基于多模态的输送带撕裂大模型算法设计
2023-10-07王学立赵辰燃何显能
王学立 ,赵辰燃 ,李 青 ,何显能 ,甘 梅
(1.西安博深安全科技股份有限公司,陕西 西安 710304;2.西安交通大学 软件学院,陕西 西安 710000;3.中煤科工集团重庆研究院有限公司,重庆 401325)
矿业行业是全球经济发展的基础产业之一,但同时也面临着诸多挑战,如人力成本上升、矿区工人的安全问题和矿区设备安全问题。人工智能技术的快速发展和应用,为矿业行业提供了一种新的解决方案,旨在通过科技手段提高矿山生产效率、降低成本、提高安全性和环保性。近年来,在一系列政策和行业应用的持续推进下,智能矿山已经进入攻坚克难、落地见效的关键阶段。AI 大模型的研发和应用无疑是核心驱动力之一。
AI 大模型[1]的应用在近年来得到了广泛的关注和应用,例如Google 的BERT 模型、Facebook 的GPT 模型、OpenAI 的GPT-3 模型等[2]。AI 大模型是指由大量参数和计算资源组成的机器学习模型,能够处理更加复杂的任务和应用到更复杂的场景之中。这些模型通常采用深度学习算法,例如神经网络,能够通过对大量数据的学习,发现数据之间的复杂关系,从而实现各种任务,例如图像识别、自然语言处理、机器翻译等。
AI 矿山大模型是一种基于人工智能技术的矿山智能化解决方案,它利用大数据、深度学习、机器学习等技术,针对矿山各种复杂场景,对矿山生产、安全、环保等方面进行综合分析和预测,帮助矿山企业做出更加精准的决策。特别是在图像识别方面,随着深度学习目标检测的发展以及矿井巷道监控相机的全覆盖,使用深度学习图像处理技术对矿井下安全问题进行监控预测[3-4],最大程度预防安全事故的发生。
为此,利用矿山AI 大模型,基于Transformer模型将视频和音频的多模态数据拼接、融合,提出了采用DETR-Audio 模型对煤矿输送带撕裂进行检测,通过现有的数据进行训练,实现对输送带裂纹的精确的识别并及时发出预警。
1 研究方法
在煤矿开采中,输送带是一个至关重要但最易耗损的材料,受井下各种复杂环境的影响,输送带在运输过程中经常出现裂纹或者直接撕裂,极容易对生产甚至安全造成影响,造成财产损失。为了避免大面积撕裂情况的直接发生,及时检测预警十分重要,目前检测输送带的撕裂主要分为2 大类:接触式检测和非接触式检测。随着设备智能化的不断普及,非接触式检测也逐渐占据主导地位,其中,视觉和声音是最常使用的2 个角度。
基于深度学习的视觉检测方法已经能够实现高精度和高效率的输送带撕裂检测。在目标检测方面,使用卷积神经网络(CNN)结构的模型已经能够实现对输送带撕裂区域的定位和分类。其中,一些基于Anchor 的目标检测算法如Faster R-CNN、YOLO 和SSD 等,已经被广泛应用于输送带撕裂检测中。文献[5]提出了一种改进区域卷积神经网络Light-Head R-CNN 的输送带撕裂检测方法,旨在解决输送带撕裂检测中破损目标检测精度不足和检测性能低下的问题;文献[6]通过Yolov4-tiny 目标检测网络对输送带损伤类型进行分类,实验结果表明,Yolov4-tiny 目标检测网络在输送带损伤数据集上对表面划伤、撕裂、表面破损和击穿4 种损伤类型检测的平均精度分别为99.36%、94.85%、89.30%、86.76%。但由于环境的特殊性和复杂性,视频成像夹杂大量噪声,直接利用传统的目标检测算法还会存在一些缺陷,由于Yolo采用了全卷积网络的结构,在多个尺度上进行检测时,不同的目标大小可能被映射到不同的层级上,这就导致了对小目标的检测不够准确,并且光线较差的环境下,对小裂纹的检测会更不敏感,出现漏检。文献[7]针对小尺寸漏检、误检问题,设计了DDS unit 替换主干网络中的Res unit,利用不同层次特征跨层连接的方式获得完整丰富的多尺度特征完成小尺寸破损的检测。
声波信号对输送带撕裂进行检测是一种非常有效的方法[8-9]。输送带的撕裂通常会产生特定的声波信号,可以通过声音传感器进行检测和识别。这种方法的优点是不需要直接接触输送带,可以在不干扰生产流程的情况下进行监测。在实践中,通过使用麦克风或其他声音传感器收集声波信号,并对其进行分析和处理,可以检测传送带是否存在撕裂。声波信号的分析可以使用各种信号处理技术,如时域分析、频域分析、小波变换等。文献[10]提出了一种基于声音的带式输送机输送带纵向撕裂检测方法,将采集的声音信号进行预处理,提取梅尔频率倒谱系数和短时能量参数,再经过高斯混合模型(GMM)进行均值估计,形成特征数据作为支持向量机(SVM)的输入进行分类和识别,实现带式输送机的输送带纵向撕裂检测。但是由于传送带所处环境复杂,噪声干扰大,会对波形图产生较大影响,导致撕裂的特征波形受到破坏,不能够很好地规避这种情况,可能会导致误检。
随着大模型热潮的兴起和Transformer 模型在自然语言处理领域的出色表现,近年来也被应用到图像处理之中,Transformer 模型可以同时处理多个类型的数据,包括图像、文本、声音等多模态数据[11-12],文献[13]调查了多模态机器学习本身的最新进展,并以一种共同的分类方式呈现它们,指出多模态机器学习旨在建立能够处理和关联来自多个模态的信息的模型。基于Transformer 模型将声音和视觉多模态数据结合对输送带撕裂检测,可以通过融合声音和视觉信息来提高检测精度和鲁棒性。声音信息可以捕捉到传送带的振动和噪声等特征,而视觉信息可以提供更丰富的目标形状、纹理等特征。将这2 种信息结合起来,可以更全面地描述目标,提高模型的检测能力。在处理多元数据时,传统的方法是将不同类型的数据分别输入到不同的深度学习模型中,然后将它们的输出进行融合和拼接,但这种方法会导致信息的丢失和误差的累积。
基于上述原因,基于Transformer 模型在处理多模态数据时,可以同时编码和解码多个类型的数据,并且在编码和解码过程中,不同类型的数据可以相互交互影响,从而实现更好的信息传递和融合,提高模型的表征能力的特点,提出综合视频和音频2 方面来对输送带撕裂进行检测的方案,视频和音频分别进行编码,最后使用1 个Transformer 解码器来将这些语义表示结合起来,进行多模态学习。
2 基于Transformer 的多模态网络结构
基于Transformer 模型能处理多模态数据的特性,提出了DETR-Audio 模型。将视频利用DETR 模型编码,同时将音频进行处理后传入编码器进行编码,最后解码器负责将视觉和音频信息的编码结果进行融合,产生最终的多模态表示。DETR-Audio 模型主要包含3 个模块:视频编码模块、音频编码模块和音视频融合解码模块。
2.1 视频编码
在计算机视觉领域,Transformer 模型被广泛应用于图像分类、目标检测和图像生成等任务[14-15]。DETR(Detection Transformer)[16]是一种使用 Transformer 实现目标检测的模型。DETR 框架对视频进行编码如图1。

图1 DETR 框架对视频进行编码Fig.1 DETR framework encodes the video
利用DERT 对视频进行编码,首先用Res-Net 作为backbone 提取图片的特征,然后结合输入的Position encoding 层提供位置信息,将图片特征输入到Transformer 的编码器中,每个Transformer 编码器层包含多个自注意力层和前馈神经网络层。自注意力层用于计算输入序列中每个元素与其他元素的相关性,从而得到每个元素在序列中的重要性,前馈神经网络层用于非线性变换和特征提取。多个Transformer 编码器层可以进一步提取输入序列中的特征,将特征向量收集起来,等待后续的使用。
2.2 音频编码
Transformer 模型针对音频处理也可以采取和视频同样的方式对音频进行编码,将收集到的音频数据利用短时傅里叶变换(STFT)对信号进行时频谱分析和去噪声[17-18],将时域信号分解成不同频率的振幅和相位。将得到的声频谱图输入到Transformer 编码器中进行特征提取。在Transformer 编码器中,输入的声频谱图会被转换为一系列特征向量,每个特征向量表示输入序列的1个时间步长。为了捕获长距离的依赖关系,Transformer 编码器会采用自注意力机制对输入序列进行建模,并利用多头自注意力机制增强模型的表达能力。最终,经过Transformer 编码器处理后的特征向量序列将被送入模型的后续阶段,进行音视频融合和预测任务。
2.3 音视频融合解码
解码器负责将视觉和音频信息的编码结果进行融合[19-20],产生最终的多模态表示。解码器也是一个Transformer 模型[21],由多层自注意力机制、前馈神经网络和残差连接组成。对音视频融合并解码如图2,图中:K、T、Q分别为多头注意力块的键、值和查询张量。
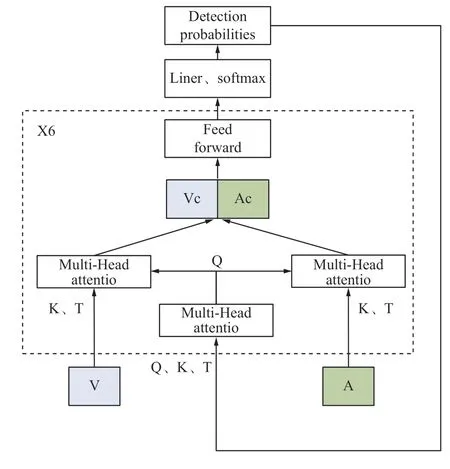
图2 对音视频融合并解码Fig.2 Fusion and decoding of audio and video
在每个解码器层中,视频(V)和音频(A)编码分别被独立的多头注意力模块分别关注。对于这2 种模态特征向量Vc和Ac,分别进行通道级的拼接,并输入到前馈层中。对于自注意力层,始终是Q=K=T,而对于编码器-解码器注意力层,K=T是编码产生的(T或A),而Q是前1 层的输出(或对于第1 层,是网络在前1 个解码步骤中的预测)。
3 实验设计和结果分析
3.1 数据集构建
本文的图像训练策略是采用DETR 检测模型,为此准备了相应的数据集。
针对DETR 模型的训练数据集,为了保证数据的质量,提升模型的鲁棒性,采集了矿井下多个场景的传送带数据,最后经过筛选选出3 000 张图像作为数据集进行标注用于训练和测试,数据集仅仅包含矿工一类标注目标,其中2 700 张用于训练,300 张用于测试。对于数据集的标注,借助LabelImg 工具采用人工标注。
针对音频的数据集,对收集到的数据先进行采样、滤波、降噪等处理,选取了图像视频对应的音频用Label Studio 进行标注。
3.2 训练参数配置
采用DETR 模型训练视频,使用的图片尺寸为800×1 333,backbone 采用resnet50,position embedding 选用sine,transformer 编码器(encoder)和解码器(decoder)的层数都是6,注意力头数(attention heads)为8,隐藏层维度(hidden dimension)为512,epochs 为300。
在利用Transformer 训练音频时,使用的采样率(sample rate)为16 kHz,每个音频片段的长度(segment length)为4 s,每个音频片段的重叠(segment overlap)为2 s,帧长(frame length)为25 ms,时域窗口(time-domain window)为Hamming window,编码器(encoder)和解码器(decoder)的层数都是6,注意力头数(attention heads)为8,隐藏层维度(hidden dimension)为512,学习率(learning rate)为10-4,大小(batch size)为16。
3.3 结果分析
通过实验,采集200 段矿井监控设备拍摄到的传送带视频片段测检测效果,先利用原生的DETR 模型进行检测测试,然后使用DETR-Audio 模型进行测试。DETR-Audio 模型测试结果见表1,音、视频综合检测如图3,对小块撕裂的识别如图4。

表1 DETR-Audio 模型测试结果Table 1 DETR audio model test results

图3 音、视频综合检测Fig.3 Sound and video comprehensive detection

图4 对小块撕裂的识别Fig.4 Identification of small pieces of tear
由表1 可知:比起单一通过视觉或音频对输送带进行检测,DETR-Audio 模型同时利用视频和音频信息来检测目标,在输送带撕裂的场景中,该模型能够更好地检测传送带的破损位置。
实验结果表明:在这个任务上,DETR-Audio 模型具有良好性能,比单独使用视频或音频信息的模型具有更高的检测准确度和鲁棒性。同时,模型通过学习音频和视频之间的关系,能够更准确地定位目标的位置(图3);对于输送带上一些小的裂纹检测会更加敏感(图4),这对于输送带撕裂等需要精确定位的任务非常重要。此外,实验还证明了在训练过程中,同时使用视频和音频信息对于提高模型性能至关重要。
4 结 语
基于Transformer 的多模态处理数据,提出了一种新的结构设计DETR-Audio 模型,用于输送带撕裂的检测。DETR-Audio 模型可以同时编码和解码音频和视频类型的数据,并且在编码和解码过程中,2 种类型的数据可以相互交互影响,从而实现更好的信息传递和融合,提高模型的表征能力。具体来说就是将视频和音频2 方面综合起来对输送带撕裂进行检测。视频和音频分别进行编码,最后使用1 个Transformer 解码器将这些特征结合起来,进行多模态学习。实验结果表明:DETR-Audio 模型相比仅利用DETR 模型识别度效果更好,可以提高传送带撕裂检测的精度和鲁棒性。
