基于通勤出行链的公共交通使用行为辨识研究
2023-09-28翁剑成王海鹏
胡 松,杨 贝,翁剑成,王海鹏,常 征
(1.交通运输部公路科学研究所,北京 100088; 2.中路公科(北京)咨询有限公司,北京 100088;3.北京工业大学 北京市交通工程重点实验室,北京 100124)
0 引言
随着国家及各地政府对于城市公共交通系统建设的大力支持及推动,尤其是2018年国家公交都市建设示范城市的评估验收,各大城市居民的交通出行模式与结构也逐渐发生了变化.如何探究出行者的公共交通出行行为机理与特征,有利于为未来提高公共交通服务及出行率.并且,随着智能交通技术等的广泛应用,交通领域的数据资源得到了极大的丰富,结合交通智能海量数据开展公共交通出行行为研究具有重大意义.
近些年,国内外许多专家学者在多源交通大数据的环境下对公共交通使用行为方面进行了大量研究.孙世超等[1]利用上海市通勤人群公交使用情况问卷调查数据,结合营销学领域中的RFM模型对乘客的态度和行为忠诚度进行划分,并得出约1/3 高频率出行者有向其他方式转移的风险.Ma等[2]基于北京市IC和AFC卡的刷卡数据汇集个体出行链,并应用基于DBSCAN算法对出行链进行分析,并结合Kmeans++聚类算法和粗糙集理论对个体的出行特征进行聚类和分类.梁泉等[3]利用北京市公共交通刷卡和线站数据,结合个体出行知识图谱构建了BP神经元网络乘客分类模型,并利用案例验证了算法的准确性.Zhang等[4]利用人际距离学提出了基于规则的群体出行行为划分规方法,并利用北京市交通刷卡大数据开展案例分析,验证了规则算法的有效性与局限性.Cui等[5]利用深圳1个月的智能卡交易数据,提出了1种基于周登机频率的用户分类方法,并利用案例对模型的有效性进行了验证.
通过以上分析可知,现有研究多是采用客观的智能卡交易数据开展研究,缺乏对个体社会经济属性的关联剖析.或者对于公共交通使用情况的分析不够聚焦.因此,本文以大型城市北京为研究背景,结合主观调查问卷数据和客观智能卡刷卡数据提取通勤者的出行链信息,并从公共交通使用行为角度构建人群聚类模型,进而揭示通勤者的公共交通使用行为特征,为未来有针对性地改善公共交通服务水平及提高其分担率奠定基础.
1 数据获取与分析
1.1 主观出行调查数据
RP(revealed preference)调查可获取出行者主观的历史出行行为信息,为进一步研究大型都市公共交通通勤个体及群体的出行行为,本研究以具有“国家公交都市建设示范城市”之称的北京市作为调查城市.
2018年9月于北京实施个体出行调查,并采用线上线下相结合的调查方式.其中,线下调查的日维度时间覆盖早晚高峰与平峰时段,周维度时间覆盖工作日与非工作日,空间维度覆盖主城区内的居住区、商业区与休闲区.详细的问卷调查设计及实施过程可参考2016年Fu和Juan的文献[6].调查共收回问卷317份,通过在公共交通刷卡大数据中检验主观问卷调查获取的卡号有效性,最终得到249份信息可匹配的问卷.部分问卷信息无法与刷卡数据匹配的主要原因为卡号信息填写有误与数据库信息缺失等.为了针对研究公共交通通勤者的使用行为机理,问卷设置了出行目的题项,选取“通勤/通学”者的问卷作为研究基础.
本次调查在研究相关文献的基础上,旨在搜集北京市公共交通乘客的出行行为特征信息与经济社会属性信息,并进行匿名处理.其中,部分出行行为特征信息如出行时间、地点和天数仅作信息验证与辅助参考作用,实际研究则采用个体刷卡的动态交易数据,以体现乘客每次出行的差异性,故本节不做具体展示;而个体经济社会属性信息主要包括年龄、职业、收入、教育程度、汽车拥有量等,具体内容如表1所示.
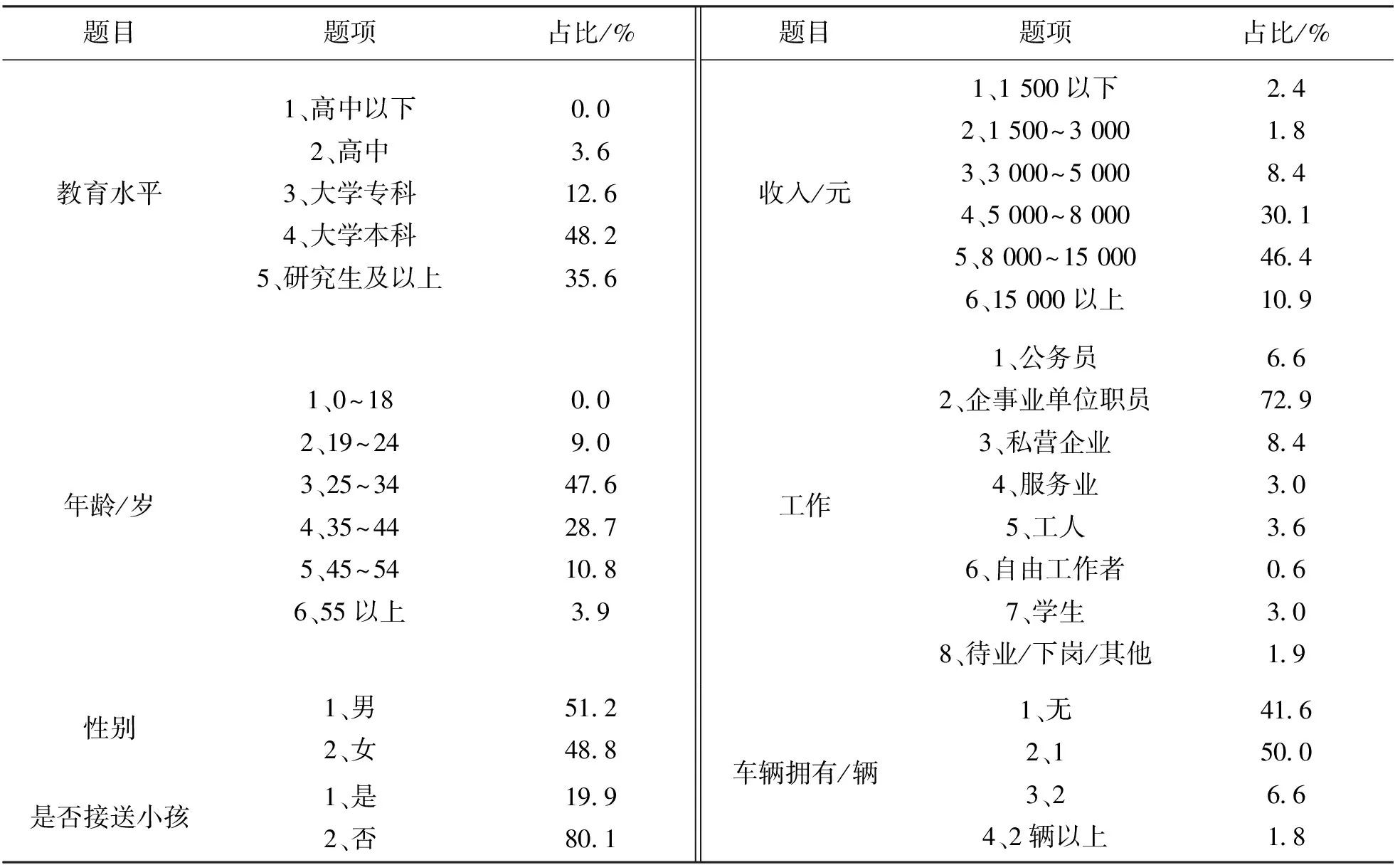
表1 出行者经济社会属性信息统计
在进行数据研究前,为了检验调查问卷结构设计的合理性与问卷信息的可靠性与有效性,需要对问卷数据进行信度与效度的检验.本文利用SPSS软件中的“可靠性分析”功能进行测度,选用Alpha模型在95%置信水平下计算信度系数Cronbach’s α值.经系统可靠性分析,可得有效个案数为249,即所有问卷数据均为有效;而Cronbach’s α值为0.883,大于可接受的最小值0.7,说明问卷数据具有良好的质量.
1.2 客观出行刷卡数据
本文主要依托北京市公交都市平台获取多源公共交通客观数据,提取2018年9月3日至7日5个工作日的刷卡数据开展研究,数据内容主要包括地面公交IC卡交易数据、地面公交GPS数据和轨道AFC系统交易数据等.地面公交初始数据共包含19个字段,从中筛选并保留用户卡号、上/下车线路编号、上/下车站点编号和上/下车时间等关键字段;轨道交通初始数据共包含37个字段,从中筛选并保留用户卡号、进/出站线路号、进/出站车站编码和进/出站时间等关键字段.选取公交GPS数据中的线路编号、数据回传时间、数据回传经纬度以及静态线站表中公交、轨道的站点编号、站点经纬度和站间距等字段,从而对原始公共交通刷卡交易数据进行数据校准与缺失数据弥补,提高数据的密集性与数据质量.
1.3 基于主客观数据的通勤出行链提取
基于处理后的主观调查数据与客观刷卡数据,以时间和用户卡号为关键字对数据进行关联匹配.为链接同1个持卡者1 d中的公交与地铁多段出行数据,需要确定出行换乘刷卡交易时间阈值与站点空间距离阈值,具体阈值可参照文献[7].
为了将获取的主客观数据进行有效的关联,形成信息全面、完备的个体出行链数据,本文提出了基于主客观数据的个体出行链提取方法,具体流程见图1.
按照图1的流程步骤,可获得包含个体社会经济属性与出行行为信息的多源数据的出行链信息,出行链结构及部分内容如表2所示.其中,出行模式表示1次出行所采用的交通方式,B为公交,R为轨道,“-”为换乘.
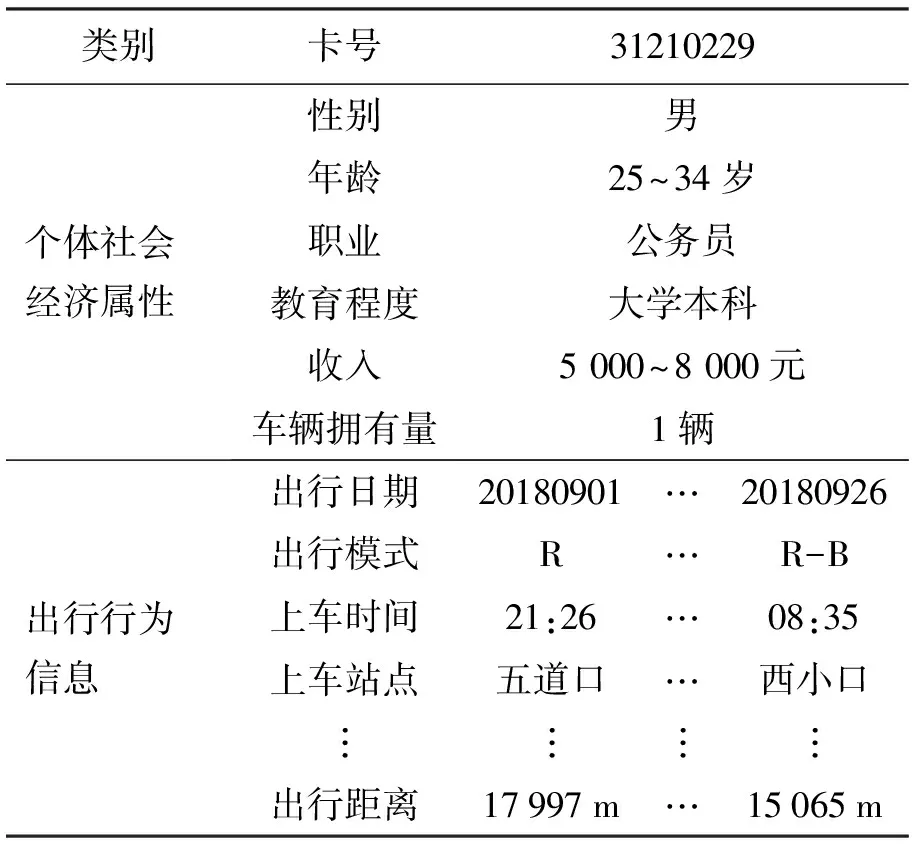
表2 通勤公共交通出行链示例
2 公共交通使用行为模型构建
2.1 公共交通使用行为刻画指标提取
在主客观数据融合的通勤链数据基础上,本研究经过对相关文献的分析与北京市公共交通出行情况的调研,拟选取换乘次数、出行天数和日均出行频次[8-9]、出行完整度[3]4个连续型变量与性别、年龄、职业、教育水平、收入和车辆拥有量6个离散型变量[6]为初始特征指标,以期对北京市公共交通的使用行为提供综合全面的特征刻画.具体指标内容见表3所示.

表3 公共交通使用行为评估指标
2.2 探索性因子分析
为了进一步研究本文所取连续型指标的共线性与相关性关系,利用SPSS软件对其开展探索性因子分析.本文采用基于特征值提取(特征值>1)的最大方差旋转主成分分析法来评估指标内部的一致性,具体结果见表4所示.

表4 指标相关性与显著性矩阵
通常相关系数不小于0.3便认为变量之间存在较好的线性相关性,否则关联性较弱,即表明该变量与其他变量测量的内容不同,在主成分提取中应该剔除.从表4可得知,多数因素之间的相关系数均大于0.3,仅C1与C2、C4之间的相关系数不满足条件;并且,从关系显著性角度可得知,除C1与C4之外的因素间显著相关,均为0.
而因素的成分得分可衡量各成分在整个目标描述过程所占的解释程度,成分得分矩阵如表5所示.
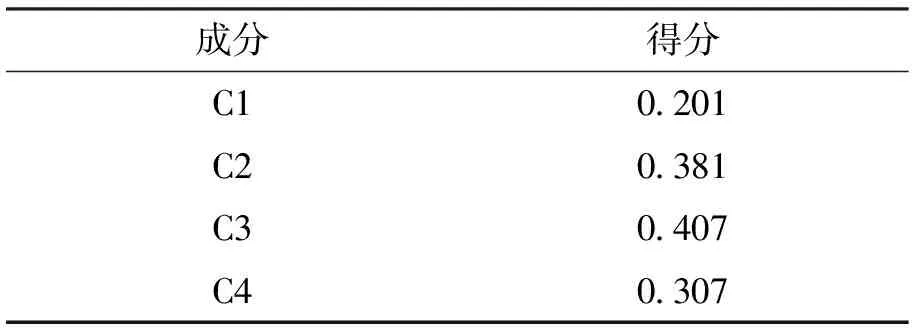
表5 成分得分矩阵
从表5看出,在主成分分析中C1指标的得分最低,表明对于数据变异的解释性较差.综合考虑,本文将换乘次数从指标集中移除,即采用出行天数、日均出行频次、出行完整度及个体社会经济属性等9个因素综合刻画通勤者使用公共交通出行的行为特征.此外,由于个体社会经济属性所表征的内容各不相同,故没有对此类指标因素进行因子分析.
2.3 基于DBSACN算法的公共交通使用行为聚类模型
为了深入挖掘不同通勤者工作日期间使用公共交通的情况,需要基于通勤出行链数据和选取因素集对调查人群进行分类.由于指标数据集中存在连续型变量与离散型变量,较难使用1种有效、准确的算法同时进行处理;并且,离散型变量更有利于分类模型进行数据划分,消除边缘数据分类的混沌性,克服数据中隐藏的缺陷,使模型结果更加稳定.因此,本文首先需要将3个连续型变量转化为离散型变量,再利用聚类模型对人群进行分类分析.
基于对出行天数、日均出行频次、出行完整度数据内容的分析,本文采用等宽法[10]进行数据的离散化.其中,出行频次以间距1将数据分割成i个区间,即[0,1)、[1,2)、[2,3)、[3,4)、[4,∞),各区间的数值类别标号分别为i=1,2,3,4,5.同理,出行天数和出行完整度的数值分割间距分别设置为1和0.2,其区间类别标号均为i=1,2,3,4,5.
具有噪声的基于密度的聚类方法(DBSCAN)模型是1种基于空间密度的聚类算法,该算法视为1种被低密度区域分隔的高密度区域划分方法,可在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合.本文模型中测度样本间的最近邻距离度量参数时,选用普适性较强的欧式距离,见式(1):
(1)
该模型涉及的参数主要为最小样本量(min_samples)、邻域的距离阈值(eps)和叶子节点数量,具体参数取值需要结合数据情况进行标定.DBSCAN模型的构建步骤如表6所示.

表6 DBSCAN模型构建步骤
3 案例分析
为深入量化分析通勤者的公共交通使用行为特征,本文基于2018年9月3日至7日的公共交通刷卡客观数据,匹配调查获取的249个受访者的主观问卷数据,提取案例研究的通勤出行链信息.
3.1 模型构建与参数选取
基于表6的模型构建流程,利用python软件实现DBSCAN模型的构建与数据聚类实施.其中,模型的最近邻搜索算法参数选择“auto”机制,该算法机制可从蛮力模型、KD树模型和球树模型3种方法中基于数据内容自动选取最优的最近邻搜索算法去拟合数据.
此外,将249个样本所对应的9个因素指标数据输入到初始DBSCAN模型中,并利用聚类结果的轮廓系数s(i)对模型结果进行评价,从而对min_samples、eps和树的叶子节点数(leaf_size)等参数进行调整.其中,s(i)的计算式见式(2):
(2)
式中,a(i)为样本i到同簇其他样本的平均欧式距离;b(i)为样本i到其他某簇Cj的所有样本的平均距离最小值,即样本i的簇间不相似度.
经过多次模型拟合的调整过程,确定各参数值为:min_samples=2,eps=1.5,leaf_size=30,此时聚类结果的轮廓系数为0.76,表明聚类结果较为合理.
3.2 群体公共交通使用行为聚类分析
将前述249位受访者的指标数据输入到调整好的模型,最终聚类算法将调查人群划分为3类,具体内容如表7所示.
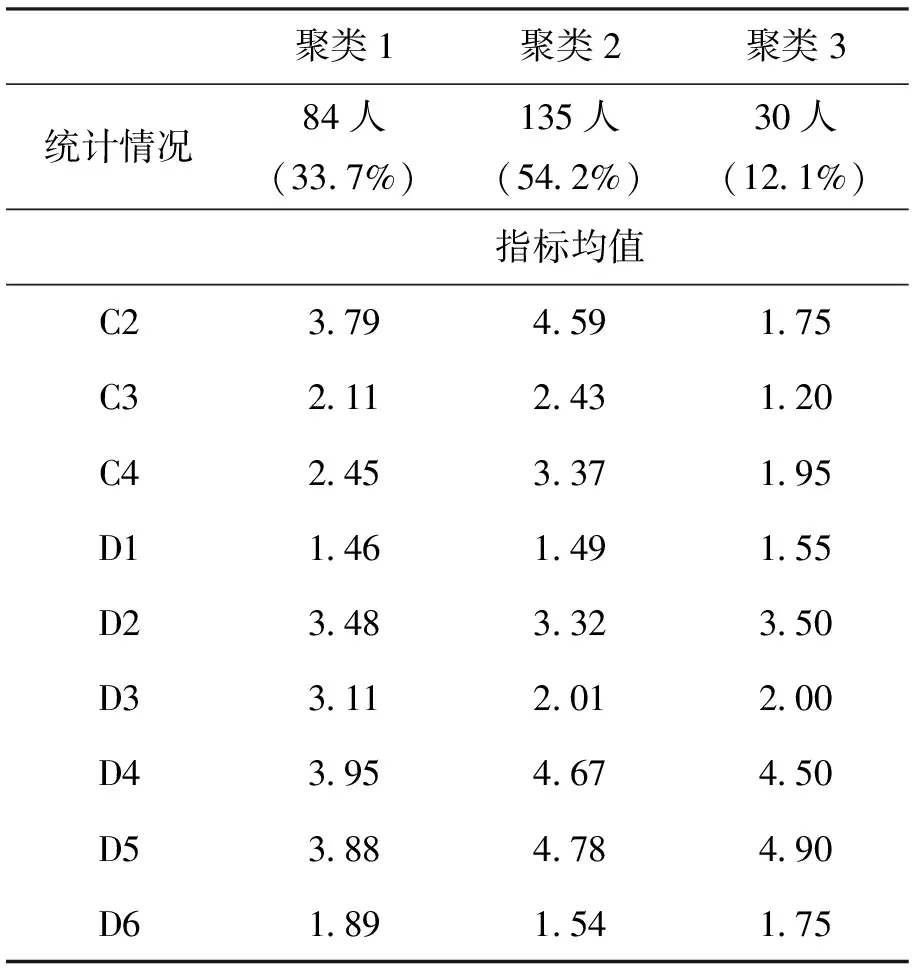
表7 聚类结果统计
从表7看出,3个出行行为指标中,第2类通勤人群的出行天数、日均出行频次和出行完整度均要远高于其他2类人群,表明此类人群在工作日会频繁使用公共交通出行,属于公共交通高使用度乘客,为公共交通系统需要持续维护的顾客群体,而且此类人群在通勤者中的占比也最多.并且,此类通勤者的性别的类别标号为1.49,非常接近1.5,表明该类人群的男女比例十分均衡;同理可知,公共交通高使用度乘客多为25~34岁之间的年轻群体,主要为本科及研究生以上高学历的企事业单位的职员,收入为中高水平,并且拥有0或1辆车的出行者人数较为均衡.
第1类人群为占据通勤者1/3公共交通中使用度乘客,其出行天数、日均出行频次和出行完整度均3个指标值均稍低于第1类通勤者.此类人群的男性稍多于女性,年龄主要在25~44岁,在私企工作者居多,以专科和本科毕业生为主,收入为3 000~8 000的中等水平,大部分人群家庭拥有1辆小汽车.同时也反映了教育水平与工作单位质量、收入整体成正比的关系.
此外,第3类人群的出行天数、日均出行频次和出行完整度3个指标值处于通勤者中最低的水平,即为公共交通低使用度乘客.该类乘客通常采用小汽车、合乘或打车等方式出行,主要由于车辆限行、交通管制、身体不适及天气不良等内外影响因素被迫选择公共交通出行的群体,也正是未来提高公共交通出行率的潜在人群.此部分用户的女性稍多于男性,年龄和是车辆拥有量与第2类人群相似,而其他社会经济属性指标多与第1类人群一致.总体来看,此类人群具有一定的经济基础与稳定的工作,拥有小汽车且追求较为舒适的出行环境,故未来公共交通管理者可从交通限制政策与服务水平2个角度去提高此类通勤者的公共交通使用程度.
4 结论
研究设计并实施了公共交通出行行为调查方案,基于客观公共交通大数据利用关联匹配算法提取公共交通通勤出行链信息.从个体出行行为与社会经济属性角度选取了公共交通使用行为影响指标,利用因子分析法筛选9个刻画指标,结合DBSCAN算法构建了乘客公共交通使用行为聚类模型.结果表明,调查的通勤人群被划分为公共交通高、中、低使用度3类,占比分别为54.2%、33.7%和12.1%,其中第3类为未来提高公共交通出行率的主要争取人群,并且可从公共交通限制政策与服务水平2个角度去促进该类人群的公共交通使用度.研究为深入理解公共交通出行行为,改善公共交通服务水平和吸引力提供技术支持.
