基于BO-FCM和PSO-XGBoost的城市快速路交通状态识别
2023-09-27孙经伟谷远利
孙经伟,谷远利
(北京交通大学 综合交通运输大数据应用技术交通运输行业重点实验室,北京 100044)
0 引言
交通状态识别是智能交通管理和控制中的重要一环,通过实时、准确的交通状态识别可获得道路状态信息,据此诱导和控制交通,有助于缓解城市交通拥堵。因此,交通状态识别成为智能交通系统中重要的研究方向。
目前,交通状态识别方法主要有聚类算法和有监督的机器学习两种。聚类算法具有良好的分类效果,能对交通流数据进行有效分类,同时对交通状态识别的模糊性有较好的适应性。部分学者通过对聚类算法优化或结合其他算法对交通状态进行识别,如结合最优自编码器和K 均值(Kmeans)聚类算法[1]、加权指数的模糊C均值(Fuzzy C-Means,FCM)算法[2]、投影寻踪动态聚类[3]、高斯混合模型聚类算法[4]等,从而实现对交通状态实时有效的判别。不过,聚类算法结果易受初始聚类中心随机选择的影响而陷入局部最优问题,从而导致交通状态识别结果的准确性和稳定性不高。有监督的机器学习算法具有良好的学习能力,可通过训练数据样本获得较高的分类精度,目前已经在交通状态识别领域得到广泛应用。如一些学者尝试使用BP 神经网络(Back Propagation Neural Network,BPNN)[5]、随机森林算法[6]、融合多个机器学习模型[7]、遗传算法优化SVM[8]、K-近邻规则(K-Nearest Neighbor,KNN)[9]、贝叶斯算法[10]等来构造交通状态识别模型,并得到较好的识别结果。不过许多研究对机器学习算法的超参数取值会影响模型训练结果和拟合程度的问题考虑不足,使得模型识别结果未达到最优。
近年来,将聚类算法和监督学习算法相结合的模型越来越多,如商强等[11]提出谱聚类算法和KNN 算法相结合的交通状态判别模型;常丽君等[12]提出优化后的FCM 算法结合概率神经网络的交通状态识别方法。可以看出,聚类算法和监督学习算法相结合的效果较好,聚类算法为监督学习提供了先验数据,监督学习算法则利用先验数据进行训练和测试,保证了交通状态识别结果的实时性。目前集成学习已经成为机器学习的重要组成部分,其通过结合多个学习器来获得优越的泛化能力,在分类问题上展现出明显优势[13]。极度梯度提升树(eXtreme Gradient Boosting,XGBoost)算法是集成学习中的重要算法,其收敛速度快,准确率高且不易过拟合,但XGBoost 算法参数过多且对参数较为敏感,使得其应用较为复杂。
为提高城市快速路交通状态识别的准确性,本文将利用贝叶斯优化算法快速确定FCM 算法的最优初始聚类中心,并利用粒子群算法确定XGBoost算法的最优参数,结合交通状态识别的变化性,构建基于贝叶斯优化改进的FCM 聚类算法与粒子群优化改进的XGBoost 算法相结合的交通状态识别模型,并使用聚类分析后的交通数据对监督学习算法进行训练,提升交通状态识别的效率和稳定性,最后采用北京市三环快速路的交通数据对模型进行实例验证,并与其他方法进行性能对比分析。
1 模型构建
本文主要通过对某一时刻的交通数据进行识别,来判断其所处的交通状态。首先对历史交通数据进行聚类分析并划分出不同的交通状态,得到先验信息,然后利用先验信息训练PSO-XGBoost 模型,在模型中对待识别交通数据进行测试,得到该交通数据所处的交通状态。
1.1 聚类分析
模糊C 均值算法是一种经典的聚类算法,因其能提供灵活的聚类结果且适用于不同的数据类型而在众多模糊算法中应用最为广泛。本文利用FCM 算法对交通流量、速度和道路占有率进行聚类分析,得到每个交通数据的状态标签,目的是实现被划分为同一聚类的样本数据对象间的最大相似性和不同聚类的样本数据对象间的最小相似性。通过对目标函数进行优化,获取每个样本对所有类中心的相似程度,即隶属度,进而对样本进行自动分类。
目标函数[14]为:
式(1)中:J是目标函数;n是样本数;c是聚类中心个数;m是任何大于1 的实数;xi是第i个样本点;uij是第i个样本点的第j个类中心的隶属度;cj是第j个类中心。
FCM 算法初始聚类中心的随机性对聚类的结果影响很大,容易使算法陷入局部最优,造成聚类结果的准确度不高且运行时间较长,故需要优化FCM 算法以解决算法局部收敛的问题。贝叶斯算法是一种运行速度快、稳定性良好的全局优化算法,其利用已搜索过的点的信息来提升搜索效率,减少迭代次数,进而快速获得最优解,可有效解决FCM算法问题。
贝叶斯优化FCM 算法(Bayesian Optimization,BO-FCM)的流程如下:
1)初始化高斯回归模型(Gaussian Process Regression,GPR),采集函数UCB(Upper Confidence Bound),确定最大迭代次数,定义目标函数Jm=f(C)和聚类中心的参数空间。
2)随机选取聚类中心点作为BO 算法的初始值。
3)拟合高斯回归模型,通过采集函数UCB来计算优化结果,执行贝叶斯优化算法后得到聚类中心Ci,计算目标函数值Jm=f(Ci)。
4)不断迭代直至达到最大迭代次数,输出历史最佳参数即聚类中心。
5)将贝叶斯优化算法的结果代入FCM 算法得到样本数据的聚类结果,完成交通状态划分。
1.2 PSO-XGBoost算法
XGBoost 算法[15]属于Boost 算法,其目标函数为:
式(2)~式(3)中:L(φ)为目标函数;l为单个样本的损失;yi为标签值;为预测输出;Ω(fk)为正则化项;fk为树模型;k为树的数量;γ为叶子树惩罚正则项;T为树叶子节点数;w为叶子权重值;λ为叶子权重惩罚正则项。
XGBoost 算法主要是在损失函数的基础上加入了正则化和采用缩减办法来防止过拟合,同时对目标函数进行泰勒展开,利用推导得到的表达式作为分裂准则来构建每一棵树。该算法能在避免过拟合的前提下对目标函数进行拟合,提升识别精度,具有较强的泛化能力,同时支持并行化处理,运行速度得以提高。XGBoost 算法的缺点是参数过多,对参数敏感,因此算法的应用较为复杂。为了合理有效地选择算法的超参数,提高算法识别精度,使用收敛速度快、可调整参数少、寻优能力强的粒子群优化算法(Particle Swarm Optimization,PSO)对XGBoost 的参数进行优化。
粒子群优化算法通过在一组无质量的粒子中对鸟类进行建模,所有粒子根据所寻求的个体极值和当前全局最优解来调整位置和速度,进而找到粒子群的全局最优解。PSO算法实现较为简单,不涉及复杂的神经网络模型且收敛速度较快。PSO-XGBoost算法流程如图1所示。
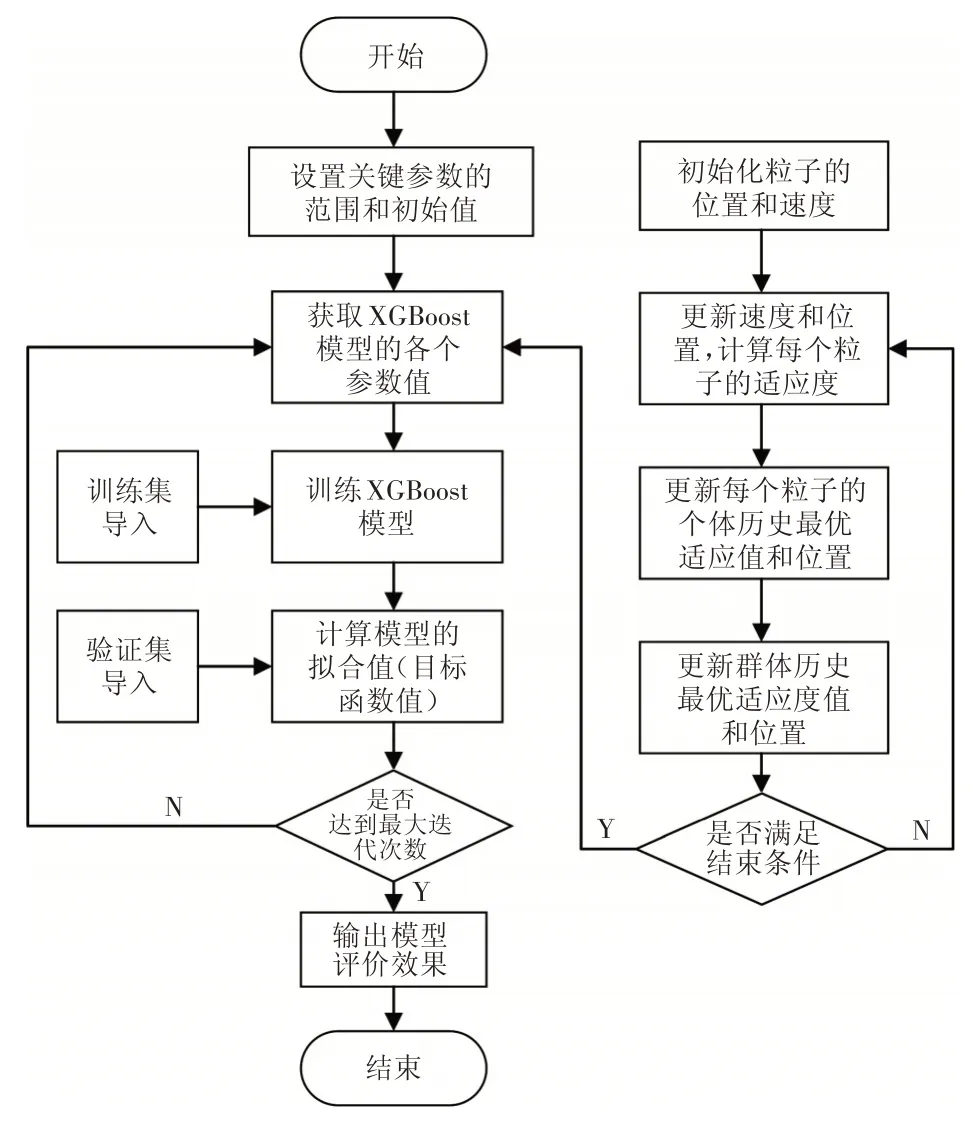
图1 PSO-XGBoost算法流程图
根据图1,PSO-XGBoost算法的具体流程如下:
1)定义PSO 算法的参数,包括粒子群规模N、粒子维度D、迭代次数K、惯性权重ω,确定需要优化的超参数,同时设置每个参数的调节范围。
2)随机初始化粒子群,通过评估粒子的适应度值来对粒子和群体的全局最优位置进行比较,不断更新速度和位置,当达到最大迭代次数后结束粒子群算法流程,得到最优参数。
3)将历史交通流数据的聚类结果分为训练集和测试集,对参数优化后的XGBoost 模型进行训练和测试,实现交通状态识别。
1.3 交通状态识别模型
本文利用贝叶斯优化后的FCM 算法对历史交通流数据进行状态划分,将聚类结果分为训练集和测试集,对PSO-XGBoost 算法进行训练和测试验证,从而实现交通状态识别。完整的交通状态识别步骤如下:
1)以交通流量、速度和道路占有率作为特征参数,进行交通状态划分。
2)根据文献[12],将城市交通状态划分为畅通、平稳、拥挤和拥堵4 个等级,对应的标签编号为0,1,2,3。使用BO-FCM 模型对交通流数据进行聚类分析并获得实验数据的交通状态标签。
3)将已经划分交通状态的特征变量数据按4∶1 分为训练数据和测试数据,其中训练集的输入为所选取的3 个特征参数,输出为相应的交通状态。
4)使用训练集数据对PSO-XGBoost 模型进行训练,然后利用测试数据对训练后的模型进行验证测试,对模型性能进行评价。
2 实例验证
2.1 数据处理
采用北京市西三环快速路的交通流数据进行交通状态识别实验和模型测试。选取西三环航天桥南—紫竹桥北作为实验路段,检测器分布如图2 所 示。采 集2014 年1 月6 日—2014 年1 月10 日全天流量、速度和道路占有率数据,以2 min 为时间间隔,日交通数据序列个数为720 个,数据缺失率不高于5%,数据总量为17 897 条,能较好地展现交通流变化和交通流特性。在实验开始前,先对原始数据进行筛选,剔除缺失数据和异常数据,如北京市三环快速路的限速为80 km/h,因此删除速度为80 km/h 以上的数据点,然后使用Z-score 标准化方法将数据转换为正态分布,同时将Z-score 值的绝对值小于3 的数据点视为异常点,予以删除。将所有数据点绘制成箱线图,如图3 所示,可以看出3 项交通流参数属性正常,异常点已剔除。以1 月6 日—1 月9 日的数据为训练数据,1 月10 日的数据为测试数据,在Python平台进行模型实验。

图2 检测器分布图
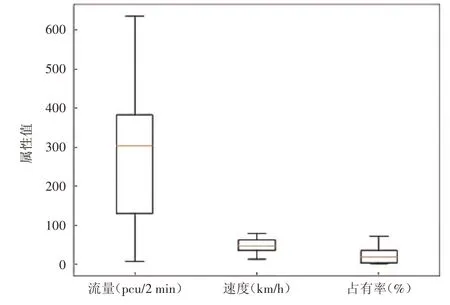
图3 样本数据箱线图
2.2 基于BO-FCM的交通状态划分
根据交通流中的速度、交通流量及道路占有率,将样本数据所处的交通状态划分为4 类,分别是顺畅、平稳、拥挤、拥堵。确定聚类数目为4,通过贝叶斯优化算法不断迭代300次得到FCM算法的初始聚类中心矩阵为:
基于以上初始聚类中心进行聚类,得到聚类结果如图4 所示。每类交通状态下的交通流量、速度和道路占有率的均值如表1 所示。从表中可以看出,每种交通状态下的交通流量、速度和道路占有率都有较大差异,且4 种交通状态都有较明显的规律。处于第0类交通状态下的速度较大,但交通流量和道路占有率都很低,对应于顺畅的交通状态;第1 类交通状态的速度较第0 类下降,但交通流量和道路占有率有所提高,此时处于平稳状态;第2 类和第3 类的交通状态变化情况相同,对应于拥挤和拥堵状态。从顺畅到拥堵的交通状态变化过程中,可以看出速度在不断降低,而交通流量和道路占有率不断提高,算法优化后所得结果与实际交通流变化规律相同。
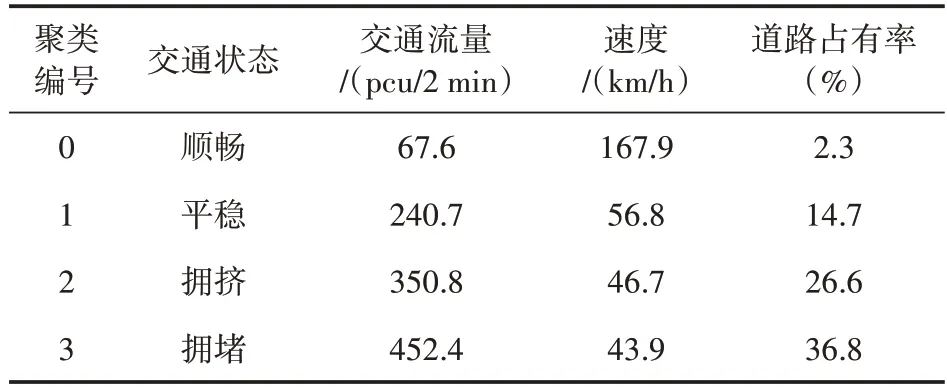
表1 交通流参数均值

图4 聚类结果
为验证聚类结果的准确性,以点位3 063 的数据聚类结果为例,其2014 年1 月6 日—1 月9 日的交通状态变化情况如图5 所示。可以看出,0:00—6:00,交通流处于顺畅状态;6:00之后车流量不断加大,出现早高峰,交通流状态从顺畅转为拥堵;随后交通流状态不断波动,晚高峰出现在15:00—18:00,此时交通状态又转变为拥堵,之后逐渐趋于平稳状态。模型得到的聚类结果和实际道路交通变化情况较为接近,BO-FCM 模型能有效划分交通状态。
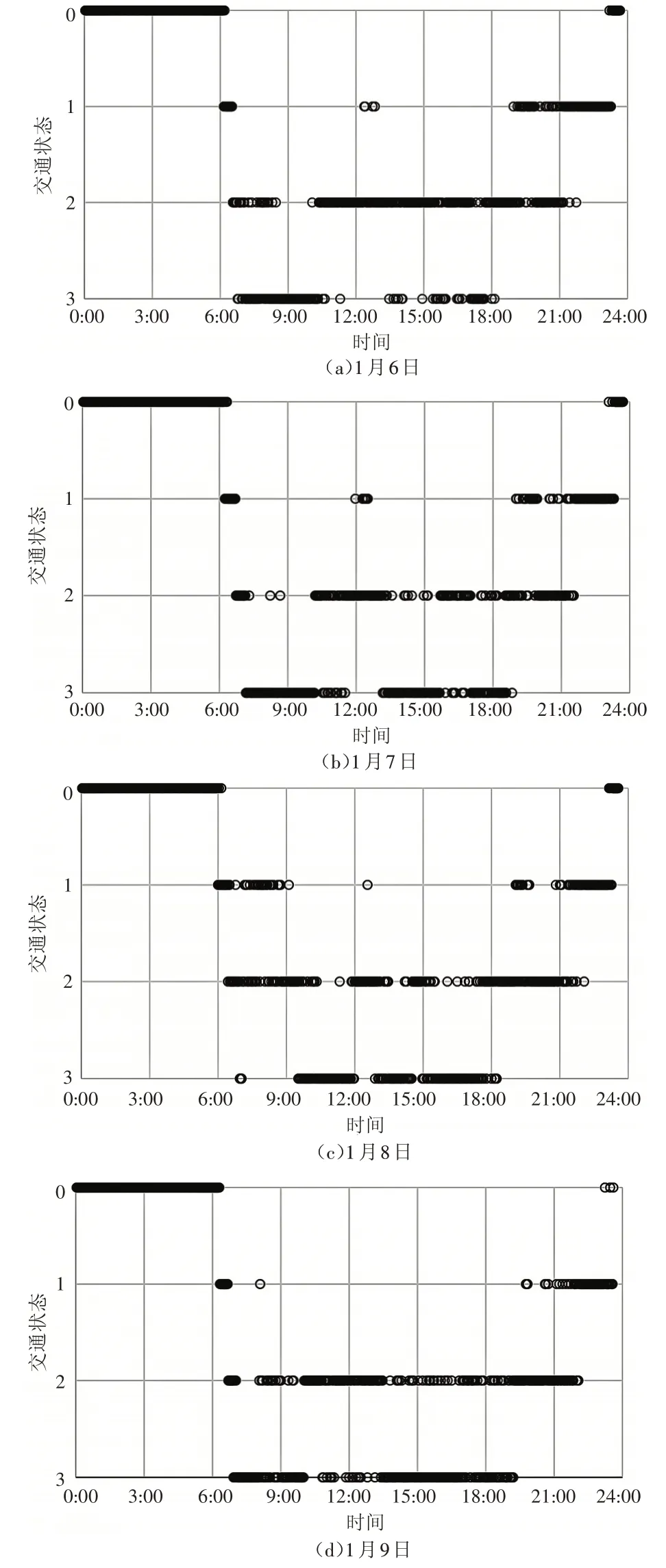
图5 1月6日—1月9日交通状态变化
2.3 PSO-XGBoost模型交通状态识别
实验中,选取6 个对模型结果影响较大的参数对XGBoost 算法进行优化,分别为影响模型稳定性的学习率,控制模型拟合程度的树的最大深度,最小叶子节点样本权重,随机采样比例,控制随机采样列数占比的使用的特征占比,影响模型损失函数值的节点分裂所需的最小损失函数下降值。设置各参数的变化范围,使用PSO 算法进行寻优得到最佳模型参数,如表2 所示。将优化得到的模型参数代入XGBoost中进行训练和测试,使用1 月6 日—1 月9 日的数据作为训练数据,1 月10日的数据作为测试数据。
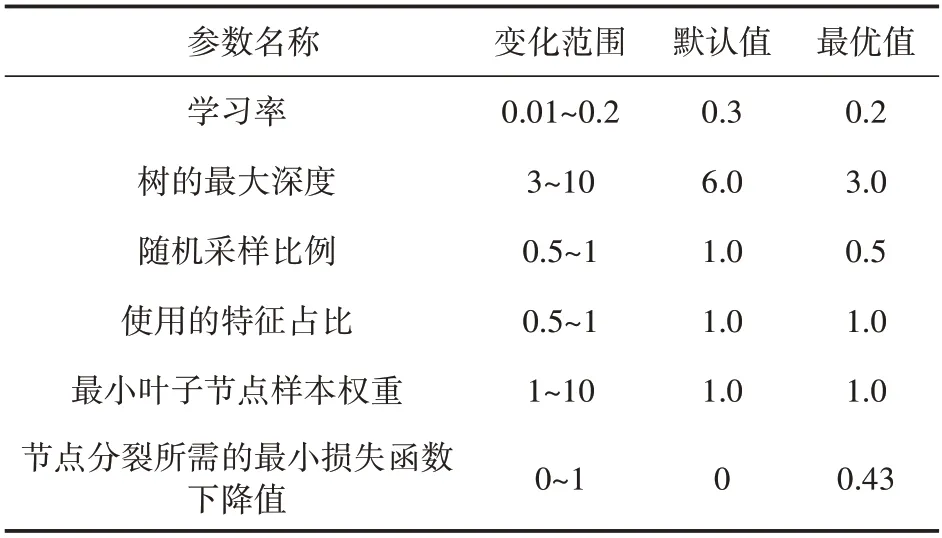
表2 最优参数值
2.4 模型性能整体评价
为了明确本文模型的准确率和稳定性,将其与支持向量机(Support Vector Machine,SVM)模型、随机森林(Random Forest,RF)算法、K 最近邻算法进行对比分析。依据文献[8],先将SVM模型中的RBF 核函数设置为21,惩罚系数设置为0.5,随机森林算法和K 最近邻算法的参数值采用默认值,然后采用Python 中的sklearn 库建立和运行SVM,RF,KNN 模型。本文模型和其他模型的交通状态识别混淆矩阵如图6 所示,图中各行是实际交通状态,每列是预测交通状态,对角方格中的数表示每个交通状态识别正确的数量,如第1 行第1 列表示能正确识别为顺畅状态的数据有853 个。由该图可知,本文算法在全部3 487 个测试数据中,识别错误的数据只有2 个,其识别出的状态和实际状态只相差1 个交通状态类型,分别是将实际的平稳状态识别为顺畅状态和拥挤状态,模型的总体准确率达99.94%,识别精度较高,其他模型则多次出现识别状态和实际状态相差2个类型的情况,这表明本文算法稳定性较好。本文算法与另外3 种算法的识别结果如表3 所示。从该表可知,本文模型的识别准确率比SVM,RF,KNN等常见模型分别提高了1.23%,1.06%,1.57%。
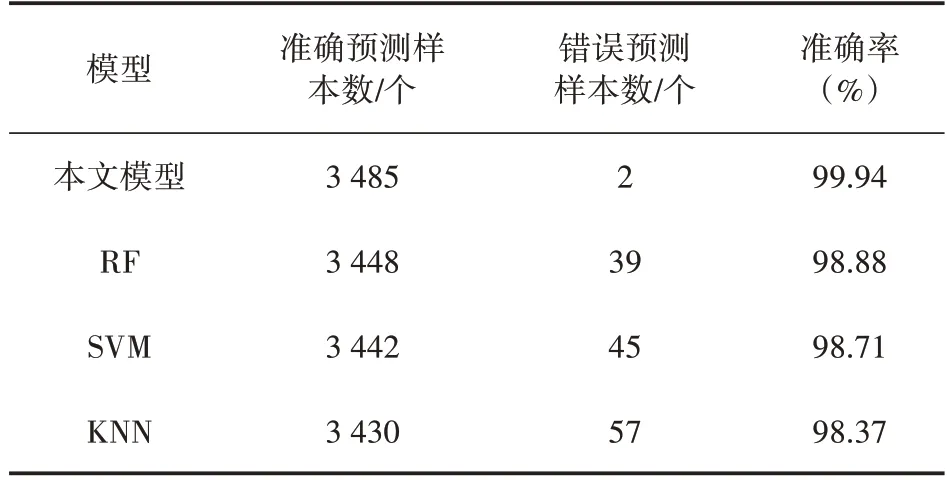
表3 不同方法的识别结果比较
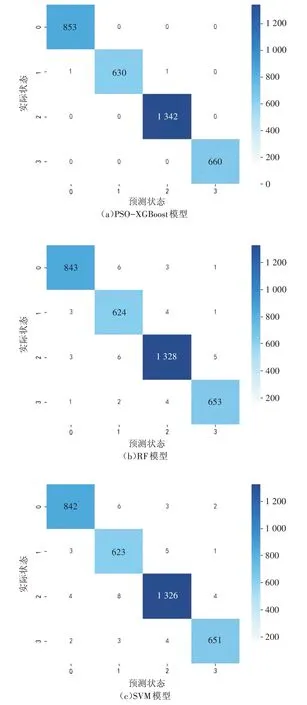
图6 不同模型识别结果的混淆矩阵
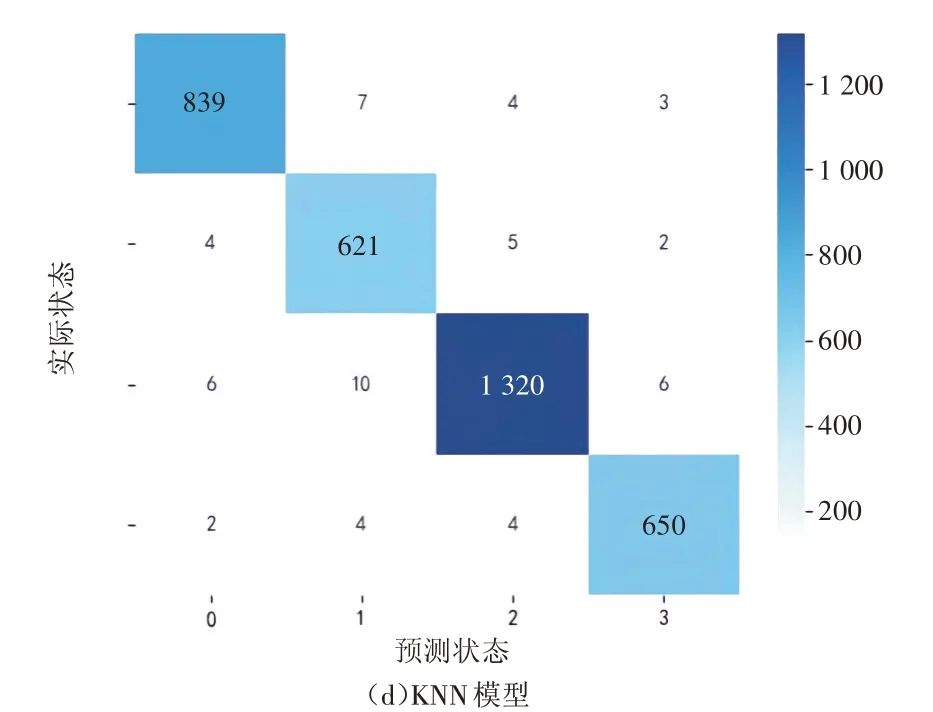
图6 (续)
3 结束语
交通状态识别是城市智能交通的重要基础,为提高交通状态识别的准确率,本文结合聚类算法和监督学习算法的优势,提出一种基于贝叶斯优化的FCM 算法和PSO-XGBoost 算法相结合的快速路交通状态识别模型,针对FCM 算法易陷入局部最优和XGBoost 算法参数复杂敏感的问题,对FCM 算法的初始聚类中心和XGBoost 算法的重要超参数两个方面进行优化,最后利用历史交通流数据对模型性能进行了测试和比较分析。结果表明,本文方法实现了对交通状态的精准识别,对比其他常见算法,不仅对交通状态识别的准确率更高,错判率更低,而且稳定性好,表明所建立的模型性能更优越,可为准确获取交通出行信息和改善交通拥堵提供方法支撑。本文在交通状态识别过程中未考虑聚类中心数量对识别结果的影响,在未来研究中将对不同聚类中心数量下不同道路的交通数据进行测试和模型性能分析。
