基于材料组分信息的高居里温度铁磁材料预测*
2023-10-06孙敬淇吴绪才阙志雄张卫兵
孙敬淇 吴绪才 阙志雄 张卫兵
(长沙理工大学物理与电子科学学院,柔性电子材料基因工程湖南省重点实验室,长沙 410004)
寻找具有高居里温度的铁磁材料是凝聚态物理的热点问题.本文建立了有效的基于材料组分信息的居里温度机器学习模型,并预测了多种高居里温度铁磁材料.基于收集到的1568 个铁磁材料数据,并以铁磁材料的组分信息作为描述符,通过超参数优化和十折交叉验证,构建了支持向量回归、核岭回归、随机森林及极端随机树四种高效的机器学习模型.这其中,极端随机树模型具有最好的预测性能,其交叉验证R2 评分可达81.48%.同时,还应用极端随机树模型对Materials Project 数据库36949 种铁磁材料进行了预测,发现了338 个居里温度大于600 K 的铁磁材料.本文提出的方法可以为获取具有高居里温度的铁磁材料提供有价值的帮助,加快铁磁材料设计的过程.
1 引言
作为一种重要的智能材料,铁磁材料在现代科学技术中得到广泛的应用.居里温度(Curie Temperature,Tc)高于室温是铁磁材料工业化应用的重要前提.遗憾的是,目前Tc高于室温的候选铁磁材料不多.为满足信息技术发展需要,近年来许多研究者通过不同的方法试图合成高Tc的铁磁材料[1-3].另一方面,密度泛函理论已成为模拟铁磁材料的典型理论方法,它结合海森伯哈密顿量,求解磁交换相互作用,并通过蒙特卡罗方法求解Tc.这种方法计算量大、效率低,不适用于高通量材料计算和设计.
在材料基因组计划的推动下,基于机器学习的材料设计[4-14]已成为当前材料研究的一个热点领域.机器学习方法缩短材料设计周期,也被广泛地应用于磁性材料的预测.Kabiraj 等[6]利用高通量自动化代码和数据驱动模型,遍历了二维(twodimension,2D)材料数据库,并预测了大量具有高Tc的二维铁磁(ferromagnetic materials,FM)材料.卢帅华等[7]通过将先进的机器学习技术与高通量密度泛函理论计算相结合,开发了一个自适应框架,以加速二维内秉铁磁材料的发现.Vishina 等[12]通过对ICSD (inorganic crystal structure database)中包含3d 和5d 元素的已知晶体结构进行数据挖掘,使用特定材料的筛选方法结合电子结构计算的高通量方法来寻找无稀土永磁体的可能候选材料.磁性是一种典型的量子效应,与材料组成、结构、化学键、电子结构等密切相关,发展简单高效的磁性如Tc预测模型仍存在挑战.
材料的化学组分是决定材料物性的基础.常用的永磁材料包括铝镍钴系永磁合金、铁铬钴系永磁合金、永磁铁氧体、稀土永磁材料和复合永磁材料等.通过分析现有的永磁材料[15]及铁磁材料数据集[16-19],可以发现绝大多数磁性材料含有Fe,Co,Mn,Ni,O 以及稀土等元素.这表明,材料的组分信息如元素和化学配比,对材料的磁性如Tc起着至关重要的作用.
本文力图基于材料的化学组成信息,建立铁磁材料Tc预测模型,并发掘具有高Tc的铁磁材料.本文构建和优化了具有较好的回归和泛化性能的多种机器学习模型.最后,还利用具有最佳性能的极端随机树模型,预测了多种Tc超过室温的铁磁材料.
2 数据及方法
2.1 数据集
从参考文献[16-19]中收集了1568 个铁磁材料作为数据集,该数据集只包含铁磁材料的化学成分信息(元素、化学配比)和相应的Tc.图1 展示了铁磁材料的Tc分布情况,可以看出数据集中铁磁材料的Tc范围为0–1400 K,大多数数据样本分布在600 K 以下,而高于600 K 的数据仅占总数据的20%左右,这表明高Tc的铁磁材料在数据集中相对较为稀缺.

图1 1568 个铁磁材料数据集Tc 的分布情况Fig.1.Distribution of Tc in 1568 ferromagnetic material data sets.
图2 显示了数据集中Tc分别大于300 和600 K时的铁磁材料元素的分布情况,元素分布主要集中在Fe,Co 和O.通过分析数据集中大于300 K 的数据,发现Fe,Co 和O 元素分别占总元素的34.3%,11.6%和16.8%,而在600 K 时,Fe,Co 和O 元素分别占总元素的32.2%,25.8%和15.8%,说明Fe,Co和O 是本数据集高Tc铁磁材料的主要元素.Ni,Mn也是常见的磁性元素,在高Tc的数据中相对Fe,Co 元素占比较少,从图2 可以得知,Ni,Mn 的占比相对其他元素依旧拥有一定的数量,对模型的训练不会产生太大的影响.

图2 数据集中铁磁材料的元素分布情况 (a) Tc 大于300 K 时元素分布;(b) Tc 大于600 K 时元素分布Fig.2.Element distribution of ferromagnetic materials in data set: (a) Element distribution when Tc is greater than 300 K;(b) element distribution when Tc is greater than 600 K.
2.2 机器学习模型及超参数的优化
本文采用sklearn[20]平台上的支持向量机(support vector regression,SVR)、核岭回归(kernel ridge regression,KRR)、随机森林(random rorest,RF)以及极端随机森(extremely randomized trees,EXT)四个机器学习模型.针对SVR 和KRR 算法的超参数采用了遗传算法[21]进行优化.KRR 和SVR选取了高斯核函数(rbf),对模型中的alpha 参数进行了优化,其值设置为0.00567165.对于SVR模型,其模型性能取决于参数c和gamma.参数c是一个常数,它决定了对估计误差的正则化惩罚,其设置为181.8797945,gamma 是核系数的系数,其设置为0.18646131.针对RF 和EXT 模型,主要由3 个超参数决定模型的性能.通过在一定的超参数区间内,采用均匀网格搜索[22]的方式选取最佳超参数(图3 所示),“n_estimators”被设置为从100 到300,步长为10;“max_features”以0.02 步,从0.10 到0.60;“min_samples_leaf”默认选择最小的0.001.不同模型的优化结果见表1.

表1 本研究中四种机器学习模型的超参数Table 1. Hyperparameters of four machine learning models in this study.

图3 均匀网格搜索 (a) 随机森林参数优化图;(b) 极端随机树参数优化图Fig.3.Uniform grid search: (a) Random forest parameter optimization map;(b) extreme random tree parameter optimization map.
3 结果及讨论
3.1 特征选择
特征选择可以降低过拟合的风险,更好地去除与目标值无关的特征从而达到优化模型以及缩短训练时间的目的.本文总共生成了397 个特征,其中使用matminer 库生成了362 个特征,参考文献[8,9,18,23]生成了35 个特征.在这些特征中,根据化学配比的关系,采用了加权比例的方法来构建特征,如Fe2O3,其原子序数特征被定义为:8(3/5)+26(2/5)=15.2.针对397 个特征,我们发现前20%的特征几乎占据了95%以上对Tc预测模型的贡献度,因此提取了前20%的80 个特征作为新一轮的候选特征.之后考虑到特征之间可能存在相似性高的情况,影响模型的预测结果,采用皮尔逊相关系数[24],计算两个特征之间的相似性且去除相似度大于90%的特征,最终得到了表2 中21 个化学参数作为铁磁材料的描述符.

表2 基于特征筛选获得的化学参数描述符Table 2. Chemical parameter descriptors obtained based on feature screening.
3.2 模型训练
本研究采用80%数据作为训练集,20%数据作为验证集,构建并比较了四个不同的机器学习模型.使用平均绝对误差(MAE),均方根误差(RMSE)和决定系数(R2)三项指标对四种机器学习模型的结果进行评估,评估结果见表3 (CS MAE,CS RMSE,CSR2分别表示十次交叉验证结果的平均绝对误差、平均均方根误差、平均决定系数).其中,KRR 模型的CS MAE,CS RMSE 和CSR2分别为94.41,141.21 和73.70%;SVR 模型的CS MAE,CS RMSE和CSR2分别为88.64,137.62 和74.92%;RF 模型的CS MAE,CS RMSE 和CSR2分别为81.18,124.13和79.45%;EXT 模型的CS MAE,CS RMSE 和CSR2分别为74.04,117.98 和81.48%.
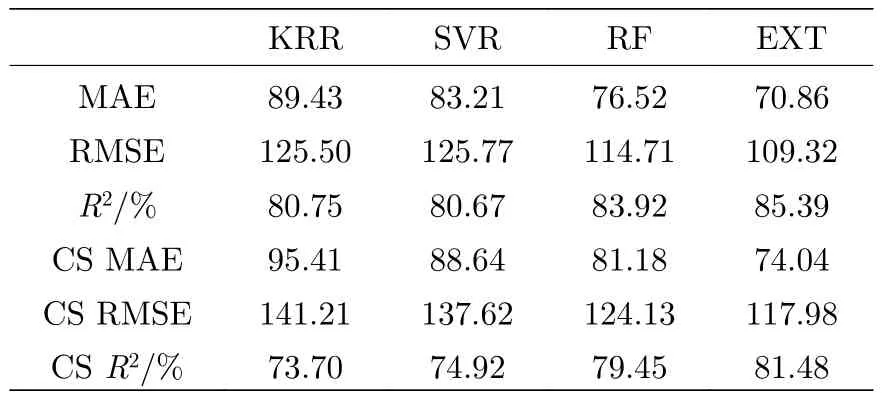
表3 本研究中四种机器学习模型的最终评估结果Table 3. Final evaluation results of four machine learning models in this study.
为了更好地展示不同机器学习模型的预测性能,图4 给出了四种机器学习模型在实验值和预测值之间的二维散点图.经过比较,发现无论是模型本身还是交叉验证的结果,EXT 模型都拥有最低的MAE 和RMSE 以及最高的R2评分.这表明相对于其他三种模型而言,EXT 模型具有更加优秀的性能,在铁磁材料Tc的预测方面表现出色.

图4 四种机器学习模型实验值和预测值对比的二维散点图 (a) 核岭回归;(b) 支持向量机;(c) 随机森林;(d) 极端随机树Fig.4.Two-dimensional scatter plots comparing experimental and predicted values of four machine learning models: (a) Kernel ridge regression;(b) support vector machine;(c) random forests;(d) extremely random tree.
图5 展示了EXT 模型在训练过程中,描述符的重要性情况.在所有描述符中,“型在训练过GSmagmom”(原子的单元素固体磁矩的平均值)是最重要的特征,占特征重要性的21.6%.其次,“Composition of Fe”和“Composition of Co”分别占重要性的11.0%和15.1%.这表明在化合物中,Fe 和Co 元素的含量对预测高Tc铁磁材料具有很大的影响.

图5 基于极端随机数模型的特征重要性排序图Fig.5.Feature importance ranking graph based on extreme random number model.
3.3 预测
还将建立的EXT 模型用于预测已有数据库中化合物的Tc.使用了Materials Project 数据库[25]中所有的铁磁材料,经过去重复处理,得到了包含36949 个数据的预测数据集.如图6 所示,我们的预测模型发现在2531 个Tc大于300 K 的材料中,主要元素成分以O,Fe 和Co 为主,分别占据了28.2%,21.5%和6.9%.在Tc大于600 K 的338 个材料中,主要元素成分以Fe,O 和Co 为主,分别占据了36.2%,33.8%和9.6%,相较于Tc大于300 K 的元素分布,Tc大于600 K 的元素分布中Fe,O 和Co在元素中的占比得到了提升,这表明,如果要获取较高的Tc铁磁材料,则在这些元素组合的化合物中进行寻找相对更为合理.

图6 预测集中铁磁材料元素分布情况 (a) 2531 个Tc大于300 K 数据的元素分布图;(b) 338 个Tc 大于600 K 数据的元素分布图Fig.6.Element distribution of ferromagnetic materials in prediction set: (a) Element distribution of 2531 data with Tc greater than 300 K;(b) element distribution of 338 data with Tc greater than 600 K.
在不存在于训练集且Tc大于600 K 以上的预测数据中,找到了6 个有实验值的数据,AlFe3预测值为750 K,实验值为755 K[26];AlFe 预测值为756 K,实验值为640 K[27];FeNi 预测值为701 K,相对实验值为785 K[28];Fe3Pd 预测值为595 K,实验值为463 K[29];Fe3Sn 预测值为704 K,实验值为743 K[30];Mn4N 预测值为758 K,实验值为710 K[31].数据分析可知实验值和预测值的平均相对误差为11.7%.由于铁磁材料的Tc微观物理机制复杂,目前仍缺少精确的预测方法.常用的平均场方法预测Tc误差在10%–20%之间,且根据磁性物质的具体特征和实验条件等因素,实际的误差范围可能会更大.因此,EXT 模型在预测铁磁材料的Tc方面表现良好.同时,图7 还给出了预测的338 个数据中Tc的分布情况,结果表示FeCo9,Li3Zn(Fe5O8)4,Fe3B,FeCo2Ge,Li9Fe23O32,Li3Fe7O12等铁磁材料可能具有较高的Tc,其预测值都在800 K 以上.

图7 预测集中338 个Tc >600 K 的铁磁材料的Tc 分布情况Fig.7.Curie temperature distribution of 338 ferromagnetic materials with Tc >600 K in prediction set.
4 结论
本文使用元素基本的物理性质等信息构建了一系列特征,针对铁磁材料的Tc进行了训练,使用了四种机器学习方法(SVR,KRR,RF 和EXT).通过模型优化和交叉验证等方法,对不同机器学习方法得到的相关评价分数进行了比较,最终发现EXT 模型表现最佳,其R2值达到了81.48%,展现了良好的精度和泛化能力.基于EXT 模型,本文预测了Materials Project 数据库中36949 个不同组分和配比的数据,并从中筛选出338 个Tc很可能大于600 K 的铁磁材料,这将有助于加速铁磁材料的设计.
