基于集成学习和近红外光谱的蓝莓贮藏品质检测方法研究
2023-10-09张晨朱玉杰冯国红
张晨,朱玉杰,冯国红
(东北林业大学 工程技术学院,黑龙江 哈尔滨,150040)
蓝莓,又称越橘,属杜鹃花科越橘属植物,富含花青素、维生素C、可溶性固形物等营养成分,具有抗癌、抗氧化衰老、调节血糖浓度、预防心血管疾病等功能[1],被誉为浆果之王。蓝莓采收季节较强,鲜果含水量高,容易受到挤压损伤,采摘后容易变质[2],因此通常采用低温贮藏技术延长保质期。在贮藏期间,蓝莓品质会随贮藏时间延长而快速变化,进而影响产品销售和深加工环节,因此建立一种高效准确无损的检测方法对当前蓝莓产业的发展具有重要意义。
由于拥有快速和无损的优势,近红外光谱技术在农业[3-5]、林业[6-8]和中草药[9-10]等领域得到广泛应用。例如孙晓荣等[11]利用近红外光谱技术实现快速无损检测小麦粉的品质,刘翠玲等[12]利用近红外光谱技术实现对京郊鲜食杏品质的快速无损检测,汤文涛等[13]利用近红外光谱技术对山核桃的蛋白质和脂肪含量进行快速检测,关晔晴等[14]利用近红外光谱技术实现对蜜桃果实内部品质快速检测。
当前对蓝莓各成分无损检测研究较多[15-19],但模型准确度和泛化能力均有待提高。本文以丹东瑞卡蓝莓和绿宝石蓝莓为研究对象,通过实验获得瑞卡蓝莓不同贮藏时间和绿宝石蓝莓不同成熟度的近红外光谱、花青素、可溶性固形物和维生素C相关数据,使用竞争性自适应重加权采样法(competitive adaptive reweighted sampling, CARS)对预处理光谱进行特征波长筛选,将支持向量回归(support vector regression, SVR)、极端梯度上升(extreme gradient boosting, XGBoost)和多层感知机(multilayer perceptron, MLP)作为基模型,采用Stacking融合策略,建立基于集成学习的蓝莓贮藏品质无损检测模型。研究结果表明,与SVR、XGBoost和MLP模型相比,本文所提出的Stacking集成学习模型具有更高的精度、稳定性和泛化能力,可为蓝莓无损检测研究提供新的思路。
1 材料与方法
1.1 实验材料
本实验选用品种相近,果实大小相同,果皮无损伤的辽宁丹东瑞卡蓝莓和绿宝石蓝莓作为样本,瑞卡蓝莓成熟度相同,绿宝石蓝莓成熟度不同,每个样本中含有20枚果实,瑞卡蓝莓共计150个样本,绿宝石蓝莓共计30个样本。将瑞卡蓝莓样本进行编号,放置在4 ℃的生化培养箱中进行贮藏,之后在第0、3、6、9、12天分别测量30个样本的近红外光谱、可溶性固形物、维生素C和花青素含量。将绿宝石蓝莓进行编号,在第0天测量所有样本的近红外光谱、可溶性固形物、维生素C和花青素含量。
1.2 仪器与设备
LabSpec 5000型光谱仪,美国ASD公司;LYT-330手持式折光仪,上海淋誉公司;UV-1801紫外可见分光光度计,北京北分瑞利公司;SPX-70BⅢ型生化培养箱,天津泰斯特公司。
1.3 数据采集
本实验采用近红外光谱仪及其漫反射组件对蓝莓近红外光谱进行采集,在采集过程中为了减小误差,对样本中的每个果实采集3次光谱,将60个光谱的平均值作为该样本的近红外光谱数据。仪器参数设定:光谱波长范围为500~2 300 nm,采集间隔1 nm,扫描次数32。原始光谱图和瑞卡蓝莓不同贮藏时间平均光谱图如图1所示。
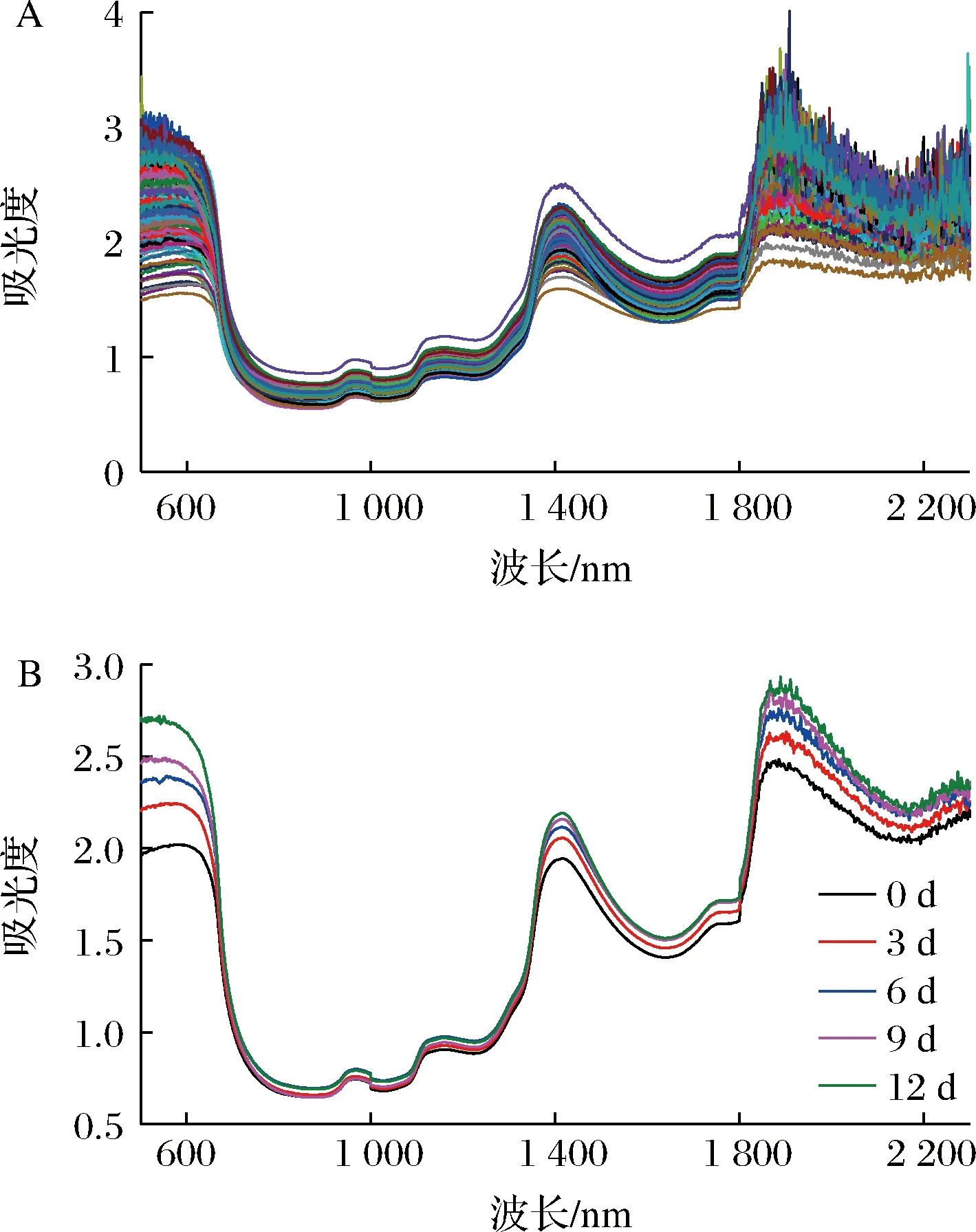
A-蓝莓原始光谱曲线;B-瑞卡蓝莓不同贮藏时间平均光谱曲线图1 蓝莓近红外光谱曲线Fig.1 Near infrared spectrum curve of blueberry
本实验采用折光仪对蓝莓可溶性固形物的含量进行采集。在使用蒸馏水对折光仪进行零点校正后,吸取样本果汁滴入折光仪进行读数,获取样本中可溶性固形物含量,其中每个样本测量3次,将3次平均值作为该样本的可溶性固形物数据。
样本中维生素C和花青素含量通过标准曲线法进行测量,参考文献[20]中的方法,分别制作出维生素C 标准曲线和花青素标准曲线。从样本中取出2 g蓝莓,加入2 mL的10%(体积分数)HCl溶液进行研磨,使用蒸馏水定容至25 mL;取出2 mL溶液,加入0.2 mL 10% HCl和0.4 mL 1% HCl,用蒸馏水定容至10 mL,最后使用分光光度计测量其243 nm处吸光度,查找标准曲线,计算出样本维生素C的含量。从样本中取出2 g蓝莓,加入少量1%(体积分数)盐酸-甲醇溶液,研磨后继续使用溶液定容至20 mL,之后放置在4 ℃的保温箱中25 min。静置完成后过滤溶液,放置在离心机(4 000 r/min)中离心10 min,取出上层清液1 mL,使用蒸馏水稀释至8 mL,测出吸光度,查找标准曲线,计算出样本花青素含量。瑞卡蓝莓可溶性固形物、花青素和维生素C平均测量值随贮藏时间变化如图2所示。

图2 瑞卡蓝莓不同贮藏时间平均理化指标曲线Fig.2 Average physicochemical index curve of Ricca blueberries at different storage times
1.4 贮藏品质分析
由图2可知,在贮藏期间,可溶性固形物含量呈上升趋势,花青素和维生素C含量呈下降趋势,这与文献[21]的实验结果具有一致性。将可溶性固形物、花青素和维生素C进行标准化处理,采用主成分分析的方法构建蓝莓贮藏品质综合得分[22-23],首先对上述指标进行主成分分析,构建3个新的相互独立的综合指标,其次按照各综合指标的方差贡献率,对综合指标进行加权求和,计算每个蓝莓样本的综合得分,瑞卡蓝莓样本综合得分如图3所示。
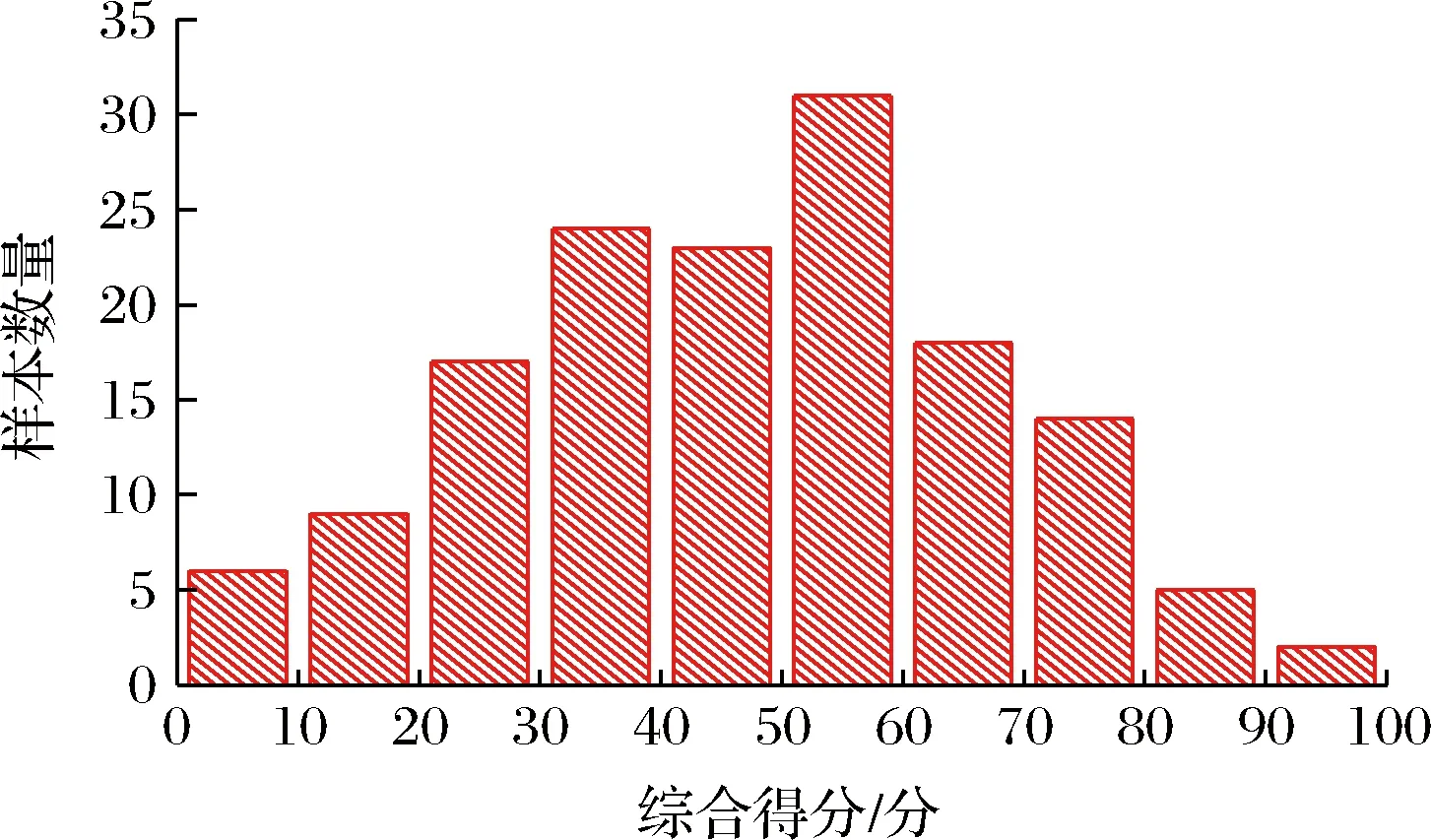
图3 综合得分图Fig.3 Comprehensive score distribution
参照NY/T 3033—2016《农产品等级规格 蓝莓》的规定,根据蓝莓贮藏品质综合得分,采用K均值聚类方法(K-means clustering,K-means),将瑞卡蓝莓150个样本分为三类,其中一级品可溶性固形物、花青素和维生素C的均值分别为10.4、10.3、20.4;二级品均值分别为11.1、8.8、17.0;三级品均值分别为11.9、7.3、13.1。样本中贮藏品质随贮藏时间变化如图4所示,可以明显看出随着贮藏时间的延长,一级品数量在前3天内快速减少,在后9天内缓慢减少,三级品数量在前6天内缓慢增加,在后6天内快速增加。

图4 贮藏品质变化曲线Fig.4 Variation curve of storage quality
1.5 数据划分
本文采用光谱-理化值共生距离法(sample set partitioning based on joint X-Y distance, SPXY)将瑞卡蓝莓样本划分为训练集和验证集,其中训练集和验证集的比例为4:1,绿宝石蓝莓样本为测试集。SPXY是基于K-S(Kennard-Stone)算法提出的一种改进方法,K-S算法依据特征维度欧氏距离对数据集进行划分;而SPXY算法,在此基础上增加了对不同样本标签维度方向的欧氏距离的计算,并通过正则化将2种距离结合,更加全面地评估和划分数据集。特征维度欧氏距离、标签维度欧式距离和正则距离计算如公式(1)~公式(3)所示。样本划分结果如表1所示。

表1 训练集样本和测试集样本结果统计Table 1 results statistics of training set samples and test set samples
(1)
(2)
(3)
式中:p,q为数据集中的一对样本;J表示特征维度;maxp,q∈[1,N]dx(p,q)和maxp,q∈[1,N]dy(p,q)分别为数据集中最大特征维度欧氏距离和最大标签维度欧式距离。
1.6 光谱预处理
由于蓝莓果实外形的差异以及环境的影响,原始光谱存在大量干扰信息,主要表现为光源散射、基线重叠和噪声,因此为了减少相关因素的影响,需要对光谱数据进行预处理。本文选用标准正态变换(standard normal variate transformation, SNV)、数据标准化(Z-score standardization, Z-score)、一阶导数(first derivative, 1st-D)、二阶导数(second derivative, 2nd-D)4种预处理方法对原始光谱进行处理,选用偏最小二乘方法(partial least squares regression, PLSR)对预处理后的数据进行建模,采用相关系数R2、均方根误差(root mean square error, RMSE)和相对分析误差(relative percent deviatio, RPD)对模型进行评价,计算方法如公式(4)~公式(6)所示:
(4)
(5)
(6)

通常所建模型的RMSE越小,R2越接近1,预测效果越好,但是在实际建模过程中,一般设定R2为0.66~0.80时,刚好达到预测效果;R2为0.81~0.90时,预测效果较好;R2>0.90时,预测效果最佳。RPD主要对模型可靠性进行衡量,当RPD<1.4时,认为所建模型可靠;当RPD为1.4~2.0时,认为所建模型较可靠;当RPD>2.0时,则认为所建模型有较高可靠性,能够用于模型分析。各种光谱预处理方法建模结果如表2所示。
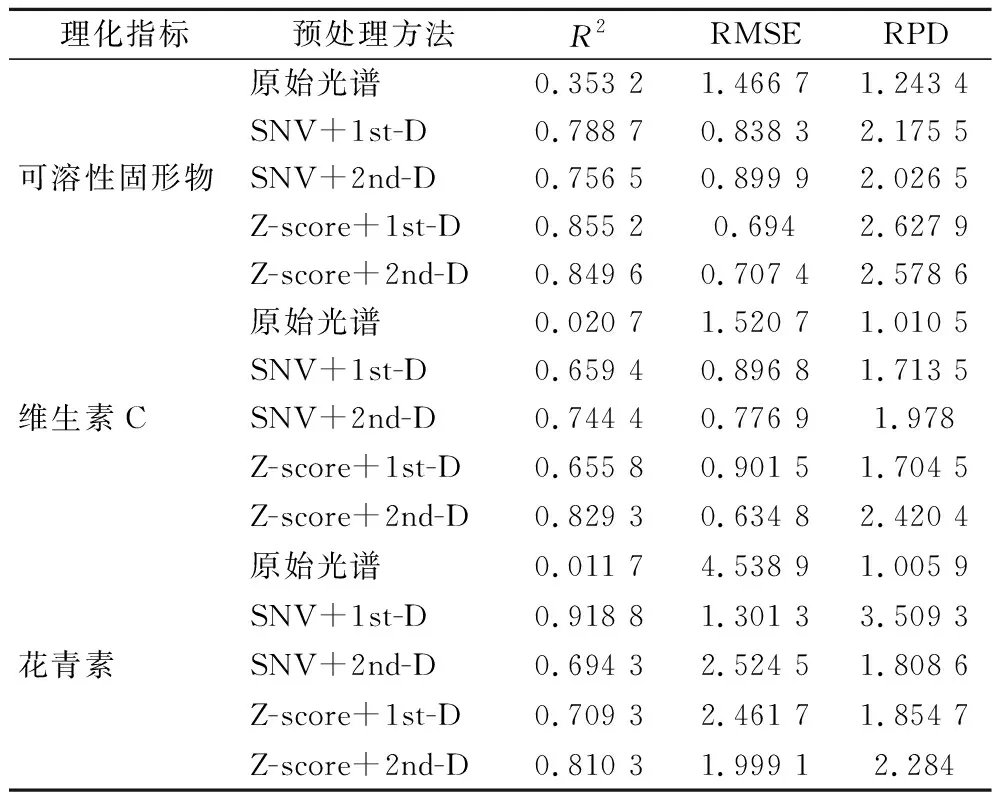
表2 不同光谱预处理方法建模结果Table 2 modeling results of different spectral pretreatment methods
从表2可知,采用预处理方法后能够大幅提高模型的相关系数和相对分析误差,减少RMSE,其中可溶性固形物、维生素C和花青素最优模型的R2均大于0.81,RPD均大于2,说明采用近红外光谱对蓝莓贮藏品质进行无损检测是可行的。由表2可知,可溶性固形物最优预处理方法为Z-score+1st-D;维生素C最优预处理方法为Z-score+2nd-D;花青素最优预处理方法为SNV+1st-D。
1.7 提取特征波长
预处理后的光谱数据中含有大量的冗余信息,严重影响模型的鲁棒性和准确性,为了简化模型结果和提高预测精度,本文使用竞争性自适应重加权采样法(competitive adaptive reweighted sampling, CARS)对蓝莓近红外光谱特征波长进行筛选。由于CARS算法具有随机性,本文多次重复,选择选取最佳波段,算法迭代过程中RMSE以及被选择波长数量变化如图5所示,最优波长数量信息如表3所示。
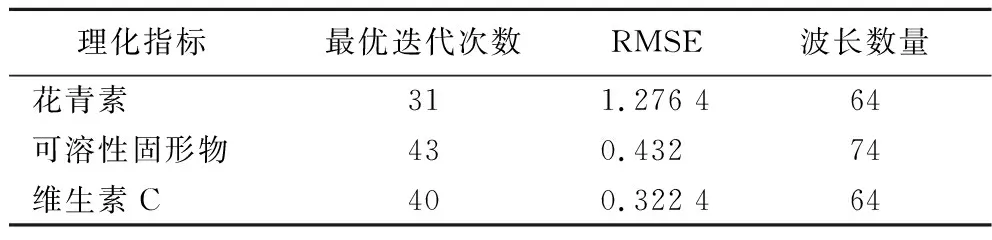
表3 最优波长数量信息表Table 3 Optimal wavelength number information table

A-RMSE曲线变化;B-波长数量曲线变化图5 RMSE和波长数量变化图Fig.5 RMSE and wavelength number changes
2 算法原理
集成学习是训练多个机器学习模型并将其输出组合在一起的过程,致力构建一个最优的预测模型。集成学习可以提高整体模型的稳定性,从而获得更准确的预测结果,其关键在于基模型的选择和融合。
2.1 基模型选择
本文利用K邻近算法(K-nearest neighbor, KNN),随机森林(random forest, RF)等10余种常见机器学习模型对数据进行训练,其中SVR对数据异常值具有鲁棒性,训练速度快,泛化能力强;XGBoost对于中低维数据有很好的处理速度和精度,具有一定的抗噪能力;MLP具有自适应自学习能力,对数据拟合能力强,预测精度高。
2.1.1 SVR
SVR是一种回归模型,与一般线性回归相比,SVR首先在损失计算上不考虑间隔带ε范围内的误差;其次通过最大化间隔带的宽度与最小化损失函数来优化模型。SVR算法回归估计函数如公式(7)所示,其中w,b分别为系数矩阵和常数项,φ(x)为样本数据与高维特征空间的映射函数。利用公式(8)计算得到w和b:
(7)
(8)
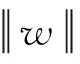
2.1.2 XGBoost
XGBoost是基于提升树的Boosting算法,其原理是把每个弱模型的输出结果当成连续值,使得损失函数连续,进而通过对弱模型迭代达到损失函数最小,最终完成对整个模型的优化。XGBoost最终预测结果为所有弱模型输出结果之和,计算方法如公式(9)所示:
(9)
XGBoost目标函数如公式(10)所示:
(10)
式中:n表示样本数量,yi表示样本i的真实值,l为真实值和预测值之间的损失函数,Ω为弱模型的复杂度函数,c为公式合并后的常数项。
2.1.3 多层感知机(multilayer perceptron, MLP)
MLP也称为人工神经网络,其结构包括输入层、输出层和隐藏层,通过线性变换和非线性函数激活的方式进行特征变换,使用小批量梯度下降和反向传播更新MLP中的参数,最后完成对整个模型的优化。损失函数的计算如公式(11)所示:
(11)
2.2 融合策略
按照基模型是否相同,融合策略可以分为同质集成和异质集成,其中同质集成按照基模型之间是否存在依赖关系,可以分为并行Bagging集成和串行Boosting集成;异质集成按照元模型训练数据选取的不同,可以分为Stacking集成和Blending集成。为了充分利用样本数据,本文采用Stacking集成策略融合SVR、XGBoost和MLP建立蓝莓贮藏品质无损检测模型,算法整体架构如图6所示,其流程共分为5步。

图6 Stacking集成学习整体架构图Fig.6 Stacking ensemble learning architecture
a)如图7所示,在训练SVR、XGBoost和MLP 3个基模型时,将训练集数据划分为5个相等的集合,取其中一份进行预测,其余进行训练。
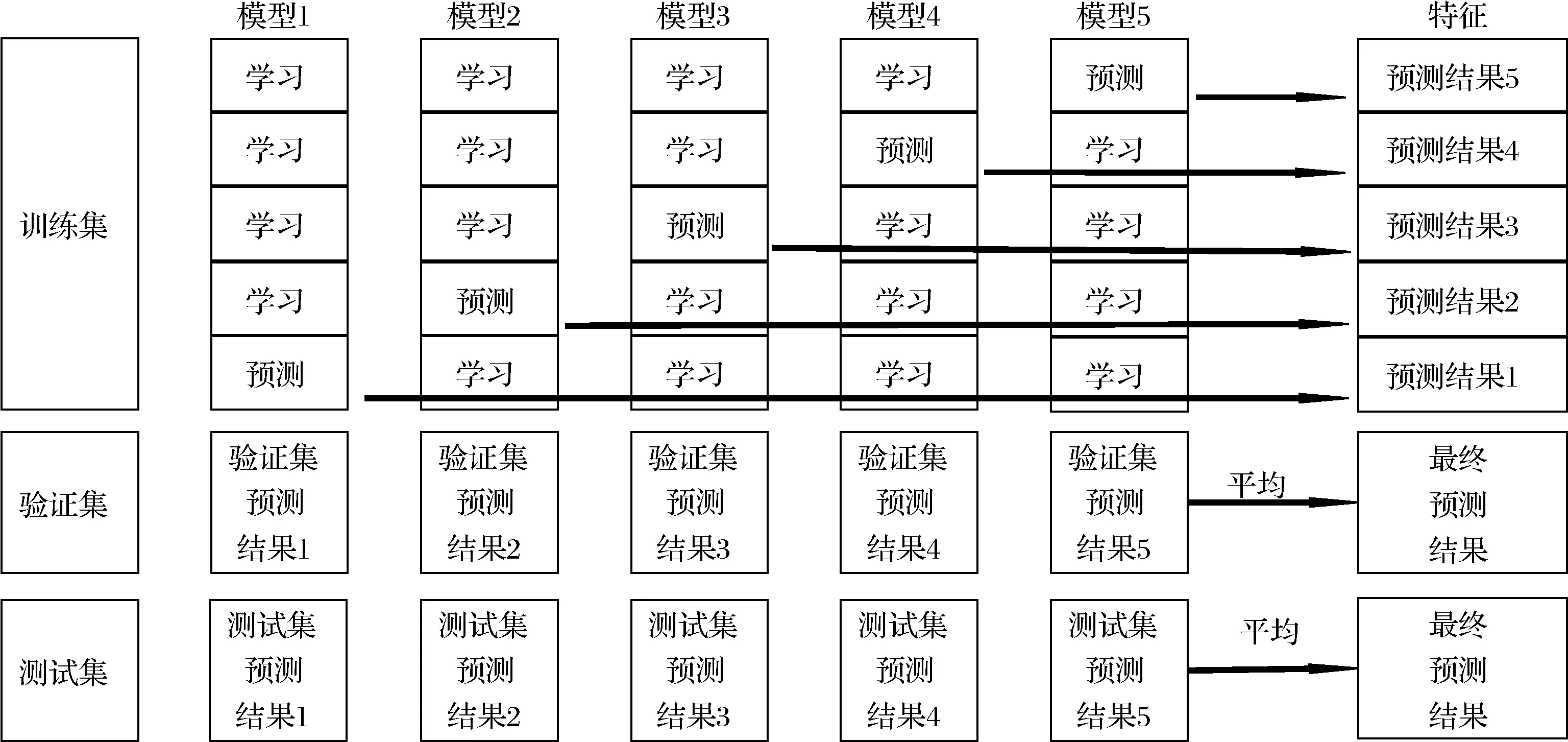
图7 基模型数据流程图Fig.7 Base model data flow diagram
b)每个基模型都要进行5折叠交叉验证,验证完成后,将训练集预测结果合并构成元模型训练集特征。
c)使用所有基模型的交叉验证模型,对验证集和测试集进行预测,将得到的5次预测结果求取平均值,获得元模型验证集特征和测试集特征。
d)如图6所示,将获得的3个特征进行合并,构建元模型XGBoost的训练集、验证集和测试集。
e)利用新的训练集、验证集和测试集对元模型XGBoost进行训练、验证和测试,得到最终结果。
3 结果与分析
为了检验本文提出的Stacking集成学习算法的有效性,将其与SVR、XGBoost、MLP算法进行比较,各算法建模结果如表4所示。与其他单一预测模型相比,本文所提出的Stacking集成学习效果最优,其中维生素C预测模型相关系数R2为0.872 6,RMSE为0.566 4,RPD为2.801 6;可溶性固形物预测模型相关系数R2为0.881 4,RMSE为0.696 3,RPD为2.903 7;花青素预测模型相关系数R2为0.905 5,RMSE为1.693 9,RPD为3.253。上述所有模型的相关系数R2均大于0.81,RPD均大于2,说明本文所提出的模型具有较高的精度和稳定性,以及良好的泛化性。维生素C、可溶性固形物和花青素测测试集的预测值与真实值分布散点图如图8~图10所示。
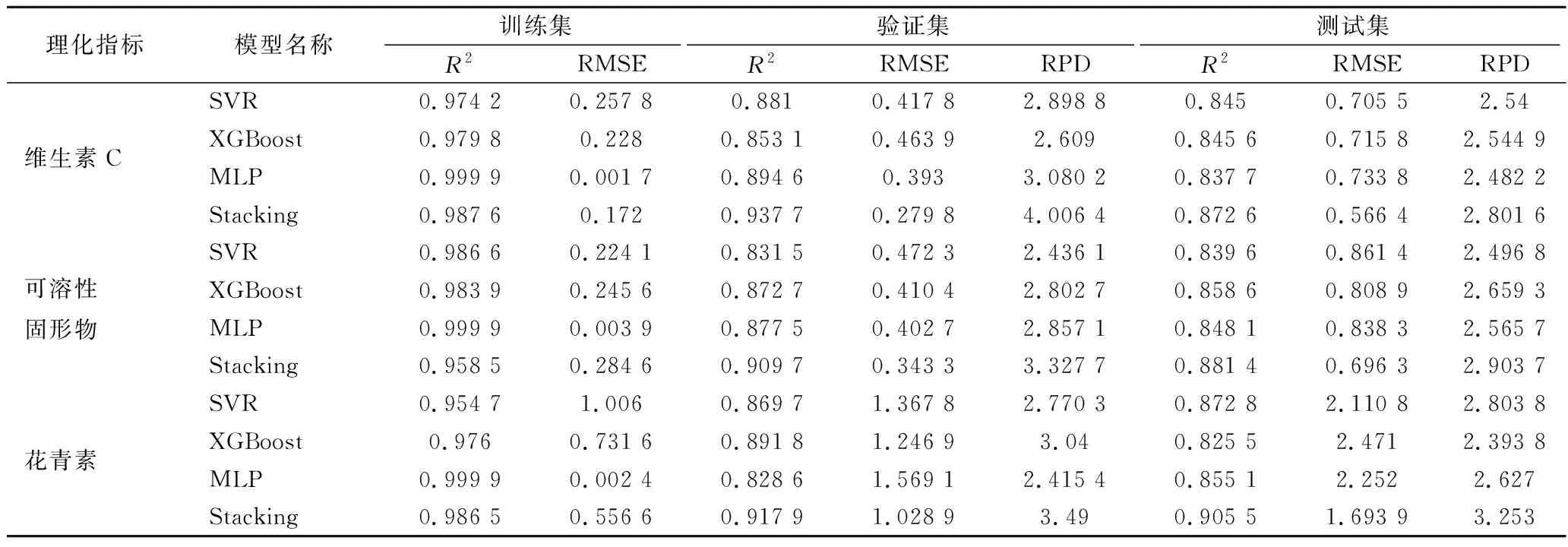
表4 不同算法建模结果Table 4 Modeling results of different algorithm
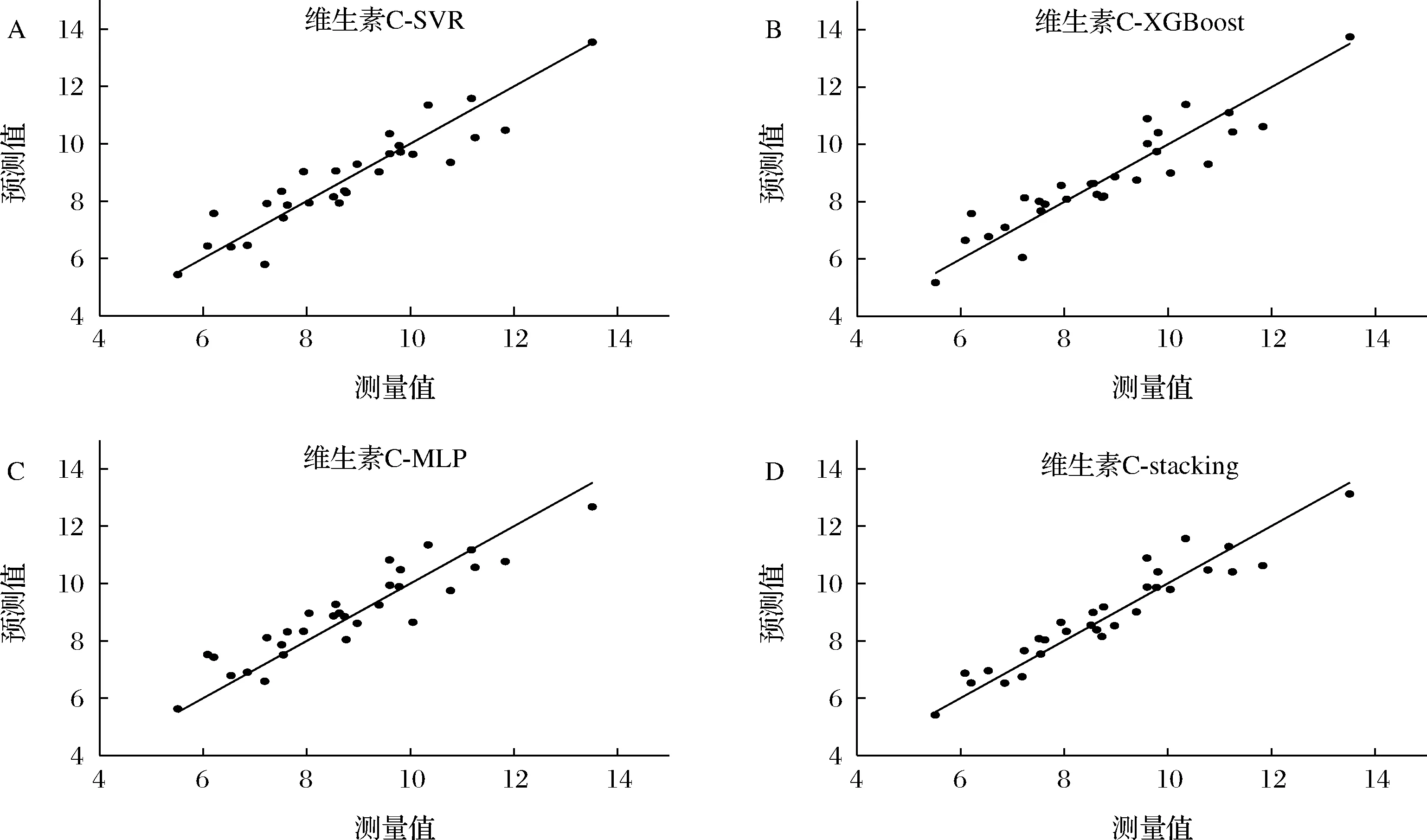
A-SVR模型散点图;B-XGBoost模型散点图;C-MLP模型散点图;D-Stacking模型散点图图8 维生素C预测值与真实值散点图Fig.8 Scatter plot of predicted and true values of vitamin C
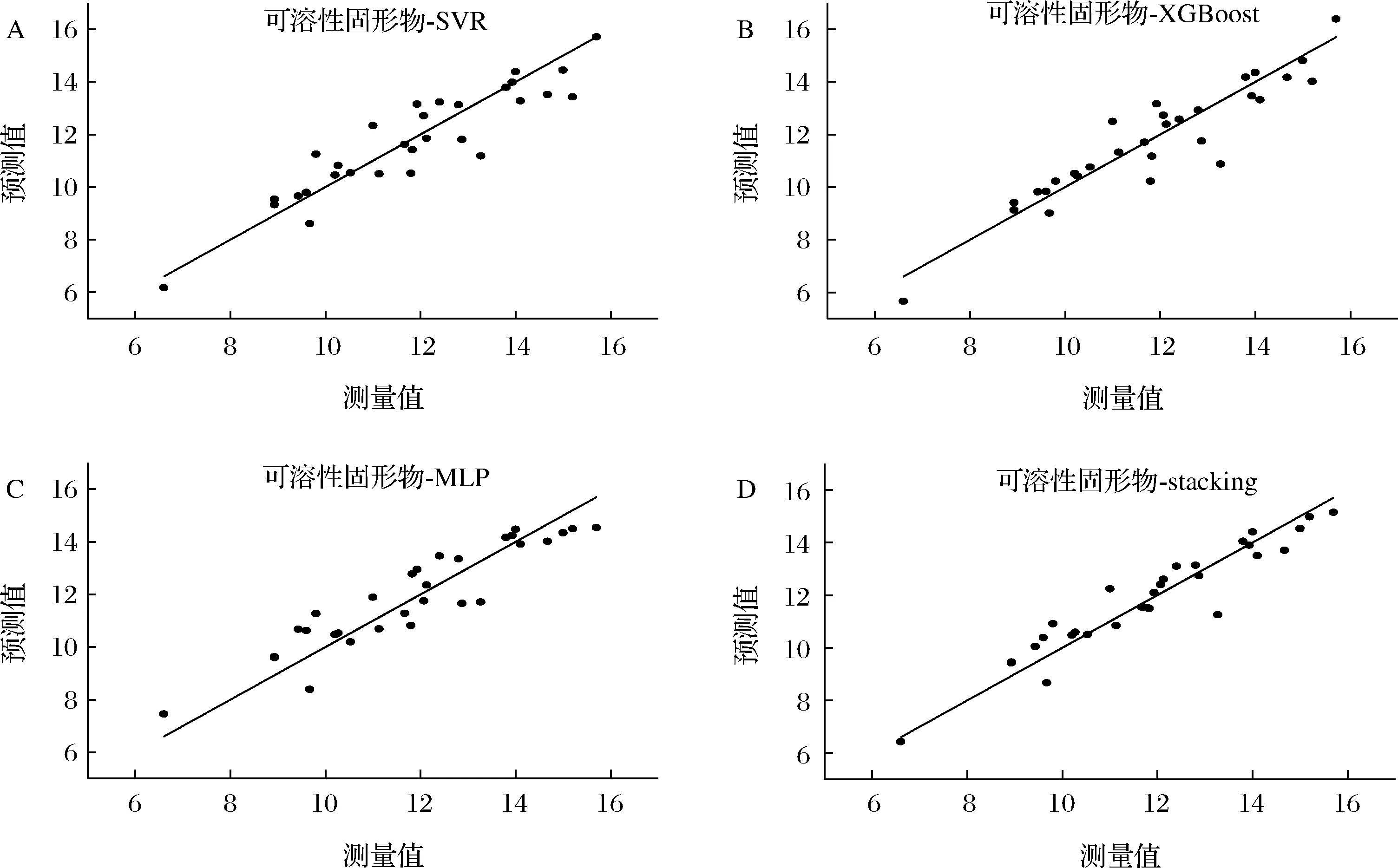
A-SVR模型散点图;B-XGBoost模型散点图;C-MLP模型散点图;D-Stacking模型散点图图9 可溶性固形物预测值与真实值散点图Fig.9 scatter plot of predicted and true values of soluble solids content

A-SVR模型散点图;B-XGBoost模型散点图;C-MLP模型散点图;D-Stacking模型散点图图10 花青素预测值与真实值散点图Fig.10 Scatter plot of predicted and true values of anthocyanin
4 结论
本文以品种相近的丹东瑞卡蓝莓和绿宝石蓝莓为研究对象,采集不同贮藏时间的瑞卡蓝莓和不同成熟度的绿宝石蓝莓近红外反射光谱和理化指标,之后利用4种算法,建立蓝莓贮藏品质无损检测模型,最终得出如下结论:
a)通过比较4种光谱预处理方法,发现可溶性固形物最优预处理方法为Z-score+1st-D,维生素C最优预处理方法为Z-score+2nd-D,花青素最优预处理方法为SNV+1st-D。
b)采用竞争性自适应重加权采样法对预处理光谱进行处理,能够有效对特征波长进行筛选,简化了模型复杂度,提高了预测精度。
c)与SVR,XGBoost和MLP模型相比,本文所提出的Stacking集成学习模型具有更高的精度和稳定性,以及更好的泛化能力,其中维生素C预测模型的相关系数R2为0.872 6,可溶性固形物预测模型的相关系数R2为0.881 4,花青素预测模型的相关系数R2为0.905 5。
