一种基础流式数据统一编码转发算法设计
2023-10-05陶世峰
陶世峰,杨 巍,宋 旋,李 刚,刘 佳
(1.中铁大桥局集团有限公司科技与信息化部,湖北武汉 430050;2.中铁桥梁科学研究院有限公司信息化建设管理部,湖北武汉 430050)
企业数据随着生产经营的发展会形成流式数据结构,给企业流式数据的挖掘与管理带来了一定的难度[1-3]。对于企业的流式数据来说,缺少可分类与过滤的相关数据特征,是流式数据挖掘的一个难点。运用统一编码形成企业流式数据挖掘特征是解决这一问题的关键[4-6]。
企业流式数据需要建立以应用标准、数据标准、技术标准为主要内容的相关规范和标准,推动企业信息系统的深度集成、数据共享和深化应用。以上需要有高效的数据挖掘方法做支撑,分期逐步实现企业基础数据统一编码与数据挖掘内容的统一维护、查询与系统间的数据集成共享,加强数据运营管理能力的提升,通过数据挖掘切实发现企业管理中存在的问题,强化企业数据管理的信息化支撑,更好地实现信息资源充分共享,信息资源利用效率最大化。综合以上方面目前取得的研究成果,应用数据挖掘技术设计一种企业流式数据的挖掘算法。
1 企业流式数据挖掘算法设计
1.1 数据挖掘统一编码特征
流式数据为不同时间段引入的数据,缺少统一的可识别特征,通过对码段进行组合、排序,每段码段调用码段管理中定义的特征码数据、码值生成规则产生码段编码,再根据码段顺序拼接码段值,形成完整的数据编码及统一挖掘特征。将多个数据资源同时使用到的编码码段进行管理,建立公共的可复用的编码码段管理。对每一个元数据定义一个编码规则,生成的编码保存在元数据模型中指定的编码字段中。基础数据要统一编码规范,对企业基础数据按照类型分别制定编码规范,如图1 所示。
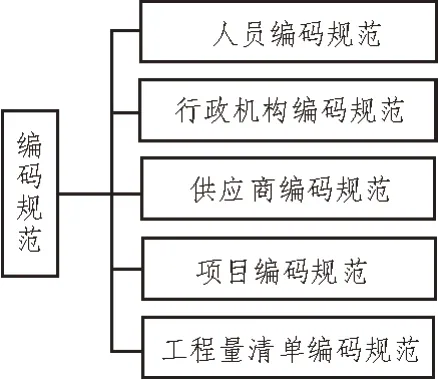
图1 企业基础数据编码规范
基础数据编码规范包括适用范围、编码概述、编码方式等。主要遵循以下原则:
1)每一编码应具有唯一性;
2)便于扩充,考虑今后的发展,各类编码应预留足够的位数;
3)综合分析现有各信息系统的编码,与原有编码尽量兼容;
4)编制中应考虑必要的反复确认过程,各部门应指定熟悉业务的人员专门配合编码的编制事宜,以使编码更符合实际应用;
5)编码内容包含基础数据说明、主要数据项、编码规则等。
采用动态随机方式进行企业基础流式数据的统一编码传输,所使用的数据包由信宿节点的编码数据信息、编码向量、包头构成[7]。数据包格式具体如图2 所示。

图2 数据包格式
其中,编码数据信息是利用编码向量进行编码计算所获得的值,用于描述数据包属性信息[8]。
在企业基础流式数据统一编码传输中,假设在组播率为h的情况下,信源发布了主题包P={p1,p2,…pn} 。在发布主题数据p1时,所播出的信息是{p11,p12,…p1h}[9]。用I(e) 表示输出信道传输e∈E对应的编码数据信息,其中输出信道的表达式如下:
式(1)中,i=tail(e)表示输出信道尾部;j=head(e)表示输出信道头部。
利用编码节点k向各输出信道e生成一个编码向量ne=(ne,1,ne,2,…,ne,h),其中,h表示编码向量长度,所生成的向量是随机的[10]。则编码数据信息是由主题数据和编码向量累积而成的,可以用式(2)来表示:
式(2)中,xi代表原始数据。
此时,对应e的各个编码向量ne=(ne,1,ne,2,…,ne,h)形成了一种编码方案[11]。其中的编码是随机网络编码,将方案记为ψ,其具体表达式如下:
式(3)中,i表示正整数;| |E代表输出信道向量E的元素个数。此时信宿节点所收到的编码数据信息可以认为是很多编码节点进行多次编码计算以后获得的全局编码数据。用式(4)来表示:
式(4)中,gi代表信宿节点编码向量,可以用式(5)来表示;pi表示第i个主题包。
式(5)中,Mk,i代表编码节点k对应的第i个输入向量。信宿节点所收到的全部编码包的对应编码值和编码向量,构成了一个统一编码传输的对应矩阵方程组[12]。具体如式(6)所示:
式(6)中,gnh代表第n行第h个编码向量;In表示第n个编码数据信息。根据矩阵线性方程组的实际可解条件,若矩阵是满秩的,则信宿即可成功解码,从而获取原始数据xi,实现企业基础流式数据统一编码,形成可识别的挖掘特征。
1.2 改进的数据过滤算法
形成可识别特征后,对一些无关的数据进行过滤,可以大幅度提高挖掘效率。但是,流式数据在传统的过滤算法下效率很低[13-15]。该文改进的过滤算法是在过滤算法思想的基础上,通过判断分类区域是流式数据的动态区域还是静态区域,来判断能不能删除一些影响挖掘的区域,减少挖掘数据的冗余干扰。这种改进后的分类过滤算法的设计流程如下:
1)针对企业的流式数据不断进入数据库的情况,设计一种数据结构kd-tree,对kd-tree 中的存储数据单元n.count 计算编码特征如下:
n.total=(xi,min,xi,max),i=1,2,…,d。
2)假如企业流式数据编码后的未分类结构为CC0,设置rt.SC=CC0,其中,rt.SC是可以看出数据的自然中心。假设这些参数都是随机的,那么有Ci.count=0 和Ci.total=0。
3)对于每个数据存储单位n,作如下假设:
假如n.SC=pn.SC,其中,pn.SC是单元n上一层单元中的子分区。
从n.SC中可以计算n.center 的流式数据编码分类中心Ci,再计算和,其中,n.center 是结点n的分类中心。
4)假如p=1,说明流式数据的分类不是最优结果,可产生新的分区CCp,其中,p是迭代计算的次数。
5)一旦CCp中分区后形成CCactive,那么rt.SC=CCp和rt.SCactive=CCactive,其中,rt.SCactive是中心候选集。设置Ci.count=0 和Ci.total=0。
6)设置p=p+1,且继续产生新的流式数据分区CCp。跳到第五步继续执行直到簇中心不再发生变化。
1.3 改进的Apriori挖掘算法设计
在完成过滤优化后,针对企业流式数据完成挖掘,该文提出一种改进的Apriori 算法,并应用到优化后的企业流式数据中,如下:
1)扫描企业存储流式数据的数据库D,产生过滤后的数据集合C1,计算其中各个数据待挖掘特征的特征相似度[16]。
2)删除特征相似度较小的分区,形成一个优化挖掘数据集L1。
3)在由Lk-1进行迭代计算,形成特征最优集合Ck以前,需要统计Lk-1中所有数据超过特征相似度阈值的次数。
4)删除Lk-1中特征相速度不相干的k-1 次的项目集,修剪后标记为
6)对Ck进行裁剪,得到Lk,计算Lk中k-项集的个数,如果个数小于k+1,则不再进行k+1 项集的运算,跳出循环;否则转到步骤3)继续执行。至此完成企业流式数据挖掘算法的设计。
2 算法仿真测试与分析
2.1 仿真测试平台与场景参数设置
通过Java 实现企业流式数据统一编码挖掘算法的设计,并在实验仿真平台上搭载设计的算法完成验证。仿真场景参数的具体设置如表1 所示。
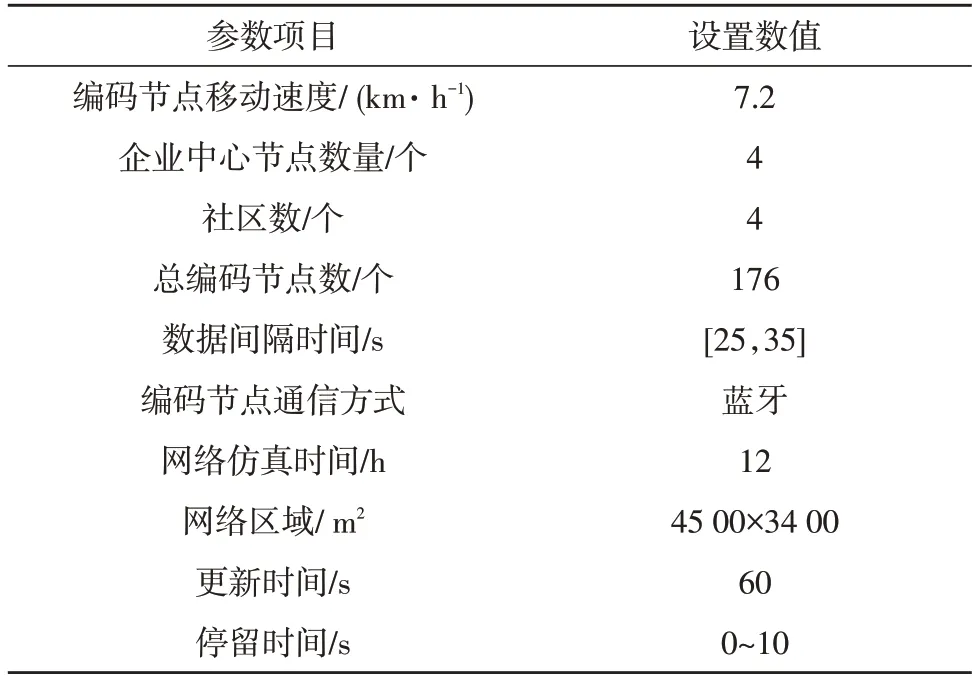
表1 设置的仿真场景参数
2.2 仿真测试性能结果分析
在ONE 仿真平台中接入某企业流式数据存储系统,将系统中的基础流式数据作为实验数据。在不同数据生存时间下,对所设计算法的耗时、挖掘成功率、负载率三项指标进行测试。其中,负载率的测试结果如图3 所示。

图3 负载率测试结果
根据图3 可知,随着生存时间的提升,负载率虽然有所提升,但整体提升步调比较平稳。说明在算法的数据挖掘中,消耗的挖掘资源整体较少。成功挖掘率结果如图4 所示。
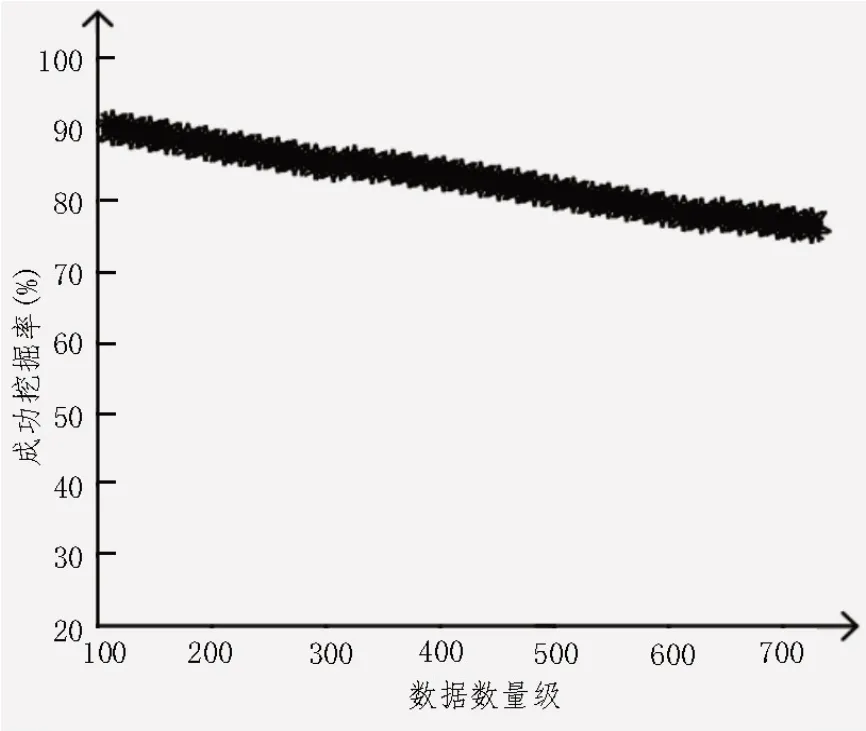
图4 成功挖掘率测试结果
根据图4 可知,设计算法成功挖掘率随着生存时间提升而下降。但在数据数量级为700 时,仍然能够维持80%左右的成功挖掘率,证明设计算法能够充分利用数据资源。耗时测试结果如表2所示。
根据表2可知,设计算法在生存时间低于300 min的情况下,耗时较低,在生存时间高于300 min 的情况下耗时较高,但整体耗时较低。
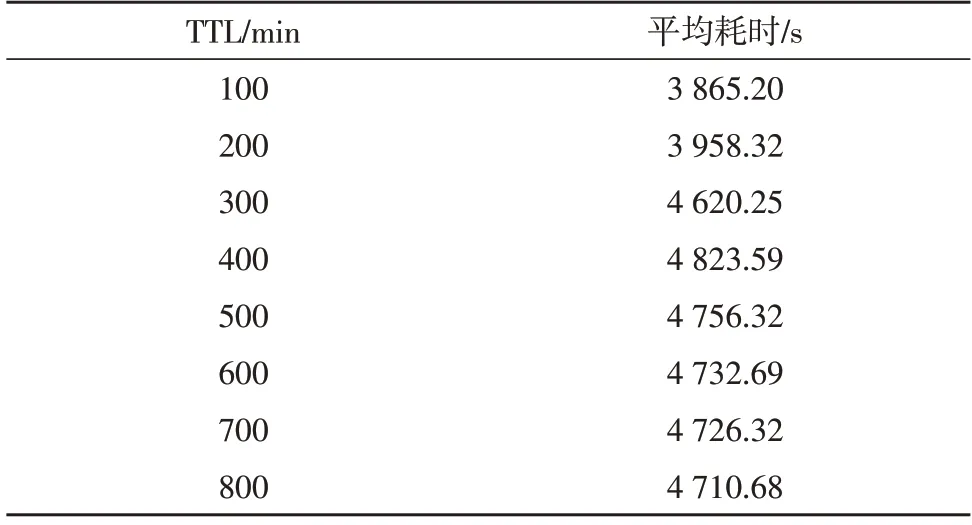
表2 耗时测试结果
3 结束语
该文设计了一种企业基础流式数据统一编码转发算法,实现了企业工控网络资源的充分利用,对于企业的数据传输有很重要的意义。在研究中,由于时间和精力的不足,未能对算法安全进行更加深入的研究,将会在日后进行更加深入的研究。
