基于EfficientNetV2和物体上下文表示的胃癌图像分割方法
2023-09-27张自力胡新荣何儒汉
周 迪,张自力*,陈 佳,胡新荣,何儒汉,张 俊
(1.武汉纺织大学 计算机与人工智能学院,武汉 430200;2.武汉纺织大学 湖北省服装信息化工程技术研究中心,武汉 430200;3.武汉纺织大学 纺织服装智能化湖北省工程研究中心,武汉 430200;4.武汉工程大学 计算机科学与工程学院,武汉 430205)
0 引言
癌症是困扰全世界的疾病之一,根据世界卫生组织在2019 年的调查统计[1],胃癌的发病率和死亡率都比较高,仅在2020 年里,就增加了100 多万新病例和76.9 万的死亡病例,相当于每13 个死亡病例里就有1 例死于胃癌。目前推测慢性幽门杆菌传染是造成患病的主要原因,该细菌的传染性极强,传染了全世界近50%的人口[2]。
病理作为医疗领域的“金标准”,在临床诊断中有着其他诊断所无法替代的重要作用。然而,病理诊断行业存在诸多问题[3]:职业风险大、培养周期长以及职业收入低。基于以上原因,主动做病理医生的人数少。
近年来,随着全切片扫描技术的发展,不但使病理切片的获取更方便,更重要的是改变了传统的阅片方式,使得将计算机视觉技术和病理图像诊断结合成为可能。利用计算机技术对病理图像进行分割,让医生更直观地发现图像中的病变区域,对于帮助病理医生更进一步地判断胃癌的分期、分型具有重要意义。
神经网络在短短几年内迅速发展,如今已应用到语音识别、图像识别、自然语言处理等诸多领域。随着人工智能的迅速发展,卷积神经网络(Convolutional Neural Network,CNN)越来越强大,在图像分割领域出现了许多优秀的网络框架,如全卷积网络(Fully Convolutional Network,FCN)[4],它被认为是深度学习用于语义分割的开山之作,将传统CNN中最后的全连接层换成了卷积层,这样的设计可以使网络适用于任意尺寸的输入,实现了端到端的训练。但是,它的缺点也很明显,上采样过程过于粗糙,只用了简单的反卷积,使得最后分割结果不够精细。后续也有许多研究者采用马尔可夫随机场[5]和条件随机场[6]优化分割结果。比如DeepLab[7-10]系列让深度学习在分割领域前进了一大步,通过引入空洞卷积来解决卷积越多,丢失信息越多的问题,在没有加入参数和多余计算的情况下,扩大了感受野;同时,引入了空洞空间卷积池化金字塔(Atrous Spatial Pyramid Pooling,ASPP)结构,在不改变特征图大小的前提下,增大网络的感受野,使网络能提取多尺度信息。采用以上优秀的成果使利用计算机视觉技术分割病理图像成为可能。
目前深度学习在胃癌病理领域的应用较少,不过在整个医学领域中已经有了较多的研究成果。Ronneberger 等[11]提出的U-Net 模型是医学分割中最经典的网络模型之一,该模型及其改进方法仍然被应用在各种医学分割任务中,并且取得了不错的分割结果。U-Net 基于FCN 结构,将上采样模块设计成和下采样类似的模块;同时,通过跳跃连接防止细节丢失,结构简单、效果好,在当时ISBI(International Symposium on Biomedical Imaging)比赛的神经元等多项任务中获得冠军,但是缺点也十分明显,该模型的特征提取网络太浅,导致提取的特征具有局限性。Milletari 等[12]针对临床图像是3D 图像的问题,提出了V-Net 模型,将3D 卷积与UNet 进行结合来分割3D 图像;同时,提出Dice 系数损失函数来解决数据集正负样本不平衡的问题,在前列腺核磁共振(Magnetic Resonance Imaging,MRI)数据集中分割的Dice 评分达到了86.9%。Alom 等[13]基于传统U-Net 提出一个全新的R2U-Net(Recurrent Residual Convolutional Neural Network based on U-Net)模型,将循环残余卷积与U-Net 结合,有利于深层网络的训练,在相同参数的情况下,该模型在视网膜血管等分割任务中取得了更好的结果。Zhou 等[14]针对U-Net最佳深度未知的问题,提出了U-Net++模型,在编码器和解码器之间加入大量跳跃连接来提高网络特征提取能力,该模型在六种常见数据集中皆取得了优于当时其他网络模型的成绩。Oktay 等[15]在U-Net 上采样过程中添加注意力机制,让网络学会抑制不相关区域,注重有用的特征,提出了Att UNet(Attention U-Net),在电子计算机断层扫描(Computed Tomography,CT)数据集的胰腺任务中Dice 系数达到84%。张泽中等[16]基于多尺度输入提出了多输入融合网络(Multi-Input-Fusion Net,MIFNet),同时将不同尺寸的图片作为网络的输入,提高网络提取不同尺度特征的准确度,在病理切片识别AI 挑战赛数据集上的Dice 评分达到81.87%。
一般来说,超声、CT 和MRI 等医学造影图像中的数据特征相对较少,器官位置等信息相对固定,往往能花费较低的计算资源就获得令人满意的效果,但在具有复杂特征的病理学等数据中,获得的结果往往不尽如人意。所以,想要提高网络预测结果准确度,需要解决以下3 个问题:1)针对胃癌病变区域和形状不固定的问题,如何提取更好的病变特征图?2)针对胃癌病变区域边缘复杂的问题,如何让网络上采样过程中保留更多细节?3)如何解决数据集偏小,容易出现过拟合的问题?
针对上述问题,本文改进U-Net 并结合EfficientNetV2 和物体上下文表示(Object-Contextual Representation,OCR)的优点,提出一种基于改进U-Net 的自动分割胃癌病理图像模型EOU-Net。本文使用公开的2021“SEED”第二届江苏大数据开发与应用大赛(华录杯)医疗卫生赛道提供的胃癌病理切片图像数据集(后文简写为SEED 数据集)(https://www.marsbigdata.com/competition/details?id=21078355578880)、2017 中国大数据人工智能创新创业大赛系列之“病理切片识别AI 挑战赛”提供的胃癌病理切片数据集(后文简写为BOT 数据集)(http://www.datadreams.org/#/newraceintro_detail?id=225)和经典分割数据集PASCAL VOC 2012(http://host.robots.ox.ac.uk/pascal/VOC/voc2012/)进行实验。
1 本文方法
1.1 网络框架
针对引言提出的3 个问题,本文对传统U-Net 作出了3点修改:首先,为了让网络能应对病理图像复杂特征,引入优秀的分类网络EfficientNetV2[17]作为U-Net 的编码器(Encoder)来提高网络的特征提取能力;然后,为防止网络在上采样阶段丢失病理图片复杂的边缘信息,加入了本文改进的OCR 模块,通过细胞上下文特征信息判断某个像素是否与周围像素属于同一类,从而提高网络分割的边缘精度;最后,为了应对医学数据集普遍偏小,训练过程容易出现过拟合的问题,加入了验证阶段增强(Test Time Augmentation,TTA)后处理模块,对同一张图片进行多次变化,分别预测,并将不同预测结果通过特征融合的方式得到网络最后的分割结果。具体网络模型如图1 所示,主要分为三个部分:1)由MBConv 和Fused-MBConv 组成的编码器,用于提取图像中不同感受野的胃癌区域特征;2)加入了改进后的OCR 解码器模块(Decoder),将不同感受野提取的特征图进行融合,然后上采样恢复到原图大小,并通过探索图像中像素间关系来解决上采样带来的细节丢失问题,优化模型输出的边缘细节;3)TTA 后处理模块,通过对输入图片进行多次变换,并融合多次变换的预测结果,得到最终的网络输出结果。
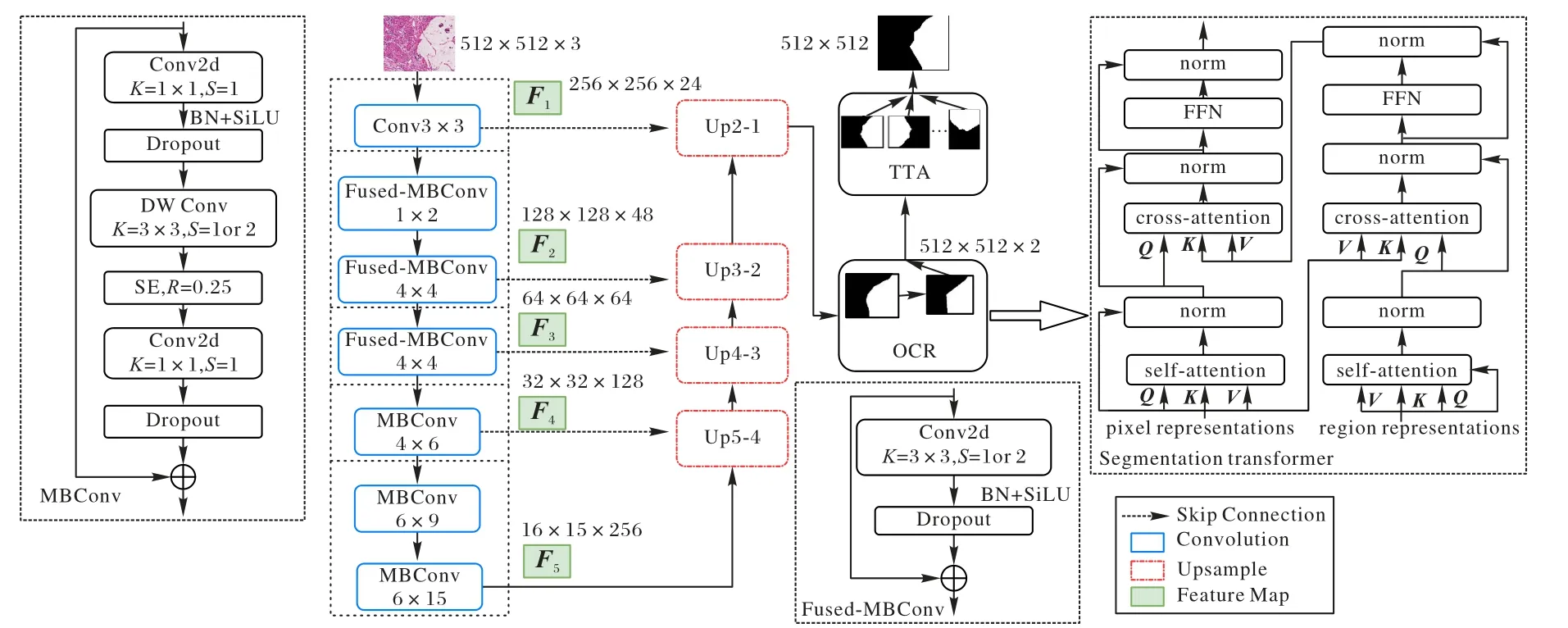
图1 EOU-Net网络模型结构Fig.1 Network model structure of EOU-Net
在数据处理阶段,本文首先对胃癌数据集进行预处理,将图像统一缩放到512×512,在编码阶段通过EfficientNetV2主干网络提取特征,得到5 个感受野不同的特征图:F1、F2、F3、F4和F5,其中:K为卷积核大小;S为卷积步距,R表示SE(Squeeze-and-Excitation)注意力模块节点舍弃的比例,MBConvM×N表示中间层通道数扩大M倍,该模块重复N次。特征提取后,依次对特征图进行上采样,接着将Up2-1上采样之后的结果,通过改进后的OCR 模块,这样就完成了一次预测。接着,通过TTA 后处理模块对输入图像多次预测,就能得到网络最后的预测结果。
1.2 EfficientNetV2特征提取模块
传统U-Net 的特征提取网络有一个致命的局限性,即模块细节是人为决定,那么很容易让人产生怀疑:如果网络更深、更宽,输入图像更大,那么网络的特征提取能力是否会更好。然而,随着卷积神经网络(CNN)的发展,已经出现了许多更优秀的卷积、激活函数、注意力等模块,这些模块的搭配方案非常多,想要人为穷举找出最好的特征提取网络并不现实。所以,如果能借助某种方法找出这些优秀模块的最佳组合方案,能有效提高特征提取网络的特征提取能力。
目前,主要从网络的深度、宽度和图像分辨率来提升CNN 的特征提取能力。然而,这三个参数并不是增加得越多,网络的特征提取能力越好,随意修改参数,往往会出现反效果;同时,参数选择过多,人工调参优化工作也会过于繁重。Tan 等[18]研究这三个参数的最佳搭配关系,并提出了EfficientNet,通过NAS(Neural Architecture Search)技术[19]以准确度和运算量为优化目标来平衡网络深度、宽度和图像分辨率,最后得到EfficientNet-B0,在ImageNet 分类任务上有84.3%的准确度,需要的参数也远少于其他网络。
EfficientNetV2[17]是继EfficientNet 之后提出的全新网络。针对EfficientNet 训练图像过大时,有可能出现内存不够以及在浅层网络使用DW(DepthWise)[20]卷积训练速度过慢的问题,提出了Fused-MBConv 模块,并且使用NAS 技术探索Fused-MBConv 和MBConv 模块的最佳组合方式,最后提出了全新的EfficientNetV2,在ImageNet 分类数据集上,不仅有87.3%的准确度,训练速度也更快。本文将EfficientNetV2 引入图像分割领域,提出一种使用EfficientNetV2 提取特征的方法,使U-Net 的编码器有更优秀的特征提取能力,EfficientNetV2 的基本模块如表1 所示。其中:MBConvM的M表示中间层通道数扩大倍率;k 表示卷积核大小;SE 表示注意力模块节点舍弃比例。本文的输入图像大小统一缩放为512×512。首先,通过Stage0 的stem 模块得到256×256 的特征图F1;其次,通过Stage1、Stage2 的Fused-MBConv 模块得到128×128 的特征图F2;然后,通过Stage3 的Fused-MBConv模块得到64×64 的特征图F3;接着,通过Stage4 的MBConv 模块得到32×32 的特征图F4;最后,通过Stage5、Stage6 的MBConv 模块得到16×16 的特征图F5。至此,得到5 个不同感受野的特征图,将用于后续的上采样和特征融合。

表1 EfficientNetV2基本模块Tab.1 Basic modules of EfficientNetV2
1.3 改进后的OCR解码器模块
感受野对于语义分割任务来说非常重要,能直接影响网络分割物体的大小。而CNN 使用的卷积不论是3 × 3 还是7 × 7,始终有大小限制。所以,CNN 通过堆叠卷积获取的感受野也必然有局限性。早些年,为了扩大网络的感受野往往会采用金字塔场景解析网络(Pyramid Scene Parsing Network,PSPNet)[21],或者ASPP[8]结构。随着Non-local[22]提出后,许多研究[23-25]尝试从self-attention 的角度解决该问题。受到OCRNet[26]的启发,本文对OCR 模块作出了两点改进:1)没有将像素特征(Pixel Representations)与细目标区域(Fine Object Regions)进行拼接;2)将Fine Object Regions 和软目标区域(Soft Object Regions)按照相加的方式进行特征融合,因为考虑到人工设置权重往往很难找到最合适的值,不如直接交给卷积去完成这个任务,这样就能在保证效果的同时,减少模块的参数和计算量,具体结构如图2 所示。

图2 改进后的OCR模块结构Fig.2 Structure of improved OCR module
在解码阶段,本文使用线性插值的上采样方法,该方法相较于转置卷积需要的计算量更小,其实际效果与转置卷积效果相差不大,而且转置卷积如果参数选择得不合适很容易出现棋盘效应[27]。基于以上原因,本文选择线性插值方法,实际结构如图3 所示。
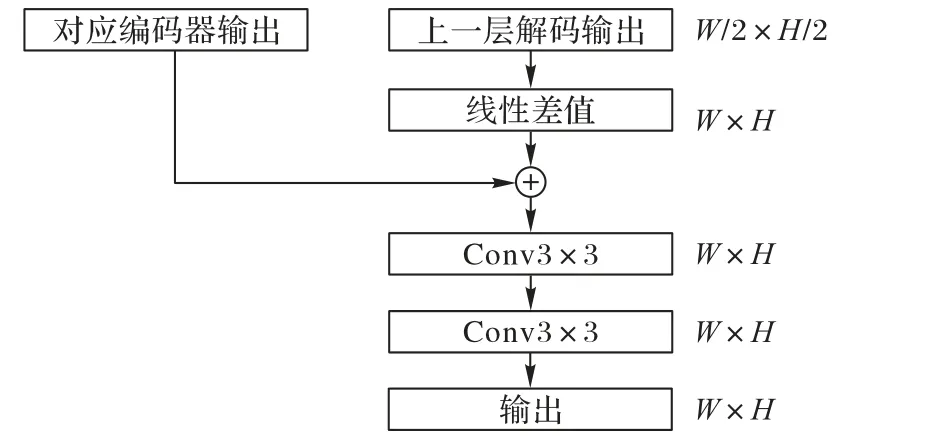
图3 上采样的结构Fig.3 Structure of upsampling
首先,将上一层上采样得到的特征图通过线性差值的方式放大一倍;然后,将它与骨干特征提取网络得到的同一大小特征图按相加的方式进行特征融合;最后,通过两个3 × 3的卷积便能得到这一层上采样输出,重复这个过程直至上采样到原图大小1/2 时,为了避免感受野带来的局限性,通过改进后的OCR 模块来探索像素与像素之间的关系。OCR 本质就是一种由粗到细的分割,设输入图片为I∈RH×W×C,对应的输出结果为Y∈RH×W。其中,H、W、C表示输入图片的行、列和通道数。在本文中,H=W=512,C=3。首先,通过骨干特征网络以及上采样操作得到输入特征图;然后,再依次通过变换函数得到每个像素特征(Pixel Representations)和2 个软目标区域(Soft Object Regions)分别对应病变区域和健康区域,如式(1)~(3)所示:
其中:θ(·)表示做4 次图3 所示操作,得到原图大小1/2 的特征图fB,将它作为改进后OCR 模块的输入;ϕ1(·)和ϕ2(·)是变换函数,由3×3 卷积、批归一化(Batch Normalization,BN)、线性整流函数(Rectified Linear Unit,ReLU)实现;fS代表软目标区域,通道数为2,将它作为粗分割,用于最后的特征融合;fP代表每个像素的语义信息和特征,通道数为256。
根据每个像素的语义信息和特征得到每个类别区域特征(Object Region Representations):
其中:Xi表示第i个像素的特征向量;Mki表示第i个像素是k类的概率,本文分为病变区域和健康区域两类,所以,k=2。随后,使用self-attention 计算每个像素与各个区域的关系,具体见式(5)~(6):
其中:κ(·)、γ(·)、δ(·)均为变换函数,由1×1 卷积、BN、ReLU 激活函数实现;Q、K、V为3 个向量;dK是K的维度,fR是像素与各个区域的关系。然后计算物体上下文特征fO:
最后,通过卷积将上下文特征通道数转换到分割类别数,然后和粗分割采用相加的方式进行特征融合,就能得到最终改进后OCR 模块的输出,具体见式(8):
其中:Y为改进后OCR 模块的最终输出;ρ(·)和σ(·)为3×3卷积。OCR 模块能很好地优化胃癌病理图像的病变细胞和正常细胞的复杂的边缘区域,使预测图更接近实际情况。
1.4 TTA后处理模块
通过1.3 节的方法能得到预测图,但该预测图很可能存在因网络过拟合而导致分割错误的地方,所以需要后处理方法来解决这个问题。图像增强技术目前被广泛应用在训练阶段,常常通过对原数据集进行一系列变换来达到扩充数据集的目的,从而增加数据集的多样性,常见的变换有翻转、裁剪、旋转和缩放等。许多研究表明,通过后处理方式能进一步提高网络的精确度,DeepLabV2[8]使用稠密条件随机场(Dense Conditional Random Field,DenseCRF)优化分割的边缘细节,从而提高网络分割结果;然而,该算法要求分割区域与其他区域存在一定差异才会有比较好的效果,具有一定局限性。Wachinger 等[28]使用3D DenseCRF 提高国际医学图像计算和计算机辅助干预协会(Medical Image Computing and Computer Assisted Intervention society,MICCAI)数据集的边缘分割效果;石志良等[29]利用腐蚀图替代人工输入初始化图割模型,实现相邻骨组织的自动分离。TTA 也是其中一种后处理方法,在验证阶段对输入图片进行增强。本文使用TTA后处理进一步提高预测精确度,常见的流程是在验证阶段将输入图像进行多次旋转、缩放、翻转,然后依次预测,最后将预测结果进行特征融合得到最终的预测结果。对于比较小的医学数据集,该方法很有效。本文对增强方法选择翻转加旋转,因为胃癌病理图像具有位置、形状不固定的特点,通过翻转和旋转能大幅增加数据集的多样性,解决容易过拟合的问题。特征融合方式选择取平均。具体操作如图4 所示。
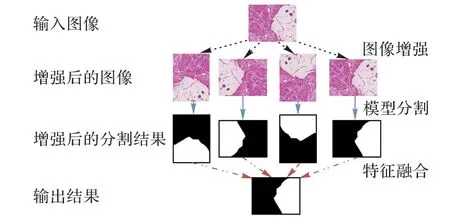
图4 TTA后处理过程Fig.4 Procedure of TTA post-processing
2 实验与结果分析
本文实验的硬件环境:CPU 为Intel Xeon Gold 5218 CPU@ 2.30 GHz,GPU 为NVIDIA Tesla V100。实验使用的PyTorch 版本为1.8.1,CUDA 版本为10.1。
2.1 数据集与预处理
SEED 数据集包含正常、管状腺癌、黏液腺癌3 种类型共1 770 张样本;BOT 数据集包含正常和病变两种类型共700 张样本。每一张图像都有对应的分割蒙版,其中:0 代表正常区域;255 代表病变区域。PASCAL VOC 2012 有2 913 张语义分割图片,训练集和验证集分别有1 464、1 449 张图片,共有背景、人、飞机等21 类。
胃癌病理细胞一般具备以下特征:1)癌细胞的细胞核体积比较大,通常是正常细胞的5~10 倍;2)癌细胞的外形一般不规则;3)癌细胞细胞质减小,细胞核与细胞质面积之比增大。它们是判断胃癌病理图像中有无病变区域的重要因素。
数据集中有的图像分辨率非常大,对比Patch 预测的结果与直接缩放到统一大小预测之后的结果,发现直接缩放的效果会好很多,所以在实验过程中会将所有图像统一缩放到512×512 大小。同时,因为CNN 对环境因素非常敏感,数据采集设备、光照、标注质量等都会影响最后的分割结果。为避免网络模型出现训练过拟合问题,在训练前对数据进行增强,提高训练集多样性,从而提高网络的鲁棒性。在获取图像数据前,使用albumentations 库对图像进行随机翻转、随机改变亮度、随机改变对比度、随机改变饱和度等操作,实际效果如图5 所示。图5(a)分别为原始图与它对应的分割蒙版;图5(b)分别为进行缩放和图像增强后的训练数据与它对应的分割蒙版,这样训练数据的多样性将会大大增加,可以有效防止数据过少或者单一导致的过拟合问题。
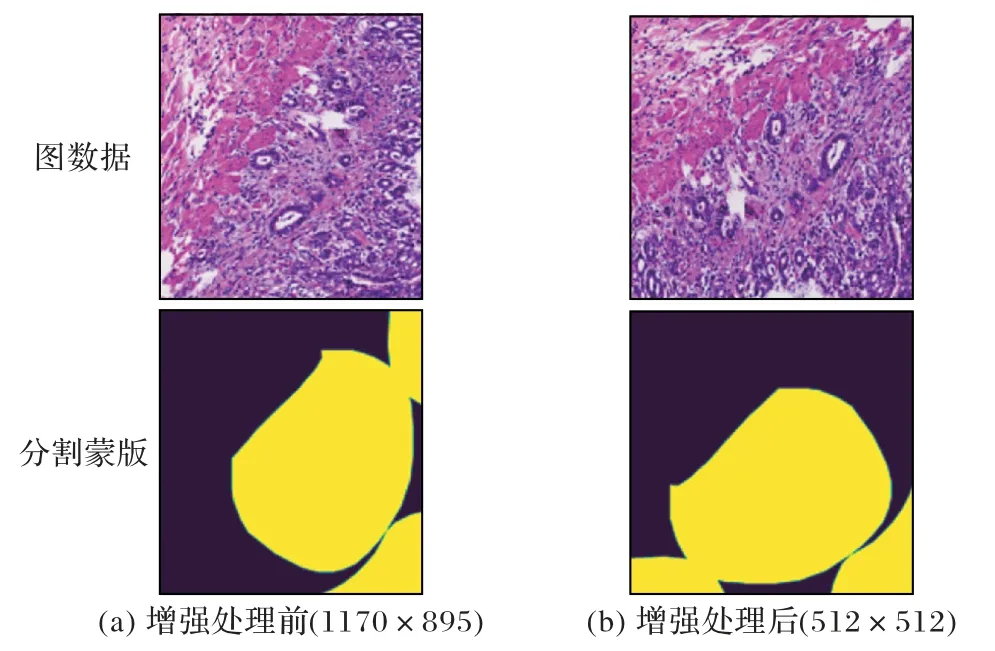
图5 增强处理前后的对比Fig.5 Comparison before and after enhancement processing
2.2 实验设置
平均交并比(Mean Intersection over Union,MIoU)是真实值和预测值两个集合的交并比,能客观地反映网络分割结果的好坏。MIoU 的计算公式见式(9):
其中:pij表示真实值为i,被预测为j的像素数量;k是类别个数;pii是预测正确的数量。MIoU 一般都根据类来计算,将每一类的交并比(Intersection over Union,IoU)计算出来后累加,最后再除以类别数,就能得到全局的预测评价。MIoU 越高,分割图像与分割蒙版重叠性越高,即分割效果越好。
本文首先通过消融实验验证每个模块的有效性,接着使用DeepLabV3+[8]、U-Net[11]、U-Net++[14]等经典医学分割模型与本文提出的EOU-Net 进行比较。
将数据集按8∶2 划分为训练集和验证集,设定随机种子为0 来保证数据集的一致性。在训练过程中,训练集的batch size 为12,验证集的batch size 为1,损失函数为二值交叉熵损失函数,优化器为Adam 优化器,初始学习率为10-4,学习率的调整策略为每30 个epoch 之后将学习率减半,总共训练250 个epoch,因为网络使用EfficientNetV2 的ImageNet21k 的训练权重进行迁移学习,所以初始学习率比较小,只需要根据新数据集进行微调便能达到很好的效果。训练集和验证集的MIoU 变化如图6 所示。
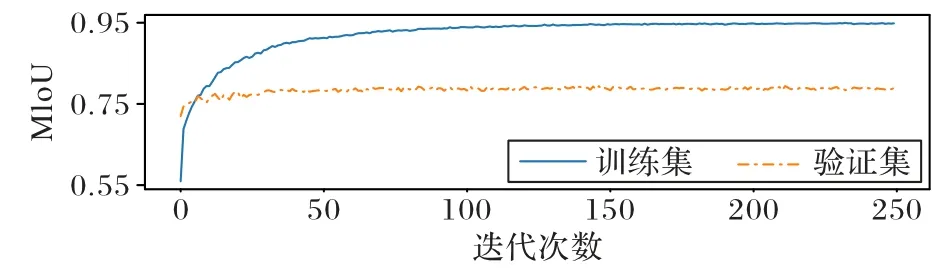
图6 训练集和验证集的MIoU曲线Fig.6 MIoU curves for training and validation sets
2.3 实验结果分析
2.3.1 消融实验
为了验证EOU-Net 各模块的有效性,分别对各模块进行消融实验,具体结果如表2 所示。基线模型为使用了ImageNet 预训练权重的EfficientNet 作为编码器的U-Net。首先,将编码器替换为使用了ImageNet 预训练权重的EfficientNetV2 之后,MIoU 比U-Net 提高了0.50%;在解码器上添加改进后的OCR 模块后,MIoU 比U-Net 提高了0.87%;使用TTA 后处理,MIoU 比U-Net 提高了1.62%。由此可见,本文提出的模块均能有效提升分割精度。
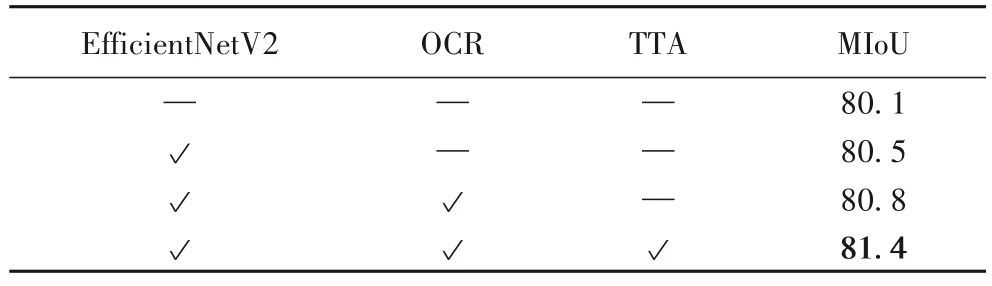
表2 EOU-Net消融实验结果 单位:%Tab.2 Ablation experimental results of EOU-Net unit:%
为了更直观地观察各模块的提升效果,随机从验证集中选出1 张图片,并依次使用不同的网络模型分割,具体结果如图7 所示,Label 为人工标注结果。从图7 中能更直观地看出各模块的有效性,将骨干特征提取网络换成EfficientNetV2后,找到的病变区域更准确,说明网络的特征提取能力确实有所提高;再加入改进后的OCR 模块之后,也能明显观察到分割边缘细节得到了优化;最后,TTA 后处理也能让EOUNet 在面对不同的环境因素时,表现差异不会过大。
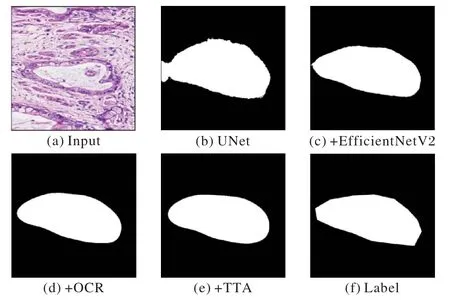
图7 消融实验可视化Fig.7 Visualization of ablation experiment
2.3.2 后处理方法对比实验
本文以未添加TTA 后处理的EOU-Net 作为基础模型,通过比较不同图像增强和特征融合的TTA 模块来找到最好的图像增强方式和特征融合方式。图像增强方法包括:水平垂直翻转、水平翻转、垂直翻转以及水平垂直翻转加旋转。特征融合方式包括:平均、相加和几何平均。同时,为了验证本文的后处理方法在胃癌数据集中的有效性,将它与经典的DenseCRF-n(n代表算法迭代的次数)后处理方法进行比较,具体结果见表3。
由表3 可以看出,选择水平垂直翻转加旋转的图像增强方式效果最好;同时,平均和相加的特征融合方式效果相当,MIoU 基本没有差别。实验中效果最好的TTA 模块与DeepLab 中的DenseCRF 后处理相比,MIoU 提升了1.10%。因为DenseCRF 算法要求分割区域的边缘与周围像素具有一定差异,所以并不适合特征复杂的医学图像,由此可见,本文的TTA 后处理优于经典后处理方法。
2.3.3 不同方法对比实验
1)SEED 数据集对比实验。
在SEED 数据集上将EOU-Net 与Att U-Net[15]、U-Net[11]、U-Net++[14]等经典网络进行了比较,具体结果如表4 所示。Att R2U-Net[13]和Att U-Net 没有使用ImageNet 预训练的权重,因此,将未使用ImageNet 预训练权重的EOU-Net 与这两个模型进行比较。可以看出,OCRNet 的表现一般,MIoU 比EOU-Net 小1.8 个百分点,说明对于医学分割还是U 型结构更通用。通过MIoU 和不同种类的IoU 结果可以发现,EOUNet 无论是正常区域还是病变区域分割结果都优于目前经典网络模型。
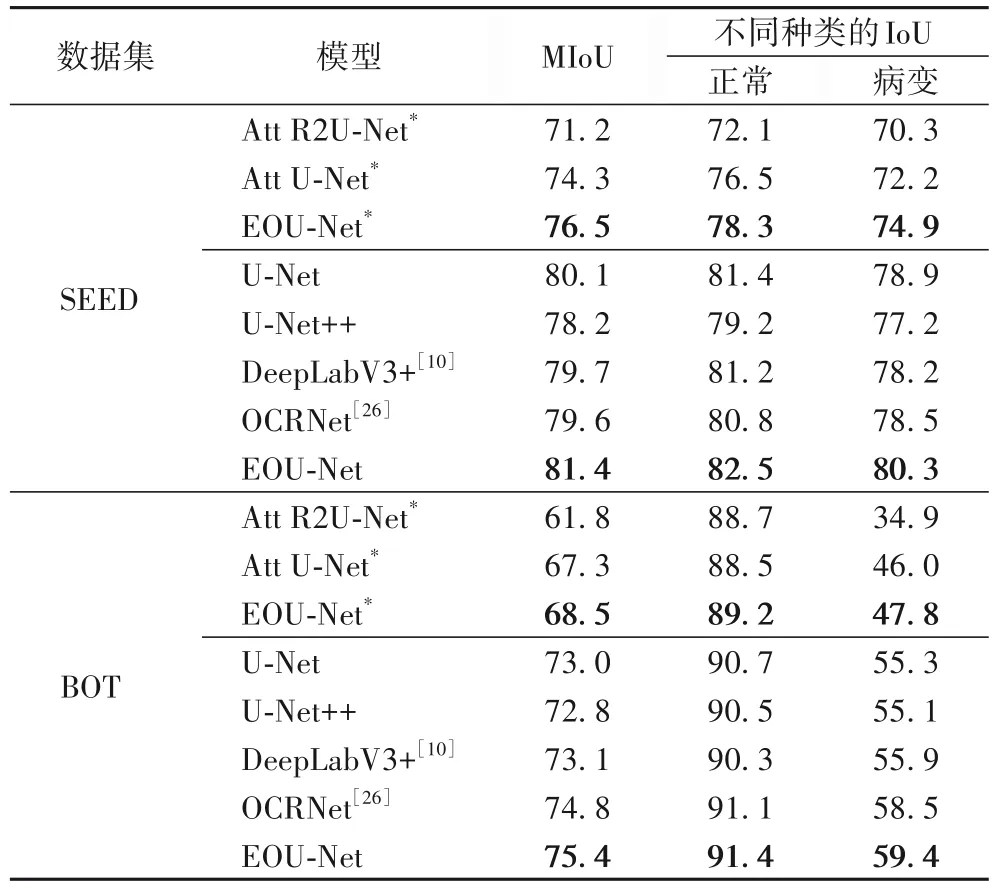
表4 SEED和BOT数据集上的对比实验结果 单位:%Tab.4 Comparison experimental results on SEED and BOT datasets unit:%
2)BOT 数据集对比实验。
为进一步验证EOU-Net 的有效性,在BOT 数据集上进行实验,结果见表4。实验设置和SEED 数据集一致,因为BOT数据集的较多样本病变区域占整张图像比例较小,所以病变区域的IoU 普遍不高。但是,从MIoU 和不同种类的IoU 结果可以看出,EOU-Net 能有效提高胃癌病理图片的分割结果,MIoU 比OCRNet 提高了0.6 个百分点。
为了更直观地比较预测结果,随机从验证集中挑出4 张病理图像,采用不同算法进行处理并显示分割效果,如图8所示。可以直观地发现,面对特征比较复杂的胃癌病理图像,EOU-Net 确实能更好地提取图片中的病变区域以及处理边缘信息,从而达到更好的分割结果。
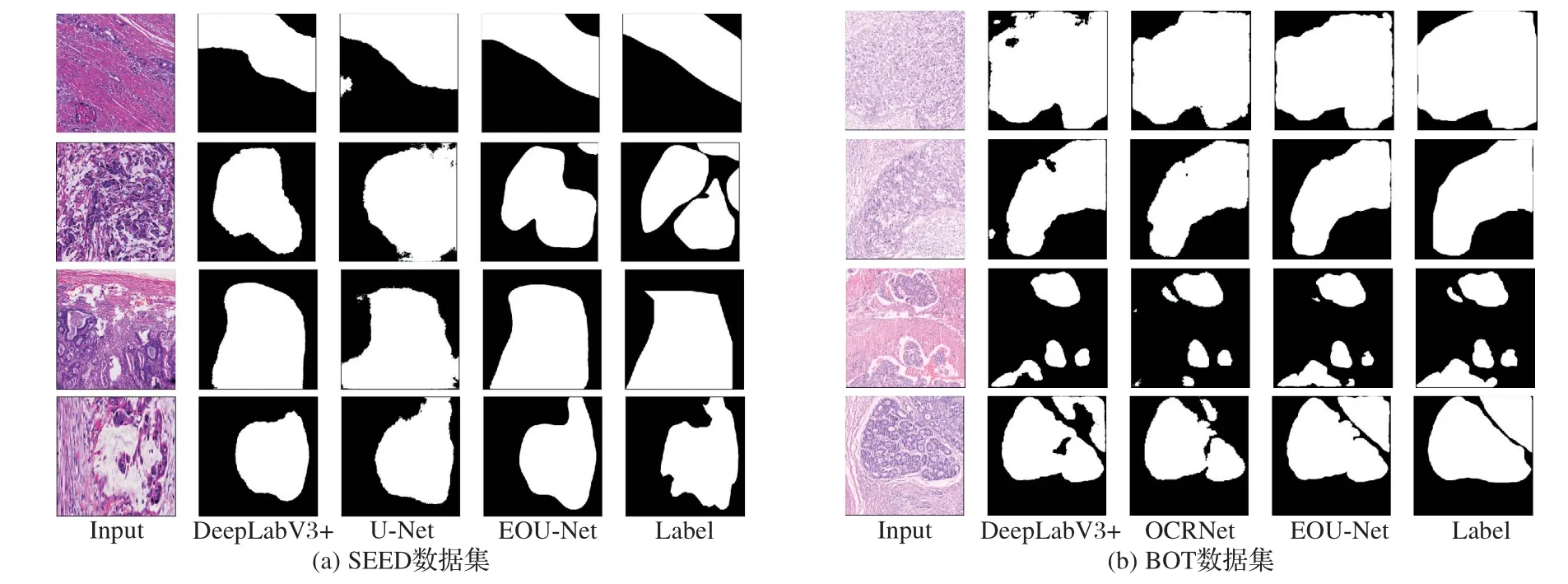
图8 对比实验可视化Fig.8 Visualization of comparison experiments
3)PASCAL VOC 2012 数据集对比实验。
在PASCAL VOC 2012 数据集上验证EOU-Net 在其他类型数据集上的表现,实验结果见表5。可以看出,EOU-Net 在非医学的数据集中的性能相较于经典网络也有所提高。当种类数变多时,U-Net 的MIoU 很低;而EOU-Net 不仅没有受太大影响,同时相较于OCRNet 有所提升,MIoU 提高了4.5个百分点。
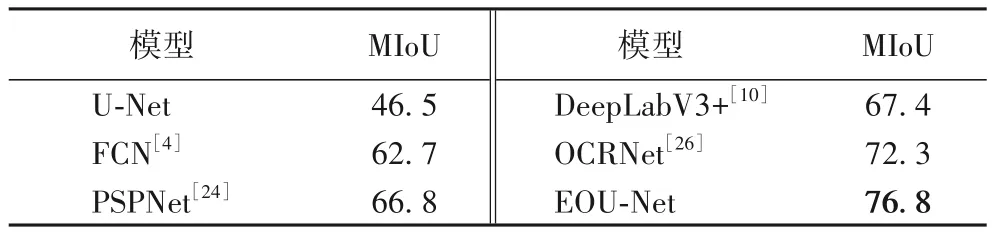
表5 PASCAL VOC 2012数据集上的对比结果 单位:%Tab.5 Comparison results on PASCAL VOC 2012 dataset unit:%
将EOU-Net、OCRNet 和DeepLabV3+进行可视化分割结果比较,如图9 所示。从图9 中也能更直观地发现EOU-Net确实能通过提高边缘分割精度从而提升网络分割准确度。
3 结语
本文针对胃癌病理图像特点,改进U-Net 模型的基本结构,提出了一种新的EOU-Net 模型。利用EfficientNetV2 的特征提取能力,使编码器部分能更好地提取胃癌病理图像复杂的病变特征;接着,通过改进后的OCR 模块,让网络在上采样阶段基于物体上下文特征探索像素间的关系,从而得到更好的边缘分割结果;最后,使用TTA 后处理方法,从多个旋转角度分别对输入图像进行分割,解决了医学图像数据集普遍偏小、容易出现过拟合的问题。在SEED 病理图像数据集、BOT 病理图像数据集以及PASCAL VOC 2012 数据集上的结果表明,本文的EOU-Net 能够有效提高网络分割效果,MIoU分别达到了81.4%、75.4%和76.8%,能为医生诊断提供辅助。然而,病理图像之间分辨率的差距非常大,本文在训练过程中将图像尺寸统一缩放到512×512,导致很多特征没有被充分利用,所以,未来准备在如何充分利用这些特征上作进一步研究。
