基于元网络的自动国际疾病分类编码模型
2023-09-27周晓敏
周晓敏,滕 飞,张 艺
(西南交通大学 计算机与人工智能学院,成都 611756)
0 引言
国际疾病分类(International Classification of Diseases,ICD)是依据疾病的某些特征,按规则将疾病分门别类并用编码的方法表示的系统。ICD 编码分配是为患者的诊断和治疗数据分配编码的过程,已经广泛地用于临床研究、医疗保健、医疗付费、诊断信息的检索等问题。然而,手工编码是劳动密集型任务并且容易出错[1]。因此,为了提高ICD 编码分配的准确性和效率,进行自动ICD 编码研究十分有必要。
自动ICD 编码分配被视为一种多标签文本分类问题,目的是从电子病历文本数据中提取信息并进行编码分配。然而,ICD 编码的分布呈现出长尾分布的问题,给研究带来了巨大挑战。具体来说,在临床中频繁出现的编码(本文称为频繁编码——many-shot)只占据总编码数的很少一部分,而临床中很少出现的编码(本文称为少样本编码——few-shot)却占据了总编码数的大部分。根据Teng 等[2]的统计,在医学数据集MIMIC-Ⅲ中共有18 000 多种ICD-9 编码,按照出现频率排序的前50 种编码占总数据的93.17%。少样本编码的训练样本是少样本编码自动分配研究的瓶颈所在。
少样本编码对于临床具有相当的重要性,主要体现在罕见病、医学研究以及医疗开销这几个方面。一方面,在临床中存在较多罕见疾病,如儿童早衰症、Cockayne 综合征等[3],这些疾病发病几率非常低,因此不容易观察到相应编码。罕见疾病的出现事关每一个患者的健康,正确为该记录分配正确的编码对于临床治疗至关重要。另一方面,随着医疗水平的发展,可能会引入一些新的编码,在这种情况下临床观察到的样本少,少样本编码的预测性能可能不会对ICD 编码的总体准确性产生重大影响,但是对于医学研究的发展可以起到积极的作用。另外,编码员在给电子病历分配编码时,可能更容易给电子病历分配常遇到的编码,而忽略或混淆少样本编码。例如,如果编码员在为电子病历分配编码时容易选择经常遇到的编码“Acute myocardial infarction,of other anterior wall,initial episode of care”(410.11:many-shot code),而不是正确的少样本编码“Acute myocardial infarction,of anterolateral wall,subsequent episode of care”(410.02:fewshot code)。编码员对少样本编码的错误分配会给患者造成不公平的经济负担,也加大了医疗机构的医疗投资。综上所述,本文认为对少样本编码的正确预测进行研究十分重要。
为了提高ICD 编码的准确性和效率,学者们对自动ICD编码进行了大量研究,包括传统的机器学习和深度学习模型。然而,在保持已有学习性能的同时,对训练数据较少的样本进行快速泛化仍然是神经网络模型面临的一个重大挑战。现有研究较少关注少样本编码,这些模型在少样本编码上的表现仍然不令人满意。由于ICD 编码数据的长尾分布,使得对少样本编码进行准确的多标签文本分类极具挑战性。
本文针对数据呈现出的长尾分布问题,提出一种元网络模型,在不牺牲整体编码性能的情况下能提高少样本编码的分类准确性。本文的主要工作如下:
1)提出一种基于元网络的ICD 编码模型(Meta Networkbased ICD Coding model,MNIC)。将频繁编码的特征表示映射到分类器权重上,以学习到元知识;同时,将元知识从数据丰富的频繁编码转移到数据贫乏的少样本编码,显著提高了少样本编码的性能,实现多标签文本分类的少样本学习。
2)对元知识的可转移性和通用性提供解释,证明了少样本编码和频繁编码存在通用的元知识。
3)在MIMIC-Ⅲ数据集上进行对比,验证了元网络模型有助于提高少样本编码的性能。
1 相关工作
在医疗保健领域,有关自动ICD 编码的研究已有约20 年的历史[4]。传统的机器学习模型以及深度学习模型被应用于临床文本的自动ICD 编码。Medori 等[5]使用具有不同属性集的朴素贝叶斯(Naive Bayes)优化了自动编码技术;Huang等[6]使用K 近邻(K-Nearest Neighbor,KNN)算法利用ICD 编码相关性构建了临床决策框架,改进了多标签分类算法;Koopman 等[7]使用支持向量机(Support Vector Machine,SVM)对死亡证书中癌症相关编码进行自动分类。除此之外,Perotte 等[8]尝试了平面分类器以及基于SVM 的层次分类器,证实了基于层次的分类器具有更良好的性能;Karimi 等[9]使用了SVM 和逻辑回归分类器(logistic regression classifiers)对放射学报告进行了自动ICD 编码。传统的机器学习为自动ICD 编码提供了解决思路,但需要手动选择特征。
随着深度学习的发展,许多研究者开始将卷积神经网络(Convolutional Neural Network,CNN)[10]、循环神经网络(Recurrent Neural Network,RNN)[11]、图卷积网络(Graph Convolutional Network,GCN)[12]、生成对抗网络(Generative Adversarial Network,GAN)[13]等应用于自动ICD 编码。Mullenbach 等[14]使用CNN 聚合文档信息,并使用注意力机制为编码分配提供可解释性;Chen 等[15]使用医学主题挖掘模型提取病历中最相关的片段,并提出一种多通道卷积注意力网络实现ICD 编码的自动预测;Ji 等[16]提出一种门控卷积神经架构,能够成功捕获临床文本中丰富的语义信息;Catling等[17]使用RNN 改善了医学文本的表示,并利用分层结构的医学知识提升了自动编码的性能;Yu 等[18]提出一种多层注意力双向递归神经网络模型,并证实了多层注意力机制的有效性;Cao 等[19]利用GCN 实现了编码共现,并借助编码的层次结构提升了模型表现;Xie 等[20]使用GCN 捕获编码间的层级关系及编码语义;Teng 等[21]使用GAN 生成对抗性样本以调和医生的写作风格,并引入知识图谱提高编码预测精度。
对于医疗编码的研究,医疗实体识别模型也是一大热点,这些研究主要关注从电子病历中识别不同类别医疗语义的短语。侯旭东等[22]针对深度学习技术在医疗实体识别问题中随着网络加深识别模型出现的识别精度与算力要求不平衡问题,提出一种基于深度自编码的医疗实体识别模型CasSAttMNER(Cascade Self Attention Medical Named Entity Recognition)。CasSAttMNER 模型与本文MNIC 的研究对象均为医疗文本,两者都采用自然语言处理提高医疗编码和分类的效率。不同的是,CasSAttMNER 模型进行的是实体识别研究,将医疗文本依据语义大致分为了6 种类别,而本文需要对医疗文本分配所有匹配的编码,编码的个数决定了N分类的精度要求。根据数据规模,本文使用了1 533 个编码,相当于需要分为1 533 个类别,与前者的6 个类别相比,任务难度不在一个数量级,因此两种模型的总体F1 分数也有显著差异;同时两个模型一个利用的是中文数据集,另一个是用的英文数据集,前者数据集文本总数为1 000 条,后者则为50 000 多条,在数据规模上的差异显著。
以上工作专注于提升常见编码的性能表现,忽略了少样本编码。Rios 等[23]最先关注到了ICD 编码的少样本及零样本学习,将出院摘要与利用具有图卷积神经网络(Graph CNN,GCNN)的结构化标签空间得到的每个编码的特征向量进行匹配,学会了预测少样本和零样本编码;Song 等[24]在他的模型基础上将GCNN 修改为GRNN(Graph Recurrent Neural Network),并使用GAN 为零样本编码生成伪特征,在保证可见编码性能的前提下提升了零样本编码的预测能力。然而这些模型在预测时几乎不会为临床文本分配少样本ICD 编码,目前最优模型少样本编码的F1 分数为19.17%。
以上研究为自动ICD 编码提供了重要的理论支撑,本文重点讨论了数据的长尾分布以及预测多标签的可解释性问题,提出了MNIC,捕获通用元知识以实现少样本学习;此外,本文使用T-SNE(T-distributed Stochastic Neighbor Embedding)图为元知识的通用性提供了有意义的解释。
2 模型构建
ICD 编码任务是一个多标签文本分类问题,设L={l1,l2,…,ls}是所有的ICD 编码的集合,其中,s为ICD 编码的数量。本文的目标是训练s个二元分类器。对于输入文本,每个分类器预测结果为,其中∈{0,1}是L 中的第i个编码的预测结果。每个ICD-9 编码l都有一个简短的编码描述。例如,466.1 的编码描述为:“急性细支气管炎”;466.11的编码描述为:“呼吸道合胞病毒(Respiratory Syncytial Virus,RSV)引起的急性细支气管炎”。
由于大部分ICD 编码并不常出现在临床文本数据中,使得ICD 编码频率的分布往往呈现出长尾分布。针对这个问题,本文主要关注少样本编码问题:在不牺牲频繁编码性能的情况下,准确预测少样本编码。
本文提出了一个用于自动ICD 编码的模型MNIC,整体框架如图1 所示。MNIC 主要由四个模块组成:第一个模块是数据输入;第二个模块是特征提取器,它从临床文档和ICD 编码描述中为每个编码提取最相关的语义信息,并且还训练了一个基础分类器获得了每个编码的初始权重,该基础分类器对于频繁编码表现良好,但对于少样本编码则不能令人满意;第三个模块是元网络,它从频繁编码的特征表示和分类器权重的映射中学习元知识,然后将元知识转移到少样本编码,并更新少样本编码的分类器权重;第四个模块是模型输出,它结合了频繁编码的原始分类器权重和少样本编码更新后的分类器权重,得到每个编码的二元分类器,输出最终的分类结果。
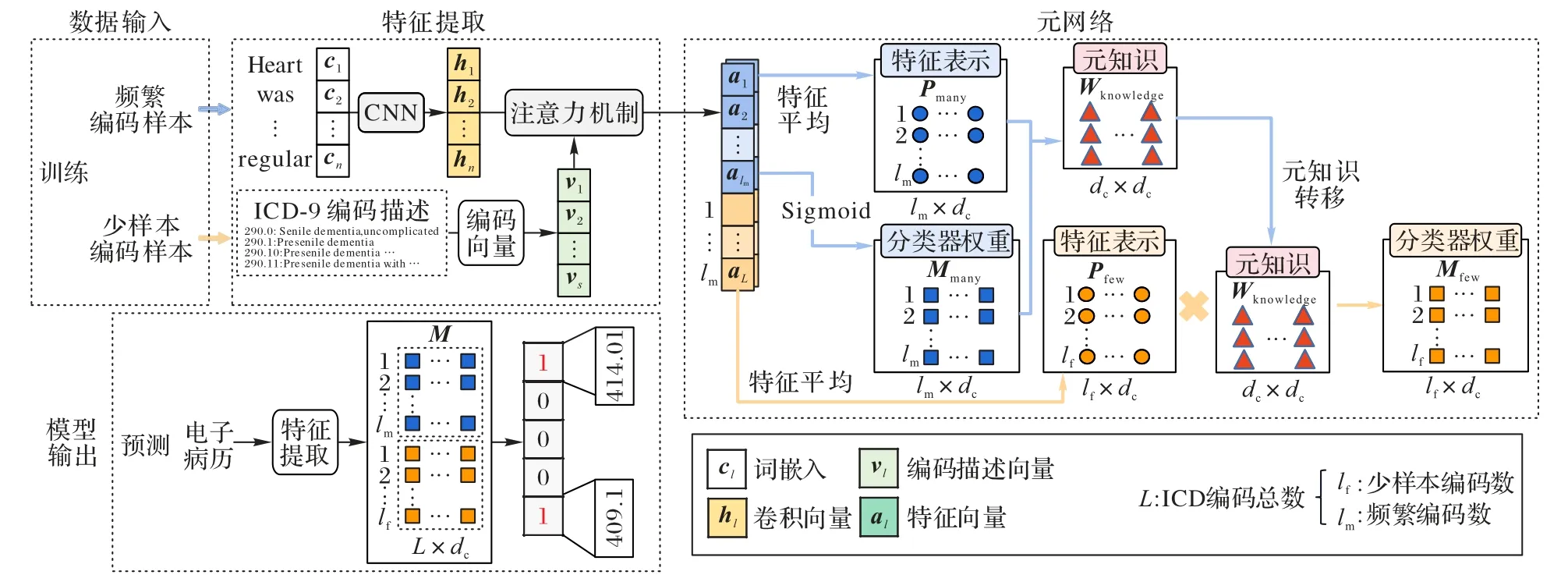
图1 MNIC的框架Fig.1 Framework of MNIC
2.1 输入层
给定一个包含n个单词的临床文本矩阵X=[x1,x2,…,xi,…,xn],对于每个单词xi,使用预训练的词嵌入方法得到每个单词的词嵌入向量ci(具有相同的维度de),得到输入文本的词嵌入向量表示D=(c1,c2,…,ci,…,cn)。
2.2 特征提取
给定输入矩阵D,特征提取模块旨在从每个输入中提取每个编码最相关的表示。具体来说,本文首先使用卷积层学习单词表示,并且为了更好地提取语义信息,使用编码描述使编码在医学领域具有说服力和可解释性;然后,使用标签注意力机制来学习每个编码最相关的特征向量。
2.2.1 卷积层
给定输入数据D,卷积层的目标是从数据密集且信息丰富的词嵌入中学习文本语义信息。在CNN 中没有使用池化层,而是通过标签注意力机制在文档中找到每个编码最相关的特征。使用卷积滤波器组合相邻词嵌入,k为滤波器宽度;de为输入的词嵌入维度;dc是滤波器输出大小。计算公式为:
2.2.2 编码向量
每个ICD 编码l都有一个编码描述,为了表示l,本文对每个编码描述进行预处理。首先将编码描述中的所有单词小写并删除停止词,然后通过平均剩余单词的词嵌入向量来形成编码向量
其中,N是编码描述中剩余的单词数。
2.2.3 注意力机制
由于临床文本很长,并且每个文档有多个编码,每个编码的相关信息可能分散在整个文档中。针对这个问题,本文采用标签注意力机制,使模型可以关注文本的不同部分。标签注意力机制的计算公式为:
2.2.4 基础分类器
本文将每个编码的特征al作为输入传递给全连接神经网络,然后使用Sigmoid 激活函数生成第i个编码的概率为所有编码构建一个基本分类器,得到每个代码l的分类结果如下:
其中:yi∈{0,1}是第i个编码的基本事实是第i个编码的预测结果;lm是频繁编码的个数。
2.3 元网络
通过特征提取模块,在每个样本中可以获得所有编码的特征向量,对d个包含r编码的样本进行采样,通过训练好的
特征提取器,获得特征表示{ar1,ar2,…,ard}。然后通过取这些向量的平均值,获得频繁编码r和少样本编码z的特征表示分别为Mmany联系起来。将每个频繁编码的特征pr映射到相应的频
元网络将频繁编码特征pmany和频繁编码分类器参数繁编码的分类器参数mr,通过多任务学习得到一个少样本编码模型参数到频繁编码模型参数的映射关系,这种映射关系为少样本编码提供了元知识Wknowledge。对于每个频繁编码,本文取样U次(U通常取30 或40),以获得不同的频繁编码的特征表示,这样可以训练一个可推广的迁移元网络学习器,提高模型的泛化性。
通过最小化损失Lt进行学习:
本文可以利用元知识将少样本编码特征表示Pfew(fewshot)映射到它的分类器参数Mmany(many-shot),从而将元知识从频繁编码迁移到少样本编码,提高少样本编码的分类性能。由式(8)能得到少样本编码z的编码特征表示
2.4 输出层
在输出层将频繁编码的分类器权重Mmany和更新后的少样本编码的分类器参数进行连接,得到用于预测的整个分类器权重M。
给定一个测试文档,首先通过特征提取器得到它的特征向量g,然后通过Sigmoid 激活函数,产生给定文档的预测结果。
3 实验设置
3.1 环境配置
本文的实验环境为Windows10 操作系统,CPU 为Intel Core i7-10700,GPU 为Nvidia GeForce RTX3060 12 GB,CUDA11.1。
3.2 数据介绍
MIMIC-Ⅲ[25]是由麻省理工学院开发的公开可用数据集,包含了2001—2012 年间在贝斯以色列女执事医疗中心重症监护病房的4 万多名患者约58×103相关数据。每份病历的出院小结中包含主诉、既往病史、诊断结果等。患者每次入院都会生成1 组ICD-9 编码,具有准确性与权威性。MIMIC-Ⅲ数据集经常被用于验证模型的有效性。
本文参考了文献[14]中的数据预处理方法。对文本进行分词,将所有标记转换为小写,使用“
3.3 数据划分
本文采用了Rios 等[23]提出的数据划分方式。少样本编码与频繁编码划分的前提是这些编码存在于验证集或测试集中。以验证集为例,在验证集中具有<5 个数据示例的ICD 编码不参与评估。若某ICD 编码同时出现在验证集及训练集中并且在训练集中的数据示例≤5,那么将它定义为少样本编码;否则将它定义为频繁编码。测试集中的编码划分标准与验证集相同。最终的少样本编码由验证集与测试集中少样本编码求并集得到。频繁编码由验证集与测试集中的频繁编码求交集得到。表1 中展示了编码划分后的结果。

表1 ICD编码划分结果Tab.1 ICD code division result
3.4 基线模型
CNN[26]:使用一维卷积神经网络进行句子分类。
双向门控循环单元(Bidirectional Gate Recurrent Unit,BiGRU)[14]:执行ICD 编码。
CAML(Convolutional Attention for Multi-Label classification)[14]:用于多标签分类的卷积注意力网络,包含一个单层CNN 和一个注意力层,为每个ICD 编码生成与标签相关的表示。
ZAGCNN(Zero-shot Attentive Graph Convolutional Neural Network)[23]:利用结构化标签空间和GCNN 来预测多标签集合中的少样本和零样本标签。
AGM-HT(Adversarial Generative Model conditioned on code descriptions with Hierarchical Tree structure)[24]:利用ICD编码层次结构和新颖的隐特征生成框架来实现多标签文本分类的广义零样本学习。
3.5 评价指标
使用精度(precision)、召回率(recall)、F1 分数、曲线下面积(Area Under Curve,AUC)来评价各模型表现。在Micro 上分别用RMicro-pre、RMicro-rec与RMicro-F1表示:
其中:n为ICD 编码总数;TP指预测为正例,实际也为正例的个数;FP指预测为正例,实际为负例的个数;FN指预测为负例,实际为正例的个数。
在Macro 上用RMacro-pre、RMacro-rec与RMacro-F1表示:
3.6 超参数设置
实验中的参数为:词嵌入维度de=200;语义提取器中CNN 的卷积核大小为10;出院小结文本的最大长度为2 000;dropout 率为0.5;生成特征表示时各类别编码采样的文本数为5,对于文本实例不足5 份的少样本编码,则根据它在训练集中对应的文本实例数确定该值;学习率为0.001;batch_size 为8。
4 实验与结果分析
4.1 实验结果
表2 展示了MNIC 与基线模型在所有编码上的实验结果。可以看出,MNIC 在大部分指标上都有一定提高,说明模型在提升少样本编码性能的同时未损害频繁编码的性能。表3 展示了MNIC 与基线模型在少样本编码上的结果对比。可以看出,与较先进的AGM-HT 相比,MNIC 将Micro-AUC 和Micro-F1 提高了3.82 和3.77 个百分点。实验结果验证了元网络策略的有效性,它将学到的知识从数据丰富的频繁编码转移到数据贫乏的少样本编码。
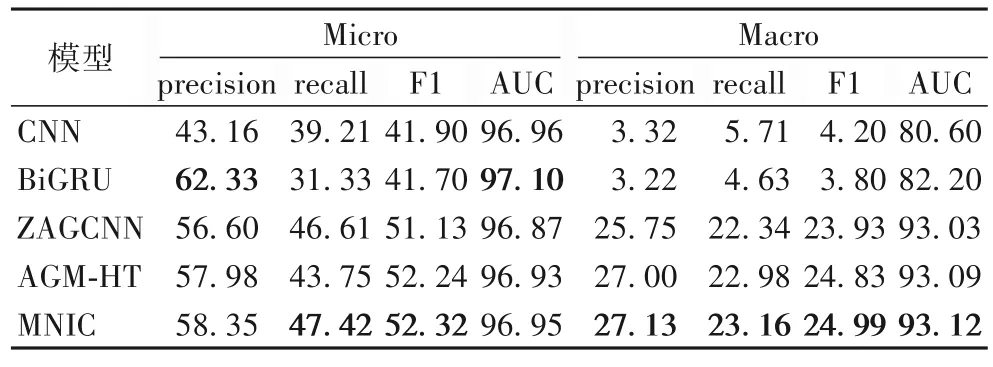
表2 各模型在所有编码上的实验结果 单位:%Tab.2 Experimental results of each model on all codes unit:%
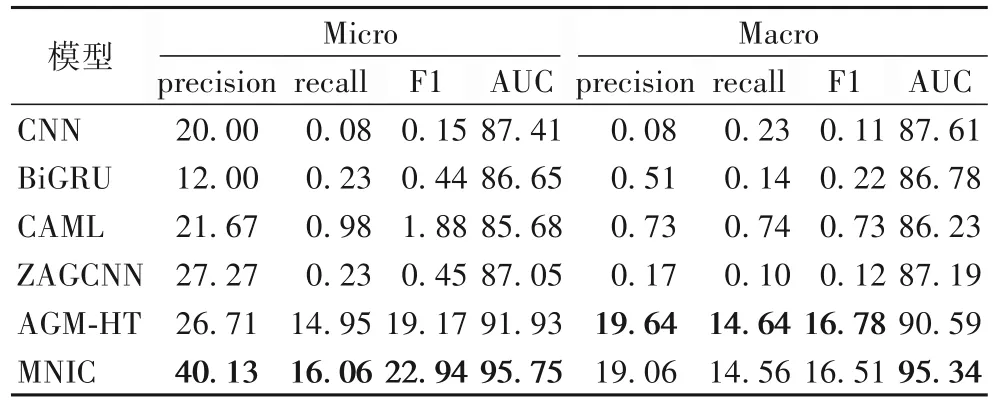
表3 各模型在少样本编码上的实验结果 单位:%Tab.3 Experimental results of each model on few-shot codes unit:%
尽管MNIC 的Micro 指标表现出色,但Macro 指标与AGM-HT 差距不大,这是因为少样本编码的数据量相对较小,样本间的差异和不确定性较大,这可能导致模型在计算Macro 指标时无法完全捕捉到每个类别的平衡性和整体性能;其次,MNIC 的架构和训练策略可能在一些类别上产生了不均衡的学习效果,导致Macro 指标没有显著提升。在实际情况中,对于大多数应用场景,Micro 指标更重要,因为它们考虑了所有类别的综合性能。因此,虽然MNIC 在Macro 分数上略低于AGM-HT,但它仍然是一种有效的模型,能够在少样本编码任务中取得显著改进。
4.2 消融实验
消融实验用于验证元网络模块的有效性。本文将去除元网络模块的模型称为MNIC-MN(Meta Network-based ICD Coding model -Meta Network)。在少样本编码上的消融实验结果如表4 所示。可以看出,MNIC 在所有的评估指标中获得了最好的结果,在没有元网络模块时,与完整的MNIC 相比少样本编码的Micro-F1 和Micro-AUC 下降了19.28、7.96个百分点。以上结果表明,元网络学到的元知识能够提高少样本编码的性能表现。

表4 消融实验结果 单位:%Tab.4 Ablation experimental results unit:%
4.3 模型可解释性
在手动编码临床记录时,编码人员通常需要寻找相关疾病描述等证据来佐证自己的判断。自动ICD 编码模型同样也需要分配编码的证据,即可解释性。自动ICD 编码的可解释性有助于提高编码员频繁编码的编码效率,同时也为编码员提供了少样本编码的选择,避免忽略罕见病的编码,从而获得专业编码员的支持和信任。
图2 为一些频繁编码样本和少样本编码样本的特征和特征表示(特征的平均值)绘制的T-SNE 图。较浅的色点是频繁编码和少样本编码特征降维的结果;较深的点是频繁编码和少样本编码的特征表示降维的结果。
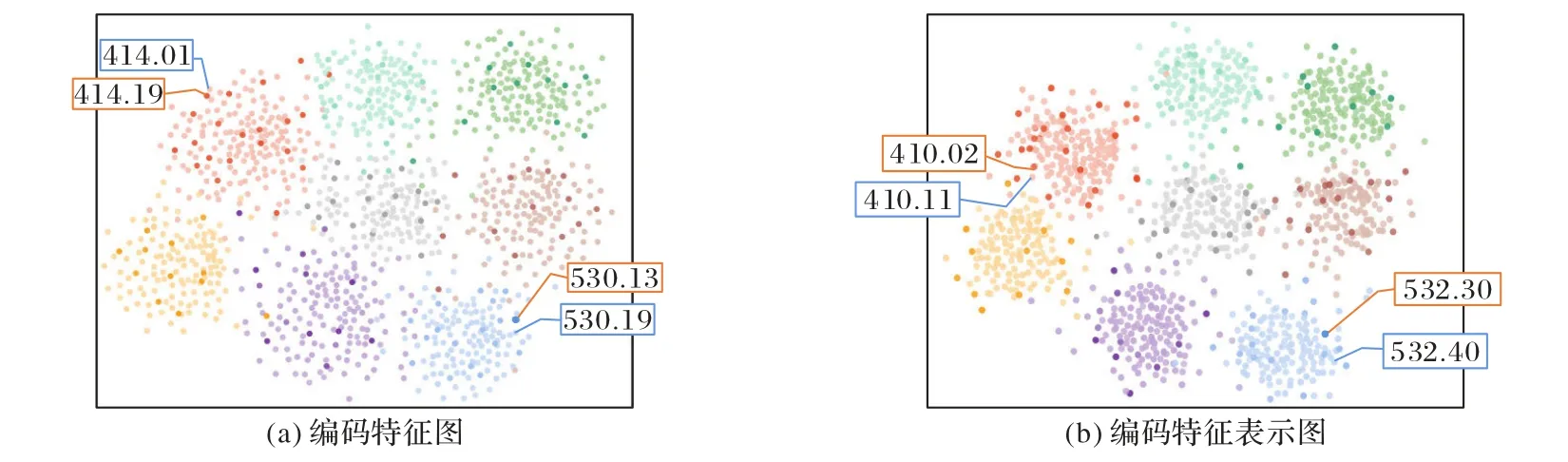
图2 T-SNE图Fig.2 T-SNE plots
图2(a)为使用部分频繁编码及少样本编码特征绘制的T-SNE 图,414.01、530.19 为频繁编码,414.19、530.13 为少样本编码;图2(b)为频繁编码原型及少样本编码原型绘制的T-SNE 图,410.11、532.40 为频繁编码,410.02、532.30 为少样本编码。图2(b)的编码特征表示2D 降维结果呈现出聚集性,表明它们具有相似的由少样本编码到频繁编码的映射转换方式。可以发现特征表示使降维结果更加集中,这是特征表示模块提高少样本编码性能的前提。此外,从图2 可以看出,频繁编码和少样本编码的特征表示的2D 降维结果呈现出一定程度的聚类,这说明相似的频繁编码和少样本编码具有相似的映射方式,因此可以通过从频繁编码学习元知识转移到少样本编码,从而提高小样本的编码性能。频繁编码和少样本编码可以实现聚类,是由于ICD 编码存在层次结构,相近的兄弟或者父子编码有相似的编码描述,这为元知识学习和转移提供了基础。
5 结语
本文提出了一种基于特征表示的元网络模型MNIC 用于ICD 编码的少样本学习。通过元网络将元知识从数据丰富的频繁编码转移到数据贫乏的少样本编码,在不影响频繁编码性能的情况下对少样本编码的性能进行了改进。在MIMIC-Ⅲ数据集上的实验结果表明,与目前最先进的模型相比,MNIC 的表现具有优越性。使用MNIC 能够改善大规模多标签数据中长尾问题所带来的影响。尽管本文的实验结果相较于同类研究性能大有提升,但是由于本文数据规模较大,训练模型的计算消耗也较大,文献[22]中的模型减少了编码深度以及对训练和应用上的算力要求,未来对于小样本分类的研究也可以考虑借鉴该思路,从减少算力要求并且不损失性能的角度入手继续优化模型。
