基于轨迹泊松多伯努利混合滤波器的浅海匹配场连续跟踪方法*
2023-10-06周玉媛孙超谢磊
周玉媛 孙超† 谢磊
1) (西北工业大学航海学院,西安 710072)
2) (西北工业大学,陕西省水下信息技术重点实验室,西安 710072)
匹配场跟踪方法依据模糊度函数时间序列中声源位置移动的连续性和伪峰位置的无序性,可实现水下声源轨迹跟踪.然而,受到浅海空时起伏波导环境和声源复杂运动场景的双重影响,已有匹配场跟踪方法易出现轨迹中断、交叉混叠和虚假轨迹等现象,导致不连续的轨迹跟踪结果.针对这一问题,本文基于轨迹泊松多伯努利混合滤波器,利用模糊度函数中峰值位置距离似然和峰值幅度似然的一致性,提出一种匹配场连续跟踪方法.该方法应用于SWellEx-96 实验数据并由线性规划准则度量跟踪性能,结果表明: 相比已有匹配场跟踪和基于随机有限集的多目标跟踪方法,所提方法实现了两个水下运动声源轨迹连续跟踪,其中,轨迹状态随机有限集的建模方式以及在轨迹空间内执行预测和更新步骤,可以防止在未持续发声且数量未知的声源跟踪过程中出现轨迹中断和混叠现象;结合模糊度函数峰值位置和幅度信息执行数据关联步骤,可抑制虚假轨迹.
1 引言
实际浅海波导呈时空非均匀分布,且海底边界对声传播影响较大.由浅海水下声源运动引起的声场扰动和沿声源轨迹的水深变化等因素易造成接收声场与拷贝场的相关性下降,此时匹配场处理(matched field processing,MFP)[1]输出的模糊度函数出现较多伪峰,导致运动声源位置不确定.于是业内学者在MFP 基础上陆续提出了多种匹配场跟踪(matched field tracking,MFT)方法[2-7],利用模糊度函数时间序列中声源所在位置移动的连续性和伪峰所在位置的无序性,降低声源位置的不确定性,实现浅海水下运动声源轨迹跟踪.
最初Bucker[2]和Fialkowski 等[3]假设声源轨迹完全由起始位置确定,通过对模糊度函数时间序列分别采取求和与平均的方式,跟踪直线运动声源的轨迹;Maranda 和Fawcett[4,5]又以声源直线运动作为约束条件,将模糊度函数峰值数量最多的搜索路径当成声源轨迹的跟踪结果;Zala 等[6]鉴于声源运动会改变测量协方差矩阵的秩,将各拷贝轨迹矩阵的最大特征向量与时间平均测量协方差矩阵进行匹配,从而实现直线运动声源的轨迹和速度估计.由于这些MFT 方法均将声源直线运动当作先验假设,以致其跟踪性能往往在实际场景中受限.后来Tantum 和Nolte[7]提出了最优不确定场跟踪,引入马尔可夫模型以捕获声源运动的随机性,是一种未假设声源直线运动的MFT 方法,但仅限于单声源跟踪情形.由于目前仍缺少有关声源数量未知的MFT 方法研究,本文将针对运动形式复杂且数量未知的水下声源进行匹配场跟踪,除模糊度函数峰值位置与声源位置不一致的影响,还面临声源未发声和轨迹交叠时间段,跟踪过程易出现轨迹中断、交叉混叠和虚假轨迹现象,导致不连续的轨迹跟踪结果,这是具有挑战性的问题.
基于随机有限集(random finite set,RFS)[8]的多目标贝叶斯滤波方法[9]是实现未知数量目标跟踪的有效途径,包含多种滤波器形式.RFS 滤波器将多个状态变量和测量向量建模为元素数量和状态随机的RFS 形式,可有效表征多目标跟踪过程中的不确定性,其中高斯混合概率假设密度(Gaussian mixture-probability hypothesis density,GMPHD)滤波器[10]在水下被动跟踪场景的应用范围最广[11-15].但由于GMPHD 将目标状态RFS中所有元素视为同分布,以致无法区分多个紧邻目标.与GMPHD 相比,泊松多伯努利混合(Poisson multi-Bernoulli mixture,PMBM)滤波器[16]考虑了多个目标状态的差异性,在轨迹交叠情形中也能获得较好的跟踪结果.在PMBM 基础上又发展了轨迹泊松多伯努利混合(trajectory Poisson multi-Bernoulli mixture,TPMBM)滤波器[17],TPMBM先将所有状态变量建模为轨迹状态RFS而非目标状态RFS,再在轨迹空间内进行预测、更新和数据关联等滤波步骤,每个时间步的滤波输出为轨迹状态后验.相比其他RFS 滤波器需将各目标状态后验添加标签才能获得各轨迹估计结果,TPMBM给出了不同的轨迹估计方式,无需标签也能保证任意步长之间目标状态的连续性[18].由于水下目标辨识是一项研究难题,难以添加声学特征标签,因此TPMBM 更适合本文考虑的水下被动跟踪场景.但环境失配和水下声源数量未知等客观因素会导致模糊度函数中存在较高的旁瓣和较多的伪峰,TPMBM 基于距离似然的数据关联方式易产生错误关联,导致虚假轨迹出现.
针对声源运动形式复杂且数量未知的浅海水下被动跟踪场景,本文基于TPMBM 滤波器,利用模糊度函数峰值位置距离似然和峰值幅度似然的一致性,提出一种匹配场连续跟踪 (trajectory Poisson multi-Bernoulli mixture filter-amplitude-matched field tracking,TPMBM-A-MFT)方法.该方法首先建立匹配场轨迹状态空间模型,将模糊度函数变换为delta 函数之和以便测量RFS 表示,同时将声源轨迹状态集合分成未检测和已检测两部分并由泊松和多伯努利混合参数集表示,以准确描述水下声源数量、运动状态及测量关联的不确定性;然后在每个时间步中于轨迹空间内依次进行预测、更新和数据关联步骤,实现声源数量估计及其轨迹连续跟踪.由于本文所提方法考虑了各声源轨迹状态的差异性并依据TPMBM 滤波方式在轨迹空间内进行预测和更新,可减少轨迹混叠现象出现;每个时间步中由当前测量RFS 对起始至当前时间步的轨迹状态先验更新可以避免轨迹中断现象;此外,本文所提方法改进了TPMBM 原有的数据关联步骤,通过结合模糊度函数中峰值位置和幅度信息,将距离似然和幅度似然联合表示关联概率,从而降低错误关联概率以及抑制虚假轨迹.
其他部分安排如下: 第2 节介绍TPMBM 滤波器;以该滤波器为基础,在第3 节首先建立匹配场轨迹状态空间模型,然后推导出结合峰值位置和峰值幅度的数据关联公式,从而给出匹配场连续跟踪方法原理和所提方法的跟踪流程;第4 节将现有匹配场跟踪方法和本文所提方法应用于SWellEx-96 实验数据,并与其他3 种RFS 多目标跟踪方法对比,再由线性规划准则评估跟踪性能,从而验证本文所提方法的优越性能;第5 节给出相关结论.
2 TPMBM 滤波器
2.1 轨迹状态RFS 和测量RFS
浅海水下运动目标辐射声波经远距离传播后到达垂直阵,将各阵元接收声压时序数据划分K段y1:K,再与声场计算的拷贝声压wlook(r,d) 进行匹配,得匹配输出功率[1]:
式中,上标 H 为共轭转置,b(·) 为匹配输出幅值,距离r与深度d二维搜索空间Z([rd]T∈Z) 中匹配输出功率构成模糊度表面函数(下文统称为模糊度函数),理想条件下模糊度函数的全局极大峰值点对应目标位置,非理想条件下模糊度函数出现较多的伪峰与高旁瓣,导致目标位置不确定.
MFT 方法在模糊度函数时间序列上沿搜索路径累加幅值,伪峰随步数增加而减少,可实现运动声源轨迹跟踪.但是,实际浅海被动跟踪场景中目标数量通常未知,现有MFT 方法采取的轨迹搜索求和方式在实际应用中受限.而RFS 多目标滤波器在跟踪时无需假设目标数量已知,将目标状态变量与测量信息建模为数量随机的特殊集合形式:
式中,β与ε(ε≤k) 分别为初始与最新目标状态对应时间步,上标T 表示转置,xβ:ε是L=ε-β+1个时间步的目标状态变量组成的目标状态序列,nx是目标状态维数.TP MBM 的轨迹状态RFS 建模方式可视为“隐式标签”,在匹配场跟踪过程中确保多个目标状态在任意步长之间关联连续性.
2.2 TPMBM 滤波过程
RFS 多目标滤波器均是基于贝叶斯滤波理论传递p(Xk) 参数集,实现状态变量及其数量估计.而TPMBM 滤波过程的独特之处在于,参数集的预测、更新和数据关联步骤是在轨迹空间内执行,并非状态空间.
2.2.1p(Xk) 参数集预测
若k-1 时刻p(Xk-1) 参数集已知,单条轨迹状态Xk-1=(β0,k-1,) PDF 为
式中,δ为delta 函数,N表示高斯分布,轨迹状态的均值µβ:k-1与协方差Pβ:k-1分别由L=k-β0个时间步上目标状态的均值与协方差组成.
(10),(11)式与(12),(13)式分别为轨迹空间与目标状态空间预测示例,对比可知,(10)式与(11)式不仅将k-1时刻目标状态µk-1与Pk-1作为先验以预测第k时间步目标状态µk|k-1与Pk|k-1,还在轨迹状态先验µβ:k|β:k-1中保留以前时刻的目标状态,可确保任意步长间各目标状态连续性,从而减少匹配场跟踪过程中出现轨迹混叠次数.
由此,任意第h个全局关联假设中第i条已检测轨迹状态先验PDF 可表示为
2.2.2p(Xk) 参数集更新
2.2.3 数据关联
各元素由(21)式与(22)式组成,描述各状态先验与各测量关联概率.在任意测量最多与一个状态先验关联的约束条件下,TPMBM 依据以求解最优后验关联假设:
3 基于TPMBM 实现匹配场连续跟踪
3.1 匹配场轨迹状态空间模型
3.1.1 模糊度函数变换
3.1.2 状态方程和测量方程
依据2.1 节状态变量建模方式,各水下运动声源轨迹状态 Xk由PMBM RFS 表示.其中,目标状态xk由声源距离xk,r、距离维速度、声源深度xk,d和深度维速度组成,维数nx=4,xk在相邻步长间的转移关系由状态方程给出:
式中T是时间间隔;G是状态噪声驱动矩阵;状态噪声nk服从均值 [0,0]T、协方差的高斯分布.xk与ok的映射关系由测量方程给出:
式中,测量噪声vk服从均值 [0,0]T、协方差R=的高斯分布.杂波测量ck与xk无关,在Z空间均匀分布,杂波密度是空间面积.
本节基于TPMBM 建模方式,建立匹配场轨迹状态空间模型.将模糊度函数时间序列变换为delta 函数之和以便测量RFS 表示,水下声源运动状态建模为PMBM RFS Xk以便描述各轨迹状态及其数量的不确定性,依据(27)式与(28)式所示状态方程和测量方程,在轨迹空间执行TPMBM滤波过程,可实现匹配场跟踪.但需注意,TPMBM的数据关联步骤以状态先验与测量的距离似然为关联依据,在匹配场跟踪过程中易将模糊度函数中伪峰与声源位置关联而出现虚假轨迹.为抑制杂波的影响,本文将在3.2 节提出结合峰值位置与峰值幅度的数据关联步骤.
3.2 结合峰值位置和峰值幅度的数据关联
3.2.1 模糊度函数峰值幅度模型
归一化模糊度函数幅度PDFp(b(zk)) 可表示为方差的瑞利分布[19]:
式中,参数S是模糊度函数中所有声源位置处幅度均方值与模糊度函数平均功率之比,Bc=是模糊度函数时间序列变换时最低门限,(30)式和(31)式分别为目标与杂波的幅度似然函数.由于声源位置是未知变量,参数S及其相关的目标幅度似然函数无法计算,只能通过估计S∈[d1,d2] 取值范围来近似,其中,
(31)式和(34)式分别描述了第k时间步测量集合Zk中任意元素是杂波测量或是目标测量的可能性,可作为匹配场跟踪过程中区分杂波和目标测量的重要依据.
3.2.2 距离似然和幅度似然实现数据关联
假定目标幅度与其运动状态相互独立,首先将3.2.1 节(34)式与(31)式所示目标幅度似然与杂波幅度似然的比值构成幅度似然矩阵:
再由Wamp与(23)式所示距离似然矩阵联合表示各状态先验与测量之间的关联概率,以(24)式约束条件不变为前提,将原有最优关联假设求解方式更改为
作为总结,表1 列出了本文所提TPMBM-AMFT 方法在每个时间步的算法流程,基于匹配场轨迹状态空间模型,在轨迹空间依次进行预测、更新以及结合峰值位置和峰值幅度的数据关联步骤,从而实现水下声源轨迹连续跟踪和数量估计.

表1 TPMBM-A-MFT 算法流程Table 1. Steps of TPMBM-A-MFT algorithm.
4 SWellEx-96 实验数据分析与验证
本节利用SWellEx-96 实验数据构建出双目标运动场景,先展示现有MFT 方法跟踪结果及局限性,再给出本文所提TPMBM-A-MFT 方法的跟踪结果,并与3 种RFS 滤波器TPMBM,PMBM和GMPHD 进行对比,最后采用线性规划准则度量跟踪性能.
4.1 构建双目标匹配场跟踪数据集
SWellEX-96 海试实验[22]是在加州圣地亚哥附近开展的浅海实验,环境信息和实验数据集可在线查阅.如图1(a)所示,测线S5 中发射船沿蓝色轨迹拖曳了9 m 和54 m 声源并以5 节速度向垂直阵方向行进.本节选取54 m 声源发出的166 Hz 信号进行数据分析,首先将垂直阵(采样频率1500 Hz)记录时长75 min 的声压数据分成156 段(每段时长约28.4 s),每段分成21 个快拍,重叠50%,将第1–142 段与第15–156 段声压数据相加,获得142 段同频双目标声压数据,时长缩短为68 min;然后使用图1(b)所示波导环境参数和声速剖面,由Kraken 模型[23]计算搜索空间Z=[0,10 km]×[0,215 m]内各拷贝向量(网格精度为0.05 km 和2 m),并与每段双目标声压数据进行匹配从而获得模糊度函数时间序列.

图1 SWellEx-96 测线S5 实验 (a)发射船轨迹;(b)波导环境示意图Fig.1.The SWellEx-96 event S5: (a) The launch ship track;(b) SWellEx-96 waveguide.
为与本文所提MFT 方法进行对比,首先将Fialkowski 等[3]所提MFT 方法应用于上述模糊度函数时间序列,该方法假设目标在一段时间保持直线运动且数量已知,令搜索轨迹由初始与终点位置决定来缩减轨迹搜索维数,以模糊度函数时间序列上沿声源轨迹累加幅值最大为原则给出跟踪结果,如图2(a)中短折线所示,圆圈与三角标记分别为每5 min 内轨迹初始与终点位置估计结果.图2(b)为双目标S1 和S2 距离维轨迹真值,如点划线和点线所示,目标S1 与S2 的最近距离点大约分别出现在第50 min 和第60 min,轨迹交叠发生在第55 min,双目标运动过程中166 Hz 信号被中断多次,如图2(b)星号标记所示.由于现有MFT 方法受直线运动假设条件约束,图2(a)所示轨迹跟踪结果需以合适时间区间分段给出.对比图2(a)与图2(b)可知,图2(a)所示S1 与S2 轨迹跟踪结果均出现轨迹中断现象,在第20–50 min 内有多段虚假轨迹.此外双目标运动过程还存在轨迹交叠,伴随轨迹中断与虚假轨迹现象出现,因此图2(a)中无法判断第55 min 前后各条轨迹跟踪结果归属目标S1 或S2,易导致轨迹混叠.

图2 双目标距离维轨迹 (a) 现有匹配场跟踪方法轨迹估计结果;(b) 轨迹真值Fig.2.Range dimension trajectory of two targets: (a) MFT result;(b) the truth.
图3(a)–(c)给出了影响匹配场跟踪方法性能的客观因素,其中,图3(a)为沿轨迹的水深变化,可以看到,前10 min 出现较大地形差异,易引起环境失配.图3(b)和图3(c)是平均阵元接收信噪比[24]和相关系数的变化曲线,其中相关系数[25]为数据快拍与最佳拷贝向量的归一化内积,失配程度越大则相关系数越小.如图3(b)和图3(c)所示,在前20 min 内,受地形变化和目标距离相对较远的影响,两目标的平均阵元接收信噪比和数据相关系数普遍较低;在第20–45 min 内,目标S1 信噪比和相关系数均低于目标S2;另外在未发声时间段,两目标的信噪比与相关系数极低.低信噪比易引起模糊度函数中非目标位置出现伪峰,低相关系数带来模糊度函数峰值偏移,因此真实目标位置与峰值位置存在较大误差.结合图2(b)与图3(a)–(c)可知,本节构建的双目标匹配场跟踪数据集中不仅存在声源运动轨迹交叠和未持续发声情形,还包含环境失配、低信噪比等客观因素影响,这是图2(a)所示MFT 方法出现轨迹中断、混叠和虚假轨迹现象,导致不连续轨迹跟踪结果的原因.

图3 匹配场跟踪性能影响因素 (a)沿轨迹的水深变化;(b)平均阵元接收信噪比;(c)相关系数Fig.3.Influencing factors of matching field tracking performance: (a) The bottom depth along the trajectory;(b) average element level SNR;(c) correlation coefficient.
实际浅海被动跟踪场景中,水下目标数量和运动状态通常难以确知.现有MFT 方法需将目标数量已知与直线运动作为先验条件,其应用场景存在较大限制.而本文所提方法假设目标数量未知,对各模糊度函数提取M1:K个最高局部峰值,峰值数量M1:K服从均值为5 的泊松分布,获得Zk=1,Zk=2,···,Zk=142测量集合.图4(a)和图4(b)分别展示某次随机提取的各时间步测量集合的距离维空间状态分布及其元素数量,从图4(a)可知,前20 min 内杂波测量的覆盖区域较大,几乎无法分辨目标测量与杂波测量以及判断轨迹起始位置.20 min 后杂波测量的覆盖面积减少,但与垂直阵相距较远的目标S1 在第20–60 min 内出现多次目标测量连续缺失,受不发声时间段的影响较大.此外距离8 km 区域附近,杂波测量密度较大.
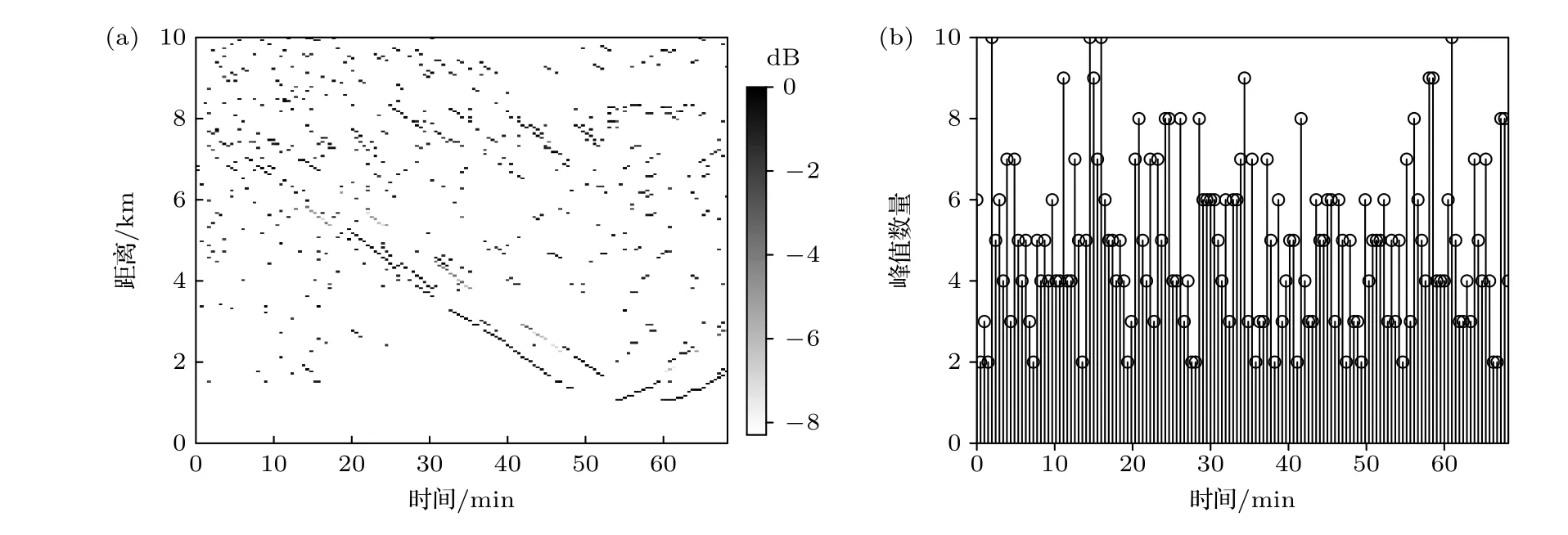
图4 所有时间步测量集合 (a) 距离维空间分布;(b) 元素数量Fig.4.Measurements sets of all steps: (a) Spatial distribution of measurement elements in range dimension;(b) the number of elements in the measurement set.
本节构建的双目标匹配场跟踪数据集中假设声源数量未知,不仅存在声源轨迹交叉和未持续发声等情形,而且环境失配等客观因素导致模糊度函数测量空间中的杂波密度和覆盖区域均较大.综合这些因素以及现有MFT 方法跟踪结果考虑,由该双目标数据集实现轨迹连续跟踪具有较大挑战性.
4.2 声源数量未知的匹配场跟踪结果
本节将TPMBM-A-MFT 与TPMBM,PMBM和GMPHD 三种RFS 滤波器一同应用于4.1 节建立的双目标跟踪数据集,基于匹配场轨迹状态空间模型执行各自的滤波过程,比较四种方法的匹配场跟踪结果.其中PMBM 和GMPHD 只估计当前时间步的目标状态,需以各时间步目标状态估计之间的最小距离为标签,形成轨迹估计结果.
表2 列出了匹配场跟踪过程中的滤波参数设置,其中,检测概率PD依据图3(b)中信噪比曲线设置,前20 min 的PD=0.2,第20–68 min 内PD=0.5 ;测量噪声标准差σr和σd与Z空间网格精度保持一致;各时间步k=1,2,···,142 出生的未检测轨迹状态先验均值设置为与模糊度函数最大峰值位置对应,其他滤波参数如表2 所列.

表2 匹配场跟踪过程的滤波参数设置Table 2. Filter parameters setup for matched field tracking process.
当4 种方法应用于图4 测量集合时,图5(a)–(d)依次给出了距离维轨迹跟踪结果.图5(a)–(d)中点划线和点线分别表示目标S1 和S2 的轨迹真值,实线、虚线和加号标记分别表示S1,S2 的估计轨迹和虚假轨迹.
首先可以看出,图5(a)和图5(b)中目标S1和S2 的估计轨迹完整,而图5(c)和图5(d)中S1和S2 的估计轨迹均有中断现象出现,原因在于漏检时间段中目标测量缺失,导致目标状态后验仅依赖于目标状态先验,随着缺失步长数增加,估计轨迹的存在概率逐渐降低至小于阈值Γ时会出现轨迹中断现象.对比TPMBM 与PMBM,GMPHD滤波过程中的更新步骤,每个时间步中PMBM 和GMPHD 只对当前时间步的目标状态进行更新,而TPMBM 会对估计轨迹中起始至当前时间步的目标状态序列进行更新.当目标再次发声时,TPMBM 和PMBM,GMPHD 中估计轨迹的存在概率均上升至大于阈值,但只有TPMBM 中漏检时间段的后验目标状态序列会被后续时间步的目标测量重新修正,轨迹中断现象消失.
对比图5(d)与图5(a)–(c)可以发现,图5(d)中不仅估计轨迹的破碎程度最大,而且目标S1 的估计轨迹分别在约第10 min,20–35 min,48 min和62 min 共出现7 次交叉混叠现象.结合两目标的运动过程和RFS 建模方式进一步分析原因,从图2(b)知目标S1 和S2 在前40 min 内保持约1 km 间距平行运动且交替地出现未发声情形,后28 min 内存在轨迹交叠,运动过程较为复杂.对比TPMBM,PMBM 与GMPHD 的RFS 建模 方式,TPMBM 和PMBM 将轨迹(目标)状态RFS 分成未检测和已检测两部分并分别由泊松和多伯努利混合参数集表示,GMPHD 未考虑目标差异性并由泊松强度参数统一表示目标状态RFS,其状态先验存在更大不确定性,导致GMPHD 的滤波过程更依赖于测量集合.当S1 和S2 交替未发声时,GMPHD 的目标状态后验估计易被测量集合迁移到另一条轨道上,从而出现轨迹交叉混叠现象(图5(d)).而在TPMBM 和PMBM 的滤波过程中,鉴于多伯努利混合参数集通过多个参数准确描述了各已检测轨迹(目标)状态先验的确定程度,已检测轨迹(目标)状态后验不轻易跟随测量位置跳变,减少了估计轨迹交叉混叠的次数.可以看到,图5(c)中估计轨迹仅在第10 min 出现一次交叉混叠,图5(a)和图5(b)中未有轨迹交叉混叠现象,说明TPMBM 将各轨迹状态建模为PMBM RFS并在轨迹空间滤波的方式,保证了任意时间步之间目标S1 和S2 状态估计的连续性.
除图5(a)以外,图5(b)–(d)中的估计轨迹数量均大于真实值,出现虚假轨迹.即只有图5(a)中未出现轨迹中断、交叉混叠和虚假轨迹等现象,实现了连续的轨迹跟踪结果.图5(b)–(d)中出现虚假轨迹的时间和空间集中在前10 min 以及8–10 km 区域,从图4(a)可知前10 min 内杂波测量覆盖区域较大且目标测量连续缺失,可能导致轨迹状态先验与杂波关联,使得轨迹状态后验逐渐偏离真值轨迹.此外8 km 区域附近的杂波测量密度较大同时存在时间和空间连续,当未检测轨迹状态先验与杂波测量的距离似然值较小且被杂波测量更新时,将驱动新的轨迹生成,其存在概率随时间累积逐渐增大,易形成虚假轨迹.图5(a)–(d)中仅图5(a)没有虚假轨迹出现,对比图5(a)与图5(b),印证了TPMBM-A-MFT 方法在数据关联步骤中通过增加峰值幅度似然信息来判决关联概率,可以有效抑制杂波与轨迹状态先验关联以及虚假轨迹形成的可能性.
为对TPMBM-A-MFT 的跟踪过程进一步分析,图6(a)–(i)给出9 个不同时间步的轨迹估计结果.按照时间顺序进行说明,如图6(a)所示,在跟踪开始的前6 min 内未出现轨迹估计,原因是S1 和S2 距垂直阵较远且S1 在第1–4 min 未发声,各轨迹状态后验的存在概率未超出阈值Γ,轨迹均值未被提取;从图6(b)知,第6.77 min 开始出现较近目标S2 的轨迹估计;如图6(c)和图6(d)所示,大约第11 min 两目标轨迹估计由初始位置向正确位置移动,由于前10 min 杂波密度较大且目标测量连续缺失,图6(c)出现一条虚假轨迹,说明此时杂波与轨迹状态先验有错误关联,但随着步长数增加以及目标测量出现,图6(d)中轨迹状态先验与杂波的关联概率逐渐降低并不再是最优后验关联假设,虚假轨迹已消失.

图6 TPMBM-A-MFT 的跟踪过程 (a)第6.29 min;(b)第6.77 min;(c)第11.13 min;(d)第11.61 min;(e)第21.77 min;(f)第22.26 min;(g)第42.10 min;(h)第54.19 min;(i)第60.00 minFig.6.Tracking process of TPMBM-A-MFT method: (a) 6.29 minutes;(b) 6.77 minutes;(c) 11.13 minutes;(d) 11.61 minutes;(e) 21.77 minutes;(f) 22.26 minutes;(g) 42.10 minutes;(h) 54.19 minutes;(i) 60.00 minutes.
由于目标S1 和S2 分别存在多个漏检时间段,在图6(e)–(i)所示后续时间步中估计轨迹出现了多次中断,但在每段漏检发生的后续检测时间步中,可观察到估计轨迹的中断部分又被重新连接.以图6(e)和图6(f)举例说明,对比图6(e)中的点划线与实线所示S1 真值和估计轨迹可知,S1 估计轨迹的中断时间步约为第15–21.77 min,当跟踪持续到第22.26 min 时,如图6(f)所示,S1 估计轨迹与真值已基本重合,S1 估计轨迹状态中第15 至当前时间步的目标状态序列已被重新估计.
以上现象归因于TPMBM-A-MFT 方法在轨迹空间内进行滤波的方式,其更新步骤利用当前时间步测量集合对整条轨迹状态修正,轨迹状态包含了之前时间步的目标状态序列,即使在目标漏检时间段内的估计轨迹中断,一旦目标被重新检测到,会将轨迹中断时间步的目标状态重新估计,最终跟踪结果如图5(a)所示,整个跟踪过程实现了连续轨迹估计.可见,相比传统MFT 方法跟踪结果(图2(a)所示),本文所提方法能在声源数量未知且间歇发声的运动场景中实现匹配场连续跟踪,突破了传统MFT 方法局限性.
4.3 跟踪性能度量
线性规划准则[26](linear programming metric,LP)通过匹配位置误差、轨迹缺失代价、虚假轨迹代价和轨迹混叠代价4 个度量指标(文献[26]中(24)式有详细说明)对跟踪性能进行量化,是衡量多目标跟踪算法综合性能的准则.令匹配截止参数c和惩罚参数γ均为2、敏感参数p为1,此时匹配位置误差是两条真值轨迹与各条估计轨迹进行位置匹配的最小绝对误差,轨迹缺失、虚假轨迹和轨迹混叠代价分别为两条真值轨迹与其匹配的估计轨迹长度之差、两条真值轨迹与各估计轨迹数量之差和估计轨迹的匹配跳变次数,LP 度量是4 种度量指标之和,LP 值越小则综合性能越优.
将4.1 节中142 段模糊度函数时间序列进行1000 次独立随机的测量集合获取,其中峰值数量M1:K服从泊松分布 P(M1:K;λz) ,均值λz在[3,8]区间任意选取.表2 跟踪参数不变,在跟踪过程的每个时间步中对当前估计轨迹应用LP 准则并按步长数进行归一化,从而给出LP 度量值以及四种度量指标随时间的变化情况用于跟踪性能评估,分别如图7 和图8(a)–(d)所示,其中实线、虚线、点划线和点线分别为TPMBM-A-MFT,TPMBMMFT,PMBM-MFT 和GMPHD-MFT 这4 种 跟踪方法的度量均值,相应半透明填充区间表示4 种跟踪方法度量标准差.

图7 四种跟踪方法在每个时间步的LP 度量结果Fig.7.LP metrics at each time step for four methods.

图8 LP 的4 种分解度量 (a)匹配位置误差;(b)轨迹缺失代价;(c)虚假轨迹代价;(d)轨迹混叠代价Fig.8.Four decomposition metrics of LP: (a) Matched localization error;(b) missed trajectory cost;(c) false trajectory cost;(d) switching cost.
由图7 可知,跟踪前10 min 内4 种方法均保持较大LP 均值,在后续时间段4 种跟踪方法的LP 均值以不同速率减小,说明跟踪过程在逐渐收敛.最后时间步的LP 值为最终轨迹估计的性能评估结果,对比最后时间步的4 个LP 均值,TPMBMA-MFT 最小,TPMBM 次之,其他两种方法较大.相比其他3 种方法,跟踪过程中TPMBM-A-MFT的LP 标准差最低,说明对测量集合均值Mk的选取具有鲁棒性.综合考虑,本文所提TPMBM-AMFT 方法的跟踪性能最佳.
图8(a)–(d)展示了4 种不同度量指标随时间的变化,跟踪过程包含142 个时间步(约68 min).从最后时间步的度量结果来看,其中,图8(a)所示平均每个时间步TPMBM-A-MFT,TPMBM-MFT,PMBM-MFT 和GMPHD-MFT 对目标S1 和S2 位置估计的绝对误差之和分别约为0.14 km,0.14 km,0.28 km 和0.49 km;图8(b)所示TPMBM-A-MFT和TPMBM-MFT 最终估计轨迹的缺失次数约为0 次,平均每个时间步PMBM-MFT 和GMPHDMFT 的轨迹缺失次数约为0.5 次和1.6 次;图8(c)中TPMBM-A-MFT 的最终估计结果未包含虚假轨 迹,TPMBM-MFT 和PMBM-MFT 约 有5.68(0.04×142)条虚假轨迹,GMPHD-MFT 最终包含的虚假轨迹条数最多,是有 19.8(0.14×142) 条;图8(d)中TPMBM-A-MFT 和TPMBM-MFT 最终估计轨迹的混叠次数约为0 次,PMBM-MFT和GMPHD-MFT 最终估计轨迹混叠总次数约为1.13(0.008×142) 次和 5.68(0.04×142) 次;图8(a)–(d)通过1000 次蒙特卡罗实验表明本文所提方法具有低匹配位置误差和轨迹数量估计误差,对两个存在轨迹重叠和未持续发声的目标能实现长时间稳健连续跟踪.
对比图8(a)–(d)中TPMBM-A-MFT 和TP MBM-MFT 的4 种度量曲线,其中两方法的匹配位置误差、轨迹缺失代价和轨迹混叠代价随时间的变化趋势大致相当,而虚假轨迹代价除外.两方法的唯一差别是,TPMBM-MFT 只依赖于测量位置与轨迹先验位置距离似然值进行数据关联,而TP MBM-A-MFT 在数据关联步骤结合峰值位置和幅度测量信息,将模糊度函数峰值幅度似然比作为区分目标测量与杂波的判别依据,改变TPMBM 原有数据关联方式.对比图8(c)中两种方法的虚假轨迹代价曲线可知,TPMBM-A-MFT 有效提高了关联决策准确性,说明在数据关联中将距离似然与幅度似然结合的方式能简单有效约束虚假轨迹数量.
5 结论
现有匹配场跟踪方法在水下运动声源未持续发声、数量未知且轨迹交叠的跟踪场景中失效,针对此问题,本文提出一种基于轨迹泊松多伯努利混合滤波器的浅海匹配场连续跟踪方法(TPMBMA-MFT).该方法建立匹配场轨迹状态空间模型,利用模糊度函数时间序列中峰值位置距离似然和峰值幅度似然的一致性,在轨迹空间内进行预测、更新和数据关联步骤,可以避免跟踪过程中出现轨迹中断、交叉混叠和虚假轨迹等现象,最终实现轨迹连续跟踪及声源数量估计.
SWellEx-96 实验数据处理结果表明: 1)相比现有MFT 方法需以声源数量已知为先验条件,并在模糊度函数时间序列上沿搜索轨迹求和以实现声源跟踪,所提方法将模糊度函数变换为delta 函数之和并表示成测量RFS 形式,声源运动状态由轨迹状态RFS 表示,无需假设声源数量已知;2)所提方法考虑了各声源轨迹状态的差异性并在轨迹空间内执行预测与更新步骤,每个时间步测量RFS 会对起始至当前时刻的目标状态先验序列矫正,可减少声源间歇发声和轨迹交叉引起的轨迹中断与混叠现象;3)所提方法更改了TPMBM 原有数据关联步骤,将模糊度函数峰值位置距离似然和峰值幅度似然联合表示关联概率,可抑制虚假轨迹;4)由线性规划准则中匹配位置误差、轨迹缺失、虚假轨迹和轨迹混叠代价4 种度量指标,验证了本文所提方法综合跟踪性能优势.
