面向微服务的容器伸缩技术的研究*
2023-09-29刘钊远
陈 哲 刘钊远
(西安邮电大学计算机学院 西安 710121)
1 引言
微服务是当下流行的软件开发架构,该架构提倡将应用按业务需求划分为一个个彼此独立运行的微服务单元,服务之间通过轻量级通信机制进行相互协作[1]。微服务可以采用不同的编程语言和存储技术,每个微服务可以独立部署、资源调度,从而实现高度的伸缩性和灵活性。容器是轻量级的虚拟化技术,在资源隔离的同时共享操作系统内核,具有启动速度快、资源利用率高的特点[2]。Kubernetes[3]这样的容器管理工具还兼具了服务发现的功能,因此大规模微服务通常采用容器进行部署。
微服务与云计算结合,已经成为业界公认的云计算时代互联网应用的主要构建方式[4]。阿里巴巴、腾讯、Netflix、Amazon 等,均开始采用微服务构建其业务应用。对云服务供应商而言,用尽可能少的资源保证托管的云上应用的服务等级协议(Service Level Agreement),可以降低运维成本。而对于应用开发者来说,在负载变化时及时调整资源配置能够提升服务质量。为了实现这两点,弹性伸缩技术不可或缺。容器化的微服务在水平扩展上具有巨大的潜力,然而现有的云平台仍缺乏能充分发挥微服务特性的弹性伸缩策略[5]。
目前业界主要采用的是基于阈值的响应式伸缩策略,该策略需要用户指定参考的资源指标并设置伸缩阈值,如当CPU 利用率超过70%时触发扩容,低于40%时则触发缩容。系统定时检查相关资源指标,将其与阈值进行对比并计算出伸缩所需的资源量。设置合适的阈值和伸缩规则需要用户对应用进行深入了解,仅凭资源利用率也难以准确估计微服务应用的性能,很容易造成无效伸缩和过度伸缩[6]。更重要的是该策略将微服务看作独立的个体,没有考虑服务之间的依赖关系,伸缩时也就无法保证应用的服务质量。
本文提出了一种基于服务容量的预测式弹性伸缩策略,以应用层指标请求访问率(request per second)取代资源利用率作为伸缩的主要参考,并通过SVR算法预测请求率的变化,从而提前制定伸缩计划,避免资源初始化期间违反SLA协议。为了精确地估计伸缩时所需的资源量,提出了基于应用分析的资源估计方法,通过一系列压力测试获得应用在不同负载强度下资源量与响应时间的关系,从而给出合适的资源分配方案。实验验证,本文提出的策略能够满足微服务应用对响应时间的要求并充分利用集群资源。
2 相关工作
目前关于弹性伸缩的研究有许多,从伸缩维度上弹性伸缩可以分为水平伸缩和垂直伸缩[7]。水平伸缩是指通过增加或减少服务实例来实现资源重分配,一实例包括虚拟机、容器等。垂直伸缩则是通过增加或减少计算资源来实现伸缩,计算资源包括CPU和内存等。
从伸缩时机上可分为响应式和预测式[7]。响应式伸缩是根据当前负载和性能指标是否超过预定阈值来判断是否进行伸缩。由于资源初始化需要时间,该方法存在滞后性。响应式、横向伸缩是云平台主流的弹性伸缩方式[8]。
预测式伸缩则是根据负载的历史数据构建预测模型,通过预测未来一段时间内的负载变化,来判断是否进行伸缩。预测模型的精度是该方法的关键,文献[9]提出了基于自回归平均移动模型(Auto Regressive Moving Average,ARMA)的负载预测方法,该方法要求数据属于平稳型序列。文献[10]采用线性回归和神经网络的方法预测CPU 利用率的变化;文献[11]利用ARIMA 与RBF 神经网络对CPU 和内存指标进行预测。文献[12]指出采用应用相关指标的伸缩策略能够提供更好的性能。
对于云环境下的微服务应用,每个微服务都能够进行水平扩展,应用可以表示为不同服务的副本组合,在特定的负载强度、性能要求以及资源限制下,并非所有的组合都是最佳的。因此,伸缩时需要进行准确的资源估计,即伸缩哪种服务伸缩多少资源性价比最高。常用的资源估计方法包括应用分析、性能建模、强化学习等。文献[4]采用Jackson排队网络对微服务进行建模,建立负载、资源利用率以及响应时间之间的关系用以指导资源分配。排队模型适用于特定的伸缩场景,但是很难在不同应用之间推广[13]。文献[14]采用马尔科夫决策描述资源配置,通过强化学习算法寻找马尔科夫决策过程中最优的伸缩策略。采用强化学习需要较长的训练过程,在集群运行前期表现较差。应用分析是通过合成或真实的负载测定应用的资源饱和点的过程,能够简单且准确建立起微服务的资源估计[7]。
3 基于服务容量的预测式伸缩策略
首先给出服务容量[15]的定义:微服务在不违反SLO 的情况下能够处理的最大请求速率。服务容量可以定量的描述微服务在特定资源配置下的性能表现。为了对微服务应用进行有效的伸缩,需要知道每种微服务的服务容量,以及何时进行伸缩。本文提出的基于服务容量的预测式伸缩策略包含如下三步:
1)首先,通过对微服务应用进行应用分析得到每个微服务容器在特定资源配置下的服务容量。
2)接下来,建立时间序列预测模型,根据过往的访问数据,预测未来短时间内的访问请求率的变化情况。
3)最后,根据预测的结果结合当前应用整体的服务容量判断是否应当进行伸缩,在需要伸缩时根据步骤1)得到的服务容量表计算出最佳的副本数。
3.1 基于应用分析的资源估计方法
微服务应用可以被描述为如下的模型:应用接收外界的请求,将其称之为系统级请求,每个系统级请求在应用内部被分解为内部请求交由相应的子服务处理,处理完后会返回给用户。对于系统中的每个子服务,又可以将其看作一个子系统,其余的子服务作为该子系统的外界环境。根据Operational Laws[16],观察系统可以得到表1列的指标。

表1 直接观测到的指标

表2 各个变量及其含义
从这些直接测量的指标可以进一步推导出下列重要的量:
吞吐量或者完成率:
利用率:
平均完成每个请求需要的时间:
定义访问量Vi是子服务i的请求完成数与系统级请求完成数的比值:
根据式(4),子服务i的吞吐量Xi等于系统总的吞吐量X与子服务i访问量Vi的乘积:
定义服务需求Di是子服务i上平均完成每个请求的时间Si与访问量Vi的乘积:
根据式(1)、(2)、(3)、(6),子服务i的利用率可以表示为
设系统内服务需求最大的子服务为b,它的服务需求为Dmax,则b的利用率可以表示为
因为利用率Ub≤1,所以:
式(9)表明应用整体的吞吐量受制于瓶颈服务,因此可以用应用整体的吞吐量等同瓶颈服务的服务容量。据此,本文提出了基于压力测试的服务容量估计方法,通过调整压力测试强度和各子服务的副本数,使得不同的微服务先后进入瓶颈状态,从而得到每个微服务的服务容量。
该方法的具体步骤如下:
1)部署微服务各子服务副本数均为1,预先指定SLO指标,本文中设为响应时间的99%分位数小于50ms。
2)使用负载生成器逐步增大负载强度,直到应用的响应时间达到预设的SLO指标。
3)检查各子服务的资源利用情况并分析应用的瓶颈点,找出分配相同资源量SLO指标提升最多的子服务,此时的请求率即为该服务的单位副本的服务容量。
4)重复2)~3)步,直到获取所有子服务的容量为止。
伪代码描述如下:

3.2 基于SVR的请求访问率预测
用户访问的请求率(request per second,rps)是一类典型的时间序列数据。考虑到弹性伸缩的目的之一是为了节省集群资源,所以在选择预测算法时应避免使用时间复杂度过高的算法。预测的目的是为资源配置争取时间,所以主要考虑短期预测。基于以上原因本文选择了SVR[17]算法建立预测模型。SVR 可以选取不同的核函数灵活适用于线性和非线性数据,在样本量较小时具有不错的准确度并且计算复杂度低。
将历史的请求率按照自定的时间粒度排列成时间序列。设训练样本为Xi为过去n个单位时间内的请求率:
SVR的模型为
其中ϕ(x)是一个非线性函数,它将样本空间映射到高位的特征空间,w和b是待确定的模型参数。SVR 允许模型输出f(x)与真实输出y有一定偏差ϵ,定义ϵ-不敏感损失函数:
以f(x) 为中心,落在f(x)-ϵ和f(x)+ϵ范围内的样本都不计入损失,SVR模型可形式化为
其中ξi,̂是松弛变量,c是惩罚系数,用来调节间隔和分类准确度,c越大表示对偏差的容忍度越小,是需要优化的指标之一。引入拉格朗日乘子将式(10)转化为其对偶问题,并引入核函数求解后得到回归方程:
其中k(x,xi)=ϕ(xi)Tϕ(xj)为核函数。常用的核函数有线性核函数、多项式核函数和高斯核函数等。令gamma=,其中σ为高斯核函数的带宽,gamma越大训练准确度会提高,但对未知样本分类效果下降,容易出现过拟合。gamma越小则无法在训练集上得到较高的准确率,也会影响测试集的准确度。
核函数、惩罚因子c、gamma(使用高斯核函数的话)三者的组合是需要优化的指标。本文使用高斯核函数并利用网格搜索确定最优的模型参数。
最后使用测试样本预测未来的请求率,即可得到预测序列:
3.3 伸缩过程
根据上文分析,各子服务容量的最小值决定了应用整体的服务容量,通过为瓶颈子服务进行扩容,可以提高应用整体的容量。当预测的请求率大于应用整体服务容量时触发扩容,为了保持系统的稳定缩容,采用请求率实测值触发,其他步骤类似。以扩容为例,触发扩容后遍历各子服务当某个子服务的容量小于预测的请求率时,为其扩容,直到容量刚好超过预测值为止,调整完所有子服务后本次扩容结束。
伪代码描述如下:

4 实验验证
4.1 实验环境
本次实验使用三台虚拟机搭建的Kubernetes集群作为实验平台,一台master 节点,另外两台作为node 节点。Kubernetes 版本是1.18,Docker 版本是1.40,操作系统是CentOS7。实验对象是一个简单的微服务应用emojivoto[18],它是一个为表情投标的应用。该应用由三个微服务组成:web 负责前端页面,emoji用于查找和列出表情符号。voting 用于记录投票和排行榜。该应用的API 如表3 所示,包括了list,leaderboard 和vote。使用Apache Jmeter模拟用户访问。

表3 emojivoto应用的API
4.2 测定服务容量
设定单个副本的资源限额,web 服务的CPU 份额为200m,另外两个服务CPU 份额为50m(Kubernetes中1000m表示一个核)。
根据3.2节描述的算法对应用的三个功能分别进行了测试,SLO 指标为响应时间99%分位数≤50ms。表4展示了测试结果,可以看到应用执行不同功能时各子服务的容量也不尽相同。以查看表情列表功能为例,web 服务的容量是135 次/s,emoji服务的容量是110 次/s,执行该功能不涉及vote 服务所以其容量不计。

表4 服务容量测试结果
4.3 基于服务容量的自动伸缩验证
使用Jmeter模拟用户使用投票功能,访问请求率从50 次/s 逐步上升至359 次/s 再下降到220 次/s。将请求率序列重复10 次后训练SVR 模型,将预测值作为本文策略的输入。Kubernetes 原策略则设置CPU利用率>70%作为扩容阈值,CPU利用率<40%作为缩容阈值。
伸缩过程中的副本数变化如图1 所示,每组条柱中左侧条柱表示使用本策略各子服务的副本数变化,右侧条柱表示使用Kubernetes 原策略各子服务副本数的变化情况。根据预测的请求率,本文策略在第2min 开始扩容,而原策略则滞后1min 才触发扩容。在第8min请求率从350次/s增大到了359次/s,原策略检测到web 子服务的CPU 利用率超过阈值进行了一次伸缩,而本文策略估计当前资源分配容量满足要求故没有进行伸缩。本文策略和原策略都在第11min 触发缩容,但是本文策略减少了更多的副本。

图1 各子服务副本变化情况对比
图2展示了伸缩过程中应用整体响应时间99%分位数的变化情况,阈值为50ms。在第3min、4min、5min,由于原策略响应滞后以及资源估计不足,响应时间超出了阈值范围。在整个伸缩过程中,本文策略始终保证应用响应时间在阈值以内,且波动幅度更小。
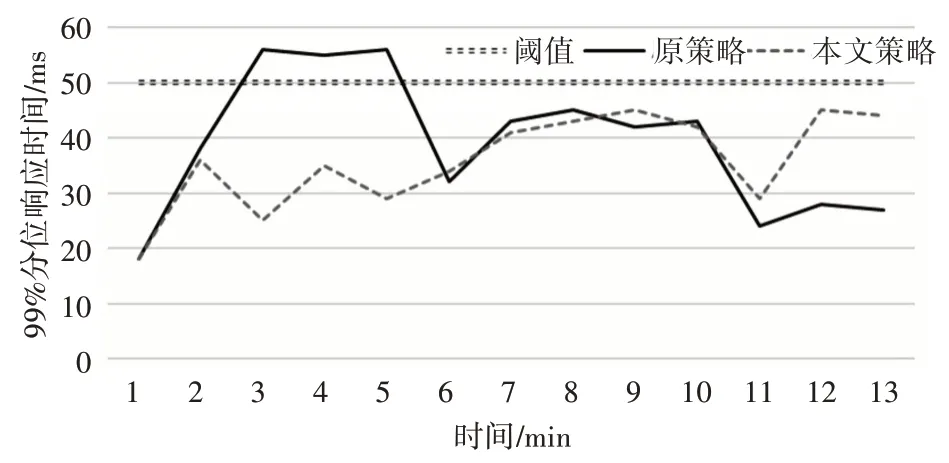
图2 伸缩过程中应用响应时间对比
5 结语
针对微服务应用场景下,传统基于阈值的响应式伸缩策略存在响应滞后以及资源估计不准的问题,本文提出了一种基于服务容量的预测式弹性伸缩策略。通过SVR 预测工作负载变化提前进行伸缩决策。为了准确地估计伸缩所需的资源量,提出了基于应用分析的资源估计方法。实验表明,相较于基于阈值的响应式策略,本文策略在保证应用服务质量的同时有效节省集群资源。
