基于机器学习的激光测距墙线目标自动分类方法*
2023-10-08蔡文郁刘一博吴培鹏盛庆华
蔡文郁,刘一博,吴培鹏,盛庆华
(杭州电子科技大学,电子信息学院,浙江 杭州 310018)
近年来,我国电网的基础建设取得了迅速发展,电力巡检的一项重要任务是检测架空输电线路的安全距离,巡检常用的方法有激光测距[1-3]、图像识别[4-5]等。 文献[6-7]在巡检无人机上使用图像处理技术进行目标检测和缺陷识别,但对于复杂环境或自然缺陷[8]样本的识别较差。 文献[9-10]通过GPS 定位获得机载的位置后使用激光测距技术精确定位输电线故障点位置,定位偏差约为0.1 m ~0.4 m。 由于激光测距具有精度高、测距时间快、测量结果直观等特性,因此在线路巡检量测中应用最为广泛。
虽然目前激光测距的研究已较为成熟,但在远距离电力巡检等复杂环境下,易受到环境干扰,例如光学镜头引入的背景噪声,天气环境的影响,被测目标的反射面情况,这些因素仍会影响测距精度。 由于电线圆柱体的特性,电线表面上不同位置对应的反射角度不同,因此激光光斑打在电线反射面的不同位置,将导致回波信号强度和上升沿速度与墙目标存在差异。 文献[11-14]研究了被测目标的距离、反射面,环境的光强、湿度等外部因素对激光测距误差的影响。 文献[15-17]使用了双阈值时刻鉴别法、高通阻容时间鉴别法和多延迟触发等方法消除回波强度变化引起的时间漂移误差。 近年来,深度学习技术在激光测距领域有较多应用,胡善江等[18]使用LeNet 模型解算回波时刻,Xu 等[19]使用CNN 模型自动学习回波信号的特征,但其真实环境下数据集的建立以及泛化能力仍值得探讨。 因此,可以发现,大小不同的测量目标特征对测距结果有明显的影响,必须进行区分处理。 虽然上述研究对激光测距回波信号的反射特征进行了初步研究,但是并没有对以墙为典型的大目标、以线为典型的小目标实现目标自动分类。
为了提高激光测距系统在电力巡检场景下测量不同目标物体的精度,本文研究了数据预处理滤波和统计机器学习分析方法,提出了一种基于机器学习的激光测距墙线目标分类方法。 通过建立XGBoost+LR 墙线分类模型,使用XGBoost 模型进行特征组合重构训练集,使用RF 模型对稀疏训练集进行特征筛选降低维度,最后采用LR 模型进行线性区分,实现墙线等大小目标的自动分类。
1 基于机器学习的激光测距墙线目标分类方法
1.1 激光测距模型
为了实现远距离测距,本文采用脉冲飞行时间(Time of Flight,TOF)激光测距技术,并且引入多阈值误差拟合修正方法[20]和自动增益控制电路[21]以提高测距精度和测距量程。 本文所研究的激光测距系统模型如图1 所示。

图1 激光测距系统模型
图1 所示的数据采集模块从激光测距仪硬件中获得测量数据,主要原理是控制电路触发激光管发射脉冲并标定为起始时刻tstart,自动增益控制电路根据回波信号幅值自动调整接收电路增益q,使其满足大于阈值电压V1的条件,而且标定此时为停止时刻tend,时间测量模块计算激光脉冲的飞行时间tend-tstart计算出离被测目标的距离dist =c×(tendtstart)/2,式中c为光在真空中传播速度3×108m/s。如图1 所示,设定阈值电压V2、V3,假设V2对应时刻为t2,定义阈值时间差Δt用于修正补偿距离,计算公式如下:
Δt值越小,波形上升沿时间越短,即更加接近于理想的高斯脉冲信号。 定义饱和度g用于判定波形是否饱和,当波形幅值达到阈值电压V3,判定为波形饱和,反之判定为波形不饱和。
因此,激光测距仪数据即为分类模块的输入样本空间T{x1,x2,…,xN},每个样本xi包含增益q、测量距离dist、阈值时间差Δt和饱和度g四个变量值。 由于系统固有的干扰和噪声具有随机不确定性,因此必须进行数据预处理。 本文采用自适应k-Means 算法,从含有噪声的数据中聚类出有效数据作为新的样本空间T′。
测量墙面等大目标时,回波信号幅值较大;测量电线等小目标时,回波信号幅值较小且上升沿缓慢[22]。 虽然墙线不同目标的激光测距回波数据分布存在着差异,但是回波信号的差异经过自适应放大调理后,已经无法直观显示不同测量目标的区别。仅仅依靠电路增益、测量距离、阈值时间差等变量无法完全区分出测量目标,因此本文从样本空间T′中计算了新的11 维特征向量f{X1,X2,…,X11},综合使用XGBoost+LR 机器学习模型训练由J个特征向量f构成的特征空间F{f1,f2,…,fJ},从而得到墙线二分类模型。 通过上述过程,输出样本空间T′和该样本空间对应的测量目标标签y,最终对墙和线不同测量目标进行不同的修正处理方法。
1.2 特征空间选择
经实际数据测试与分析可以发现,墙和线目标主要存在以下差异:
①测量近距离墙等大目标时,回波信号基本饱和,即在较低增益下就可以得到较多的测距结果,测量出错次数较少,距离、阈值时间差等波动较小且稳定。
②当测量目标为线等小目标时,回波信号幅值受实际测量距离、对准等因素影响,电路增益较高,测距结果数量较少,测量出错次数相对较多。
根据以上测量差异,本文从样本空间T′中提取出以下11 维数据特征,如表1 所示。

表1 特征数据
以下为各个特征数据在不同测试环境下的分布情况,圆形标注的数据为测量目标为线目标的实际测量数据,叉形标注的数据为测量目标为墙目标时的实测测量数据。 图2 表明在不同维度特征下不同测量目标分布情况存在一定差异,但是单独使用某一个维度特征无法完全实现墙线等目标的自动分类。

图2 墙目标和线目标的不同特征测试数据
1.3 基于自适应k-Means 聚类的数据预处理方法
云雾、雨滴、粉尘等对回波信号产生散射效应,同时太阳光中包含了测距激光所在波长段的能量干扰。 这些散射噪声具有随机性和不确定性,因此本文提出了一种自适应k-Means 聚类算法,用以激光测距中噪声数据的筛选与剔除。 图3 为测试集1(100 m 测距情况)的阈值时间差数据分布情况,横坐标为距离dist 值,纵坐标为阈值时间差Δt。 有效数据(label0,图中圆形标注)的测试结果较多且密集度高,由云雾、雨滴、粉尘等因素引起噪声(如label1,图中下三角标注)的分布表现为局部密集,但数据量少于正常数据,由太阳光等因素引起的噪声,分布表现为空间范围内零散随机出现。

图3 测试集1(100 m 测距)数据分布图
本文提出了一种自适应k-Means 聚类算法,从含有噪声的样本空间中提取出干净的有效样本,主要步骤如下所示:
①通过计算样本空间的密度参数来确定初始的聚类中心位置,避免因随机选取初始聚类中心而造成的震荡。
②以最快降低误差平方和(Sum of Squared Error,SSE)为目的,自适应调整聚类中心个数,降低离群点对迭代过程的影响。 具体地,算法首先使用RobustScaler 方法[23]对样本空间T{x1,x2,…,xN}进行标准化处理,计算公式如下:
式中:Q(index)为数据x中索引index 的分位数,Q(50)表示数据x的中位数,Q(75)-Q(25)表示x的四分位距。 RobustScaler 方法相较于Min-Max 归一化方法[24]降低了离群值对标准化的影响,相比ZScore 中心化方法[24]最大限度地保留了离群值特征。
③定义样本xi局部密度函数Density(xi),其值为5 个最近邻样本距离xi的欧氏距离平均值。 将样本空间中最密集点定义为第一个聚类中心C1,将最稀疏点定义为第二个聚类中心C2。
④迭代过程同K-Means,计算样本xi与每个聚类中心的相似度(欧氏距离),并将样本归于最近的聚类中心Ck。 如果最大SSE 样本的误差大于设定阈值,则将该样本定义为新的聚类中心,并更新此样本的近邻点,以快速降低SSE 并减少离群点对聚类效果的影响。
⑤重复迭代过程,直到聚类中心不再更新或满足迭代条件,输出样本最多的簇作为新的样本空间T′。
1.4 基于XGBoost+LR 机器学习的多特征融合分类方法
本文使用XGBoost+LR 机器学习算法建立多特征融合的墙线分类模型,以解决墙线目标之间的量化误差问题和学习特征组合必要性的问题。 由于LR 模型对于特征组合上存在学习局限性,而GBDT模型正好可以用来挖掘特征之间的关联,将回归树中每个节点的分裂看作是自然的特征选择过程,多层节点的结构对特征进行了有效的自动组合。GBDT+LR 结合模型[25]将LR 和GBDT 两个模型相结合完善分类模型,GBDT 进行特征组合,将数据高维化,使其变得线性可分,带正则项的LR 线性模型对于高维的稀疏矩阵有很好的处理能力,并不容易过拟合。 XGBoost 使用牛顿法进行梯度更新,对损失函数进行了二阶泰勒公式展开并加入了正则项,获得了比GBDT 更优的运算速度和精度。 本文以XGBoost模型代替GBDT+LR 结合模型中的GBDT 模型,同时,由于XGBoost 输出的特征组合向量高度稀疏,因此在LR 模型前加入一层RF 特征选择层,以降低模型复杂度,图4 为XGBoost+LR 结合模型框架。

图4 XGBoost+LR 墙线分类模型
图4 中XGBoost 模型对含有J个样本的数据集T{(f1,y1),(f2,y2),…,(fJ,yJ)}进行训练,得到含有M棵CART 决策树的分类模型。 将样本xi落在第m棵决策树Tm的叶节点位置标记为1,其余叶节点标记为0,则可得到该棵树的稀疏向量lm,组合M棵树的稀疏向量构成该样本xi特征组合向量(li1,li2,…,liM),最终组合所有样本点获得新的训练数据集T{(l1,y1),(l2,y2),…,(lJ,yJ)}。
由上可知,对于复杂度(决策树个数)为complexity,深度(决策树大小)为depth 的XGBoost 模型,其最大叶结点个数为complexity×2depth,其中标记为1 的个数为complexity,构成的新训练集高度稀疏,且这种稀疏程度受模型复杂度和深度影响,过大的特征维度将导致LR 分类器参数更新缓慢且易过拟合。 因此,在LR 分类模型训练前,本文使用随机森林RF 算法对特征组合向量l进行重要度评估,筛选出重要程度较高的部分特征,筛选阈值定义为:
筛选后的数据集缩小为T′,送入LR 分类器进行训练得到墙线目标二分类模型。
2 实验与测试结果
2.1 数据聚类去噪性能测试
为衡量自适应k-Means 算法相较k-Means、k-Means++对于激光测距对噪声数据的剔除性能,本文使用轮廓系数Silhouette 和调整互信息AMI[26]作为评价指标。 Silhouette 为内部指标,反映了聚类内紧凑程度和聚类外分散程度的差异。 AMI 为外部指标,计算预测标签和真实标签的互信息分数来衡量相似程度。
表2 为三种k-Means 算法对3 个测试数据集聚类效果比较结果。k-Means++和自适应k-Means 相较于k-Means 算法有更快的运行时间,k-Means 采用随机方式选取初始聚类中心位置,迭代后的聚类中心位置也存在一定随机性,即陷入局部最优,这也造成了k-Means 算法在三个测试集下的调整互信息(准确率)最低。 自适应k-Means 相较于k-Means++能够自适应地确定最优化的k值,从而调整聚类中心个数,同时聚类中心的选取以快速下降SSE 为目的,因此对离群噪声有更好的处理效果。
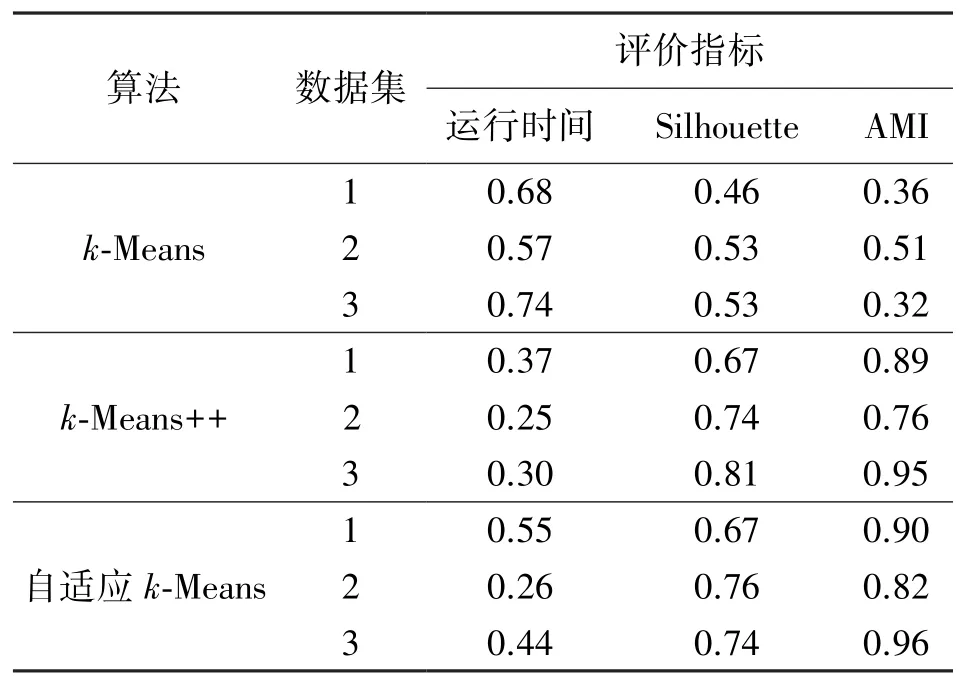
表2 三种k-Means 算法聚类效果比较
图5 为三种k-Means 算法对测试集1(100 m 测距情况)的聚类效果比较,图5(d)中自适应k-Means设定了21 个聚类中心,因此同样设定k-Means 和k-Means++的k值为21,另外增加了k值为10 的k-Means++对照组。 图5(a)中k-Means 算法将有效数据(label0)分裂为多个簇,这与其随机选取聚类中心有关,初始聚类中心大概率选取在密集处。k-Means++相较于k-Means,初始聚类中心设置更加合理,但是k值无法自主确定:选取较小k值(k=10)时(如图5(b)所示),噪声数据被归为有效数据集;选取较大k值(k=21)时(如图5(c)所示),能较好地将有效数据分离出来,但是k值需要依靠人工经验确定。 自适应k-Means 算法在迭代中自动调整聚类中心个数,弥补了k-Means 和k-Means++算法的缺陷,同时对离群噪声点有很好的处理效果。

图5 三种k-Means 算法对测试集1(100 m 测距)聚类效果
2.2 目标自动分类性能测试
为了验证XGBoost+LR 分类器在线墙目标分类的性能,本文通过k-Fold 交叉验证方式[27],将数据划分成k份,其中1 份作为测试集,其余k-1 分用于训练模型。 分别使用逻辑回归(Logistic Regression,LR)、随机森林(Random Forest,RF)、梯度提升决策树(Gradient Boosting Decision Tree,GBDT)、梯度提升决策树+逻辑回归(GBDT+LR)这4 种模型作为对比模型。
对于二分类问题,利用模型预测值和真实值计算混淆矩阵[28],以评价模型的性能,墙线二分类问题中混肴矩阵的描述如表3 所示。

表3 二分类问题判决表
评价二分类模型性能的指标常采用准确率Accuracy 和F1_Score 值[27],计算公式如下:
式中:Accuracy 表示预测的准确率,即预测正确的样本占总样本的比例。 F1_Score 是对精确度Precision和召回率进行综合考虑得出的指标。
ROC 曲线是分类器性能直观的评价工具[28],以假阳性率(FPR)为横坐标,真阳性率(TPR)为纵坐标,将预测为阳性的概率作为阈值,通过遍历所有预测的概率,得到多组FPR 和TPR 的坐标值,该曲线越靠近左上角延伸即曲线下方的面积AUC 值越大,表明分类器性能越好。 图6 为不同模型对应的一次ROC 曲线,LR 模型的AUC 为最低的0.918,说明单一学习器模型的性能远低于集成学习器模型。GBDT 模型相较于RF 模型,在建模策略上串行地拟合上一决策树的残差,因此它的损失函数在每次迭代中局部降低,能更好地提高模型精度。 GBDT+LR和XGBoost+LR 模型的AUC 曲线面积最大,分别为0.993 和0.999,验证了在GBDT 或XGBoost 基础上叠加LR 模型比仅使用GBDT 或XGBoost 模型获得了更好的性能。

图6 不同模型的ROC 曲线图
表4 是不同模型的准确率Accuracy、精确度Precision、召回率Recall、F1_Score 值和AUC 的对比结果。 从表4 可以看出,XGBoost+LR 模型的分类效果总体上优于其他4 种模型,准确率达到了98.3%,召回率Recall 和F1_Score 值分别达到了98.1%和98.2%,说明此模型具有很好的预测性能。 LR 模型的5 项指标都最低,准确率仅为85.8%,证明单凭线性系统无法完全区分测距数据集。 GBDT+LR、XGBoost+LR 的结合模型将数据引向高维化,使其变得线性可分,一定程度上提高了分类模型性能。 同时本文使用XGBoost 替代GBDT+LR 中的GBDT 模型进行特征组合,并使用RF 筛选出重要的特征组合送入LR 分类器进行训练,以期望提高模型精度和运算速度。

表4 不同模型评价指标对比
图7 比较了GBDT+LR 和XGBoost+LR 模型的训练时间开销与最大叶节点数量(模型复杂程度)关系曲线。 由图7 可知,XGBoost+LR 模型的运算速度优于GBDT+LR 模型,而且随着模型复杂程度的提升愈加明显。 其一是因为XGBoost 使用牛顿法二阶逼近损失函数最优,获得了更快的收敛速度,其二是使用RF 模型进行特征组合的筛选,很大程度降低了XGBoost 模型输出的稀疏矩阵维度,当叶节点数为3 043 时,经RF 模型筛选后仅保留了64 维特征,LR 分类器也获得了更快的收敛速度。
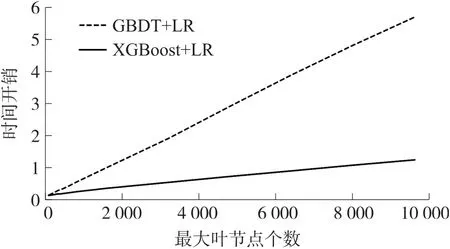
图7 两种模型的最大叶节点个数与时间开销关系曲线
2.3 测距精度测试结果比较
为验证墙线目标自动分类方法对激光测距系统精度的影响,本文以TruPulse200 型号激光测距仪[29]为标准,对比有无自动目标分类时的测量误差。 本文选取不同测试环境和天气下的2 067 个样本,其中1 056 个样本被分类为线目标,1 011 个样本被分为墙目标,线目标样本的测试范围为20 m~120 m,墙目标样本的测试范围为0 ~1 000 m,测试环境如图8 所示。

图8 实际测试场景
本文使用最小二乘法拟合距离、增益、阈值时间差关于真实距离(TruPulse200 激光测距仪结果)的曲线,通过测试得到2 067 个样本的标准差曲线如图9 所示。

图9 有无墙线分类时激光测距的标准差曲线图
图9(a)为未进行墙线分类时的测距标准差曲线,1 000 m 距离段的标准差维持在0 ~0.35 之间,图9(b)和图9(c)分别为进行本文提出的墙线目标自动分类方法后归类为墙和线的测距标准差曲线,归类为墙目标时前100 m 的标准差在0 ~0.1 之间,100 m~900 m 的标准差在0 ~0.2 之间,归类为线目标时120 m 范围内标准差在0.05~0.25 之间。 通过对比有无使用墙线分类方法时的标准差,可以发现本文提出的墙线自动分类方法能有效提高测距精度,减小测量误差,同时一定程度上降低了测量的数据抖动。 墙线自动分类方法能根据测量数据自动区分出测量目标为墙或线,对墙目标和线目标采用不同的数据拟合方式,经测试测量目标为墙时,标准差低于0.2 m,测量目标为线时标准差低于0.25 m。
3 结论
为了提高激光测距系统在电力巡检场景下测量不同目标物体的精度,本文提出了一种基于机器学习的激光测距墙线目标分类方法。 针对散射噪声问题,在数据预处理阶段提出了一种自适应k-Means聚类算法,基于密度确定初始聚类中心并在迭代过程自适应调整k值,实验验证本方法能较好处理离群噪声数据,筛选出有用数据。 针对墙线目标分类问题,本文了建立了XGBoost+LR 墙线分类模型,使用XGBoost 模型进行特征组合重构训练集,使用RF模型对稀疏训练集进行特征筛选,降低维度,最后使用LR 模型进行线性区分。 经测试验证,XGBoost+LR 墙线自动分类的准确率达到98.2%,较GBDT+LR 模型提高了1.3%,运算速度提升明显。
