基于双重注意力机制的图像修复方法*
2023-09-29王威李众
王 威 李 众
(江苏科技大学电子信息学院 镇江 212003)
1 引言
图像修复是通过图像中的已知信息来推测出缺失的像素值的过程,是计算机视觉领域和计算机图形学的热点研究方向之一。当需要移除图像中不需要的部分或是恢复被遮挡区域的时候,都需要进行图形修复。图像修复的重点在于推测出的图像在语义上和真实图像要保持一致,并且在纹理细节上要逼真。
早期的图像修复算法主要分为两种,一种是基于图像块的算法[1~3],通过在图像中匹配合适的图像块并复制到缺失区域来实现图像的修复;另一种是基于扩散的算法[4~6],将图像内容从缺失区域的边界平稳地传播到缺失区域的内部。这些传统算法本质上是利用图像本身的冗余性,用图像已知部分的信息来补全未知部分,但是无法获得图像高级别的语义。这些方法在应对简单一致的背景修复任务时能取得不错的效果[7],然而,当缺失区域纹理复杂时,比如物体或是自然场景,它们都无法很好地完成修复任务。
得益于卷积神经网络(CNN)对于提取特征的高效[8],以及生成对抗网络[9](GAN)取得的大量进展,大量研究人员将其应用在图像修复领域。相比于传统算法,基于CNN 和GAN 的方法通过大量的训练数据,可以学习到真实图像中的特征以及抽象的语义特征,然后用于完成缺失部分的修复任务,并不像传统算法是对图像块的复制,因此修复结果在上下文信息上更加连贯。Pathak 等[10]首次基于编码器-解码器机制提出Context Encoder 修复模型,其将图像修复任务转换为是有约束的图形生成问题。通过编码器进行高级别的特征提取,用解码器来预测缺失图像的内容,同时加入对抗网络共同训练,以加强生成的像素与现有像素之间的一致性。实验表明该方法相比传统方法在修复结果的语义一致性更好,能生成更加合理的图像。但是其在纹理细节上还不够精细,并且修复区域有很明显的边界。IIZUKA 等[11]在此基础上将判别器模型修改为全局判别器和局部判别器相组合的方式来辅助生成器的训练,同时生成随机二值掩膜,以进行任意区域的修复。Chen 等[12]提出将生成器分为两个阶段,先将待修复图片进行粗略的修复,再将其输出作为第二阶段精细修复的输入,获得了更好的修复效果。这些方法[10~13]表明结合CNN 和GAN 的算法可以生成语义上合理的图像,但是基于GAN的模型难以训练,并且直接对原始输入使用CNN导致内存占用量非常高,因此即使有较好的硬件支持,训练速度仍然很慢。随着缺失区域的增加,修复质量会迅速下降。
针对上述问题,为了改善模型对于图像的上下文信息的理解能力,以及生成纹理更加清晰的图像,本文设计了一种结合双重注意力机制的两阶段修复方法:将生成器分成粗修复和精修复两阶段,同时在精修复阶段的模型中加入双重注意力机制,可以聚合图像特征的空间相关性和通道相关性,使生成器更好地利用图像的上下文信息。为了让修复结果更加逼真,采用多尺度判别器,利用三个结构相同,但输入图像尺度不同的判别器同时训练。在训练时,判别器的梯度会反向传播给生成器,使生成器可以获得不同尺度的梯度信息。
2 基于双重注意力机制的图像修复模型
2.1 双重注意力机制
卷积运算有一个显著缺陷,其仅在局部相邻区域工作,也由此会错失全局信息。不少研究只采用U-net 结构去融合底层和高层的语义特征,但还是没有综合考虑各个位置的联系和相关性。双重注意力机制由空间注意力和通道注意力两部分组成。
2.1.1 空间注意力
注意力机制有匹配和替换两个阶段。在匹配阶段计算特征之间的注意力得分,在替换阶段,通过注意力得分聚合完整区域的特征块来替换缺失区域的特征块。空间注意力得分在计算时首先将特征图切分成3×3 大小的块,然后利用余弦相似度来计算缺失部分的特征块与完整区域的特征块的相关性:
其中pi表示特征图中完整区域的特征块,pj表示特征图中缺失部分的特征块。再利用softmax 运算得到每个特征块的空间注意力得分:
其中N表示特征图中完整区域的个数。最后在替换阶段,通过空间注意力得分,聚合完整区域的特征块来重建特征图中的缺失区域:
其中α为重建系数,将重建的特征图P͂作为新的特征图传递给通道注意力机制,进行第二次的重建,以更好地利用全局的语义信息。
2.1.2 通道注意力
特征图中的每一层都可以看作是卷积核对一个特定特征的响应,而不同的语义响应相互关联。通过计算通道之间的相互依赖性,可以强调相互依赖的特征图,改善特定语义的特征表示。本文的通道注意力采用自注意力模型,将各层特征图转置之后进行矩阵乘法来计算各层之间的相关性:
其中Ai表示第i层特征图,Aj表示第j层特征图。利用softmax 运算来计算各层通道注意力分数:
其中C表示特征图的通道数。最后通过融合各层通道注意力分数来修正特征图:
其中β为重建系数。空间注意力机制的输出作为通道注意力机制的输入,相较于只使用单个注意力机制,双重注意力机制可以获取更丰富的语义信息。
2.2 两阶段生成器模型
生成模型的主要工作原理是模型根据输入的待修复图像,输出完整的在语义上一致的图像。然后通过裁剪将生成的图像粘贴到待修复区域。生成器的网络架构如图1 所示。本文采用了两阶段网络架构,其中第一阶段粗略的生成缺失内容,而第二阶段则生成出更精细的结果。
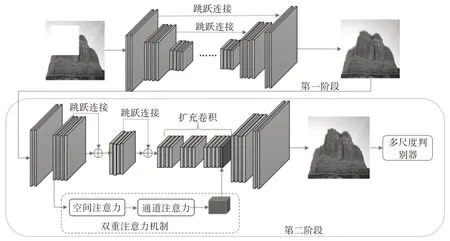
图1 图像修复流程图
对于第一阶段,首先生成随机二值掩膜,同时处理图像来模拟任意区域的缺失部分,然后将缺失图像和对应的二值掩膜作为第一阶段的输入进行训练,完成粗略的修复。第一阶段模型参考U-Net[15]全卷积结构,去掉其中的池化层,采用步幅卷积来实现降采样,避免池化操作对于信息的丢失,同时将其中的有效卷积修改成同维卷积。将第一阶段的输出以及对应的二值掩膜作为第二阶段的输入。第二阶段中通过双重注意力机制来对高层特征图处理,改善特定语义的特征表示。在图像修复任务中,模型感受野的尺寸应该尽可能的大[16]。因此本文采用了扩充卷积用来扩大模型的感受野,同时加入残差块结构和跳跃连接,在一定程度上也可以缓解生成器由于模型过深而导致的模型退化和梯度消失[17]。扩张卷积可以在不改变特征图尺寸的情况下增大感受野,但同时导致不能让所有数据参与计算,体现在特征图上就是卷积中心点的不连续[18],因此在设计扩张卷积结构时将扩张率改成锯齿状。
2.3 多尺度判别器模型
在图像修复任务中,最重要的是对缺失部分像素值的预测。在对抗学习中,判别器通过判别图像是否与原图相似来约束生成器的训练。好的判别器可以有效地保持修复图像整体的语义一致性,增强修复区域的纹理细节。
本文使用多尺度判别器来辅助生成器训练。多尺度判别器由三个相同结构的判别器构成,通过最大池化处理图像来实现降采样,以获得不同尺度的图像分别作用于三个判别器。小尺度的判别器模型能获得的更大的感受野,使得生成图像的语义一致性就好。大尺度的判别器模型能学习到更精细的纹理结构,使得生成图像更加清晰。
为了能更好地约束GAN 的训练,对判别器每一层的卷积核参数矩阵W施加谱范数归一化(Spectral Normalization,SN),参数矩阵更新公式计算方法如式(7)所示:
其中σmax(W)是WTW的最大特征值。谱范数归一化严格实现利普希茨连续性约束,使得判别器对于输入扰动具有更好的稳定性,防止梯度异常,从而使训练过程更容易收敛。Miyato 等[14]证明,使用谱范数归一化的判别器模型比使用梯度裁剪的要更稳定。
2.4 损失函数
本文修复模型的损失函数包括对抗损失和重建损失两个部分。对抗损失通过对抗训练使生成器生成更加合理的图像,重建损失可以强化生成图像的纹理细节与原始图像之间的一致性。
本文的对抗损失采用的是WGAN 损失[19],因为已经使用了谱范数归一化来约束模型波动,因此本文中不使用梯度惩罚。WGAN 损失采用的是Wasserstein 距离用来衡量生成数据和真实数据之间分布的差异,在确保了生成样本的多样性的同时,改善了原始GAN 训练不稳定的问题。依据WGAN 的目标函数设计多尺度判别器的损失函数Ld和对抗损失Ladv:
其中Pg和Pr分别表示通过生成器生成的数据的概率分布和真实数据的概率分布。通过最小化生成器损失以及最大化判别器损失来优化网络。
WGAN 在训练生成器G 的同时联合训练判别器D为生成器提供梯度,通过两个网络之间相互对抗,使G尽可能地逼近真实数据分布。不同于原始GAN 的判别器是做二分类任务,WGAN 的判别器属于回归任务,因此最后一层需要去掉sigmoid 运算。本文采用L1 范数损失作为重建损失,相较于L2范数损失,能恢复更多的边缘信息,避免纹理过于平滑。
本文的修复模型采用两阶段训练,在训练第一阶段网络时,只使用重建损失来获得粗略的修复结果。第二阶段强化训练,使用重建损失和对抗损失相结合的方式进行训练。
3 实验与分析
3.1 训练
本文使用Place 2 数据集[20]作为训练数据,其包含许多场景类别,例如卧室、街道、犹太教堂、峡谷等。数据集由1000 万张图像组成,其中每个场景类别包含5000 张训练图像和500 张测试图像。每张原始图像的尺寸为256×256,掩膜为128×128的矩形。
本文在基于tensorflow-gpu 1.14.0 框架的异构平台上进行试验,显卡为NVIDIA GeForce GTX1080,对应的cuda 版本为10.0,batch size 大小设置为8,对抗训练轮数为1000000 次。为了消除奇异样本数据导致的不良影响,将图像的像素值归一化到[-1,1]之间作为生成器模型的输入。
3.2 图像修复结果评估
图2 展示了本文的方法与PatchMatch(PM)方法[6]和Context Encoder(CE)方法[9]修复结果的比较。图2(c)为PM 方法修复结果,可以看到其修复结果纹理十分清晰,但是这种方法缺少对图像的语义理解,第一张图和第三张图出现了很不合理的部分。图2(d)为CE 方法修复结果,其对于全局的语义有一定的理解,相较于PM方法,修复结果在结构一致性上会更好,但是修复区域十分模糊,并且有很明显的修复边界,无法达到图像修复任务的要求。图2(e)为本文方法修复结果,可以看到本文的方法可以更好地利用周围的纹理和结构,能恢复出更多的有效信息。同时生成的图像也在视觉上更真实,不会产生明显的修复边界和伪影。

图2 与其他修复方法对比
为了量化图像修复结果,本文给定评价指标为峰值信噪比[21](PSNR)、结构相似性(SSIM)和平均误差(L1 loss)。PSNR[22]通过像素级别的误差来评估生成图像与原图像的差异,其计算方法如式(11)。
其中,MSE 是原图像与修复图像之间均方误差。PSRN 值越大,图像之间的像素差异越小。SSIM 分别从亮度、对比度和结构三个方面来评估生成图像与原图像的相似性,计算方法如式(12):
其中μ是图像的平均值,σ是图像的方差。C1和C2是用来维持稳定的常数。SSIM 值越大整体结构约相似。L1 loss是输入和输出之间绝对差值之和,值越小,表示图像失真越小。计算方法如式(13):
表1 统计了本文方法的修复结果与各个方法修复结果几组数据的平均值,可以看到本文方法在三个评价指标上都优于其他方法。

表1 图像修复评价指标
4 结语
本文提出了一种基于生成对抗网络的图像修复方法,利用双重注意力机制和残差网络来增加模型对于图像的上下文信息的理解与利用。同时设计了一种基于多尺度判别器的对抗训练模型,给判别器模型提供不同尺度的梯度信息,帮助模型生成更加清晰的图像。实验结果表明,相比于现阶段的方法,本文的方法充分利用图像中的上下文信息,能生成视觉上更加合理的图像,同时与周围区域的纹理一致性上会更好。通过PSNR、SSIM 和l1 损失对修复结果进行评估也表明本文的方法有更高的可信度。
