender(x,″男性″)。
(3) 逻辑运算约束。共有与、或、非三种不同的逻辑操作计算,其对应的语义表达式为∧、∨、。
(4) 时间先后约束。常常用于约束不同医疗事件之间的时间先后关系,其语义表达式为λx.∃y1.∃y2.MedEvent1(x,y1)∧MedEvent2(x,y2)∧EventName1(y1,e1)∧EventName2(y2,e2)∧TimeRelation(y1,y2)。例如“得了糖尿病后用了胰岛素的病人”,表达式为λx.∃y1.∃y2.DiseaseEvent(x,y1)∧DrugEvent(x,y2)∧DiseaseName(y1,″糖尿病″)∧DrugName(y2,″胰岛素″)∧Before(y1,y2)。
(5) 数值范围约束。用于约束病人的数值型属性,λx.Value(x,e)。例如“70岁的病人”,其语义表达式为λx.Age(x,70)。
(6) 对比关系约束。在医疗统计问题中会常常出现需要对比两者的语义的情况,其语义表达式为λx1.λx2.Compare(x1,x2),其中x2表示另一个病人。
(7) 统计目的约束。用于约束问句最终的分析目的,例如“男性病人的总数”其语义表达式为Count(λx.″男性″))。
同时本文还根据上述的电子病历语义模型,定义了对应的医疗领域依存关系。依存句法的本质是提取词与词之间的依存关系、在通用领域中一般使用语法关系,例如主谓关系,动宾关系。但在医疗领域的文本中,存在一部分能够明确表示语义的关系,例如病人属性关系、医疗事件关系。但如果完全使用此类关系,无法完整表示所有的文本,因此需要使用语法关系进行补充。在阅读了大量医疗领域文本的基础上,本文总结出一套针对医疗领域的依存关系,与语法关系一起训练,最终得到了不错的结果,具体定义可见表2。
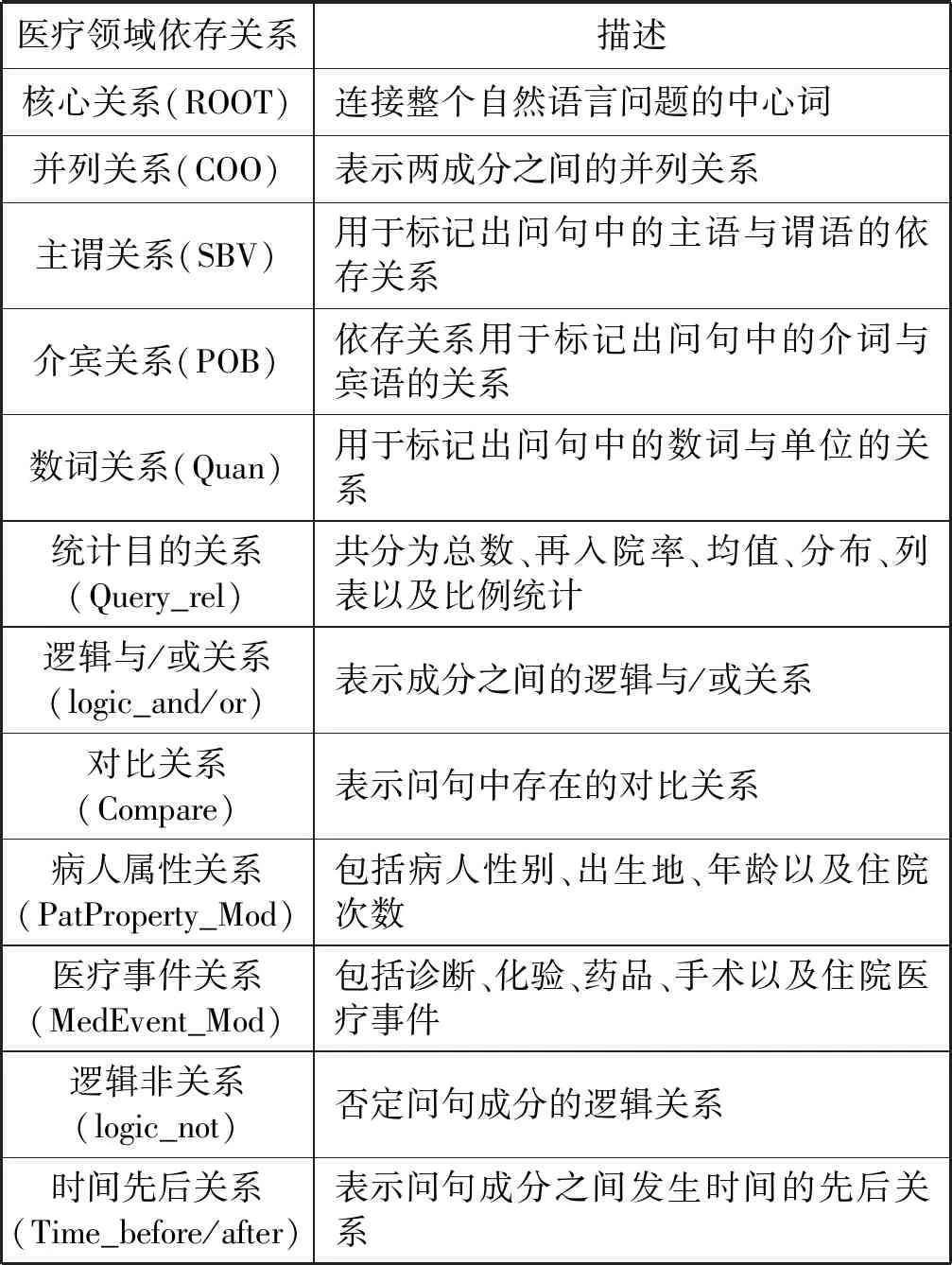
表2 医疗领域的依存关系定义
2.3 基于转移方法的依存关系融合模型
本文利用基于转移的方法来训练依存关系。首先对于每个输入的问句,初始化其结构C=(s,b,a)。其中s表示堆栈(stack),初始化后s=[ROOT],s1代表栈顶词,s2代表栈顶第二个词。b表示缓冲区(buffer),初始化后b=[w1,w2,…,wn],wj表示问句中的第j个词汇。a表示依存关系(Dependency Arcs),初始化后a=∅。终止条件为当结构C中堆栈s仅有一个[ROOT],且缓冲区b=∅。基于转移的依存解析目标就是将问句从初始结构到终止结构,预测每次的转移动作。转移动作包括以下3个。
(1)shift:将缓冲区b中的栈底元素b1移到堆栈s的栈顶,前提条件是len(b)≥1。
(2)left_arc(l):向依存关系a中加入关系边s1→s2,及其边上的标签l,并把s2移出堆栈s,前提条件是len(s)≥2。
(3)right_arc(l):向依存关系a中加入关系边s2→s1,及其边上的标签l,并把s1移出堆栈s,前提条件是len(s)≥2。
因为本文定义了一共21种依存关系,所以神经网络的输出为2T+1=43维的向量(其中T为依存关系个数)。具体的操作流程如表3所示。

表3 转移序列表
通过表3的Step13将“对比服用地诺帕明、卡托普利病人再入院率”这句句子用本文的方法进行了依存关系生成,生成后的对应图形如图2所示。
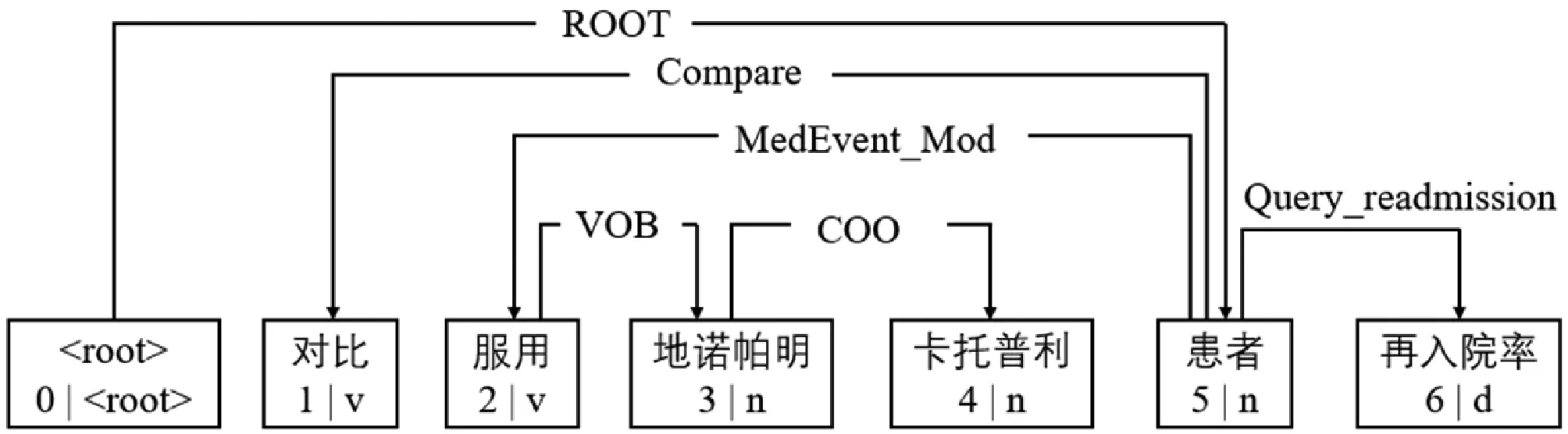
图2 “对比服用…病人再入院率”的依存关系图
本文提出了一种依存关系的融合模型,其融合方式是基于Blending的方式。其中第一层分类器包括神经网络模型以及XGBoost模型,第二层分类器则使用了随机森林。具体地,本文Blending模型结构如图3所示。
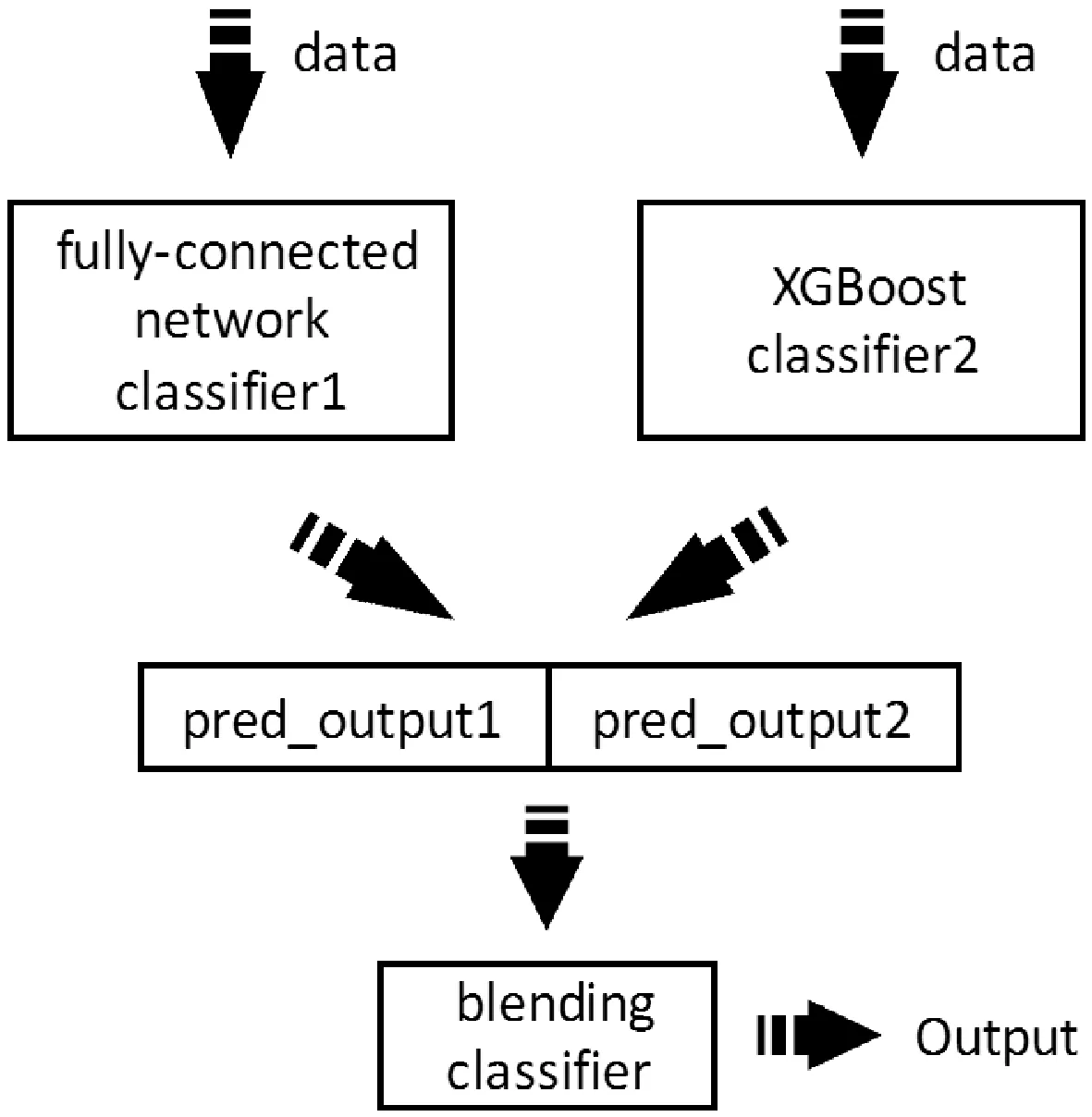
图3 Blending模型示意图
对于基于神经网络的模型,本文利用了文献[20]中的训练方法,并进行了部分改进,具体描述如下:输入的特征包括词特征、词性特征和依存关系特征三类特征。本文使用Word2vec来训练对应的词向量。因为在语料中会存在大量的数字,训练这些数字的词向量意义并不大,因此本文对数字都做预处理,用“num”来替代数字,即所有数字共用一个词向量。训练好的词向量、词性向量和依存关系向量均为200维,后两者分别以方差为0.1的正态分布来进行初始化。
本文的神经网络模型结构分为输入层、两层全连接层以及输出层。其中第一层全连接层包括300个神经元,第二层全连接层包括200个神经元,输出层为一个43维的向量,且激活函数为Cube函数y(x)=x3。本文一共使用了48个特征,每个特征用对应的200维向量来表示。图4展示了模型的部分特征,其中s表示stack,b表示buffer,下标数字i(i=1,2)表示栈中第i个词,lc(si)表示与栈中第i个词完成最近一次左移操作的词汇,反之,rc(si)表示与栈中第i个词完成最近一次右移操作的词汇。每个词汇又都包括对应的词、词性和依存关系3个粒度上的特征。如果不存在对应特征,则赋值NULL。本文所使用的所有特征可详见表4所示。
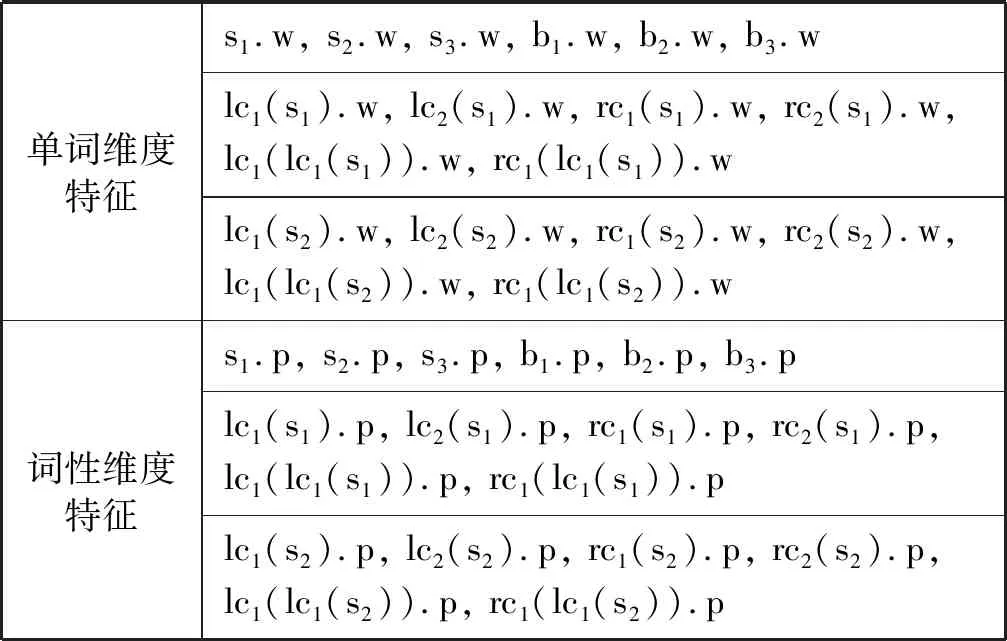
表4 特征模板

图4 模型部分特征示意图
同时本文还使用了XGBoost作为融合模型第一层中的另一个单模型。XGBoost作为一种高效的分布式Boosting模型,因为其算法学习速度快以及出色的训练效果,而被广泛使用。但是其本质上属于梯度提升决策树算法,在列抽样时会破坏词向量原有的信息。因此本文中XGBoost模型的输入特征为词汇在字典中的序号。在训练模型完成之后,本文还输出了特征重要性,在48维特征中,stack栈中词汇的词向量以及词性向量对训练是非常重要的。
2.4 问题语义解析
首先对于医生输入的问题Q,利用jieba分词后,将会生成一个词序列wordList=[w1,w2,…,wn]。特别地,对于词序列中的所有数字,均用“num”来替换。生成词序列时,同样调用jieba生成对应的词性序列posList=[p1,p2,…,pn],其中数字“num”的词性均为数词m。然后将问题Q的词序列和词性序列作为模型的输入,输入到融合模型中进行预测。因为本文的任务是对病人信息及诊断疗效进行统计,所有的问句均是以病人为中心展开提问,所以最终会得到一棵由“病人”为根节点连出的依存关系树。例如问题为“未服用地诺帕明和卡托普利,入院次数小于6次的男性高血糖病人的人数?”,会生成表5所示的以CoNLL格式表示的依存关系树。
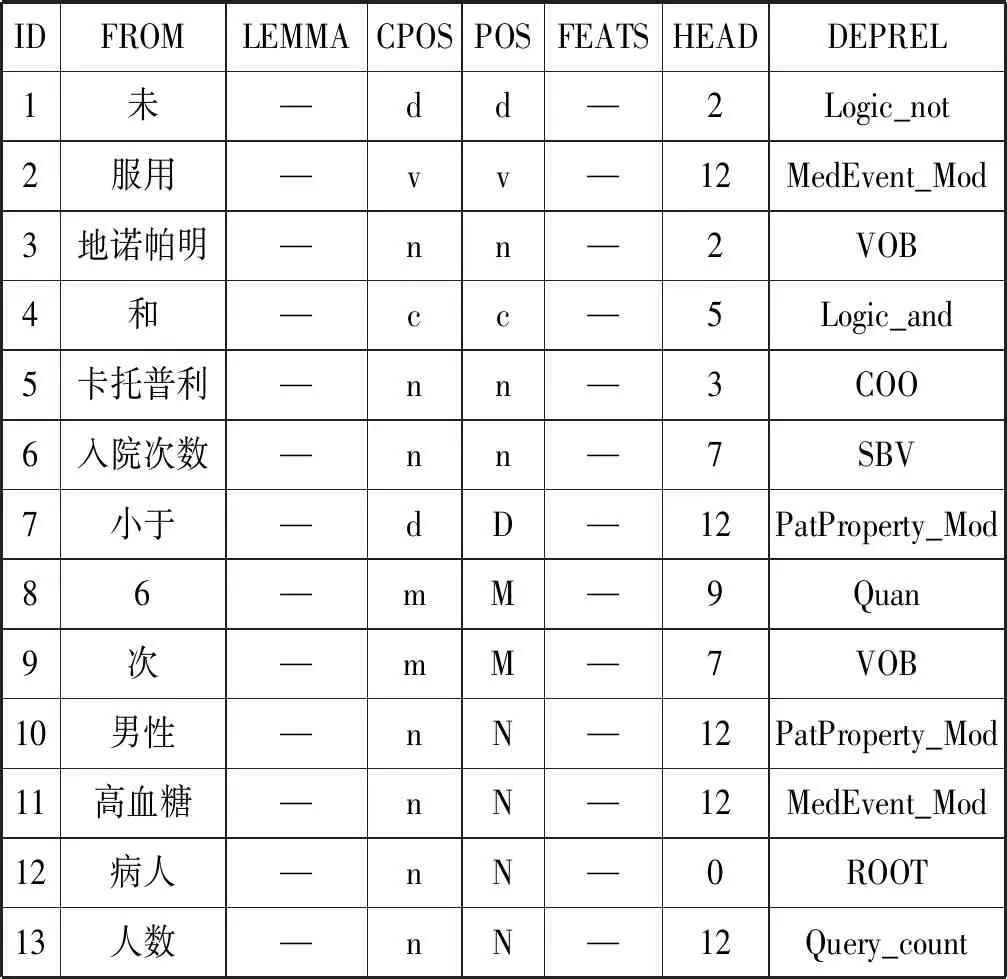
表5 依存关系树示例
首先对于依存树中的依存关系,会将其映射到语义逻辑表达式上。依存关系与语义之间往往存在一对一或多对一的映射关系。下面将介绍本文的映射方法:
(1) 对于医疗事件约束,MedEvent_Mod关系与之直接构成映射关系。例如上例中“高血糖病人”,将会映射到λx.∃y.DiseaseEvent(x,y)∧DiseaseName(y,″高血糖″)语义表达式上。
(2) 对于病人属性约束,PatProperty_Mod关系与之直接构成映射关系。例如中的“男性病人”其语义表达式为λx.Gender(x,″男性″)。
(3) 对于逻辑运算约束,一共有与或非三种不同的约束,一般出现在医疗事件之间来表示对应的逻辑关系。
(4) 对于时间先后约束,用于约束医疗事件之间的时间先后关系。例如“患有高血压前患有高血糖的患者”,将会映射到λx.∃y1.∃y2.DiseaseEvent(x,y1)∧DiseaseEvent(x,y2)∧DiseaseName(y1,″高血压″)∧DiseaseName(y2,″高血糖″)∧Before(y2,y1)。
(5) 对于数值范围约束,一般出现在病人属性项中,限制病人的某个数值属性,例如“入院次数小于6次”,会映射到语义表达式λx.λy.HospitalizationFrequency(x,y)∧Less(y,6)上。
(6) 对于统计目的约束,Query_rel依存关系与该语义直接构成映射关系,例如上述例子中的“高血糖病人人数”会映射到Count(λx.∃y.DiseaseEvent(x,y)∧DiseaseName(y,″高血糖″))语义表达式上。
(7) 对于对比关系约束,用于约束“病人”,即比较的对象一定为不同类型的病人。
最终问句映射到对应的语义逻辑表达式后,则再需要将其翻译成对应的Neo4j查询语言Cypher。其中Cypher可以分为三类查询子句,分别是:(1) match子句,用于匹配子图,一般以MATCH(p)-[r]->(n)的格式出现,其中:p和n分别代表图中的连接节点,r则表示节点之间的关系边。(2) where子句,与SQL中where语句相似,用于条件限制。(3) return子句,则是用于返回最终的查询目标。
本文利用启发式规则的方法,最终会将表5例子中的语义逻辑表达式Count(λx.∃y1.∃y2.∃y3.∃n.(DrugEvent1(x,y1)∧DrugEvent2(x,y2)∧DrugName1(y1,″地诺帕明″)∧DrugName2(y2,″卡托普利″)).HospitalizationFrequency(x,n)∧Less(n,6).Gender(x,″男性″).DiseaseEvent(x,y3)∧DiseaseName(y3,″高血糖″)),翻译为以下的Cypher查询语句:MATCH(x)-[r1:HaveTaken]->y1),(x)-[r2:HaveTaken]->(y2),(x)-[r3:SufferFrom]->(y3)WHERENOT(y1.DrugName=″地诺帕明″ANDy2.DrugName=″卡托普利″)ANDy3.DiseaseName=″高血糖″ANDx.Gender=″男″ANDx.HospitalizationFrequency<6RETURNcount(x)。
3 实 验
3.1 数据集
本文用于测试系统性能和准确性的EHR数据来自上海中医药大学附属曙光医院,其中病人的诊疗信息都有详细的记录和时间戳,并将这些关系型数据库中的数据存入图数据库Neo4j中。Neo4j库中一共有204条病人记录,324条疾病记录,49条手术记录,300条化验记录,182条药品记录,992条住院记录,992条住院信息边连接住院记录和病人,4 838条医嘱信息边连接药品记录和病人,2 792条诊断信息边连接疾病记录和病人,157条手术信息边连接手术记录和病人,117 771条化验信息边连接化验记录和病人。
本文的测试集(Test Set)共有261个医疗问题,具体由以下两部分构成:(1) 本文经过德尔菲法(Delphi Method)向临床医生收集了144个自然语言问题,将其加入到测试问题集中。(2) 同时本文在万方数据库中,使用关键字检索“电子病历/电子健康病历”、“统计/数据分析”和“流行病调查/临床科研”三种不同条件组合下的文献。在相关度排序前50篇的论文中,将16篇带有临床科研统计型问题的文献加入到测试问题集中。同时也从Caliber Research Projects[21]中选取2016年-2017年发表的所有与医疗统计相关的12篇文献中,对应的医疗统计问题也整合出来,共计117个问题。其中英语文献中的问题由上海中医药大学附属曙光医院临床医生翻译整理成中文问题。
因为目前仍缺乏大量且高质量的依存关系标注语料用于模型训练。本文通过医疗文献中收集的共86个医疗统计分析问题。同时归纳这些问题对应的句式模板,通过模板填充块的方法,结合自定义的问句多样性策略以及合法性策略,自动生成8 000条医疗统计分析问题的依存关系训练语料,以及对应的依存关系CoNLL格式。其中6 000条作为训练数据来训练神经网络以及XGBoost,2 000条数据作为验证集,并根据Blending模型中第一层的模型生成新的特征,同时按照7∶3的比例划分新的训练集和验证集,用于训练第二层的随机森林模型。最后本文为保证所生成语料的质量,随机抽取了400个问题交给上海曙光医院医生进行打分,具体评分如表6所示。
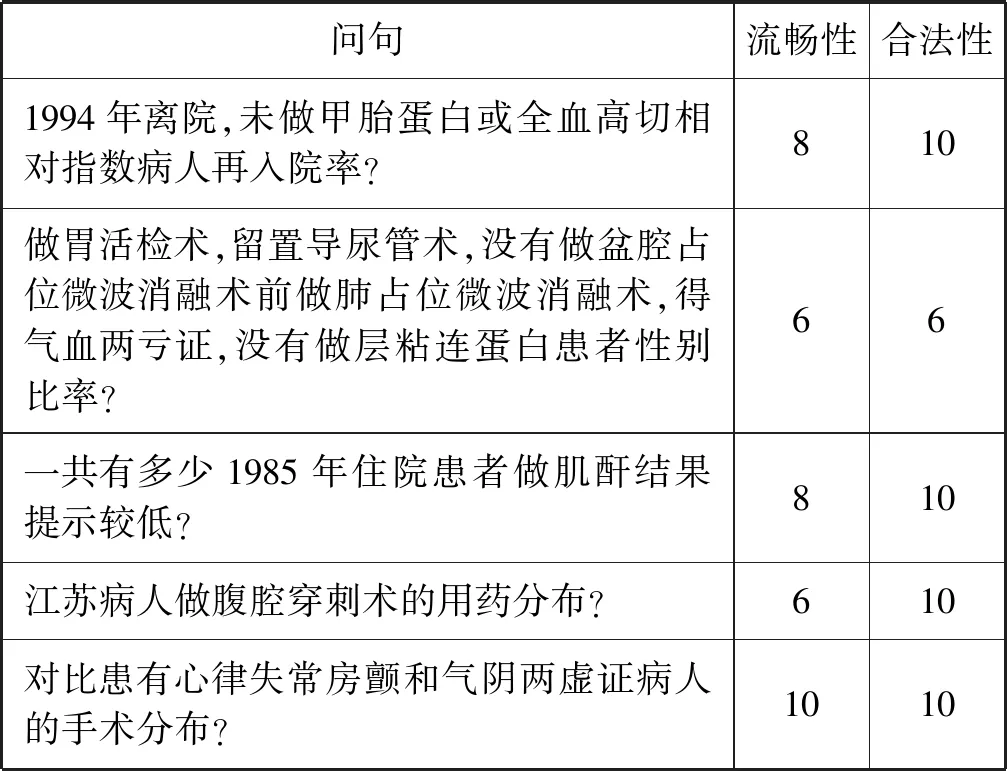
表6 部分问句评分展示
3.2 实验设置和评价指标
在本文的神经网络模型中,第一层全连接层均设为300维,第二层全连接层均设为200维。本文使用Word2vec方法进行词向量和特征向量的预训练,并将其作为嵌入层的初始化向量。训练过程采用小批量梯度下降法,学习率设置为0.01,并选用了L2正则化,lam值设置为1e-8。为了防止梯度爆炸,本文使用了梯度裁剪的方法。对于XGBoost模型,其学习器个数为100,随机列抽样和行抽样系数均设置为0.8。
同时本文选用了UAS和LAS作为模型的评测指标,具体定义如下:
(1) 无标记依存正确率(UAS):中心词预测正确的词汇数占总词数的百分比,即:
(1)
(2) 带依存标记正确率(LAS):中心词预测正确并且中心词的依存关系也正确的词汇数占总词数的百分比,即:
(2)
对于与文献[4]中基于上下文无关文法的统计式问答系统的实验对比,本文使用了如下评价指标查询正确率,具体描述如下:

(3)
3.3 实验结果对比
为了验证模型的有效性,本文在4个方面做了对比实验,如表7所示。首先,本文比较了Cube激活函数与其他三种常见的非线性激活函数,分别是Sigmod、Tanh和ReLU函数。可以明显看出cube激活函数较其他三种函数有着更好的结果,相比较于Sigmod函数在LAS指标上提高了32.4百分点,UAS指标上提高了25.52百分点。这是因为本文的Cube函数h=(WwXw+WpXp+WdXd)3,相当于对词、词性、依存关系三个维度上进行了特征组合,故而取得了较好的效果。
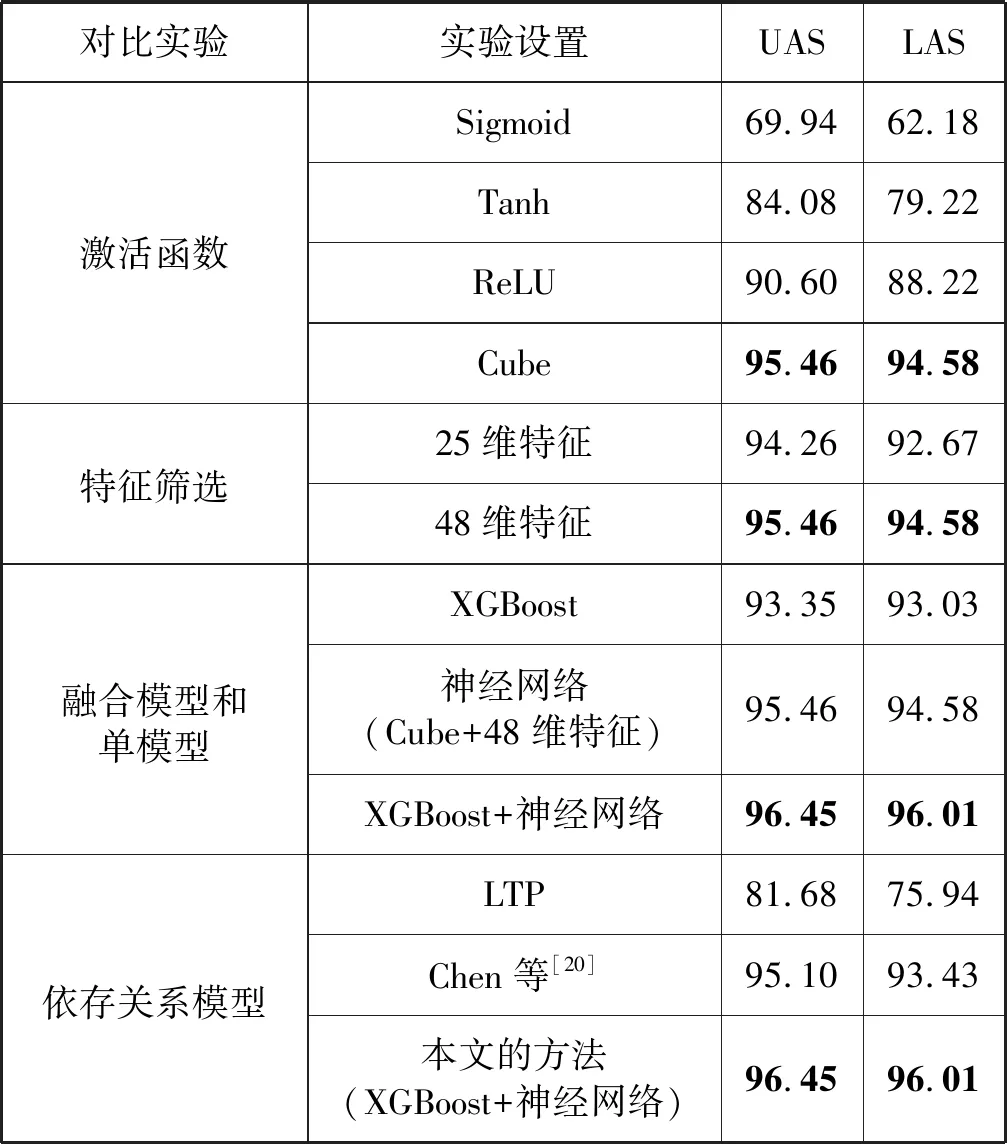
表7 本文对比实验的结果(%)
其次,本文依据XGBoost输出的特征重要性进行特征筛选。本文剔除了重要性小于100的23维特征,在剔除的特征中,共有9维是属于依存关系维度的。据此,本文为了比较不同特征对神经网络模型性能的影响,可以看到48维特征相较于特征未筛选前25模型在UAS和LAS这两个评价指标上分别高了1.20百分点和1.91百分点,这说明依存维度对于模型的训练依旧非常重要。这是因为在上述提到的Cube函数中会对其和词、词性维度上的特征进行特征组合,而组合后会有助于模型的训练。
本文使用的是基于Blending方法的融合模型,在Blending的第一层中使用的是神经网络和XGBoost,第二层使用的则是随机森林。为了验证融合模型的效果,本文在261个测试问题集上,对两个单模型以及融合模型做了性能比较。如表7所示,可以看到本文所使用的融合模型在UAS与LAS两个评价指标上相比于神经网络模型分别提升了0.99百分点、1.43百分点,而相比较于XGBoost模型上则分别提升了3.10百分点、2.98百分点。这证明了本文的融合模型在性能上有着较强的优势。
同时本文还对依存关系模型和问答系统的性能与现有方法进行了比较。在依存关系模型方面,本文和目前市面最流行的依存关系分析工具LTP以及最经典的由Chen等[20]提出的基于神经网络依存关系模型进行了对比。可以从表7看到本文提出的基于Blending方法的神经网络和XGBoost的融合模型在性能上较前两者均有提升。在UAS与LAS两个评价指标上,相比于LTP分别提升了14.77百分点、20.07百分点,同时相比于Chen等[20]的模型则分别提升了1.35百分点、2.58百分点。
目前在医疗自然语言统计问答方面,只有文献[4]与本文的研究目标一致。文献[4]基于CFGs的解析正确率为68.97%,而本文基于依存关系方法的解析正确率为81.61%。本文方法能取得更好效果的原因是在文献[4]中的上下文无关文法是利用规则递归生成问句中相邻词汇间的关系,很难将模板覆盖全面,导致能正确解析出的句式有限。如对于问句“对比a病和b病患者的用药分布”,文献[4]中因为没有制定相应的处理规则,无法生成对应的文法树。而本文提出的依存关系树是通过基于Blending的融合模型对医疗统计问题进行依存关系解析,能处理的句式相对自由,并将解析结果映射成语义表达式,翻译成Cypher查询语句后,从Neo4j中查询得到结果,故而取得了比文献[4]更好的效果,相较于文献[4]在查询结果正确率上提升了12.64百分点。
4 结 语
针对面向电子病历的医疗自然语言统计问题,本文利用依存关系分析的方法来理解自然语言问题的语义。具体而言,本文定义了面向医疗统计问题的依存关系,并通过基于Blending的融合模型进行依存分析,将自然语言问题转换成依存关系树。先将依存关系树映射至语义表达式,再根据表达式翻译成对应的Cypher查询语句,最终将查询结果以图表的形式返回给用户。本文的工作还存在一些不足,当然也是未来准备完善的部分。像“年增长率”的问题,现在的图谱还不支持,但未来只需要将其标注到正确的标签中,根据规则查询前一年的数据,结合本年数据后,保存查询中间值来解决该问题。还会出现一些头标签、关系标签的预测问题,以后可以根据先验知识制定一些规则来限制预测的输出,进一步提高精度。接下来会将图谱进一步完善,使其能更好地支持医疗自然语言统计问答。
